[인공지능사관학교: 자연어분석A반] 텍스트마이닝 (7)
지난 시간 복습
- 네이벼 영화 리뷰 분석
- 허깅페이스 transformers 라이브러리를 사용해 다양한 모델을 적용
- KoBERT
- KoELECTRA
- KoBART
- ex01
- ex02
- 모델 학습 결과를
./results/에 저장 → 저장해두면 나중에 가져와서 재활용도 가능
- 모델 학습 결과를
- 허깅페이스 transformers 라이브러리를 사용해 다양한 모델을 적용
- Fine-Tuning
- 대규모 언어 모델(LLM)을 개인 데이터에 맞춰 조정하는 기법
- cf. pre-train: 대규모 데이터셋으로 모델을 사전 학습하는 과정 → 다양한 데이터셋을 활용해 기본적인 언어 이해 능력 학습
- Downstream Task: 특정 작업 성능 향상을 위한 과정 → 특정 작업에서 성능을 내기 위해 모델을 미세 조정
- cf. Upstream Task: 대량의 데이터셋으로 모델을 학습하는 과정
- 대규모 언어 모델(LLM)을 개인 데이터에 맞춰 조정하는 기법
- 연합 뉴스 데이터셋(YNAT)
- 뉴스 카데고리 분류와 같은 특정 태스크에 맞춰 학습을 진행하는 건 '다운스트림 학습/파인튜닝'
- 데이터셋을 train, validation, test 세트로 분리하여 학습 준비
- 데이터셋에서 타이틀과 레이블 컬럼만 추출하여 학습용 데이터셋 구성 → 불필요한 컬럼은 삭제하여 효율적 데이터셋 생성
- 레이블은 숫자 인덱스에서 문자열(IT, 과학 등)로 변환해 가독성 향상
- transformers map 함수: python apply 함수와 같은 역할(to apply a processing function to each example in a dataset, independently or in batches.)
- map 함수를 사용해 숫자 레이블을 문자 레이블로 변환
모델 선정 및 학습
- Hugging Face가 제공하는 transformers 라이브러리 사용
- AutoModelForSequenceClassification
- AutoModel 써도 됨
- AutoTokenizer
- AutoModelForSequenceClassification
- 로버타(RoBERTa) 모델을 체크포인드로 불러와 분류 작업에 활용
RoBERTa
- facebook AI가 2017년도에 발표한 모델
- BERT의 성능을 개선
from transformers import AutoModelForSequenceClassification, AutoTokenizer, TrainingArguments, Trainer
# 토큰화 과정에서 패딩, 배치 처리할 거라 DataCollator 생략
import torch
import numpy as np
# 분류를 위해 사용할 모델 huggingface 경로
checkpoint = "klue/roberta-base"
# 토큰화 도구 생성
tokenizer = AutoTokenizer.from_pretrained(
checkpoint
)
# 모델 불러오기
model = AutoModelForSequenceClassification.from_pretrained(
checkpoint
, num_labels=len(train_dataset.features["label"].names)
)
# 토큰화(title)
def tokenizer_function (example):
return tokenizer(
example["title"]
, padding="max_length"
, truncation=True
# , max_length=128 → title이라 그렇게 길지 않을 것으로 추정되므로 따로 최대 길이 지정 X
)
train_dataset = train_dataset.map(tokenizer_function, batched=True, batch_size=1000)
valid_dataset = valid_dataset.map(tokenizer_function, batched=True, batch_size=1000)
test_dataset = test_dataset.map(tokenizer_function, batched=True, batch_size=1000)
print(train_dataset[0]){
'title': 'SKT AR동물원 개장'
, 'label': 0
, 'label_str': 'IT과학'
, 'input_ids': [0, 19963, 13122, 27589, 2252, 8886, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
, 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
, 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}추가: 허깅페이스 map() function
- 토크나이저
- 텍스트를 토큰 단위로 변환
- 패딩, 트런케이션, 최대 길이 설정 가능
- 패딩: 최대 길이보다 짤은 문장에 빈 토큰 추가
- 트런케이션: 최대 길이보다 긴 문장 자르는 과정
평가 함수 정의
# 평가 함수 정의
# 모델의 출력 logits을 통해 예측값 확인 후 실제 레이블과 비교하여 정확도 계산
def compute_metrics (eval_pred):
# eval_pred: HuggingFace에서 Trainer 객체를 사용할 때 자동으로 전달되는 값. 튜플 형태 → (logits, labels)
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1) # 모델의 출력값 중 최댓값의 인덱스를 출력
return {"accuracy": (predictions == labels).mean()} # 정확도 계산: predictions == labels → True(1), False(0) → 합의 평균- eval_pred
- Hugging Face Trainer에서 자동으로 출력되는 객체
- 튜플 형태: (logits, labels)
- 로짓과 레이블 두 개의 배열로 구성
- 정확도 계산에 사용
- logits
- 모델이 출력한 값(모델의 출력값)
- 모델이 출력하는 정답에 대한 확률 전 단계의 점수
- 소프트맥스 이전 값
- 형태(shape)는
[batch_size, num_labels] - 예시:
- 모델이 출력한 값(모델의 출력값)
logits = np.array([
[1.2, 0.3, 2.5], # 샘플 1에 대한 logit
0.1, 3.2, 0.8], # 샘플 2에 대한 logit
...
])- labels
- 실제 정답
- 정확도
- 전체 데이터에서 맞춘 비율
- 따라서 맞춘 횟수의 평균을 내면 정확도가 나옴
- 정확도는 맟춘 샘플 수의 평균으로 계산: 맞음 1, 틀림 0으로 처리되기 때문
- 로짓에서 가장 큰 값을 예측값으로 선택하고 실제 레이블과 비교
- numpy의 argmax 함수를 이용해 최댓값을 가진 인덱스를 추출한 뒤 정답과의 일치 여부 판단
모델 하이퍼파라미터 설정 및 트레이닝
- DataCollatorWithPadding의 경우 앞선 토큰화 과정에서 패딩 및 배치를 완료했으므로 생략
학습 모델 설정
- Huggingface의 Transformers 라이브러리의 TrainingArguments()를 사용
- 모델 학습 과정에 필요한 다양한 설정값을 정의
- 각 매개변수는 학습 성능과 효율정을 조절
✅ Huggingface TrainingArguments 설정 요약
| 매개변수 | 설명 |
|---|---|
output_dir="./results" | 학습 결과 저장 디렉토리 (모델, 로그, 체크포인트 등 저장) |
num_train_epochs=10 | 전체 학습 데이터 반복 횟수 (Epoch 수) |
per_device_train_batch_size=4 | 각 디바이스(GPU/CPU)별 배치 크기 |
gradient_accumulation_steps=1 | 그래디언트 누적 스텝 수 (메모리 절약용) |
optim="paged_adamw_32bit" | 32비트 정밀도 사용 AdamW 옵티마이저 변형 |
save_steps=25 | 몇 스텝마다 모델을 저장할지 설정 |
logging_steps=25 | 몇 스텝마다 로그를 기록할지 설정 |
learning_rate=2e-4 | 학습률 설정 |
weight_decay=0.001 | 가중치 감소 계수 (정규화 효과로 과적합 방지) |
fp16=False | 16비트 부동소수점 정밀도 사용 여부 |
bf16=False | BF16 정밀도 사용 여부 (Brain Floating Point) |
max_grad_norm=0.3 | 그래디언트 최대 노름(norm) 값 설정 (폭발 방지) |
max_steps=-1 | 전체 학습 스텝 수 (-1은 전체 epoch만큼 학습) |
warmup_ratio=0.03 | 학습률 워밍업 비율 (초기 안정적 학습 유도) |
group_by_length=True | 입력 시퀀스 길이에 따라 배치 그룹화 (패딩 최적화) |
lr_scheduler_type="constant" | 학습률 스케줄러 유형 (constant는 고정) |
report_to="tensorboard" | TensorBoard에 로그 기록 여부 설정 |
- TrainingArguments
- 학습 시 필요한 하이퍼파라미터를 설정하는 객체
- 저장 디렉터리, 에폭(epoch) 수, 배치 사이즈, 로깅 및 체크포인트 저장 주기 등을 포함
- 다양한 파라미터를 적절히 조절하여 모델 성능 최적화 가능
- 학습 시 필요한 하이퍼파라미터를 설정하는 객체
# 모델 하이퍼파라미터 설정
training_args = TrainingArguments(
output_dir="./results/roberta-base-klue-ynat-classification"
, num_train_epochs=1
, per_device_train_batch_size=8
, per_device_eval_batch_size=8
, learning_rate=5e-5
, push_to_hub=False
)- Trainer 객체
- 모델, 학습 데이터셋, 평가 데이터셋, 평가 함수, 트레이닝 아규먼트를 전달하여 학습 진행
- 학습 시 GPU 사용하기
# 학습 객체(트레이너) 생성
trainer = Trainer(
model=model
, args=training_args
, train_dataset=train_dataset
, eval_dataset=valid_dataset
, tokenizer=tokenizer
, compute_metrics=compute_metrics
)
# 모델 학습
trainer.train()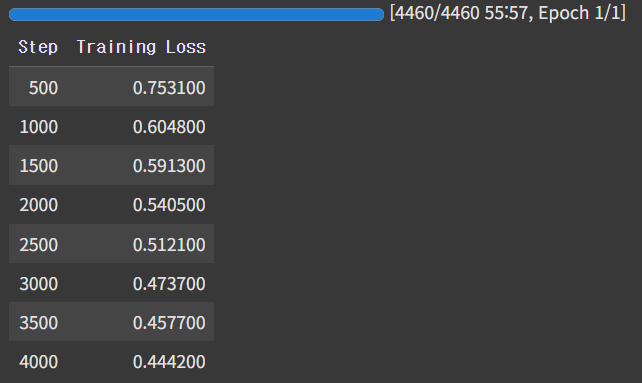
핵심 개념:
업스트림 태스크와 다운스트림 태스크 차이
파인 튜닝 vs 사전 학습(Pre-training / From scratch)
→ 파인 튜닝의 반대, 대비되는 개념은 “모델을 처음부터(제로 베이스) 학습시키는 것” 또는 “사전 학습(Pre-training, Pretrain)” (“From scratch(처음부터)”라는 표현도 자주 사용)
로짓 값과 정확도 계산 원리
평가 함수 구현 방법
핵심 단어:
프리트레인 / 다운스트림 / 로짓 / 토크나이저 / 트레이닝아규먼트
- Point:
- LLM의 업스트림, 다운스트림 개념
- 사전 학습 vs. 파인 튜닝
- 로짓 값을 이용한 정확도 평가 함수 구현
파인튜닝 관련 1
파인 튜닝(Fine-tuning)과 대비되는 가장 일반적인 용어는 사전 학습(Pre-training)
파인 튜닝은 이미 대규모 데이터로 사전 학습된(Pre-trained) 모델을, 특정 작업이나 도메인에 맞춰 추가로 미세하게 학습(fine-tune)시키는 과정
사전 학습(Pre-training): 매우 방대한 범용 데이터를 사용해서 모델이 기초적인 언어나 지식 능력을 습득하게 하는 첫 단계이고 파인 튜닝(Fine-tuning)은 그 사전 학습된 모델을 목적에 맞는 소량의 특화 데이터로 추가 학습시켜, 특정 응용(예: 법률, 의료 등)에 맞게 최적화하는 단계파인튜닝 관련 2: 'PLM을 이용한 성능 향상 방법'
Feature-based Approach는 Fine-tuning과 대비되는 대표적 전이학습(transfer learning) 방식 중 하나
Feature-based Approach(피처 기반 방식)는 사전학습(pre-trained) 모델의 파라미터는 고정(업데이트하지 않음)하고, 사전학습 모델이 출력한 임베딩(특징 벡터)을 새로운 다운스트림 과제에 맞는 레이어(예: 분류기)에 입력하여 그 레이어만 따로 학습시키는 방식
Fine-tuning과는 반대로, fine-tuning은 사전학습 모델 전체(혹은 대부분)의 파라미터를 다운스트림 과제 데이터로 다시 훈련시키는 방식
Feature-based Approach는 특히 데이터가 적거나, 사전학습된 모델이 이미 충분히 일반적일 때 자주 사용되고, 연산·메모리 효율성이 높음
- 즉,
- 사전학습 모델로부터 feature(임베딩)를 추출
- 그 feature를 입력으로 사용해 별도의 분류기(예: 로지스틱 회귀, SVM 등)만 훈련
- 사전학습 모델 자체는 변경(업데이트)되지 않음
- 정리:
- Fine-tuning: 임베딩 포함 전체(혹은 일부) 모델 파라미터를 모두 업데이트
- Feature-based: 사전학습 모델은 고정, feature만 추출해서 그 위에 얹은 새로운 레이어만 학습
모델 성능 평가
trainer.evaluate(test_dataset){'eval_loss': 0.4929060637950897,
'eval_accuracy': 0.843,
'eval_runtime': 26.7698,
'eval_samples_per_second': 37.356,
'eval_steps_per_second': 4.669,
'epoch': 1.0}- 로스와 정확도 확인
- 학습한 데이터 양에 비해 양호한 성능 확인
- loss만으로는 정규 지표가 아니기 때문에 정확도와 함께 평가하는 것이 중요
eval_runtime은 평가에 소요된 시간(초 단위)- 이 외에도 초당 스탭 수 등의 주요 평가 지표가 존재함 → 우리가 봐야 할 건 loss, accuracy, epoch 정도
허깅페이스에 모델 업로드
- hugging face token 파일로 저장하기
데이터 업로드 및 저장 방법
- 허깅페이스 로그인 후 api-key를 가져와 이를 입력하는 것으로 데이터를 업로드할 수 있음
- results 폴더에서 해당 모델을 확인해 보면 학습 중간중간 체크포인트마다 데이터가 저장되어 잏음
- 체크포인트는 학습 횟수에 따라 구분되어 저장됨
- 1000개~2000개 단위로 처리됨
- results 폴더에서 해당 모델을 확인해 보면 학습 중간중간 체크포인트마다 데이터가 저장되어 잏음
- 로컬에 저장된 모델을 허깅페이스에 업로드하기 위해 로그인 및 API 토큰 필요
- API 토큰은 허깅페이스 사이트에서 생성
- 토큰 생성 시 반드시 "write" 권한으로 발급하기
- 매번 토큰을 복사해서 붙여넣는 과정이 번거로움 → 허깅페이스 토큰을 파일로 저장해 관리
- os 라이브러리를 활용해 API 키를 저장할 폴더 생성 및 파일 저장 자동화
# token 파일로 저장해두기: open 사용해 불러 사용할 수 있게 됨
# 폴더 생성 → api_key 저장
import os # 파일, 폴더 관리 시스템
if not os.path.exists("./key"):
os.mkdir('./key')
# 나의 api_key 등록
api_key = "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"
with open("./key/huggingface_api_key", 'w') as f:
f.write(api_key)
# 허깅페이스 로그인
from huggingface_hub import login
# 파일 형태의 api_key 불러오기
with open("./key/huggingface_api_key", 'r') as f:
api_key = f.read().strip()
login(token=api_key)
# 허깅페이스에 업로드
# repo_id(report id) == 이름: 사용모델, 데이터, task 기록
repo_id = f"be2be2/roberta-base-klue-ynat-classification"
trainer.save_model(repo_id)
model.save_pretrained(repo_id)
tokenizer.save_pretrained(repo_id)
trainer.push_to_hub(repo_id)- API 키 관리 시 주의사항
- 토큰은 개인별로 발급받아야 함
- 타인의 토큰 사용 금지
- 토큰 공개되지 않도록 주의
- 악용 사례 발생 가능
- 토큰은 개인별로 발급받아야 함
- 로그인 시 API 키를 코드 내에서 불러와 자동 인증 처리
- 토큰을 파일에서 읽어와 허깅페이스 로그인에 사용
- 레포지토리 이름 작성 및 모델 업로드 관리
- 사전 학습 모델명, 데이터셋 명, 작업명 등을 포함하여 명명
- 모델과 함꼐 토크나이저 및 사전 학습 정보도 함께 업로드해야 함
trainer.save_model(repo_id)tokenizer.save_pretrained(repo_id)model.save_pretrained(repo_id)
- 업로드 완료 후 푸시(push) 명령어로 데이터 전송
trainer.push_to_hub(repo_id)
업로드한 모델 불러오기 및 활용
# 업로드한 나의 모델 불러와서 사용하기
from transformers import pipeline
checkpoint_mymodel = "be2be2/roberta-base-klue-ynat-classification"
my_model = pipeline(task="text-classification", model=checkpoint_mymodel)Device set to use cuda:0- 허깅페이스에 업로드된 모델 불러오기
- transformers 라이브러리의 pipeline 함수를 사용해 모델 불러오기
- 모델명과 작업명(task="text-classification") 지정해 간단히 사용가능
- transformers 라이브러리의 pipeline 함수를 사용해 모델 불러오기
# 테스트 데이터
test_dataset["title"][:5]['게시판 우리금융 고종황제 묘소 참배로 새해 첫날 맞이',
'보해양조·한창제지에 시황변동 조회공시 요구',
'프로농구 개막 첫날부터 NBA 출신 맞대결…티그 vs 그레이',
'제30대 한국방송작가협회 이사장에 임기홍 작가',
'게시판 서울새활용플라자 어린이 위한 환경학습 키트']result = my_model(test_dataset["title"][:5])
# 'IT과학', '경제', '사회', '생활문화', '세계', '스포츠', '정치'
def make_str_label(batch):
if batch['label'] == "LABEL_0":
batch['label'] = 'IT과학'
elif batch['label'] == "LABEL_1":
batch['label'] = '경제'
elif batch['label'] == "LABEL_2":
batch['label'] = '사회'
elif batch['label'] == "LABEL_3":
batch['label'] = '생활문화'
elif batch['label'] == "LABEL_4":
batch['label'] = '세계'
elif batch['label'] == "LABEL_5":
batch['label'] = '스포츠'
elif batch['label'] == "LABEL_6":
batch['label'] = '정치'
return batch
# 레이블을 실제 값으로 변환
str_result = [make_str_label(title) for title in result]
str_result[{'label': '경제', 'score': 0.5693342685699463},
{'label': '경제', 'score': 0.9462602138519287},
{'label': '스포츠', 'score': 0.9923964142799377},
{'label': '사회', 'score': 0.7058424353599548},
{'label': '사회', 'score': 0.9218515157699585}]- 불러온 모델로 테스트 데이터 예측 수행
- 테스트 데이터셋에서 title 5개 선택해 모델에 입력 후 예측 결과 확인
- 예측 결과는 레이블과 매칭해 사람이 이해하기 쉽게 출력
# 뉴스 페이지에서 뉴스 제목 1개 가져와서 예측해보기
news_title = "SKT, 최신 GPU 클러스터 ‘해인’ 가동…엔비디아 B200 1000장 담았다"
# 예측
my_result = my_model(news_title)
my_result_str = [make_str_label(title) for title in my_result]
my_result_str[{'label': 'IT과학', 'score': 0.9689147472381592}]news_title = [
"세금 폭주하는 트럼프…'美 특허제도 개편시 韓기업 수수료 9.9배↑'"
, "[속보]하루 새 연인·지인 잇단 살해 혐의 50대 남성, 마창대교서 떨어져 숨져"
, '진성준 "아들 부동산 사준 적 없다"…김근식 "쿨하게 사과"'
, "조광래 대표 결국 사의 표명…이례적인 시즌 도중 ‘혁신안’, 대구를 바꿀 수 있나"
, '주영달 총감독 작심 쓴소리, “유리한 상황되면 급해져, 무한 반복 악순환”'
]
# 예측
my_result = my_model(news_title)
my_result_str = [make_str_label(title) for title in my_result]
my_result_str[{'label': '세계', 'score': 0.9829148054122925},
{'label': '사회', 'score': 0.9756367802619934},
{'label': '정치', 'score': 0.7036828994750977},
{'label': '스포츠', 'score': 0.9919844269752502},
{'label': '사회', 'score': 0.7948532104492188}]→ 마지막 뉴스 기사는 사실 '스포츠'임
- 실제 뉴스 제목을 입력해 분류 성능 확인
- 레이블(카테고리)에 해당하는 실제 뉴스 제목을 찾아서 입력해보기
- 모델이 해당 뉴스 제목을 적절히 분류하는지 확인
- 사전 학습된 모델에 추가 학습을 진행 → 뉴스 데이터 분류 정확도 향상
- 최종 모델 저장 시 과적합 여부를 확인하여 일반화된 모델을 유지할 수 있어야 함
핵심 개념:
허깅페이스에 모델 업로드 시 모델, 토크나이저, 사전 학습 정보 업로드 후 push_to_hub()
핵심 단어:
API key(token) / 모델 업로드 / 실제 뉴스 타이틀로 예측
- Point:
- 모델 학습 후 loss, accuracy 평가
- 허깅페이스에 모델 업로드
- API-key(token) 파일로 저장해 사용하기
- os 라이브러리를 이용한 폴더 관리
- 허깅페이스 로그인
- 저장한 api key 이용하는 법
- 허깅페이스에서 내가 업로드한 모델 불러오기
실습: 토큰 분류 - 개체명 인식(NER)
토큰 분류(Token Classification)
- 문장의 개별 토큰에 레이블 할당 (문장의 각 토큰에 레이블을 지정)
- 자연어 처리(NLP)에서 문장 내 개별 토큰에 특정 레이블을 할당하는 작업
- 개체명 인식은 가장 일반적인 토큰분류 작업 중 하나
NER(Named Entity Recognition)
- 문장에서 사람, 위치, 조직, 날짜, 법률, 의료 용어 등 개체 이름을 인식하여 레이블을 부여하는 과정
- 토큰 분류는 문장을 단어 단위로 나누고 각 토큰에 정답 레이블을 할당하는 과정을 지칭
- NER은 토큰 분류 작업 중 가장 일반적인 형태
- 개체 인식을 통해 문장 내 의미 파악과 학습 정확도 향상에 기여
KLUE-NER 데이터셋
- KLUE: Korean Language Understanding Evaluation의 약자
- KLUE-NER: 한국어 개체명 인식 태스크를 위한 NER 데이터셋
- 뉴스 기반 개체명 인식 데이터셋
- KLUE-NER: 한국어 개체명 인식 태스크를 위한 NER 데이터셋
- 훈련 데이터 21,418 문장, 검증 데이터 8,881 문장, 테스트 데이터 9,497 문장으로 구성
- KLUE-NER 데이터셋을 HuggingFace transformers 라이브러리를 퐁해 불러오면 내부적으로 정수 레이블과 그에 대한 태그(BIO+타입)로 구성되어 있음을 확인 가능
BIO란?
- 개체명 인식(NER)에서 각 단어가 어떤 엔티티에 속하는지 구분하는 방식
| 약어 | 의미 |
|---|---|
| B- | Begin: 개체의 시작 단어 |
| I- | Inside: 개체의 내부(연속) 단어 |
| O | Outside: 개체가 아님 |
- BIO 태깅 방법
- B: Begin의 약자로 개체명이 시작되는 부분
- I: Inside의 약자로 개체명의 내부 부분을 의미
- O: Outside의 약자로 개체명이 아닌 부분을 의미
- 예시
- 6월 17일에 → 6월 17일: DT
- 6월: B-DT
- 17일: I-DT
- 에: O
- 해리포터 보러 메가박스 가자
- 해: B-movie
- 리: I-movie
- 포: I-movie
- 터: I-movie
- 보: O
- 러: O
- 메: B-theather
- 가: I-theather
- 박: I-theather
- 스: I-theather
- 가: O
- 자: O
- 6월 17일에 → 6월 17일: DT
KLUE - NER 의 개체 종류
| 약어 | 풀네임 (Full Name) | 의미 설명 |
|---|---|---|
| DT | Date | 날짜 (예: 2023년 8월 5일) |
| LC | Location | 위치 / 장소명 (예: 서울, 강릉) |
| OG | Organization | 조직 / 기관 (예: 삼성전자, 경찰청) |
| PS | Person | 사람 이름 (예: 이순신, 김철수) |
| QT | Quantity | 수량 / 수치 (예: 5개, 100명, 30%) |
| TI | Time | 시간 (예: 오전 9시, 오후 3시) |
| LV | Law (Legal Document) | 법률 / 조항명 (예: 민법 제1조, 정보보호법) |
개체 종류를 보면 해당 데이터는 뉴스 정보에 특화되어 있음을 알 수 있음
→ 의료 용어 데이터 분석을 원할 경우 다른 데이터셋을 사용해야 함!
→ 도메인 또는 목적에 특화되도록 개체명 인식을 정확하게 하는 방법 중 하나는 기존에 공개된 개체명 인식기를 사용하는 것이 아니라, 직접 목적에 맞는 데이터를 준비하여 모델을 만드는 것
✅ 예시
- 문장: 삼성전자는 2021년 3월 15일에 새로운 스마트폰을 출시했다.
| 토큰 | 태그 |
|---|---|
| 삼성전자 | B-OG |
| 는 | O |
| 2021년 | B-DT |
| 3월 | I-DT |
| 15일에 | I-DT |
| 새로운 | O |
| 스마트폰을 | O |
| 출시했다 | O |
| . | O |
데이터셋 불러오기
from datasets import load_dataset
klue_ner = load_dataset("klue", "ner")
# 일부 데이터만 사용
klue_ner["train"] = klue_ner["train"].select(range(250))
klue_ner["validation"] = klue_ner["validation"].select(range(50))
klue_ner["train"]Dataset({
features: ['sentence', 'tokens', 'ner_tags'],
num_rows: 250
})- sentence: 문장
- tokens: 문장을 토큰으로 분할한 리스트
- ner_tags: BIO 기반 정수 레이블
print(klue_ner["train"][0]){
'sentence': '특히 <영동고속도로:LC> <강릉:LC> 방향 <문막휴게소:LC>에서 <만종분기점:LC>까지 <5㎞:QT> 구간에는 승용차 전용 임시 갓길차로제를 운영하기로 했다.'
, 'tokens': ['특', '히', ' ', '영', '동', '고', '속', '도', '로', ' ', '강', '릉', ' ', '방', '향', ' ', '문', '막', '휴', '게', '소', '에', '서', ' ', '만', '종', '분', '기', '점', '까', '지', ' ', '5', '㎞', ' ', '구', '간', '에', '는', ' ', '승', '용', '차', ' ', '전', '용', ' ', '임', '시', ' ', '갓', '길', '차', '로', '제', '를', ' ', '운', '영', '하', '기', '로', ' ', '했', '다', '.']
, 'ner_tags': [12, 12, 12, 2, 3, 3, 3, 3, 3, 12, 2, 3, 12, 12, 12, 12, 2, 3, 3, 3, 3, 12, 12, 12, 2, 3, 3, 3, 3, 12, 12, 12, 8, 9, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12]
}- BIO 태그명 확인
- BIO 태그는 정수형 레이블로 변환되어 있음
- O는 12, B-DT는 2 등 특정 정수값으로 매핑됨
- 레이블과 ID 간 상호 변환을 위한 딕셔너리(label2id, id2label) 생성
- 인코딩: 텍스트 레이블을 정수 ID로 변환하여 모델 입력에 사용
- 디코딩: 모델이 출력한 정수 ID를 다시 텍스트 레이블로 변환하여 결과 해석
- BIO 태그는 정수형 레이블로 변환되어 있음
klue_ner['train'].features['ner_tags'].feature.names['B-DT',
'I-DT',
'B-LC',
'I-LC',
'B-OG',
'I-OG',
'B-PS',
'I-PS',
'B-QT',
'I-QT',
'B-TI',
'I-TI',
'O']- KLUE NER 태그셋 (정수 라벨) 매핑
| 숫자 | BIO 태그 | 설명 |
|---|---|---|
| 0 | B-DT | 날짜 시작 |
| 1 | I-DT | 날짜 내부 |
| 2 | B-LC | 위치 시작 |
| 3 | I-LC | 위치 내부 |
| 4 | B-OG | 조직 시작 |
| 5 | I-OG | 조직 내부 |
| 6 | B-PS | 사람 시작 |
| 7 | I-PS | 사람 내부 |
| 8 | B-QT | 수량 시작 |
| 9 | I-QT | 수량 내부 |
| 10 | B-TI | 시간 시작 |
| 11 | I-TI | 시간 내부 |
| 12 | O | 개체 아님 |
| 13 | B-LV | 법률 시작 |
| 14 | I-LV | 법률 내부 |
# 각 정수형 NER 라벨과 실제 이름 매핑하여 확인
label_list = klue_ner['train'].features['ner_tags'].feature.names
mapping_tags = [
"날짜 시작 (Date)"
, "날짜 내부"
, "장소명 시작 (Location)"
, "장소명 내부"
, "조직명 시작 (Organization)"
, "조직명 내부"
, "인명 시작 (Person)"
, "인명 내부"
, "수량 시작 (Quantity)"
, "수량 내부"
, "시간 시작 (Time)"
, "시간 내부"
, "개체명 아님"
]
for idx, label in enumerate(label_list):
print(f"{idx}: {label} → {mapping_tags[idx]}")0: B-DT → 날짜 시작 (Date)
1: I-DT → 날짜 내부
2: B-LC → 장소명 시작 (Location)
3: I-LC → 장소명 내부
4: B-OG → 조직명 시작 (Organization)
5: I-OG → 조직명 내부
6: B-PS → 인명 시작 (Person)
7: I-PS → 인명 내부
8: B-QT → 수량 시작 (Quantity)
9: I-QT → 수량 내부
10: B-TI → 시간 시작 (Time)
11: I-TI → 시간 내부
12: O → 개체명 아님- 인덱스와 태그 정보를 함께 출력하여 각 토큰이 어떤 개체명 태그를 갖는지 눈으로 확인
KLUE-NER의 BIO 포맷 예시
- 토큰과 라벨번호(ner_tags)
{
'tokens': ['서', '울', '중', '앙', '지', '검', '은', '홍', '길', '동', '을', '기', '소', '했','다', '.']
, 'ner_tags': [2, 3, 4, 5, 5, 5, 12, 6, 7, 7, 12, 12, 12, 12, 12]
}- 해석
| 토큰 | 서 | 울 | 중 | 앙 | 지 | 검 | 은 | 홍 | 길 | 동 | 을 | 기 | 소 | 했 | 다 | . | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 태그 | 2 | 3 | 4 | 5 | 5 | 5 | 12 | 6 | 7 | 7 | 12 | 12 | 12 | 12 | 12 | 12 | |
| 해석 | B-LC | I-LC | B-OG | I-OG | I-OG | I-OG | 객체x | B-PS | I-PS | I-PS | 객체x | 객체x | 객체x | 객체x | 객체x | 객체x |
인코딩/디코딩 매핑을 위한 딕셔너리 작성
- NER 작업을 할 때 필수적으로 수행되어야 함
- HuggingFace transformers 모델과 Trainer에서 사용하는 label2id, id2label 매핑 딕셔너리를 만드는 작업
- label2id
- 모델이 학습을 진행할 때 BIO 레이블로 붙어 있는 토큰을 id로 매핑하여 학습 진행
- id2label
- 사람이 보기 편하게 하기 위해 모델 예측 결과를 BIO 레이블로 매핑하여 변경
- 모델이 예측을 하면 숫자 시퀀스 출력됨 →
[0, 1, 12, 3, 3, 12, 12, ...]
- label2id
# NER Task를 위하여 필수!
label2id = {label: str(idx) for idx, label in enumerate(label_list)}
id2label = {str(idx): label for idx, label in enumerate(label_list)}
print(label2id)
print(id2label){'B-DT': '0', 'I-DT': '1', 'B-LC': '2', 'I-LC': '3', 'B-OG': '4', 'I-OG': '5', 'B-PS': '6', 'I-PS': '7', 'B-QT': '8', 'I-QT': '9', 'B-TI': '10', 'I-TI': '11', 'O': '12'}
{'0': 'B-DT', '1': 'I-DT', '2': 'B-LC', '3': 'I-LC', '4': 'B-OG', '5': 'I-OG', '6': 'B-PS', '7': 'I-PS', '8': 'B-QT', '9': 'I-QT', '10': 'B-TI', '11': 'I-TI', '12': 'O'}전처리 도구 로드
from transformers import AutoTokenizer
checkpoint = "monologg/koelectra-base-v3-discriminator"
# 토크나이저 객체 불러오기
tokenizer = AutoTokenizer.from_pretrained(checkpoint)- monologg님의 koelectra-base-v3-discriminator
- 한국어에 최적화된 KoELECTRA 모델 사용
- 한국어 문장에 대한 정확한 subword 분할을 수행함
subword(서브워드)
- 단어보다 더 작은 단위의 토큰
- 자연어에는 다양한 단어들이 너무 많이 존재함 → 단어 전체가 아니라 단어 조각으로 분해하여 토큰화하는 방식
- 모든 단어를 학습하는 것이 어려워서 단어를 조각으로 나누어 폭넓게 대응하기 위함
- BERT, KoBERT, GPT 등 최신 모델은 대부분 Subword 기반 토크나이징을 진행함 → 학습 효율과 범용성 강화
- 서브워드 토크나이저(Subword Tokenizer)
- 서브워드 분리(Subword segmenation) 작업은 하나의 단어는 더 작은 단위의 의미있는 여러 서브워드들(예: birthplace = birth + place)의 조합으로 구성된 경우가 많기 때문에, 하나의 단어를 여러 서브워드로 분리해서 단어를 인코딩 및 임베딩하겠다는 의도를 가진 전처리 작업
- OOV(Out-Of-Vocabulary) 또는 UNK(Unknown Token)나 희귀 단어, 신조어와 같은 문제를 완화시킬 수 있음
- 서브워드 토크나이저(Subword Tokenizer)
- 사용 이유
- 학습을 하지 않은 신조어, 희귀어 같은 경우 vocab에 없으면 OOV(Out-Of-Vocabulary) 값으로 설정 → 모르는 단어로 인해 문제를 푸는 것이 까다로워지는 상황: OOV 문제
- 사전에 없는 단어나 모르는 단어가 등장해도 서브워드 단위로 분해하여 처리 가능
-
예시
- 문장: 'huggingface is cool'
- 기본 입력:
'huggingface','is','cool' - subword 형식 토큰화:
'hugging','##face','is','cool'##의 의미: 앞 토큰에 붙는 조각 단어임을 의미
- 토크나이저 입력 시
- 입력문장 :
["HuggingFace", "is", "cool"] - 토큰화 :
["Hugging", "##Face", "is", "cool"] - word_ids :
[0, 0, 1, 2]→ 각 서브워드가 원래 단어 내에서 몇 번째 단어인지 인덱스로 관리
- 입력문장 :
-
장점
- 희귀 단어, 신조어, 복합어 대응 가능
- 학습 단어 수를 줄이고 어근, 접미사, 조사 분석이 쉬워짐
학습 파이프라인 구성
- 데이터셋 불러오기, 전처리, 레이블 매핑, 모델 및 토크나이저 준비, 학습 인자(Arguments) 지정, 트레이너 설정
- 전처리 과정에서 BIO 기반 레이블 매핑과 인코딩 작업 필수
핵심 개념:
개체명 인식은 문장에서 특정 개체를 토큰 단위로 식별하는 과정
BIO 태그 체계로 레이블링 필수
서브워드는 단어를 쪼개어 처리 → 희귀 단어와 신조어 대응에 효과적
핵심 단어:
NER, BIO Tag, KLUE-NER dataset, label mapping, KoELECTRA, Subword, tokenizer, word_ids
- Point:
- 개체명 인식(NER)
- KLUE-NER
- 레이블과 ID 간 매핑 작업은 모델 학습 및 결과 해석에 필수적
- 서브워드: 단어보다 작은 단위로 분해
- 서브워드 기반 토크나이저: 최신 자연어 처리 모델에서 필수적으로 사용됨
- 패딩, 특수 토큰은 학습에서 제외됨
AWS Skill Builder
- Welcome to AWS Skill Builder
- 1년 구독권 제공
- 원하는 시간에 원하는 장소에서 원하는 과정을 자유롭게 학습하는 학습 플랫폼
- 자율 학습 과정: 약 600개 이상
- 실습 과정: 125개 이상
- 직업별, 산업별 직무 기반 학습 계획(Learning Plan): 50개 이상
- 게임형 학습 등으로 구성
- 4가지 주요 contents
- 디지털 과정: 자막과 음성으로 구성된 비대면 강의
- Digital Courses
- Digital Classroom w/ trainers ★ (★: requires subcription)
- Learning Plans
- Knowledge Badgt Readiness Paths ♧ (♧: Earn a verifiable badge)
- 게임형 학습
- Cloud Quest(Tournament) ★ : 도시 개발 시나리오 기반 몰입형 롤플레잉 게임. 8개 과정 75개 시나리오. 약 100시간 소요
- Industry Quest ♧ : 특정 산업군(금융, 제조, 헬스케어 등) 사례 중심의 실습 진행
- AWS SimuLearn ★ : 실제 비즈니스 환경 시나리오 기반 문제 해결 학습. 고도화된 AI 어시스턴트 활용. 200개 이상의 주제와 역할 기반 학습 계획 포함
- AWS Card Clash : 카드 게임 형식. 기초 개념 학습에 적합한 게임형 컨텐츠
- AWS Escape Room ★
- AWS Skill Builder Trivia
- AWS Jams & Jam Journeys ★ : AI 어시스턴트와 협력해 실제 비즈니스 미션 해결. 팀 대항 토너먼츠 가능. 다양한 난이도
- 시험 준비 과정
- Exam Prep Readiness Plans
- Practice Questions ★
- Practice Exams ★
- AWS Escape Room ★
- 실습(Builder Labs)
- AWS Builder Labs ★
- Cloud Quest ★
- Industry Quest ♧
- AWS SimuLearn ★
- 디지털 과정: 자막과 음성으로 구성된 비대면 강의
- 상세 설명
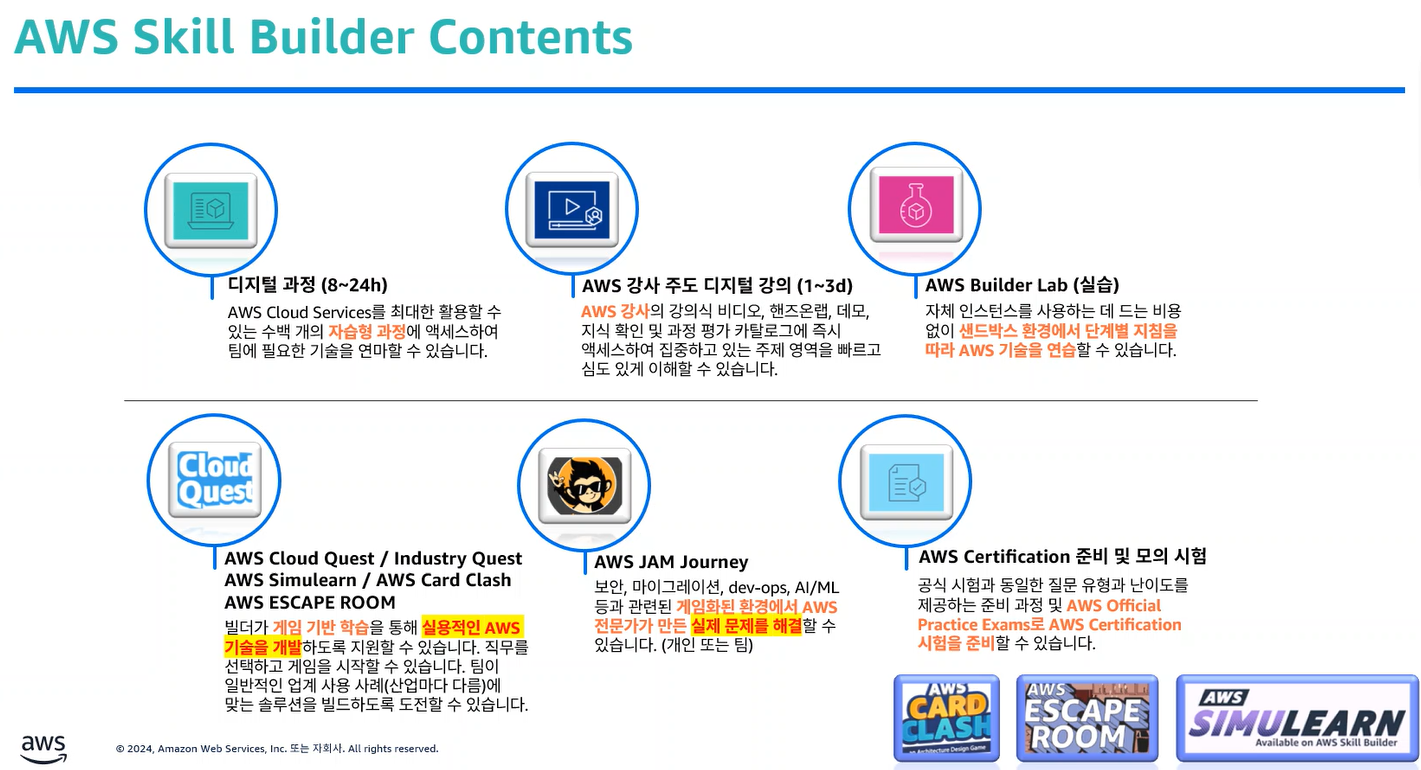
- 디지털 과정: 영상 없이 텍스트 중심으로 진행
- AWS 강사 주도 디지털 강의
- AWS builder Lab
- 게임 기반 학습
- AWS Cloud Quest

- AWS Cloud Quest(Tournament)

- Industy Quest: 비즈니스 사례 기반 클라우드 기술 학습

- AWS Simulearn

- AWS Card Clash: 기초 학습하기 좋음

- AWS ESCAPE ROOM
- AWS Cloud Quest
- AWS Jam : 초반 진입 난이도 있음. 중반 이용 활용 권장
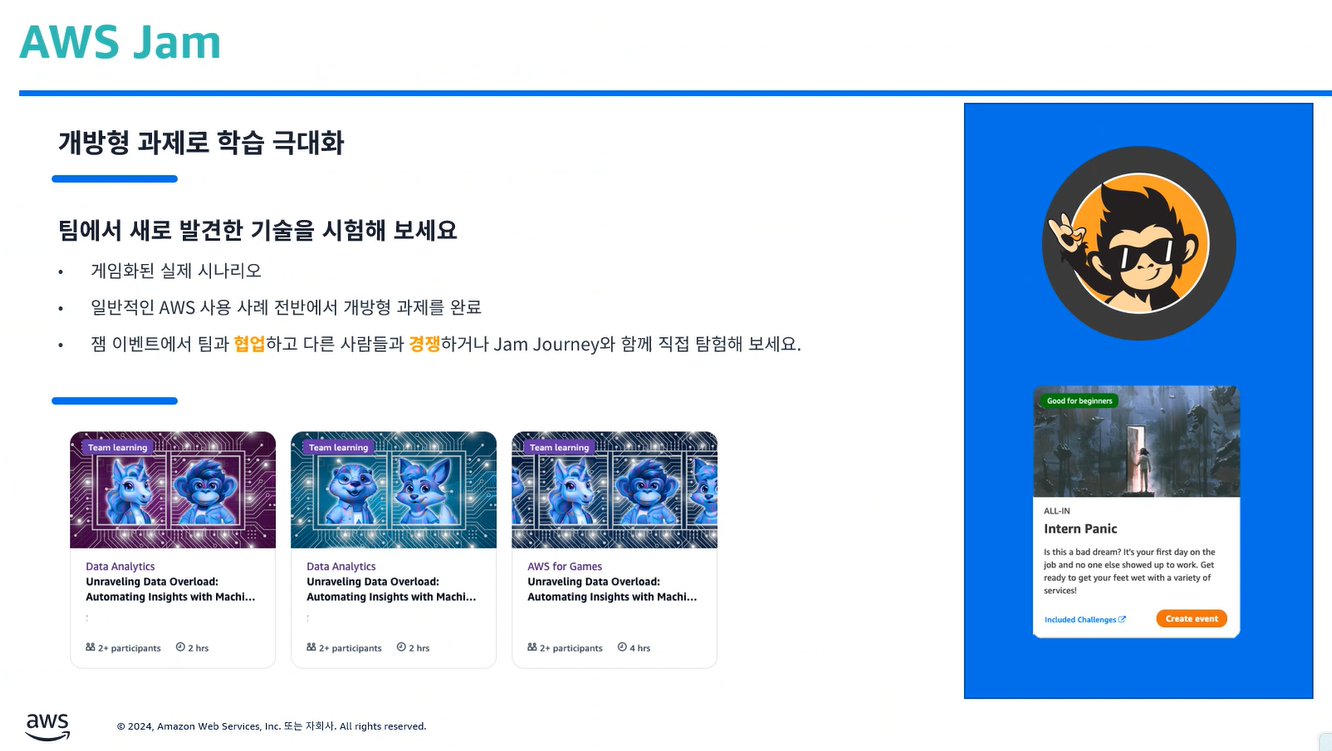
- events

- events
- AWS JAM Journey
- 자격증 준비 과정: AWS Certification 준비 및 모의 시험 ★★★
-
학습 동기 부여를 위한 배지 시스템
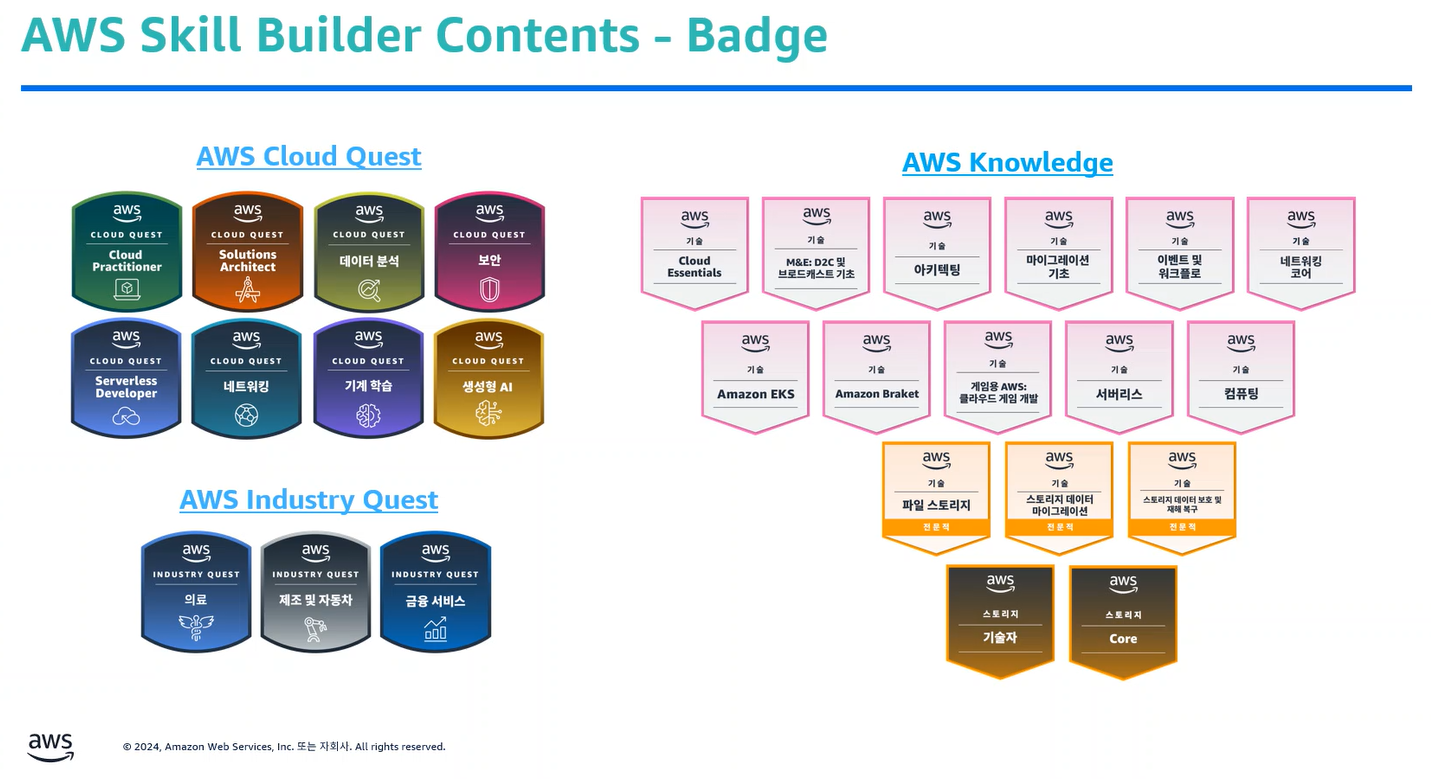
- 디지털 배지 및 자격증 배지 발급으로 학습 동기 부여 및 커리어 관리 지원
- 링크드인 등 커리어 플랫폼에 공유 가능
-
자격증 일람 ★★★
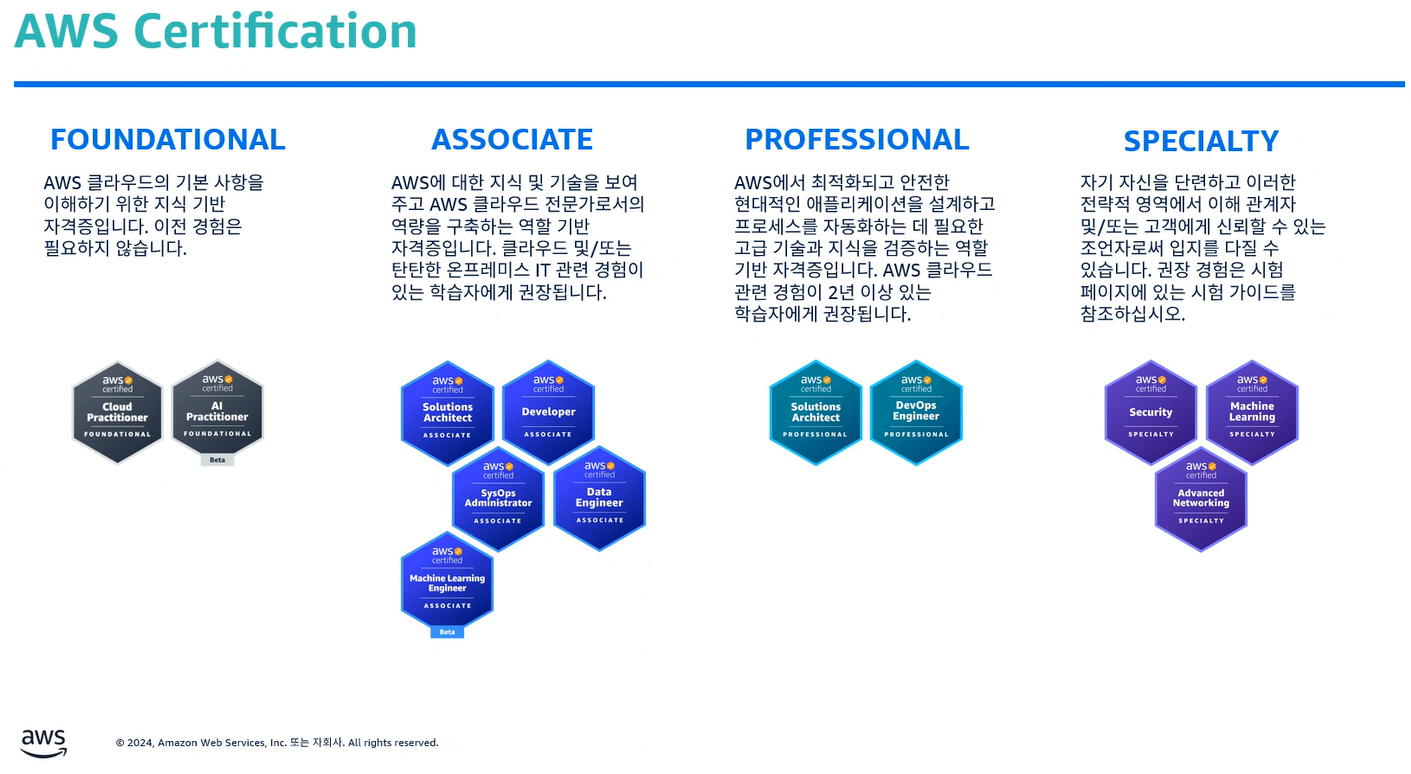
사용 방법 살펴보기
- 로그인 후 첫 화면
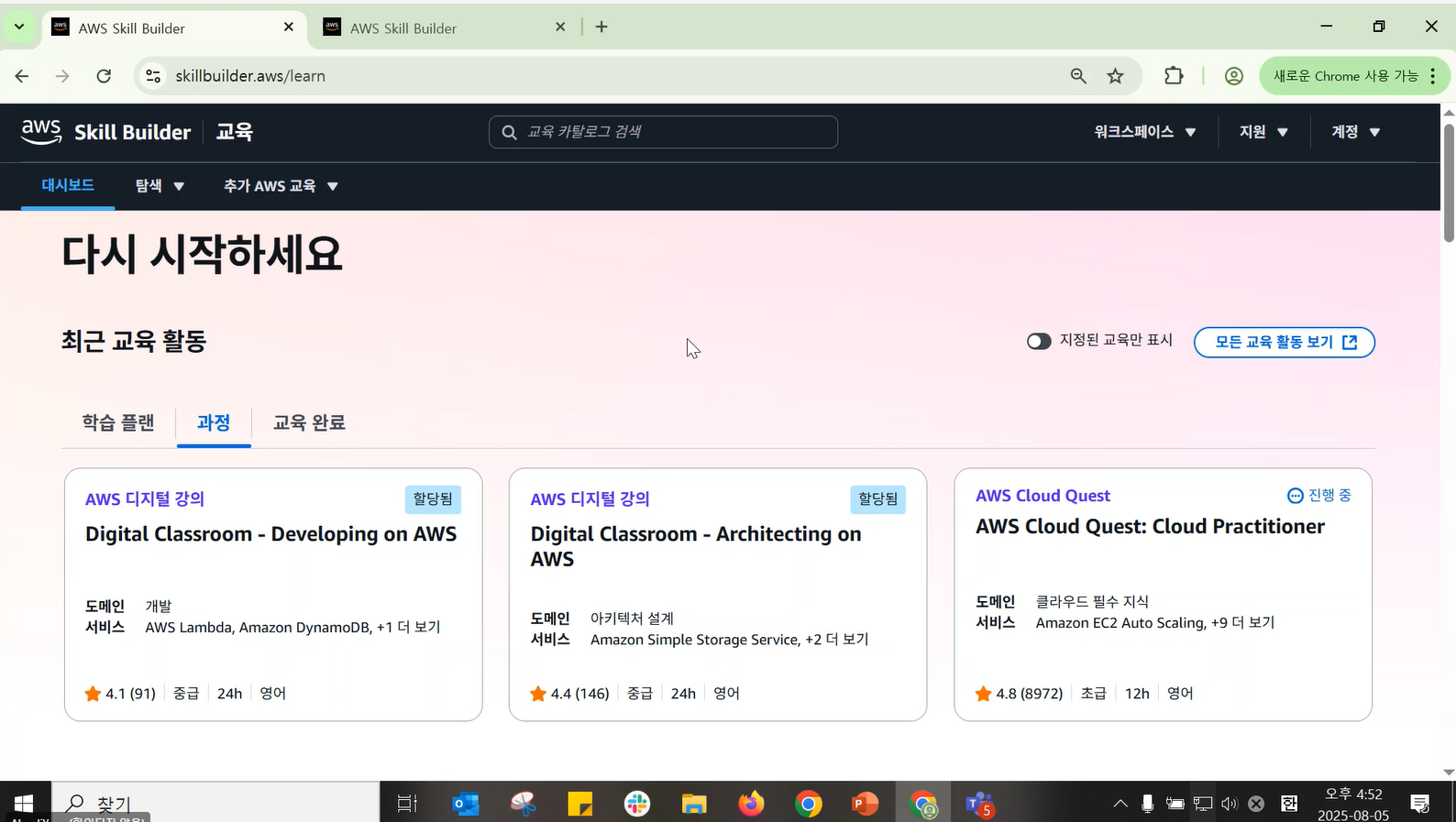
- 가입 시 입력한 관심사에 맞춰 교육 제안
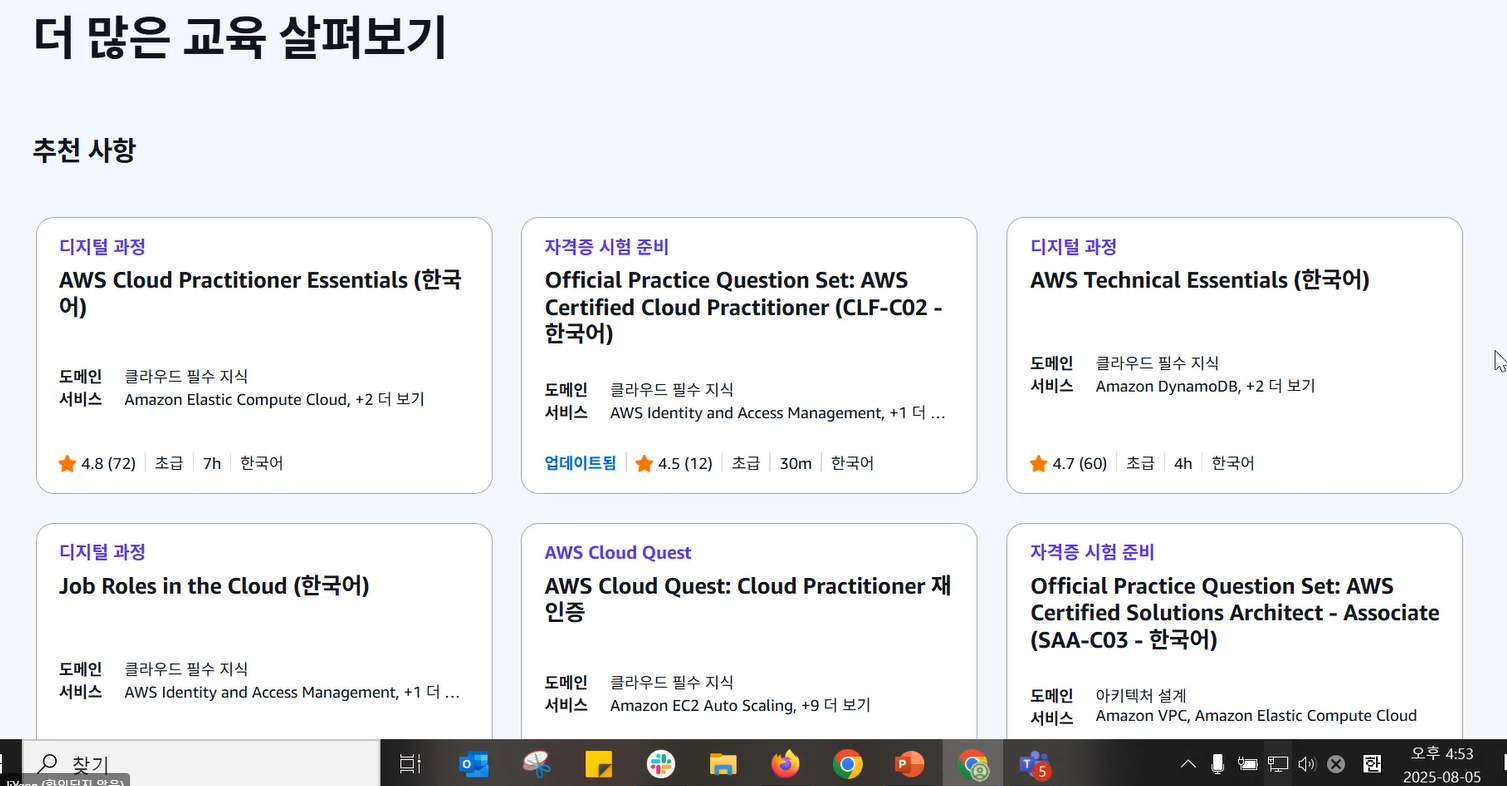
- 관심 있는 분야, 역할군을 고르면 과정 추천해 줌
- 역할군
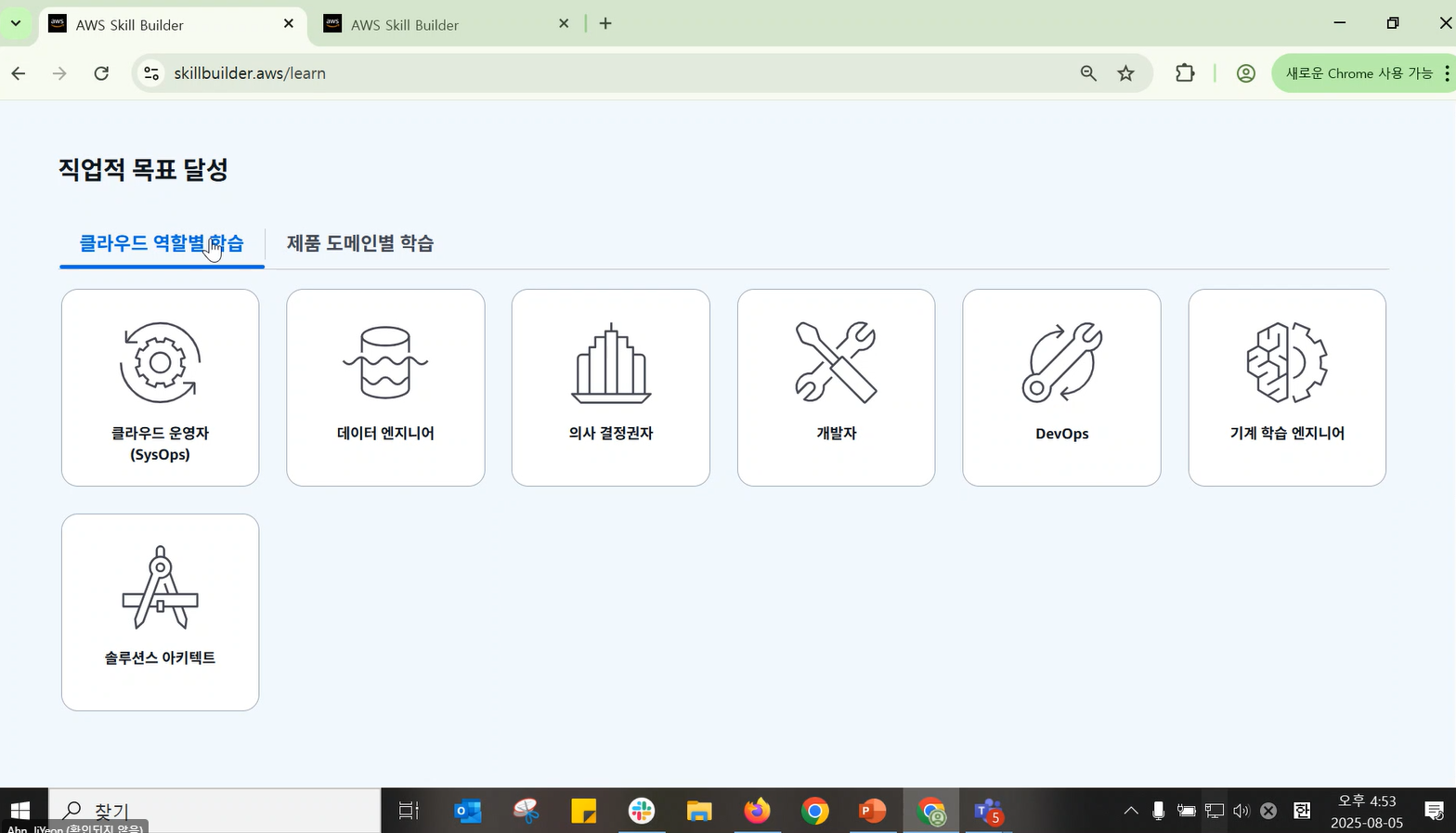
- 도메인
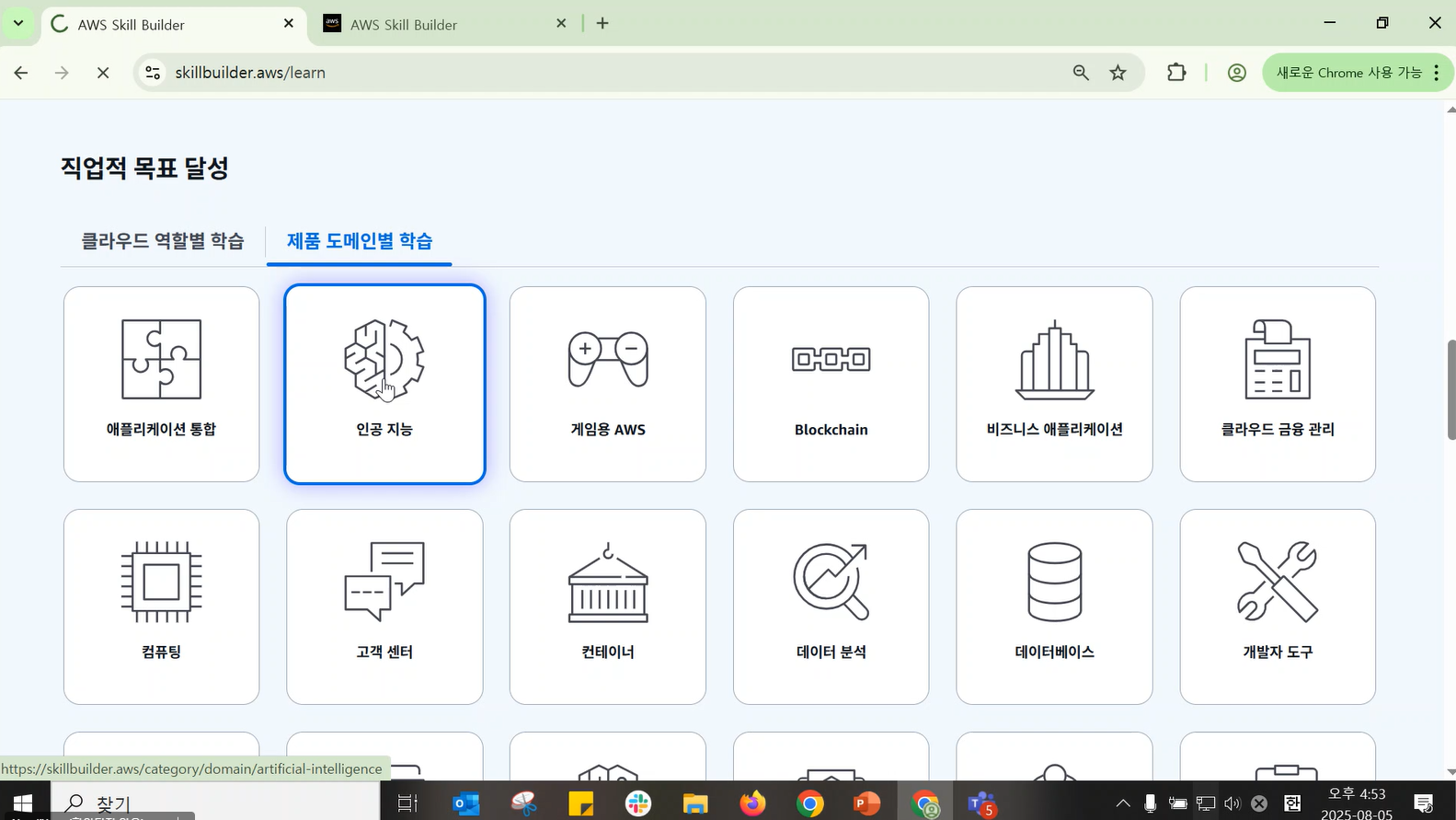
- 인공지능 도메인 예시
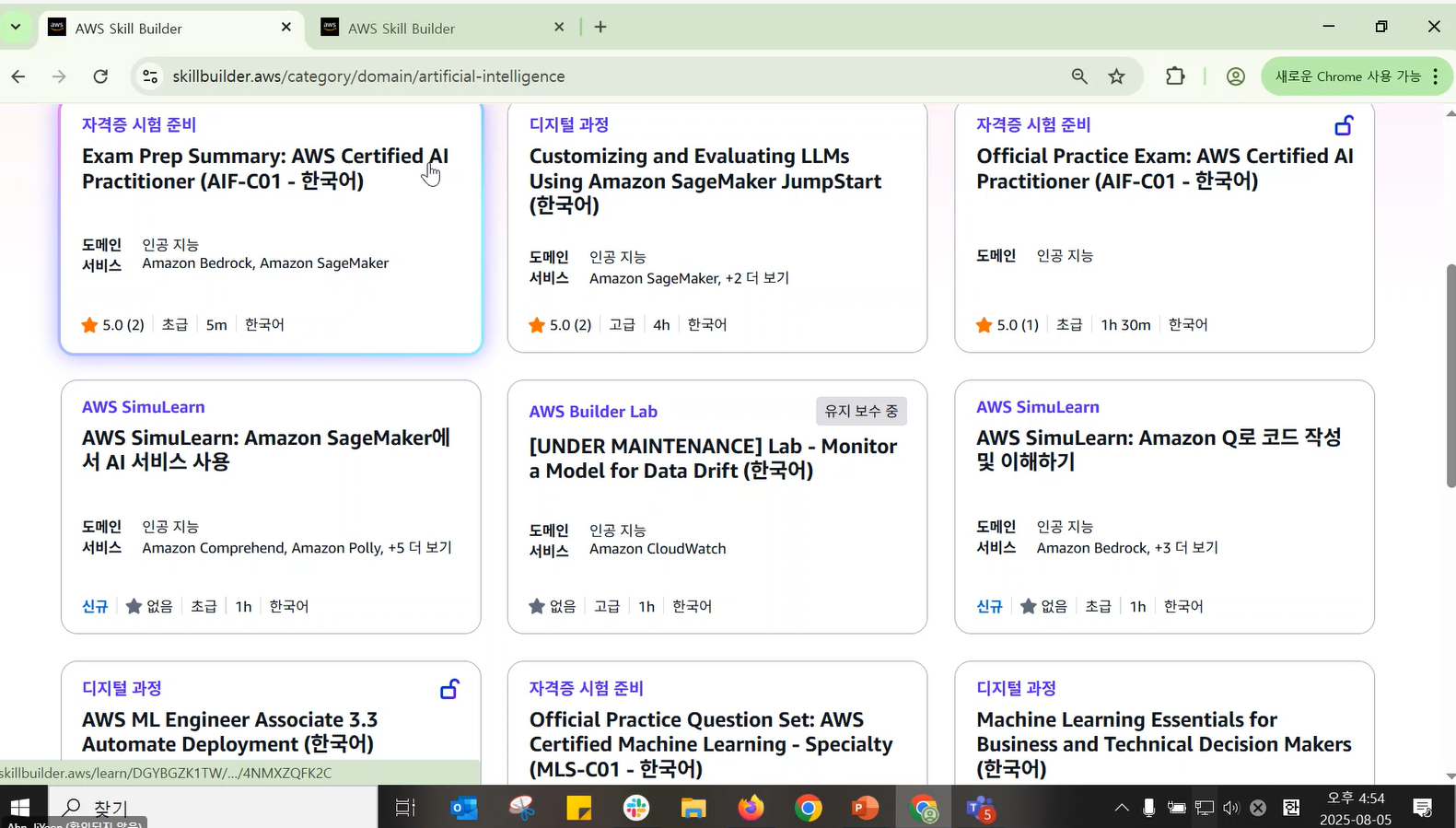
- 인공지능 도메인 예시
- 역할군
- 자격증 기반 과정 추천

- 언어 설정
- 우측 상단 프로필 → 개인 정보 및 기본 설정에서 언어 변경 가능
- 지원 센터 Support Center
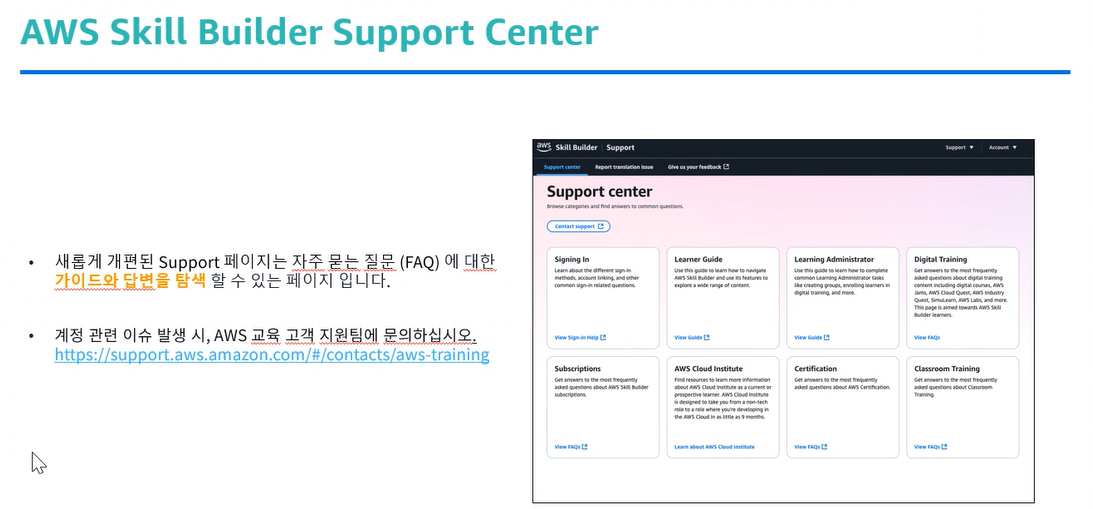
- 우측 상단 지원 버튼에서 FAQ, 티켓 오픈, 번역 문제 신고, 피드백 제공 가능
- 한국어로 이용하다가 번역 문제 발견 시 report하기
- 티켓 오픈 시 24시간 내 담당자 배정 및 이메일 알림 발송
- 한국어로 이용하다가 번역 문제 발견 시 report하기
- 우측 상단 지원 버튼에서 FAQ, 티켓 오픈, 번역 문제 신고, 피드백 제공 가능
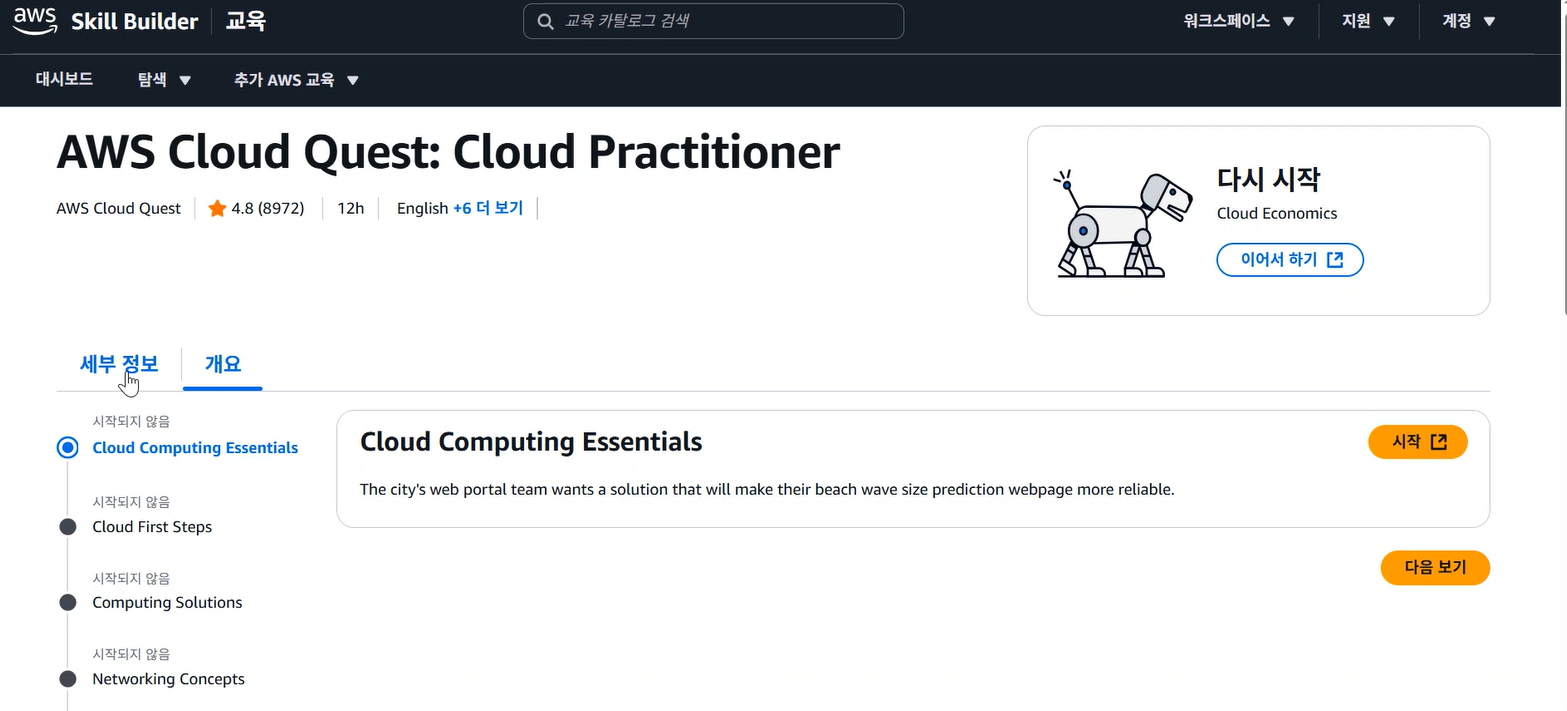
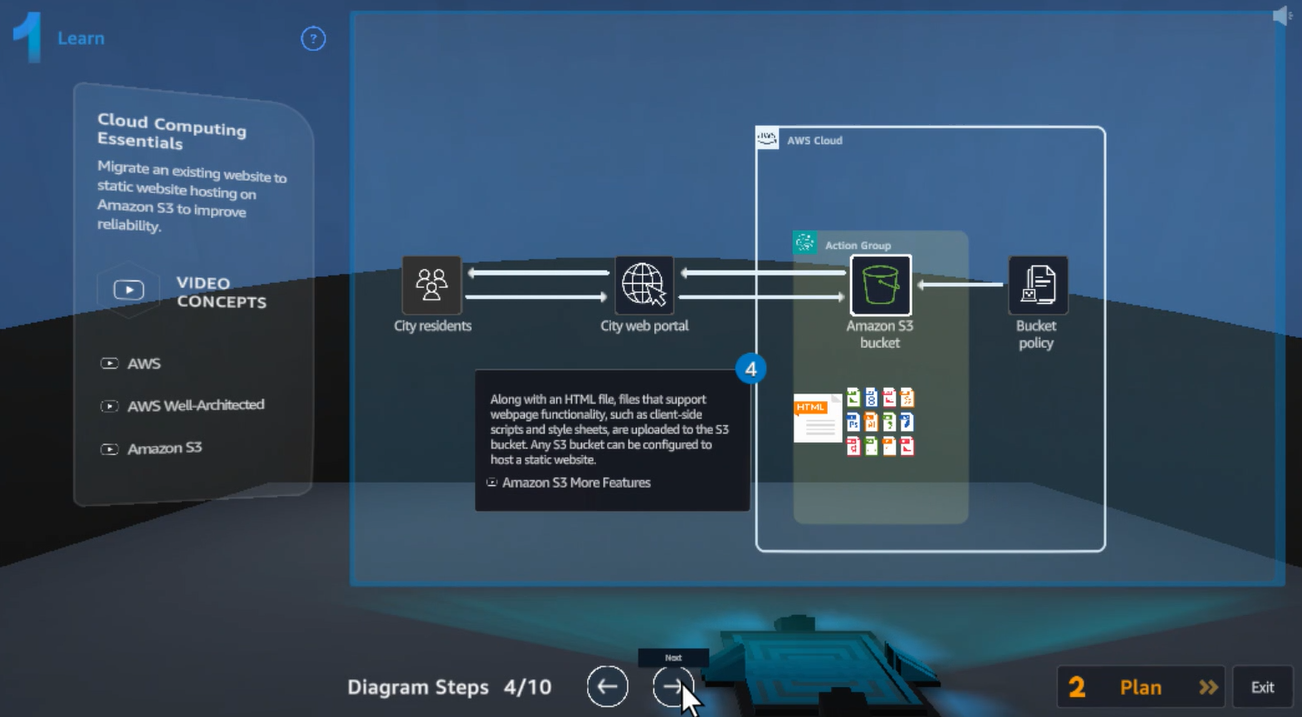
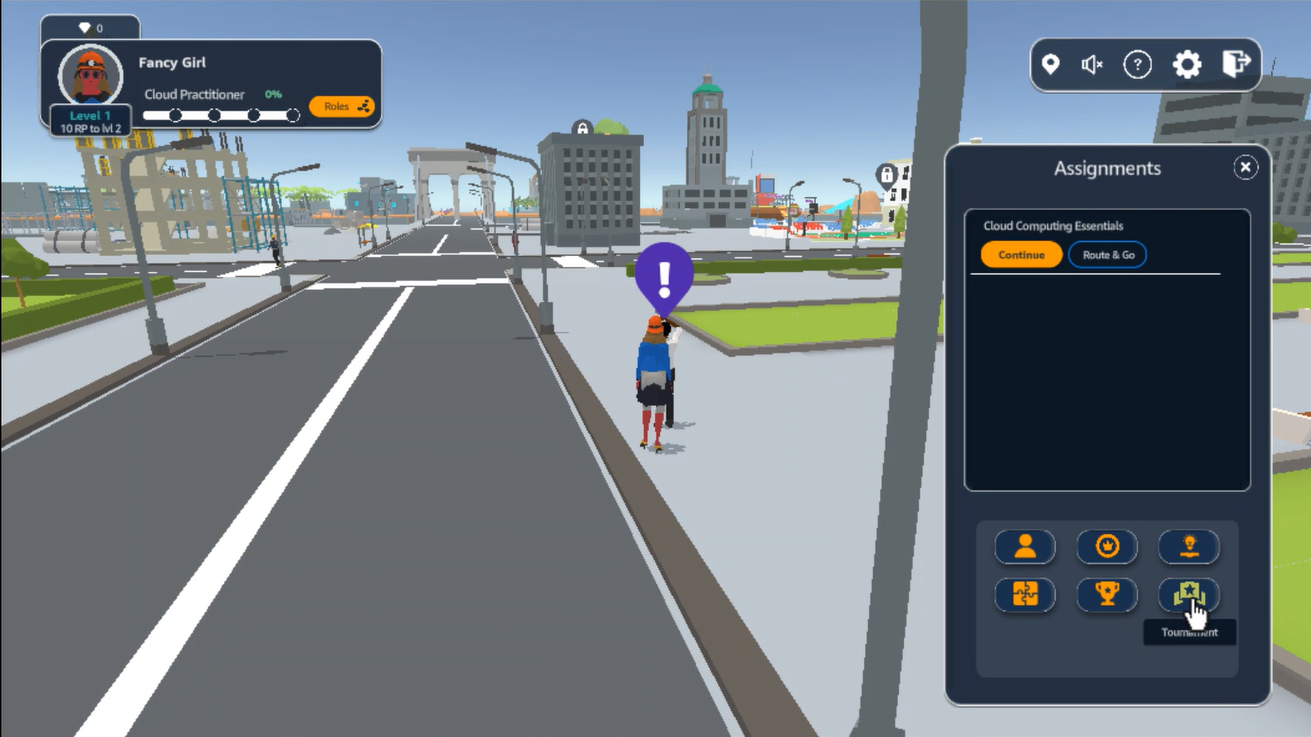
Cloud Quest
- 도시 문제 해결 시나리오 기만 → 문제에 딱 맞는 AWS 서비스를 적용할 수 있는 능력 갖추기
- AWS 서비스 적용 및 실습 가능
- 토너먼츠 형식 → 빠르고 정확한 미션 수행 경쟁 가능
-실제 화면 예시:




전체 과정에서 검색하는 법
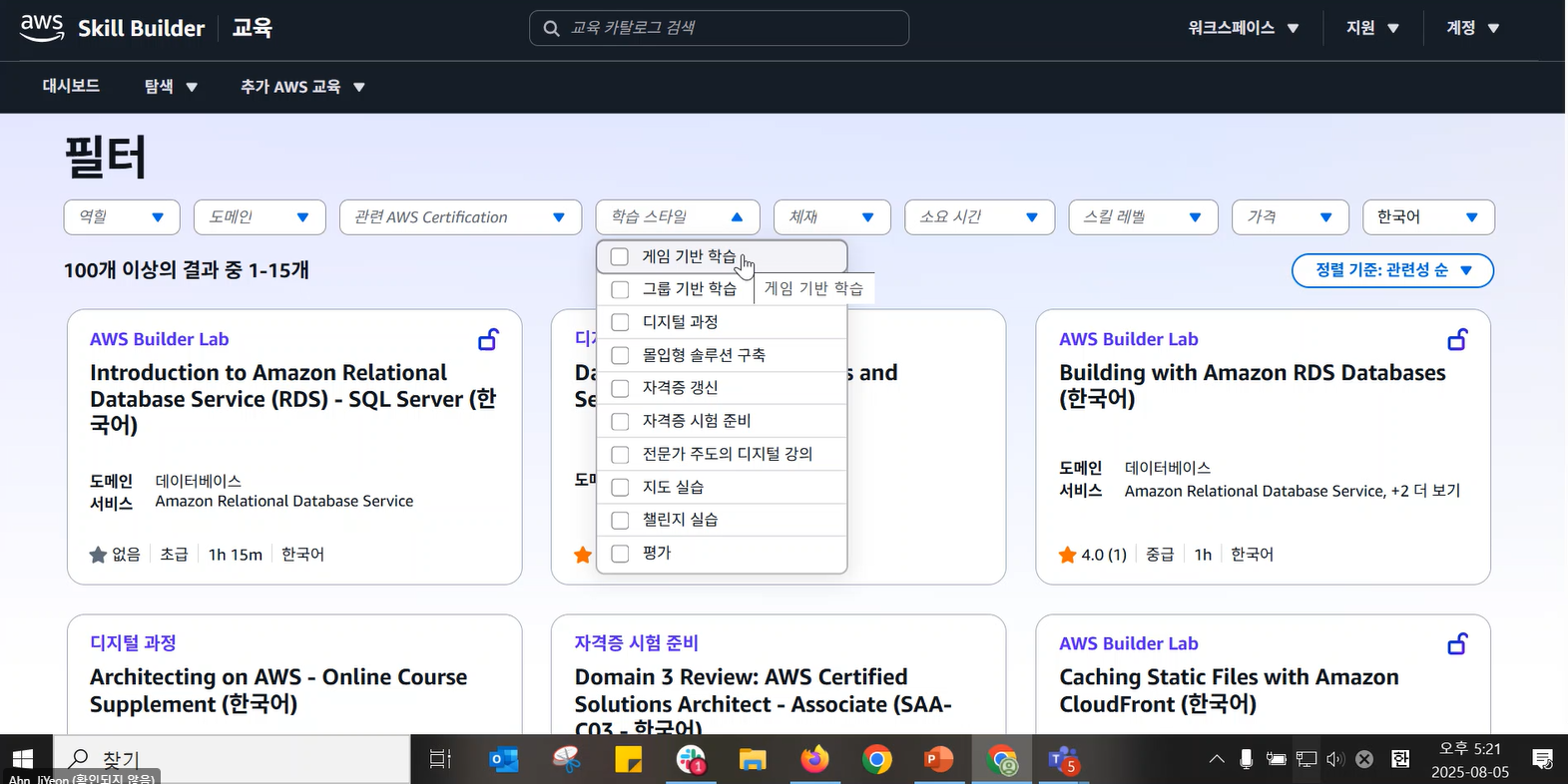
- 아무 표시 없는 과정은 계정만 있으면 누구나 접근 가능
- 자물쇠 표시된 과정은 구독권 구매 후 접근 가능
- 유지보수 표시된 과정은 현재 개편 중 또는 오류 개선 중으로 접근 불가
Skill Builder 잘 활용하기

- 목표 설정의 중요성
- 자격증 취득, 특정 과정 완료 등 구체적 목표 수립하기
- 역할별, 산업군별, 자격증별 경로 중 하나 선택해 집중 학습
- 다양한 학습 컨텐츠 활용하기
- 디지털 강의 외에도 실습, 게임, 모의 시험 등 다양한 학습 방식 병행
하루 돌아보기
👍 잘한 점
- 수업 시간에 대답 열심히 했음
- 모르는 부분 바로바로 질문함
- 쉬는 시간 활용해 수업 내용 복습 진행함
👎 아쉬웠던 점
- 시험을 3개나 신청해버려서(정보처리기사, 리눅스마스터, 빅데이터분석기사) AWS skill builder 학습할 시간을 바로는 빼지 못한다는 점
🔬 개선점
- 일단 이번 주 토요일에 정보처리기사 시험 보고 생각하기
- 균형을 잘 맞춰서 리눅스, 빅데이터, AWS 모두 루틴에 넣고 굴러갈 수 있도록 만들기
