목차
Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
2. GET 방식
3. POST 방식
B. 2교시
1. routes 폴더 사용하기
C. 3교시
1. routes 폴더 사용하기 (cont.)
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
B. 5교시
1. FastAPI: HTML 문서 반환하기
2. 내가 학습시킨 모델을 활용하여 웹으로 챗봇 구현
3. Local LLM 연동하기
C. 6교시
1. Ollama
Ⅲ. CAREER UP
수업 복습 / 추가 공부
Ⅳ. 하루 돌아보기Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
- Express 약속 두 가지
- 파일을 불러오거나 데이터를 가지고 올 때 무조건 절대경로 쓰기:
__dirname키워드- 절대경로 안 쓰면 오류남
__dirname: 현재 작업 중인 파일을 포함하는 폴더까지가 기준- path 모듈 활용하기
- 정적 파일은 무조건 public에 경유하게 세팅 ★
app.use(express.static("public"));
- 파일을 불러오거나 데이터를 가지고 올 때 무조건 절대경로 쓰기:
목적 파일이 상위 폴더에 위치한다면
path.join(__dirname, '../test.html')와 같이 path 모듈을 사용해 경로를 명시const path = require('path'); const filePath = path.join(__dirname, '../test.html'); const filePath = path.resolve(__dirname, '../test.html'); // path 모듈 활용 시 코드 안정성이 높아짐
__dirname + "/../test.html"는 안 되나요? → 직접 문자열 덧셈은 OS별 경로구분자가 달라서 에러가 나는 경우가 많아 추천하지 않음
- GET 방식 데이터 처리
- app.js의 app.listen(3000): 3000번 포트에 누가 들어왔어요! → 경로 뒤에 뭐가 있나요? → 아무것도 없어요 그냥 '/'뿐입니다(=메인 페이지 접근) → 그러면
app.get("/",(req,res)=>{res.sendFile(__dirname+"/public/login.html")});가 처리할게요~ → 사용자에게 절대 경로 상에 있는 파일 보여주기 - login.html:
action="http://localhost:3000/getLogin"으로 데이터 보낼게요 → app.js:app.get("/getLogin",(req,res)=>{});로 받을게요😊- login.htm에서
action="http://localhost:3000/"으로 보내버리면 무한 루프에 빠짐 (req에 정보가 담겨 있긴 하지만 이걸 쓰면 메인 경로 안에서 전부 처리해야 해서 역할 분담이 안 됨)
- login.htm에서
- 클라이언트가 보낸 정보는 req 안에 있음 → Express는 url 모듈 기능도 가지고 있어서
req.query라는 객체로 바로 쓸 수 있음
- app.js의 app.listen(3000): 3000번 포트에 누가 들어왔어요! → 경로 뒤에 뭐가 있나요? → 아무것도 없어요 그냥 '/'뿐입니다(=메인 페이지 접근) → 그러면
- sendFile()은 단순하게 파일만 바꾸는 거라 "URL이 변하지 않음" → 사이트가 새로 고침이 되면 똑같은 URL이 재실행되고 app.get의 로직이 반복됨 (결제 등 사용자의 행위나 상태가 변하는 로직이 들어있을 때 매우 위험) → 해결책: 사이트가 변할 때 URL도 같이 변화하게 만들자! → redirect: 경로 자체를 바꿔버림
TIP: 파일 자체를 redirect로 리턴해버리면 url에 파일명이 나오니까 파일명을 바로 명시하지 말고 다른 경로로 보내기!
2. GET 방식
- redirect는 경로 자체를 바꾼다!
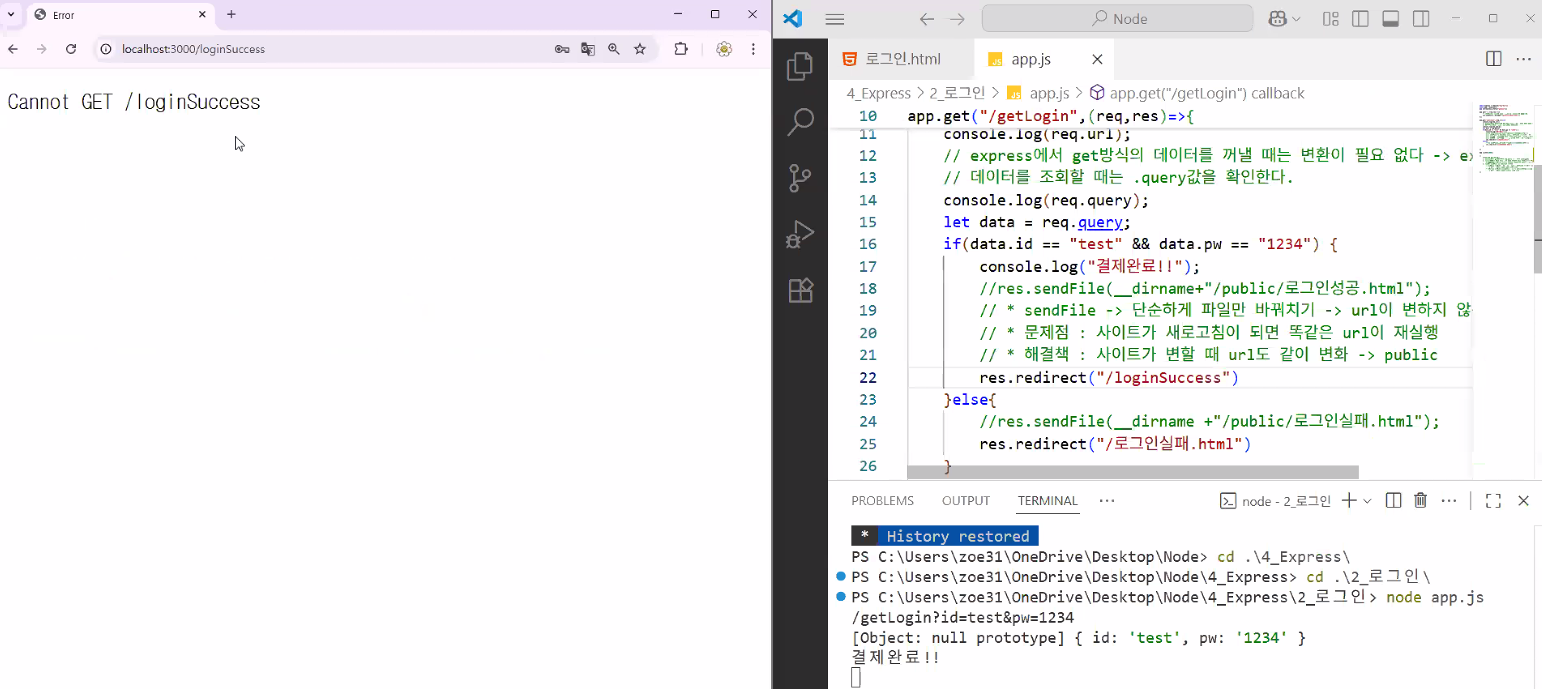
- 요청한 경로를 처리(응답)하는 곳이 없어서 화면이 안 보임 → app.js에 새 응답을 만들자!

- 실행 결과
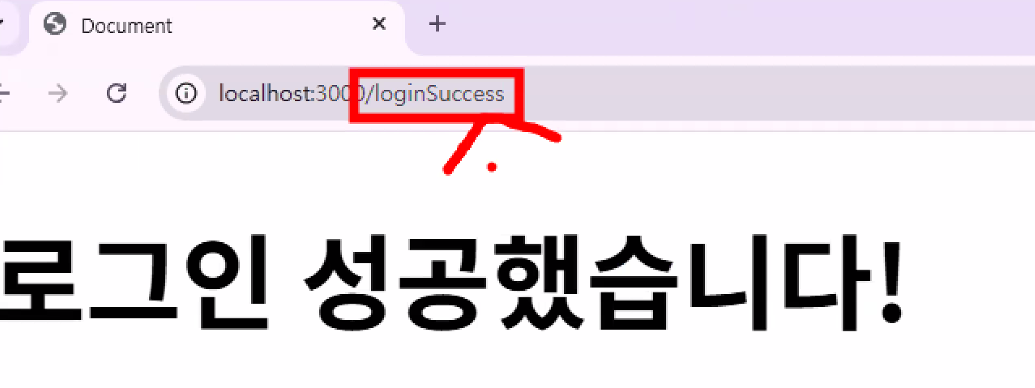
- 실행 결과
- 요청한 경로를 처리(응답)하는 곳이 없어서 화면이 안 보임 → app.js에 새 응답을 만들자!
- redirect와 sendFile은 이렇게 혼합해서 사용해요 (거의 같이 사용되는 개념임)
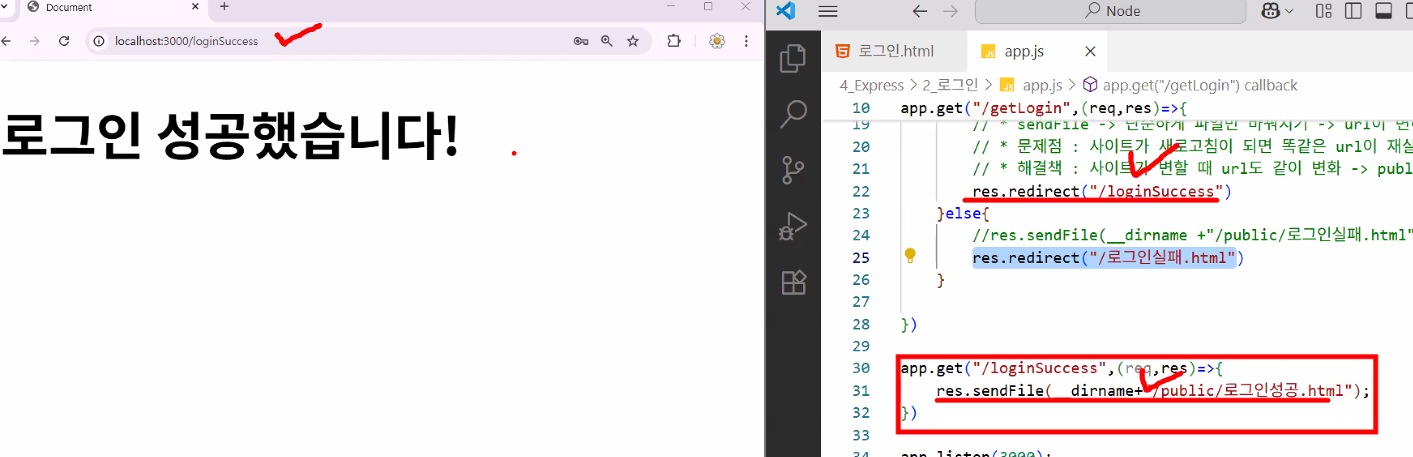
- url에 파일명도 안 보이고 경로도 달라지고 화면도 새로 나옴
- 파일명과 확장자가 드러나지 않아 보안상 좋음
- 경로가 바뀌어서 새로 고침 해도 이전 로직이 반복되지 않음
- url에 파일명도 안 보이고 경로도 달라지고 화면도 새로 나옴
매번 서버 수정하고 껐다 켜는 거 힘드니까 라이브러리 하나 설치해요~
→ 자동으로 서버 업데이트(내용 바뀌면 알아서 껐다 켜줌)
→ 로컬 환경에서만 쓰기!
npm i nodemon -g
-g: 전역설치(모든 프로젝트에서 쓸 수 있게 설치한다는 의미)
3. POST 방식
- buffer 형식 데이터 → String → Object (by querystring)
- 데이터 처리를 위해 모듈 필요:
body-parser- buffer 형태의 데이터를 문자열로 변환하는 모튤
- 모듈 사용할 거면 무조건 app에게 사용등록 해야 함!
app.use(bp.urlencoded({extended:true}));- 'bp를 가지고 url 형태로 바꿀 거니까 허락해주세요'라는 뜻
- 앞서 배웠던 두 가지 기능이 하나로 합쳐져 있음

- Express에서 모듈을 사용할 때 주의점
- app.js에서 모듈을 호출하면 반드시 사용등록이 필요함!
- 다른 파일에서는 필요없음
- app.js에서 모듈을 호출하면 반드시 사용등록이 필요함!
- http 모듈 썼을 때와 비교해보기
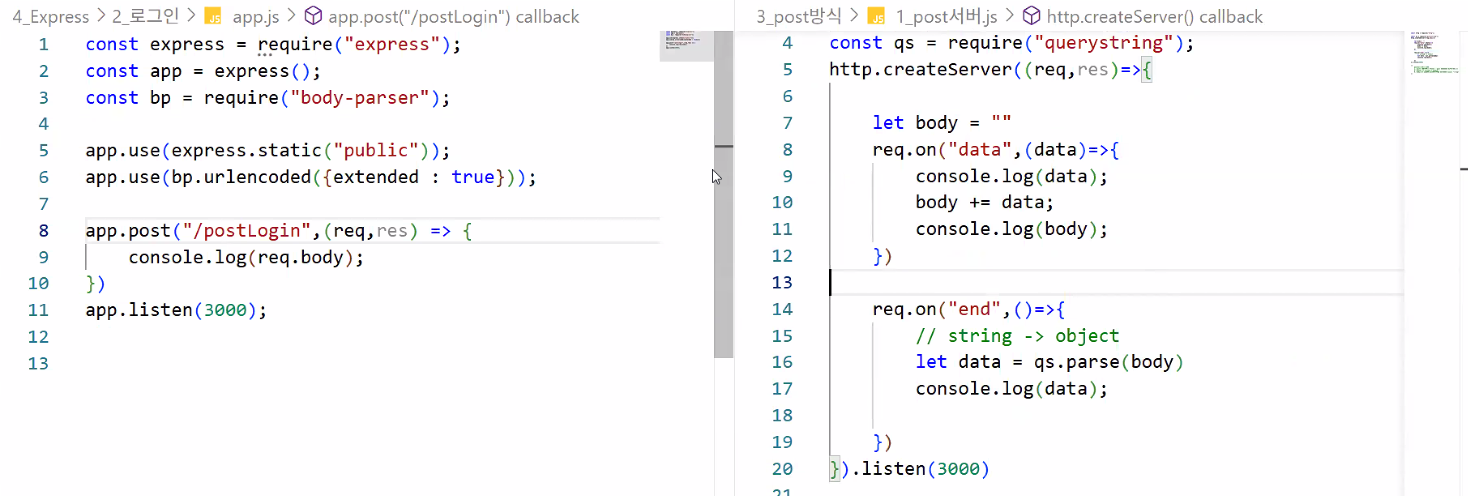
GET, POST 방식의 데이터 처리
- express에서 GET 데이터는 req.query에 객체 형태로 자동 저장된다.
- form 태그에서 값을 보낼 때는 항상 메인이 아닌 특정 경로로(e.g. /getLogin) 보낸다.
- 프론트에서 새로운 경로로 보내면, 백에서는 반드시 받는 로직을 작성(e.g. app.get("/getLogin"))
- (중요) sendFile vs. redirect 차이점
- sendFile: URL이 변하지 않고 파일만 바꿔치기 → ★새로 고침이 되면 그 전의 로직이 다시 실행★ → 메인 페이지 or 파일 바꿔야 할 때만 쓰기
- 값이 변하는 로직이 없는 경우 사용
- redirect: URL의 경로 자체를 변경 → public 폴더의 파일을 직접 찾아간다. → 새로 고침이 돼도 로직이 실행되지 않는다.
- 값이 변하는 로직이 포함된 경우 사용
- sendFile: URL이 변하지 않고 파일만 바꿔치기 → ★새로 고침이 되면 그 전의 로직이 다시 실행★ → 메인 페이지 or 파일 바꿔야 할 때만 쓰기
- Express에서 POST 데이터는 req.body에 자동 저장된다.
- 단, 먼저 body-parser 모듈을 호출해서 app에 등록해야 한다.
B. 2교시
Express 등장 이유를 잊지말자!
업무의 과중화 → 업무를 분배해서 관리하자!
지금까지 작성한 내용은 사실 업무의 분배가 잘 되지 않은 상태임 → 업무를 쪼개자!
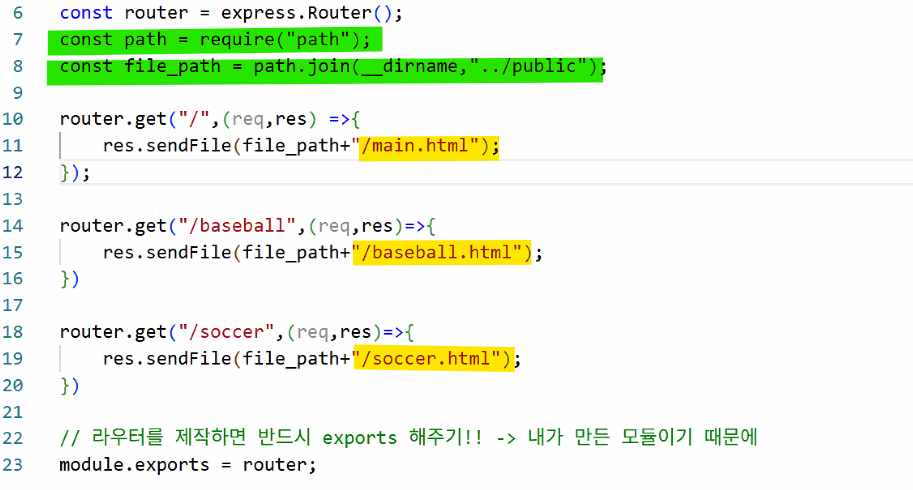
1. routes 폴더 사용하기
- main.html 만들기
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>스포츠 페이지입니다!</h1>
<a href="/baseball">야구 페이지</a>
<a href="/soccer">축구 페이지</a>
</body>
</html>- a 태그로 인해 변경된 경로(페이지 이동)에 대한 서버 쪽의 대응 필요
- 경로 변경 주체가 다름!
- a 태그: Frontend에서 경로 변경
- redirect: Server에서 경로 변경
- 경로 변경 주체가 다름!
Router 설정
- 라우터: 사용자가 보낸 요청에 관련된 업무를 담당하는 파일
- 주의점: 절대경로의 위치가 변경 → 파일을 호출할 때 문제가 발생
- 라우터를 사용할 때 경로가 여러 그룹이라면 라우터를 쪼개는 게 효율적
- 왜 sendFile() 쓰나요?
- redirect 보낼 곳이 없음
- frontend에서 이미 a 태그를 이용해서 url 경로를 바꿔놓은 상태라 해당 경로에서 페이지 리턴만 해 주면 됨
- 라우터 씨를 고용하자: routes/mainRouter.js
- app.js에 있던 업무 인수인계하기
- app: Express 안에 있는 모든 기능 사용 가능
- app이 get/post하던 건 사실 router 업무(express.Router())였음 → 이관해주기

- app이 get/post하던 건 사실 router 업무(express.Router())였음 → 이관해주기
const express = require("express");
const router = express.Router();
router.get("/",(req,res)=>{
});
router.get("/baseball",(req,res)=>{
});
router.get("/soccer",(req,res)=>{
});
module.exports = router;- 라우터를 제작하면 반드시 exports 해주기! → 내가 만든 모듈이기 때문
- 라우터 씨는 내가 만든 모듈임 → 파일만 만든 상태로는 연결이 안 됨 → app.js로 가지고 가서 쓰려면 mainRouter.js에서는
module.exports = router;로 꼭 exports 하고 app.js에서는 반드시 호출해야 함!
- 라우터 씨는 내가 만든 모듈임 → 파일만 만든 상태로는 연결이 안 됨 → app.js로 가지고 가서 쓰려면 mainRouter.js에서는
C. 3교시
1. routes 폴더 사용하기 (cont.)
핵심: 서버는 페이지의 흐름을 파악하는 게 가장 중요 → 어떤 파일이 실행되는지를 생각하자
const mainRouter = require("./routes/mainRouter");
app.use("/",mainRouter);- 등록 포인트
- 내가 제작한 모듈을 호출할 때는 반드시 경로를 확인하자!
- "경로" 기억하기: 현재 위치(app.js)에서 mainRouter.js로 가는 경로를 정확하게 알려줘야 함
- js 파일이 js 파일을 호출하는 경우 확장자명 생략 가능
- app.use("출력 출발지 조건",실행 내용);
app.use("/",mainRouter);: 내가 호출하고자 하는 경로의 맨 앞이 그냥 일반적인 슬래시(메인)인 경우 mainRouter에게 가라는 뜻
- 내가 제작한 모듈을 호출할 때는 반드시 경로를 확인하자!
- mainRouter.js 경로 설정
- routes 폴더에서 public으로 가려면 폴더를 한 번 나와서 이동해야 함 → 모듈의 힘을 빌리자:
path
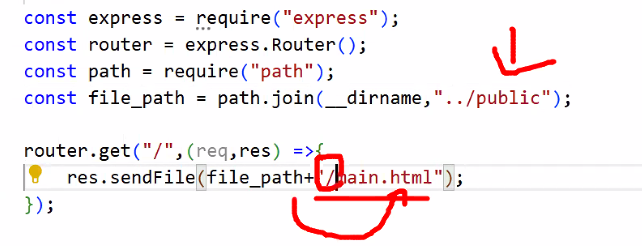
- 경로 수정 모듈 적용 결과
- file_path는 폴더까지만 쓰고 연결시킬 때 파일명 앞에 들어간다("/")는 표현을 넣는 게 가장 직관성이 좋음
- routes 폴더에서 public으로 가려면 폴더를 한 번 나와서 이동해야 함 → 모듈의 힘을 빌리자:
router는 경로를 담당하는 모듈 path와 항상 함께 다닌다!
2. 전체 프로세스 복습
- 메인 사이트 방문 → app.js: 3000번 포트를 통해 누가 왔어요! → app.js: 사용자가 들어온 경로에 특이한 구분자 있나요? (포트 번호 뒤 내용을 묻는 것) → 없어요! 그냥 '/'만 있네요~ → mainRouter 호출(
app.use("/",mainRouter);)- mainRouter가 다시 질문
- 경로 뒤에 내용 있나요? → 아뇨 → main.html 리턴
- mainRouter가 다시 질문
- 사용자가 메인 사이트에서 야구 페이지 a 태그를 누름 → "app.js": 3000번 포트를 통해 누가 왔어요! → app.js: 특별한 구분자 있나요? → 아뇨 → mainRouter 호출(
app.use("/",mainRouter);)- mainRouter가 다시 질문
- 경로 뒤에 내용 있나요? → baseball이 있어요 → baseball.html 리턴
- mainRouter가 다시 질문
- 주의: 사용자의 행위에 '가장 먼저 응답'하는 건 항상 app.js!
- 3000번 포트로 오기 때문 (3000번 포트에 대해 듣고 있는 건 app.js임)
- app.js가 물어보는 특별한 구분자는 'app.use()'에 있는 경로 이야기임
이벤트 방식이라 ①, ② 한꺼번에 다 기억하고 있다가 상황에 맞게 이동함
app.use("/",mainRouter); // ① app.use("/esport",subRouter); // ②→
http://localhost:3000/esport로 접근하면 바로 ②로 이동(①은 고려되지 않음)
Ⅱ. 오후 수업
A. 4교시
1. 지난 시간 복습
- FastAPI
- API를 만들기 위한 파이썬 웹 프레임워크
- API: 프로그램과 프로그램이 서로 대화할 수 있도록 도와주는 통로
- API를 만들기 위한 파이썬 웹 프레임워크
- uvicorn: FastAPI를 실제로 구동시키는 엔진
- FastAPI를 실행하려면 웹 서버가 필요한데, 그 역할을 하는 게 Uvicorn
- LangServe
- LangChain을 API를 통하여 배포하기 위한 라이브러리
- FastAPI와 통합이 되어 있어 사용하기 편리
- LangChain 서버 라우터 설정
- 방법 1: 모델만 정의하고 프롬프트와 체인은 클라이언트에서 재정의하여 사용
- 단순 모델을 요청해서 사용
- 방법 2: 서버에서 prompt_1과 LLM으로 이어지는 체인 연결하고 클라이언트에서 입력값만 받기
- 서버에 고정된 프롬프트를 사용하고 클라이언트는 입력값만 정의
- 클라이언트가 topic(입력값)만 작성하면 서버에 고정된 프롬프트가 적용
- 방법 1: 모델만 정의하고 프롬프트와 체인은 클라이언트에서 재정의하여 사용
- 비동기 방식
- await - ainvoke/astream/abatch
answer = await chain_2.ainvoke({"region":"싱가포르", "target":"맛집"})
추가: 데코레이터(@기호)
함수 정의 위에 위치하여, 해당 함수를 인자로 받아 데코레이션(기능 추가, 변형)하는 파이썬 문법 요소
예를 들어 @app.get("/")는 FastAPI 프레임워크에게 해당 함수가 특정 경로의 GET HTTP 요청을 처리한다고 알려주는 역할을 함
B. 5교시
1. FastAPI: HTML 문서 반환하기
1. 코드 형태로 반환
- html 코드가 단순할 때
from fastapi import FastAPI
import nest_asyncio
import uvicorn
from fastapi.responses import HTMLResponse
app = FastAPI()
nest_asyncio.apply()
@app.get("/", response_class=HTMLResponse)
async def index():
return """
<html>
<body>
<h1>Hello World !! </h1>
</body>
</html>
"""
if __name__ == '__main__':
uvicorn.run(app, host="127.0.0.1", port=5000)2. 파일 형태로 반환
- html 코드가 복잡할 때
import os
if not os.path.isdir("./templates"):
os.makedirs("./templates")
print("폴더 생성 완료")
else:
print("이미 폴더가 존재합니다!")폴더 생성 완료%%writefile ./templates/hello2.html
<html>
<head>
<meta charset="UTF-8">
<title>Hello World Page</title>
</head>
<body>
<h1>Hello World !!</h1>
<!-- 간단한 테이블 -->
<h2>교육생 명단</h2>
<table border="1" cellpadding="5" cellspacing="0">
<tr>
<th>번호</th>
<th>이름</th>
<th>이메일</th>
</tr>
<tr>
<td>1</td>
<td>홍길동</td>
<td>hong@example.com</td>
</tr>
<tr>
<td>2</td>
<td>김철수</td>
<td>kim@example.com</td>
</tr>
</table>
<br>
<!-- 입력값 받는 form -->
<h2>교육생 등록</h2>
<form action="/submit" method="post">
이름: <input type="text" name="name"><br><br>
이메일: <input type="email" name="email"><br><br>
<input type="submit" value="등록">
</form>
</body>
</html>- HTML 생성: 아래 코드로도 가능
# Python 내에서 HTML 작성 후 파일로 내보내기
html_text = """
<html>
<head>
<meta charset="UTF-8">
<title>Hello World Page</title>
</head>
<body>
<h1>Hello World !!</h1>
<h2>교육생 명단</h2>
<table border="1" cellpadding="5" cellspacing="0">
<tr>
<th>번호</th>
<th>이름</th>
<th>이메일</th>
</tr>
<tr>
<td>1</td>
<td>홍길동</td>
<td>hong@example.com</td>
</tr>
<tr>
<td>2</td>
<td>김철수</td>
<td>kim@example.com</td>
</tr>
</table>
<br>
<h2>교육생 등록</h2>
<form action="/submit" method="post">
이름: <input type="text" name="name"><br><br>
이메일: <input type="email" name="email"><br><br>
<input type="submit" value="등록">
</form>
</body>
</html>
"""
with open('./templates/hello2.html', 'w', encoding='utf-8') as f:
f.write(html_text)- 서버: 위에서 만든 HTML 불러와서 클라이언트에게 보내주기
from fastapi import FastAPI
import nest_asyncio
import uvicorn
from fastapi.responses import FileResponse
app = FastAPI()
nest_asyncio.apply()
@app.get("/", response_class=FileResponse)
async def index():
return "./templates/hello2.html"
if __name__ == '__main__':
uvicorn.run(app, host="127.0.0.1", port=5000)2. 내가 학습시킨 모델을 활용하여 웹으로 챗봇 구현
3. Local LLM 연동하기
- 로컬 컴퓨터에 LLM을 설치하여 사용함으로써 비용 및 보안 문제 해결
- 로컬 컴퓨터에 LLM보다 큰 메모리를 갖는 GPU 필요
Ollama
- 로컬 환경에서 LLM을 실행할 수 있도록 설계된 오픈소스
- 포함된 모델 종류가 다양
- Ollama, LMStudio, Llamma 등
- 설치
- 설치를 완료한 후 챗 화면이 자동 실행
챗 화면에서 사용하고자 하는 모델을 선택하여 메시지를 전송 → 모델 다운로드 시작~ - 모델 다운로드가 완료되면 해당 모델을 사용하여 챗봇 동작 수행 가능
- 일부 모델에서 지원되는 Turbo를 선택하면 더 빠른 응답모드를 지원 (로그인 필요)
- 설치를 완료한 후 챗 화면이 자동 실행
- 한국어 지원 모델이 gemma뿐이라고 함
- gemma3:1b 선택하기

- 학습 파라미터 10억 개
- ':' 뒤의 숫자가 클수록 학습 파라미터가 많다는 뜻 (e.g. gemma3:12b → 120억 개 파라미터. 7.6GB) → 추론 능력이 더 좋음
- gpt처럼 사용 가능

- gemma3:1b 선택하기
Local 모델인 Gemma3를 LangChain과 연동하기
from langchain_community.llms import Ollama
# 실행할 모델명 설정
llm = Ollama(
model="gemma3:1b"
)
while True:
q=input("입력: ")
if q=="exit":
break
print(llm.invoke(q))- 설치된 모델 정확한 모델명 확인하기
- cmd에서 ollama list 입력

- cmd에서 ollama list 입력
C. 6교시
1. Ollama
1. 프롬프트 템플릿 사용하여 체인 연결
chain = prompt | llm | StrOutParser()
from langchain_community.llms import Ollama
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 실행할 모델명 설정
llm = Ollama(model="gemma3:1b")
# 프롬프트 형식 정의
template = """
당신은 질문-답변을 수행하는 정확하고 친절한 AI 어시스턴트입니다.
당신의 역할은 주어진 질문(question)에 답하는 것입니다.
한글로 답변해 주세요. 단, 기술적인 용어나 고유 이름은 번역하지 않고 그대로 사용해주세요.
질문: {question}
답:
"""
prompt = PromptTemplate.from_template(template)
chain = prompt | llm | StrOutputParser()
res = chain.invoke({"question":"팬케이크 만드는 법 알려줘"})
print(res)팬케이크를 만드는 방법은 다음과 같습니다.
1. 계란, 밀가루, 우유, 베이킹파우더, 설탕, 바닐라 익스트랙 등 재료를 준비합니다.
2. 팬에 기름을 두르고 따뜻하게 데웁니다.
3. 계란물을 붓고 덩어리가 지지 않도록 잘 섞습니다.
4. 팬에 얇게 반죽을 붓고 2~3분 정도 익힙니다.
5. 마지막에 바닐라 익스트랙을 뿌려주면 완성입니다.
맛있게 드세요!2. 프롬프트 템플릿 (메시지 시스템을 활용하여 역할, 출력값 형태를 지정)
from langchain_community.llms import Ollama
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = Ollama(model="gemma3:1b")
prompt = ChatPromptTemplate.from_messages([
('system', "너는 여행 전문가이고 여행지의 중요한 부분에 대해 전문적으로 대답할 수 있어"),
('human', '{area}에서 유명한 {topic} {num}가지를 추천해 줘~'),
('ai',""" 아래의 형식처럼 답변을 작성해주세요
======================
타이틀
======================
- 응답 1
- 설명
- 응답 2
- 설명
- 응답 3
- 설명
""")
])
chain = prompt | llm | StrOutputParser()
res = chain.invoke({
"area":"일본"
, "topic": "관광지"
, "num": 3
})
print(res)======================
**타이틀:** 일본의 대표적인 관광지 3곳
**======================**
**- 응답 1**
* **일본 교토:** 일본의 역사와 문화를 대표하는 도시입니다. 금빛 나라이시의 웅장한 사찰, 아름다운 정원, 고풍스러운 전통 건축물 등 다양한 볼거리가 있습니다. 특히, 기요미즈데라, 료안지, 금각사 등은 꼭 방문해야 할 명소입니다.
* **일본 오사카:** 활기 넘치는 분위기와 맛있는 음식으로 유명한 도시입니다. 오사카성, 도톤보리, 우메다 공원 등 다양한 볼거리가 있으며, 특히 오사카바비와 타코야키는 꼭 맛봐야 할 음식입니다.
* **일본 하코네:** 아름다운 자연과 몽환적인 분위기로 유명한 곳입니다. 100개의 작은 산 꼭대기 위에 자리 잡은 하코네는, 아름다운 풍경을 감상하며 걷거나 자전거를 타는 것을 즐길 수 있습니다.
**======================**
**- 응답 2**
* **일본 다카야마:** 일본의 전통적인 분위기를 느낄 수 있는 도시입니다. 아름다운 거리, 전통 가옥, 숲길 등 다양한 볼거리가 있으며, 특히 다카야마 시장은 활기 넘치는 분위기를 느낄 수 있습니다.
* **일본 후쿠오카:** 아름다운 해변과 맛있는 음식으로 유명한 도시입니다. 후쿠오카성, 겐로쿠 시장, 텐진 거리 등 다양한 볼거리가 있으며, 특히 텐진 거리는 젊은이들의 거리로 알려져 있습니다.
* **일본 나라이시:** 웅장한 댐과 아름다운 자연이 어우러진 곳입니다. 나라이시 댐은 일본의 대표적인 댐 중 하나로, 댐의 아름다운 경관을 감상할 수 있습니다.
**======================**
**- 응답 3**
* **일본 아즈하기:** 아름다운 자연과 조용한 분위기로 유명한 곳입니다. 아즈하기 호수는, 신선한 물과 아름다운 풍경을 감상할 수 있는 곳입니다. 또한, 아즈하기 지역에는 다양한 식물과 동물이 서식하고 있어, 자연을 즐기기에 좋은 곳입니다.
* **일본 홋카카:** 웅장한 산과 아름다운 풍경으로 유명한 곳입니다. 홋카카 주변에는 다양한 관광 명소가 있어, 자연과 문화를 동시에 즐길 수 있습니다.
* **일본 고치:** 일본의 전통적인 문화와 아름다운 자연을 동시에 느낄 수 있는 곳입니다. 고치는, 훌륭한 음식과 풍경을 자랑하며, 일본의 전통 문화를 체험할 수 있는 좋은 장소입니다.
이 외에도 일본에는 수많은 아름다운 관광지가 있습니다. 여행 계획에 맞춰 다양한 관광지를 방문해 보시길 바랍니다.3. 메모리 기능이 부여된 챗봇 구현하기
from langchain_community.llms import Ollama
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# 실행할 모델명 설정
llm = Ollama(
model="gemma3:1b"
)
# 프롬프트를 한국어용으로 정의
prompt = PromptTemplate(
input_variables=["history", "input"],
template=(
"다음은 사람과 AI의 한국어 대화입니다.\n"
"대화 기록:\n{history}\n\n"
"사람: {input}\nAI:"
),
)
# 메모리 객체 생성
memory = ConversationBufferMemory()
# 2. 체인 구성: 대화형 모델과 메모리를 결합
conversation = ConversationChain(
llm=llm
, memory=memory
, prompt=prompt
, verbose=True
)
# 챗봇 실행
while True:
q = input("입력 :")
if q == "exit":
print("채팅 종료")
break
# 모델 응답
res = conversation.predict(input=q)
# 아니면 conversation.invoke(q)["response"] 로 접근해야 함
print(res)
print() # 개행용입력 : 한국 전통 음식 5가지 알려줘
네, 한국 전통 음식 5가지 알려드릴게요!
1. **비빔밥:** 나라별로 다양한 비빔밥이 있지만, 밥 위에 다양한 채소와 고기, 계란 등을 올려 먹는 음식입니다.
2. **갈비찜:** 부드러운 갈비를 푹 익혀 리소스에 재워 먹는 음식으로, 달콤 짭짤한 맛이 특징입니다.
3. **불고기:** 얇게 썬 소고기를 간장, 참기름, 마늘 등으로 양념하여 구워 먹는 음식입니다.
4. **떡볶이:** 쫄깃한 떡을 고추장, 참치 등을 넣어 매콤하게 볶은 음식입니다.
5. **김치:** 한국의 대표적인 발효 음식으로, 배추, 무 등을 갈아 찌거나 삶아 김치통에 담아 먹습니다.
어떠신가요? 혹시 다른 질문이 있으신가요?
입력 : 일본 전통 음식 5가지 알려줘
네, 일본 전통 음식 5가지 알려드릴게요!
1. **스시:** 밥 위에 생선을 말아 올린 음식으로, 얇게 썬 생선과 밥, 그리고 다양한 튀김, 장아찌 등을 곁들여 먹습니다.
2. **라멘:** 면을 끓인 바탕에, 육수를 부어 지은 음식으로, 다양한 재료를 넣어 취향에 맞게 즐겨 먹습니다.
3. **우동:** 면을 끓인 바탕에, 육수를 부어 만든 면 요리로, 밥과 함께 먹거나 튀김과 함께 먹기도 합니다.
4. **타코야끼:** 노층으로 지은 따뜻한 라면처럼 보이는 일본식 튀김 요리로, 튀김옷을 입혀 맛을 더했습니다.
5. **오코노미야키:** 얇게 썬 고기와 재료를 튀김옷을 입혀 볶아 먹는 음식으로, 다양한 재료를 넣어 맛을 냅니다.
어떠신가요? 혹시 다른 질문이 있으시나요?
입력 : 앞에서 알려준 한국 전통 음식 5가지 순서까지 정확하게 다시 말해줄래?
네, 알겠습니다. 한국 전통 음식 5가지 순서를 다시 말씀드리겠습니다.
1. **비빔밥**
2. **갈비찜**
3. **불고기**
4. **떡볶이**
5. **김치**
이게 맞나요?
입력 : 프랑스 전통 음식 5가지 알려줘
네, 알겠습니다. 프랑스 전통 음식 5가지 알려드릴게요!
1. **크루아튼:** 프랑스어로 '마른 빵'이라고도 하며, 얇고 부드러운 빵으로, 꿀, 버터, 견과류 등을 곁들여 먹습니다.
2. **마카롱:** 솜털처럼 부드러운 젤리 형태의 디저트로, 다양한 맛과 색으로 출시됩니다.
3. **마카롱 시럽:** 마카롱을 굽는 과정에서 사용되는 시럽으로, 마카롱의 풍미를 더합니다.
4. **마카롱 퐁듀:** 마카롱에 곁들이는 부드러운 소금물로, 마카롱의 맛을 더욱 돋보이게 합니다.
5. **마카롱 퐁듀 시럽:** 마카롱 퐁듀를 끓일 때 사용하는 시럽으로, 마카롱의 맛을 더욱 돋보이게 합니다.
어떠신가요? 혹시 다른 질문이 있으시나요?
입력 : 이탈리아 전통 음식 5가지 알려줘
네, 알겠습니다. 이탈리아 전통 음식 5가지 알려드릴게요!
1. **파스타:** 이탈리아어로 '파스타'는 '면'을 의미합니다. 다양한 토핑과 소스와 함께 먹는 면 요리입니다.
2. **피자:** 이탈리아어로 '피자'는 '면'을 의미합니다. 얇은 면을 빵처럼 구워 만든 음식으로, 다양한 토핑을 올려 먹습니다.
3. **라자냐:** 얇은 파스타 면을 굽고 안에 치즈, 토마토 소스, 고기 등을 넣어 만듭니다. 겉은 바삭하고 속은 촉촉한 맛입니다.
4. **젤라또:** 이탈리아어로 '젤라또'는 'Ice Cream'를 의미합니다. 다양한 맛과 색깔로 출시되는 아이스크림입니다.
5. **트러플 파스타:** 이탈리아어로 '트러플'은 '마늘'을 의미합니다. 트러플 오일이나 트러플을 넣어 만든 파스타 요리입니다.
어떠신가요? 혹시 다른 질문이 있으신가요?
입력 : 오스트리아 전통 음식 5가지 알려줘
네, 알겠습니다. 오스트리아 전통 음식 5가지 알려드릴게요!
1. **슈니첼 (Schnitzel):** 얇게 썬 고기를 심게로 기름에 튀긴 음식으로, 빵가루를 입혀 먹습니다.
2. **하트 (Hert):** 닭고기를 얇게 썰어 튀긴 음식으로, 겉은 바삭하고 속은 촉촉한 것이 특징입니다.
3. **프라츠 (Sausage):** 오스트리아식 고기 소자으로, 꼬투리에 넣어 튀거나 구워 먹습니다.
4. **브로이클 (Brezel):** 빵에 젖은 빵을 굽는 음식으로, 겉은 바삭하고 속은 촉촉합니다.
5. **베이컨 젤라또 (Bacon Gelato):** 베이컨을 젤라또에 넣어 만든 디저트로, 독특한 풍미를 자랑합니다.
어떠신가요? 혹시 다른 질문이 있으신가요?
입력 : 노르웨이 전통 음식 5가지 알려줘
네, 알겠습니다. 노르웨이 전통 음식 5가지 알려드릴게요!
1. **스모크 salmon (훈제 연어):** 연어를 훈제 방식으로 조리하여 맛과 향을 더한 음식입니다.
2. **해산물 샐러드 (해산물 샐러드):** 신선한 해산물과 채소를 함께 넣어 만든 샐러드입니다.
3. **브뤼헐 롤 (브뤼헐 롤):** 얇게 펴서 만든 빵 안에 새우, 훈제 연어, 샐러드 등을 넣어 만든 롤입니다.
4. **요크셔 샐러드 (요크셔 샐러드):** 샐러드에 훈제 연어, 크림치즈, 고기 등을 넣어 만든 요크셔 주의의 대표적인 샐러드입니다.
5. **스모트라트 꼬치 (스모트라트 꼬치):** 훈제 연어, 꼬 stick, 샐러드, 빵 등을 꼬치에 꽂아 먹는 음식입니다.
어떠신가요? 혹시 다른 질문이 있으신가요?
입력 : 앞에서 알려준 일본 전통 음식 5가지 순서까지 정확하게 다시 말해줄래?
네, 알겠습니다. 일본 전통 음식 5가지 순서를 다시 말씀드리겠습니다.
1. **스시**
2. **라멘**
3. **우동**
4. **덮밥**
5. **가츠동**
어떠신가요? 혹시 다른 질문이 있으시나요?
입력 : exit
대화 종료- 주의 사항
- ConversationChain 은 내부적으로 LLMChain 을 감싸는데, 기본 Prompt 템플릿이 영어 중심("The following is a friendly conversation between a human and an AI...")으로 설정되어 있음
- 한국어 지시어가 포함된 prompt 를 직접 지정하지 않으면 모델에 아무리 한국어를 던져도, 프롬프트가 영어니까 답이 영어로 나오게 됨!
- ConversationChain 은 직접 parser를 받지 않음 & 결과를 dict 로 반환함
- 문자열만 반환하고 싶으면 간단하게
conversation.predict(input=q)쓰기 - 아니면
conversation.invoke(q)["response"]로 접근
- 문자열만 반환하고 싶으면 간단하게
- 질문을 “두 번째 음식이 무엇인가요?” → “앞서 알려준 목록에서 2번 음식명을 알려주세요” 형태로 구체화하기
- '앞서 알려준 한국 전통 음식 목록에서 두 번째로 나온 음식이 무엇이었나요?'로 질문해보기

- '앞서 알려준 한국 전통 음식 목록에서 두 번째로 나온 음식이 무엇이었나요?'로 질문해보기
- ConversationBufferWindowMemory는 메시지 객체 리스트를 요구해 문자열 타입 불일치가 생길 수 있음
- 메시지 리스트(MessagesPlaceholder) 기반 프롬프트 대신 문자열 변수를 써서 타입 충돌 최소화
- ConversationChain 은 내부적으로 LLMChain 을 감싸는데, 기본 Prompt 템플릿이 영어 중심("The following is a friendly conversation between a human and an AI...")으로 설정되어 있음
질문 자체는 전혀 잘못되지 않았습니다. 실제로 체인이 출력하는 프롬프트와 대화 기록을 보면 “두 번째 음식”을 맞추기에 충분한 정보가 있습니다.
그런데도 모델이 “비빔밥”이 아니라 “불고기”가 아닌지 혼동하는 이유는 다음과 같습니다.
원인 분석
1. LLM의 인식 및 위치 정보 한계
대부분의 LLM은 목록(리스트) 안에서 “첫 번째”, “두 번째” 같은 위치 정보를 정확히 추론하지 못하는 경우가 많습니다. 특히,
- 목록이 여러 줄로 나뉘거나,
- 답변 사이에 설명이 포함되거나,
- 사용된 포맷이 일관적이지 않으면
모델이 “두 번째”의 기준을 헷갈릴 수 있습니다.2. 대화 기록 포맷 문제
대화 기록이 영어 “Human”, “AI”로 저장될 때와 “사람”, “AI”로 나올 때 혼동이 생길 수 있고,
- 프롬프트 템플릿을 한국어로 재정의했을 때도 내부적으로 영어 기반 히스토리 포맷이 영향을 줄 수 있습니다.
- 일부 모델(특히 Gemma, Llama3 기본 버전)은 아직 한국어 포맷에서 정보 추출·위치 인식이 약한 편입니다.
3. 사용한 모델의 언어 특성
기본 Gemma3:1b 모델 등은 한국어에 최적화되어 있지 않아서,
- 위치 기반 추론, 목록 인식이 다소 부정확할 수 있습니다.
- 구체적으로 “비빔밥”과 “불고기” 중 두 번째가 어느 것인지 정확히 파악하지 못하는 사례가 빈번합니다.
실전 해결책
A. 프롬프트 개선
질문을 명확하게 해주면 더 나은 추론(답변) 확률이 올라갑니다.
예시로
“앞서 알려준 한국 전통 음식 목록에서 두 번째로 나온 음식이 무엇이었나요?”
같이 목록의 위치정보를 강조해서 질문해 보세요.B. 모델 교체/튜닝
- 한국어에 특화된 LLM(예: Bllossom-Korean, DeepSeek-R1 8B/70B 등)을 Ollama에서 설정하면 위치 추론력이 크게 향상됩니다.
- 특히 최근 공개된 Bllossom-Korean(3B/8B/70B) 모델은 “목록안 위치 연상”에 강점이 있어 추천합니다.
C. 목록 포맷 일관성
프롬프트에서 목록의 각 행이 "숫자. 음식명: 설명" 형식으로 일관되게 나오도록 조정하면 혼동이 줄어듭니다.
결론
- 질문은 잘못되거나 부족하지 않습니다.
- 현재 모델(Gemma3:1b 등)의 한계와 목록/포맷 인식 문제로 답변이 불안정하게 나오는 것입니다.
- 질문을 “두 번째 음식이 무엇인가요?” → “앞서 알려준 목록에서 2번 음식명을 알려주세요” 형태로 구체화하거나, 한국어 전용 튜닝 모델로 교체해 보십시오.
- 추가 공부: verbose=True 옵션
- 체인이 실행되는 모든 내부 동작(예: 프롬프트 템플릿이 어떻게 구성됐는지, 입력과 메모리의 상태 등)을 콘솔에 상세하게 출력해주는 디버깅용 설정
- 역할 및 효과
- 프롬프트 출력: LLM에 전달되는 최종 프롬프트(본문 + 대화 기록 + 입력 등)가 어떻게 포맷되는지 콘솔에 확인할 수 있게 해줍니다.
- 체인 입출력 노출: 체인 시작/종료 타이밍, 형식화된 프롬프트, Memory 내용 등도 실시간으로 보여줍니다.
- 디버깅/최적화: 대화 흐름이 꼬이거나, 프롬프트가 의도와 다르게 동작할 때 원인을 파악하는 데 도움을 줍니다.
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI.
Current conversation:
Human: 3x2는 몇이야?
AI: 3x2는 6이야.
Human: 거기에 2를 곱하면?
AI:
> Finished chain.
3x2x2는 12이야.- verbose=True로 하면 내부 프롬프트와 Memory 내용, 각 단계마다 어떤 데이터가 들어가는지 바로 볼 수 있음
- verbose를 켜면 "체인의 자동 생략/감추는 내부 처리과정"을 전부 콘솔에 그대로 보여주기 때문에, 대화형 AI 파이프라인을 개발/테스트/디버깅 할 때 필수 옵션으로 자주 활용됨
- 로그인해서 turbo 모델 써 보는 것도 추천해요~
Ⅲ. CAREER UP
수업 복습 / 추가 공부
추가: 대화 메모리 응용
ValueError: variable history should be a list of base messages, got of type <class 'str'>
지금 상황을 종합해보면 다음 두 가지 주요 문제가 교차하고 있습니다:
ConversationBufferWindowMemory를 기본적으로 쓰면history변수가 메시지 객체 리스트가 되어야 하는데, 실제로는 문자열(string)이 들어가서 오류 발생chat_memory=True로 설정하려 하면 타입 오류가 나서 못 씀
이는 LangChain의 메모리 구조와 프롬프트 템플릿의 MessagesPlaceholder 간에 타입 불일치 문제이고, 버전별로 인터페이스가 다소 바뀌어 혼선이 발생하는 전형적인 케이스입니다.
- 안정적인 해결법 제안
ConversationBufferMemory(기본 문자열 메모리) +PromptTemplate사용- 가장 간단하고 호환성 좋은 방식을 씁니다.
ConversationBufferMemory는 단순 문자열 기반 메모리라서,MessagesPlaceholder대신 일반PromptTemplate에{history}문자열을 넣어 처리합니다.
- 예제 코드
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = Ollama(model="gemma3:1b")
memory = ConversationBufferMemory() # 문자열 형태의 메모리
prompt = PromptTemplate(
input_variables=["history", "input"],
template=(
"다음은 사람과 AI의 대화 내용입니다:\n"
"{history}\n"
"사람: {input}\n"
"AI:"
),
)
chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
while True:
q = input("입력 : ")
if q.lower() == "exit":
print("종료합니다.")
break
res = chain.invoke({"input": q})
# res는 dict, 여기선 'text' 키로 결과 문자열 들어있음
print(res["text"])
print()- 요점
ConversationBufferMemory는history를 문자열로 관리합니다.PromptTemplate에서{history}도 문자열 변수로 처리해서 타입 에러 없습니다.MessagesPlaceholder등 구조화된 메시지 기반 프롬프트는ConversationBufferWindowMemory(chat_memory=True)같이 엄격히 메시지 객체 리스트를 주는 메모리와만 쓸 수 있습니다.- 만약 꼭 구조화된 메시지 타입 메모리를 쓰고 싶으면 LangChain 버전을 맞추거나,
ChatMessageHistory객체를 메모리에 주입하는 등 추가 작업이 필요한데, 초기 단계라면 위처럼 문자열 메모리 + 일반 프롬프트 템플릿 조합이 가장 무난합니다.
프롬프트 관련
prompt = ChatPromptTemplate.from_messages([
("system", "당신은 친절한 AI 챗봇입니다. AI는 기억을 참고해 항상 명확하게 한국어로 대답해주세요."),
MessagesPlaceholder(variable_name="history"), 대화 기록 삽입 위치 (중요)
("user", "{input}")
])- 구조화된 메시지 타입 메모리를 쓰면 오류가 발생
- LangChain의 메모리 구조와 프롬프트 템플릿의 MessagesPlaceholder 간에 타입 불일치 문제 → 버전별로 인터페이스가 다소 바뀌어 혼선이 발생하는 전형적인 케이스
- ConversationBufferMemory 는 history를 문자열로 관리
- PromptTemplate 에서 {history}도 문자열 변수로 처리해서 타입 에러는 없지만 MessagesPlaceholder 등 구조화된 메시지 기반 프롬프트는 ConversationBufferWindowMemory(chat_memory=True) 같이 엄격히 메시지 객체 리스트를 주는 메모리와만 쓸 수 있음
- 만약 꼭 구조화된 메시지 타입 메모리를 쓰고 싶으면 LangChain 버전을 맞추거나, ChatMessageHistory 객체를 메모리에 주입하는 등 추가 작업이 필요
체인 관련
- ConversationChain만으로도 메모리, 프롬프트, 출력 처리 등 대화형 챗봇 구현에 필요한 대부분을 커버 가능
- 별도 출력 파서 없이도 응답이 문자열로 잘 나오고 메모리도 문제 없이 작동함
- 만약 LLMChain을 꼭 쓰고 싶다면 출력 파서, 문자열 변환, 메모리 관리 등을 세세히 직접 맞춰야 함
from langchain_community.llms import Ollama
from langchain.memory import ConversationBufferWindowMemory
from langchain.chains import ConversationChain
from langchain_core.prompts import PromptTemplate
llm = Ollama(model="gemma3:1b")
memory = ConversationBufferWindowMemory(k=2)
template = (
"다음은 사람과 AI의 대화 기록입니다:\n{history}\n"
"질문: {input}\n"
"AI는 기억을 참고해 한국어로 명확하게 대답하세요."
)
prompt = PromptTemplate(input_variables=["history", "input"], template=template)
conversation = ConversationChain(llm=llm, memory=memory, prompt=prompt)
while True:
q = input("입력 : ")
if q == "exit":
break
res = conversation.predict(input=q)
print(res)
print()기억 연결 관련
- Ollama 모델과 LangChain 호환성 고려
- Ollama가 OpenAI GPT 계열과 작동 방식이 완전 같지 않아서, LangChain 대화형 컴포넌트에서 완벽한 기억 연결이 안될 수도 있습니다.
- 그럴 때는 직접 프롬프트 템플릿 내에 memory 내용을 넣는 방식을 권장합니다
- 두 번째 음식이 "불고기"가 아닌 "갈비찜"으로 나오는 현상
- 대화 기록(메모리) 구조와 내용 누적 방식
- 현재 메모리(
ConversationBufferMemory또는ConversationBufferWindowMemory)는 최근 대화들을 단순히 순서대로 누적합니다. - 따라서 대화 히스토리에서 "한국 전통 음식 5가지 알려줘" 질문에 대한 대답 전체를 그대로 문맥으로 제공하지만, 단순 목록에서 두 번째 아이템을 인식해 답변하는 로직은 모델이 학습된 방식 및 프롬프트 내 문맥에 좌우됩니다.
- 현재 메모리(
- 모델 언어 이해/추론 한계
- LLM은 문장 전체를 토큰 단위로 이해하고 답변을 예측하지만 목록 아이템의 순서를 완벽히 인식하지 못할 수 있습니다.
- 질문이 "두 번째 음식 이름"이지만, 모델이 리스트 순서에서 두 번째를 "불고기"가 아닌 "갈비찜"으로 혼동하거나, 문맥상 강조된 요소를 기준으로 답변한 결과일 수 있습니다.
- 프롬프트 문맥 부족 또는 모호함
- 프롬프트가 단순히 대화 기록과 질문을 연결하는 수준이라, 모델에게 정확히 리스트 내 두 번째 항목을 골라내라고 명확히 지시하지 않을 경우 혼란 발생
- 리스트 내 번호 붙인 항목들이 문장이나 문단 사이에 섞여서 순서 판단이 어려워질 수 있음
- 대화 기록(메모리) 구조와 내용 누적 방식
- 해결책 및 개선 방법
- 프롬프트에 정확한 지시문 추가
- 프롬프트 내 질문 부분을 조금 더 명확히 바꿔 모델이 순서대로 항목을 인식하도록 유도 → 위 대화에서 한국 전통 음식 5가지 중 두 번째로 소개된 음식 이름을 정확히 알려주세요.
- 또는 질문 바로 전에 리스트 내용 요약을 별도 문장으로 강조할 수도 있음
- 대화 기록 요약 및 정리 메모리 사용
ConversationSummaryMemory같은 요약형 메모리를 쓰면 대화 히스토리가 정돈되어 모델이 핵심 정보를 더 명확히 인식
- 별도 QA 체인이나 RAG 체인 활용
- 대화용 메모리 대신, 리스트나 문서를 외부 지식으로 저장 후, 정확한 질문에 문서 기반 답변을 얻는 RAG(Retrieval-Augmented Generation) 체인 구성
- 프롬프트에 정확한 지시문 추가
- 요약
- 모델은 대화 기록 문맥과 프롬프트에 크게 의존하여 답을 만드므로, 문맥 내 리스트 항목 순서 인식이 완벽하지 않을 수 있습니다.
- 정확한 순서 정보를 요구할 때는 프롬프트를 명확히 하거나, 대화 기록을 잘 정리하고 요약하는 메모리를 쓰는 것이 효과적입니다.
- 고도화하려면 질문별 전문 QA 시스템과 결합 구성이 필요합니다.
추가: wrapper
- wrapper
- 사전적 의미는 '(특히 식품) 포장지'라는 뜻
- 프로그래밍에서: 활동범위를 설정하고 좀더 중요한 다른 프로그램의 실행을 가능하게 하는 프로그램이나 스크립트
- 실제 데이터의 앞에서 어떤 틀을 잡아 주는 데이터 또는 다른 프로그램이 성공적으로 실행되도록 설정하는 프로그램
- 기존 코드에 새로운 기능을 추가하거나, 호환되지 않는 인터페이스를 맞춰주는 등의 목적으로 사용
- 데이터 통신에서: 전송 메시지의 앞이나 둘레에 놓여져 그에 관한 정보를 제공하는 데이터
- http://와 ftp:// 등과 같이 인터넷 주소 또는 URL의 앞에 붙는 것
- 어떤 단어를 감싸는데 사용되는 < 또는 > 등과 같은 꺾쇠 기호
- 데이터베이스 기술에서: 감추어진 데이터를 보거나 변경하기 위해 누가 액세스해야 할지를 결정하는 데 사용
- 래퍼 클래스(wrapper classes): 기본 자료형(primitive data types)에 대한 클래스 표현
- 기본 자료형에 대해서 객체로서 인식되도록 '포장'을 했다는 뜻
- 객체라는 상자에 기본 자료형을 넣은 상태로 생각하면 됨
- 필요시 컴파일러가 자동으로 수행 → 오토박싱(autoboxing)
- 기본 자료형에 대해서 객체로서 인식되도록 '포장'을 했다는 뜻
- 예시
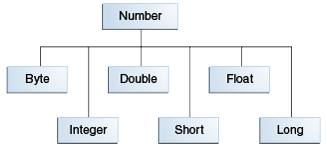
- Byte 클래스는 byte 자료형, Short는 short 자료형, Integer는 int 자료형, Long은 long 자료형, Float는 float 자료형, Double은 double 자료형에 대한 래퍼 클래스
- 숫자 자료형의 모든 래퍼 클래스는 모두 Number라는 추상 클래스를 상속 받아서 구현한 것
- 래퍼 클래스를 사용하는 이유
- 객체 또는 클래스가 제공하는 메소드 사용
- 클래스가 제공하는 상수 사용(MIN_VALUE and MAX_VALUE)
- 숫자, 문자로의 형변환 또는 진법 변환시 사용
- Facade는 복잡성을 줄이기 위해 여러 Wrapper를 활용하여 통합된 인터페이스를 제공하는 디자인 패턴
- Facade 객체는 내부의 여러 복잡한 객체들을 Wrapper로 감싸고, 이를 통합하여 클라이언트에게 제공하는 인터페이스를 구성
- Facade 패턴은 여러 Wrapper 객체들을 활용하여 최종적으로 하나의 단순한 인터페이스를 제공하는 방식으로 구현
- Facade는 복잡한 하위 시스템을 감싸는 Wrapper의 역할을 하지만, 그 목적과 범위가 훨씬 더 크고 구조적
- Facade 객체는 내부의 여러 복잡한 객체들을 Wrapper로 감싸고, 이를 통합하여 클라이언트에게 제공하는 인터페이스를 구성
하루 돌아보기
👍 잘한 점
- 수업 시간 참여 많이 함 & 질문 많이 함
👎 아쉬웠던 점
- Local LLM 메모리 구현 과정에서 실수가 많았음
🔬 개선점
- 주말에 복습하기!
