코딩테스트 연습
알고리즘
def solution(n, arr1, arr2):
answer = []
for i, j in zip(arr1, arr2):
answer.append(str(bin(i|j))[2:].rjust(n,' ').replace('1','#').replace('0',' '))
return answer- Python String rjust() Method
- Python의 문자열 함수
- 기존 문자열의 길이를 width로 늘려 오른쪽 정렬
문자열.rjust(전체 자리 숫자, 공백이 있을 경우 공백을 채울 텍스트)
- 비트연산자
- 비트 OR (|): 두 비트 중 하나라도 1이면 1을 반환합니다.
- 한 줄로 적는 것도 가능
# 1
def solution(n, arr1, arr2):
return [str(bin(i | j))[2:].rjust(n,' ').replace('1','#').replace('0',' ') for i,j in zip(arr1,arr2)]
# 2
solution = lambda n, arr1, arr2: ([''.join(map(lambda x: '#' if x=='1' else ' ', "{0:b}".format(row).zfill(n))) for row in (a|b for a, b in zip(arr1, arr2))])zfill()써도 됨
def solution(n, arr1, arr2):
answer = []
for i, j in zip(arr1, arr2):
answer.append(str(bin(i|j))[2:].zfill(n).replace('1','#').replace('0',' '))
return answer- args 활용
f'{x:016b}'로 x(=a|b)를 16자리 이진수 문자열로 만들어준다.- 문제에서 1≤n≤16이라고 줬기 때문에 16자리 이진수 문자열로 만들면 다 커버됨
- 슬라이싱해서 n자리 수로 만들어 줌
- 입력 받은 지도의 한 변 크기 n에 맞춰야 하기 때문
- 0이면
' #'[0]으로 공백이 문자열에 추가되고 1이면' #'[1]이 돼서 #이 추가됨 - 그걸 maps(=arr1,arr2)의 모든 요소에 반복
def solution(n, *maps):
return [line(n, a | b) for a, b in zip(*maps)]
def line(n, x):
return ''.join(' #'[int(i)] for i in f'{x:016b}'[-n:])- 비트연산자 없이 풀기
# 하나라도 벽인 부분은 전체 지도에서도 벽 (벽: 1)
# 모두 공백인 부분은 전체 지도에서도 공백 (공백: 0)
def adjust_length(binary, n):
while len(binary)<n:
binary = '0' + binary
return binary
def solution(n, arr1, arr2):
answer = []
for i in range(n):
real_map = ''
map1 = bin(arr1[i])[2:]
map2 = bin(arr2[i])[2:]
map1 = adjust_length(map1, n)
map2 = adjust_length(map2, n)
for j in range(n):
if map1[j]=='1' or map2[j]=='1':
real_map += '#'
elif map1[j]=='0' and map2[j]=='0':
real_map += ' '
answer.append(real_map)
return answerSQL
SELECT
u.user_id AS buyer_id
, u.join_date
, COUNT(o.order_id) AS orders_in_2019
FROM
Users AS u
LEFT JOIN Orders as o
ON u.user_id = o.buyer_id
AND YEAR(order_date) = 2019
GROUP BY
u.user_id
;- ON에 년도 조건을 걸지 않고 해결하고 싶다면:
SELECT u.user_id AS buyer_id, u.join_date AS join_date,
SUM(CASE WHEN YEAR(o.order_date)=2019 THEN 1 ELSE 0 END) AS orders_in_2019
FROM Users u
LEFT JOIN Orders o
ON u.user_id=o.buyer_id
GROUP BY u.user_id
;- WHERE를 사용해 해결하고 싶다면 꼭 UNION까지 해 주어야 함!
SELECT buyer_id, join_date, COUNT(*) AS orders_in_2019
FROM Orders
JOIN Users ON buyer_id=user_id
WHERE YEAR(order_date) = 2019
GROUP BY buyer_id
UNION
SELECT user_id AS buyer_id, join_date, 0 AS orders_in_2019 FROM Users
WHERE user_id NOT IN (SELECT DISTINCT buyer_id FROM Orders WHERE YEAR(order_date) = 2019)- CTE 사용
WITH OrderCount AS (
SELECT buyer_id, COUNT(*) as order_count
FROM Orders
WHERE order_date >= '2019-01-01' AND order_date <= '2019-12-31'
GROUP BY buyer_id
)
SELECT u.user_id as buyer_id, u.join_date, COALESCE(
(
SELECT o.order_count
FROM OrderCount o
WHERE o.buyer_id = u.user_id
),
0
) AS orders_in_2019
FROM Users u
;지난 시간 복습
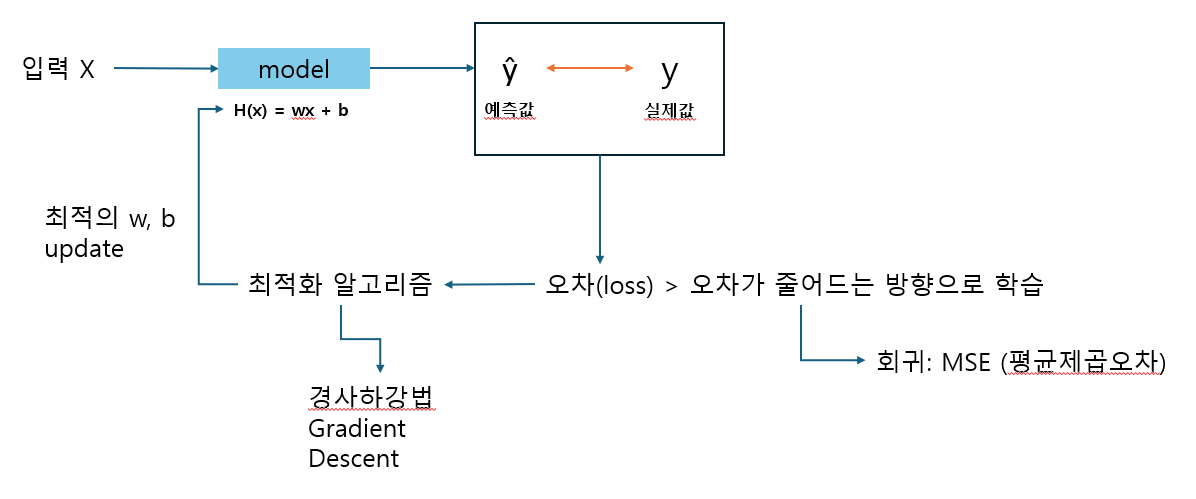
- 선형모델(Linear Model)
- 다양한 선형 모델이 존재
- 선형 회귀 분석: 예측값이 평균과 같이 일정한 값으로 돌아가려는 경향(회귀)을 이용한 통계학 기법 이용
- 선형 회귀의 원리: 데이터를 가장 잘 설명하는 직선을 그리는 것
- 입력 특성에 대한 선형 함수를 만들어 예측 수행
- 입력 특성 == feature == x축을 이야기한다!
- 분류와 회귀 모두 가능
- 선형 회귀 함수

- 다양한 입력값을 가짐
- p: 입력 특성의 개수
- 입력값의 가중치(w) 값에 따라 어떤 예측값이 나오는지 판단
- 수치를 확인해 데이터를 가장 잘 설명하는 직선을 그림
- 실제값과 예측값의 차이가 가장 작은 직선 찾기
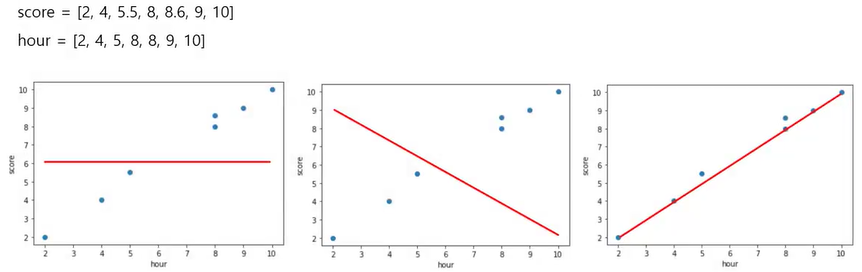
- 실제값과 예측값의 차이가 가장 작은 직선 찾기
- 다양한 입력값을 가짐
- MSE
- 데이터를 가장 잘 대표하는 직선을 그어 나가는 과정 중에서 '오차가 가장 작은' 직선을 찾기 위해 사용 → 오차를 수치로 나타낸 것
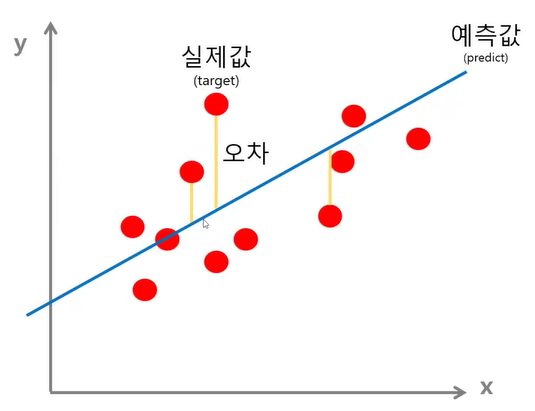
- 데이터 포인트를 가장 잘 나타내는 선 → 실제값(target)과 예측값(predict)의 오차가 작을수록 좋다! → 평균제곱오차가 최소인 w와 b 찾기

- 데이터 포인트를 가장 잘 나타내는 선 → 실제값(target)과 예측값(predict)의 오차가 작을수록 좋다! → 평균제곱오차가 최소인 w와 b 찾기
- 왜 제곱? 오차 상쇄를 막는다! → 오차가 상쇄되면 작게 느껴져서 수정을 잘 못함 (오차가 커야 수정을 많이 해서 설명을 가장 잘 하는 직선을 만들 수 있음)
- 절댓값 쓰면 안됨? 제곱해서 오차를 극대화해야 차이를 더 잘 느낄 수 있음 → 오차가 크게 보여야 수정에 도움이 됨
- 식
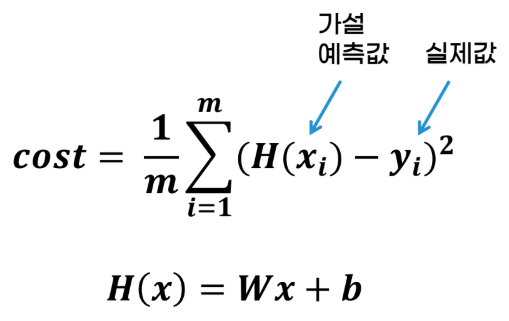
- 데이터를 가장 잘 대표하는 직선을 그어 나가는 과정 중에서 '오차가 가장 작은' 직선을 찾기 위해 사용 → 오차를 수치로 나타낸 것
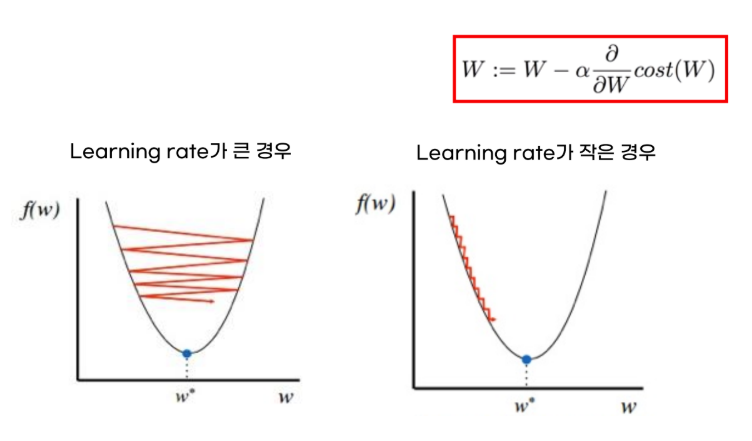
- 경사하강법
- MSE가 최소가 되는 w와 b를 찾는 방법
- 비용함수의 기울기(경사)를 구해 기울기가 낮은 쪽으로 계속 이동하여 값을 최적화시킴 → w, b의 가장 초기값은 랜덤으로 정함
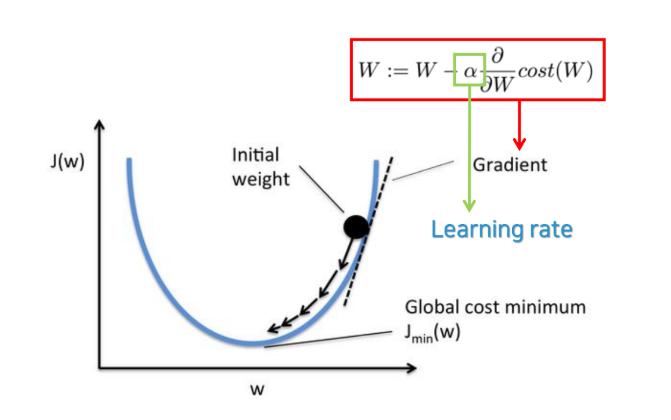
- learining rate(학습 보폭) 크면 발산, 비효율적
- learining rate 작으면 epoch(학습 횟수) 내에 최솟값을 찾지 못할 수 있음
추가: 회귀분석 기본 가정
- 독립변수와 종속변수 간의 관계는 선형적이어야 한다. → Linearity(선형성)
- 산점도 확인 → 선형성이 위배된다면 다항 회귀나 로그 변환 같은 방법을 고려해야 함
- 잔차(Residuals)는 모든 독립변수 값에 대하여 동일한 분산을 갖는다. → Homoscedasticity(등분산성)
- 독립변수의 변화에 따른 종속변수의 분산은 동일해야 함
- 잔차의 분포가 일정해야 한다 == 회귀선과 실제 데이터 간의 오차 크기가 일정해야 한다
- 산점도에서 점들이 부채꼴 모양으로 퍼져 있다면 가중 최소제곱법 같은 방법을 고려
- 잔차(오차)는 서로 독립적: 자기 상관(autocorrelation)이 없어야 함 → Independence(독립성)
- 잔차의 평균은 0이고, 정규 분포해야 한다. → Normality/Normality of Residuals(정규성)
- 회귀분석에서는 종속 변수(Y) 자체가 아니라, 잔차(Residuals)가 정규분포를 따라야 한다는 것이 중요
- 잔차가 정규성을 따르지 않으면 t-검정이나 F-검정의 결과가 신뢰할 수 없게 되므로 반드시 점검 → Q-Q Plot을 그려보거나 Shapiro-Wilk Test나 Kolmogorov-Smirnov Test 같은 정규성 검정을 수행
- 만약 정규성이 위배된다면, 로그 변환이나 Box-Cox 변환을 고려
- 회귀분석에서는 종속 변수(Y) 자체가 아니라, 잔차(Residuals)가 정규분포를 따라야 한다는 것이 중요
- 독립변수 상호 간에는 상관관계가 없어야 한다. → No Multicollinearity
- 독립변수들간에 상관관계가 나타나는 경우 다중공선성(Multicollinearity) 문제라고 함
- 독립 변수들끼리 너무 친하면 안 된다!
- X 변수들끼리 너무 비슷한 정보라면, 회귀모형이 헷갈려서 엉뚱한 결과를 내놓을 수도 있다
- VIF(Variance Inflation Factor, 분산팽창계수)를 확인 →보통 VIF 값이 10 이상이면 다중공선성이 심하다고 판단 → 변수를 줄이거나(Lasso 회귀), 주성분 분석(PCA) 등을 고려
- 시간에 따라 수집한 데이터들은 잡음의 영향을 받지 않아야 한다.
- 수집된 데이터의 분산은 정규분포를 이루고 있다.
집값 예측 실습
학습 목표
- 선형회귀이론 및 선형회귀모델의 학습 알고리즘에 대해 알 수 있다!
- LinearModel을 통해 집값을 예측해보자~
기본 설정
# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 경고창 무시
import warnings
warnings.filterwarnings("ignore")
# 데이터 불러오기 (data)
data = pd.read_csv("./data/melb_data.csv")
data
# 정답 -> Price 집값 데이터 (연속형 -> 회귀 학습)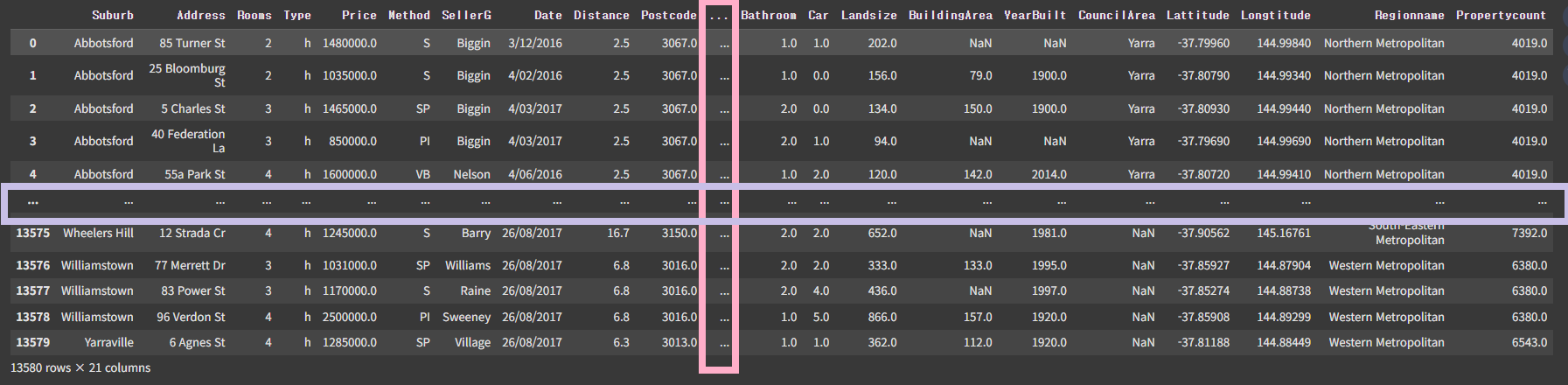
-
데이터프레임의 크기가 커서 열과 행이 생략된 상태로 출력됨 -> 열을 다 보고 싶은데 어떨게 하면 될까?
- 생략된 컬럼 열어보기
pd.set_option("display.max_columns", None): 전체 열 출력pd.set_option("display.max_rows", None): 전체 행 출력pd.reset_option("all"): 전체 설정 초기화pd.reset_option("display.max_columns"): 한 개의 설정만 초기화할 때(컬럼 설정 초기화)
- 생략된 컬럼 열어보기
-
집값 데이터 컬럼 설명
| 컬럼명 | 설명 |
|---|---|
| Suburb | 주택이 위치한 교외 지역의 이름 |
| Address | 주택의 주소 |
| Rooms | 주택의 방 개수 |
| Type | 주택 유형 (h: 주택, u: 유닛, t: 타운하우스) |
| Price | 주택 가격(호주 달러) |
| Method | 판매 방법 (S: 매매, SP: 매매 후 가격 공개, PI: 경매 전에 가격, VB: 경매 후 가격 공개) |
| SellerG | 판매 대행 부동산 중개인의 이름 |
| Date | 판매 날짜 |
| Distance | 주택이 CBD (중심 업무 지구)에서 떨어진 거리 (킬로미터 단위) |
| Postcode | 우편번호 |
| Bedroom2 | 주택의 침실 개수 (2개의 침실을 갖춘 주택) |
| Bathroom | 주택의 욕실 개수 |
| Car | 주차 가능한 자동차 수 |
| Landsize | 대지 면적 (평방 미터 단위) |
| BuildingArea | 건축 면적 (평방 미터 단위) |
| YearBuilt | 주택이 건축된 연도 |
| CouncilArea | 관할 구역 |
| Lattitude | 주택의 위도 |
| Longtitude | 주택의 경도 |
| Regionname | 지역 이름 |
| Propertycount | 지역 내의 부동산 개수 |
→ 정답(y)이 되는 컬럼: Price
- 데이터에 대한 정보 확인
# 기본 정보
data.info()
# 결측치가 있는 컬럼 확인 -> EDA를 통해 채울지 결정
data.isna().sum().sort_values(ascending=False)
# 기술통계량 확인
data.describe().T # 수치 데이터만 확인 가능
# 텍스트 데이터(범주 데이터)는 하나씩 따로 확인해보기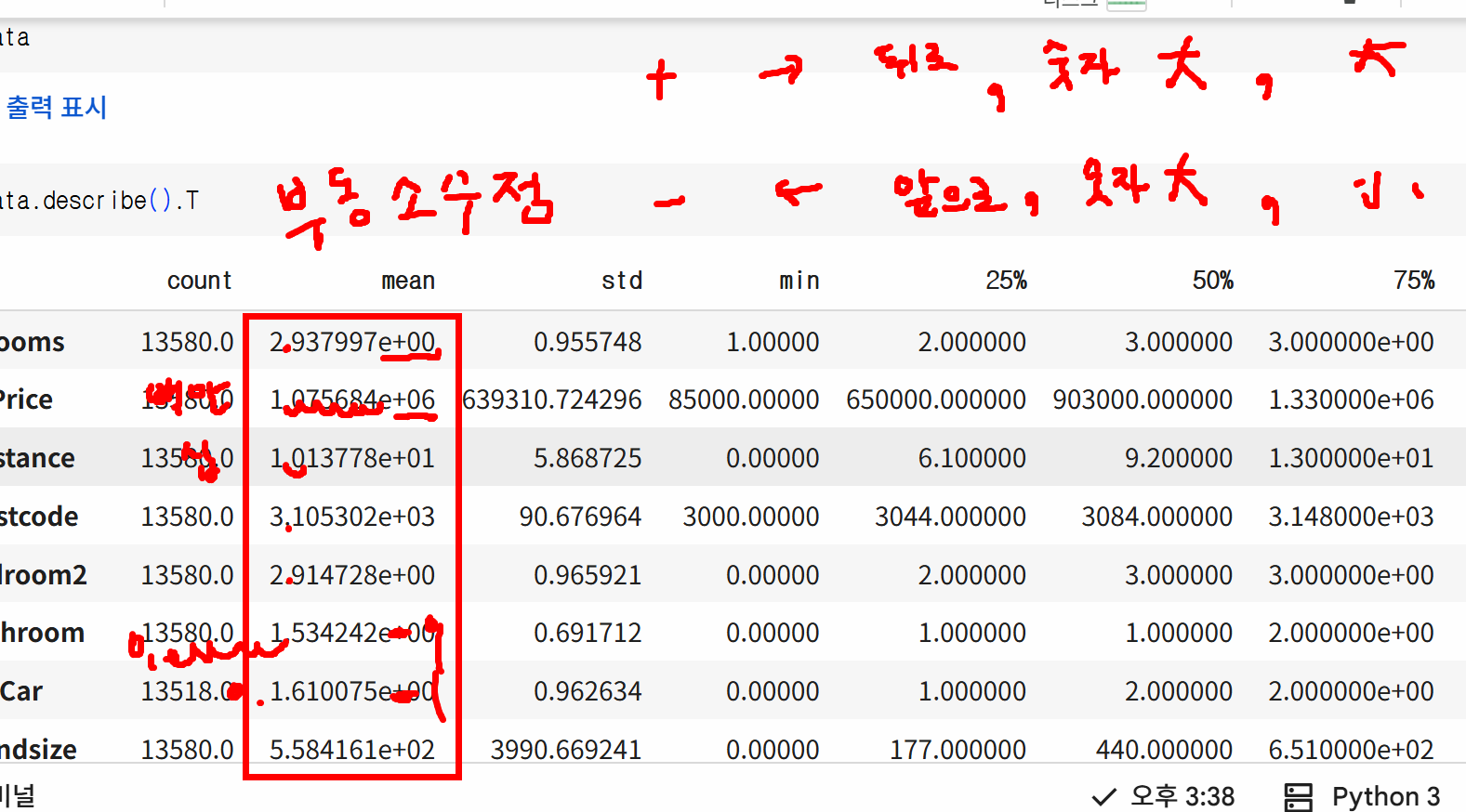
- 부동소수점을 일반 숫자로 출력하는 방법
# 부동소수점 일반 숫자로 출력하는 방법
pd.options.display.float_format = '{:.2f}'.format탐색적 데이터 분석(EDA)
주택 타입별 가격 확인
data["Type"].unique()
# 출력:
# array(['h', 'u', 't'], dtype=object)
# 각 타입들의 개수를 확인
data["Type"].value_counts()| Type | count |
|---|---|
| h | 9449 |
| u | 3017 |
| t | 1114 |
- h: house
- u: unit
- unit? 4-5의 소수의 세대 옆으로 수평적으로 위치한 주택
- 한국 빌라 같은 거
- unit? 4-5의 소수의 세대 옆으로 수평적으로 위치한 주택
- t: townhouse
# 주택 타입별 가격 평균 확인 -> groupby
data["Price"].groupby(data["Type"]).mean()
# 방법은 다양함
# 사용할 컬럼.groupby(기준이 되는 컬럼).함수()
data[["Type", "Price"]].groupby(["Type"]).mean()
# agg() 함수도 가능
data.groupby(["Type"])["Price"].agg('mean')
# Pivot table로도 가능하지만 보통 groupby를 더 많이 씀
data.pivot_table(index="Type", values="Price", aggfunc="mean")| Type | Price |
|---|---|
| h | 1242664.76 |
| u | 933735.05 |
| t | 605127.48 |
# 시각화 -> pandas에서 제공해주는 간략하게 그래프 그리는 방법
data[["Type", "Price"]].groupby(["Type"]).mean().plot(kind="bar")
# 범주 형태의 데이터는 주로 막대그래프를 그림(or 히스토그램)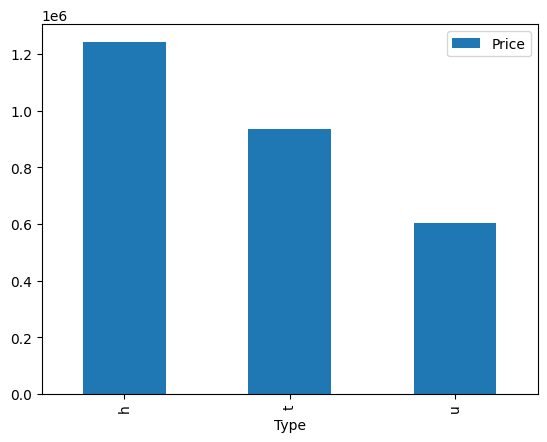
# x축 글씨 방향 돌리기
data[["Type", "Price"]].groupby(["Type"]).mean().plot(kind="bar")
plt.xticks(rotation=0)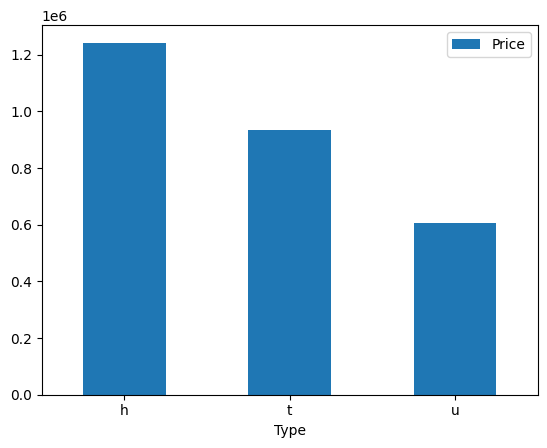
# 상관계수 확인
data.corr(numeric_only=True)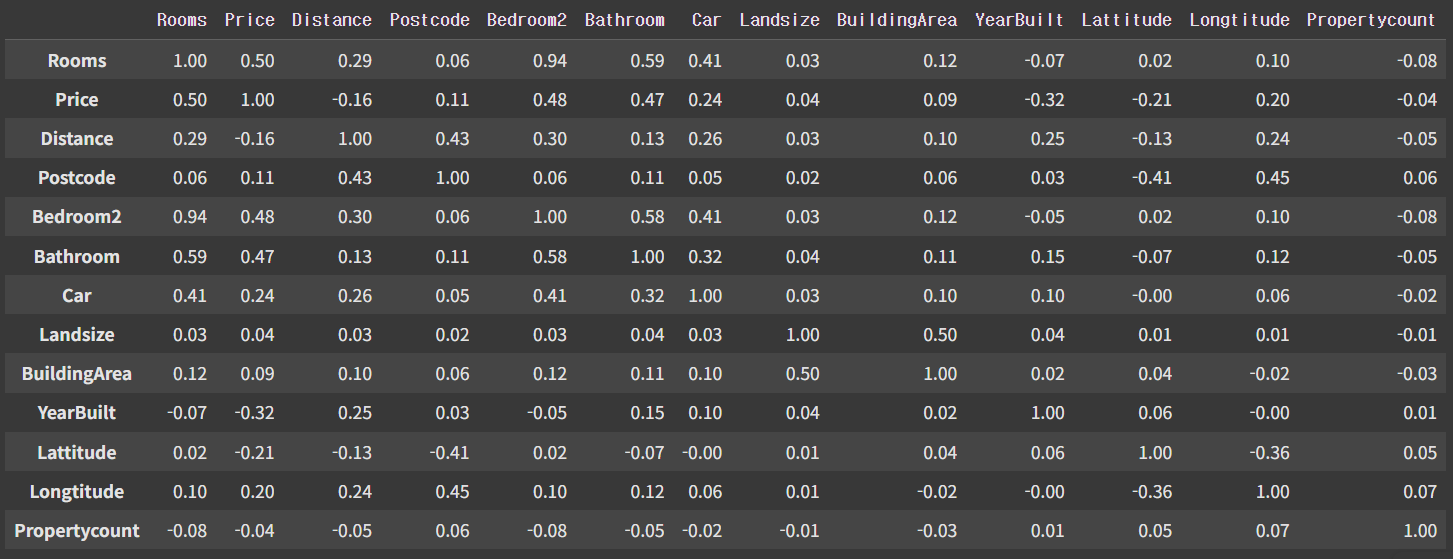
# 내림차순(절대값)으로 Price 컬럼 정렬
data.corr(numeric_only=True).abs().sort_values(by="Price", ascending=False)["Price"]
# 이렇게 써도 됨
data.corr(numeric_only=True)["Price"].abs().sort_values(ascending=False)
# Price에 영향을 가장 많이 미치고 있는 Rooms 확인해보기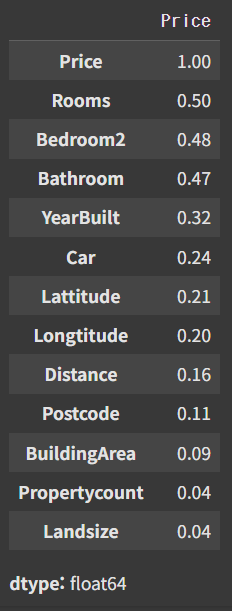
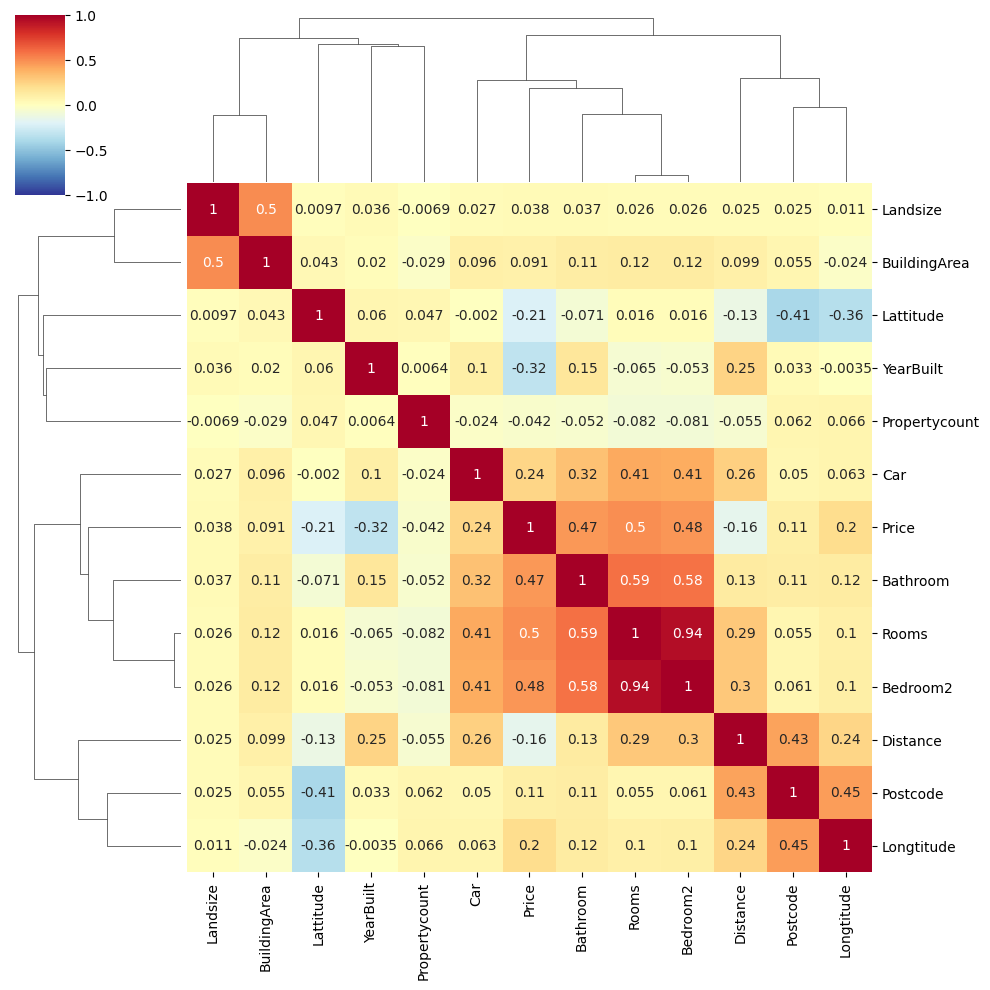
추가: 상관계수 시각화
df_plus = data.corr(numeric_only=True)
sns.clustermap(df_plus,
annot = True, # 실제 값 화면에 나타내기
cmap = 'RdYlBu_r', # Red, Yellow, Blue 색상으로 표시
vmin = -1, vmax = 1, #컬러차트 -1 ~ 1 범위로 표시
)
# 그림 사이즈 지정
fig, ax = plt.subplots(figsize=(7,7))
# 삼각형 마스크를 만든다(위 쪽 삼각형에 True, 아래 삼각형에 False)
mask = np.zeros_like(df_plus, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# 히트맵을 그린다
sns.heatmap(df_plus,
cmap = 'RdYlBu_r',
annot = True, # 실제 값을 표시한다
mask=mask, # 표시하지 않을 마스크 부분을 지정한다
linewidths=.5, # 경계면 실선으로 구분하기
cbar_kws={"shrink": .5},# 컬러바 크기 절반으로 줄이기
vmin = -1,vmax = 1 # 컬러바 범위 -1 ~ 1
)
plt.show()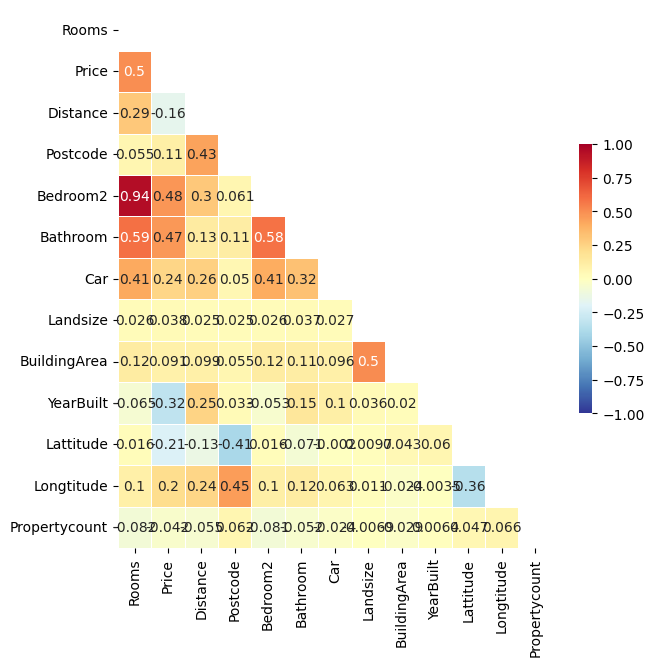
방의 개수에 따른 가격
# 상자 그림 -> 데이터의 분포 확인 -> 이상치 여부 확인도 가능하다~
fig1, ax1 = plt.subplots(figsize = (8,12))
sns.boxplot(data=data, x="Rooms", y="Price", ax=ax1)
plt.show()
# 방의 개수가 증가할수록 주택가격이 상승
# 특정 지점 이상에서는 가격 상승이 정체됨
# 박스의 크기가 크다는 것은 방 개수에 따른 가격 변동성이 큰 것을 의미
# 방의 개수가 많아질수록 가격 변동성이 크다!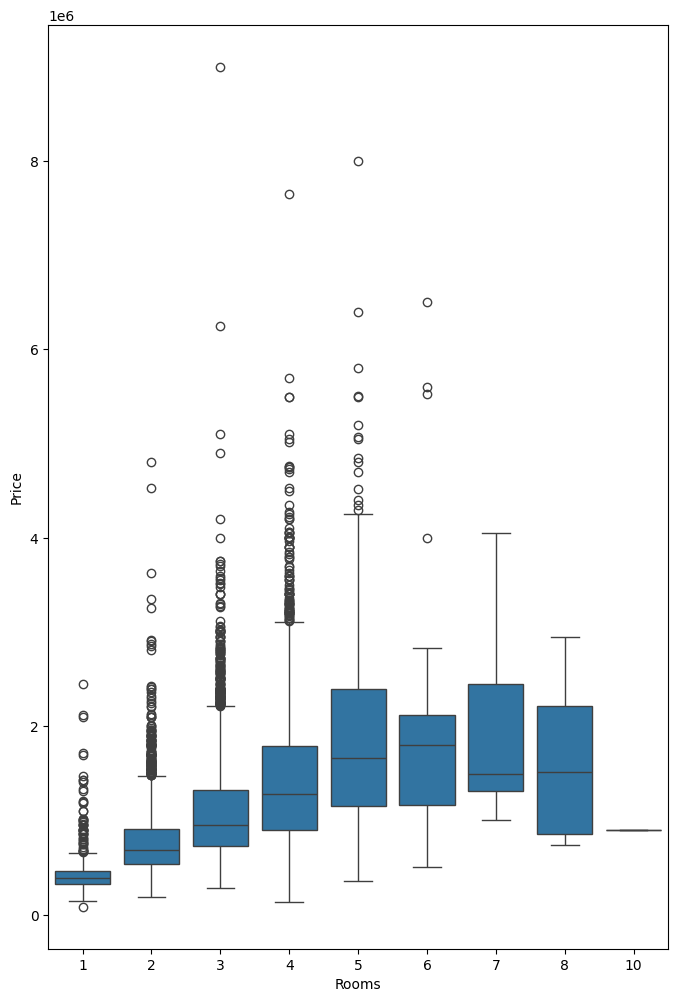
상자 그림 해석
- 중앙값을 보면서 경향 확인하기
- 방의 개수가 많아질수록 가격이 상승
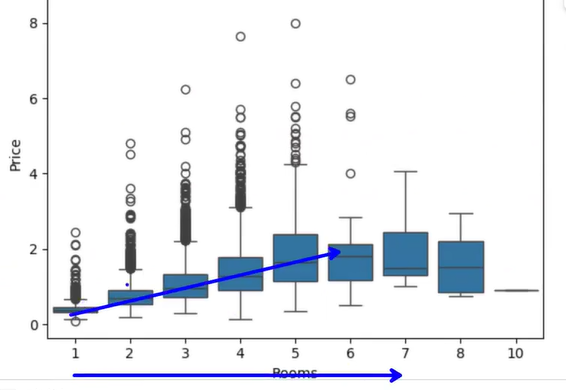
- 특정 개수를 넘어서면 가격이 더 이상 오르지 않는 경향
- 특정 지점 이상에서는 가격 상승이 정체됨
- 7개 이상에서는 크게 영향을 미치지 않고 있음
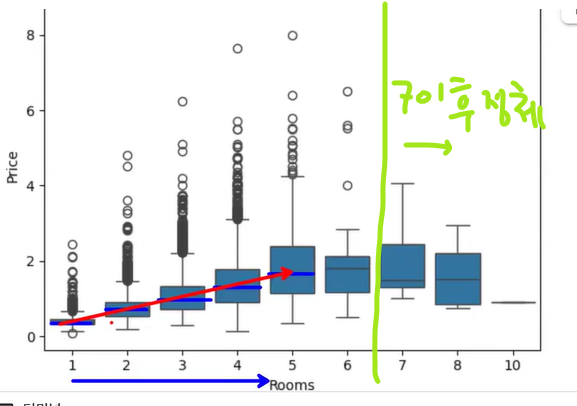
- 방의 개수가 많아질수록 가격이 상승
- 상자의 크기를 보면서 경향 확인하기
- 박스 크기가 크다는 것은 방 개수에 따른 가격 변동성이 크다(분포가 크다)는 의미
- 방의 개수가 많아질수록 가격의 변동성이 커지는 것을 알 수 있음
이상치 개수 확인
# 방이 3개인 데이터의 이상치 개수 확인
# 방이 3개인 데이터만 추출
rooms_3 = data[data["Rooms"]==3]
# 이상치는 박스 플롯에서 최댓값보다 클 때 (상위경계값: Q3 + 1.5*IQR)
# IQR: 4분위수 범위 (Q3-Q1)
Q1 = rooms_3["Price"].quantile(0.25)
Q3 = rooms_3["Price"].quantile(0.75)
IQR = Q3 - Q1
# 이상치 조건
upper_bound = Q3 + 1.5 * IQR
# 이상치 추출 -> 불리언 인덱싱
rooms_3[rooms_3["Price"]>upper_bound]
# 총 173개변수 간 산점도 확인
- Pair Plot 그래프
- 대각선: 해당 변수의 히스토그램 -> 변수의 분포 확인
- 대각선 외: 변수 간 산점도 확인 -> 두 개의 변수 간 분포 확인
# pairplot(data): 변수 간 상관관계를 시각화 -> 분포 확인
sns.pairplot(data[['Rooms','Bedroom2','Bathroom','Lattitude','Distance','Type','Price']])
plt.show()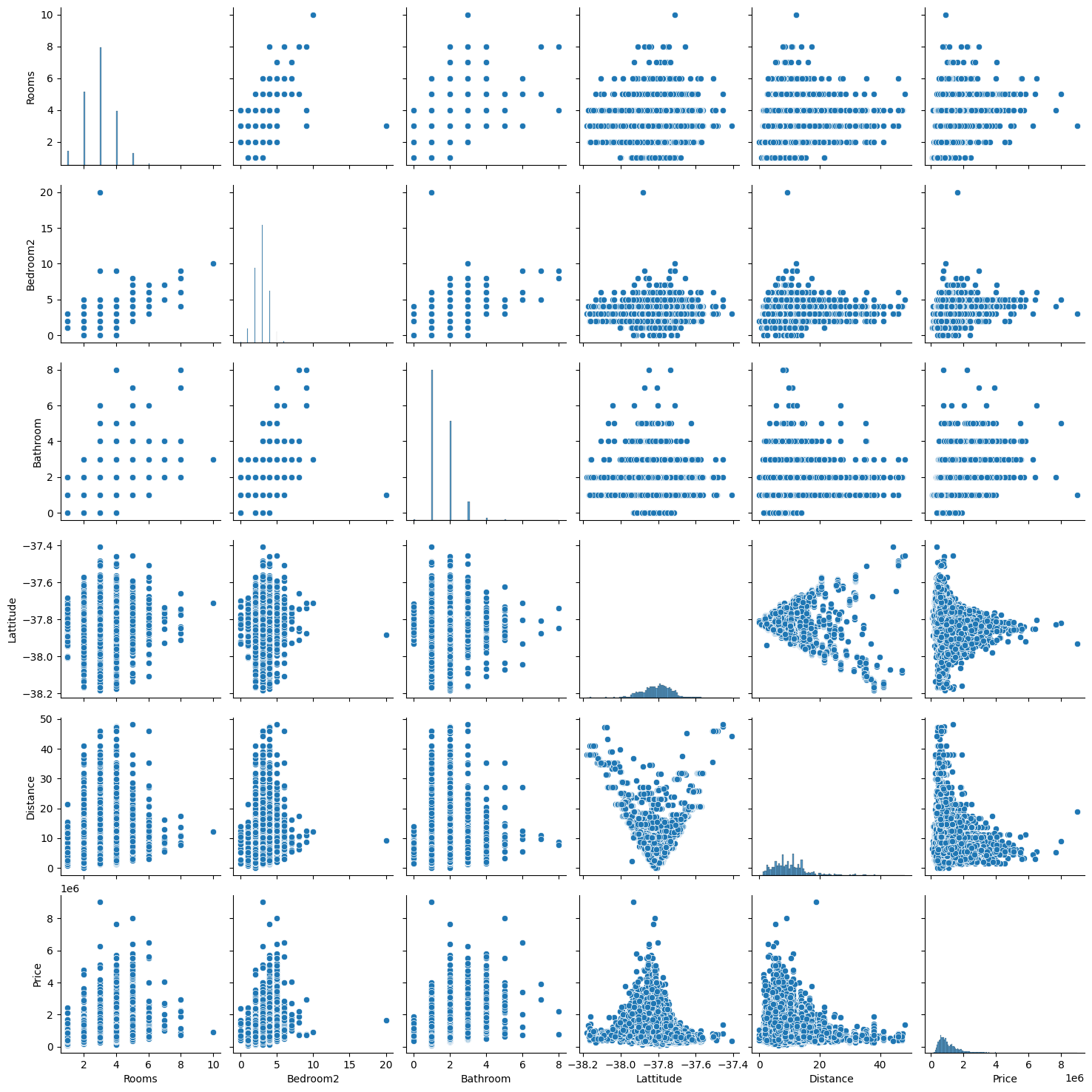
- 이변수 데이터의 분포
- 인자로 전달되는 데이터프레임의 열(변수)을 두 개씩 짝 지을 수 있는 모든 조합에 대해서 표현
- 열은 정수/실수형이어야 함
- 3개의 열이라면 3행 x 3열의 크기로 모두 9개의 그리드를 만든다.
- 각 그리드의 두 변수 간의 관계를 나타내는 그래프를 하나씩 그리며 같은 변수끼리 짝을 이루는 대각선 방향으로는 히스토그램을 그린다.
- 서로 다른 변수 간에는 산점도를 그린다.
- 인자로 전달되는 데이터프레임의 열(변수)을 두 개씩 짝 지을 수 있는 모든 조합에 대해서 표현
- 히스토그램 (대각선)
- 방의 개수 -> 2~4개 사이가 일반적으로 존재
- 위도: 특정 범위에 분포 -> 분포된 위치에 따른 가격도 확인
- 가격: 오른쪽으로 긴 꼬리를 가지는 분포
- 대부분 가격이 앞쪽에 몰려있으나 극단적으로 높은 가격이 존재
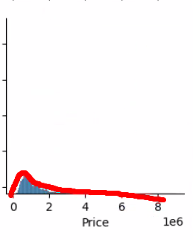
- 앞쪽에 데이터가 많이 모여 있는 분포
- 대부분 가격이 앞쪽에 몰려있으나 극단적으로 높은 가격이 존재
- 상관관계 분석 결과
- Rooms: 양의 상관관계
- 방의 개수가 많아질수록 가격이 증가
- 하지만 7개 이상부터는 큰 의미를 띄지 않음
- Bedroom2: 양의 상관관계이지만 방의 개수보다는 큰 영향을 미치지는 않음
- Lattitude
- -37.8 부근에 가까워질수록 가격이 상승
- 위도가 낮아질수록 가격도 낮아지는 것을 확인
- Distance: 음의 상관관계
- 중심지와의 거리가 멀어질수록 가격이 하락한다
- 중심지와 가까울수록 가격이 높음
- Rooms: 양의 상관관계
결측치 채우기 ★★★
- 다른 컬럼과의 연관성 파악 -> 데이터 유추하여 결측치 채움
- 기술통계량 확인 후 결측치 채우기
- 평균, 중앙값, 최빈값
- 특수값으로 대체
- 결측치 자체가 의미를 가지는 경우 -> 특수값으로 대체 후 정답과의 상관관계 확인
- 예: 타이타닉 Cabin(호실) 데이터 -> 'M'이라는 값으로 결측치를 채웠음
- 결측치 자체가 의미를 가지는 경우 -> 특수값으로 대체 후 정답과의 상관관계 확인
- 컬럼 삭제
- 결측치 비율이 너무 높을 때
- 컬럼의 특성이 영향에 영향을 적게 미칠 때
- 데이터 내에서 관계를 찾기가 어려울 때
Car 컬럼의 결측치 채우기
- Car: 주차 가능한 자동차 수
data["Car"].isna().sum()
# 출력:
# np.int64(62)
data.corr(numeric_only=True)["Car"]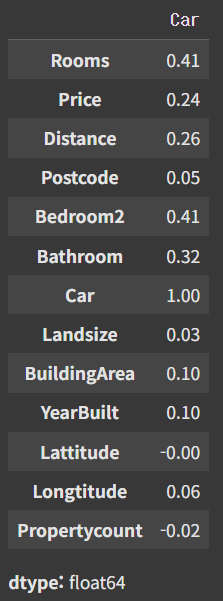
# Type과 Car 데이터 분포 확인
plt.figure(figsize=(9,5))
sns.boxplot(x="Type", y="Car", data=data)
plt.show()
# u에 비해 t, h 순으로 주차 공간이 많은 것을 확인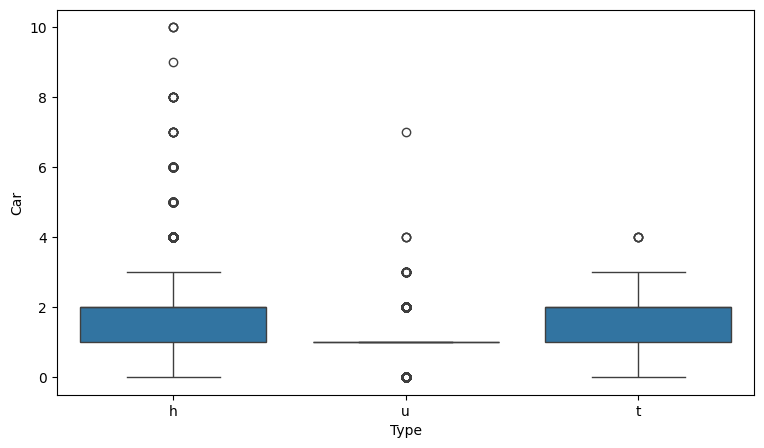
- h, t에 비해 u는 주차 공간 적음(박스 크기)
- h는 주차 공간 많음(이상치 개수 → 이상치로 보지 않기로)
# Rooms와 Type에 따른 Car 중위수 계산 -> car_mid = data.groupby(["Rooms", "Type"])["Car"].median()
# 단순하게 결측치를 채우는 것이 아니라 값의 상관관계를 통하여 결측치를 채움
# 함수 생성(fill_car) -> 값이 비어있으면 방과 타입에 따라 차 대수를 반환, 값이 있으면 해당 차 대수를 반환
def fill_car(data)->float:
if pd.isna(data["Car"]):
return car_mid.loc[(data["Rooms"], data["Type"])] # ※1
else:
return data["Car"]
# 함수 적용 -> apply()
data["Car"] = data.apply(fill_car, axis=1)
data["Car"].isna().sum()
# 출력:
# np.int64(0)※1: # titanic의 Age는 pivot_table(→테이블: 행과 열 존재)이었기 때문에 열 이름이 필요했지만 car_mids는 groupby(→단순 계산 결과)의 결과라 단순 값을 한 줄만 추출했기 때문에 필요 없음
CouncilArea 결측치 채우기
- CouncilArea: 관할 구역
data["CouncilArea"].unique()array(['Yarra', 'Moonee Valley', 'Port Phillip', 'Darebin', 'Hobsons Bay',
'Stonnington', 'Boroondara', 'Monash', 'Glen Eira', 'Whitehorse',
'Maribyrnong', 'Bayside', 'Moreland', 'Manningham', 'Banyule',
'Melbourne', 'Kingston', 'Brimbank', 'Hume', nan, 'Knox',
'Maroondah', 'Casey', 'Melton', 'Greater Dandenong', 'Nillumbik',
'Whittlesea', 'Frankston', 'Macedon Ranges', 'Yarra Ranges',
'Wyndham', 'Cardinia', 'Unavailable', 'Moorabool'], dtype=object)len(data["CouncilArea"].unique())
# 출력:
# 34
# 관할구역 그래프 그리기~
# 각 값들의 개수 확인
data["CouncilArea"].value_counts()
# 데이터 개수를 세어 그래프 추출 -> countplot
plt.subplots()
sns.countplot(y="CouncilArea", data=data, order=data["CouncilArea"].value_counts().index)
plt.show()
# 최빈값으로 채울까? -> 최빈값으로 채운다면 Moreland, Boroondara... 둘 중에 뭘로 채우지?
# 다른 컬럼과의 연관성 파악 -> 데이터 유추하여 결측치 채움 -> Suburb, Postcode, Regionname, Address 등- 결측치를 채우는 다양한 방법 -> 주변의 컬럼과의 관계성을 파악하여 결측치를 채워보자!
- CouncilArea: 관할 구역
- 위도경도 -> 비슷한 위치에 따른 관할 구역 설정
- 우편번호
- 지역이름
- Suburb (주택 시장 내에서 지역을 구분할 때 사용되는 가장 세분화된 단위 중 하나)
# Suburb 데이터를 활용하여 CouncilArea 결측치 처리
# 지역에 따른 매칭을 위해 최빈값으로 두 값을 매칭
mode_co = data.groupby("Suburb")["CouncilArea"].agg(pd.Series.mode)
# 관할 구역값이 있으면 그 값을 추출, 없으면 Suburb에 해당하는 값을 추출
def fill_council (row):
if pd.isna(row["CouncilArea"]):
return mode_co[row["Suburb"]]
else:
return row["CouncilArea"]
data["CouncilArea"] = data.apply(fill_council, axis=1)
data["CouncilArea"].isna().sum()모델링
- 모델링 전에 상관관계를 확인하여 집 가격에 영향을 많이 미치는 컬럼을 선택하여 학습
data.corr(numeric_only=True)["Price"].sort_values(ascending=False)
# 정답(집 가격)에 영향을 많이 미치는 컬럼들 선택
feature_names = ["Rooms", "Bedroom2", "Bathroom", "Car", "Distance", "Type", "CouncilArea", "Lattitude", "Longtitude"]
# 문제와 정답 분리
X = data[feature_names] # 인덱싱 대괄호 2개와 동일 효과
y = data["Price"]- 데이터 전처리: 문자 -> 수치형 (인코딩)
- One-hot encoding
- 문자 데이터 개수만큼 컬럼을 생성 -> 0 or 1로 변환하는 방법
- Label encoding
- 데이터 내에서 우선 순위를 주고 싶을 때 사용!
- 우선 순위? 숫자를 높게 줄 수록 영향을 미치고 싶을 때!
- 예: 연봉 예측 -> 직급: 사장, 과장, 대리, 사원 -> 사장에게 사원보다는 큰 숫자를 매칭 -> 예측에 작은 영향
- One-hot encoding
X["CouncilArea"].dtype
# 출력:
# dtype('O') → object라는 뜻
# X["CouncilArea"].unique() 확인 시 -> 넘파이 배열 형태로 저장 -> 확인 불가
# 데이터를 str 형태로 형변환
X["CouncilArea"] = X["CouncilArea"].astype(str)
X["CouncilArea"].unique()
# '[]' 없애줘야 함!
# [] 데이터가 있는 7개의 행 삭제 후 인코딩 진행 -> CouncilArea로 채워줘도 되지만 삭제 연습할 겸 지워보기
dd = X[X["CouncilArea"]=="[]"]
# [] 값이 들어 있는 인덱스를 통해 삭제 -> 문제, 정답 모두 삭제하기~
X.drop(dd.index, inplace=True)
y.drop(dd.index, inplace=True)
# 원핫 인코딩 -> pd.get_dummies()
X_one_hot = pd.get_dummies(X, dtype="int")- train, test 분리:
train_test_split()- stratify: 분류 문제에서 각 클래스의 비율을 훈련 및 테스트 세트에 균일하게 유지하려면 y 값을 설정하여 사용 -> 이번 문제는 회귀이므로 해당 파라미터 설정할 필요 없음
# 분리 도구 -> train_test_split()
# 랜덤 규칙 7 사용하기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_one_hot, y, test_size=0.3, random_state=7)
# 데이터 크기확인
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)선형 회귀 모델링
from sklearn.linear_model import LinearRegression
# 모델 객체 생성
linear_model = LinearRegression()
# 모델 학습
linear_model.fit(X_train, y_train)
# 모델 예측
y_pred = linear_model.predict(X_test)
y_pred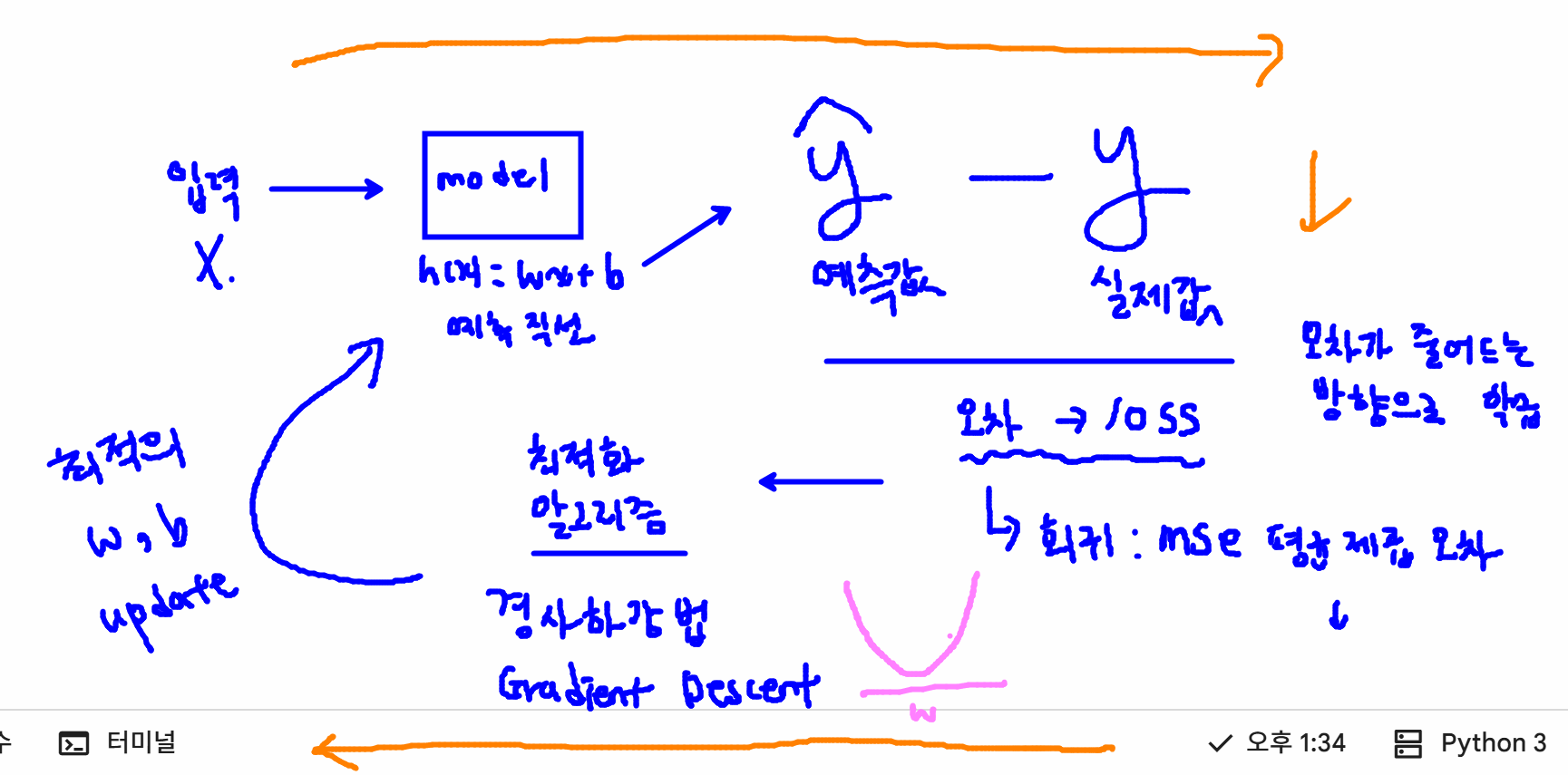
# 선형 모델의 원리: 데이터를 잘 대표하는 직선을 찾아나가는 과정
# y = wx + b (y = w1x1 + w2x2 + w3x3 + ... + wpxp + b)
# 모델의 가중치(w), y절편(b)
w = linear_model.coef_
b = linear_model.intercept_
print("가중치(w):", w)
print("y절편(b):", b)
print(len(w))
print(X_one_hot.shape)
→ p개의 가중치가 생김
>> [Out]
가중치(w): [ 1.59878350e+05 1.94650326e+04 1.76017553e+05 4.20028467e+04
-3.41832898e+04 -1.93532844e+06 -2.55260954e+05 2.89889911e+05
-4.44002459e+04 -2.45489665e+05 8.34855253e+03 3.87318781e+05
4.62733753e+05 -3.77694557e+05 -3.66776004e+04 -2.66944949e+05
7.41208976e+02 -2.31974862e+05 -1.39791963e+04 -2.51684700e+05
-2.60774899e+05 -7.62707974e+04 -1.49010867e+05 -1.25038573e+05
9.60451191e+05 1.30302856e+05 -2.88579328e+05 1.11700332e+05
-6.89389116e+03 -2.17451901e+05 6.37393748e+03 -5.12408279e+04
2.07753815e+05 -1.18329616e+05 4.07312711e+04 1.37533027e+05
2.82986271e+05 -4.07453626e-10 1.90005263e+05 -8.15858302e+02
-7.38655714e+05 3.45421553e+04 2.50495723e+05]
y절편(b): -35771502.19889437
43
(13573, 43)-
각 가중치를 해석하는 방법
- Rooms:방의 개수가 1개씩 증가할 때마다 주택 가격이 상승하는 것을 의미 (1.59878350e+05 → 159878.350)
- Distance: 거리가 멀어질수록 주택 가격은 감소하는 것을 의미
-
숫자가 클수록 주택 가격에 영향을 크게 미친다!
# 모델 평가
linear_model.score(X_test, y_test)
# 회귀는 어떻게 해석?
# 분류: score 결과값이 accuracy(정확도) -> O, X의 비율
# 회귀는 O, X로 낼 수가 없어요... 이 score는 mse가 아닙니다!
# 그럼 회귀의 score는 뭔가요 -> r2
from sklearn.metrics import r2_score
r2 = r2_score(y_test, y_pred)
print("linear_model의 r2:", r2)
print("linear_model의 score:", linear_model.score(X_test, y_test))linear_model의 r2: 0.6210579795833158
linear_model의 score: 0.6210579795833158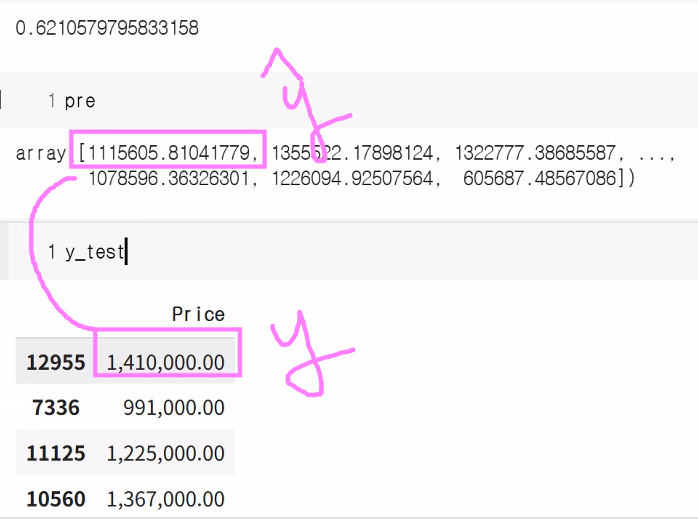
# 회귀 모델은 분류 모델처럼 맞았다/틀렸다를 O/X로 확인할 수가 없음
# 얼마나 틀렸니? 오차 정도를 평가 지표로 활용 -> MSE(mean_square_error)
# mse 구하기!
from sklearn.metrics import mean_squared_error
# mean_squared_error(실제값, 예측값)
mse = mean_squared_error(y_test, y_pred)
print("linear_model의 mse:", mse)
# 천오백억 달러의 오차? -> 평균"제곱"오차라 달러^2임 -> 따라서 루트를 씌워줘야 단위가 돌아옴!
# RMSE -> MSE에 루트를 씌운 값
rmse = np.sqrt(mse)
print("linear_model의 rmse:", rmse)
# 단위까지 제곱해버려서 평가 때 너무 불편해요...
# 그럼 처음부터 제곱 안 하고 구하면 되지!: mean_absolute_error -> 절댓값
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_test, y_pred)
print("linear_model의 mae:", mae)linear_model의 mse: 159095759804.25632
linear_model의 rmse: 398868.0982533654
linear_model의 mae: 260501.7287048834- 오차 기반은 평가가 애매함 → 기준이 없기 때문!
- 오차는 굉장히 상대적임
- 평가자가 평가할 때 당시 그 자리를 가서 아는 것 외에는 알 수 있는 방법이 없음(자리에 있어도 애매함)
- 3억 차이라고 하면:
- 집값이 100억인데 3억 차이면 예측 잘 한 것
- 집값이 10억인데 3억 차이면 예측 잘 못한 것
- 누가 봐도 이해할 수 있는 정규화된 평가 지표가 필요! → R²의 등장
- 오차는 굉장히 상대적임
회귀 모델의 평가 지표
- 분류: accuracy(정확도) 지표를 대표적으로 사용
- 정답 데이터가 범주형 -> 전체 데이터에서 맞은 데이터의 개수를 확률로 표현
- 0 ~ 1 사이의 숫자로 출력
- 1에 가까울수록 좋은 모델
- 회귀: 오차 기반의 평가지표를 사용한다.
- 오차가 크니? 작니?에 따라서 모델의 성능을 평가한다!
- mse(평균제곱오차, mean_squared_error)
- mse 지표는 학습과 평가 모두 사용된다!
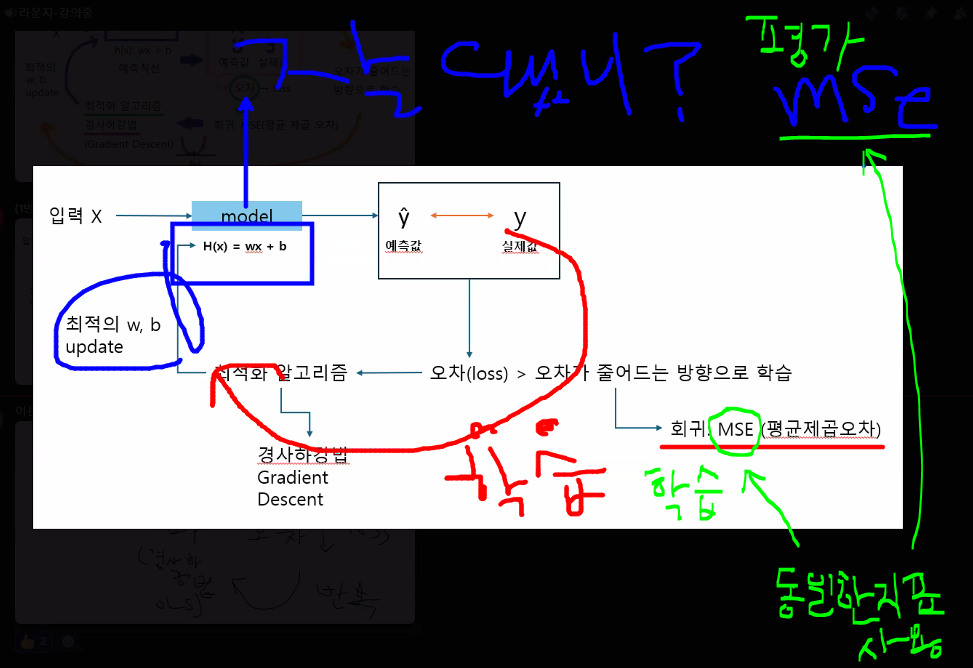
- 예측직선 업데이트 이후 평가에서 사용하는 mse와 학습 과정에서 오차가 줄어드는 방향으로 학습하기 위해 사용하는 mse의 사용 방향 자체가 완전 달라요! → 구분을 명확히 하는 이유: 그래야 분류에서 헷갈리지 않기 때문(분류는 평가지표와 학습지표가 서로 다름)
- 회귀분석의 평가지표는 정확도처럼 맞았다/틀렸다로 볼 수 없음 → 얼마나 틀렸는지에 대한 지표로 확인: "오차"
- 하지만 원래 우리가 보던 오차 mse는 단위까지 제곱하는 문제가 있음 & 오차를 극대화시켜 학습할 때는 좋았지만(학습할 때 loss는 극대화해 보는 게 유리함) 평가 시에는 제곱한 값은 평가가 어렵다! → 평가하는 과정에서 mae, rmse를 사용해서 대처 가능
회귀 → 오차 기반 학습 & 오차 기반 평가
- Q: R² 스코어도 과적합, 과소적합을 확인하는 지표로 많이 사용하나요?
- A: 아니요. 많이 사용하지 않습니다.
- 회귀 분석의 과대적합, 과소적합 확인 → 오차(loss)를 가지고!
- 학습마다 loss값을 출력할 수 있음 → accuracy와 달리 줄어들어야 학습이 잘 된 것
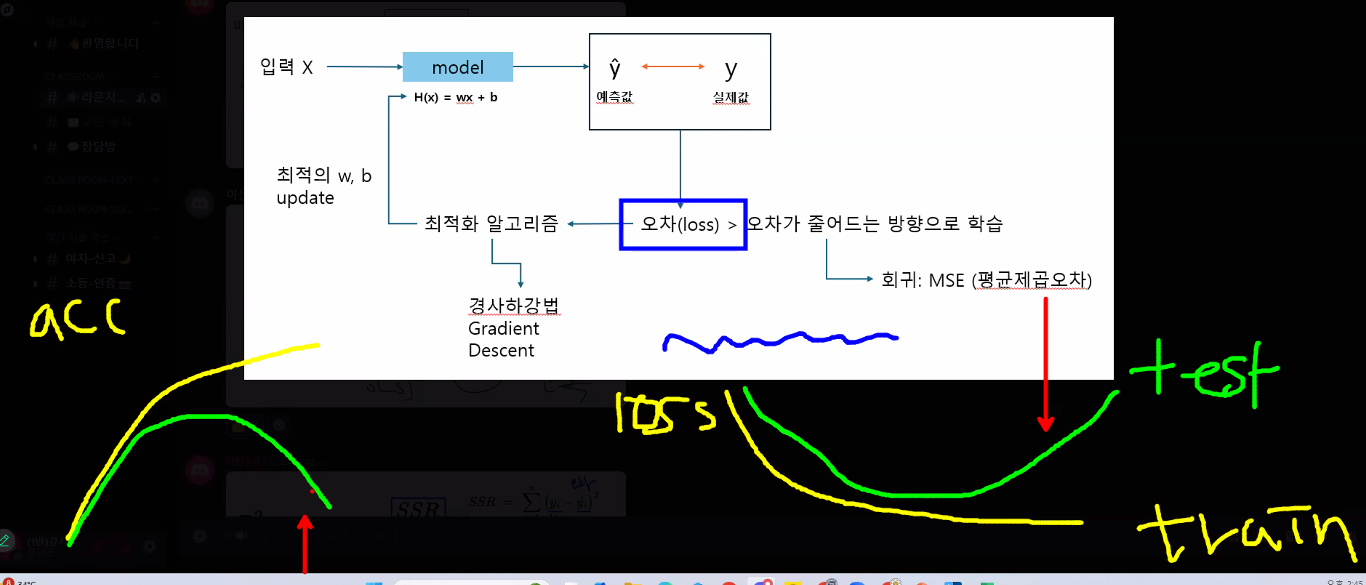
- 학습 과정에서 과대적합/과소적합 판별 가능 by 학습 과정에서 출력되는 loss
- 학습마다 loss값을 출력할 수 있음 → accuracy와 달리 줄어들어야 학습이 잘 된 것
- 회귀 분석의 과대적합, 과소적합 확인 → 오차(loss)를 가지고!
- R² 스코어는 오차를 확인하는 지표 중 하나 BUT 명확한 한계가 있음
- 결정계수(R²)는 회귀 모델의 평가 지표로서, 모델이 데이터를 얼마나 잘 설명하는지, 즉 예측값이 실제값의 분산을 얼마나 잘 설명하는지 나타냅니다.
- 값이 1에 가까울수록 모델의 설명력이 높고, 0에 가까울수록 설명력이 낮습니다.
- 결정계수(R²)는 독립변수의 개수가 증가할수록 값이 커지는 경향이 있기 때문에, 결정계수만으로 회귀 모델의 성능을 평가하는 데 한계가 있습니다. 이는 설명력이 거의 없는 독립변수를 추가하더라도 R² 값이 소폭이라도 증가하거나 최소한 감소하지 않기 때문입니다. 따라서, 불필요한 변수를 추가해도 모델의 설명력이 과대평가될 수 있습니다.
- 과적합(Overfitting)과 과소적합(Underfitting) 판별에 R² 스코어를 활용하는 방법:
- 과적합: 훈련 데이터의 R²는 높지만, 테스트 데이터의 R²가 현저히 낮은 경우 모델이 훈련 데이터에만 치우쳐 일반화가 잘 되지 않은 상태로 볼 수 있습니다.
- 과소적합: 훈련 데이터와 테스트 데이터 모두에서 R²가 낮은 경우, 모델이 데이터의 패턴을 제대로 학습하지 못한 상태로 해석할 수 있습니다.
- 실제로 R² 스코어는 MAE, MSE 등과 함께 모델의 적합도와 과적합/과소적합 여부를 확인하는 데 자주 사용됩니다. 특히, 훈련 데이터와 테스트 데이터의 R² 스코어 차이가 클 경우 과적합을 의심할 수 있습니다.
- 정리
- R² 스코어는 과적합, 과소적합 확인에 많이 사용되는 대표적인 지표입니다. 다만, R² 스코어만으로 모든 문제를 판단할 수는 없으므로(독립변수가 많아질수록 R²는 무조건 커짐), 다른 지표(MAE, MSE 등)와 함께 종합적으로 해석하는 것이 바람직합니다.
- 이러한 한계를 보완하기 위해 수정된 결정계수(Adjusted R²)를 사용
- 수정된 결정계수는 독립변수의 수와 표본 크기를 함께 고려하여 계산되며, 설명력이 없는 변수가 추가될 경우 오히려 값이 감소할 수 있습니다.
- 따라서, 다중회귀분석에서는 반드시 수정된 결정계수를 확인하는 것이 권장됩니다.
선형 회귀 모델의 평가 지표
- 오차(= 실제값과 예측값의 차이)를 이용한 평가지표: 오차 기반 평가 지표
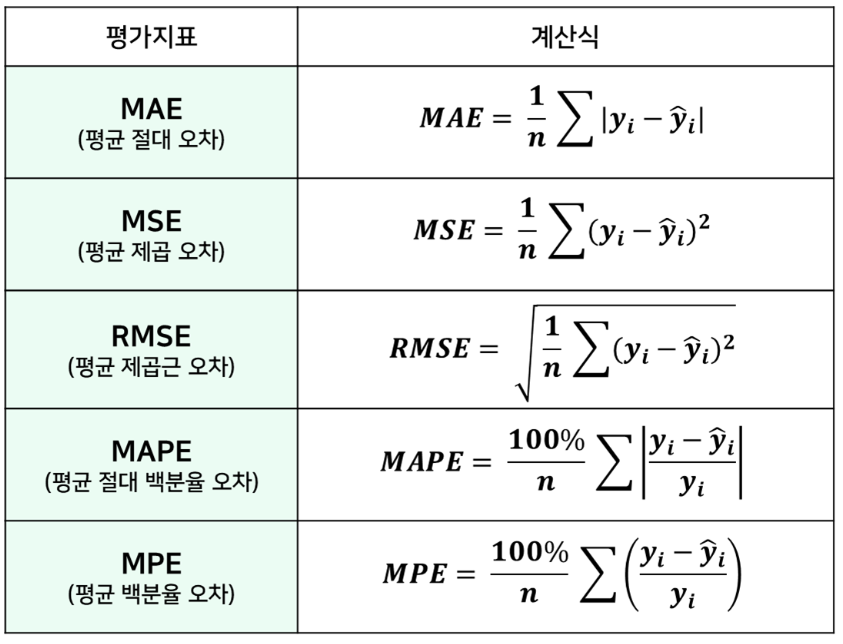
- MAE(Mean Absolute Error; 평균 절대 오차)
mean_absolute_error- 값이 작을수록 모델 성능이 좋음(지표가 작을수록 잘 예측)
- 오차를 절댓값으로 변환하여 평균을 구한 값 → MSE에 비해 오차에 덜 민감
- MSE(Mean Squared Error; 평균 제곱 오차)
mean_squared_error- 값이 작을수록 모델 성능이 좋음(지표가 작을수록 잘 예측하는 모델)
- 제곱을 취하기 때문에 특이값이 있는 경우 영향을 크게 받음(특이값에 민감한 지표)
- RMSE(Root Mean Squared Error; 평균 제곱근 오차)
- MSE에 루트를 씌워서 값을 축소시킨 지표
- 값이 작을수록 모델 성능이 좋음
- 해석 시 단위 문제를 해결하기 위해 MSE에 루트를 씌워 수치를 정상화
- MAPE(Mean Absolute Percentage Error; 평균 절대 백분율 오차): MAE를 비율(%)로 나타낸 지표. 백분율이므로 다른 모델과 비교하기 좋음. 0%에 가까울수록 모델 성능이 좋음
- MPE(Mean Percentage Error; 평균 백분율 오차): MAPE에서 절댓값을 제외한 지표. 0%에 가까울수록 모델 성능이 좋음
- MAE(Mean Absolute Error; 평균 절대 오차)
- R² score(결정계수) ★★★

- 오차와 평균값을 활용하여 정규화된 평가가 가능하도록 만든 평가 지표
- 해석
- 0~1 사이의 값을 주로 가지며
- 0에 가까울수록 평균적인 성능을 가지는 모델(좋은 편은 아님)
- 1에 가까울수록 좋은 성능을 가지는 모델
- 음수: 성능이 매우 좋지 않은 모델
- 회귀 모델은 오차 기반으로 평가 진행
- 정규화된 방법으로 평가할 수 있는 방법: R2 score (= R square, 결정계수)
- 오차는 판단하는 사람마다 다르게 느낄 수 있기 때문에 정규화된 방법으로 평가하는 편
R² score(결정계수)
- 회귀 모델이 데이터에 얼마나 적합한지 나타내는 지표
- 회귀 모델의 성능에 대한 평가지표
- 회귀 모델에서 독립 변수가 종속 변수를 얼마나 잘 설명해주는지 보여주는 지표
- 통계학에서 결정계수는 추정한 선형 모형이 주어진 자료에 적합한 정도를 재는 척도
- 반응 변수의 변동량 중 적용한 모형으로 설명 가능한 부분의 비율을 가리킴
- 값이 1에 가까울수록 모델 성능이 좋다고 평가
- 종속변수와 독립변수 사이에 상관관계가 높을수록 1에 가까워짐
- 따라서 결정계수가 0에 가까운 값을 가지는 회귀모형은 유용성이 낮고, 결정계수의 값이 1에 가까워질수록 회귀 모형의 유용성이 높아짐
- 하지만 독립변수의 개수가 증가하면 결정계수 또한 함께 증가하기 때문에 결정계수에만 의존하여 회귀 모델을 평가하기 어려움
- 그래서 조정된 결정계수(adjusted R-squared)가 제시됨
- 조정된 결정계수(adjusted R-squared): 독립변수의 개수가 2개 이상일 경우(→다중회귀분석 수행 시) 사용
- 조정된 결정계수(수정 결정계수)는 표본의 크기와 독립변수의 수를 고려하여 계산 → 독립변수가 2개 이상이면 수정결정계수를 본다
- 결정계수는 상향편의된 추정치이므로 표본 결정계수의 값은 항상 모집단의 결정계수보다 클 수 밖에 없음
- 따라서, 보다 정확한 추정치를 얻기 위해서는 수정결정계수를 사용해야 함
- 수정결정계수의 값은 결정계수보다는 작고 때에 따라서는 음의 값도 나타날 수 있음
- 표본의 크기가 200개 이상일 때는 두 결정계수의 차이가 미미함.
- 표본이 200개 미만일 때는 반드시 수정결정계수를 고려해야 함! & 반드시 표기해야 함
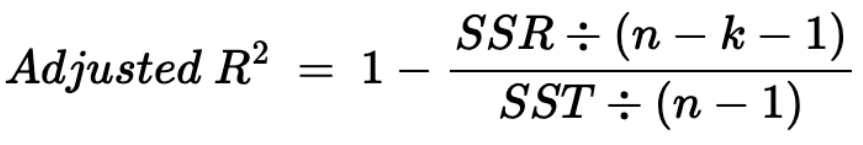
- 그래서 조정된 결정계수(adjusted R-squared)가 제시됨
- 공식 설명
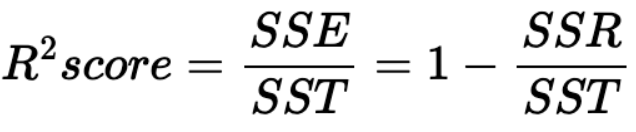
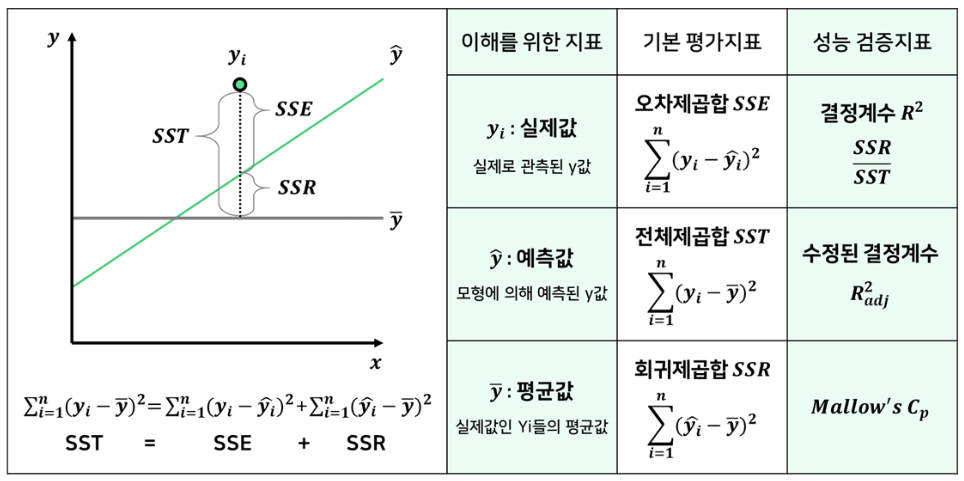
- SST: 총 제곱합
- SSE: 회귀 제곱합(회귀식 추정값과 관측값의 평균 간 차이)
- SSR: 잔차 제곱합
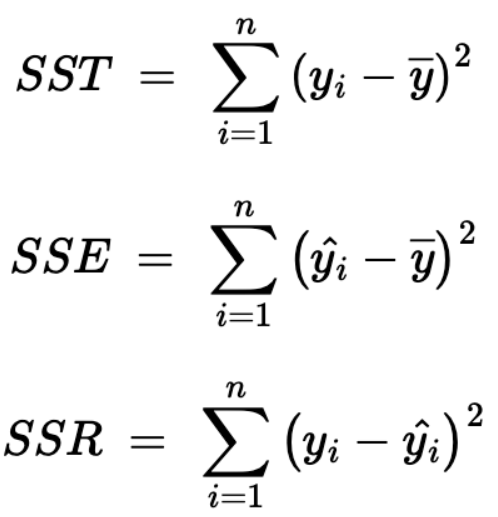
추가: 결정계수(coefficient of determination)와 상관계수(correlation coefficient)
- 결정계수: coefficient of determination, R² (회귀식, 회귀모델 설명력)
- 회귀 분석에서 사용
- 회귀분석에서 하나의 변수(독립변수)로 설명되는 종속변수의 분산(variance)의 정도 혹은 추정회귀식의 적합도를 의미
- 모형(즉 독립변수들)이 종속변수를 얼마나 설명하냐를 보여주는 계수 → 회귀직선의 적합도(goodness-of-fit)를 평가하거나 종속변수에 대한 설명변수들의 설명력을 알고자 할 때 사용
- 독립 변수가 종속 변수의 변동성을 얼마나 설명하는지 나타내는 지표
- 0: 독립 변수가 종속 변수의 변동성을 전혀 설명하지 못함
- 1: 독립 변수가 종속 변수의 모든 변동성을 설명함
- 독립변수와 종속변수의 인과성은 해석자가 판단해야 함
- 결정계수가 크다고 자동적으로 인과성이 크다고 말할 수는 없음
- 회귀모형이 잘 추정되었다고는 말할 수 있음
- 회귀 분석에서 사용
- 상관계수: correlation coefficient, r (양의 상관성, 음의 상관성, Pearson/Spearman 상관분석 결과)
- 두 변수 간의 선형 관계의 방향과 강도를 나타냄(두 변수간의 상관성을 나타내는 척도)
- 보통 영어로는 r로 나타내는데 전체모집단의 경우 ρ(혹은 대문자 R), 표본에 대한 것은 r로 나타냄
- 양의 상관관계/음의 상관관계/상관관계 없음
- 두 변수의 선형적인 관계, 변화의 관계강도를 나타낼뿐 인과관계를 말하지는 않음
- 즉 인과관계가 있던 없던 변화의 방향성과 연관의 강도만을 나타냄
- 우연히 발생하는 사건도 상관계수는 클 수 있음
- 상관계수 값이 0에 가까운 값을 가질지라도 두 변수 간에 비선형적인 관계가 있을 수 있다
- 가장 보편적인 상관계수는 피어슨 선형상관계수(Pearson linear correlation coefficient)
- 자료들이 정규분포하거나 혹은 자료의 수가 많을 경우 사용
- 선형회귀분석의 경우 피어슨상관계수 r은 이 결정계수(R²)의 R값과 같아 실수하는 경우가 많으니 주의 → 결정계수를 제시하고는 상관성이 크다니 상관계수가 크다니 하는 것은 엄밀히 말해 틀린 표현
- 자료의 수가 작거나 자료가 정규분포하지 않을 경우에는 비모수상관분석에 의한 스피어만랭크 상관계수(Spearman rank correlation coefficient)를 사용
- 상관계수를 나타낼 경우 상관계수값만 제공하는 것이 아니라 유의수준(significance level)도 함께 나타내야 그 값의 신뢰도를 평가할 수 있음
- 보통은 유의수준 p=0.05, 다시 말해 신뢰수준(confidence level) 95% 수준으로 평가 → 상관계수가 r이라고 할때 5%의 틀릴 가능성을 허용한다는 의미 (p값이 클수록 구한 상관계수에 대한 신뢰도는 감소)
- 측정값과 예측값의 산포도 위에 회귀식과 결정계수 R²를 제시했다면, 상관성이 크다고 하는 것보다는 결정계수가 크다(모델의 설명력이 XX%이다)고 기술하는 것이 적절합니다. 같은 자료에 대해서 상관계수 r 값을 제시했다면, 측정값과 예측값의 상관성이 크다고 할 수 있습니다.
- 두 변수 X, Y의 상관계수 r = 0.8 → 두 변수는 강한 양의 상관관계가 있음
- 회귀분석 결과 R² = 0.64 → 독립 변수들이 종속 변수의 변동성의 64%를 설명한다는 의미
- 정리
- 회귀분석은 독립변수를을 가지고 종속변수를 설명하는 게 목적
- 상관분석은 두 변수의 직선관계 정도를 보는 것 → 두 변수 중 어떤 변수가 종속변수(설명 당하는)이고 독립변수(설명하는)인지는 관심의 대상이 아님
경사하강법(Gradient Descent)
- 손실 함수(loss function)의 값을 최소화하기 위해 가중치(w)와 절편(b)을 반복적으로 업데이트하는 최적화 알고리즘
- 손실 함수의 기울기(=미분)를 따라 가장 빠르게 감소하는 방향으로 파라미터를 이동시켜 최솟값에 도달하게끔 하는 알고리즘
- 학습률(learning rate) -> 보폭
- 학습률이 너무 크면:
- 발산한다
- 비효율적인 학습
- 학습률이 너무 작으면:
- 수렴 속도나 너무 느림
- 정해진 epochs(반복 횟수) 내에 도달이 어려울 수 있음
- 학습률이 너무 크면:
# 경사하강법 그래프 작성을 위하여 간단한 성적 데이터 생성
# 공부 시간에 따른 성적
score = pd.DataFrame(
{"시간": [2, 4, 8, 9]
, "성적": [20, 40, 80, 90]}
, index = ["동인", "원희", "후상", "은지"]
)
# LinearRegression() -> 모델을 활용하여 성적 예측
# 모델 객체 생성
score_model = LinearRegression()
# 모델 학습 -> 문제 데이터는 항상 2차원!
# 문제: 시간(2차원), 정답: 성적(1차원)
X = score[['시간']]
y = score['성적']
lr_model.fit(X,y)
# 모델 예측 -> 7시간을 공부했을 때 점수를 예측
lr_model.predict([[7]])
# 가중치와 절편 출력
# y = 10x + 0
w = lr_model.coef_
b = lr_model.intercept_
print("가중치(w):", w)
print("절편(b):", b)- scikit-learn의 LinearRegression 모델은 기본적으로 정규방정식을 사용하여 회귀 계수를 추정
- LinearRegression 에서 어떤 방법을 통해서 해를 찾을 것인 지와 관련된 parameter는 solver
→ solver='gd' 로 설정하면, 경사하강법을 사용하여 회귀 계수를 추정할 수 있음
- LinearRegression 에서 어떤 방법을 통해서 해를 찾을 것인 지와 관련된 parameter는 solver
경사하강법 그래프 그려보기
- 가중치 변화에 따른 loss 변화 그래프
# 가설함수 h(x)
def h(w, x):
return w*x + 0
# 비용함수, 손실함수 (mse)
def loss (data, target, weight):
# 예측할 데이터의 X: data, 실제 답: target, 가중치: weight
y_pre = h(weight, data)
mse = np.mean((target - y_pre)**2)
return mse
# 예측한 가중치가 10이라면:
loss(score["시간"], score["성적"], 10) # np.float64(0.0)
# 예측한 가중치가 5라면:
loss(score["시간"], score["성적"], 5) # np.float64(1031.25)
# 예측한 가중치가 15라면:
loss(score["시간"], score["성적"], 15) # np.float64(1031.25)- w값 변화에 따른 mse 변화율 그래프 그리기
- x축: w
- y축: mse (loss)
# x축 범위
w_arr = range(-10, 30+1) # -10 ~ 30
# mse 값 저장
loss_list = []
for w in w_arr:
loss_list.append(loss(score["시간"], score["성적"], w))
# 그래프
plt.subplots()
sns.lineplot(x = w_arr, y = loss_list)
plt.show()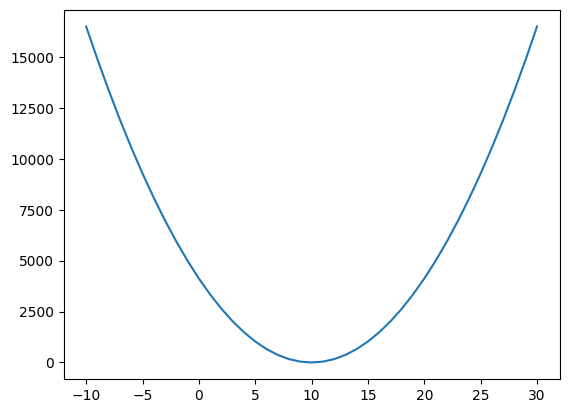
Career Up
회고
- 回 돌아올 회 顧 돌아볼 고
- 지나간 일을 돌이켜 생각함
- Retrospective(latin. Retro(뒤)+Spectare(본다))
- 과거의 경험에서 학습하고 다음을 위한 변화를 계획한다
- A ritual held at the end of a project to learn from the experience and to plan changes for the next effort.
- 회고의 중요성
- 학습을 할 때 문제점을 기억하기 위해 회고(돌아보는 과정) 필수
- 학습에 있어 '회고'가 가장 중요합니다!
- 과거의 경험 → 문제점 인식 → 개선
- 경험을 통해 문제점을 발견하는 가장 효과적인 프로세스
- YTN 뉴스 '복기하고 복기하라'
- 2016년 이세돌 vs. 알파고 경기
- 끝없는 복기로 알파고 약점 파악
- 복기(復棋): 대국이 끝난 후 서로의 수를 처응부터 두어보며 승패의 원인을 분석하는 것 → 승자와 패자가 서로를 통해 배움
- 바둑 격언 by 이창호 9단
"승리한 대국의 복기는 이기는 습관을 만들어주고 패배한 대국의 복기는 이기는 준비를 만들어준다."
→ 복기를 통해 성찰하는 바둑의 전통
- 2016년 이세돌 vs. 알파고 경기
TIL(Today I Learned)
- 오늘 하루 무엇을 배우셨나요?
- 본인이 오늘 하루 배운 것 혹은 경험하고 느낀 것들을 기록하고 회고하는 것
-
작성 이유
- 성실성을 보여주기 위해: 잘 키운 블로그 하나가 자격증 10개보다 낫다
- 학습한 것을 회고하기 위해: 학습기록을 통해 문제와 해결방법을 내 것으로 만들기
- 관심의 표현: 어떠한 것을 공부하고, 관심 있어 하는지 알리기
-
포트폴리오 4가지 관점
- Skill(기술적인 부분)
- Project(기술 활용)
- Awards(대회 참여)
- Community
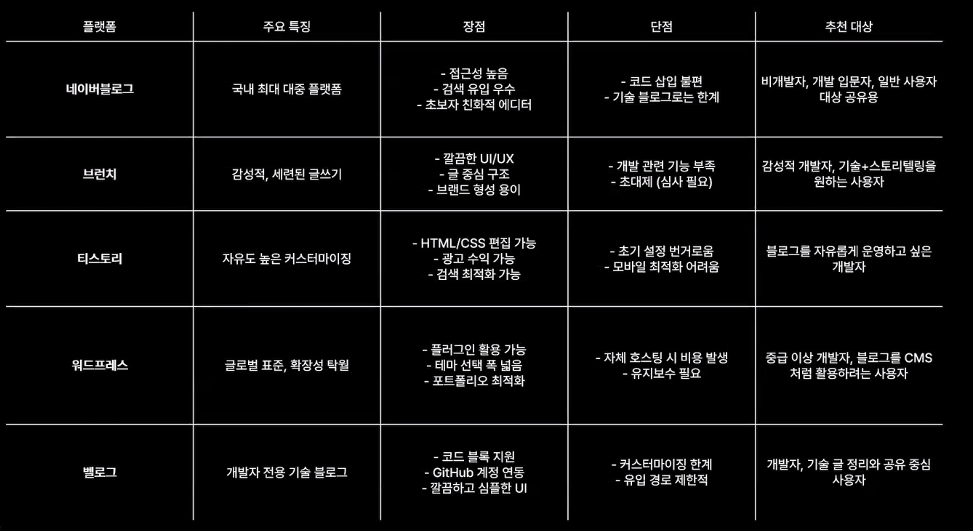
TIL 작성용 블로그 추천
- 네이버 블로그
- 가장 친화적인 Naver
- 누구나 네이버 아이디는 하나씩 있음
- 검색 노출도 잘 됨
- 작성 방법 찾기도 편함
- 가장 친화적인 Naver
- 브런치
- 감성적, 깔끔
- 기획, 마케팅 쪽을 생각하는 분들이 접근하시면 좋을 듯
- 작가 인증을 받아야 해서 조금 불편할수도
- 티스토리
- 높은 자유도
- 구글 노출이 높음
- 개발 쪽 사람들이 많이 씀
- 폐쇄된다는 소문이 있음
- 워드프레스
- 글로벌 표준
- 한국 사람들에게는 조금 생소할수도
학습 어떻게 하시나요?
- 학습 방법 1: 강사 강의 → 메모 → 복습 → 메모 보기
- 내가 배운 내용을 시간 순서로 정리하며 메모
- 학습 메모란 정답지? 복기?
- 어떤 식으로 활용할지 정해야
- 학습 방법 2: 효과적인 학습법
- 한 메모지 안에 하나의 주제만 적기
- 학습 메모 == 복기 재료!
- 내가 배운 내용 중심(시간 순서) → 내가 겪는 문제 중심으로 재조립
- 사건 순서
- 문제
- 시도
- 해결
- 느낀점
| 강사 강의 | ||||
|---|---|---|---|---|
| 메모 | 기능 | 조합 | 정리 | 회고 |
| 주제 | ||||
| 코드 |
- 가장 중요한 것은 '학습 결과'입니다:
- 김익한 교수: 오히려 뇌를 망가뜨리는 메모
- 현재 메모를 한다는 행위를 통해 지금 해당 내용을 각인한다는 목적성을 두고 메모 or 기록하기 → 키워드 위주로
- 나중에 봐야지 X, 지금 당장 기억하기 위해 O
- 김익한 교수: 오히려 뇌를 망가뜨리는 메모
- TIL 작성 주의사항 3가지
- 누구나 봐도 이해될 수 있도록 → 남들과 공유하는 기록 남기기 (남이 보든 내가 보든 알아볼 수 있는 기록)
- 꾸미기보다는 내용에 집중
- 학습에 관련된 내용만 작성
이력서를 어디에 어떻게 작성할 것인가?
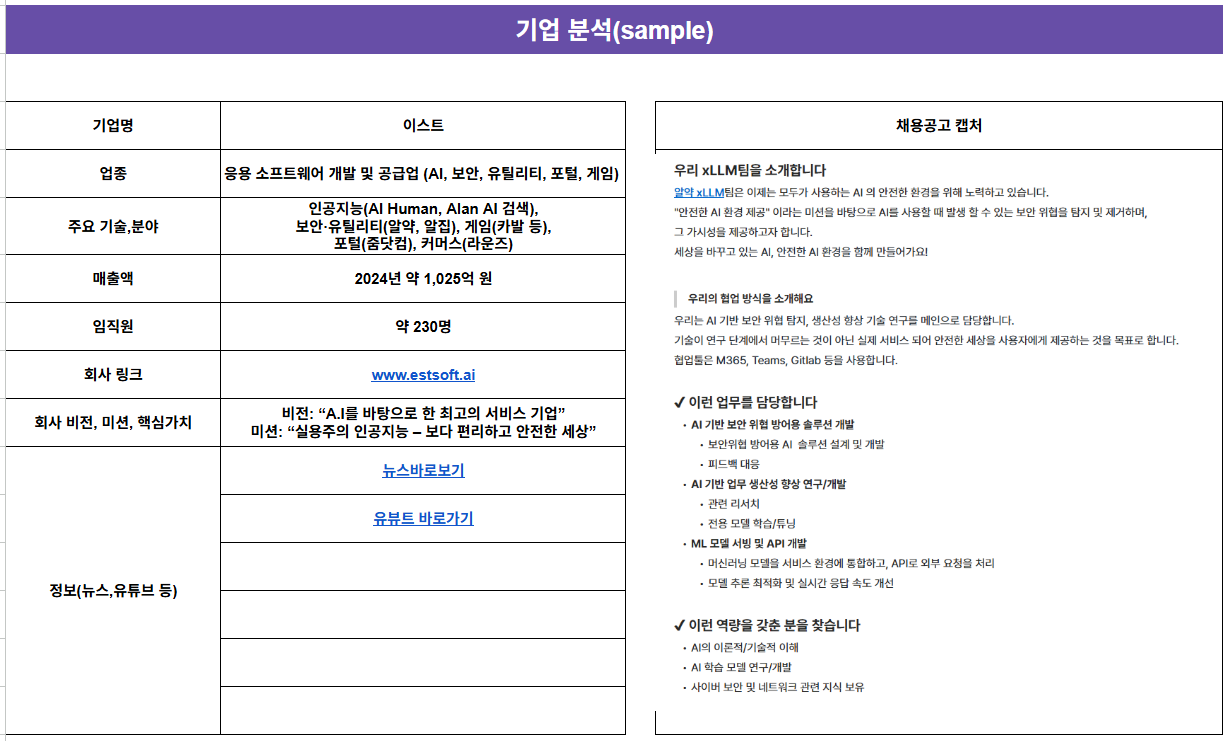
- 먼저 내가 가고자 하는 기업에 대해 분석해봅시다:
하루 돌아보기
👍 잘한 점
- 회귀분석 및 결정계수에 대해 더 알고 싶은 점을 추가로 공부함
- 야간자율학습 진행
👎 아쉬웠던 점
- 커리어업 시간에 '가고 싶은 회사' 이야기가 나왔는데 회사까지는 생각해 본 적이 없어 당황스러웠음
- 어떤 회사가 있는지부터 찾아보는 중이라 목요일까지 과제를 할 수 있을지 잘 모르겠음
🔬 개선점
- 취업 관련한 부분 미리미리 조사하기

2 B R 0 2 B