코딩테스트 연습
알고리즘
(작성할 내용 정리 중)
SQL
(작성할 내용 정리 중)
지난 시간 복습
각자 수립한 가설 확인해보기
- 미혼 인구의 외근별 이직률
- "차이"가 어떤지를 확인
- 워라밸과 결혼 여부
- 회사 내 기혼자 지원 정책
- 결혼 장려 문화
- 부서별 직무 레벨
- 직무 레벨이 낮은 사람의 이직률이 높음
- Sales 부서의 이직률이 높음
- 오래 근무 == 직무 레벨 높음 & 오래 근무한 사람은 이직 잘 안함
- 추가로 직무 레벨과 근속년수 비교하면 더 좋을 듯
- 근속년수와 승진에 걸린 기간에 따른 이직률
- 두 컬럼을 그룹화하여 이직률 비교
- 승진 적정 시기를 알아본 것
- 승진 적정 시기는 1~3년 이내, 6년 이상
- 두 컬럼을 그룹화하여 이직률 비교
- 경력연수/근속연수 관련
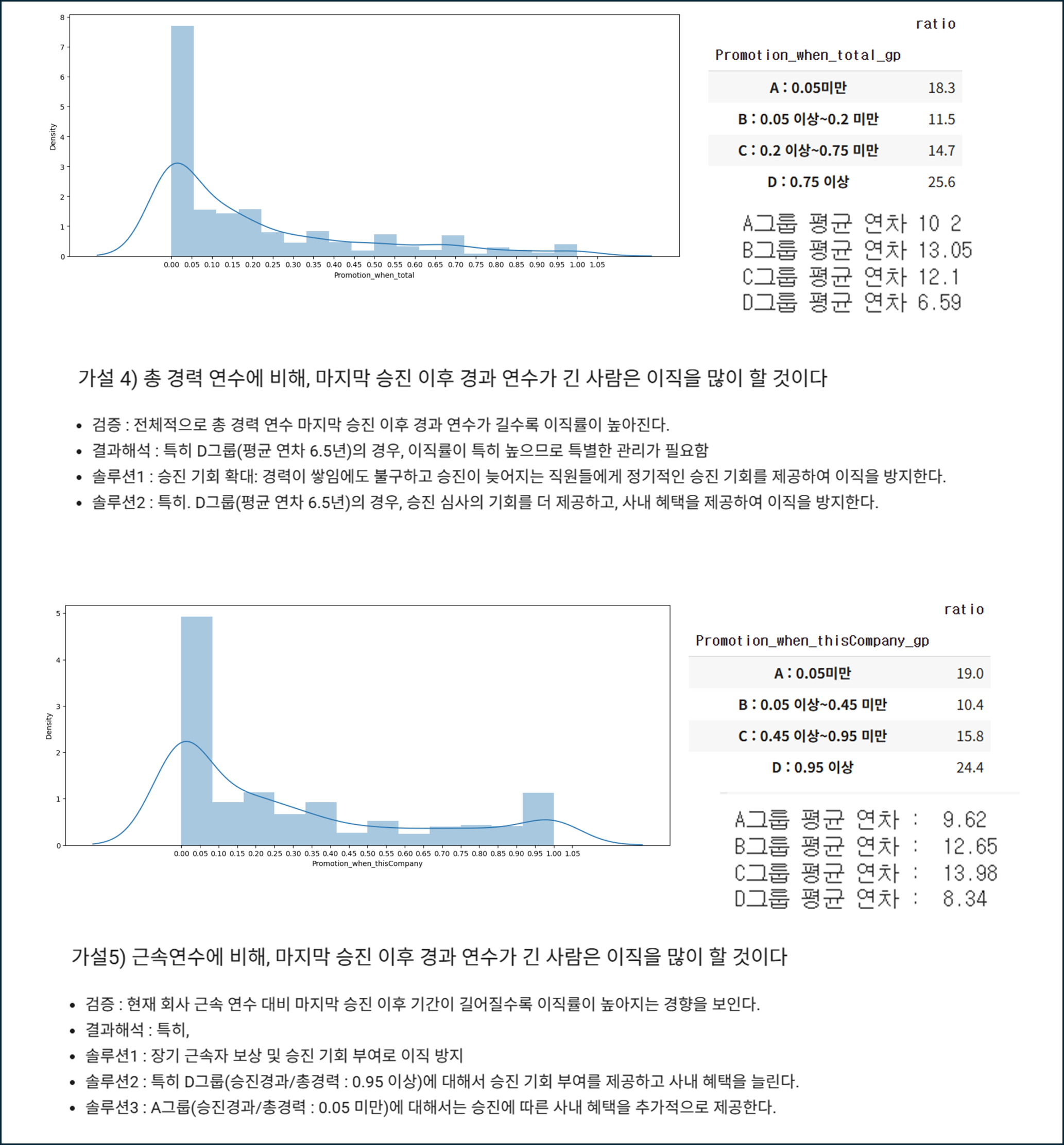
- 총 경력이 좀 더 영향 있지만 전체적으로 경향성이 유사
- 교육 기회 제공
- 적절한 교육은 이직 방지에 효과 있음
- 교육 기회를 제공하지 않는 건 리스크
- 너무 적거나 많은 고육은 이직률을 높일 수 있음
- 고학력자는 교육에 더 민감하게 반응
- 적절한 교육은 이직 방지에 효과 있음
- 회사를 많이 옮긴 횟수와 업무 환경
- 이직을 많이 해본 사람들이 이직을 더 많이 함
- 이직은 용기가 필요하니까
- 이직을 많이 해본 사람들이 이직을 더 많이 함
- 스톡옵션과 업무성과
- 업무 성과가 높은(3, 4) 사람에게만 스톡옵션 제공됨
- 너무 높으면 오히려 효과가 줄어드니 적절한 스톡옵션이 필요
- 없으면 이직률이 높음
- 많아도 조금 높음
- 전공 분야와 부서가 관계가 없다면 이직률이 높을 것
- 부서 배치 시 전공 분야를 고려
- 급여와 경험이 낮은 미혼자는 높은 이직률을 보일까? 그렇다면 자신의 직무와 환경에 대한 만족도가 해당 영향을 감소시킬 수 있을까?
- 미혼자의 이직률이 높음 -> 미혼자 근속년수와 월급여에 따른 이직률 확인
모델링: 선형분류모델
- 데이터 분리
- 데이터 타입별로 분리
- 데이터 타입에 따른 인코딩
- 레이블 인코딩 사용
- train, test 나누기
- 모델 선택, 학습, 평가
- 평가 해석 -> 분류평가지표
인코딩
- 원핫 인코딩(0, 1)
- 레이블(label) 인코딩
- 값의 크고 작음에 의미가 약간 있을 때 사용하는 인코딩
- 여기서 '약간'은 인코딩한 숫자의 크기가 학습 전체에 영향을 엄청 많이 주는 건 아니라는 의미임 (dominant하지는 않음)
- 우선 순위가 있는 데이터를 수치화할 때 주로 많이 사용
- 우선 순위가 높을수록(영향을 많이 미칠수록) 큰 숫자 부여
- 예: 급여는 직책이 높으면 높음 → 직책이 높은 사람에게 높은 숫자 부여하기
- 숫자값의 크고 작음에 대한 특성이 작용: 머신러닝 모델에서 가중치가 더 부여되거나 더 중요하게 인식할 가능성이 발생
- 랭크된 숫자 정보가 모델에 잘못 반영될 수 있다.
- 값의 크고 작음에 의미가 약간 있을 때 사용하는 인코딩
- 빈도수 인코딩(frequency incoding)
- 범주형 변수를 인코딩할 때, 빈도수 많은 범주에 가중치를 두어 인코딩하는 방식
- 범주가 데이터에서 나타나는 횟수를 기반으로 인코딩: CountFrequencyEncoder()를 불러올 때 전달인자에 encoding_method= 'count'를 집어넣어 변수의 범주별 개수를 학습하고 적용
- 범주가 전체에서 차지하는 비율을 기반으로 인코딩: CountFrequencyEncoder()를 불러올 때 전달인자에 encoding_method= 'frequency'를 집어넣어 변수의 범주별 빈도를 학습하고 적용
- 범주형 변수를 인코딩할 때, 빈도수 많은 범주에 가중치를 두어 인코딩하는 방식
- 예: 집값 예측 실습의 CouncilArea 컬럼
- Gender는 m/f라 원핫 인코딩도 괜찮지만 class가 여러 개인 컬럼의 경우 차원이 너무 커지면서 데이터 분석에 영향을 줄 수 있음 (분석에 어려움이 생길 수 있다. → 비효율적일 수 있음)
for i in df.columns:
print(df[i].dtype, df[i].dtype == 'O') # 대문자 O, object 컬럼은 True로 출력됨
# numerical data(수치형 데이터), object data를 각각 다른 리스트에 담아주기
numeric_list = []
categorical_list = []
for i in df.columns:
if df[i].dtype == 'O':
categorical_list.append(i)
else:
numeric_list.append(i)
print("categorical_list:", categorical_list)
print("numeric_list:", numeric_list)
# 인코딩을 위해 데이터 분리
df[categorical_list]레이블 인덱싱
# 가설 검증 과정에서 만든 컬럼 삭제: Age_gp, Role_Company, Role_Company_gp
# 문제 데이터와 정답 데이터로 분리
X = df.drop(["Age_gp", "Role_Company", "Role_Company_gp", "Attrition"], axis=1)
y = df["Attrition"]
# 레이블 인코딩: 값의 크고 작음에 의미가 약간 있을 때 사용하는 인코딩
# BusinessTravel: 출장이 많을수록 이직률이 높은 것을 앞서 확인했음
# Travel_Frequently > Travel_Rarely > Non-Travel 순으로 이직률 영향을 많이 끼침
# 앞으로 갈수록 이직률에 영향을 크게 미친다.
# 딕셔너리로 정의: 우선순위가 높은 데이터에게 큰 숫자를 매핑
BT_dict = {
"Non-Travel": 0,
"Travel_Rarely": 1,
"Travel_Frequently": 2
}
# 매핑
# 특정 대상에게 딕셔너리의 key값에 따라 value로 변경해주는 함수 -> .map()
X["BusinessTravel"] = X["BusinessTravel"].map(BT_dict)
# 나머지 데이터는 원핫 인코딩으로 진행
X_one_hot = pd.get_dummies(X)추가: 순서가 없는 데이터 매핑
- 위에서 살펴본 BusinessTravel은 특성이 크기별로 순서가 있었기 때문에 직접 순서를 딕셔너리로 정의 후 매핑
- 매핑된 걸 다시 되돌리고 싶다면 아래와 같이 처리:
inv_mapping = {v: k for k, v in BT_dict.items()}
df["BusinessTravel"].map(inv_mapping)- 만약 순서가 없는 데이터라면 enumerate나 판다스 factorize(), 또는 sklearn에서 제공하는 LabelEncoder 사용
- enumerate: enumerate에 넣는 리스트의 순서가 인코딩되는 정수 값의 순서를 결정
- np.unique()가 사전식 순서(lexicographical order)로 정렬 → 0부터 숫자 매칭
- 순서가 있는 데이터에서도 사용 가능(원하는 순서대로 리스트를 만들어 넣으면 됨)
- factorize: 출현 순서대로 0부터 부여
- LabelEncoder: 원본 데이터의 값에 사전순으로 번호를 매김
- enumerate: enumerate에 넣는 리스트의 순서가 인코딩되는 정수 값의 순서를 결정
# enumerate()
import numpy as np
class_mapping = {label:idx for idx,label in enumerate(np.unique(df['classlabel']))}
df['classlabel'] = df['classlabel'].map(class_mapping)
# factorize
import pandas as pd
data = ['B', 'A', 'A', 'C', 'B', 'A']
encoded_values, categories = pd.factorize(data)
print("인코딩된 값:", encoded_values) # 출력: [0 1 1 2 0 1]
print("고유 범주:", categories) # 출력: ['B' 'A' 'C']
# LabelEncoder()
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
y=class_le.fit_transform(df['classlabel'].values)데이터 분리
# 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_one_hot, y, test_size=0.3, stratify=y, random_state=9)
# 데이터 크기 확인
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)모델 선택, 학습, 평가
로지스틱회귀
from sklearn.linear_model import LogisticRegression
# 회귀라는 단어가 있지만 분류 모델이다!
# 모델 객체 생성
lr_model = LogisticRegression()
# 모델 학습
lr_model.fit(X_train, y_train)
# 모델 평가
lr_model.score(X_test, y_test) # accuracy 정확도 확인~
# 로지스틱 모델도 linear 모델이고 거리 계산 기반이라 스케일링을 하면 정확도가 좀 더 올라감SVM
from sklearn.svm import LinearSVC
svm_model = LinearSVC()
svm_model.fit(X_train, y_train)
svm_model.score(X_test, y_test)
분류 결과의 불확실성 및 분류 결과에 대한 평가지표를 확인해보자
분류 예측의 불확실성 추정
- 불확실성을 추정한다 == 예측한 클래스가 무엇인지 뿐만 아니라 정확한 클래스임을 얼마나 확신하는지를 나타내는 것
- 어떤 테스트 포인트에 대해 분류기가 예측한 클래스가 무엇인지 뿐만아니라 정확한 클래스임을 얼마나 확신하는지가 중요
- 거짓 양성false positive 예측은 환자에게 추가 진료를 요구하겠지만 거짓 음성false negative 예측은 심각한 질병을 치료하지 못하게 만들 수 있음
- scikit-learn 분류기에서 불확실성을 추정할 수 있는 함수
- decision_function
- 데이터가 양성인 클래스 1에 속한다고 믿는 정도(확률)를 반환
- 이진 분류에서 decision_function 반환값의 크기는 (n_samples,)이며 각 샘플이 하나의 실수 값을 반환
- 기준: 0 (0 이상이면 양성, 0 이하면 음성으로 판별)
- predict_proba
- 이진 분류에서 predict_proba의 크기는 (sample 수, 2)
- 하나의 데이터에 대해 음성일 확률, 양성일 확률이 구해지고 그 둘의 합은 1
- 각 열에 데이터에 대한 음성일 확률, 양성일 확률이 들어있음
- 기준 : 0.5 (0.5 이상은 양성, 0.5 이하는 음성)
- decision_function
평가지표
- 회귀에서 가장 많이 사용하는 평가지표: 오차
- 오차 기반 평가지표
- MSE: 가장 많이 사용함
- RMSE: 루트를 씌워 MSE의 단위 문제 해결
- MAE: 절댓값 사용
- 단점: 정규화된 지표가 없다는 문제 →
- Score
- 정규화 문제 해결
- 오차 기반 평가지표
- 분류에서 사용되는 평가지표는 accuracy (정확도) 말고 뭐가 있을까?
- accuracy(정확도) → 맞춘 비율
- 비율 0~1
- 비율 0~1
- accuracy(정확도) → 맞춘 비율
분류평가지표
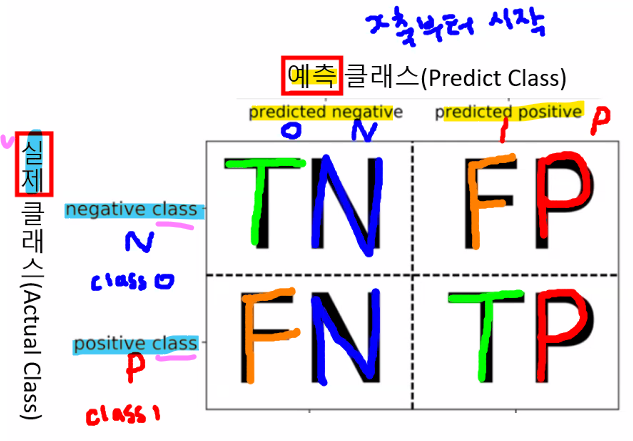
Confusion Matrix(혼동행렬)
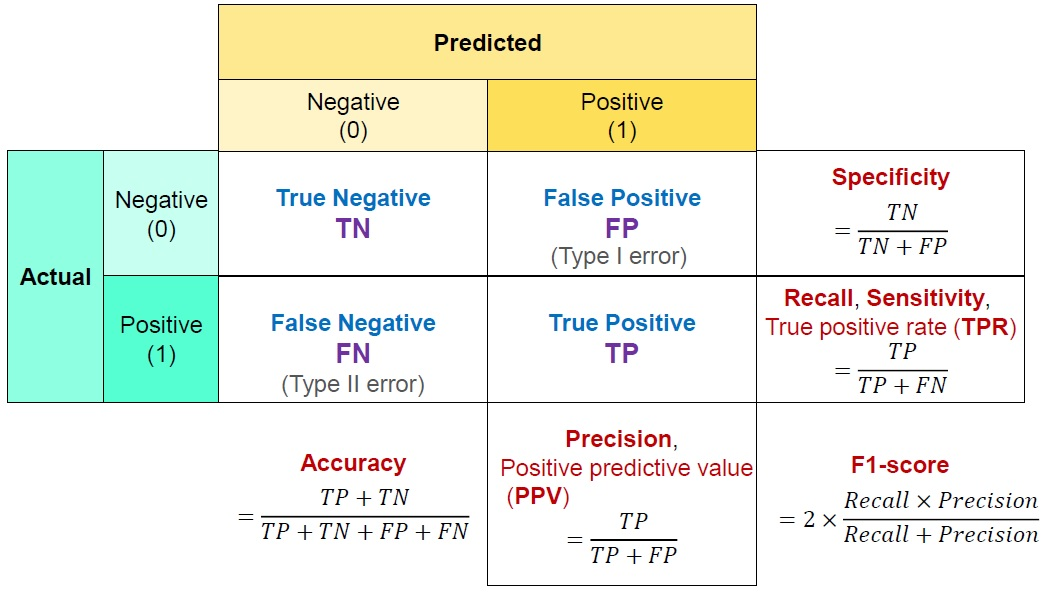
- True Negative(TN)
- 실제 음성인 정답을 잘 예측 → 정답
- False Positive(FP)
- 실제 음성인 정답을 잘 못 예측 → 오답
- False Negative(FN)
- 실제 양성인 정답을 잘 못 예측 → 오답
- True Positive(TN)
- 실제 양성인 정답을 잘 예측 → 정답
- 정확도(Accuracy)
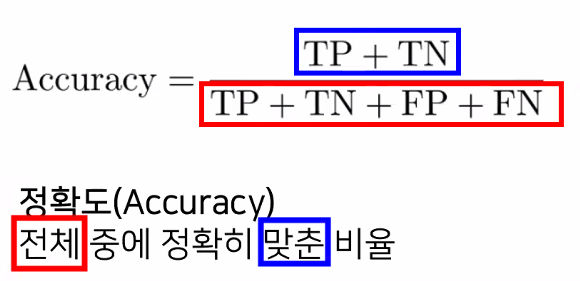
- 전체 중에 정확히 맞춘 비율
- 불균형한 데이터가 들어있을 경우 정확도로 성능을 평가하는 것은 문제가 됨
- 예:
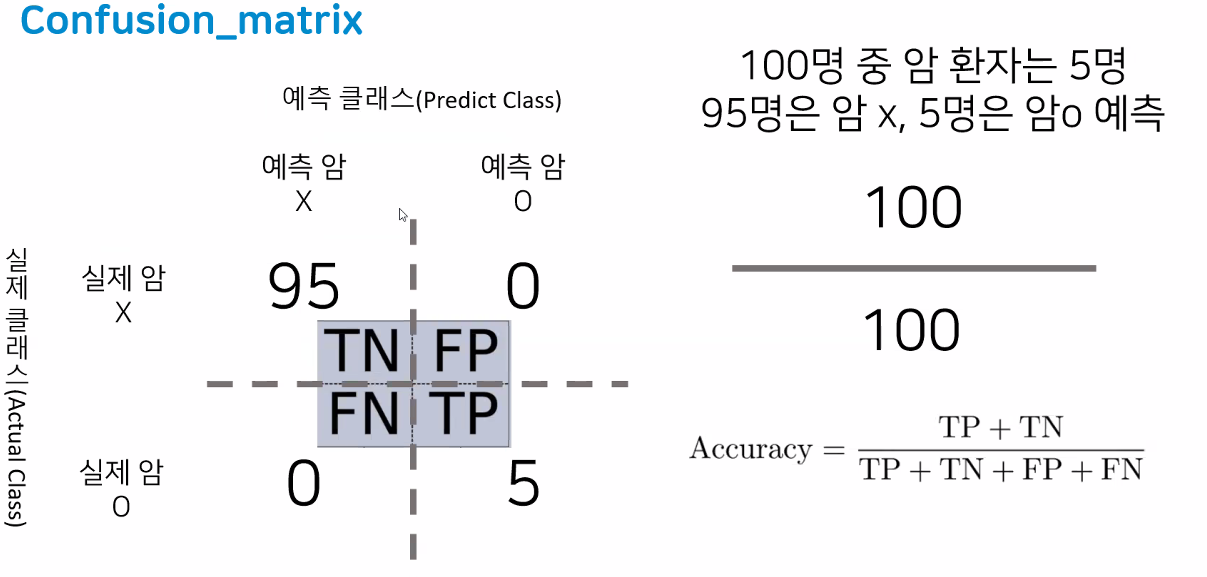

→ 모델도 학습하기 쉬운 방향으로 학습하려는 경향성이 있음: 전체 사람 중에서 암인 사람은 사실 극소수라 전부 암이 아니라고 판단하면 편하고 정확도도 높은 수치가 나오니까 모델이 그냥 전부 다 암이 아니라고 학습해버릴 수 있음
→ TN/FP/FN/TP가 85/10/5/5 인 경우 앞선 모델보다 실제 암인 사람을 잘 고르지만 정확도는 0.90
→ 이 모델은 정확도가 0.95지만 믿을 수 없는 모델: 정확도가 높다고 모델을 무조건 사용해서는 안 된다! 그럼 어떻게 판단하지?
→ "재현율"의 등장
- 예:
- 재현율(Recall)
- 실제 양성 중에 예측 양성 비율
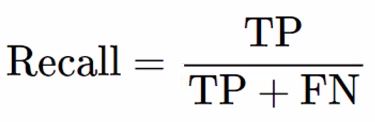
- 예:
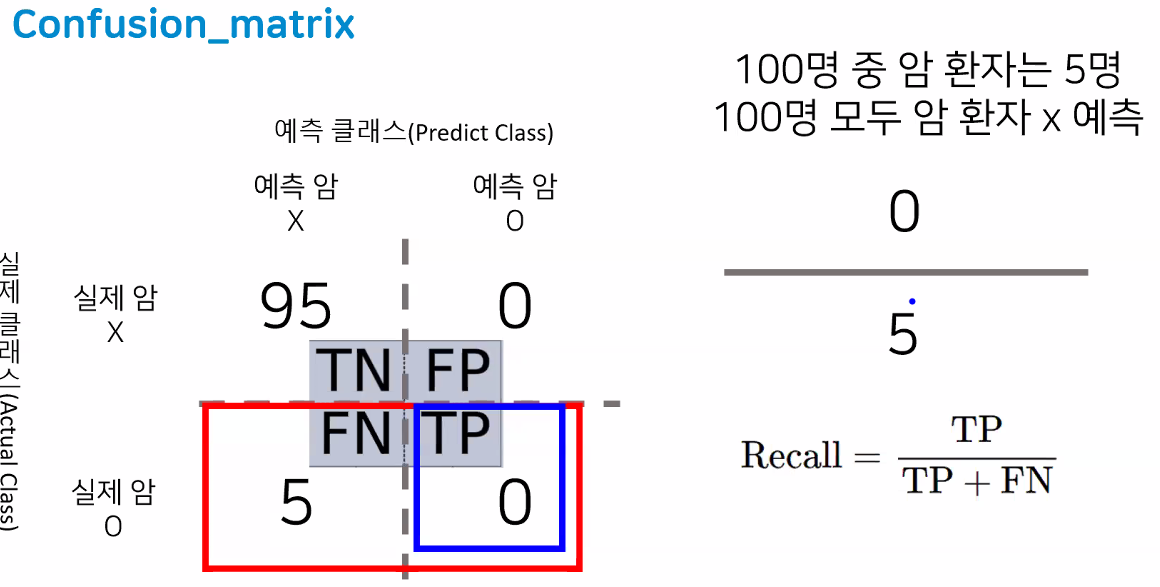
- 재현율이 0 == 실제 데이터 중에서 맞춘 게 하나도 없다는 뜻
- 실제 양성 중에 예측 양성 비율
- 하지만 재현율만 보는 것도 한계가 존재
- 예:
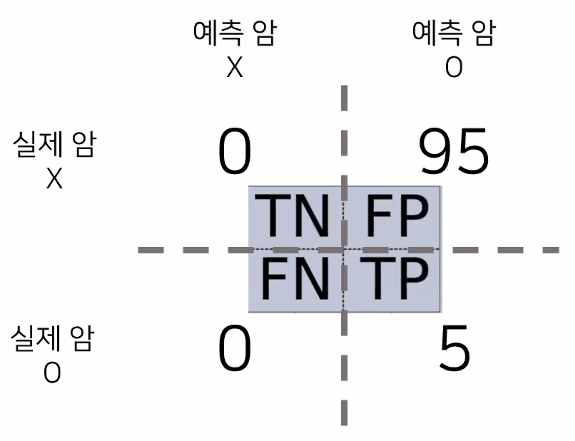
- 재현율 5/5 = 1지만 사실 이것도 좋은 모델이 아님(모두 암이라고 판단하는 모델 → 95명이나 잘못 예측한 거니까)
→ "정밀도"의 등장
- 재현율 5/5 = 1지만 사실 이것도 좋은 모델이 아님(모두 암이라고 판단하는 모델 → 95명이나 잘못 예측한 거니까)
- 예:
- 정밀도(Precision)
- 예측 양성 중에 실제 양성 비율
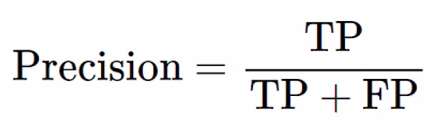
- 예:
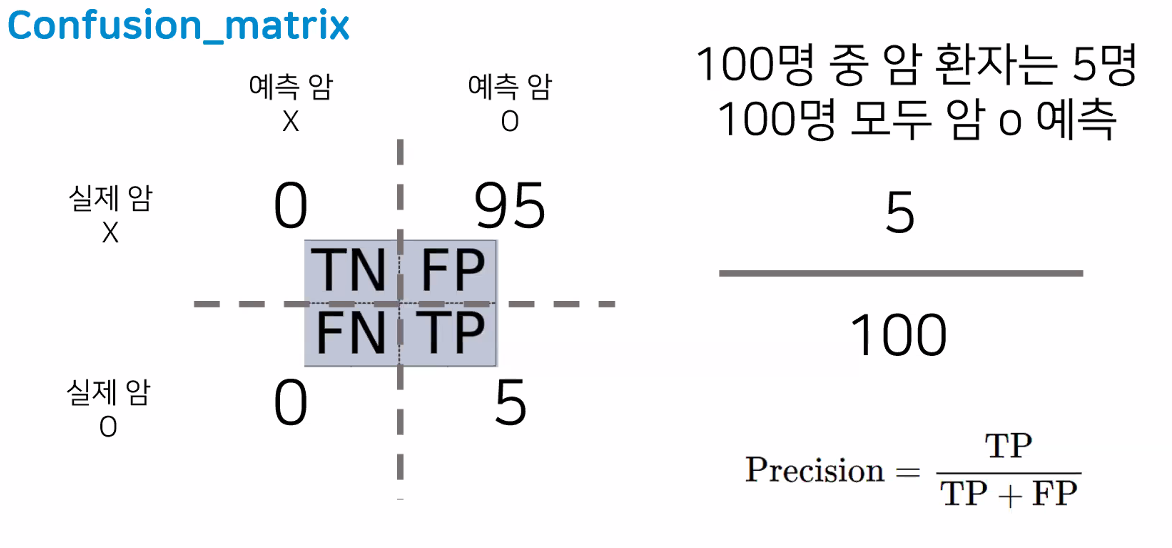
- 앞서 재현율 1이었던 모델의 정밀도 5/100=0.05
- 예측 양성 중에 실제 양성 비율
- 지표를 볼 때 하나만 보면 안 됨!
- 정확도, 재현율, 정밀도 모두 확인해야 함
- 정확도를 기반으로 하되 재현율과 정밀도가 모두 조화롭게 높은 모델을 선택해야 함 → "F1-score"의 등장
- 하지만 완전히 두 개가 다 높을 수는 없음 → 상황에 따라 재현율, 정밀도 상대적 중요도 달라짐
- 정확도, 재현율, 정밀도 모두 확인해야 함
- F1-score
- 정밀도와 재현율의 조화평균

- 예시
- 모델 A: r=0.1, p=0.9 → 0.018
- 모델 B: r=0.7, p=0.7 → 0.7
- 정밀도와 재현율의 조화평균
- 상황에 따른 재현율과 정밀도의 상대적인 중요도
- Recall(재현율: 예측 양성÷실제 양성)을 선호하는 경우
- 실제 positive(양성)인 데이터 예측을 Negative(음성)로 잘못 판단하게 되면 업무상 큰 영향을 줄 때
- 암 진단: 암 양성(1)
- 금융사기 판별
- 도둑 판별
- Precision(정밀도:실제 양성÷예측 양성)를 선호하는 경우
- 실제 Negative(음성)인 데이터 예측을 Positive(양성)으로 잘못 판단하게 되면 업무상 큰 영향을 줄 때
- 스팸 메일: 스팸(1) 정상(0)
- 어린아이 제공 영상: 안전 영상(1) 비안전 영상(0)
- Recall(재현율: 예측 양성÷실제 양성)을 선호하는 경우
이진 분류에서 보통 중요한 쪽에 1을 부여 → 예: 암 양성(1), 암 음성(0)
y_pred = lr_model.predict(X_test)
# 예측값과 실제값을 넣어 confusuion matrix 확인
from sklearn.metrics import classification_report
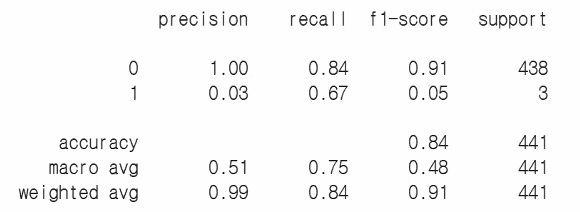
print(classification_report(y_test, y_pred))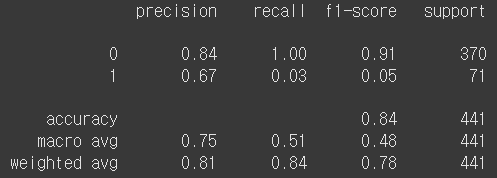
→ support: 데이터의 개수(각 레벨의 샘플 개수)
print(classification_report(y_pred, y_test))로 쓰면 아래와 같이 출력됩니다.
- ROC(Receiver Operating Characteristic) curve
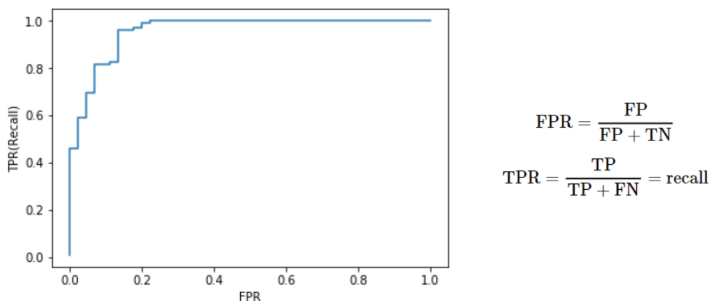
- 다양한 threshold에 대한 이진분류기의 성능을 한번에 표시한 것
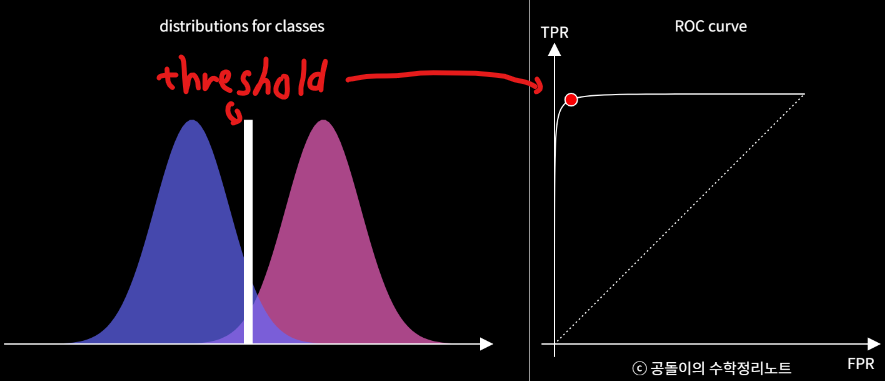
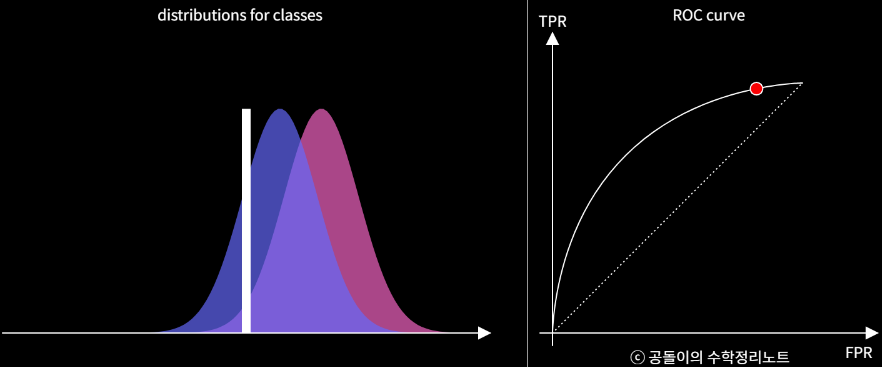
- threshold: 클래스를 분류하기 위해 사용자가 결정하는 것
- 좌상단에 붙어있는 커브일수록 더 좋은 이진분류
- ROC curve를 잘 이해하기 위해 ROC curve plot에서 보이는 세 가지 특성에 대해 파악해야 함:
- True Positive Rate과 False Positive Rate
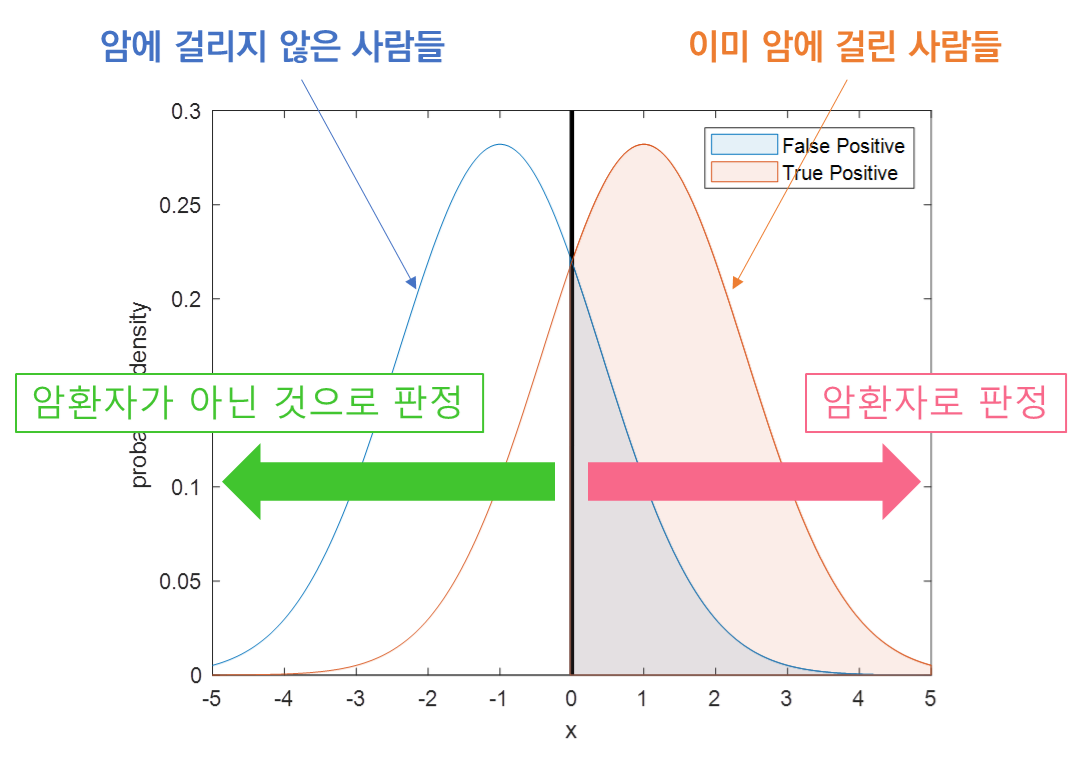
- ROC Curve위의 한 점이 의미하는 것 → 모든 가능한 threshold별 FPR(False Positive Rate)과 TPR(True Positive Rate)을 알아보겠다
(현재 이진 분류기의 분류성능은 변하지 않되, 가능한 모든 threshold별 FPR과 TPR의 비율을 알아내서 plot하겠다)
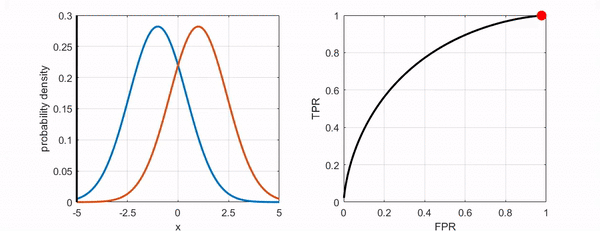
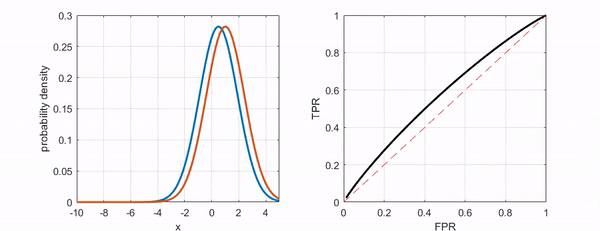
- ROC Curve의 휜 정도가 의미하는 것 → 두 클래스를 더 잘 구별할 수 있다면 ROC 커브는 좌상단에 더 가까워지게 된다
- True Positive Rate과 False Positive Rate
- 다양한 threshold에 대한 이진분류기의 성능을 한번에 표시한 것
분석 결과 해석
- class 0은 대부분 정확하게 예측하고 있음
- class 1은 낮은 정밀도와 중간의 재현율을 보인다
- accuracy는 0.84로 보통 수준이지만 이는 클래스 불균형으로 인해 발생하게 된 것
- 대부분 0(이직 안 함)으로 예측했기 때문에 높아보이게끔 나옴
- 이는 결론적으로 데이터의 클래스 불균형 문제를 해결해줘야 한다!
- 학습한 데이터부터 잘못된 것이므로(class 1을 맞추는 게 중요한데 class 1에 대한 학습량이 부족) 학습 데이터의 비율을 맞춰준 후 모델 학습을 진행해야 함
비지도 학습(Unsupervised Learning)
- 데이터에 대한 Label(명시적인 답)이 없는 상태에서 컴퓨터를 학습시키는 방법
- 데이터의 숨겨진 특징, 구조, 패턴을 파악하는 데 사용
- 종류
- 클러스터링(Clustering)
- 데이터를 비슷한 특성끼리 묶음
- 차원 축소(Dimensionality Reduction) 등
- 클러스터링(Clustering)

-
지도학습은 이미 정답을 알고 있음(과거가 주어진 것)
-
비지도학습은 정답이 없기 때문에 탐색을 통해 미래에 일어날 일을 예측
-
비지도 학습 예시
- 비지도 학습 → 데이터의 특성을 추출

- 이미지 감색 처리: 비슷한 특성끼리 모아서 화면의 객체가 어떤 객체인지 판별
- 소비자 그룹 마케팅: 카드 추천, 기저귀-맥주
- 손글씨 숫자 인식: 같은 그룹끼리 묶기
- 주로 지도 학습 전에 비지도 학습을 진행: 비지도 학습을 통해 그룹을 나누고 사용자가 그룹마다 레이블을 지정해 정답이 있는 데이터로 만들어 준 다음 손글씨 → 숫자 지도 학습을 수행할 수 있음
- 비지도 학습 → 데이터의 특성을 추출
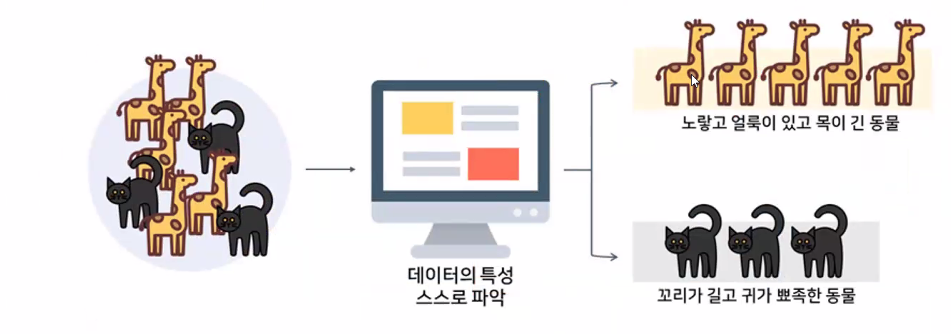
→ 비지도 학습의 결과물에 사람이 각각 "기린", "고양이"라는 레이블을 부여(정답 제시)하면 이후 지도 학습 수행이 가능해짐
학습 목표
- 군집(Clustering)에 대해 이해할 수 있다.
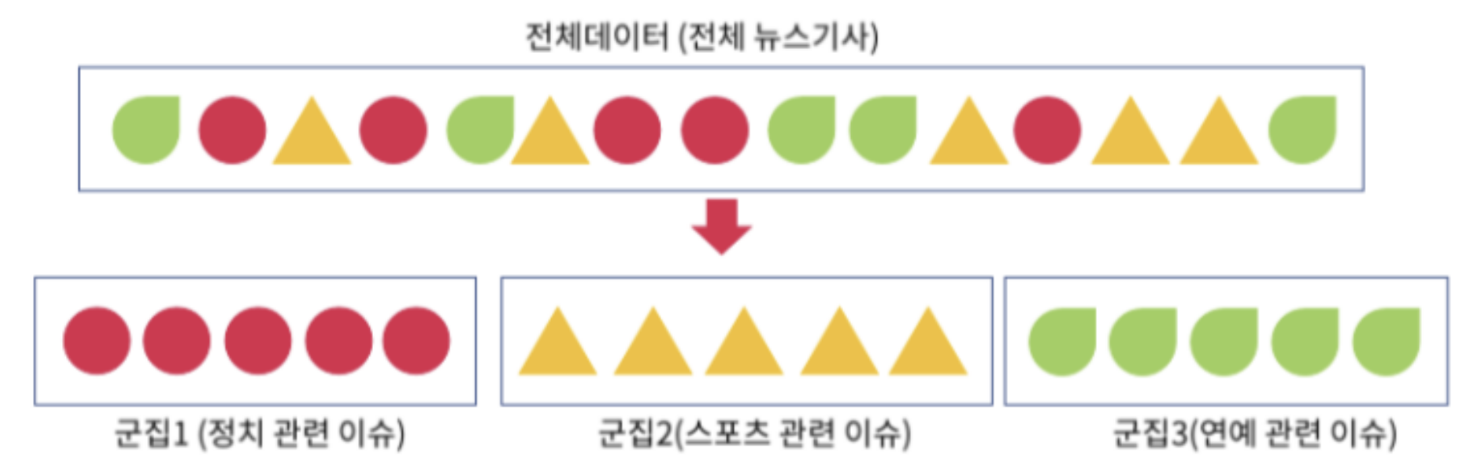
- 정답이 없고 각 특징만을 가진 데이터 묶음에서 비슷한 특성을 가진 데이터들만 한곳으로 모으는 작업
- 전체 뉴스 기사를 카테고리별로 묶고 싶을 때
- 정답이 없기 때문에 데이터별로 비슷한 관련 단어를 모아서 분류
- 농구, 야구, 배구, 선수, 공 … -> 군집으로 묶어서 하나의 클래스를 부여: 스포츠 관련 뉴스
- K-means, 계층적 군집, DBSCAN을 이해하고 사용할 수 있다.
군집화(Clustering)
- 비슷한 데이터끼리 하나의 클러스터로 묶고, 다른 데이터끼리는 다른 클러스터로 분류
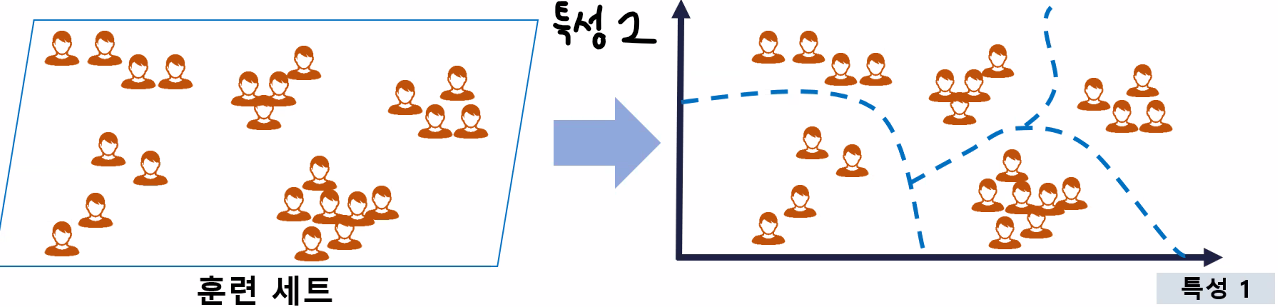
- 비슷한 데이터끼리는 뭉쳐 있어야 하고 서로 다른 데이터끼리는 멀리 떨어져 있어야 잘 분류한 것
- 가까이 있는 데이터가 비슷한 특징을 가진다는 것을 전제로 군집화 진행
- 비슷한 데이터끼리는 뭉쳐 있어야 하고 서로 다른 데이터끼리는 멀리 떨어져 있어야 잘 분류한 것
- 대표적인 예시로 K-means가 있음
- 군집의 개수(K)를 사용자가 정해야 함 → 정답이 없음 → 알맞은 군집의 수를 결정하는 것이 데이터 분석가의 역량
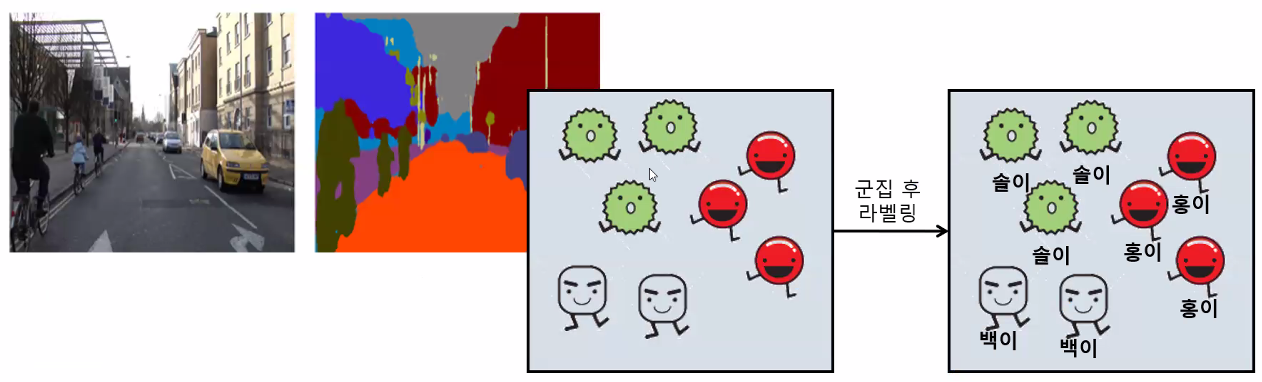
- 군집의 개수(K)를 사용자가 정해야 함 → 정답이 없음 → 알맞은 군집의 수를 결정하는 것이 데이터 분석가의 역량
- 군집화(Clustering) 종류
- 계층적 클러스터링(Hierarchical clustering): 데이터 간의 관계를 계층적인 구조로 표현
- 응집형(Agglomerative)
- 분리형(Divisive)
- 분할적 군집화(Partitional Clustering): 데이터를 특정 개수의 군집으로 나누는 방식
- K-means(K-평균): 데이터 포인트를 K개의 군집으로 나누고, 각 군집의 중심(centroid)을 기준으로 데이터를 재할당하는 방식을 반복
- DBSCAN(Density-based spatial clustering of applications with noise): 밀도 기반으로 군집을 형성하며, 노이즈 데이터를 식별할 수 있음
- 기타
- 평균 이동(Mean Shift)
- 가우시안 혼합 모델(Gaussian Mixture Model)
- 유사도 전파(Affinity Propagation)
- 계층적 클러스터링(Hierarchical clustering): 데이터 간의 관계를 계층적인 구조로 표현
K-means 군집
- 가장 일반적으로 사용되는 알고리즘
- 일반적인 군집화에서 많이 활용되는 알고리즘
- 알고리즘이 쉽고 간결함
- 거리 계산: 거리 기반 알고리즘
- 속성의 개수가 많은 경우 군집화 정확도가 떨어짐
- 입력 특성의 개수가 많으면 중심점 계산이 어려움: 차원이 많아지기 때문
- 따라서 PCA 등의 차원 축소를 적용해야 할 수도 있음
- 속성의 개수가 많은 경우 군집화 정확도가 떨어짐
- Centroid(군집 중심점)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법
- K: Centroid의 개수(군집의 개수) → 하이퍼파라미터임
- 초기 단계에 사용자가 값을 직접 지정해 주어야 함
- K: Centroid의 개수(군집의 개수) → 하이퍼파라미터임
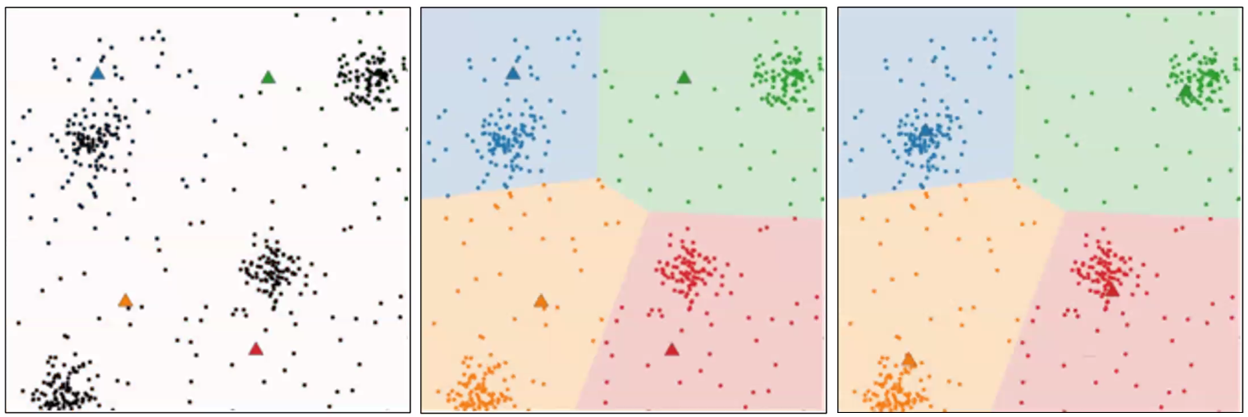
- 반복 횟수가 많아질 경우 수행 시간이 매우 느려짐
- 몇 개의 군집을 선택해야 할지 가이드하기가 어려움
- 사용자가 군집을 명확하게 선택하는 것이 중요
- 단점
- 적절한 클러스터의 수(K) 지정 필요
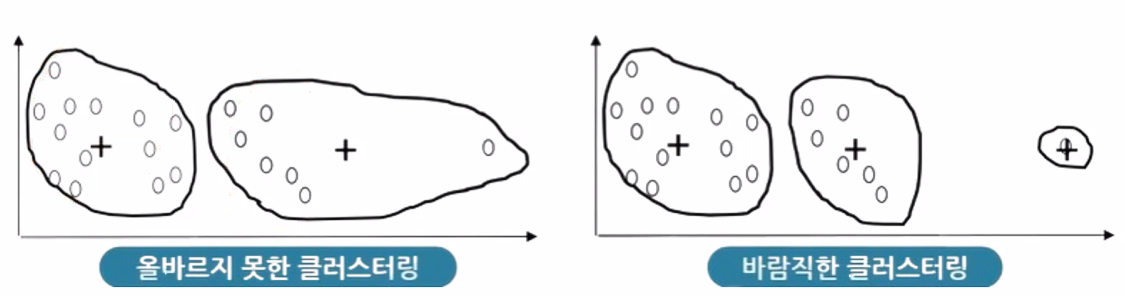
- noise에 매우 민감
- 올바르지 못한 클러스터링 → 중짐점 왜곡 문제 발생
- 적절한 클러스터의 수(K) 지정 필요
- 성능 저하의 원인
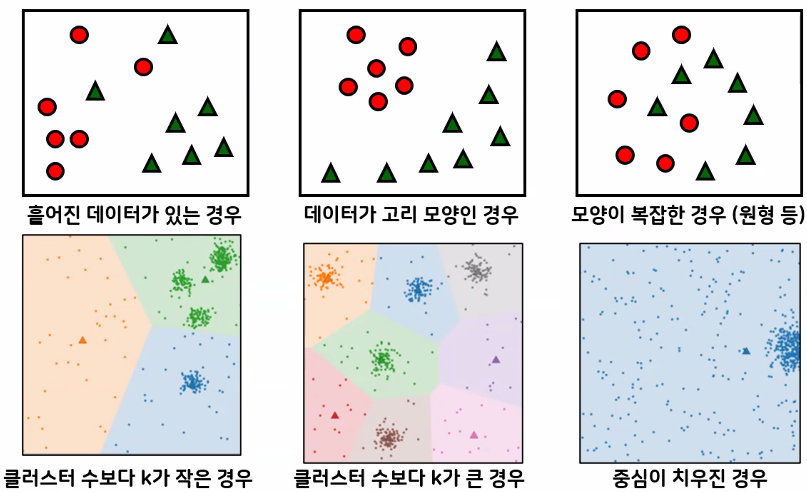
- (보충 필요함)
- k의 개수를 너무 많이 지정하면 억지로 그룹을 나눔
- 스포츠까지만 묶으면 되는데 축구, 배구, 야구, 농구, ...로 나눠버림
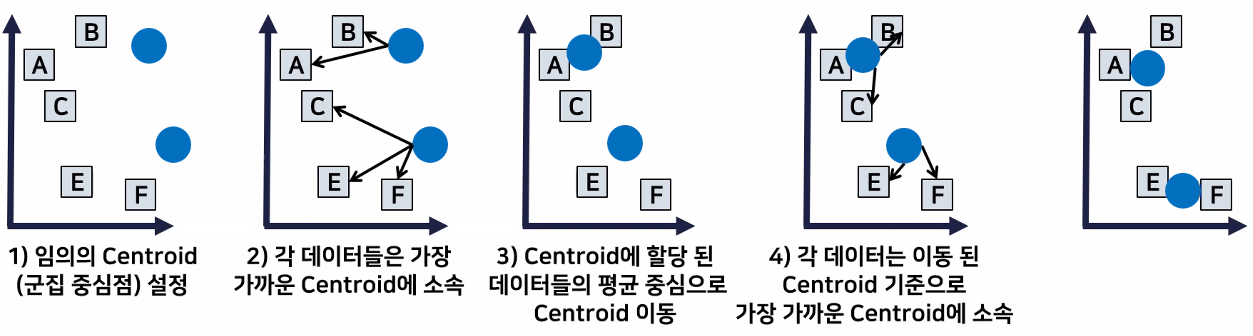
- 원리
- 처음에는 임의로 Centroid(군집중심점) 설정
- 군집중심점으로부터 가까운 데이터 포인트 선점 (거리 계산)
- 가장 가까운 데이터들로부터 평균 중심으로 군집중심점이 이동 → 이름에 means가 들어가는 이유
- 수렴(군집중심점의 이동이 없음)할 때까지 계속 반복
계층적 클러스터링(Hierarchical clustering)
-
데이터 포인트들을 계층적인 구조로 그룹화하는 방법
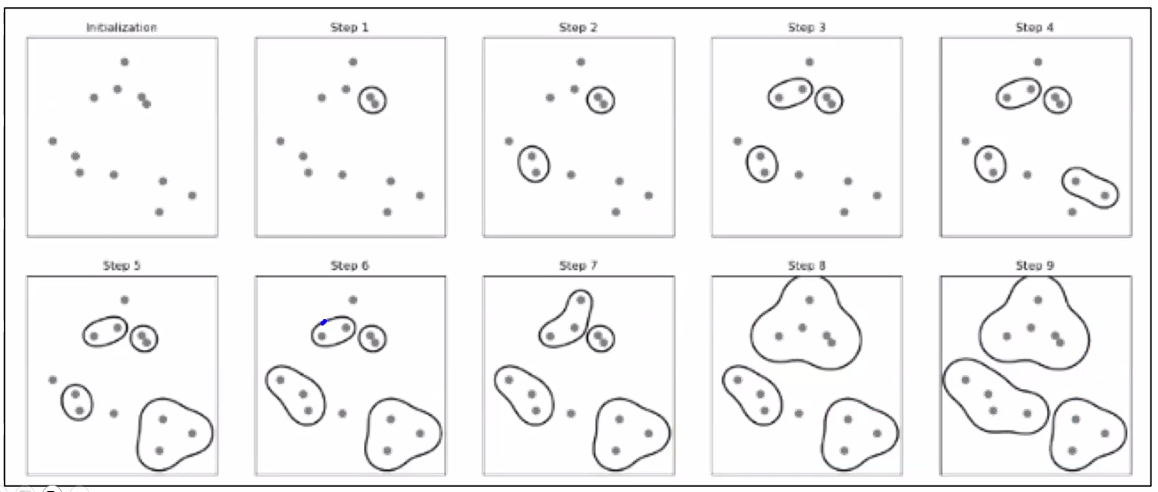
- 데이터를 가까운 집단부터 순차적이며 계층적으로 군집화
- 모든 데이터 사이의 거리에 대한 유사도 계산
- 유사도가 비슷한 데이터끼리 클러스터 구성
- 유사도 업데이트
- 데이터를 가까운 집단부터 순차적이며 계층적으로 군집화
-
계층적 트리 모형을 이용하여 개별 데이터 포인트들을 순차적, 계층적으로 유사한 클러스터로 통합하여 군집화 수행
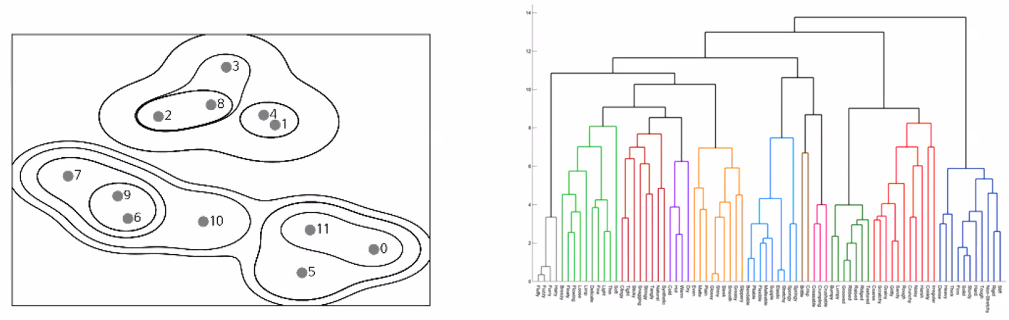
- 계층적 구조로 인해 클러스터 혹은 군집의 개수를 미리 정하지 않아도 된다는 장점이 있음
- 클러스터를 구성할 때 매번 local minimum을 찾아가는 방법을 활용하기 때문에 클러스터링의 결과값이 global minimum이라고 해석하기에는 어려움이 있음
- K-means 군집 알고리즘과 달리 클러스터 개수를 사전에 고르지 않아도(초기 단계에 군집의 개수를 정하지 않아도) 학습을 수행
- 최종적으로는 결과를 보고 사용자가 군집의 개수를 몇 개로 할 건지 골라야 함
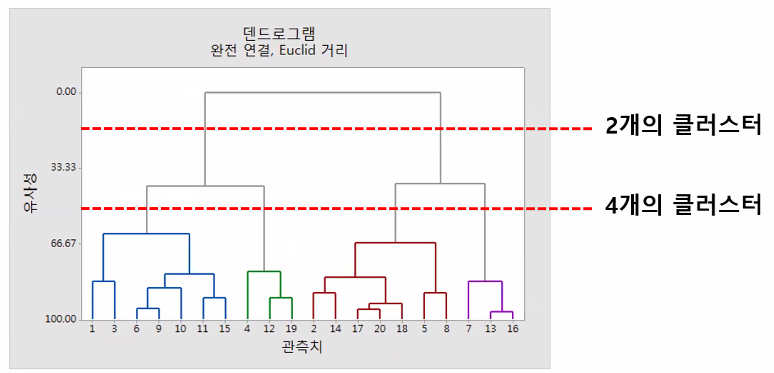
- 시각화 가능 → 덴드로그램
- 가지에 직선(가로 선)을 그어 군집을 몇 개로 할 건지만 정하면 됨
- 덴드로그램(Dendrogram)
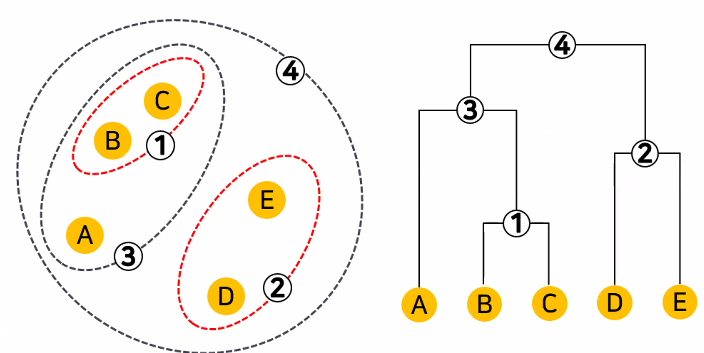
- 계층 군집을 시각화하는 도구
- 덴드로그램에서 가지의 길이가 의미하는 것
- 합쳐진 클러스터가 얼마나 멀리 떨어져 있는지를 보여줌
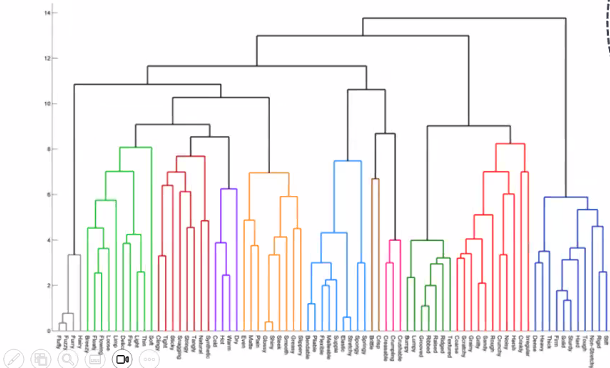
- 계층적으로 군집화를 완료한 후에 사용자가 시각화된 덴드로그램을 보고 가로 선으로 분할하면 클러스터를 임의로 나눌 수 있음
- K-Means 군집과 마찬가지로 계층적 군집에서도 데이터 간의 거리를 기반으로 하기 때문에 복잡한 형상의 데이터 세트는 구분하지 못함
- SpiCy 모듈을 사용해 수행 → 덴드로그램(Dendrogram)을 쉽게 그릴 수 있음
DBSCAN
: Density-based spatial clustering of applications with noise
- 밀도 기반 클러스터링
- 밀도 있게 연결되어 있는(density-connected) 데이터 집합은 동일 클러스터라 판단
- 일정한 밀도를 가지는 데이터의 무리가 마치 체인처럼 연결되어 있으면 거리 개념과 관계없이 같은 클러스터로 판단
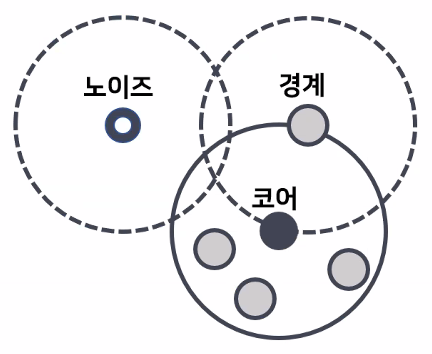
- 노이즈 제거가 들어감
- 어떤 방식으로 노이즈를 제거하는지 알아두기
- 용어 3개 파악
- 코어 포인트(Core Point)
- 해당 데이터 포인트의 일정 반경 내에 충분한 다른 데이터 포인트가 있는 경우(다른 데이터 포인트가 최소 포인트 수 이상 존재)
- 경계 포인트(Border Point)
- 데이터 포인트가 코어 포인트는 아니지만, 코어 포인트의 반경 내에 있는 경우
- 노이즈 포인트(Noise Point)
- 데이터 포인트가 코어 포인트도 아니고 경계 포인트도 아닌 경우
- 코어 포인트(Core Point)
-
초반에 설정해줘야 하는 것: 반경, 최소 포인트 수
- 일정 반경(epsilon), 최소 포인트 수(min_samples)는 사용자가 설정
- min_samples=3이라고 설정하면 포인트 P를 중심으로 eps 내에 Core Point 제외 포인트 3개 이상 있으면 하나의 군집으로 판단
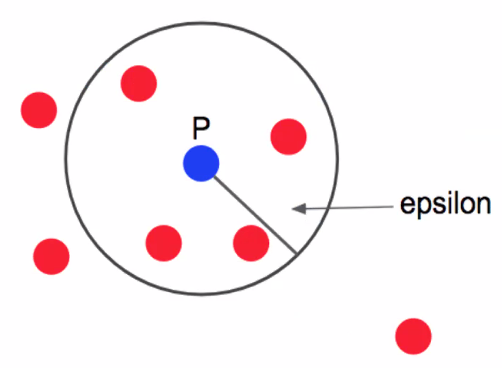
- P값의 반경(epsilon) 내에 4개의 데이터가 있기 때문에 하나의 군집으로 판단
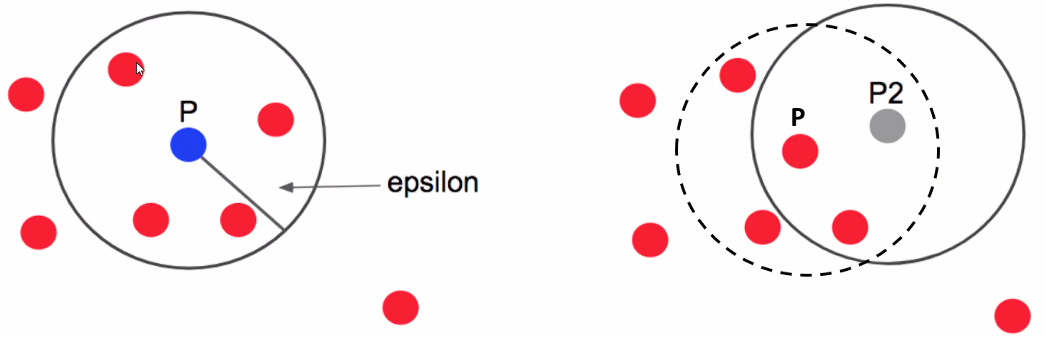
- P는 핵심 포인트(Core Point)가 됨
- Core Point P에 속해 있는 포인트 중심으로 재탐색 → 포인트 P2
- 포인트 P2는 eps 반경 내 포인트가 2개로 min_sample=3에 미치지 못하기 때문에 Core Point가 되지 못하지만, 앞의 포인트 P를 핵심 포인트로 하는 군집에는 속하기 때문에 '경계 포인트(Border Point; 경계점)'라고 함
- 포인트 P3: eps 반경 내 포인트 3개 → Core Point
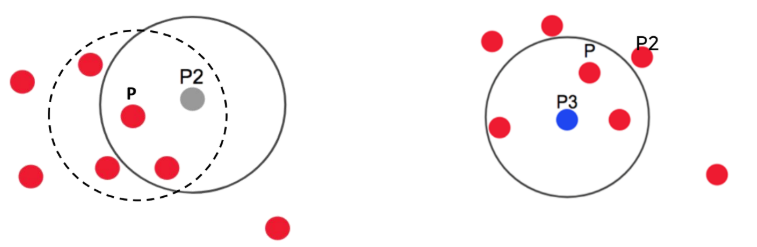
- 포인트 P3를 중심으로 하는 반경 내에 다른 Core Point P가 포함되어 있음 → 핵심 포인트 P와 P3는 연결되어 하나의 군집으로 묶임
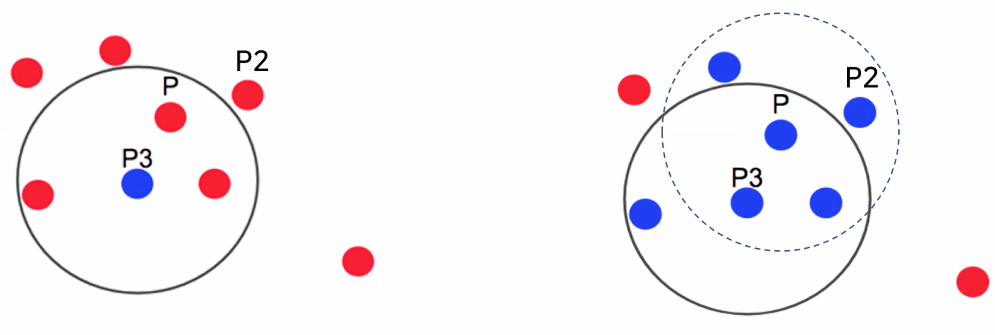
- 마지막으로 포인트 P4는 어떤 점을 중심으로 하더라도 min_point=3 만족하는 범위에 포함되지 않음 → 어느 군집에도 속하지 않는 outlier: noise point

-
장단점
- K-means와 달리 클러스터를 미리 지정할 필요가 없음
- 클러스터의 밀도에 따라 클러스터를 서로 연결하기 때문에 복잡한 형상이나, 어떤 클래스에도 속하지 않는 포인트(Noise)를 부분할 수 있음
- K-means 성능 저하의 원인(데이터가 고리 모양인 경우 등)에 대처 가능
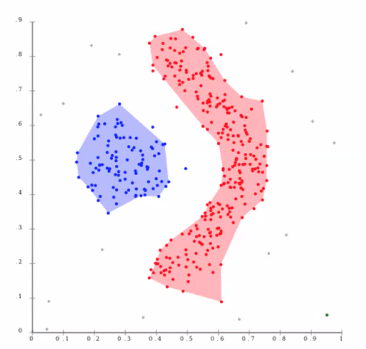
- K-means 성능 저하의 원인(데이터가 고리 모양인 경우 등)에 대처 가능
- 비선형 클러스터를 잘 찾아낼 수 있음
- Noise 데이터를 감지하고 무시할 수 있음
- 클러스터의 모양과 크기에 관계없이 효과적으로 클러스터를 찾을 수 있음
- 하이퍼파라미터(하이퍼 매개변수) 설정에 민감함
- epsilon
- min_samples
- 데이터의 밀도가 크게 차이나는 경우, 클러스터링 효과가 좋지 않을 수 있음
군집 평가(Cluster Evaluation)
- 비지도 학습의 특성상 어떠한 지표라도 정확하게 성능을 평가하기는 어려움
- 정답이 없는 문제이기 때문
- 그러나 군집화의 성능을 평가하는 지표들은 존재함 → 여러 지표들을 활용하여 어느 정도 군집화에 대한 성능 판단 가능
엘보우 기법(Elbow Method)
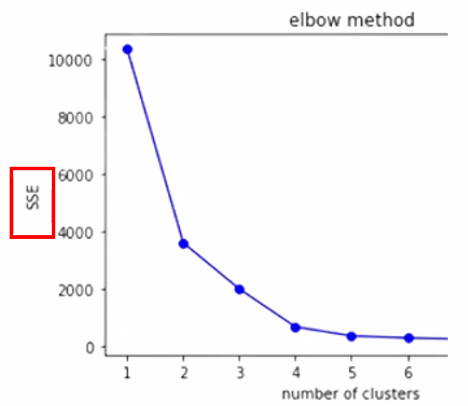
- 클러스터링 알고리즘에서 최적의 클러스터 수를 결정하기 위해 사용되는 시각화 기법
- 군집간 분산과 전체 분산의 비율을 확인
- 기울기가 가장 완만해지는 지점 선택
- 최적의 군집 수 → 기울기가 급격하다가 완만해지는 부분!
- SSE(Sum of Squared Error)
- 데이터 포인트와 군집중심점의 거리라고 생각하면 됨
- 오차!
- SSE가 작을수록 군집 중심점에 가깝게 모여 있다는 의미
- 클러스터 내에서 데이터 포인트들이 클러스터 중심으로부터 얼마나 떨어져 있는지를 나타내는 값
- 값이 작을수록 군집중심점에 가깝게 모여있다는 의미
- 그래프에서 클러스터 수가 증가함에 따라 SSE가 급격히 감소하다가 완만해지는 지점을 찾는 것이 목표
- 급격히 감소하다가 완만해지는 지점이 최적의 클러스터 수(최적의 군집 수)를 나타낸다고 판단
- 데이터 포인트와 군집중심점의 거리라고 생각하면 됨
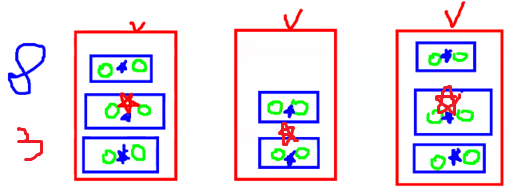
- 위와 같은 경우 SSE는 줄어들지만 너무 상세한 분류일 수 있음
- 오차가 크면 군집 수 늘려야 함
- 오차가 작으면 군집 수 줄여야 함
- 장단점
- 그래프를 통해 최적의 클러스터 수를 직관적으로 파악할 수 있음
- 엘보의 지점을 선택하는 과정에서 주관이 개입될 수 있음: 명확한 답이 없음 → 다양한 지표를 봄으로써 보완
- 엘보우 기법도 보는 사람마다 생각하는 포인트가 다를 수 있음
- 위 예시에서도 4를 고를 수도 있고 5를 고를 수도 있음
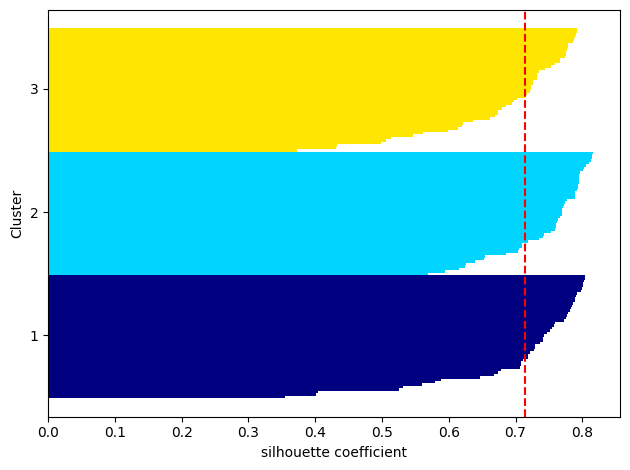
실루엣 분석(silhouette analysis)
- 실루엣 계수(silhouette coefficient) 기반
- 얼마나 효율적으로 잘 분리되었는지를 나타냄
- 다른 군집과 거리가 떨어져 있는가? → 분리도
- 동일 군집끼리의 데이터는 가깝게 잘 뭉쳐 있는가? → 응집도

- 왜 max()를 사용하나요?
- 둘 둥 큰 값을 분모로 두는 이유: 값을 정규화해 주기 위해
- 값이 -1 ~ 1 사이로 나올 수 있게 만듦
- 둘 둥 큰 값을 분모로 두는 이유: 값을 정규화해 주기 위해
- 해석
- 1에 가까울수록 데이터 포인트가 잘 군집화되고, 다른 군집과는 잘 분리됨
- 0에 가까울수독 데이터 포인트가 클러스터 경계에 위치하고 있음
- -1에 가까울수록 데이터 포인트가 잘 못 군집화 되어 있음을 의미
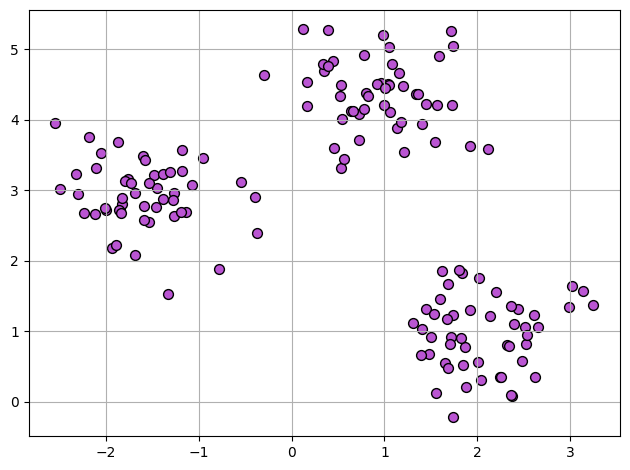
실습: 그래프 그려보기
- mglearn 라이브러리를 활용하여 비지도학습 학습용 그래프 그려보기
- 파이선 라이브러리를 활용한 머신러닝 저자가 만든 라이브러리로 학습용 그래프를 제공함
!pip install mglearn # 최초 1회만 실행
import mglearn
mglearn.plots.plot_kmeans_algorithm()
# 데이터 없이도 K-means에 대한 학습용 그래프를 볼 수 있습니다.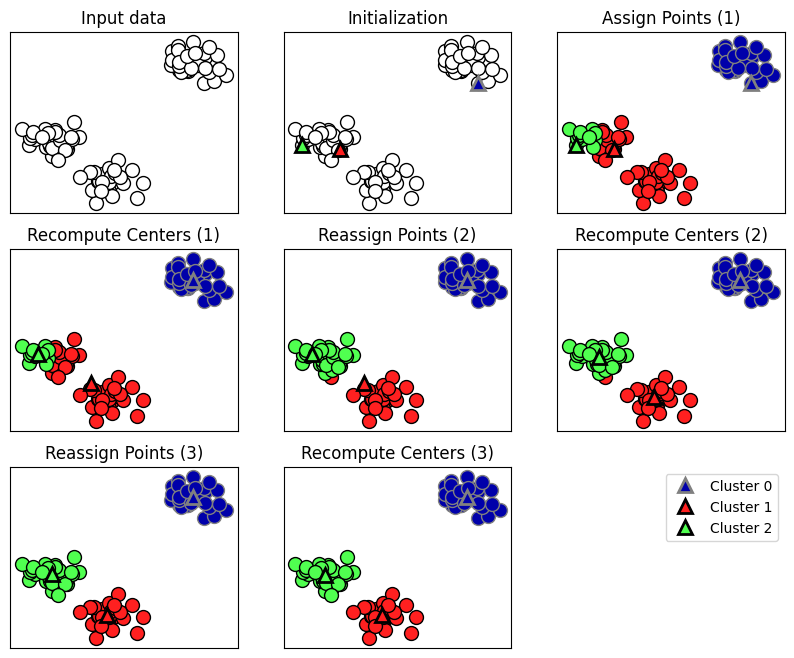
실습: 구내식당 식수 인원 예측
학습 목표
- 구내식당 데이터를 통하여 비지도 학습을 이해할 수 있다.
- 구내식당의 메뉴 데이터 전처리를 통하여 비지도 학습을 준비하자
1. 문제 정의
- 의뢰인: 구내식당의 회사 사장
- 문제: 음식 재고로 인한 스트레스
- 감으로 하다 보니 식수 많고 적고 차이가 큼
- 메뉴와 직원 정보를 통하여 적정 식수를 예측하고 재고를 효율적으로 관리하고자 함
- 식수와 관련있는 다양한 데이터를 확인하여 식단 프로그램 개발
- 휴가, 출장 일정, 야근 예정, 메뉴, 요일 등
- 구내식당 이용 직원 만족도 올리기
# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 인코딩 확인 후 데이터 불러와야 해요! (한글 데이터라서)
import chardet
with open("./data/Cafeteria.csv", "rb") as f:
data = f.read()
chardet.detect(data){'encoding': 'EUC-KR', 'confidence': 0.49705603534497006, 'language': 'Korean'}# 파일 불러오기
data = pd.read_csv("./data/Cafeteria.csv", encoding="euc-kr")
data.head()컬럼 설명
| 컬럼명 | 설명 |
|---|---|
| 일자 | 데이터가 수집된 날짜 |
| 요일 | 해당 날짜의 요일 |
| 본사정원수 | 본사에 근무하는 전체 직원 수 |
| 본사휴가자수 | 본사에 휴가 중인 직원 수 |
| 본사출장자수 | 본사에 출장 중인 직원 수 |
| 본사시간외근무명령서승인건수 | 본사에서 승인된 시간 외 근무 명령서 건수 |
| 현본사소속재택근무자수 | 본사 소속 중 재택 근무 중인 직원 수 |
| 조식메뉴 | 해당 날짜의 조식 메뉴 |
| 중식메뉴 | 해당 날짜의 중식 메뉴 |
| 석식메뉴 | 해당 날짜의 석식 메뉴 |
| 중식계 | 해당 날짜에 중식을 이용한 직원 수 |
| 석식계 | 해당 날짜에 석식을 이용한 직원 수 |
# 데이터 정보 확인
data.info()데이터 탐색(전처리)
날짜 데이터
- 일자 컬럼
# 날짜 데이터는 연산, 비교 등 유의미한 데이터로 다루기 위해서 datetime 자료형 형태로 변경
import datetime
pd.to_datetime(data["일자"])
data["일자"] = pd.to_datetime(data["일자"])
# 일자 컬럼: 데이터 타입이 datetime으로 변경됨 -> 일자별로 계산 or 비교가 가능해짐
# 언제부터 언제까지의 데이터인지 확인
data["일자"].min(), data["일자"].max()(Timestamp('2016-02-01 00:00:00'), Timestamp('2021-01-26 00:00:00'))하루 돌아보기
👍 잘한 점
- confusion matrix 수업 자료 내용 오류 제보
- 보충 수업 참여함
- 야간자율학습 진행
👎 아쉬웠던 점
- 엘보우 기법 기울기가 가장 완만해지는 지점 보는 게 헷갈림
- 회귀/분류 평가지표가 헷갈릴 때가 있음
🔬 개선점
- 해당 부분 복습 진행
- 학습한 부분 지급 받은 교재에서 다시 한번 찾아보기
신재구 님이 다음과 같은 페이지를 만들어 공유해 주셨음:
머신러닝 학습 허브
기업 분석 가이드
갈톤보드 이항분포 시각화 도구
서현수 님도 정리 페이지를 공유해 주셨음:
즐겨찾기 페이지
→ 공부할 때 참고하기!

2 B R 0 2 B