코딩테스트 연습
알고리즘
SQL
지난 시간 복습
- 비지도 학습
- 명시적인 답(label)이 없는 상태에서 학습
- 숨겨진 특징, 구조, 패턴 파악
- 클러스터링, 차원 축소 등
- 군집화(Clastering)
- 정답이 없는 데이터를 분류: 특징이 비슷한 것끼리
- 지도 학습을 위해 사용(→ 비지도 학습으로 군집을 나눈 것에 레이블을 부여 후 지도 학습 진행) 또는 특징 파악을 통한 그룹화(→ 고객 성향 분류)
- 비슷한 데이터끼리 하나의 클러스터로 묶고, 다른 데이터끼리는 다른 클러스터로 분류
- K-means, Hierarchical clustering, DBSCAN(Density-based spatial clustering of applications with noise)
- K-means
- K: 군집의 수 == Centroid(군집 중심점) 수
- means: 군집 중심점이라는 특정한 임의의 지점에 할당된 데이터들의 평균 중심으로 군집 중심점이 이동하기 때문
- 성능 저하의 원인
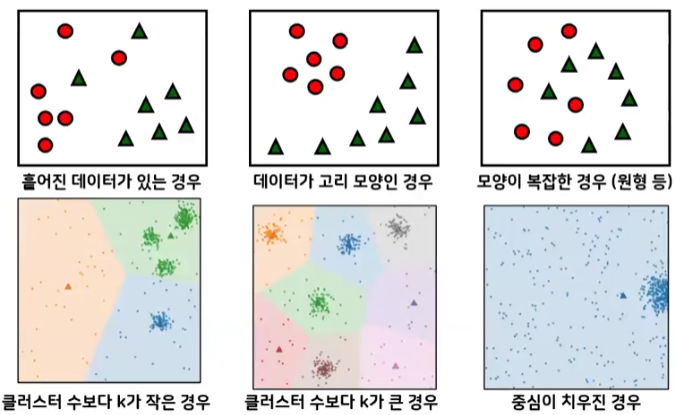
- 군집 평가 지표
- 엘보우 기법
- 최적의 클러스터 수 결정
- SSE(sum of squared error): 데이터 포인트 - 군집 중심점 사이 거리 기반 → 응집도와 관련 있음
- 사람마다 기울기가 완만해지는 지점에 대한 기준이 다른 문제 → 실루엣 지수로 보완
- 실루엣 분석
- 응집도와 분리도를 이용
- 응집도: 데이터 포인트와 동일 클러스터 내 다른 모든 데이터 포인트 간 평균 거리 → 작아야 좋음(동일 군집끼리의 데이터는 가깝게 잘 뭉쳐 있어야 하므로)
- 분리도: 데이터 포인트와 가장 가까운 다른 클러스터 내의 모든 데이터 포인트 간 평균 거리 → 커야 좋음(다른 군집과는 거리가 떨어져 있어야 하므로)
- 1에 가까울수록 good, 0에 가까울수록 iffy, -1에 가까울수록 bad
- 엘보우 기법
- 계층적 클러스터링
- K-means 등을 보완하는 목적으로 많이 사용
- 복잡한 형상은 잘 구분 못함
- 유클리디언 거리 공식 사용
- DBSCAN

- 키워드 3개 기억하기
- 코어 포인트
- 경계 포인트
- 노이즈 포인트
- 사용자가 설정해야 하는 것 2개
- eps(epsilon; 반경)
- min_samples(최소 샘플 수)
- 키워드 3개 기억하기
{kind=link}
- 실습: 구내식당 인원 예측
- 문제 정의
- 메뉴와 직원 정보를 통한 식수 예측
- 식수 관련 다양한 데이터 확인
- 데이터 탐색
- 일자 데이터가 object로 되어 있는 걸 datetime으로 변환 → 연산이 가능하게 만들기 위함
- 문제 정의
딥러닝에서는 특성 추출(feature extraction)까지 컴퓨터가 하기 때문에 지금 실습에서 데이터 탐색 & 특성 추출 과정을 잘 알아둬야 함!
실습: 구내식당 인원 예측
데이터 탐색
요일별 식수 확인
# 요일별 식수 확인
# 요일에 따른 중식계, 석식계 식수 평균 구하기
# groupby() 사용
df_day = data.groupby("요일")[["중식계", "석식계"]].mean()
# 요일 순으로 정렬: 월화수목금
df_day = pd.DataFrame(df_day, index=("월", "화", "수", "목", "금"))
# 한글 폰트 자동 설정 라이브러리: koreanize_matplotlib
!pip install koreanize-matplotlib
import koreanize_matplotlib
# 요일별 중식계 평균 식수
plt.bar(df_day.index, df_day["중식계"])
plt.ylim(600,)
# 월요일에는 중식계에 대한 식수가 가장 많음
# 초반에는 회사에 출근하여 구내식당을 이용하는 직원이 많으나
# 후반에는 식수가 감소 -> 연차, 반차 사용 또는 다른 식당을 이용하지 않을까?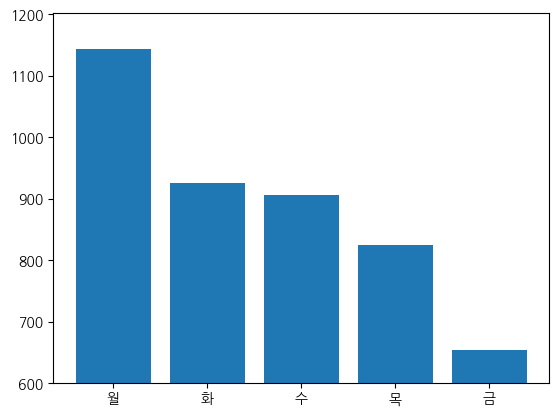
# 요일별 석식계 평균 식수
plt.bar(df_day.index, df_day["석식계"])
plt.ylim(300,)
# 월: 석식계의 식수가 높음 -> 월요일에 늦게까지 일하는 직원이 많은듯 보임
# 화, 목: 업무 진행
# 수: 석식계 식수 감소 -> 주중의 중반임을 감안하여 직원들의 피로도가 높아 야근을 적게 하지 않을까?
# 금: 석식계 식수 감소 -> 사회적 약속이 많은 요일, 외부에서 식사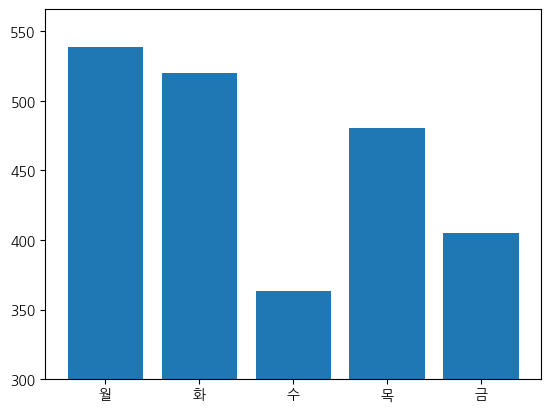
월별 식수 확인
# 월별 식수 평균 확인
data["month"] = data["일자"].dt.month
# 월별 중식계, 석식계 식수 평균 확인 → 그래프 →해석
df_month = data.groupby("month")[["중식계", "석식계"]].mean()
# 월별 중식계 평균 식수
plt.bar(df_month.index, df_month["중식계"])
plt.ylim(800,) # 범위를 제한하여 그래프의 특이점 확인하는 과정이 필요
# 1, 2, 3월: 가장 많은 중식 식수 -> 신입사원 입사? 영향이 있지 않을까?
# 6, 7, 8월: 여름 휴가, 11, 12월: 겨울 휴가
# 9, 10월: 또 상승 -> 여름 휴가로 인한 지출 높아짐, 지출 제한을 위해 구내식당을 사용하지 않을까?
# 식수의 빈도수 확인을 통해 월별, 요일별 식수 변동 패턴을 고려하여 재고를 조절할 수 있도록 해줘야 함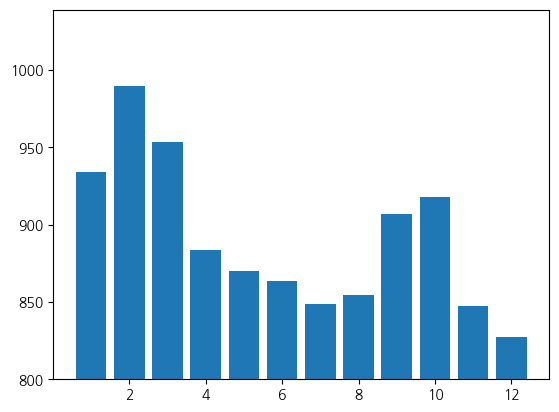
# 월별 석식계 평균 식수
plt.bar(df_month.index, df_month["석식계"])
plt.ylim(400,)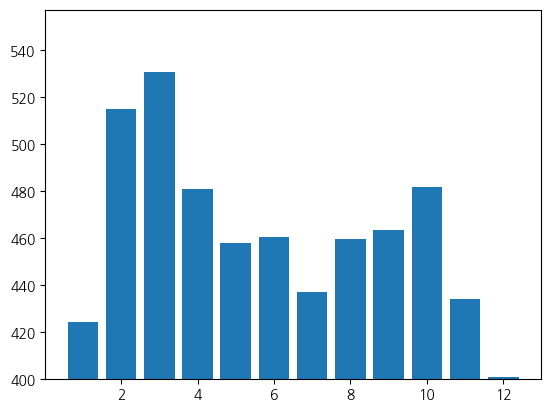
추가: 그래프 한글 출력을 위한 한글 폰트 설정법
- 방법이 여러 가지 있으니까 다양하게 알아두고 상황에 맞게 사용하기
- 커널 재시작 필요!
# 참고: 코랩에 설치된 폰트 목록 확인
!ls /usr/share/fonts/truetype/- 방법 1
!sudo apt-get install -y font-nanum
!sudo fc-cache -fv
!rm ~/.cach/matplotlib -rf
plt.rcParams["font.family"] = "NanumBarunGothic"
plt.rcParams["axes.unicode_minus"]=False- 방법 2: koreanize-matplotlib
- 한글을 쓸 때 문제가 없도록 matplotlib의 폰트 설정을 자동으로 한국어로 지정해주는 라이브러리
!pip install koreanize-matplotlib
import koreanize_matplotlib- 방법 3: 구글드라이브에 폰트 업로드 한 뒤 사용
# 한글 폰트 설정
import matplotlib.font_manager as fm
import matplotlib as mpl
# 폰트 파일 경로
font_path = "./data/fonts/NanumFont/NanumGothic.ttf"
# 폰트 매니저에 직접 추가
fm.fontManager.addfont(font_path)
# 폰트 이름 확인
font_name = fm.FontProperties(fname=font_path).get_name()
print(font_name)
# rcParams에 적용
mpl.rc("font", family=font_name)
# 마이너스 표시
mpl.rc("axes", unicode_minus=False)- 또 다른 방법
참고: 코랩은 리눅스 운영 체제입니다.

추가: 데이터프레임 str 키워드
- 판다스에서 문자열 관련 함수를 사용하거나 전처리를 하기 위해서는 함수 및 명령어 앞에 str 을 붙여주어야 함
- str 접근자(str accessor)
- 데이터프레임에서 문자열 데이터를 다룰 때 사용
- 문자열 데이터 타입의 시리즈에 대해 다양한 문자열 연산을 수행할 수 있도록 해주는 기능
- 시리즈 내에서 특정 데이터 유형에만 적용되는 별도의 네임스페이스 → pandas Series 객체에서 문자열 메소드를 호출할 수 있게 해주며, 이를 통해 데이터프레임의 문자열 열에서 다양한 작업을 수행할 수 있음
- 특정 문자열 연산을 수행하기 위한 핵심적인 도구
- 문자 형식의 원소를 가지는 Pandas Series 객체는 .str 접근자(accessor)를 사용하여 관련 어트리뷰트 또는 메서드를 사용할 수 있음
- 데이터프레임에서 문자열 데이터를 다룰 때 사용
- 주요 기능
- 문자열 추출 및 분할
- str.split(), str.extract(), str.get() 등을 사용하여 문자열을 분할하거나 특정 부분만 추출할 수 있음
- 문자열 검색 및 치환
- str.contains(), str.replace(), str.match() 등을 사용하여 특정 문자열을 검색하거나, 다른 문자열로 변경할 수 있음
- 문자열 길이 및 인덱스
- str.len(), str.startswith(), str.endswith() 등을 사용하여 문자열의 길이, 시작 또는 끝 문자를 확인하거나, 특정 위치의 문자를 가져올 수 있음
- 문자열 포매팅
- str.format() 등을 사용하여 문자열을 원하는 형식으로 포맷할 수 있음
- 문자열 추출 및 분할
- 주의사항
- str 접근자는 문자열 데이터가 저장된 열에서만 사용할 수 있음
- 데이터프레임의 열 데이터 타입이 object인 경우 문자열로 간주
- str 접근자를 사용할 때, 데이터가 누락되었거나 (NaN) 예상치 못한 데이터 타입인 경우 오류가 발생할 수 있음
- 이 경우 fillna() 또는 astype() 등을 사용하여 데이터를 먼저 처리
- 정규 표현식을 사용할 때는 주의
- 정규 표현식 패턴이 복잡하거나 예외적인 경우, 의도하지 않은 결과를 얻을 수 있음
- str 접근자는 문자열 데이터가 저장된 열에서만 사용할 수 있음
| 메서드 | 설명 |
|---|---|
| .str.split() | 문자열을 특정 구분자로 분리한다. |
| .str.contains() | 특정 문자열이 포함되어 있는지 확인한다. |
| .str.replace() | 문자열을 다른 값으로 대체한다. |
| .str.startswith() | 특정 문자열로 시작하는지 확인한다. |
| .str.endswith() | 특정 문자열로 끝나는지 확인한다. |
| .str.len() | 문자열의 길이를 반환한다. |
| .str.strip() | 양쪽 공백을 제거한다. |
| .str.upper() | 대문자로 변환한다. |
| .str.lower() | 소문자로 변환한다. |
| .str.extract() | 정규 표현식을 이용하여 패턴 추출한다. |
메뉴 데이터 확인
- 조식, 중식, 석식 메뉴를 분석하여 메뉴별 식수율 변화 확인
- text 데이터이기 때문에 전처리 필요
data["조식메뉴"][0]모닝롤/찐빵 우유/두유/주스 계란후라이 호두죽/쌀밥 (쌀:국내산) 된장찌개 쥐어채무침 포기김치 (배추,고추가루:국내산) - 공백으로 분리되어 있는 것을 확인
- 하지만 공백의 개수가 들쑥날쑥해 보임 → 명확한 확인을 위해 공백 대신
*로 변환
- 하지만 공백의 개수가 들쑥날쑥해 보임 → 명확한 확인을 위해 공백 대신
data["조식메뉴"][0].replace(' ', '*')모닝롤/찐빵**우유/두유/주스*계란후라이**호두죽/쌀밥*(쌀:국내산)*된장찌개**쥐어채무침**포기김치*(배추,고추가루:국내산)*- 두 칸의 공백을 한 칸으로 변경
# 전체 메뉴에 적용
data["조식메뉴"] = data["조식메뉴"].str.replace(" ", ' ')
data["중식메뉴"] = data["중식메뉴"].str.replace(" ", ' ')
data["석식메뉴"] = data["석식메뉴"].str.replace(" ", ' ')
# 확인
data["조식메뉴"][0]모닝롤/찐빵 우유/두유/주스 계란후라이 호두죽/쌀밥 (쌀:국내산) 된장찌개 쥐어채무침 포기김치 (배추,고추가루:국내산) - 한 칸의 공백을 기준으로 split
# 전체 메뉴에 적용
data["조식메뉴"] = data["조식메뉴"].str.split(' ')
data["중식메뉴"] = data["중식메뉴"].str.split(' ')
data["석식메뉴"] = data["석식메뉴"].str.split(' ')
# 확인
data["조식메뉴"][0]['모닝롤/찐빵',
'우유/두유/주스',
'계란후라이',
'호두죽/쌀밥',
'(쌀:국내산)',
'된장찌개',
'쥐어채무침',
'포기김치',
'(배추,고추가루:국내산)',
'']텍스트 분석
- 텍스트 마이닝(Text Mining)이라고도 함
- 비정형 텍스트에서 의미 있는 정보를 추출하는 데 중점을 둠
- cf. NLP: 머신이 인간의 언어를 이해하고 해석하는 데 더 중점을 둠
- 비정형 텍스트에서 의미 있는 정보를 추출하는 데 중점을 둠
- 데이터 분석을 위해 토큰화 결과(텍스트를 데이터 분석 단위로 나눈 결과)를 수치로 만드는 방법
- 원 핫 인코딩
- 단점: 희소행렬
- 따라서 텍스트 데이터는 원핫 인코딩을 잘 사용하지 않음
- BOW(Bag of Word)
- 문맥의 의미를 반영하지 않고 단어 빈도수만 고려
- CounterVecorize: 피처(수치화) → 특징 추출 → 벡터화 by 단순 빈도수
- TF-IDF: 단순 빈도수로 하면 의미 없는 데이터들만 들어가는 문제 해결
- 원 핫 인코딩
향후 진행되는 '텍스트 마이닝' 과정에서 좀 더 상세하게 다룰 예정이니 여기서는 특징만 알고 넘어가기
One-Hot Encoding
- 토큰에 고유 번호를 배정하고 모든 고유 번호 위치의 한 컬럼만 1, 나머지 컬럼은 0인 벡터로 표시
- 희소행렬 문제로 텍스트 분석에서는 잘 사용하지 않는 기법
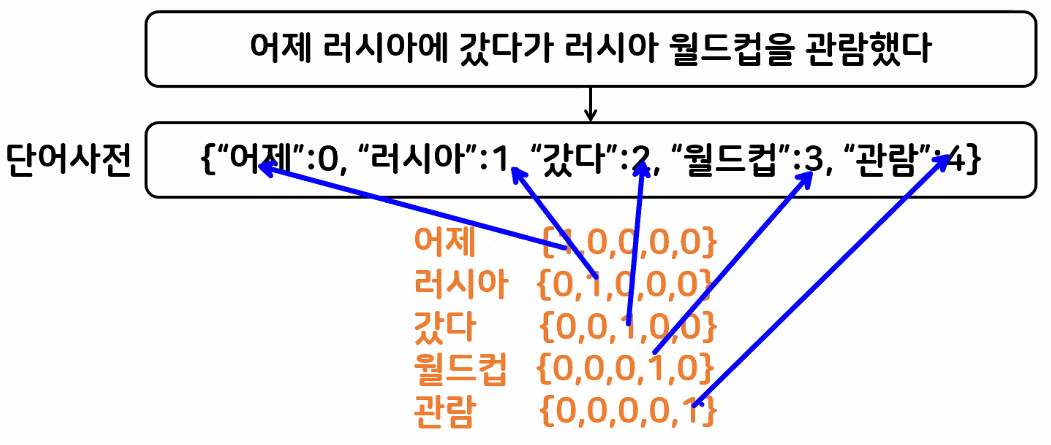
- 단어사전(데이터 사전): 단어 임베딩(단어를 벡터 공간 내의 실수 벡터로 표현) 과정에서 단어를 어떤 숫자로 바꿔줄지 정리한 것
- 단어들을 쪼개 유니크한 값들로 담아 두는 것
- 희소행렬 문제로 텍스트 분석에서는 잘 사용하지 않는 기법
BOW(Bag Of Words)
- 모든 문서의 모든 단어를 추출하여 피처로 만듦

- 단순 카운트 기반의 벡터화(CounterVectorize)
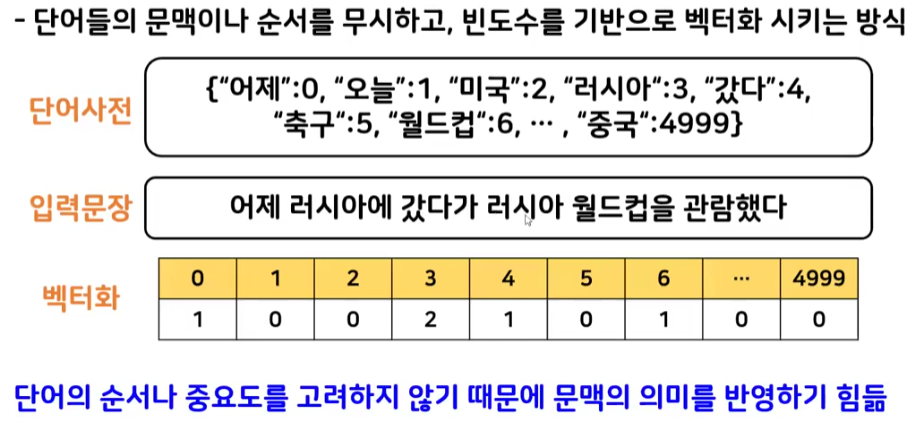
- 카운트 벡터화는 카운트 값이 높을수록 중요한 단어로 인식(분별성 X)
- 단순 지시대명사, 관사 등 중요 키워드가 아닌 의미 없는 단어가 벡터화로 인해 우선 순위에 오를 수 있음
- TF-IDF (Term Frequency-Inverse Document Frequency)
- 카운트 벡터화 보완 (패널티 부여)
- 단순 카운트 기반의 벡터화(CounterVectorize)
TF-IDF
- 개별 문서에서 자주 등장하는 단어에는 높은 가중치를 주되 모든 문서에서 자주 등장하는 단어에는 페널티를 주는 방식
- 단어의 중요도 반영
-
TF: 단어가 각 문서에서 발생한 빈도
-
DF: 단어가 등장한 문서의 수
-
적은 문서에서 상대적으로 많이 발견될수록 가치 있는 정보
-
많은 문서에서 자주 등장하는 단어일수록 일반적인 단어
- 예: 나, 그, 했다 등
-
단어가 특정 문서에서만 나타나는 희소성을 반옇가이 위해 TF에 DF의 역수(IDF)를 곱한 값을 사용
데이터 탐색(cont'd)
메인 메뉴 추출을 위한 자연어 처리
- TF-IDF (Term Frequency - Inverse Document Frequency)
- 단어 토근을 수치화하는 과정
- 특성 문서에서만 자주 등장하는 토큰은 가중치 부여
- 모든 문서에서 자주 등장하는 토큰은 패널티 부여
- 매일 등장하는 메뉴는 메인 메뉴 X → 패널티
- 특정 하루에만 등장하는 메뉴는 메인 메뉴 O → 가중치
# 자연어 처리는 시간이 부족해서 생략
# 추후 텍스트 마이닝에서 다룰 예정
data2 = pd.read_csv("./data/Cafeteria_preprocess.csv", encoding="UTF-8")
# 메인 메뉴별 중식계 식수 확인
df_lunch = pd.DataFrame(data2.groupby("중식메뉴_Main")["중식계"].mean())
df_lunch10 = df_lunch.sort_values(by="중식계", ascending=False).head(10)
df_lunch10.plot(kind="barh")
plt.xlim(1300)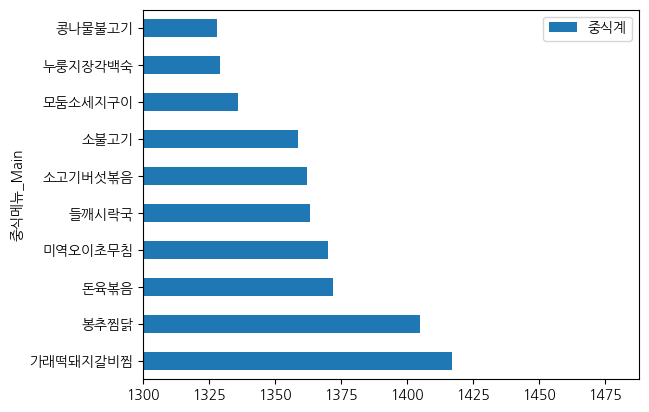
# 석식 확인
df_dinner = pd.DataFrame(data2.groupby("석식메뉴_Main")["석식계"].mean())
df_dinner10 = df_dinner.sort_values(by="석식계", ascending=False).head(10)
df_dinner10.plot(kind="barh")
plt.xlim(700)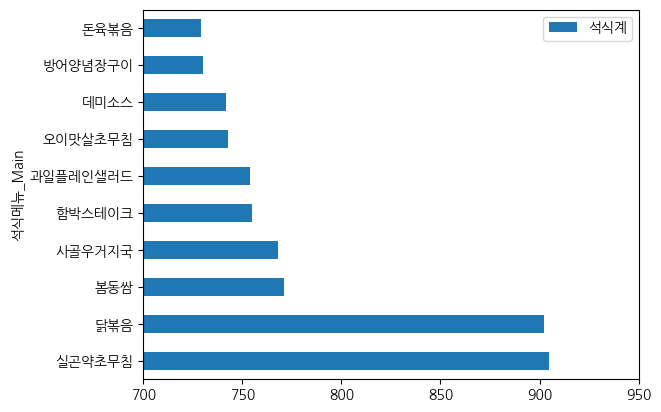
→ 전처리가 잘못 된 것 같다는 생각:
FT-IDF가 상대적으로 보기 때문에 실곤약초무침이 사실 메인이 아니라 서브 메뉴인데 빈도수 문제로 메인메뉴에 선정될 수 있음
(TF-IDF는 단어에 많이 쓰이지 메뉴를 전처리하는 방식은 아니기 때문)
하지만 단순 빈도수보다는 낫기 때문에 해당 전처리 방식을 사용한 것

모델링
- 거리 계산을 진행하는 수치 데이터의 경우 스케일링을 하는 게 좋음
모델링 준비
- 데이터 스케일링 수행
- 비지도학습 중 클러스터링 기법으로 군집화 분석을 수행하고자 함
- 데이터의 특성과 패턴을 파악할 계획
- 클러스터링 기법 중 가장 많이 사용되는 기법이 K-means 알고리즘
- 거리 계산 기반 알고리즘이므로 스케일링 진행
- 비지도학습 중 클러스터링 기법으로 군집화 분석을 수행하고자 함
- 범주형, 텍스트 데이터 인코딩 진행
- 문자열 데이터를 수치화하는 과정
- '요일', '조식/중식/석식메뉴_Main' 데이터 수치화 진행
# 불필요한 컬럼 삭제
# 이미 유의미한 데이터를 추출한 컬럼
data2.drop(["일자", "조식메뉴", "중식메뉴", "석식메뉴"], axis=1, inplace=True)- 그 외 컬럼 정보 정리
- 본사정원수(본사에 근무하는 전체 직원 수)
- 전체 직원 수는 식수에 영향을 미칠 수 있음
- 본사휴가자수(본사에 휴가 중인 직원 수)
- 휴가 중인 직원 수는 실제 식수에 영향을 미칠 수 있음
- 본사출장자수(본사에 출장 중인 직원 수)
- 출장 중인 직원 수 역시 식수에 영향을 미칠 수 있음
- 본사시간외근무명령서승인건수(본사에서 승인된 시간 외 근무 명령서 건수) == 야근
- 직원의 근무 패턴에 영향을 미쳐 식수에 영향을 줄 수 있음
- 현본사소속재택근무자수(본사 소속 중 재택 근무 중인 직원 수)
- 재택 근무 중인 직원 수는 실제로 사무실에 있는 인원 수를 반영하므로 중요
- 본사정원수(본사에 근무하는 전체 직원 수)
데이터 스케일링
- StandardScaler: 데이터 평균을 0, 표준편차 1로 변환
- 데이터가 정규분포를 따를 때
- 한쪽으로 치우치지 않음
- 이상치에 해당하는 값이 많이 없음
- 평균과 표준편차가 극단적이지 않을 경우
- 데이터가 정규분포를 따를 때
- MinMaxScaler: 데이터 최솟값 0, 최댓값 1로 변환
- 데이터가 정규분포를 따르지 않을 경우
- 이상치에 민감하게 변환(반응)
- 이상치가 너무 크거나 작을 때는 좋지 않은 결과를 낼 수 있음
- 이상치가 있을 때 이상치의 영향을 상대적으로 최소화하고 싶은 경우 사용? → 이상치 영향 완화
- 이상치가 모델에 미치는 영향을 상대적으로 줄여줄 수 있음!
- 특정 범위 내로 데이터를 변환해야 할 때 (예: 이미지처리)
- RobustScaler: 중앙값과 IQR을 활용한 스케일러
- 이상치에 강하다!
- 이상치의 영향을 무시하고 중앙값을 기준으로 스케일링
- 데이터 스케일링이란?
- 서로 다른 피처 값의 범위(최댓값 - 최솟값)가 일치하도록 조정하는 작업
- 값의 범위가 데이터마다 다르면 모델 훈련이 제대로 안 될 수도 있기 때문
- 특성(예: 키와 몸무게)의 값이 놓인 범위가 매우 다름 == 두 특성의 스케일이 다름 → 알고리즘이 거리 기반일 때 제대로 사용하려면 특성값을 일정한 기준으로 맞춰 주어야 함
- 스케일링 적용 전 데이터 분포 확인해야 함! (히스토그램)
- 서로 다른 피처 값의 범위(최댓값 - 최솟값)가 일치하도록 조정하는 작업
# 수치형 데이터 타입, 범주형 데이터 타입 분리 (for 스케일링, 인코딩)
numeric_list = [] # 수치형 컬럼명 담을 list
categorical_list = [] # 범주형 컬럼명 담을 list
for i in data2.columns:
if data2[i].dtype == 'O':
categorical_list.append(i)
else:
numeric_list.append(i)
# 숫자 데이터 → 스케일링
# 데이터의 분포 확인을 위한 히스토그램 출력해보기
data2[numeric_list].hist(figsize=(10, 10))
plt.show()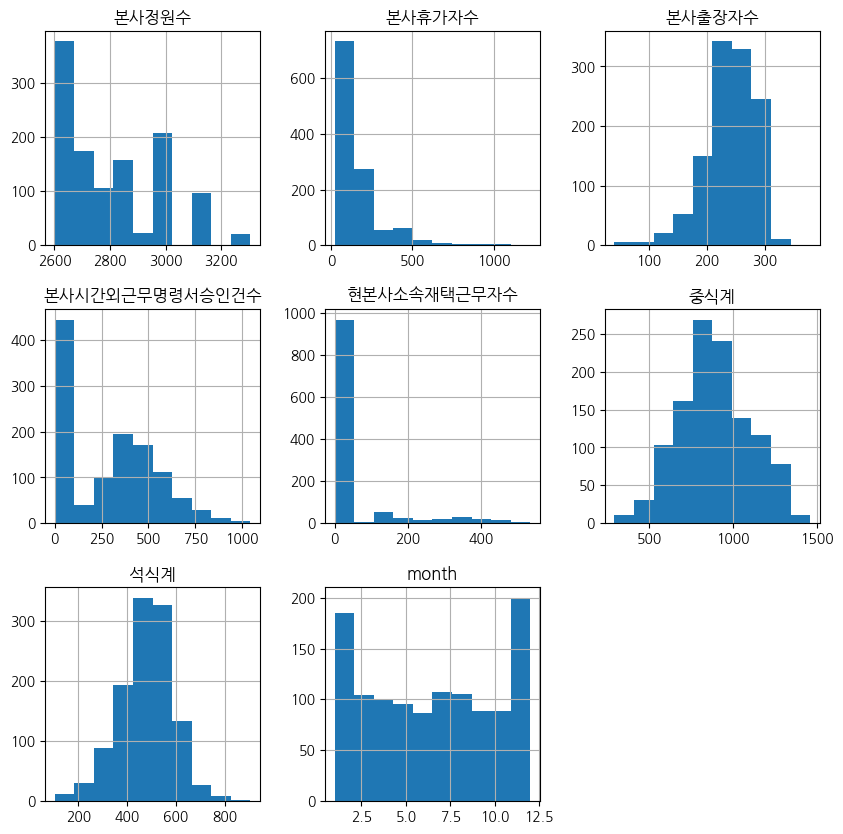
- 히스토그램 해석
| 항목 | 분포 형태 | 설명 |
|---|---|---|
| 본사정원수 | 다중 피크를 가진 비정규 분포 | 특정 구간에서 집중되는 경향이 있으며, 전체 범위가 비교적 넓음 |
| 본사휴가자수 | 오른쪽으로 치우친 비대칭 분포 | 대부분의 값이 0에서 200 사이에 집중되어 있으며, 일부 높은 값들이 존재함 |
| 본사출장자수 | 정규분포에 가까움 | 값이 평균을 중심으로 어느 정도 고르게 분포되어 있음 |
| 본사시간외근무명령서승인건수 | 오른쪽으로 치우친 비대칭 분포 | 대부분의 값이 0에서 400 사이에 집중되어 있으며, 일부 높은 값들이 존재 |
| 현본사소속재택근무자수 | 매우 오른쪽으로 치우친 비대칭 분포 | 대부분의 값이 0에 매우 가깝게 집중되어 있으며, 일부 높은 값들이 존재함 |
| 중식계 | 정규분포에 가까움 | 값이 평균을 중심으로 고르게 분포되어 있음 |
| 석식계 | 정규분포에 가까움 | 값이 평균을 중심으로 고르게 분포되어 있음 |
| month | 균등 분포 | 각 월이 조금씩 차이가 있으나, 균등하게 분포되어 있음 |
스케일링 방법 선택
- 모든 데이터가 동일한 스케일을 가지도록 하나의 스케일링 방법을 사용하는 것이 좋음
- 히스토그램을 통해 확인한 결과 정규분포를 따르지 않는 데이터가 더 많다고 판단
- 따라서 MinMaxScaler를 사용하여 스케일링을 진행
# 스케일링
from sklearn.preprocessing import MinMaxScaler
# 스케일러 객체 생성
scaler = MinMaxScaler()
# 스케일러 학습 및 변환
df_scaled = data2.copy()
# 스케일러 적용
data2[numeric_list] = scaler.fit_transform(df_scaled[numeric_list])데이터 인코딩
- One-Hot Encoding
- 각 범주 수만큼 컬럼으로 확장
- 범주에 해당하면 1, 미해당하면 0으로 채워주는 방법
- 장점: 데이터들의 수치화 진행 시 균등한 값으로 변환
- Label Encoding
- 데이터에 우선 순위를 약간 주고 싶을 때 사용
- map() 함수를 사용하여 영향을 많이 미친다고 생각하는 값에 큰 숫자를, 그렇지 않은 값에 작은 숫자를 매핑해 주는 방법
- Frequency Encoding
- 각 범주의 빈도를 확인하여 숫자로 변환하는 방법
- 장점: 범주형 데이터의 빈도를 반영
- 단점: 빈도가 같을 때 구분이 어려움
data2[categorical_list]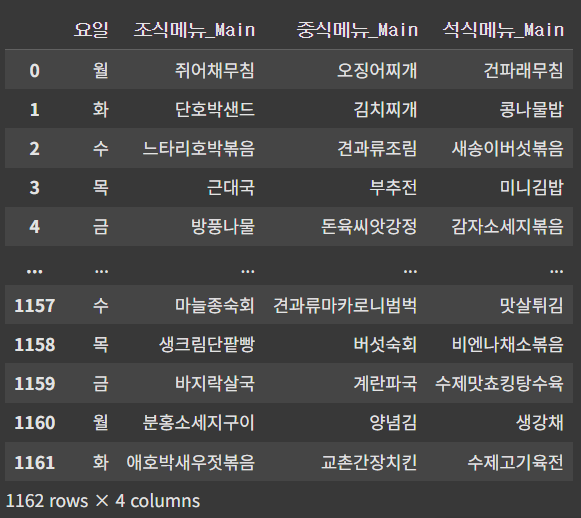
인코딩 방법 선택
- 군집화: 데이터 내의 유사한 특징을 찾아내는 것이 목적
- 요일 컬럼은 고유값이 많지 않으므로(5개의 요일) 원핫 인코딩 진행
- 메뉴 컬럼은 고유값이 많음(570개) → 단순 원핫 인코딩을 진행하면 차원이 크게 증가할 위험(희소행렬 생성)
- 메뉴의 빈도가 식수에 어떤 영향을 미치는지 분석하는 데 도움이 된다고 판단 → Frequency Encoding을 적용
# 요일 원핫 인코딩
data2 = pd.get_dummies(data2, columns=["요일"], dtype="int64")
# categorical_list에서 3개의 메인 메뉴만 추출
categorical_list[1:]
# 반복문을 활용하여 모두 딕셔너리로 변경
for col in categorical_list[1:]:
freq_map = data2[col].value_counts().to_dict()
data2[f"{col}_encoded"] = data2[col].map(freq_map)
# Main 텍스트 데이터 삭제
data2.drop(columns=["조식메뉴_Main", "중식메뉴_Main", "석식메뉴_Main"], inplace=True)K-means 알고리즘
- 가장 대표적인 군집화 알고리즘
- 비슷한 샘플끼리 군집 형성
- 원리가 쉽고 간결함
- 거리 기반 알고리즘
- 속성의 개수가 많으면 군집화 정확도가 떨어짐
- 그래서 one-hot encoding이 아닌 frequencey encoding을 사용했음
- 속성의 개수가 많으면 군집화 정확도가 떨어짐
- 단점
- 사용자가 직접 군집의 수(K수) 지정
- 정확하지 않았을 때 제대로 된 군집이 되지 않을 수 있다.
from sklearn.cluster import KMeans
# 모델 객체 생성
km_model = KMeans(
n_clusters=3 # 클러스터의 수 (군집의 수) 설정 (기본값: 8)
, random_state=10 # 고정 규칙 → 초기 중심점을 랜덤으로 결정하기 때문에 재현성을 위해 고정해 주면 좋음
, n_init = 10 # 내부적으로 10번의 학습 진행 → SSE가 가장 낮은 값을 최종 결과로 활용
, max_iter=300 # 중심점의 이동 횟수(하나의 n_init마다 300번 움직인다는 의미)
)
# 학습
km_model.fit(data2)
# 군집 결과 확인하기
print("클러스터의 개수:", km_model.n_clusters)
print("클러스터 레이블:", km_model.labels_)
print("클러스터 레이블의 고유값:", np.unique(km_model.labels_))
# 각 클러스터에 분류된 데이터 포인트 수 확인
unique, counts = np.unique(km_model.labels_, return_counts=True)
cluster_counts = dict(zip(unique, counts))
print("클러스터별 데이터 포인트 수:", cluster_counts)
print("클러스터별 데이터 포인트 수:", np.bincount(km_model.labels_))클러스터의 개수: 3
클러스터 레이블: [1 2 0 ... 1 1 1]
클러스터 레이블의 고유값: [0 1 2]
클러스터별 데이터 포인트 수: {np.int32(0): np.int64(200), np.int32(1): np.int64(490), np.int32(2): np.int64(472)}
클러스터별 데이터 포인트 수: [200 490 472]자주 활용하는 하이퍼파라미터
- n_cluster
- n_init
- max_iter
- 실시간 대응을 해야 할 때는 max_iter 크기가 크면 곤란
최적의 군집수 탐색
- 엘보우 기법
- 클러스터 수가 증가하는 동안(x축) 가파르다가 완만해지는 지점을 찾는 방법
- 가장 효율적인 클러스터 개수임을 의미
- 장점: 직관적이며 간단
- 단점
- 엘보우 지점 선택 시 사용자의 주관이 개입
- 엘보우 지점이 명확하지 않을 수 있음
# 군집화 후 각 중심점에서 군집의 데이터 간 거리를 제곱하여 합산: SSE
km_model.inertia_ # 출력: 3534.3412440404613
# 오류라고 생각하면 안 됨! (오류 개념 아님)
# 데이터 포인트틀이 중심에 얼마나 더 가까워졌는지를 확인하는 수치값
# 클러수터 수 범위 설졍
c_r = range(1, 9+1)
# 반복문을 활용하여 각 클러스터 개수에 따른 SSE를 누적
# 리스트명 = [실행문장 for i in range()]
kmeans_fit = [KMeans(n_clusters=k,n_init=20, max_iter=300, random_state=7).fit(data2) for k in c_r]
kmeans_sse = [model.inertia_ for model in kmeans_fit]
# 한 번에 쓸 수도 있음
# sse_list = [KMeans(n_clusters=k, random_state=10).fit(data2).inertia_ for k in c_r]
plt.figure(figsize=(8, 3.5))
plt.plot(c_r, kmeans_sse, marker='o', color="purple")
plt.xlabel("클러스터 수")
plt.ylabel("SSE")
plt.show()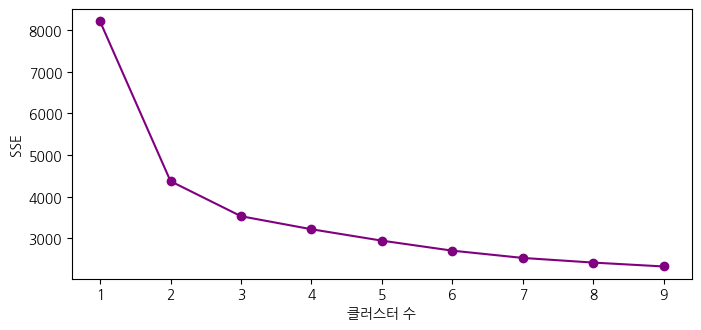
- 실루엣 분석
- 실루엣 지수를 통하여 최적화된 군집화인지 판단할 수 있음
- -1~1 사이의 값으로 출력
- 1에 가까울수록 잘 군집화된 결과
- -1에 가까울수록 잘못된 결과
# 10개의 모델들 중에서 클러스터의 개수가 3인 모델을 가져와 실루엣 지수 확인
kmeans_fit[2]
# 실루엣 지수 확인
from sklearn.metrics import silhouette_score
silhouette_score(data2, kmeans_fit[2].labels_) # 출력: np.float64(0.29610377253257636)
# 1에 가까울수록 데이터 포인트가 잘 군집화 되고, 다른 군집과는 잘 분리됨
# 0에 가까울수록 데이터포인트가 클러스터 경계에 위치하고 있음을 의미
# -1에 가까울수록 데이터 포인트가 잘 못 군집화 되어 있음을 의미
# 실루엣 지수 시각화
sil_score = [silhouette_score(data2, model.labels_) for model in kmeans_fit[1:]]
# 군집을 1로 하는 건 군집화가 아니므로 0번 인덱스 모델은 가져오면 안 됨
plt.plot(range(2, 9+1), sil_score, marker='o')
plt.grid()
plt.show()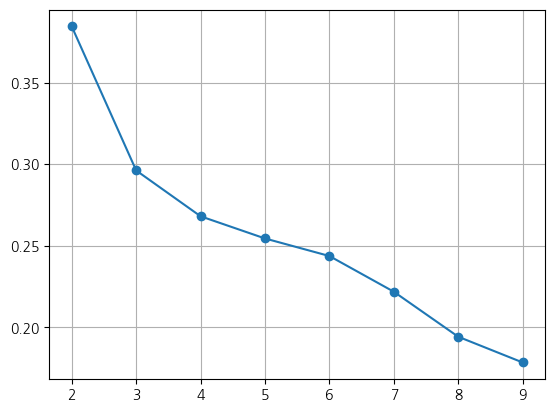
계층적 군집
- 덴드로그램 그래프 시각화하여 K 수 확인
- K-means를 확인하는 용도로 많이 사용
import scipy.cluster.hierarchy as sch
plt.figure(figsize=(12,8))
dend = sch.dendrogram(sch.linkage(data2, method="ward"))
plt.xlabel("samples")
plt.show()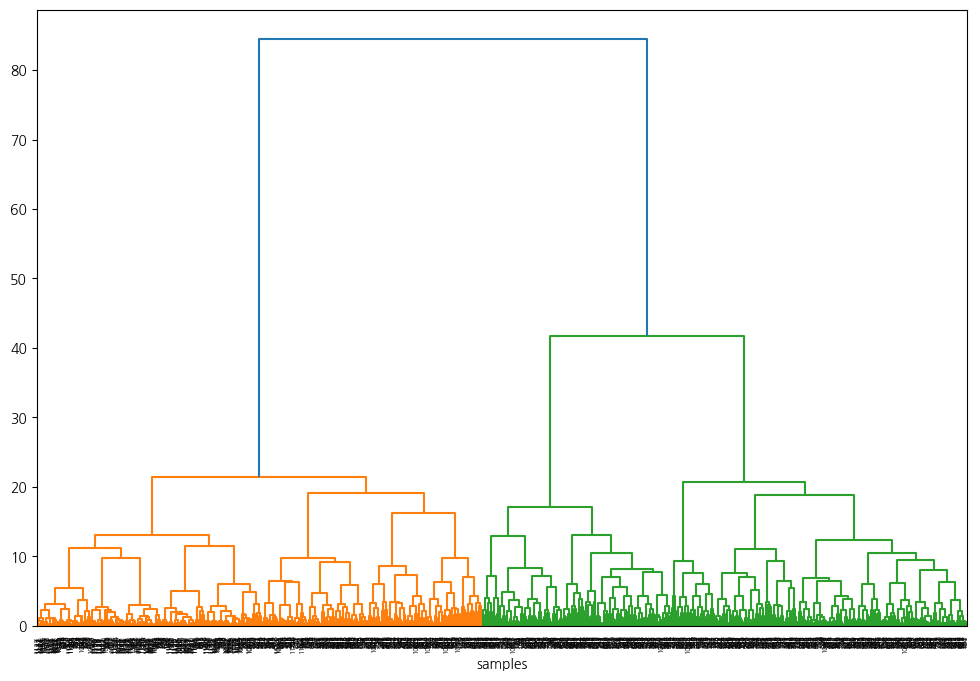
DBSCAN
- 얼마나 밀도 있게 연결되어 있는가?
- 3개의 포인트
- 코어 포인트
- 경계 포인트(보더 포인트)
- 노이즈 포인트
- epsilon(반경), min_samples(반경 내의 최소 데이터 수) → 사용자가 직접 입력해야 하는 값
- cluster의 -1 값은? 노이즈 포인트를 의미!
- 되도록 이상치 없이 나오는 게 좋음
# 이해를 돕기 위한 예시
mglearn.plots.plot_dbscan()min_samples: 2 eps: 1.000000 cluster: [-1 0 0 -1 0 -1 1 1 0 1 -1 -1]
min_samples: 2 eps: 1.500000 cluster: [0 1 1 1 1 0 2 2 1 2 2 0]
min_samples: 2 eps: 2.000000 cluster: [0 1 1 1 1 0 0 0 1 0 0 0]
min_samples: 2 eps: 3.000000 cluster: [0 0 0 0 0 0 0 0 0 0 0 0]
min_samples: 3 eps: 1.000000 cluster: [-1 0 0 -1 0 -1 1 1 0 1 -1 -1]
min_samples: 3 eps: 1.500000 cluster: [0 1 1 1 1 0 2 2 1 2 2 0]
min_samples: 3 eps: 2.000000 cluster: [0 1 1 1 1 0 0 0 1 0 0 0]
min_samples: 3 eps: 3.000000 cluster: [0 0 0 0 0 0 0 0 0 0 0 0]
min_samples: 5 eps: 1.000000 cluster: [-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]
min_samples: 5 eps: 1.500000 cluster: [-1 0 0 0 0 -1 -1 -1 0 -1 -1 -1]
min_samples: 5 eps: 2.000000 cluster: [-1 0 0 0 0 -1 -1 -1 0 -1 -1 -1]
min_samples: 5 eps: 3.000000 cluster: [0 0 0 0 0 0 0 0 0 0 0 0]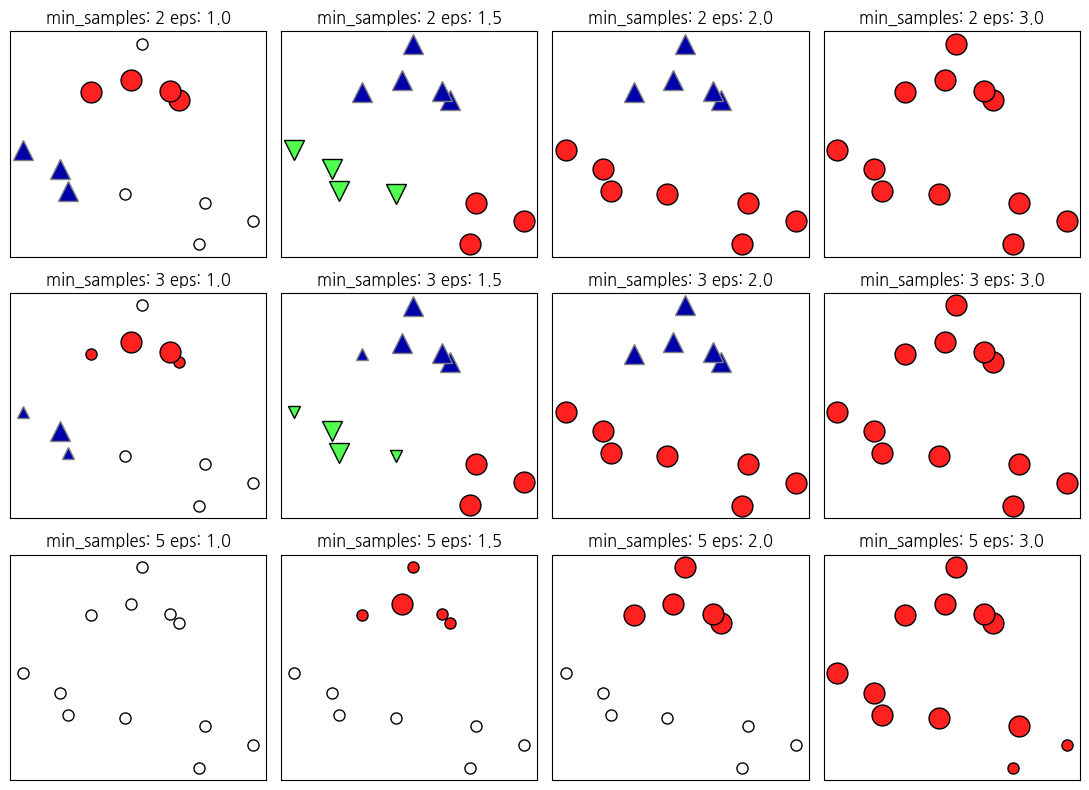
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.5, min_samples=4)
data2["dbscan_cluster"] = dbscan.fit_predict(data2)
data2["dbscan_cluster"].value_counts()
# -1: 노이즈 포인트
# 적절한 하이퍼파라미터를 찾는 게 중요함 count
dbscan_cluster
-1 639
4 45
8 44
27 44
18 42
44 36
0 13
15 10
12 10
29 10
7 9
32 9
36 9
2 9
13 9
1 8
10 8
25 8
22 8
11 7
37 7
47 7
34 7
48 7
28 7
23 7
39 6
20 6
30 6
6 6
35 6
52 5
40 5
5 5
17 5
14 5
16 5
53 5
46 5
51 5
55 4
50 4
21 4
9 4
54 4
26 4
3 4
19 4
24 4
41 4
31 4
38 4
33 4
43 4
45 4
42 4
49 4
dtype: int64하이퍼파라미터 설정 팁
-
MinPts 설정하기
- 일반적 가이드라인
- 데이터 셋 크기가 클수록 MinPts 값을 크게 잡는 것이 유리 (너무 작으면 노이즈가 많아짐)
- 데이터에 Noise가 많은 경우에도 MinPts를 크게 잡는 것이 유리
- 도메인 지식이 있다면 이를 활용해 설정
- Rule of thumb
- 데이터 포인트 차원 D에 대해 MinPts ≥ D+1 로 지정
- 보통 MinPts = 2 * D (차원의 2배수)로 둔다고 하는데, 항상 옳은 값은 아님
- 일반적 가이드라인
-
Eps 설정하기
- K-NN 알고리즘을 활용한 Epsilon 값 설정
- K-NN: 특정 포인트 주변 k개의 데이터 포인트를 이용해 예측 또는 분류하는 알고리즘
- K개 이웃 점과의 평균 거리를 순서대로 정렬해 갑자기 값이 확 커지는 지점(Elbow Point)의 거리를 Eps로 설정
- K는 보통 MinPts(또는 MinPts - 1)값을 사용
- K-NN 알고리즘을 활용한 Epsilon 값 설정
DBSCAN 강의
파이썬 사이킷런 DBSCAN 군집화 과정
dbscan = DBSCAN(eps=3, min_samples=17)
cluster, counts = np.unique(dbscan.fit_predict(data2), return_counts=True)
cluster, counts(array([-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]),
array([ 22, 673, 50, 52, 116, 19, 42, 102, 23, 27, 36]))dbscan = DBSCAN(eps=2, min_samples=17)
cluster, counts = np.unique(dbscan.fit_predict(data2), return_counts=True)
cluster, counts(array([-1, 0, 1, 2, 3, 4, 5]),
array([307, 644, 45, 44, 42, 44, 36]))추가: scatter_matrix
dbscan = DBSCAN(eps=3, min_samples=17)
cluster, counts = np.unique(dbscan.fit_predict(data2), return_counts=True)
cluster, counts # dict(zip(cluster, counts))로 묶어도 OK
data2["dbscan_cluster"] = dbscan.fit_predict(data2)
pd.plotting.scatter_matrix(
data2[numeric_list] # 문제 데이터(좌표 역할)
, figsize=(10,10) # 그래프의 크기
, c=data2["dbscan_cluster"] # 클래스별 색상 지정
, alpha=0.5 # 그래프 산점도 점 투명도 → 겹치는 걸 보여주려고
)
plt.show()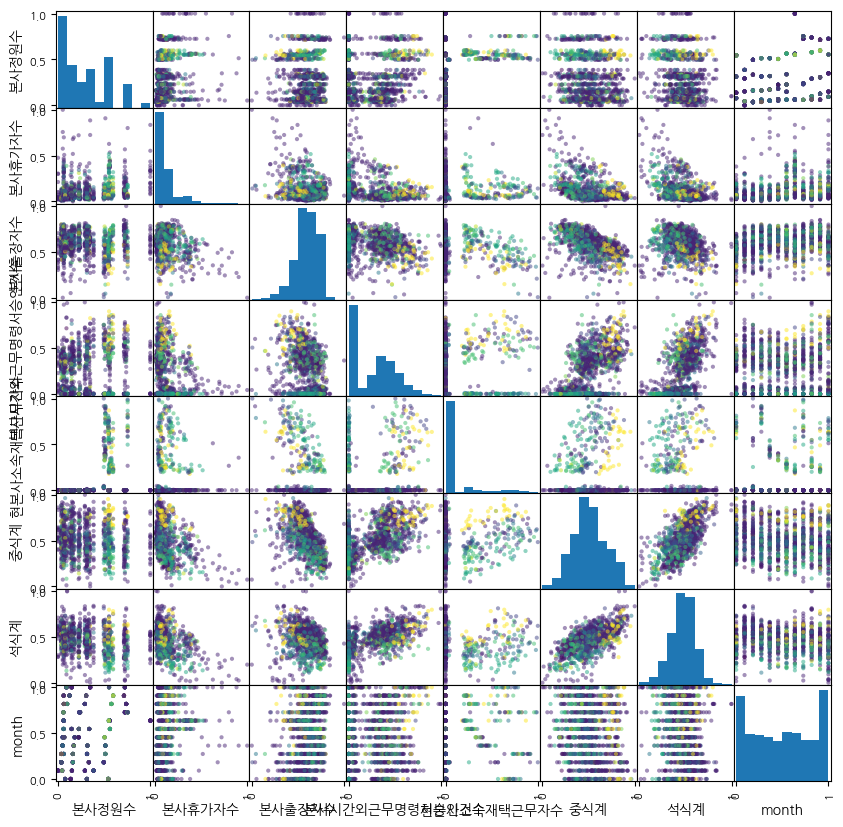
하루 돌아보기
👍 잘한 점
- 수업 과정에서 궁금했던 부분 스스로 찾아 추가
- 보충 수업 참여함
- 야간자율학습 진행
👎 아쉬웠던 점
- 그래프 그리는 것에 꽂혀서 수업 중에 강사님 설명을 몇 개 놓쳤음...
🔬 개선점
- 구글 드라이브 폴더 관리 잘 하기!
- 관리를 잘 해야 나중에 수업 자료 보기가 쉬움
- 지급받은 교재 활용 잘 하기
- 수업 중에는 수업에만 집중하기

2 B R 0 2 B