코딩테스트 연습
머신러닝 복습
- AI vs. ML vs. DL
- 인공지능: 기게(컴퓨터)가 인간이 가지는 지능을 갖는 것
- 머신러닝: 기계가 데이터를 기반으로 스스로 학습하여 새로 들어온 데이터에 대해 예측하는 과정
- 딥러닝: 인간의 신경망을 모방하여 학습
- 머신러닝 학습 3가지 종류
- 지도학습
- 정답 데이터(label)가 있는 상태에서 학습
- 비지도학습
- 정답 데이터(label)가 없는 상태에서 학습
- 강화학습
- 보상을 주는 방향으로 학습
- 지도학습
- 지도학습
- 정답 데이터의 형태에 따라 2가지로 구분
- 분류(범주형): 정답 데이터가 카테고리컬한 형태, class: 정답의 고유값들
- 이진분류: class의 개수가 2개
- 다중분류: class의 개수가 3개 이상
- 회귀(연속형)
- 분류(범주형): 정답 데이터가 카테고리컬한 형태, class: 정답의 고유값들
- 정답 데이터의 형태에 따라 2가지로 구분
- 비지도학습
- K-means
- 군집 중심점(Centroids)을 임의로 지정
- 가까운 데이터들의 평균점으로 이동하면서 군집화하는 방법
- 사용자가 초기에 K개의 개수(군집의 개수)를 미리 지정
- 계층적 군집, 계층 클러스터링
- 사용자가 이미 군집화된 결과를 보고 K개의 개수를 정함
- DBSCAN
- 반경(epsilon), 최소샘플수(min_samples)
- 코어 포인트, 경계 포인트, 노이즈 포인트
- K-means
- 평가지표(Performance measure) ★★
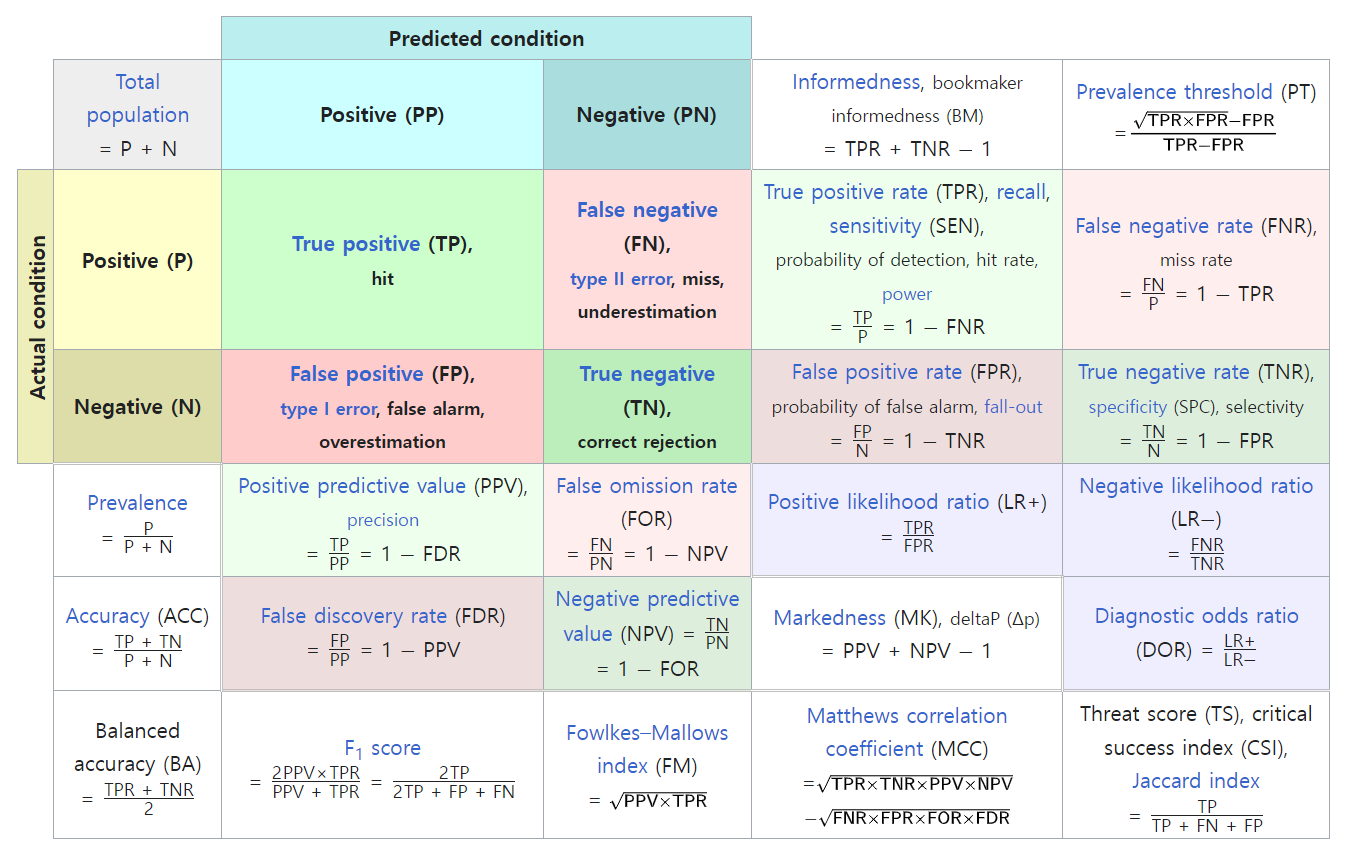
- 분류
- accuracy(정확도): 전체 데이터 중에서 정답을 맞춘 비율
- recall(재현율)
- precision(정밀도)
- f1-score: 재현율과 정밀도의 조화 평균
- 회귀
- MSE(평균제곱오차; mean_squared_error): 실제 데이터와 예측 데이터의 차이 제곱 평균
- RMSE
- MAE
- R2 score: 오차 기반이 가지는 문제점(오차가 큰 건지 작은 건지 알기 어려움)을 보완 → 정규화된 지표
- 비지도학습: 명확한 정답이 없기 때문에 다양한 지표를 활용하여 판단
- 엘보우 기법: 군집의 개수가 증가함에 따라 SSE의 변화를 판단 → 급격하게 감소하다가 완만해지는 지점을 사용자가 선택 → 주관이 개입할 수 있으므로 실루엣 분석도 함께 봐야 함
- 실루엣 분석: 응집도, 분리도 계산하여 군집이 잘 된 정도를 파악 → -1부터 1 사이의 값: 1에 가까울수록 잘 군집, -1에 가까울수록 잘못된 군집
- 분류
- 학습에 사용하는 오차값 → loss function ★★
- 학습의 목표: 손실 함수의 결과값(오차값)을 가장 작게 만드는 가중치를 구하는 것
- 회귀: 평균 제곱 오차(MSE)
- 분류: 교차 엔트로피 오차(Cross-entropy error) ★★★
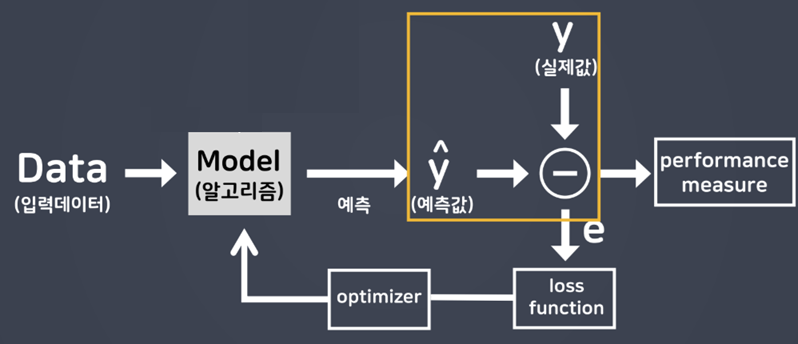
- loss function(손실 함수)
- 실제값과 예측값에 대한 오차에 대한 식
- 목적 함수(Objective function) 또는 비용 함수(Cost function)이라고도 함 (엄밀히는 같은 의미가 아니지만 세 가지 용어를 같은 의미로 혼용해서 쓰는 경우가 많음)
- 함수의 값을 최소화하거나, 최대화하거나 하는 목적을 가진 함수 → 목적 함수
- 값을 최소화하려고 하면 → 비용 함수 또는 손실 함수
- 최적의 매개변수 값을 찾기 위한 지표
- 단순히 실제값과 예측값에 대한 오차를 표현하면 되는 것이 아니라, 예측값의 오차를 줄이는 일에 최적화 된 식이어야 함
- 예:
- 평균제곱오차(MSE)
- 오차제곱합(SSE)
- 교차 엔트로피 오차(CEE)
- 적절한 매개변수를 찾기 위한 지표로 왜 정확도가 아닌 손실 함수를 설정할까? "미분"의 역할 때문
- 최적의 매개변수를 탐색할 때 매개변수에 대해 미분(기울기)을 계산하고 미분 값을 갱신하는 과저을 반복함으로써 손실 함수의 값을 가능한 작게 하는 매개변수를 탐색 → 미분 값이 양수이면 매개변수를 음의 방향으로 갱신하고, 음수이면 양의 방향으로 갱신
- 반면 정확도를 지표로 삼으면 대부분의 미분 값이 0이 되므로 갱신할 수 없음
- 즉, 손실함수는 매개변수의 값이 조금 변하면 그에 연속적인 값으로 반응하지만 정확도는 거의 반응을 보이지 않기 때문
- 실제값과 예측값에 대한 오차에 대한 식
- 회귀모델의 경우 loss function, performance measure 모두 동일한 지표(MSE) 사용
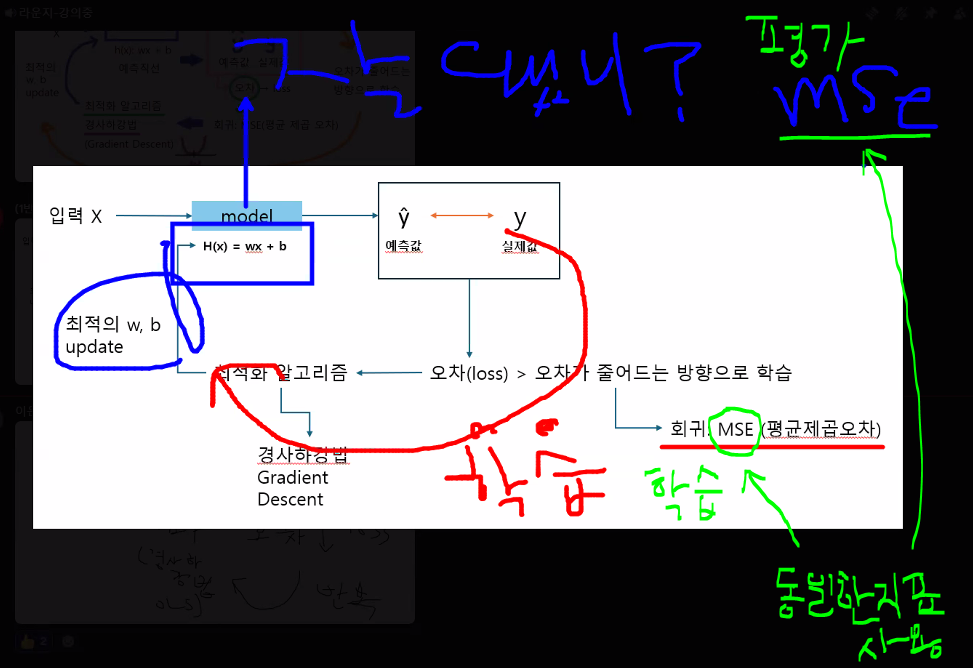
- 분류모델
- 최적화 알고리즘
- 경사하강법(Gradient Descent)
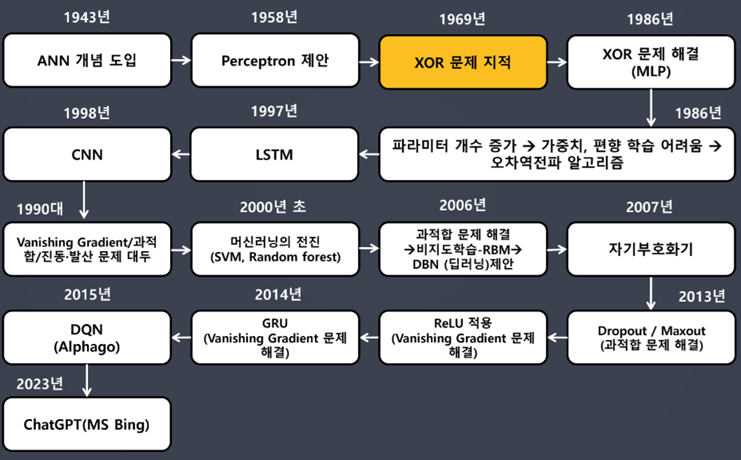
딥러닝 개요
학습 목표
- 딥러닝의 개념을 이해해보자.
- 딥러닝의 역사를 알아보자.
- 딥러닝 개발 환경을 구축해보자.
딥러닝 개념
AI vs. ML vs. DL
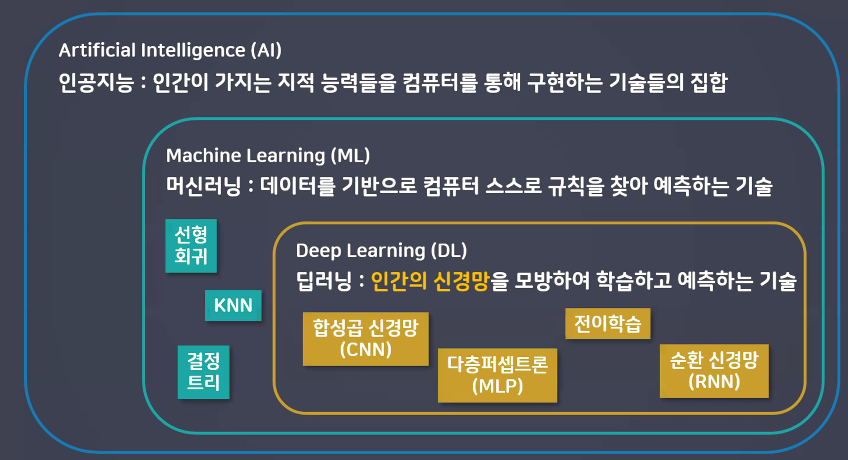
딥러닝이란?
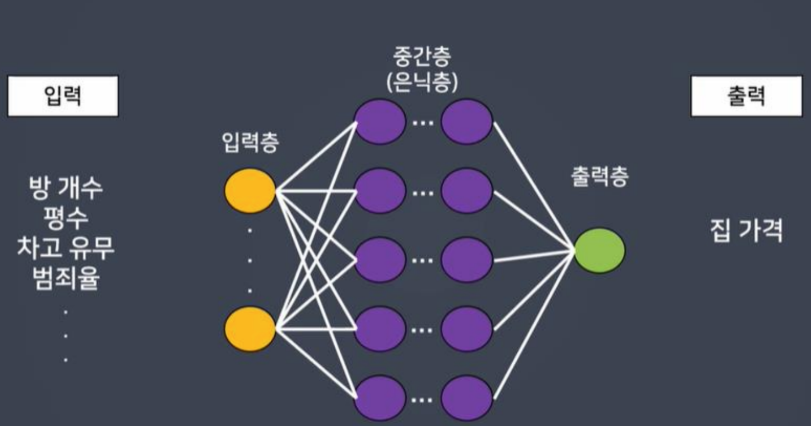
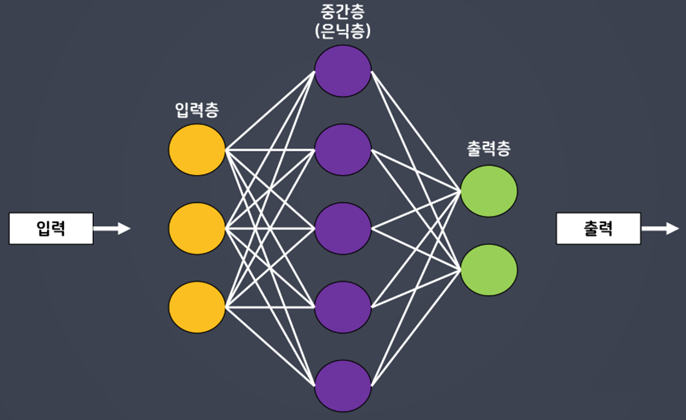
- 사람의 신경망을 모방하여 기계가 병렬적 다층 구조를 통해 학습하도록 만든 기술
- 병렬적 다층 구조: 입력층 - 연산층 - 출력층
- 연산층 == 중간층 == 은닉층
- 병렬적 다층 구조: 입력층 - 연산층 - 출력층
ANN(Artificial Neural Network)
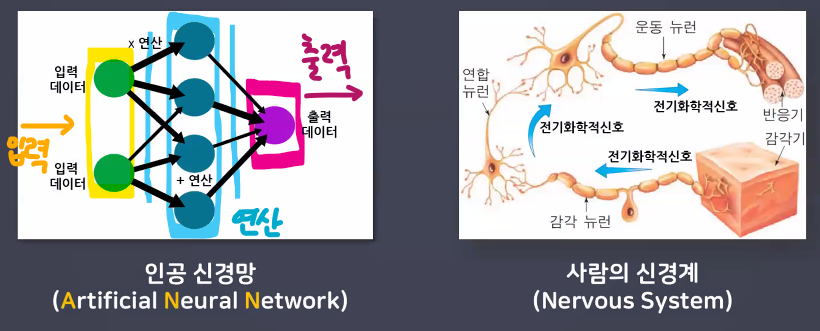
- 구성(층)을 쌓아서 학습
- 입력층과 출력층 반드시 설계해야 함
- 입력층은 입력받는 데이터의 형태를 지정
- 은닉층: 내부적으로 어떤 관계를 가지고 있는지 연산해주는 층
- 출력층은 결과를 내보내는 형태에 대해 지정해주는 것
- 딥러닝은 데이터에 따라 신경망 설계를 다르게 구성해 줘야 함
- 머신러닝은 기계처럼 학습: 정형된 틀 안에서 판단
- 인간의 사고를 담은 텍스트 데이터 등을 잘 판단하지 못함
- 기계는 판단하는 기준이 명확히 정해져 있음
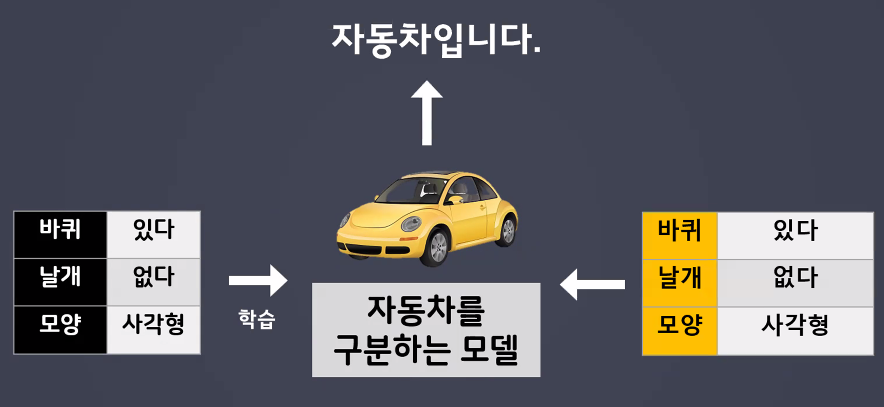
- 찌그러진 사각형은 기준에 맞지 않으므로 자동차가 아니라고 판단
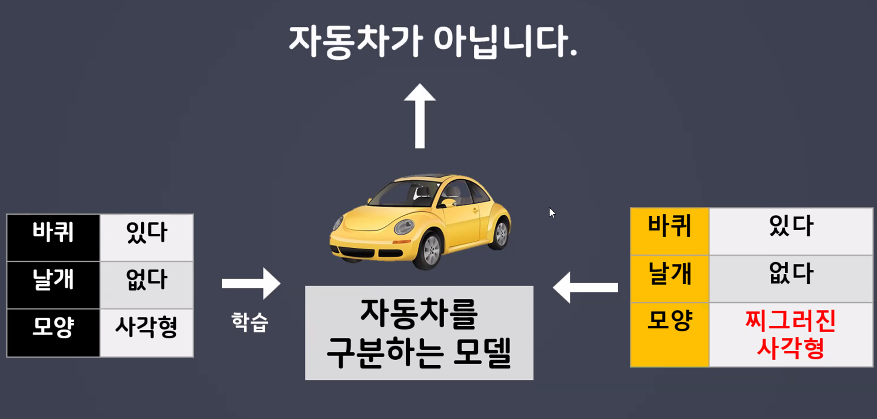
- 하지만 사람은 대상을 판단하는 경계가 느슨함(추상적)
- 유연한 사고/인간적인 사고
- 찌그러진 사각형은 기준에 맞지 않으므로 자동차가 아니라고 판단
- 인간의 신경망
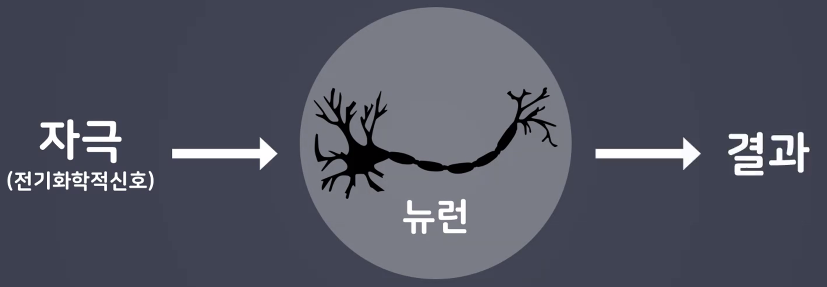
- 많은 뉴련의 결과를 종합하여 판단을 한다.
- 많은 뉴련의 결과를 종합하여 판단을 한다.
- 딥러닝 → 인간의 신경망(뉴런)을 모방

- 많은 모델(전문가)들의 의견을 종합적으로 판단하여 학습하고 예측한다.
- 대량의 데이터에서 복잡한 패턴이나 규칙을 찾아내는 능력이 뛰어나다.
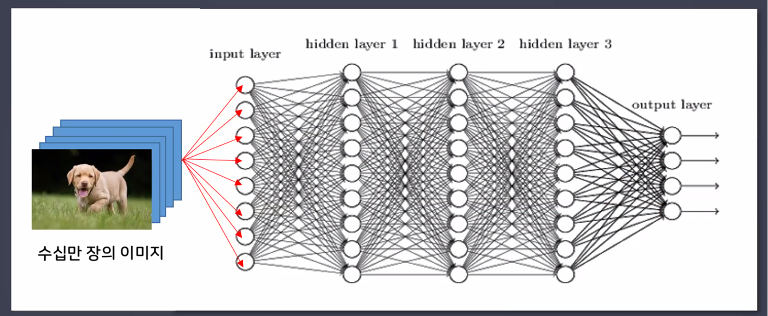
- 동그라미 하나 하나가 퍼셉트론(딥러닝 신경망의 가장 작은 구성 단위)
- 입력받는 데이터 형태, 결과를 내보내는 형태를 직접 설정해야 함 → 데이터에 따라 신경망 설계하기!
- 활용 예시
- 많은 모델(전문가)들의 의견을 종합적으로 판단하여 학습하고 예측한다.
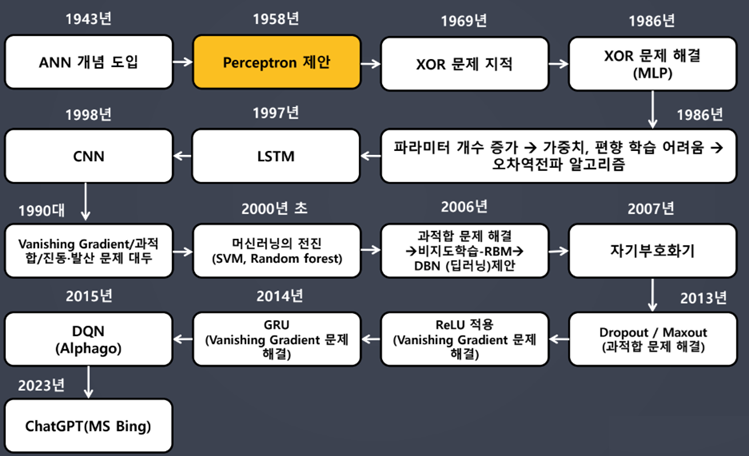
딥러닝 역사
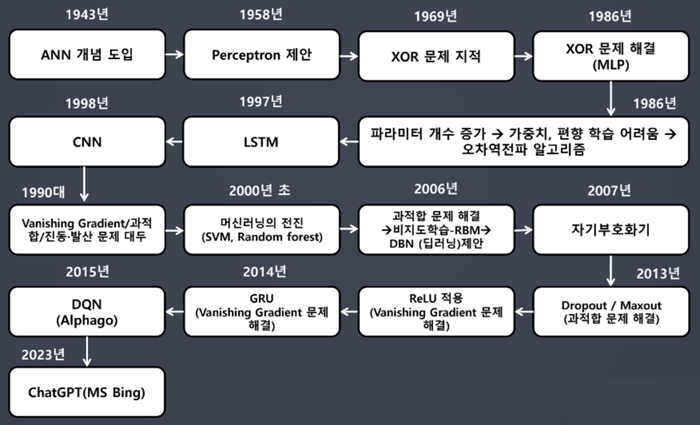
- 퍼셉트론(Perceptron) 개념 꼭 알아두기
- 딥러닝을 구성하는 가장 작은 단위
- 선형 모델을 근간으로 함
학습 로드맵
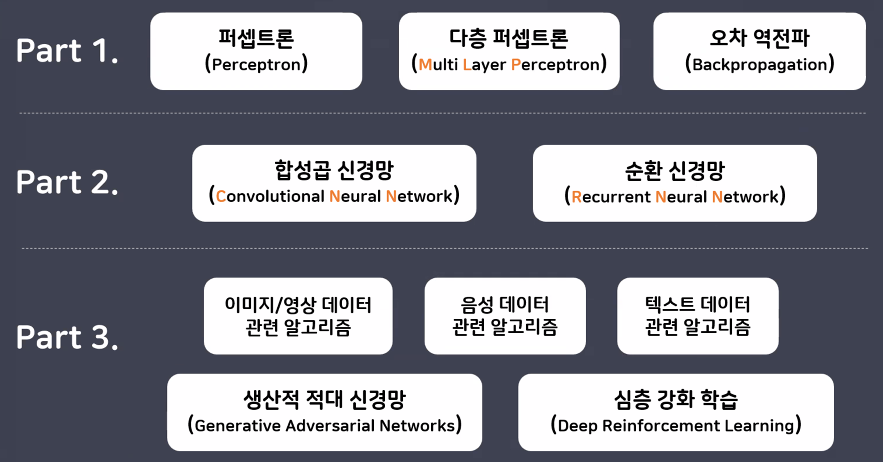
기존 머신러닝과의 비교
- 기존 머신러닝(선형모델)과 딥러닝의 공통점: 과정이 동일함
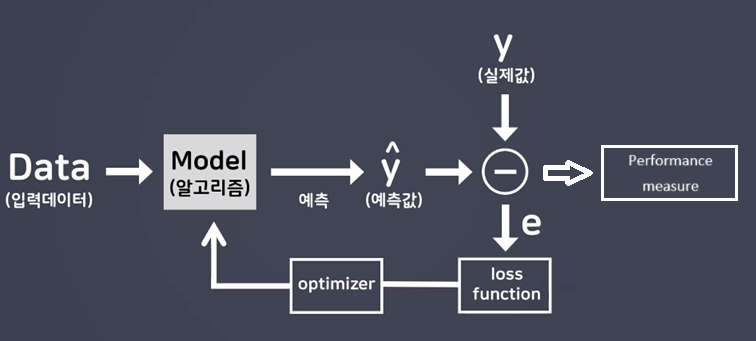
- optimizer == 최적화함수
- 예: 경사하강법(GD)
- optimizer == 최적화함수
- 기본적인 흐름은 동일하고 사용하는 알고리즘이 달라짐!
- 머신러닝
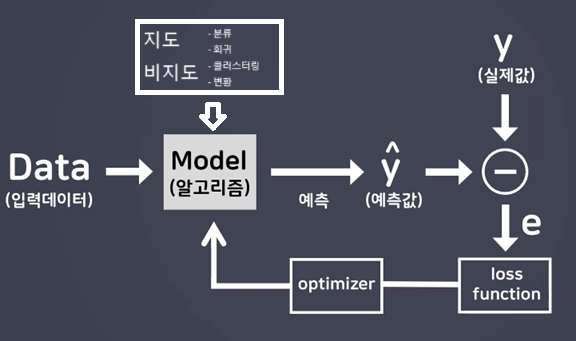
- 딥러닝
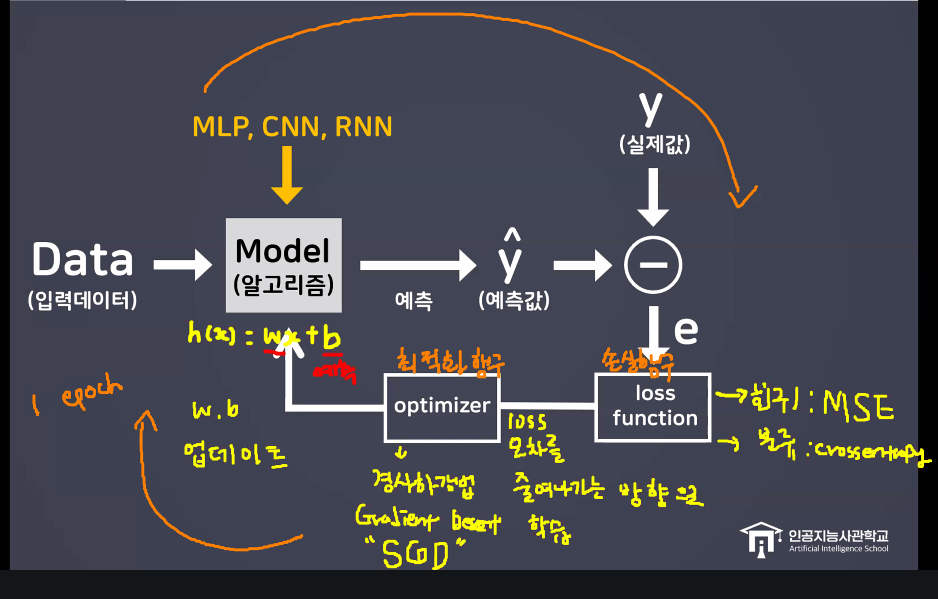
- h(x): 가설함수(Hypothesis Function) → 학습 데이터를 기반으로 예측 모델을 표현하는 함수
- 가설 함수를 사용해 훈련 데이터로부터 패턴을 학습하고 새로운 데이터에 대한 예측을 수행
- 학습 과정은 가설 함수의 파라미터를 조정하여 데이터에 가장 잘 맞는 함수를 찾는 과정
- 머신러닝
- 기존 머신러닝과 딥러닝의 차이점
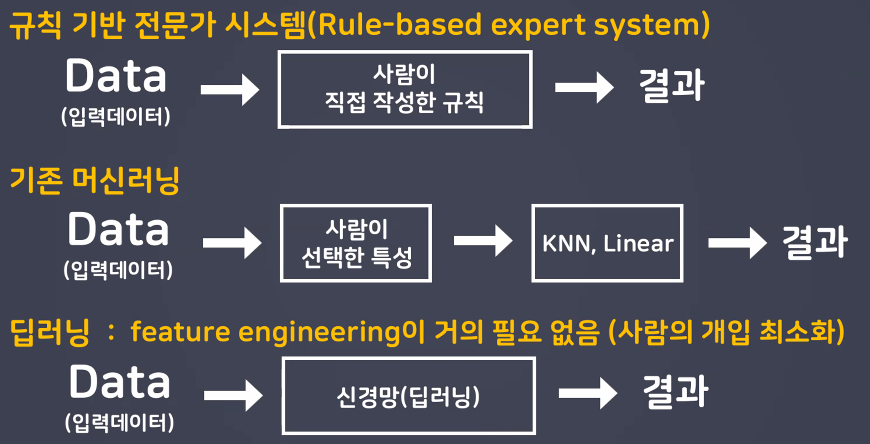
- 머신러닝에서는 특성 추출(Feature Extraction) 과정을 사람이 직접 해 줘야 함
- 딥러닝은 입력 특성을 사람이 선택하지 않고 모델이 직접 선택
- 따라서 특성을 사람이 직접 추출하기 어려운 데이터에 대해 자주 사용(음성, 이미지 등)
- 그렇다면 무조건 딥러닝이 좋을까?
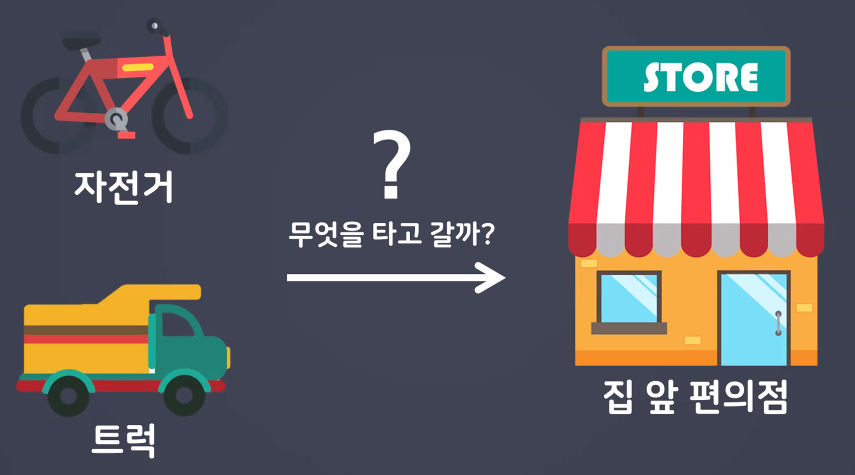
- 똑같은 일을 할 때 머신러닝이 더 편한 경우도 있음 → 적재적소인 분야가 각자 존재함!
- 딥러닝은 처리 시간 오래 걸림 & 모델 설계도 어려움
- 똑같은 일을 할 때 머신러닝이 더 편한 경우도 있음 → 적재적소인 분야가 각자 존재함!
- 딥러닝(Deep Learning)
- 컴퓨터 비전, 음성 인식, 자연어 처리, 신호 처리 등의 분야에 적용 → 복잡한 데이터
- 모든 문제를 딥러닝으로 해결하지는 않는다 → 기존 머신러닝 모델이 더 잘 동작하는 경우도 있음 (단순 수치형 데이터 등)
딥러닝 프레임워크
- Theano
- Tensorflow
- Caffe
- Keras
- 사용자들이 어떻게 하면 코딩을 쉽게 할 수 있을까 고민하며 만들어진 라이브러리
- 실제로 Keras에서는 다양한 류럴 네트워크 모델을 미리 지원해주고 있으므로, 그냥 블록을 조립하듯이 네트워크를 만들면 되는 식
- 전반적인 네트워크 구조를 생각하고 작성한다면 빠른 시간 내에 코딩을 할 수 있는 엄청난 장점
- 현재는 tensorflow 위에서 keras가 동작하도록 설계되어 있고, keras를 tensorflow 안에 포함시켜 표준 라이브러리로 지원하고 있음
- Pytorch
- DeepLearning4J
- Mxnet
추가: 가설 함수
- 데이터에 가장 잘 맞는 선(최적선)을 찾기 위해 시도해보는 모든 함수
- 머신 러닝에서의 역할:
- 머신 러닝 모델은 가설 함수를 사용하여 훈련 데이터로부터 패턴을 학습하고, 새로운 데이터에 대한 예측을 수행합니다.
- 학습 과정은 가설 함수의 파라미터를 조정하여 데이터에 가장 잘 맞는 함수를 찾는 과정입니다.
- 예시:
- 선형 회귀에서 가설 함수
- 일반적으로 선형 함수 (예: y = wx + b) 형태로 표현
- 여기서 w와 b는 학습을 통해 조정되는 파라미터
- 선형 회귀에서 비용 함수: 맨 앞에 2를 나누는 것은 미분했을 때 계산의 편의성을 위함
- 다항 방정식에서의 가설 함수 등 더 알아보기
- 선형 회귀에서 가설 함수
- 다양한 형태:
- 가설 함수는 선형 함수 외에도 다양한 형태로 표현될 수 있습니다. 예를 들어, 로지스틱 회귀에서는 시그모이드 함수, 신경망에서는 복잡한 구조의 함수 등이 사용될 수 있습니다.
- 평가:
- 가설 함수의 성능은 손실 함수(cost function)를 사용하여 평가됩니다. 손실 함수는 예측값과 실제값의 차이를 계산하여 가설 함수의 정확도를 측정합니다.
- 최적화:
- 학습 과정은 손실 함수를 최소화하는 방향으로 가설 함수의 파라미터를 조정하는 과정입니다. 경사 하강법과 같은 최적화 알고리즘이 일반적으로 사용됩니다.
- 가설 함수와 가정 함수:
- 가설 함수는 머신 러닝 모델에서 사용되는 함수를 의미하며, 가정 함수는 통계학에서 모델링을 위해 설정하는 함수를 의미합니다. 두 용어는 유사하지만, 사용되는 맥락이 다릅니다.
실습: 학생 성적 데이터 예측 (회귀)
학습 목표
- 딥러닝 개념에 대해 이해하고 딥러닝 구조를 설계할 수 있다.
- 머신러닝과 딥러닝의 차이를 알고 목적에 맞는 모델을 사용할 수 있다.
딥러닝이란?
- 인간의 신경망을 모방하여 학습하고 예측하는 기술
- 대량의 데이터에서 복잡한 패턴이나 규칙을 찾아내는 능력이 뛰어나다
- 머신러닝에 비해 조금 더 유연한 사고를 한다~
- 인간의 뉴런 == 딥러닝의 퍼셉트론(선형모델을 근간으로 함)
- 퍼셉트론은 선형 모델로 구성되어 있음
- 주로 음성처리, 영상처리, 이미지처리, 신호처리 등에 사용된다.
- TensorFlow
- google이 만든 딥러닝 라이브러리
- Keras
- tensorflow 위에서 작동하는 라이브러리로 사용자 친화적 라이브러리
- 교육용에 좋음
- 리눅스 기반으로 만들어진 거라 코랩에서 쓰기 좋음(코랩도 리눅스 기반)
- 코랩이 리눅스 기반? 명령어 생각해보면 됨: %cd, !pwd, !ls
머신러닝 모델과 딥러닝 모델 비교
- 동일한 데이터를 가지고 머신러닝 모델링, 딥러닝 모델링 후 학습과정 및 결과 차이 확인
- 머신러닝
- 모델 생성 → 모델 학습 → 모델 예측 → 모델 평가
- 모델 생성 과정에서 완성된 객체 사용
- 완제품로봇 - 팔다리 정도만 움직일 수 있음(하이퍼 파라미터 조절)
- 딥러닝
- 모델 생성 → 모델 학습 → 모델 예측 → 모델 평가
- 모델 생성 과정에서 모델을 직접 구성
- 조립식로봇, 레고블럭(우리가 구성하고 싶은 대로 만들 수 있음)
- 다양한 결과를 만들어 낼 수 있음
- 머신러닝
- 학생 성적 데이터 예측
- 성별, 나이, 부모의 교육수준/직업, 결석 횟수 등
- 공부시간에 따른 수학성적을 예측하는 회귀모델을 만들어 보자!
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 데이터가 세미콜론(;)으로 구분되어 있음 → delimiter 지정 필요
data = pd.read_csv("./data/student-mat.csv", delimiter=';')
data.info()
# 공부시간에 따른 학생 성적 예측
# 문제 데이터: studytime
# 정답 데이터: G3(3학년 성적)
# 문제와 정답으로 분리
X = data["studytime"] # 딥러닝에 바로 쓸 거라 2차원([[]])으로 만들지 않았음
y = data["G3"]
# 크기 확인 꼭 하고 다음 단계로 넘어가기
X.shape, y_shape((395,), (395,))# train, test 나누기~
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=11)
# 크기 확인
print('훈련용 문제: ',X_train.shape)
print('훈련용 답: ',y_train.shape)
print('테스트용 문제: ',X_test.shape)
print('테스트용 답: ',y_test.shape)훈련용 문제: (316,)
훈련용 답: (316,)
테스트용 문제: (79,)
테스트용 답: (79,)머신러닝 모델링
- sklearn 모델링: LinearRegression
- 평가지표: MSE 확인
- 주의사항: 머신러닝에 넣을 X_train은 2차원이어야 함
# X 문제 데이터 변경 (머신러닝 학습을 위하여)
ml_X_train = X_train.values.reshape(-1, 1)
ml_X_test = X_test.values.reshape(-1, 1)
ml_X_train.shape, ml_X_test.shape((316, 1), (79, 1))from sklearn.linear_model import LinearRegression
# 모델 객체 생성
ml_model = LinearRegression()
# 모델 학습
ml_model.fit(ml_X_train, y_train)
# 모델 예측
ml_y_pred = ml_model.predict(ml_X_test)
# 모델 평가(R2 score)
ml_model.score(ml_X_test, y_test)
# 출력: 0.00902064205225106
# 모델 평가(mse)
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, ml_y_pred)
# 출력: 24.114413256338526딥러닝 모델링
신경망 모델링
- 신경망 구조 설계
- 신경망 학습 방법 및 평가 방법 설정
- 신경망 모델 학습 및 학습 결과 시각화
- 신경망 모델 예측 및 평가
4가지 순서 꼭 지키기!
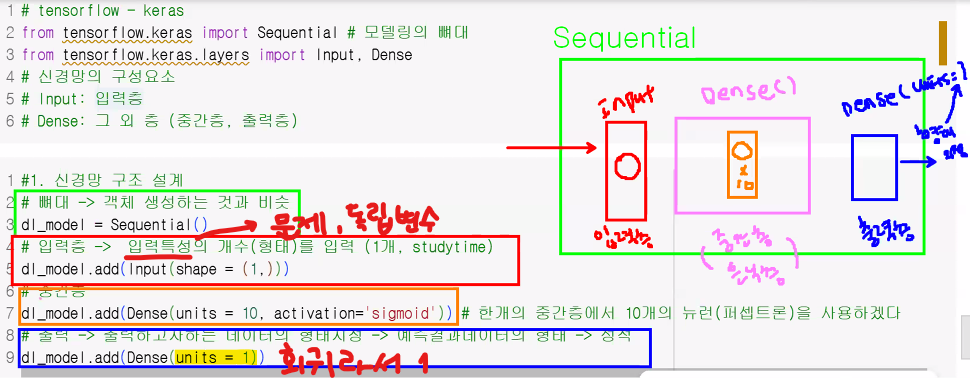
# tenseoflow - keras
from tensorflow.keras import Sequential # 모델링의 뼈대
from tensorflow.keras.layers import Input, Dense
# 신경망의 구성 요소
# Input:입력층
# Dense: 그 외 층(중간층, 출력층)
# 1. 신경망 구조 설계: 단층 설계로 설계해봅시다.
# 뼈대 깔기 → 머신러닝에서 객체 생성하는 것과 비슷
dl_model = Sequential()
# 입력층 쌓기 → 입력 특성(=문제 데이터, 독립 변수)의 개수(형태)를 입력 (1개, study)
dl_model.add(Input(shape=(1,)))
# 중간층 쌓기
dl_model.add(Dense(
units=10 # 한 개의 중간층에서 10개의 뉴런(퍼셉트론)을 사용하겠다는 의미
, activation="sigmoid" # 활성화함수(사람처럼 행동할 수 있도록 도와준다고 생각하면 됨)
))
# 출력층 쌓기 → 출력하고자 하는 데이터의 형태를 지정: 예측 결과 데이터의 형태 → 성적(수치 데이터 1개)
dl_model.add(Dense(units=1))
# 2. 신경망 학습 방법 및 평가 방법 설정
dl_model.compile(
loss = "mean_squared_error"
, optimizer = "SGD"
, metrics = ["mse"]
)
# 3개를 입력해 주어야 함:
# loss → 모델이 학습을 하기 위해 사용하는 오차/손실함수(loss function)/비용함수(cost function)
# 각 문제들에는 적합한 비용 함수들이 존재 → 회귀: mse
# optimizer → 최적화 함수. 오차/손실/비 줄여나가는 방법을 정의 → 경사하강법 사용 → 확률적경사하강법(SGD)
# metrics → 평가지표 → 회귀: mse
# 3. 모델 학습 및 학습 결과 시각화
dl_model.fit(
X_train
, y_train
, epochs = 20 # 모델의 최적화 횟수 (w, b값의 업데이트 횟수)
, validation_split = 0.2 # 훈련 데이터에서 20%를 검증 데이터로 사용 → 평가하기 전에 과적합인지 아닌지 확인하기 위함
)
# 시각화
plt.figure(figsize = (5,3))
plt.plot(dl_model.history.history["loss"], label="loss")
plt.plot(dl_model.history.history["val_loss"], label="val_loss")
plt.legend()
plt.show()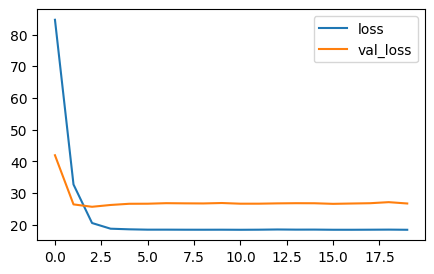
# 4. 모델 평가
dl_model.evaluate(X_test, y_test)
# 출력: - loss: 26.6983 - mse: 26.6983
[24.06447410583496, 24.06447410583496]
# 딥러닝 모델이라고 무조건 머신러닝보다 좋은 게 아님!
# 수치형 데이터에 대해서는 머신러닝이 좋을 때도 있음
# 딥러닝 깊이를 얕게 설정한 영향도 있음- 신경망 구조 설계 꼭 기억하기
퍼셉트론(Perceptron)과 다중 퍼셉트론(MLP)
학습 목표
- 퍼셉트론의 개념을 이해할 수 있다.
- 다중 퍼셉트론의 개념을 이해할 수 있다.
딥러닝 역사: 퍼셉트론 제안(1958)
인공신경망: 퍼셉트론(Perceptron)
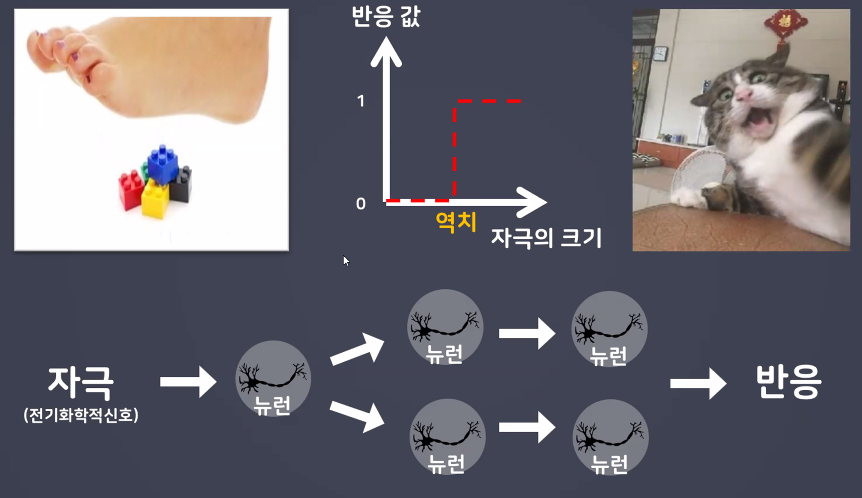
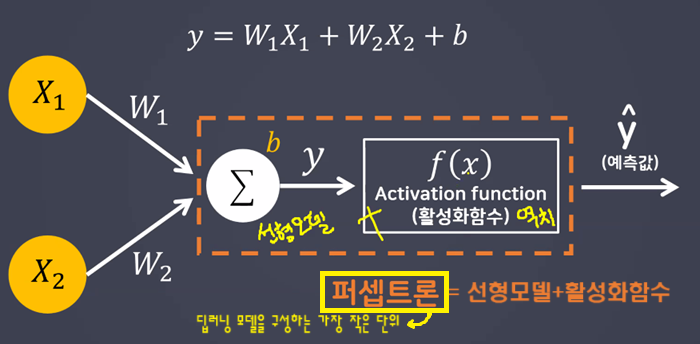
- 인공신경망 구성 요소 중 하나
- 딥러닝 모델의 가장 작은 기본단위
- 뇌를 구성하는 신경세포인 뉴런의 동작과 유사하게 동작
- 퍼셉트론은 뉴런이다!

- 퍼셉트론은 뉴런이다!
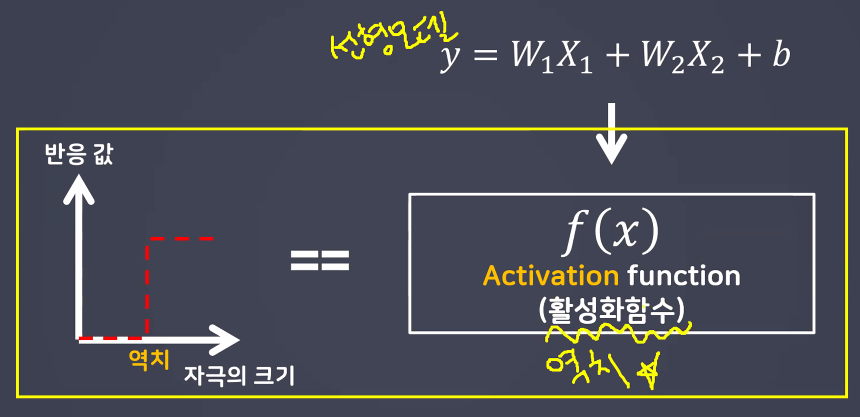
- 사람의 신경망 속 뉴런은 모든 자극을 다 다음 뉴런으로 전달하는 것이 아님
- 신경의 흥분이 전달되기 위해서는 뉴런에 전달되는 자극의 크기가 역치 이상이 되어야 함 (역치 이상의 자극만 전달)

- 퍼셉트론에도 "역치"를 담당한 무언가가 필요함 → 활성화 함수(activation function)
- 신경의 흥분이 전달되기 위해서는 뉴런에 전달되는 자극의 크기가 역치 이상이 되어야 함 (역치 이상의 자극만 전달)
- 퍼셉트론(Perceptron) 개념의 시작
- 프랑크 로젠블라트가 1957년에 고안
- 초기 형태의 인공신경망
- 퍼셉트론의 구성
- 선형 모델
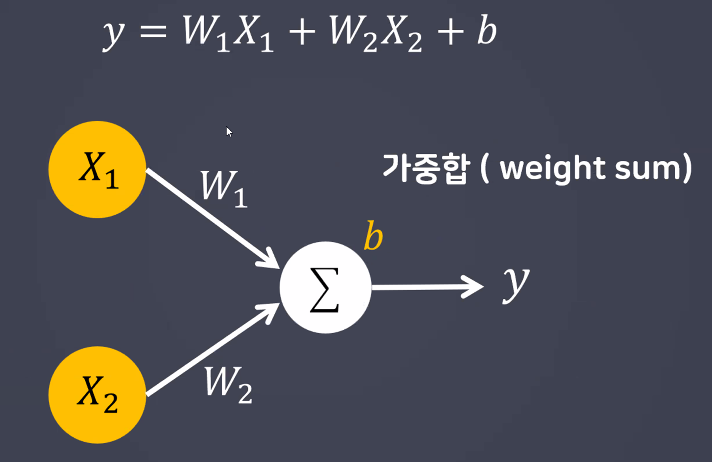
- BUT 선형 모델만으로는 역치를 구현할 수 없다!(식에 역치에 해당하는 내용이 없음)
- 따라서 이를 보완하기 위해 활성화 함수 개념이 등장
- 활성화 함수
- 초기 활성화 함수: 계단함수(step function) → optimizer 과정에서 걸림 (미분 문제)
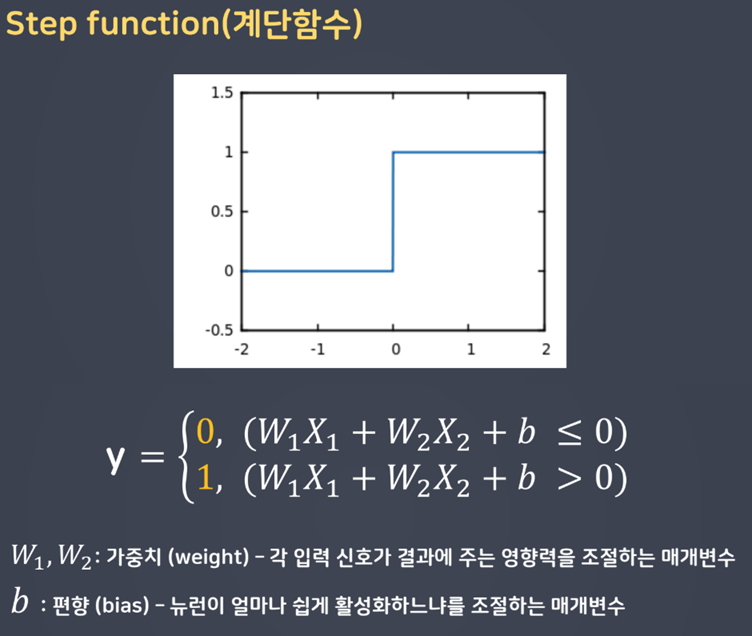
- 매개변수의 값이 조금 변할 때 그에 대해 연속적인 값으로 반응하지 못함
- 이를 해결하기 위해 시그모이드(sigmoid) 도입
- 초기 활성화 함수: 계단함수(step function) → optimizer 과정에서 걸림 (미분 문제)
- 선형 모델
참고: 미분가능하지 않은 함수
XOR 문제 지적
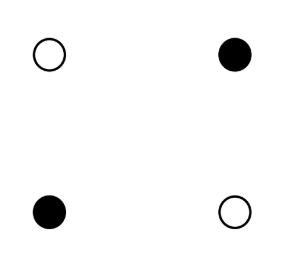
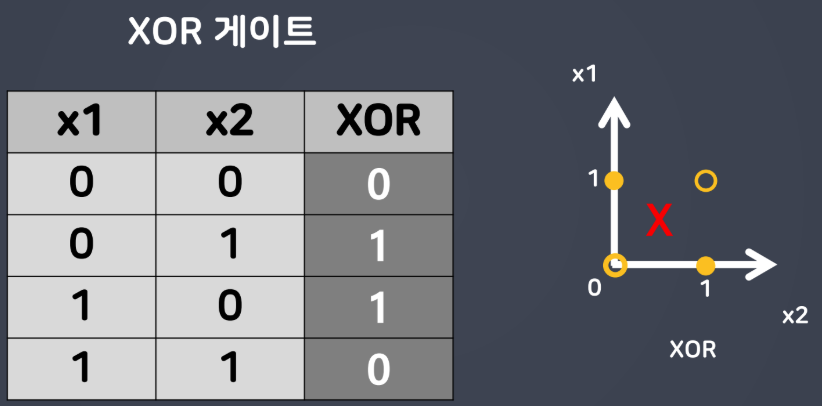
- XOR?
- 논리 게이트 중 하나
- 베타적 OR 게이트 또는 배타적 논리합(Exclusive logical sum) 또는 상호 배재적 OR 게이트라고 함
- 두 개의 입력 신호가 서로 같으면 출력이 0으로 나타나고 서로 다르면 1로 동작
- 논리 게이트(Logic gate)
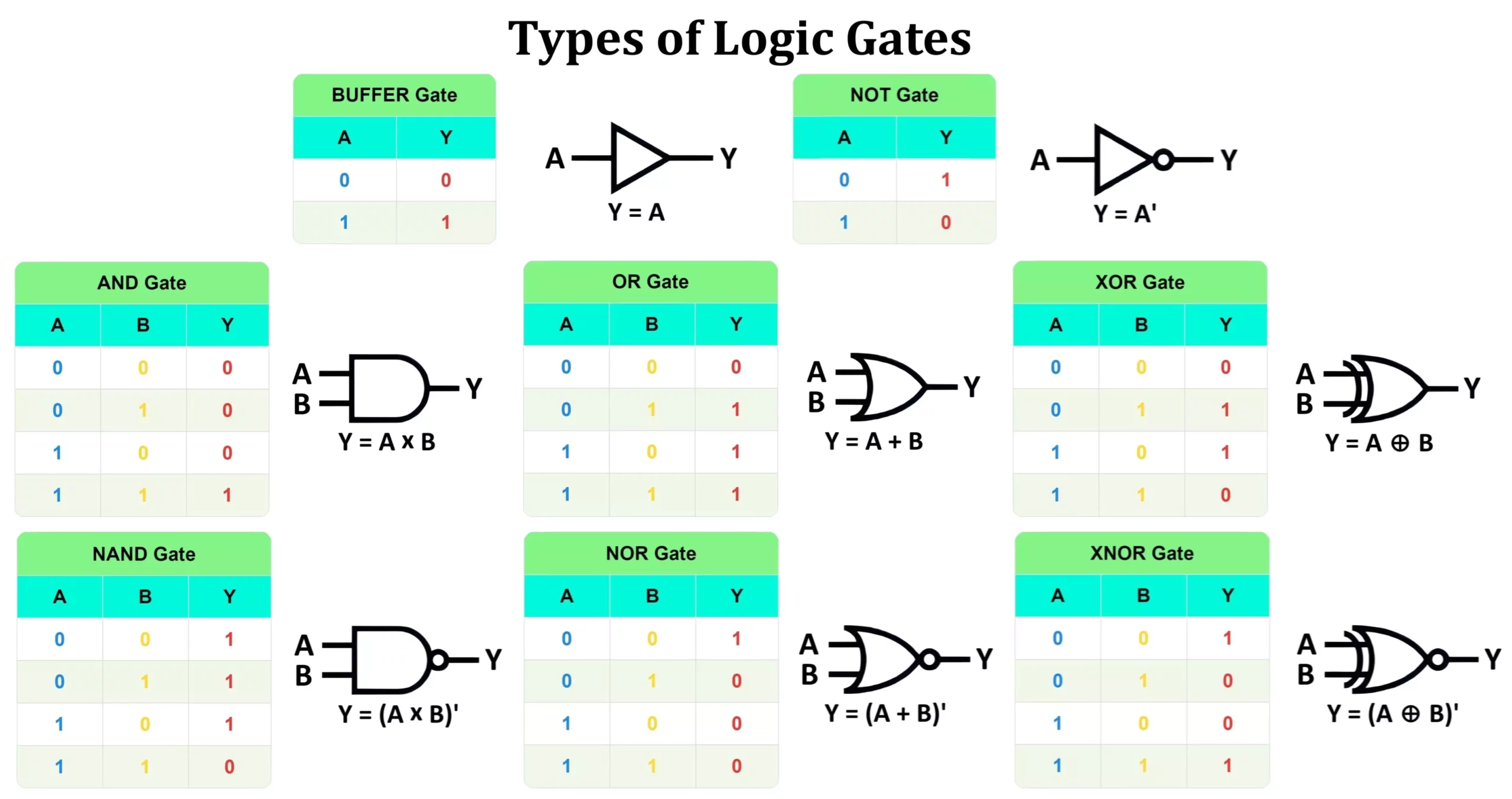
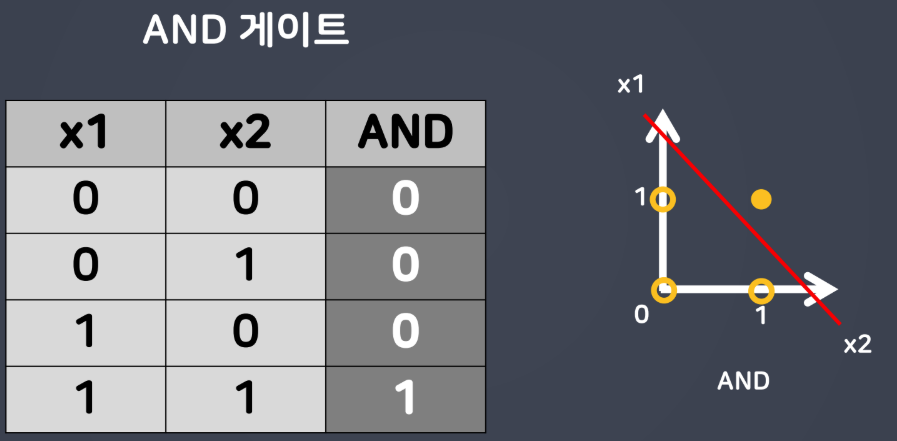
- AND 게이트
- NAND 게이트: AND 게이트에 반전 회로(NOT 게이트; inverter) 적용
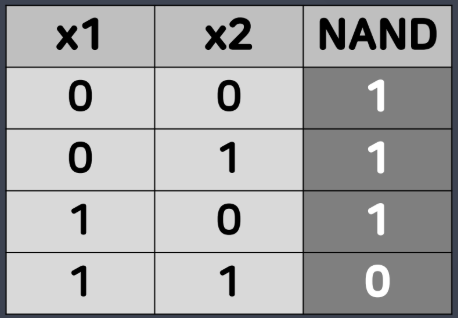
- NAND 게이트: AND 게이트에 반전 회로(NOT 게이트; inverter) 적용
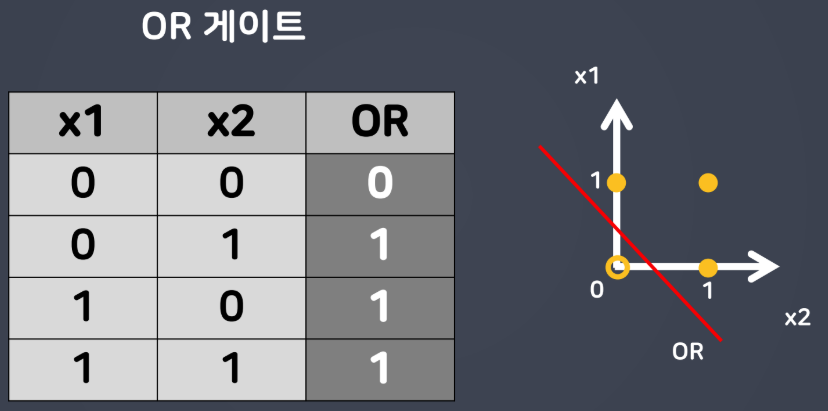
- OR 게이트
- XOR 게이트(exclusive OR gate)
- AND 게이트
- 초기 퍼셉트론: AND, OR는 해결이 가능하지만 간단한 XOR 문제를 해결할 수 없었음
- 한 개의 직선을 그어 XOR 연산 결과로 도출되는 점을 두 개의 그룹으로 나누는 게 불가능하기 때문 → "공간을 접는" 것으로 해결: 다층(Multi-layer) 퍼셉트론
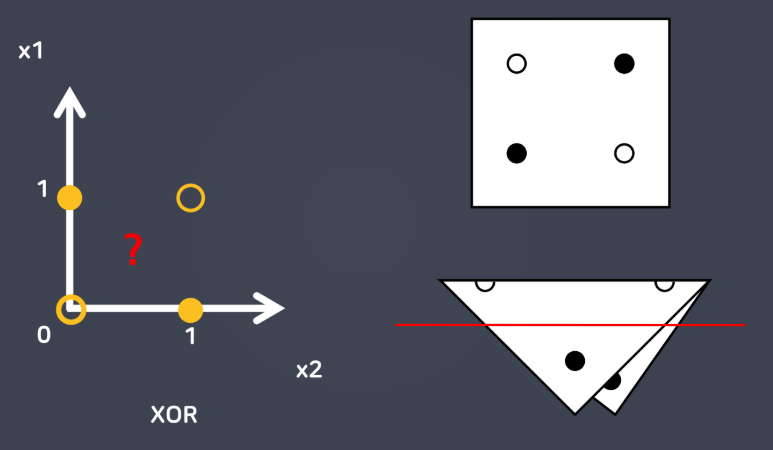
- 한 개의 직선을 그어 XOR 연산 결과로 도출되는 점을 두 개의 그룹으로 나누는 게 불가능하기 때문 → "공간을 접는" 것으로 해결: 다층(Multi-layer) 퍼셉트론
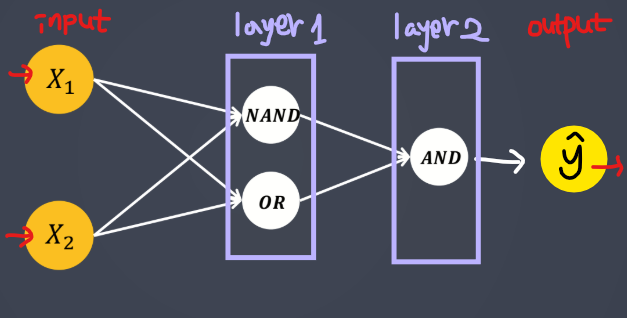
XOR 문제 해결
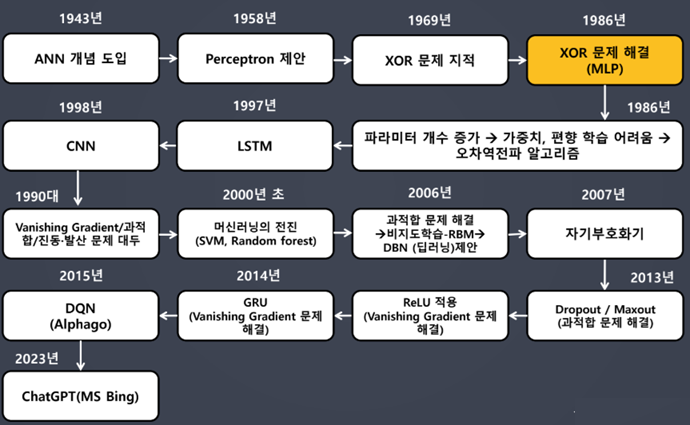
- 다층 퍼셉트론(MLP, Multi Layer Perceptron) 개념을 도입하여 해결
- 논리표
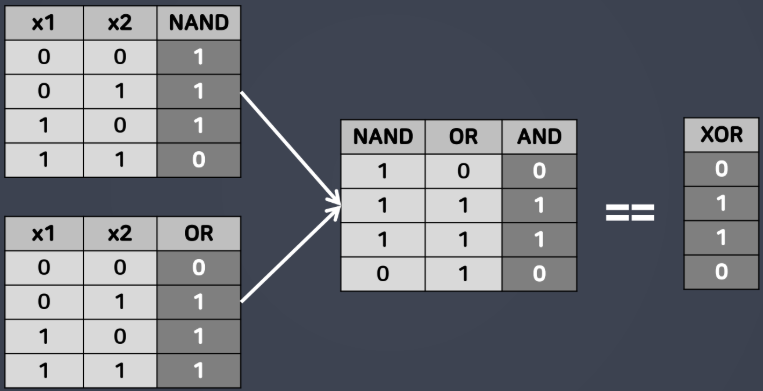
- 논리표
- 다층 퍼셉트론
- 퍼셉트론을 여러 개의 층으로 구성하여 만든 신경망
- 한 번의 연산으로 해결되지 않는 문제를 해결할 수 있음
- 단층에 비해 학습 시간이 오래 걸림
- 단층 구조
- 단층 구조
- 모델(신경망)이 복잡해지면서 학습 시 과대적합되기 쉬움
- 퍼셉트론을 여러 개의 층으로 구성하여 만든 신경망
Career Up
골트래커 작성의 중요성
- 골트래커를 통해 커리어 방향 정하기 & 나와 맞는 기업 탐색
- 기업에서는 지원자에 대해 구체적이고 디테일한 부분까지 살피는 추세
- 채용 트랜드는 계속 바뀌지만 학습 과정 및 결과는 바뀌지 않음!
- 학습 참여, 프로젝트 참여 & 기여 내용 을 중요하게 살펴봄
- 지원자의 환경(스펙 등)보다 프로젝트 내용을 더 고려하는 편
- 채용 트랜드는 계속 바뀌지만 학습 과정 및 결과는 바뀌지 않음!
- 그럼 어떤 걸 준비해야 할까? → 골트래커를 상세하게 작성
- 목표를 어떻게 세울 것인가
- 구체적이고 현실적인 목표 설정
- 월/주/일 단위 계획 세우기
- 성장 포인트 고민하기: 부족한 부분을 어떻게 채울 것인가
- 구체적으로 무엇을 할 것인지 작성해야 함
- 목표별 행동 및 구체적 지표, 예시 적기
- 실제로 행동하며 느꼈던 부분, 내가 잘 한 부분을 앞으로 성장하는 도구로 어떻게 활용할 것인지 고민
- 목표를 어떻게 세울 것인가
- 피드백의 중요성
- 건설적인 피드백 제공하기
- 장점은 극대화, 단점은 보완
- 동료/강사진 피드백
- 어떤 식으로 피드백 반영했는지 골트래커에 작성하기
- 건설적인 피드백 제공하기
- 자격증
- 자격증 찾아본 내용/정보
- 무엇을 할 수 있는지 검토
- 취업에 도움이 되는지? 개인적인 성취를 위한 자격증인지? 구분짓기
- 책/강의 등 주차별 학습 내용 골트래커에 작성해서 관리
- 골트래커를 커리어 자료로 활용하기
- 커리어 완성을 위한 발판
- 밀려도 괜찮으니까 완성을 목표로
이력서
- 각자만의 틀을 만드는 것이 중요
실제 빅데이터 개발자 커리어 이력서를 예시로 설명
- 경력기술서
- 보유 기술에 대해 서술하기: 요약/나열 -> 보기 좋게 작성
- 데이터 처리 -> 파이썬, SQL, 엑셀
- 머신러닝/딥러닝 -> XGBoost, RandomForest, Tensorflow, Keras
- 시각화 및 보고서 작성 -> matplotlib, seaborn, Powerpoint
- 공간 데이터 분석 -> QGIS
- 기타 툴 -> Jupyter, Git
※ 내가 가지고 있는 툴/보유 기술에 대해 이력서를 보는 평가자가 봤을 때 지원자의 역량이 JD에 어울리는지 한눈에 깔끔하게 알 수 있도록 깔끔하게 정리하고 묶어주기
- 문장으로 길게 서술하는 것보다 구분해서 정리하는 것이 좋음 → 한 눈에 볼 수 있게! 눈에 잘 띄게! 간략하게!
- 회사명/기간(년.월 ~ 년.월 (개월수))
- 주요 프로젝트 경험: JD에 맞게 서술하기 → 프로젝트명/기간/내용/개인 성과/기여도
- 취득 자격증을 쓰는 건 좋지만 취득 예정인 건 쓰지 마세요! (흠이 될 수 있음)
- 보유 기술에 대해 서술하기: 요약/나열 -> 보기 좋게 작성
- 자기소개서
- 경력 기술서를 바탕으로 작성
- JD 내용을 결합해서 작성
- 제목을 '~ 해서 --한 데이터 개발자 ()입니다'와 같이 작성
- 해당 직무를 위해 한 내용 간략히 맨 앞에 적고 시작하기
- 프로젝트 설명 & 기여도 다시 한번 언급해서 신뢰도 더하기
- 프로젝트 내용을 양쪽 모두에 녹여내서 일관성&신뢰도&능력 어필
- 포트폴리오: PPT나 본인이 쓰는 다른 툴
- 본인 소개 짧게
- 경력 짧게 소개
- 스킬: 크게 1~2 페이지
- 어학 능력은 기타로 넣기
- 도식화&요약된 문장으로 직무 능력 기술하기
- 참여 프로젝트, 주요 경력을 경력 기술서를 참고해서 작성(조금 더 구체적으로 명시하기)
- 프로젝트 소개: 문제해결과정을 중심으로 (특히 커뮤니케이션 능력을 강조하기 → 기업에서 원하는 부분이 커뮤니케이션 능력을 갖추고 있는지 & 문제해결을 어떻게 하는지 보는 것이기 때문)
- 내가 뭘 했는지(담당한 부분) 명확하게 & 크게 작성: 기여도 초기-중기-말기 나눠서
- 나의 연대표라고 생각하고 작성하기
- 이력서가 이미 있다면:
- 내 이력서 내용이 명확히 눈에 들어오는지 점검하기
- 오늘 소개한 이력서 틀과 비교하기
- 이력서 간 연결이 떨어지는 부분 빨리 파악해서 보완하기
- 이력서의 틀을 항상 갖춰놓고 준비해 두는 것이 중요합니다
- 매월 했던 일 정리하기
- 매년 했던 일 정리하기
- 이력서는 계속 추가해 나가는 것!
- 컨플루언스 같은 곳에 기록하는 것도 좋음
- 내가 한 내용
- 내가 기여한 내용
- 어떤 어려움을 겪었는지
- 어떻게 극복했는지
- 본인에 대한 평가도 가능하기 때문에 잘 작성하기
- 이력서-취업 후 내부 평가까지 다 연결
- 컨플루언스 같은 곳에 기록하는 것도 좋음
- 공채로는 잘 안 뽑고 필요한 인원이 생길 때만 보충하는 식으로 바뀌고 있음
- 신입은 와서 배우면 된다? NO!
- 신입을 바라보는 구체적 기준이 있음
- 신입은 와서 배우면 된다? NO!
- 신입도 직무별 역량중심평가를 진행합니다:
- 기술 문제 해결력
- 툴 이해도, 문제 해결 능력, 서비스 장애를 빨리 인지하는지 등을 평가
- 성장 가능성
- 얼마나 빨리 배울 수 있나요
- 적응하는 데 얼마나 걸리나요
- 조직에 대한 fit 확인
- 어떤 것들을 공부하고 있는지
- 어떤 것이 어려웠는지, 어떻게 극복했는지 중간 과정과 결과에 대해 세세하게 질문
- 트랜드와 기술이 계속 변화하기 때문에 이에 관심을 꾸준히 가지고 기술 스펙을 꾸준히 쌓는 것이 중요 → 기술 스펙을 가지고 작은 거라도 실제로 시도해 보는 것까지! 시도 과정에서 발생한 문제를 해결하는 과정을 또 이력서, 포트폴리오 등에 넣을 수 있음
- 뭐라도 한 번 더 해보는 것이 좋은 평가를 받을 수 있음
- 커뮤니케이션 능력
- 이스트에이드는 스쿼드 체제 운영 → 개발자+기획자+디자이너+PM 등 여러 직군이 한 팀으로 묶여 일함(TF 구조)
- 직군마다 필요한 능력을 갖추었는지 체크
- 필요 역량 업데이트 & 정리해줌 (직무 리더가)
- 기능 단위로 묶일 때는 소통 문제가 덜하지만 여기는 여러 직무가 함꼐 모여 일하기 때문에 각자의 직무에 대해 이해하고 용어를 알고 소통&어우러질 수 있는지를 평가
- 모르면 모른다고 하는 게 중요
- 어려움, 문제점 발생 시 리더 직군에게 물어보고 피드백을 잘 소화하는 능력이 중요(피드백 수용력도 커뮤니케이션의 한 단계 - 피드백 부정적으로 받아들이지 말기, 어떻게 수용해서 어떻게 발전시키는지도 평가 기준임)
- 고급 역량 능력
- 기술 문제 해결력
- 문제 해결 경험이 가장 중요
- 어떤 문제가 생겼을 때 그 문제를 어떻게 해결했는지
- 프로젝트 과정에서 발생한 문제를 커뮤니케이션/특정 툴/기타 방법으로 해결한 과정 단계별로 기술하기
- 회사 특성상 도메인 이해도와 협업 능력에 대해서도 질문 많이 하는 편
- 해결이 안 되는 문제라면 어떻게 대처할 것인지
- 조직에 대한 fit을 확인해 보려는 질문
- 최근 채용 트랜드는 서류-1차-2차까지의 과정이 빠른 편입니다(짧게는 3주면 끝)
- 따라서 미리미리 준비해 두는 게 중요함!
- 골트래커가 정말 중요함
- 기본기, 성장 가능성, 커뮤니케이션이 모두 결합되어 있음
- 어떤 회사? 어떤 jD? JD에 맞게 성장하고 있는지? 골트래커를 통해 체크하기
하루 돌아보기
👍 잘한 점
- 강의에 집중 잘 했음
- 쉬는 시간 및 자투리 시간 활용해 복습 끝냄
- 교재에서 강의에서 배운 내용에 해당하는 부분 찾아서 복습하는 느낌으로 공부 진행함
👎 아쉬웠던 점
- 배운 내용 개념별로 정리하는 블로그를 티스토리에서 깃허브로 바꾸려고 깃허브 공부하고 있는데 생각보다 잘 안되고 있음
🔬 개선점
- 리눅스로 하면 잘 된다고 해서 이참에 리눅스 공부하고 리눅스 마스터 시험까지 노려보기

2 B R 0 2 B