[인공지능사관학교: 자연어분석A반] 딥러닝 (2)
지난 시간 복습
- 딥러닝
- 인공지능
- 인간의 지적 능력을 컴퓨터를 통해 구현하는 기술의 집합
- 머신러닝
- 데이터 기반으로 컴퓨터 스스로 학습하여 규칙을 찾아 예측하는 기술
- 딥러닝
- 인간의 신경망을 모방해 학습하고 예측하는 기술
- 인공지능
- 사람의 신경망을 모방하여 기계가 병렬적 다층 구조를 통해 학습하도록 만든 기술
- 병렬적 다층 구조
- Sequential
- input layer
- hidden layer(s)
- output layer
- 병렬적 다층 구조
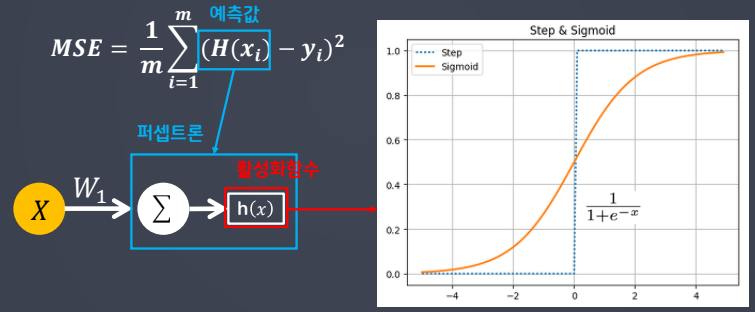
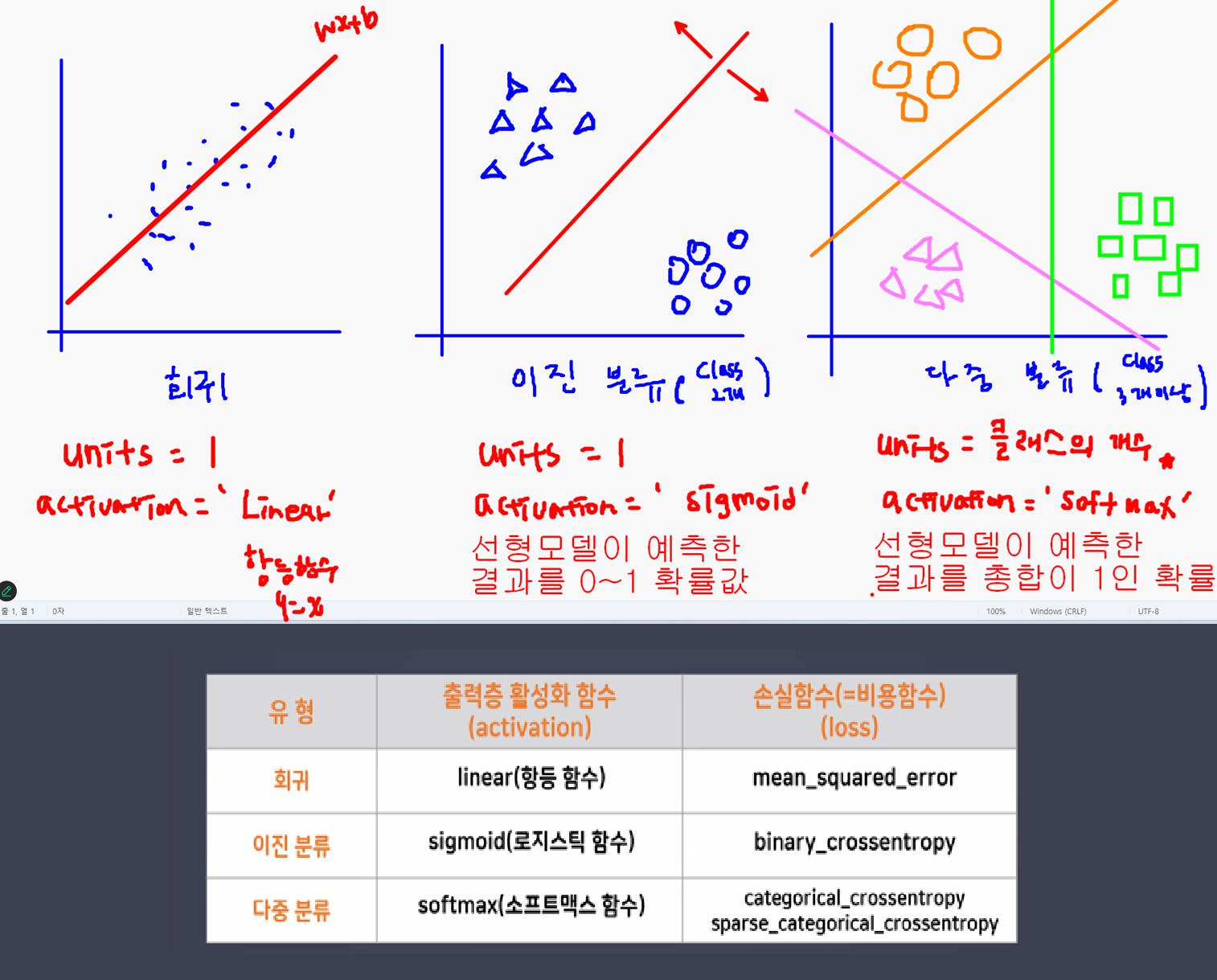
- 퍼셉트론
- Perceptron = Linear model + Activation function
- 인공신경망 구성요소 중 하나
- 딥러닝 모델의 가장 작은 기본 단위
- 뇌를 구성하는 신경세포인 뉴런과 유사하게 동작
- 역치 구현을 위해 활성화 함수 도입
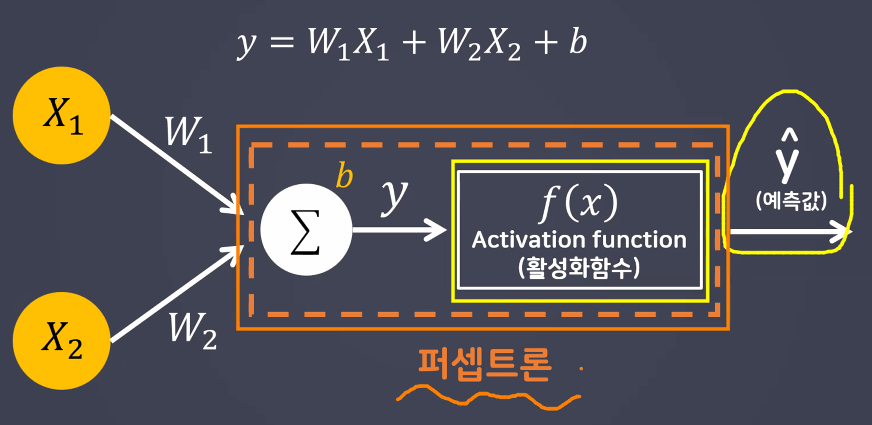
- 역치 구현을 위해 활성화 함수 도입
- 활성화 함수
- 초기에는 계단 함수 썼지만 optimizer로 w, b값 업데이트 위해서는 기울기가 필요해서 시그모이드 도입
- 다층 퍼셉트론(MLP)
- XOR 문제 해결하기 위해 도입
- MLP 학습법: 딥러닝의 가장 기초!
model.add(Dense(units=10, activation='sigmoid))- units: 한 층에 들어갈 퍼셉트론 수
- Perceptron = Linear model + Activation function
- 딥러닝 지도학습
실습: 딥러닝 이진 분류
학습 목표
- 유방암 환자 데이터를 바탕으로 유방암인지 아닌지를 구분해보자
- 딥러닝을 활용하여 이진 분류 학습을 진행해보자
- sklearn.datasets에서 제공하는 breast_cancer 데이터(유방암 데이터) 활용
# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer # 사이킷런 내장 데이터
# 데이터 가져오기
data = load_breast_cancer()
# 사이킷런 데이터 타입(번치 객체) → 파이썬의 딕셔너리와 동일하게 구성: {key:value}
# 키값만 확인
data.keys()
# data: 입력특성, 문제 데이터
# target: 정답 데이터(인덱스 번호)
# target_names: 정답 데이터의 이름
# feature_names: 입력특성의 이름(컬럼명)
# DESCR: 데이터에 대한 설명
# 정답 데이터 확인
data["target"]
data["target_names"]
# target이 인덱스 번호
# 0: 'malignant', 악성
# 1: 'benign', 양성
# 클래스가 2개인 이진 분류 학습이 필요하다!
# 문제, 정답 데이터 분리
X = data["data"]
y = data["target"]
# 4개의 train, test 분리
# 랜덤→11, 분리→7.5:2.5, 클래스 비율 맞춰주도록 설정
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y, random_state=11)
#크기 확인
print('훈련용 문제: ',X_train.shape)
print('훈련용 답: ',y_train.shape)
print('테스트용 문제: ',X_test.shape)
print('테스트용 답: ',y_test.shape)훈련용 문제: (426, 30)
훈련용 답: (426,)
테스트용 문제: (143, 30)
테스트용 답: (143,)모델링
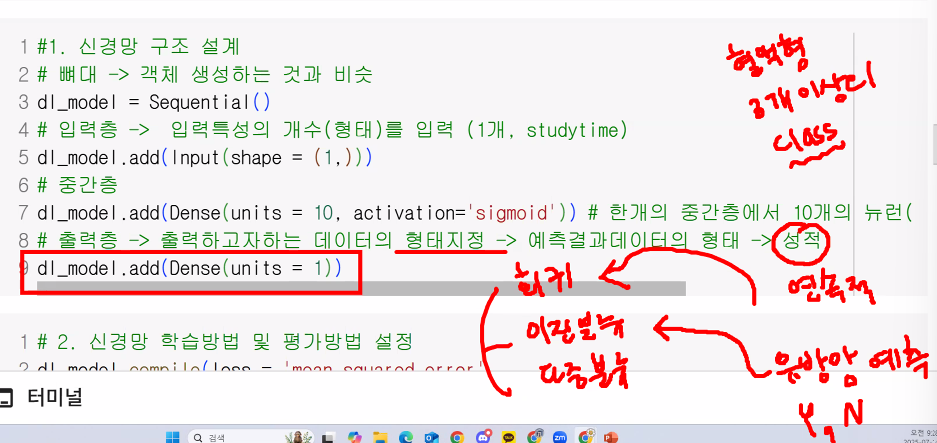
- 신경망 모델 구조 설계 (뼈대, 입력층, 중간층, 출력층)
- 신경망 모델 학습 방법 및 평가 방법 설정 (loss, optimizer, metrics)
- 회귀, 이진분류, 다중분류인지에 따라 다르게 설정
- 신경망 모델 학습 및 학습 결과 시각화
- 신경망 모델 예측 및 평가
# 모델 생성을 위한 도구 불러오기
from tensorflow.keras import Sequential # 뼈대
from tensorflow.keras.layers import Input, Dense
# Dense: '빽빽한','밀집된'이라는 의미를 가짐
# 층을 쌓을 때 사용 (중간층과 출력층에서 사용)
# 1. 신경망 모델 구조 설계
# 뼈대
model = Sequential()
# 입력층
# Input(shape = ()): 입력특성의 개수를 설정
model.add(Input(shape = (30,)))
# 중간층, 은닉층
# 학습능력을 설정
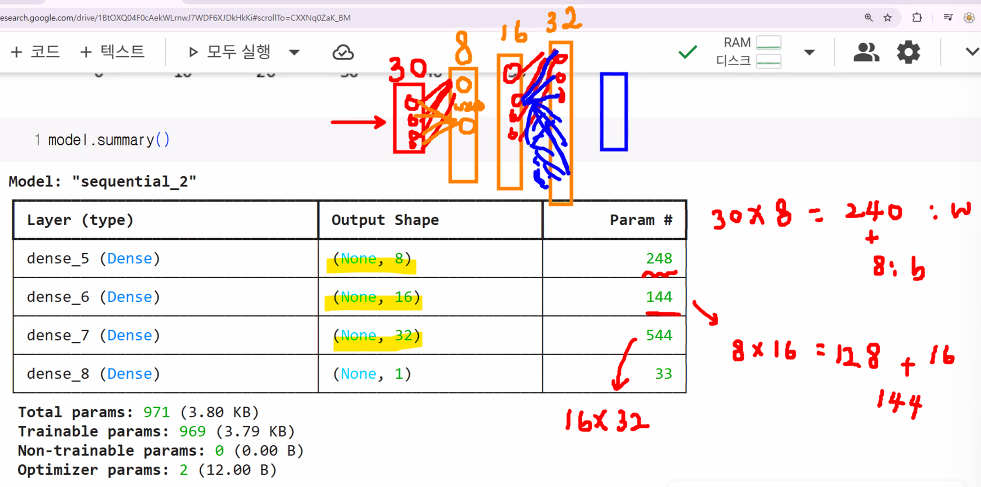
# 다층설계 (8,16,32) → Dense 층 3개 쌓기!
model.add(Dense(units = 8, activtion = 'sigmoid'))
model.add(Dense(units = 16, activtion = 'sigmoid'))
model.add(Dense(units = 32, activtion = 'sigmoid'))
# 출력층
# 출력하고자 하는 데이터의 형태를 지정~
# 이진분류 → 한 개의 확률값!
# 한 개 → units=1)
# 확률값 → activation='sigmoid'
model.add(Dense(units = 1, activation = 'sigmoid'))
# 이진분류: 1인지 아닌지에 대해서만 판별
# 1인지에 대한 확률값 1개만 필요
# 임계점(0.5) 이상 → class 1
# 임계점(0.5) 미만의 확률값 → class 0- 출력층 units=1인 이유: 직선이 하나니까
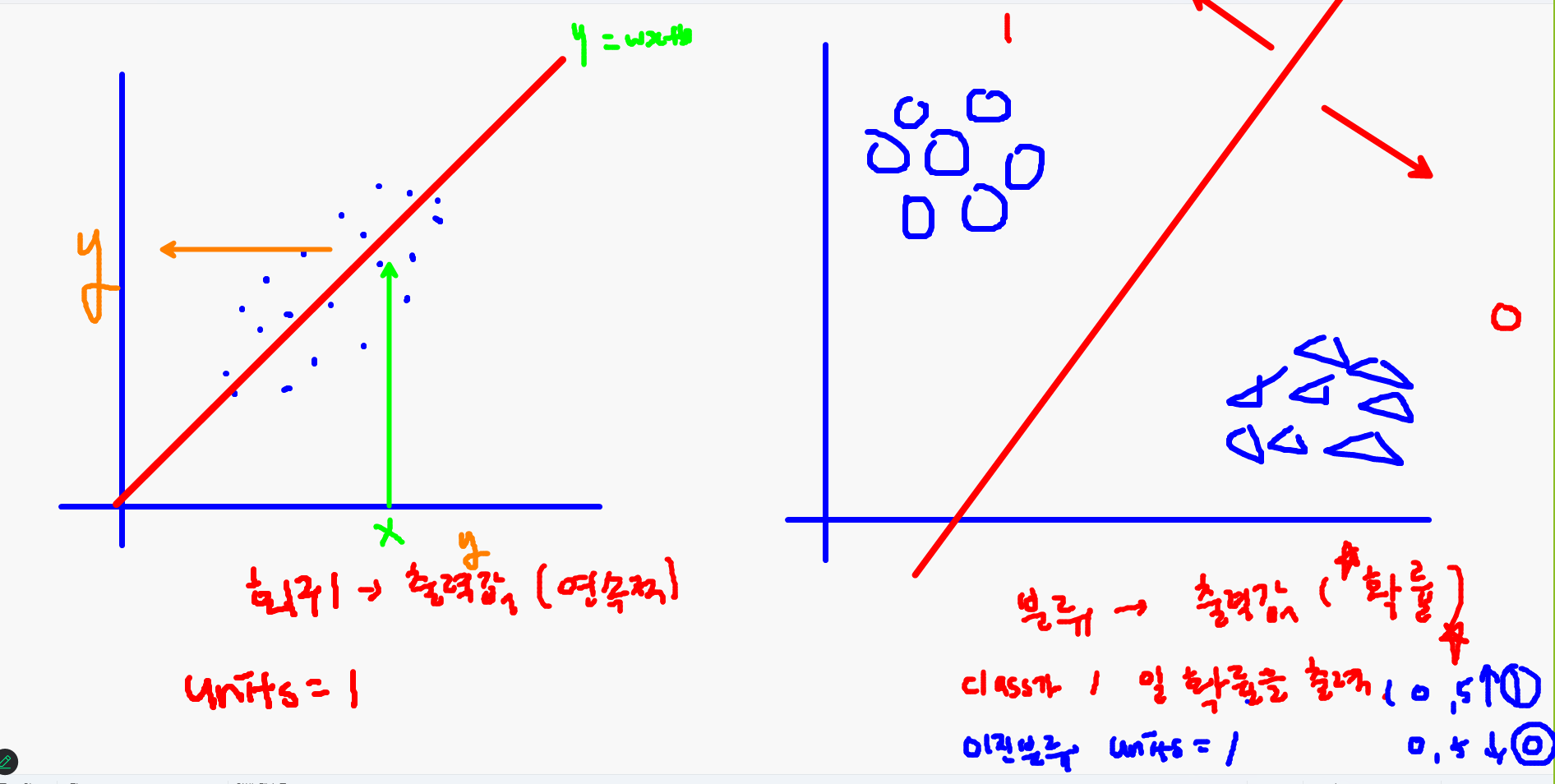
- units의 개수는 결국 직선의 개수임
- 회귀: 데이터를 가장 잘 설명하는 최적의 직선
- 분류: 한 개의 직선으로 두 클래스 구분
활성화 함수의 역할
- 중간층과 출력층의 역할이 다르다!
- 중간층: 활성화 여부 ('역치'의 개념)
- Step function(계단함수) → sigmoid(시그모이드)
- 출력층: 출력하고자 하는 데이터의 형태를 지정
- 회귀: Linear(activation 파라미터의 기본값이라 생략 가능)
- 이진분류: sigmoid (BUT 중간층과 다른 역할 → 한 개의 확률값)
- 중간층: 활성화 여부 ('역치'의 개념)
- 회귀와 이진분류의 출력층 활성화 함수가 다른 이유 이해하기
- 회귀
- 연속값이 출력되어야 함 → 선형모델이 출력한 값을 그대로 출력하면 됨 → Linear(항등함수, y=x): activation 파라미터 default 값
- 이진분류
- 확률값(0~1 사이의 숫자로 변환)이 출력되어야 함 → sigmoid: 임계점(0.5) 보다 크면 1, 작으면 0으로 판별하는 함수 (선형모델이 예측한 연속적인 결과를 0~1 사이의 확률값으로 변환)
- 회귀
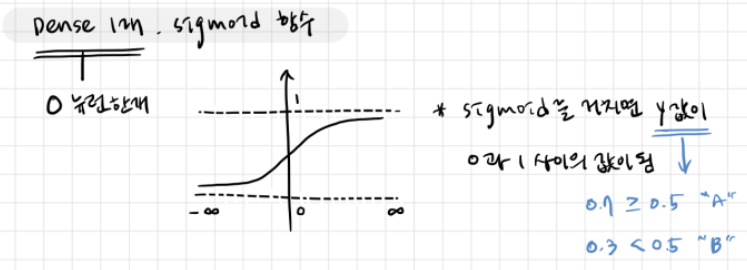
- cf. 다중분류
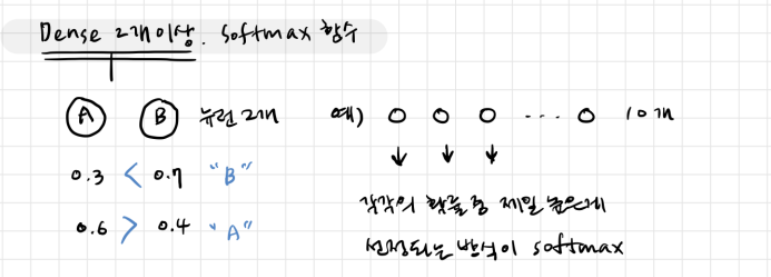
- 활성화 함수 발전사
- Step function(계단함수) → sigmoid(시그모이드) → cont'd
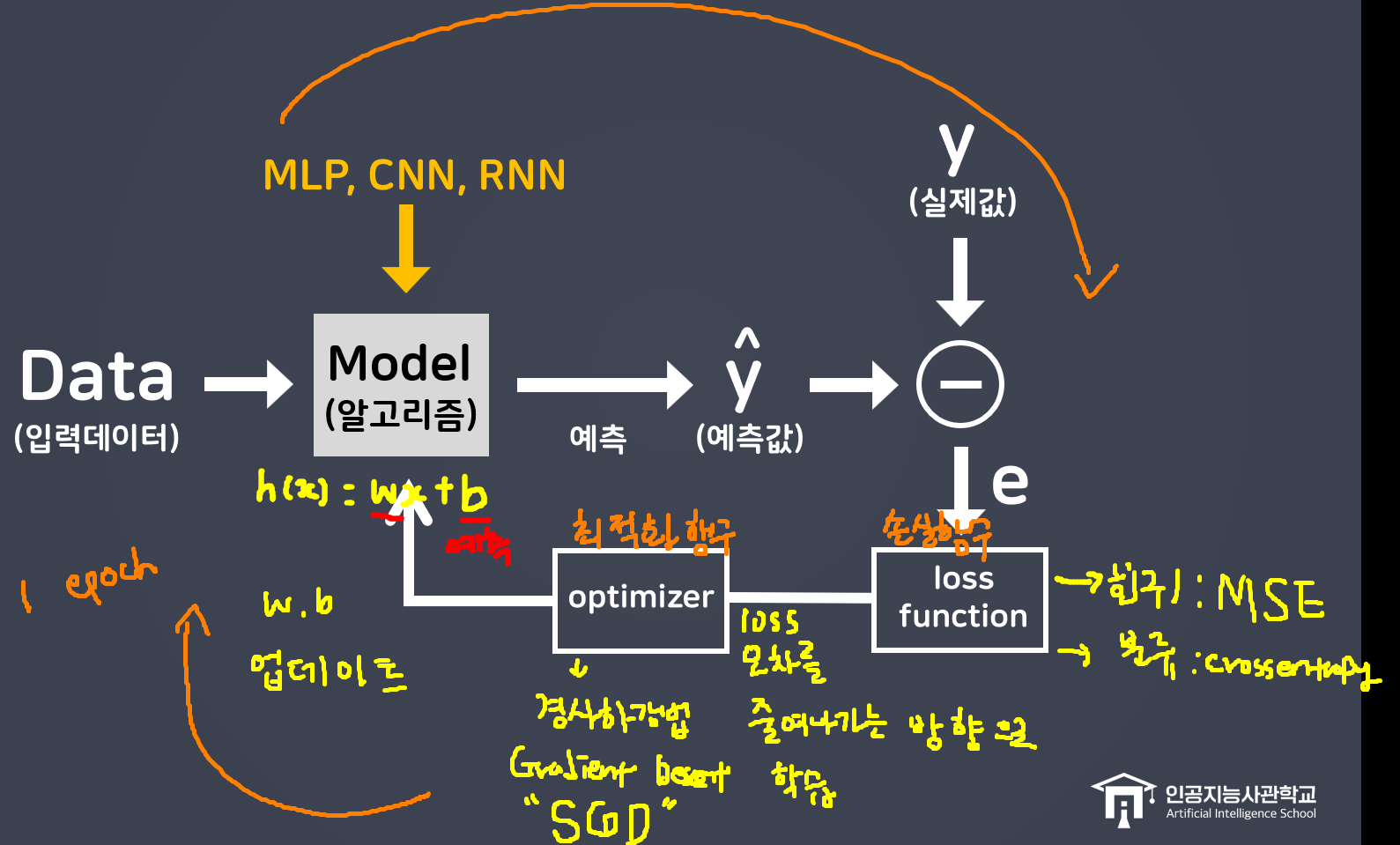
# 2. 모델 학습 방법 및 평가 방법 설정
model.compile(
optimizer="SGD" # 최적화 알고리즘(경사하강법)
, loss="binary_crossentropy" # 이진분류
, metrics=["accuracy"] # 평가지표 (분류: 정확도)
)
# 3. 모델 학습 및 시각화
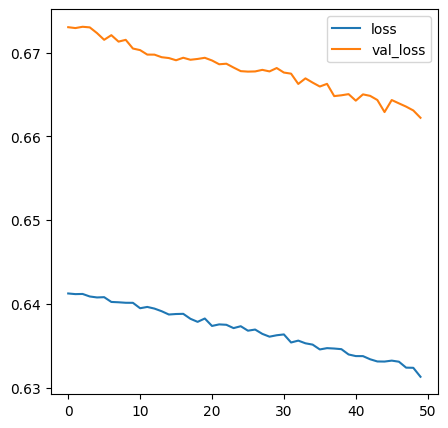
h1 = model.fit(X_train, y_train, validation_split=0.2, epochs=100)
# 시각화
plt.figure(figsize=(5,5))
plt.plot(h1.history["loss"], label="loss")
plt.plot(h1.history["val_loss"], label="val_loss")
plt.legend()
plt.show()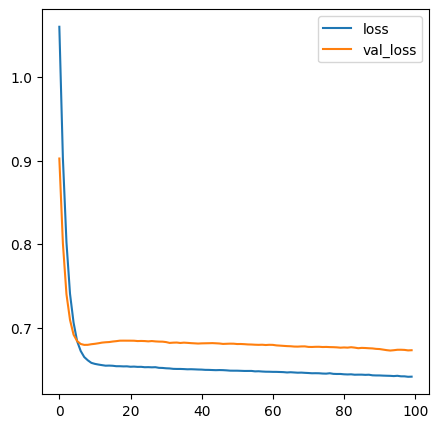
- 모델을 reset하고 싶으면 모델 구성(설계)부터 다시 시작해야 함
- epoches를 50으로 변경해봅시다!
model = Sequential()
model.add(Input(shape=(30,)))
model.add(Dense(units=8, activation='sigmoid'))
model.add(Dense(units=16, activation='sigmoid'))
model.add(Dense(units=32, activation='sigmoid'))
model.add(Dense(units=1, activation='sigmoid'))
model.compile(
optimizer="SGD"
, loss="binary_crossentropy"
, metrics=["accuracy"]
)
h1 = model.fit(X_train, y_train, validation_split=0.2, epochs=50)
plt.figure(figsize=(5,5))
plt.plot(h1.history["loss"], label="loss")
plt.plot(h1.history["val_loss"], label="val_loss")
plt.legend()
plt.show()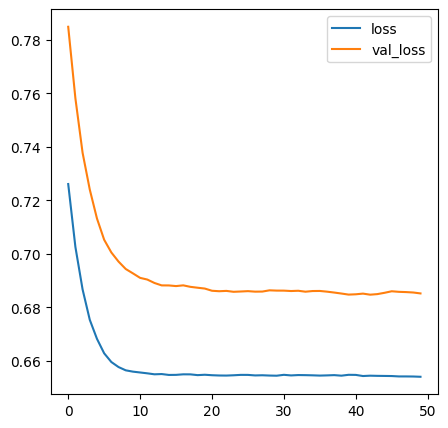
- fit 부분만 다시 돌리면 동일 모델을 누적 학습시키는 결과가 나옴
model.summary()
활성화 함수, 오차역전파, 경사하강법
학습 목표
- 활성화 함수의 개념을 이해하고 종류를 알 수 있다.
- 오차역전파의 개념을 이해할 수 있다.
- 다양한 경사하강법 종류를 알 수 있다.
- Keras를 활용해 다양한 경사하강법을 적용할 수 있다.
Activation Function
- 딥러닝 신경망은 선형회귀와 달리 한 계층의 신호를 다응 계층으로 전달하지 않고 활성화 함수를 거친 후에 전달함
- 사람의 신경망 속 뉴런이 역치 이상의 자극만 전달하는 것을 구현
- 활성화 함수는 이런 부분까지 사람과 유사하게 구현하여 사람처럼 사고하고 행동하는 인공지능 기술을 실현하기 위해 도입됨
- 또한 선형모델을 기반으로 하는 딥러닝 신경망에서 분류 문제를 해결하기 위해서 비선형 활성화 함수가 필요함
- 항등함수: 회귀에서 사용
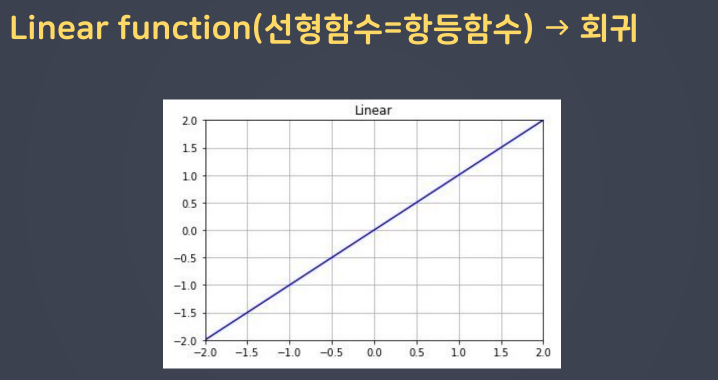
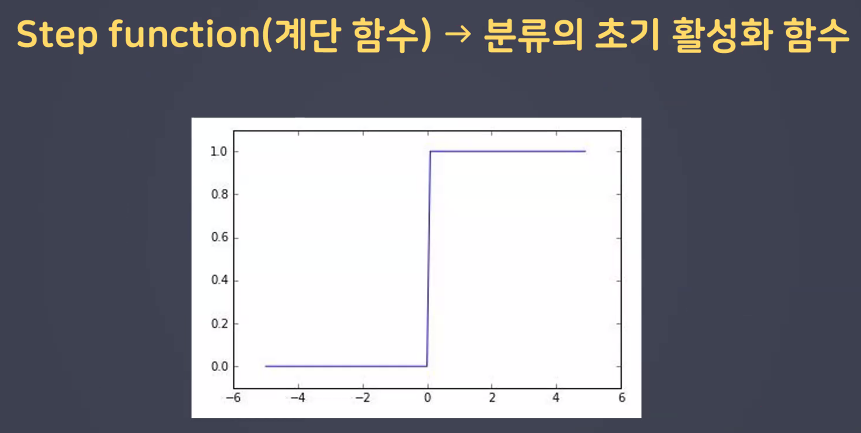
- 계단함수: 분류의 초기 활성화 함수였으나 optimizer에서의 미분 문제 발생
- Sigmoid 함수: 이진분류에서 사용
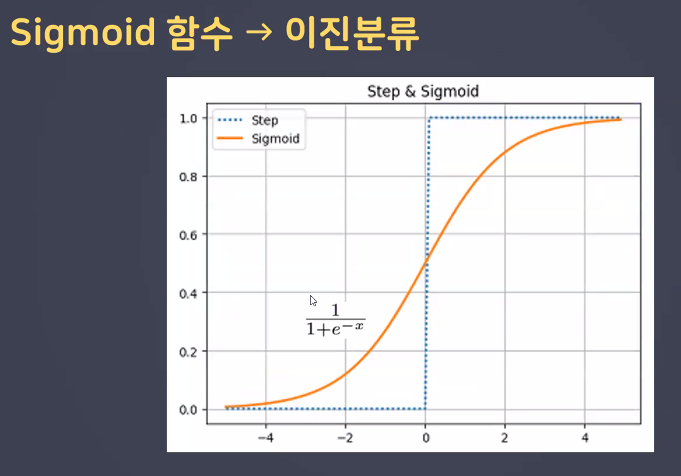
- 계단함수의 문제를 해결하기 위해 등장 → 기울기가 존재!
- 소프트맥스(Softmax) 함수: 다중분류
- 다중분류에서 레이블 값에 대한 각 퍼셉트론의 예측 확률의 합을 1로 설정
- sigmoid에 비해 예측 오차의 평균을 줄여주는 효과

Back Propagation
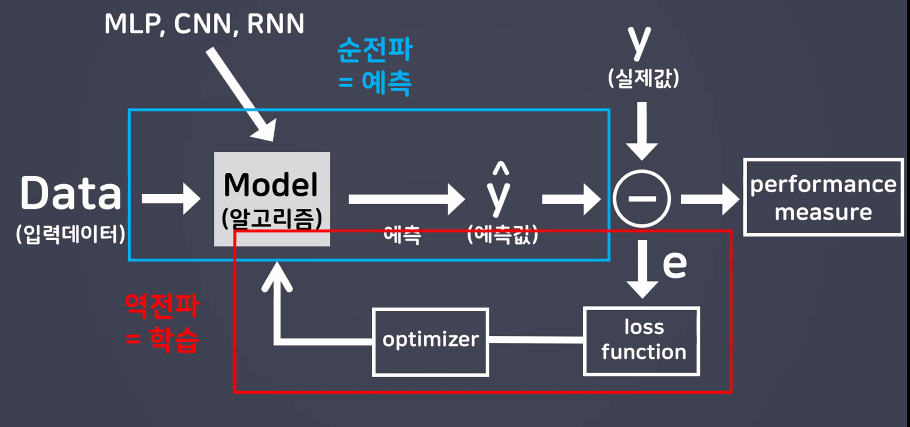
- 순전파(Forward Propagation)와 역전파(Backpropagation)는 인공 신경망 학습 과정에서 핵심적인 두 단계: 순전파는 예측값을 계산하고, 역전파는 오차를 이용하여 가중치를 조정하여 신경망을 학습시키는 과정
- 순전파와 역전파: 딥러닝 학습의 핵심 원리
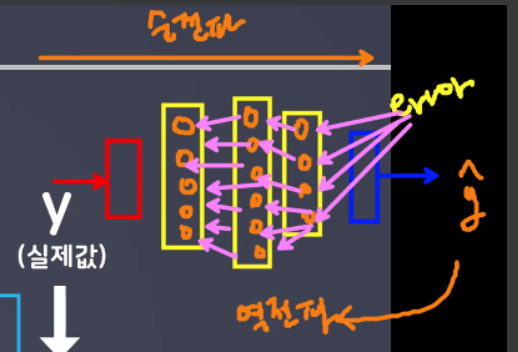
- 순전파: 입력 데이터를 입력층에서부터 출력층까지 정방향으로 이동시키며 출력 값을 예측해 나가는 과정
- 입력 데이터가 신경망의 각 층을 통과하며 연산되어 최종 출력값을 생성하는 과정
- 각 층에서 가중치와 활성화 함수를 적용하여 다음 층으로 데이터를 전달
- 예측값을 계산하고, 실제값과 비교하여 오차를 평가
- 역전파: 출력층에서 발생한 에러를 입력층 쪽으로 전파시키면서 최적의 결과를 학습해 나가는 과정 (=오차역전파)
- 순전파 과정에서 발생한 오차를 이용하여 각 가중치의 중요도를 계산
- 계산된 가중치 중요도(기울기)를 이용하여 각 가중치를 조정
- 오차를 줄이는 방향으로 가중치를 업데이트하여 신경망의 성능을 개선
- 주로 경사 하강법을 사용하여 가중치를 조정
- 순전파와 역전파: 딥러닝 학습의 핵심 원리
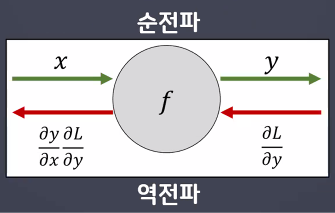
손실함수 및 Sigmoid 함수의 미분
- 신경망이 학습하기 위해서는 경사하강법을 사용
- 경사하강법은 loss 함수를 미분함
- 계단함수는 미분 과정에서 문제가 발생 → Sigmoid 함수 사용 → 하지만 Sigmoid도 문제가 있음: 기울기 소실 문제
- 경사하강법은 loss 함수를 미분함
Vanishing Gradient
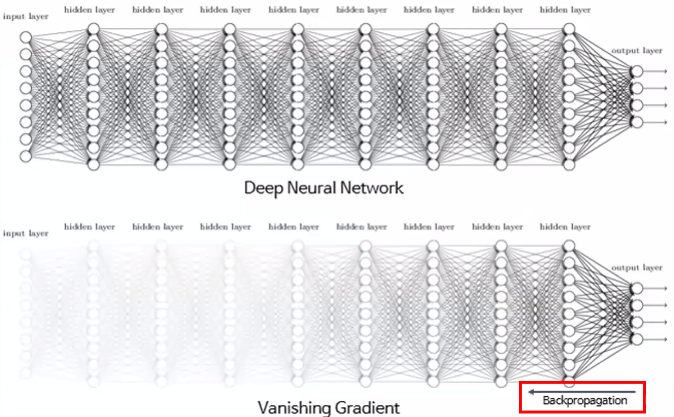
- Sigmoid 함수의 문제점
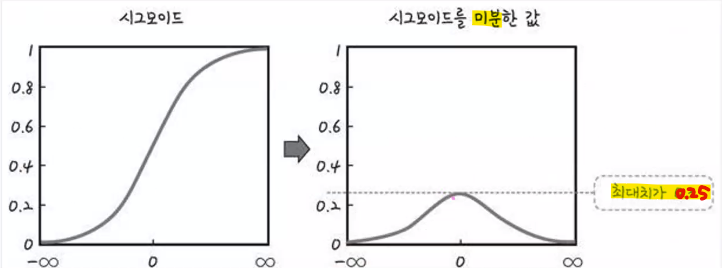
- 시그모이드를 미분한 값의 최대치는 0.25 → 오차가 커도 수정이 1/4만 적용됨
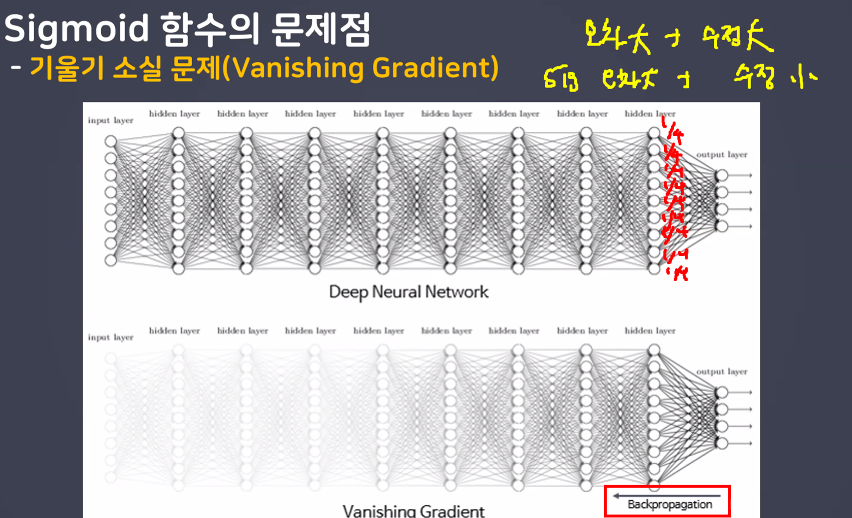
- 100점을 맞아야 하는데 0점이 나옴 → 수정을 100만큼 진행해야 해서 역전파 진행 → 시그모이드 미분으로 인해 1/4만 적용 → 최대 수정해도 25만큼만 수정됨
- 시그모이드를 미분한 값의 최대치는 0.25 → 오차가 커도 수정이 1/4만 적용됨
Optimizer
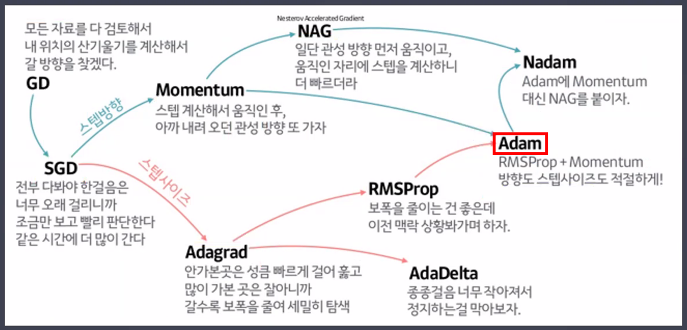
- 최적화 함수
- 모델의 가중치를 업데이트하여 손실 함수(loss function)를 최소화하는 함수
- 주요 딥러닝 최적화 함수
- 경사 하강법 (Gradient Descent): 손실 함수의 기울기(경사)를 이용해 함수의 최솟값을 찾아가는 방법입니다. 가장 기본적인 최적화 방법이지만, 학습률 설정에 따라 수렴 속도나 최적 지점 도달에 어려움이 있을 수 있습니다.
- 확률적 경사 하강법 (SGD): 전체 데이터 대신 일부 데이터 (미니배치)를 사용하여 경사를 계산하고 업데이트하는 방법입니다. 계산 비용을 줄이고 지역 최솟값에 갇히는 문제를 완화할 수 있습니다.
- 모멘텀 (Momentum): 과거의 기울기 정보를 활용하여 최적화 속도를 높이는 방법입니다. 관성처럼 작용하여 지역 최솟값을 더 잘 탈출할 수 있도록 돕습니다.
- RMSprop: 학습률을 적응적으로 조절하여 각 변수별로 다른 학습률을 적용하는 방법입니다. 학습률이 너무 커서 생기는 문제를 완화할 수 있습니다.
- Adam: 모멘텀과 RMSprop을 결합한 방법으로, 딥러닝에서 가장 널리 사용되는 최적화 방법 중 하나입니다. 적응적인 학습률 조절과 관성 효과를 동시에 얻을 수 있습니다.
- Adagrad: 각 변수별로 학습률을 조절하는 방법으로, 희소한 데이터에 효과적입니다. 시간이 지날수록 학습률이 작아져서 학습이 느려질 수 있습니다.
- Adadelta: Adagrad의 단점을 개선하여 학습률이 너무 작아지는 문제를 해결한 방법입니다.
- 경사 하강법 (Gradient Descent): 손실 함수의 기울기(경사)를 이용해 함수의 최솟값을 찾아가는 방법입니다. 가장 기본적인 최적화 방법이지만, 학습률 설정에 따라 수렴 속도나 최적 지점 도달에 어려움이 있을 수 있습니다.
경사하강법(Gradient Descent Algorithm)
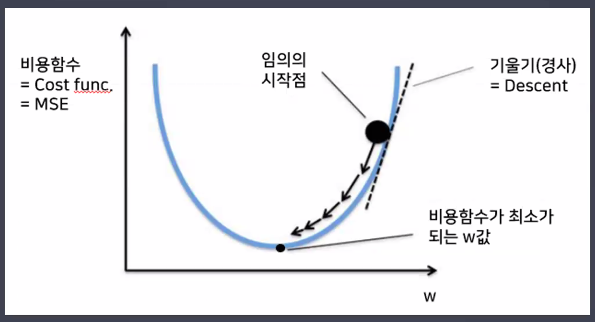
- 네트워크의 파라미터들을 라고 했을 때 Loss function 의 optima(최소화)를 찾기 위해 파라미터의 기울기(gradient)를 이용하는 방법

- 는 learning rate → 갱신 속도를 결정
- 에 loss function을 미분한 값을 곱해 빼주며 갱신
- 최종 목표: 초기값부터 시작해서 최종적인 minimum에 도달하는 것
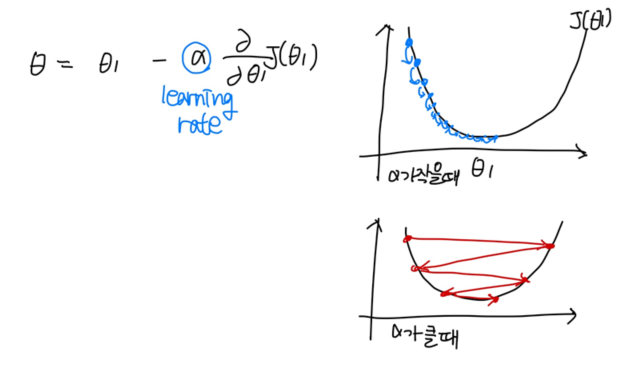
- learning rate에 따른 수렴 정도
- 는 learning rate → 갱신 속도를 결정
- 전체 데이터를 이용해 업데이트
- 한 번 학습할 때마다 시간이 오래 걸림
- 데이터 크기에 따라 세 가지로 나눔:
- 확률적 경사 하강법(Stochastic Gradient Descent, SGD)
- 임의로 선택한 하나의 데이터에 대해 에러를 구한 뒤 기울기를 계산 후 파라미터 업데이트
- 확률적으로 선택된 일부 데이터를 이용해 업데이트
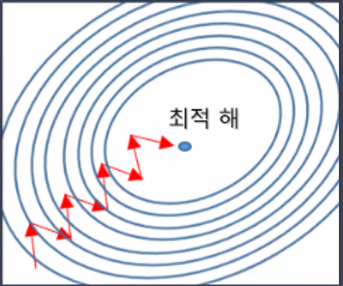
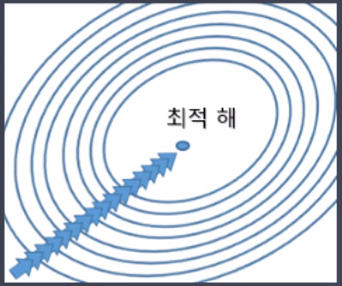
- local minima에 빠질 위험은 적지만(지역 최저점을 빠져나갈 수 있음) optimal을 찾지 못할 가능성이 있음
- 배치 GD보다 더 빨리, 더 자주 업데이트
- 탐색 경로가 비효율적(진폭이 크고 불안정)
- Batch Gradient Descent(BGD)
- 전체 데이터 세트에 대한 에러를 구한 뒤 기울기를 한 번만 계한 후 파라미터 업데이트
- loss가 안정적으로 수렴하지만 학습이 오래 걸리며 local minima에 걸릴 수 있음
- Mini-batch Gradient Descent(MGD)
- 전체 데이터 세트에서 뽑은 mini-batch의 데이터에 대하여 mini-batch별 기울기를 구해 평균 기울기를 계산하고 그때마다 파라미터를 업데이트
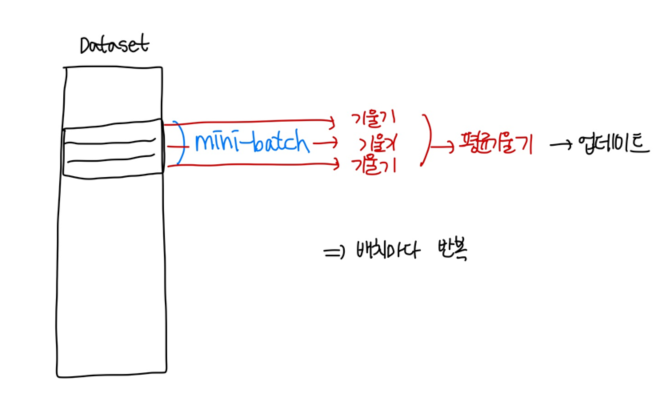
- 전체 데이터 세트에서 뽑은 mini-batch의 데이터에 대하여 mini-batch별 기울기를 구해 평균 기울기를 계산하고 그때마다 파라미터를 업데이트
- 확률적 경사 하강법(Stochastic Gradient Descent, SGD)
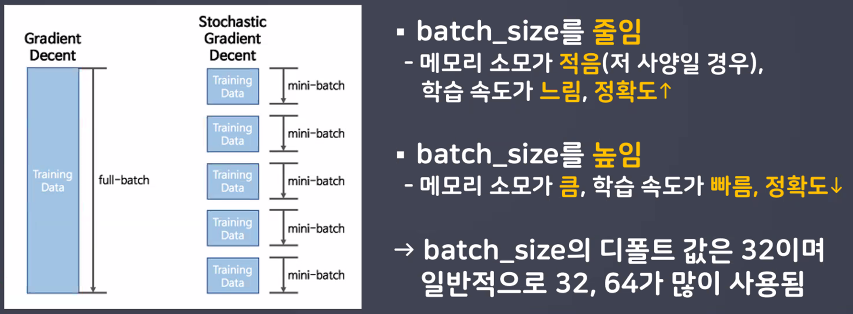
Batch_size
일반적으로 PC 메모리의 한계 및 속도 저하 때문에 대부분의 경우 한 번의 epoch에 모든 데이터를 한꺼번에 집어넣기가 힘듦
모멘텀(Momentum)
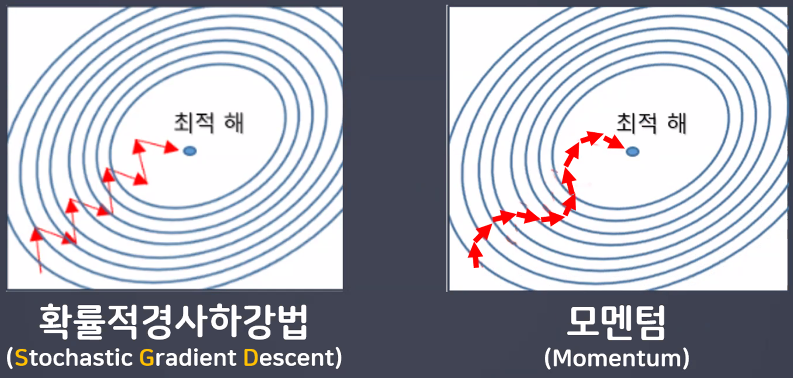
- Gradient Descent의 단점을 보완 → 경사하강법에 관성을 적용해 업데이트
- GD 단점: 기울기가 0인 점을 잘 벗어나지 못한다, 학습이 느리다 → 관성, momentum을 적용해 보완
- 관성: 변수가 가던 방향으로 계속 가도록 하는 속도항을 추가 → 기울기가 0이더라도 속도가 있어 더 잘 탈출함
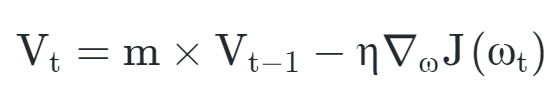
- 는 이전 이동거리와 관성계수 m에 따라 파라미터를 업데이트하도록 수식이 적용됨
- 현재 batch뿐만 아니라 이전 batch 데이터의 학습 결과도 반영
- 특징
- 가중치를 수정하기 전 이전 방향을 참고하여 업데이트
- 지그재그 형태로 이동하는 현상이 줄어듦
- momentum이 없다면 최소값을 향해 접근할 때 learning rate에 맞춰 진동폭이 동일하게 접근 & learning rate가 훨씬 크다면 발산할 가능성 있음
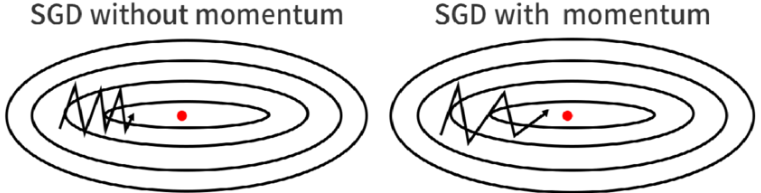
- 관성을 이용하면 세로축에 대해서는 느리게 , 가로축 방향으로는 빠르게 움직여 최소값에 더 잘 접근하도록 적용할 수 있음
- momentum이 없다면 최소값을 향해 접근할 때 learning rate에 맞춰 진동폭이 동일하게 접근 & learning rate가 훨씬 크다면 발산할 가능성 있음
- 는 Learning rate, m은 momentum 계수 (보통 0.9)
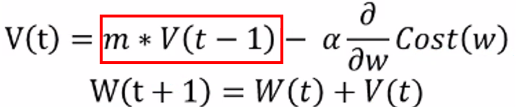
네스테로프 모멘텀(Nesterov Accelrated Gradient, NAG)
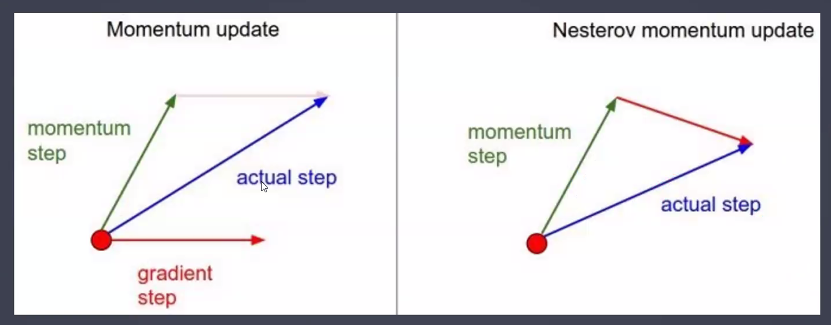
- 개선된 모멘텀 방식
- w, b값 업데이트 시 모멘텀 방식으로 먼저 더한 다음 계산
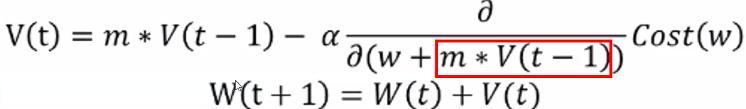
- 미리 해당 방향으로 이동한다고 "가정"하고 기울기를 계산해본 뒤 실제 업데이트 반영
- 일단 관성 방향 먼저 움직이고 움직인 자리에 스텝을 계산하니 더 빠르더라는 이야기
- 불필요한 이동 감소
- w, b값 업데이트 시 모멘텀 방식으로 먼저 더한 다음 계산
에이다그래드(Adaptive Gradinet, Adagrad)
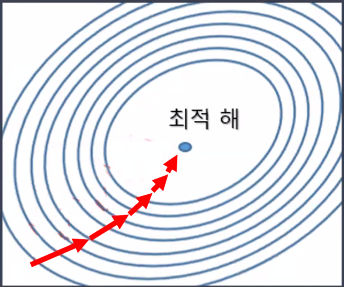
- 학습을 진행하면서 학습률을 점차 줄여가는 방법
- 처음에는 크게 학습하다가 조금씩 작게 학습 → 학습을 빠르고 정확하게 할 수 있음
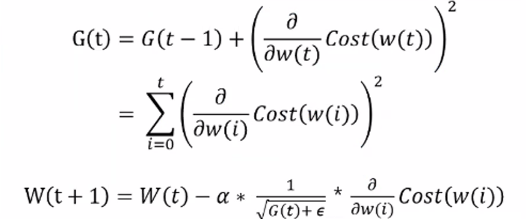
- 처음에는 크게 학습하다가 조금씩 작게 학습 → 학습을 빠르고 정확하게 할 수 있음
- 학습률 감소 방법을 적용해 업데이트
- 지금까지 많이 변화한 매개변수는 적게 변화하도록 하고, 적게 변화한 매개변수는 많이 변화하도록 learning rate의 값을 조절하는 개념
- 기존 GD에서 h를 곱해 학습률에 개입
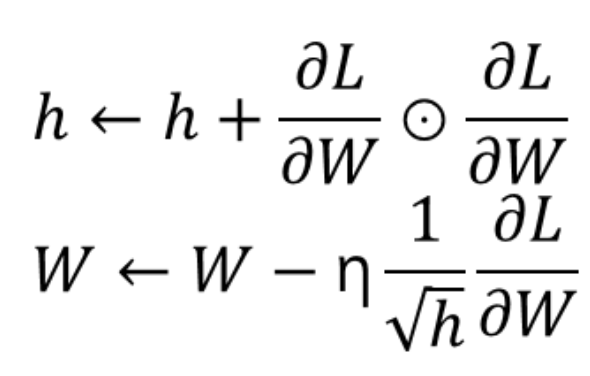
- h에는 매번 갱신될 때마다 해당 매개변수의 기울기값을 제곱하여 넣음
⊙: 아다마르 곱(Hadamard product) - 처음에는 학습률을 높이고 많이 이동할수록 학습률을 낮출 수 있음 → learning rate를 반비례로 적용
- h에는 매번 갱신될 때마다 해당 매개변수의 기울기값을 제곱하여 넣음
- 학습이 진행될수록 변화폭이 너무 줄게 되면 움직이지 않게 된다는 단점
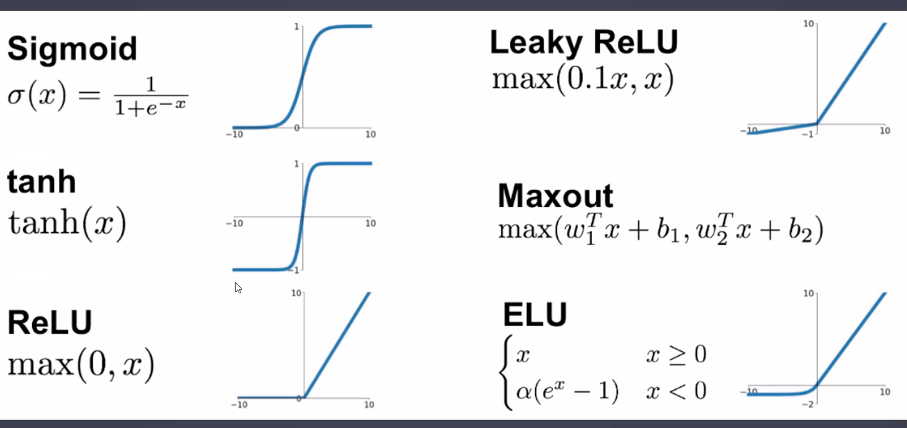
활성화 함수(Activation)의 종류
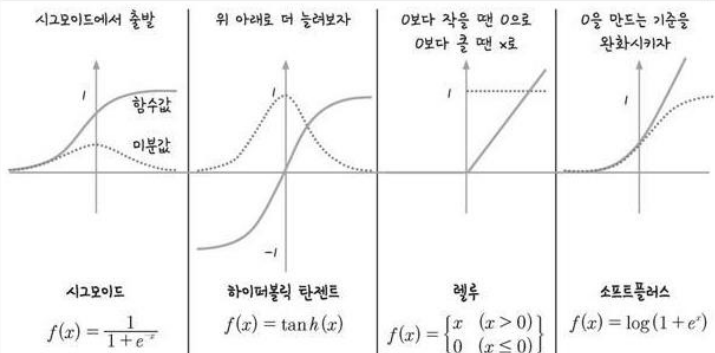
ReLU를 사용하는 이유
1. sigmoid 대신 ReLU를 사용하는 이유가 뭔가요?
- 가장 먼저 sigmoid, tanh, ReLU, Leaky ReLU 등의 정의와 그래프부터 파악해야 함
- 신경망(뉴럴넷; Neural Networks)에서는 입력된 값을 weight와 bias로 연산하고, 연산 결과를 활성화 함수(activation function)으로 처리
- sigmoid function 은 모든 실수를 0과 1사이의 값으로 변환하는 활성함수 → 각 노드의 결과값은 y=sigmoid(Wx+b)
- 신경망은 학습 과정에서 backpropagation이라는 방법을 이용해 결과값의 오차를 역전파해서 노드의 가중치 w를 수정 → chain rule에 의한 미분식
- 여기서 output은 2번째 은닉층의 결과에 활성함수를 적용한 결과, 즉 sigmoid(z1)
- 2번째 은닉층의 입력값인 hidden2는 1번째 은닉층의 결과에 활성함수를 적용한 결과, 즉 sigmoid(z2)
- 이처럼 sigmoid를 활성함수로 사용하는 신경망은 역전파 학습 시 sigmoid 미분값이 chain rule에 의해 곱해진다:
- 여기서 sigmoid function의 미분값은 (0, 0.25) 범위에 존재
- 따라서 레이어의 층수가 깊어질수록 레이어의 미분값인 d(error)/d(w1)는 매우 작아짐 → sigmoid 함수의 미분값인(0, 0.25) 값이 곱해지니까
- 이로 인해 최종 값의 오차가 앞에 있는 레이어까지 전달되지 않아서 신경망의 학습이 저하되는 vanishing gradient 문제가 발생
- ReLU는 max(0, x)로 음수는 모두 0으로 반환하고 양수는 값을 그대로 반환함
- 따라서 ReLU 함수의 미분은 음수는 모두 0, 양수는 모두 1 → sigmoid 대신 ReLU를 사용하면 chain rule이 적용될 때 레이어의 개수가 늘어나더라도 최종 결과의 오차를 레이어에 그대로 전달할 수 있음
- ReLU는 미분 불가능한데 BP가 어떻게 가능한가요?
- ReLU가 미분 불가능한 지점은 x=0일 때 뿐
- 실제 연산에서 x=0이 되는 경우가 극히 드물기 때문에 이를 무시하고 사용할 수 있다는 것이 일반적인 견해
- ※심화: ReLU의 미분불가능한 영역(x=0)이 backpropagation 연산에 미치는 영향에 대한 연구결과
- Bertoin et al., 2021. Numerical influence of ReLU’(0) on backpropagation @ NeurIPS 2021
- TensorFlow와 PyTorch 와 같은 상용 라이브러리에서는 ReLU'(0) = 0 으로 두고 전체 학습에 영향이 없을 것으로 가정하지만 저자인 Bertoin의 실험결과에 따르면 TF와 Torch의 기본셋팅인 32비트 연산에서는 x=0이 되는 지점(bifurcation zone)이 실제로 발생할 수 있고, 이 때 ReLU'(0)=0 또는 ReLU'(0)=1 으로 할 떄 학습결과에서 유의미한 차이가 발생할 수 있다고 주장함(동일한 학습을 16비트에서 할때는 결과가 더 안 좋아지고, 64비트에서는 문제가 없어진다고 함)
- 결론적으로, x=0인 minima가 거의 발생하지 않으므로 BP 자체는 문제가 없다고 가정할 수 있다. 그러나 이론적인 생각과 달리 컴퓨팅 과정에서 x=0 이 문제를 야기할 수도 있다.
- Leaky-ReLU는 무엇인가요?
- dying ReLU 문제(0보다 작은 입력값의 반환값과 미분값이 모두 0으로 반환되기 때문에 많은 뉴런들이 0으로 비활성화되는 단점) 보완을 위해 ReLU의 음수 구간에서 x보다 작은 값을 취할 수 있도록 정의한 함수
- Leaky-ReLU(x) = MAX(0.01x, x)
- 이외에도 ELU, PReLU 등 다양한 보완 방안이 존재
- 그러나 ReLU를 통해 뉴런이 0으로 변하는 것은 네트워크의 Sparsity를 높이는 장점이기도 함
- 따라서 어떤 게 더 좋냐는 질문보다는 해결해야 할 문제, 신경망의 구조, 그 외 학습 환경 등을 종합적으로 고려해서 가장 적합한 활성함수를 찾는 게 베스트
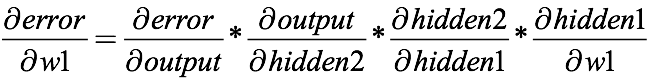

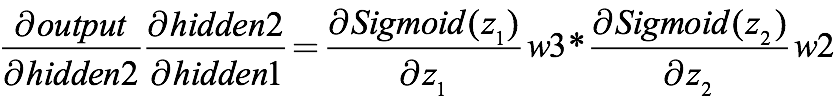
# ReLU 사용해보기
# ReLU 사용해보기
model = Sequential()
model.add(Input(shape=(30,)))
model.add(Dense(units=8, activation='relu'))
model.add(Dense(units=16, activation='relu'))
model.add(Dense(units=32, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))
model.compile(
optimizer="SGD" # 최적화 알고리즘(경사하강법)
, loss="binary_crossentropy" # 이진분류 → 분류: crossentropy
, metrics=["accuracy"] # 평가지표 (분류: 정확도)
)
h1 = model.fit(X_train, y_train, validation_split=0.2, epochs=20)
plt.figure(figsize=(5,5))
plt.plot(h1.history["loss"], label="loss")
plt.plot(h1.history["val_loss"], label="val_loss")
plt.legend()
plt.show()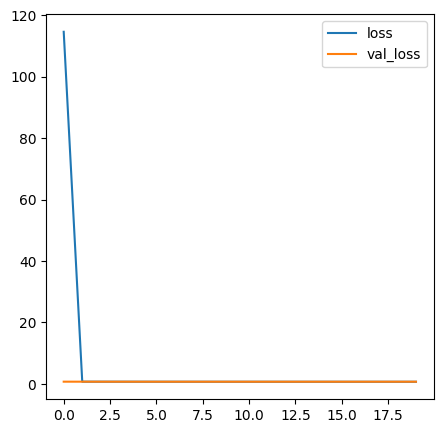
→ 시그모이드를 사용했을 때보다 훨씬 더 적은 epochs로 좋은 결과를 낼 수 있음
- P = L + A
- P: perceptron → 뉴런과 같은 역할
- L: Linear model
- A: Activation function → 추가 연산 진행
- 중간층: 활성화 여부 결정 (역치 역할)
- 출력층: 출력 형태 지정 → 회귀: Linear(항등함수
y=x), 이진분류: sigmoid(선형모델이 출력하는 연속적인 값(-∞ ~ ∞)을 sigmoid를 통해 0~1 사이 값으로 변환(확률값)
- 모델 학습 방법 및 평가 방법 설정
- optimizer: 경사하강법 기반 다양한 모델 사용
- loss
- 회귀: mse
- 분류: crossentropy → 이진분류: binary_crossentropy
- metrics
- 회귀: mse
- 분류: accuracy
- Optimizer 더 알아보기
실습: 손글씨 데이터 분류
학습 목표
- 손글씨 데이터를 분류하는 딥러닝 모델링을 설계해보자
- 다중분류 딥러닝 모델링을 연습해보자
- 이미지 데이터 기본 정보에 대해서 확인해보자
데이터 불러오기
- keras에서 제공하는 손글씨 데이터 불러오기
from tensorflow.keras.datasets import mnist
# 훈련용 데이터, 테스트용 데이터 구분해서 저장해 둠 → 변수에 담아주기
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 크기 확인
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# 훈련용 데이터 6만장
# 평가용 데이터 1만장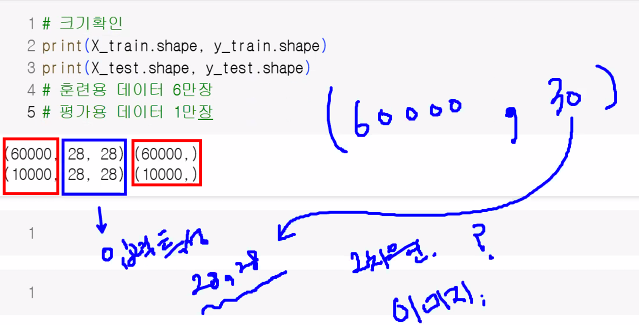
- Pixel(Picture Element; 화소)
- 디지털 이미지를 구성하는 최소 단위인 점
- 더 이상 나눌 수 없는 이미지의 최소 단위
- 디지털 이미지를 구성하는 최소 단위인 점
- 손글씨 데이터는
(28, 28)→ (28, 28, 1)에서 1을 생략한 것- 흑백 이미지라는 의미: 단순 0~255 1개 채널
- 컬러 이미지라면 (28, 28, 3) → 3은 색상 채널(RGB 컬러)
X_train[0].shape
# 28, 28 → 가로 28개, 세로 28개의 픽셀로 구성되어 있다!
# 픽셀: 사진의 정보를 가지는 최소 단위(이미지를 구성하는 작은 사각형 1개)
# 흑백 이미지 (28, 28, 1) → 얼마나 검은색인지, 흰색인지에 대한 정보를 담고 있음
# 0 (검은색), 255 (흰색)
X_train[0]
# 이미지 데이터는 넘파이 배열 형태로 출력이 된다
# 손글씨 데이터 그래프에 출력
plt.imshow(X_train[0])
# 왜 노란색으로 출력됨? cmap 파라미터 default 값이 'yellow'라서
plt.imshow(X_train[0], cmap='gray')
MLP 모델링
- 입력층 구조, 출력층 구조
- 학습 능력을 결정하는 중간층의 깊이 고려
- loss, optimizer 고려
- 학습 결과 시각화를 통한 일반화 판단
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Input, Dense, Flatten
# Flatten: 2차원의 입력 데이터를 1차원의 선형 모델이 학습할 수 있도록 해 주는 함수
# 2차원의 사진 데이터를 1차원으로 표현해 주기 위한 클래스
# 현재 우리 데이터 세트는 2차원: (28, 28) → 1차원의 선형 모델을 돌리기 위함
# 1. 모델 설계
# 뼈대
model = Sequential()
# 입력층
model.add(Input(shape=(28, 28))) # 28, 28의 2차원 이미지 데이터이다.
# 중간층
model.add(Flatten()) # 2차원의 사진 데이터를 1차원으로 변경(선형 모델 학습을 위함)
model.add(Dense(units=16, activation='relu'))
model.add(Dense(units=8, activation='relu'))
model.add(Dense(units=16, activation='relu'))
# 출력층 → 출력하고자 하는 데이터의 형태를 설계 → 다중분류
model.add(Dense(units=10, activation='softmax'))
# 분류는 확률값을 출력해야 함
# 다중분류 활성화함수: softmax
# 다중분류는 클래스 개수만큼의 units을 필요로 함
# 클래스 개수만큼의 결과 여러 개를 종합하여 총합이 1이 되게 만들어주는 함수: softmax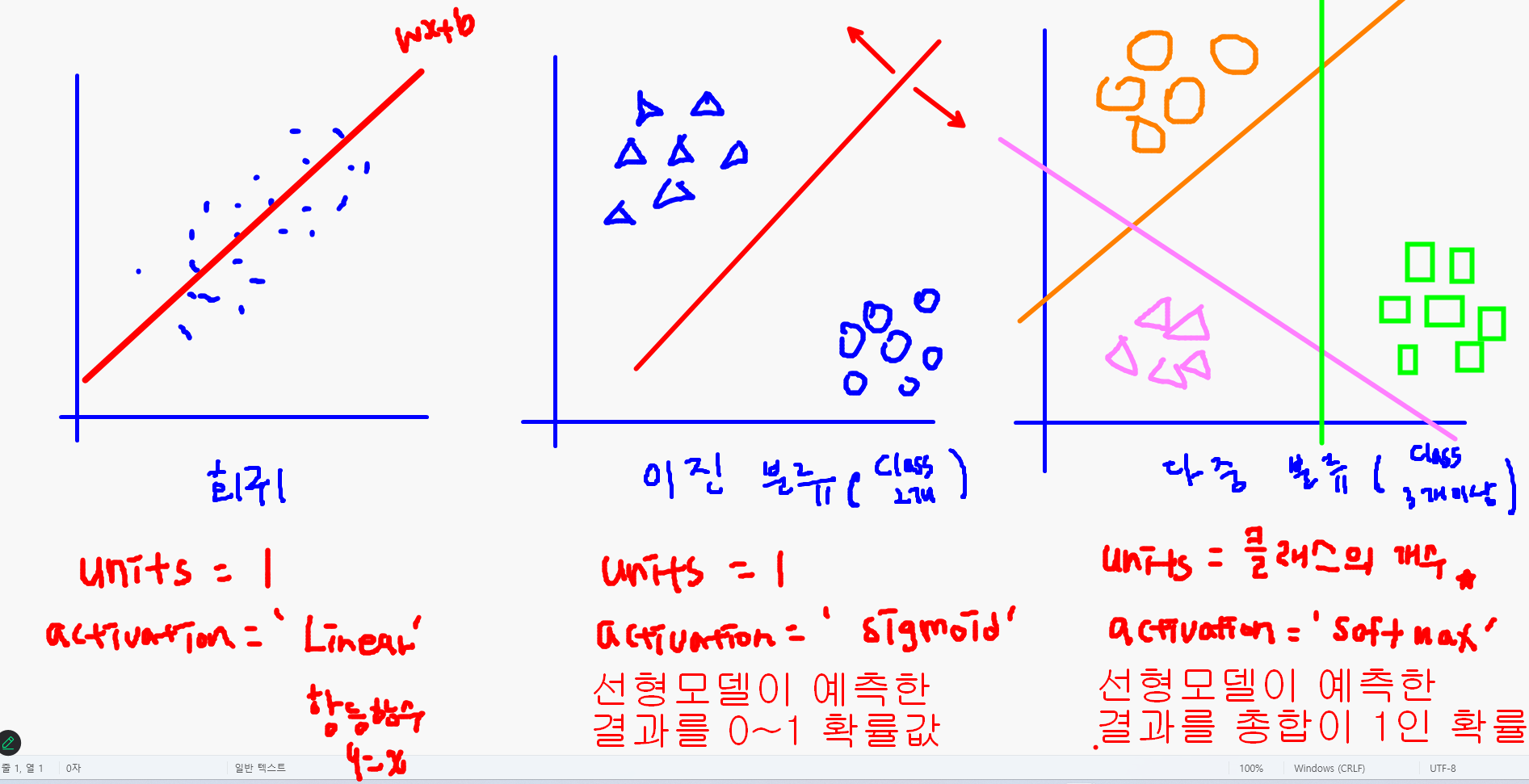
- units의 개수는 결국 직선의 개수라는 사실을 기억하자
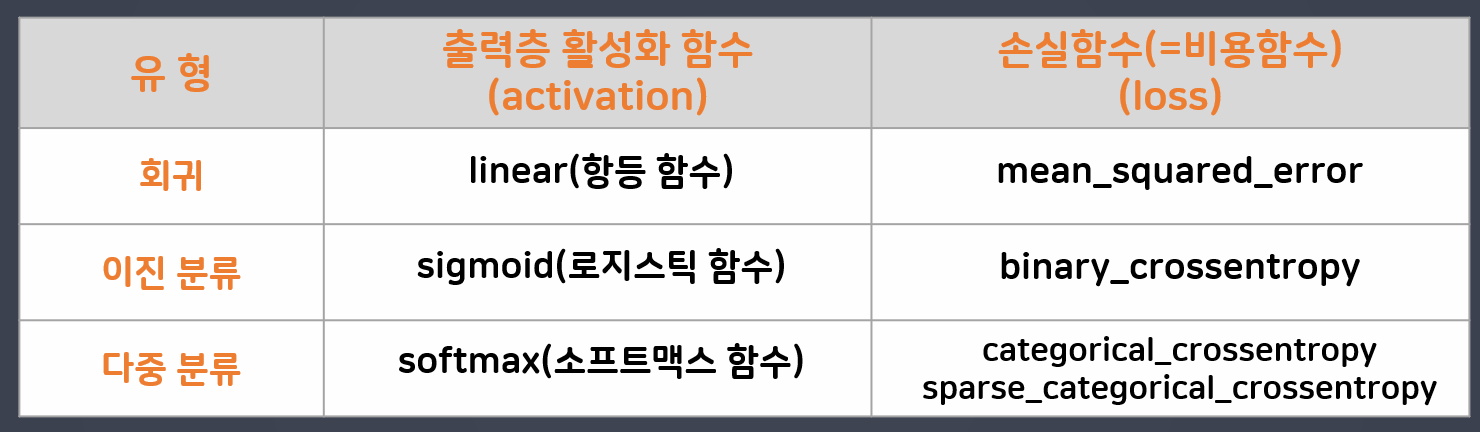
| 문제 유형 | 출력층 Unit 수 | 활성화 함수 | 설명 |
|---|---|---|---|
| 회귀 문제 | 1개 | 없음 (또는 linear) | - 항등함수: y = x- 선형 모델이 예측한 값을 그대로 출력 - activation을 지정하지 않으면 기본값- mean_squared_error 손실함수와 함께 사용 |
| 이진 분류 | 1개 | sigmoid | - 출력값은 0~1 사이 - 특정 클래스일 확률로 해석 가능 - 보통 binary_crossentropy 손실함수와 함께 사용 |
| 다중 분류 | 클래스 개수만큼 | softmax | - 각 클래스에 대한 확률값 출력 - 전체 합이 1이 되도록 정규화 - categorical_crossentropy 또는 sparse_categorical_crossentropy 손실함수와 함께 사용 |
# 2. 모델 학습 방법 및 평가 방법 설정
model.compile(
optimizer='SGD'
, loss='sparse_categorical_crossentropy' # y값에 대해 원핫 인코딩 자동 진행
, metrics=['accuracy']
)
# y는 하나의 숫자인데 output은 0~9 확률이 담긴 2차원 데이터
# compile에서 sparse_categorical_crossentropy 사용하면 원핫 인코딩을 해 줘서 오류 없이 학습 가능
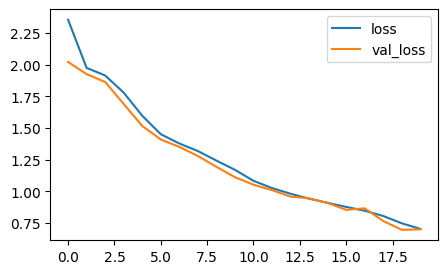
# 3. 모델 학습 및 시각화
h1 = model.fit(X_train, y_train, validation_split=0.2, epochs=20)
plt.figure(figsize=(5,3))
plt.plot(h1.history["loss"], label="loss")
plt.plot(h1.history["val_loss"], label="val_loss")
plt.legend()
plt.show()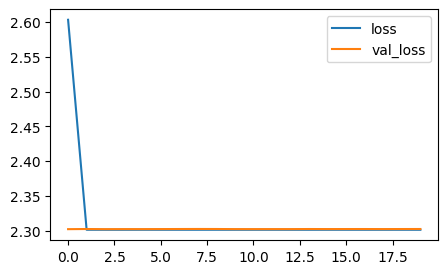
- 유형별 loss, activation
- 위에서 확인한 그래프와 함께 이해하면 좋음
하이퍼 파라미터 조절
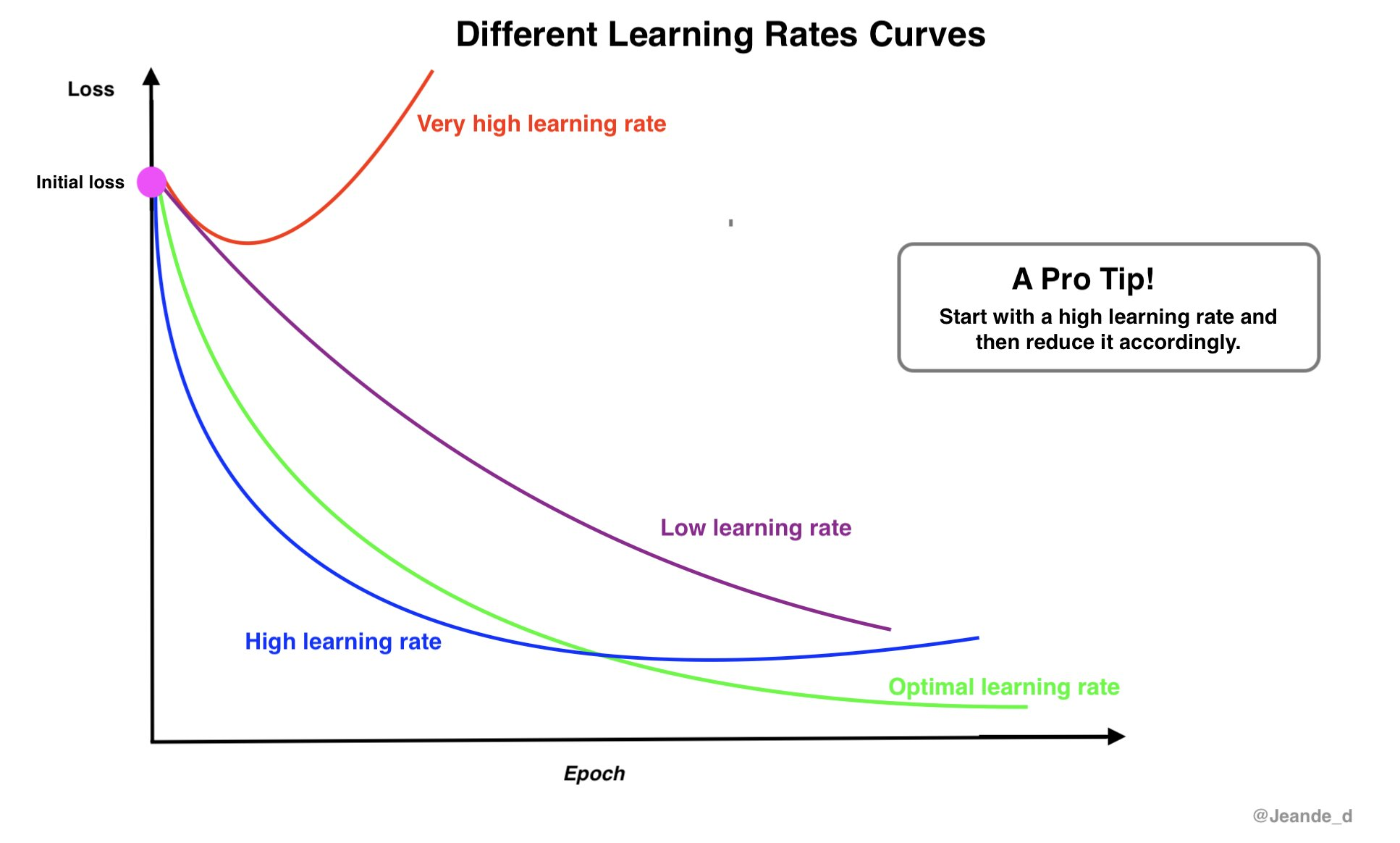
- 학습률(learning rate) == 보폭
- 오차의 크기 따라 조절
- 일반적으로 0.1, 0.01, 0.001로 변화시키며 실험
- 큰 값에서 작은 값으로 감소시키며 실험하는 것을 추천
- 큰 값에서 작은 값으로 감소시키며 실험하는 것을 추천
- 경사하강법에서 Learning Rate의 중요성과 적절한 학습률을 찾는 방법
- 경사하강법: 모델의 파라미터를 최적화하기 위해 사용되는 알고리즘
- 모델의 예측 값과 실제 값 간의 차이를 나타내는 손실 함수(loss function)의 기울기(Gradient)를 이용해 파라미터 업데이트
- learning rate(학습률, step size)
- 각 업데이트 단계에서 기울기에 곱해지는 스칼라 값
- 파라미터 업데이트의 크기를 조절 → 파라미터를 얼마나 업데이트할 것인지를 결정
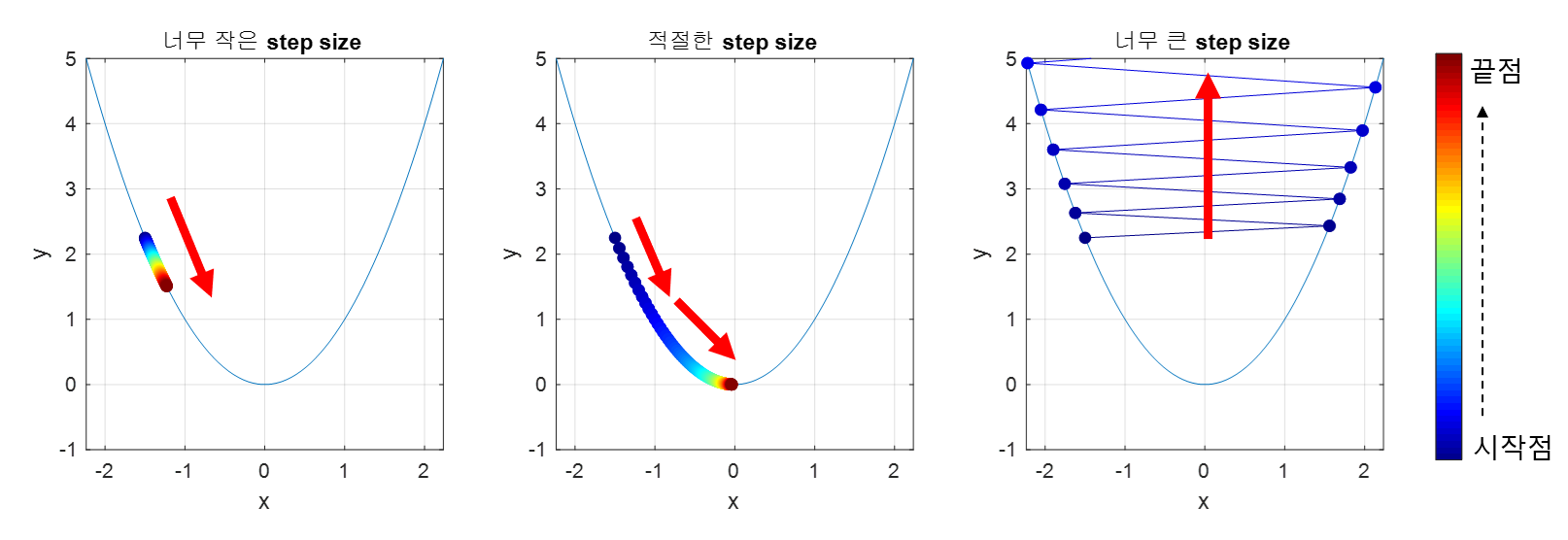
- 너무 크면 모델이 최적점을 지날 수 있고, 너무 작으면 학습 속도가 느려질 수 있음
- 최적의 learning rate는 모델의 수렴 속도와 안정성을 결정짓는 핵심 요소
- 각 업데이트 단계에서 기울기에 곱해지는 스칼라 값
- 경사하강법: 모델의 파라미터를 최적화하기 위해 사용되는 알고리즘
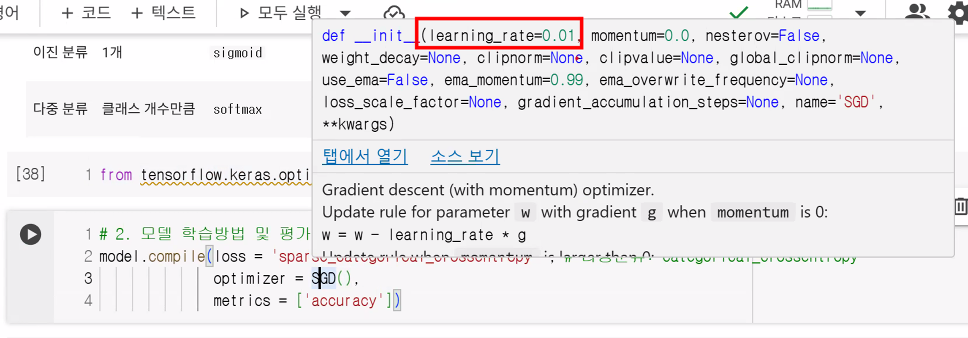
from tensorflow.keras.optimizers import SGD
model = Sequential()
model.add(Input(shape=(28, 28)))
model.add(Flatten())
model.add(Dense(units=16, activation='relu'))
model.add(Dense(units=8, activation='relu'))
model.add(Dense(units=16, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
model.compile(
optimizer= SGD(learning_rate=0.001)
, loss='sparse_categorical_crossentropy' # 다중분류: categorical_crossentropy
, metrics=['accuracy']
)
h1 = model.fit(X_train, y_train, validation_split=0.2, epochs=20)
plt.figure(figsize=(5,3))
plt.plot(h1.history["loss"], label="loss")
plt.plot(h1.history["val_loss"], label="val_loss")
plt.legend()
plt.show()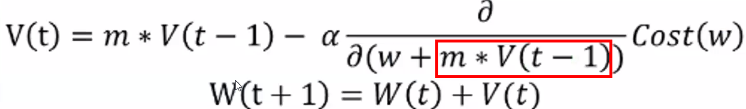
Carrer Up
- 기업 분석에서 어떤 인사이트를 얻으셨나요?
- 희망 기업 구체화
- 지원할 만한 기업인가?
- 조직 문화는 나와 잘 맞는가?
- 합격 가능성이 있는가?
- 희망 기업 현황(매출, 기술, 이슈 등)
- 안정적인 조직인가
- 발전과 성장이 기대되는가
- 경영 기타 이슈는 없는가?
- 희망 기업 채용 현황
- 채용공고가 많이 기재되는가?
- 대체 채용인가, 신규 채용인가?
- 동일 채용 건이 계속 되지는 않는가?
- JD를 통한 나의 목표 설정
- 담당 업무의 경우 내가 수행이 가능한가?
- 요구 역량에 내가 부합하는가?
- 필요 자격증은 어떤 것이 있는가?
- 희망 기업 구체화
- JD/채용공고는 평소에 틈틈히 많이 봐 주세요.
- 요구 능력을 정리하는 것만으로도 큰 도움이 됩니다.
- 이는 JD가 해당 분야의 최신 트랜드를 반영하기 때문입니다.
- 요구 능력을 정리하는 것만으로도 큰 도움이 됩니다.
- 내가 바꿀 수 없는 부분에 대해 빠르게 대체제를 찾는 것이 중요합니다.
- 자격증, 프로젝트 등으로 채우기
- 채용 공고를 계속 보면서 니즈에 적합한 사람으로 맞춰나가기 (보는 눈 키우기)
- 채용공고를 보다 보면 자신의 상태에 대한 예측에 따라 현재, 교육 수행 후, 5년 후 10년 후 이렇게 나눠서 계획을 세울 수 있음
- 이력서는 누가 읽을까요?
- 이력서: 지원자가 취업 목표 직무에서 성과를 내기 위해 필요한 역량(경험, 기술, 자격 등)을 갖추었다는 것을 어필하기 위한 문서
- 경력이 화려한 사람이 채용되는 것이 아니라 "채용 기업의 니즈에 적합한 사람"이 선택됨
- 따라서 역량을 강조해야 함 → 내가 내세울 수 있는 것이 무엇일까?
- 나의 성장 스토리를 항목별로 미리 적어놓고 조합해서 쓰기
- 이력서 종류
- 연대기적 이력서(경력직)
- 경력사항 등을 시간 역순으로 작성
- 동일 업종 및 유사 업종에 취업하는 경우
- 최근 직장 경력과 경험을 강조할 필요가 있을 때
- 최근 직장이 업종 선도업체인 경우
- 기능적 이력서(신입)
- 핵심 보유 역량 중심 작성
- 다른 업종, 다른 직무로 취업하고자 하는 경우
- 직장 이력보다는 보유 전문성을 강조
- 한 회사에서 장기 근속하면서 다양한 업무 수행
- 연대기적 이력서(경력직)
- 이력서 작성 순서
- 전략 구성
- 취업 목표, 직무 내용 검포, 채용 정보 분석을 통해 핵심 역량 파악
- 형식 결정
- 경력으로 어필 → 연대기 구성
- 역량으로 어필 → 기능적 구성
- 쓰기
- 이력서 순으로 작성
- 정보에 틀림이 없는지 검토
- 편집
- 읽는 사람 입장에서 검토하기
- 전체 스토리 라인 검토하기
- 전략 구성
- 신입 지원자의 경우
- 관심
- 이런 문제에 관심이 있다.
- 그래서 이런 걸 진행했다.
- 경험
- 이런 문제를 발견했다.
- 그래서 이렇게 풀었다.
- 그래서 비슷한 문제를 해결할 수 있다.
- 역량
- 나에게는 A, B, C 역량이 있다.
- 그래서 ㄱ, ㄴ, ㄷ 문제 해결이 된다.
- 실제 1, 2, 3 프로젝트를 진행했다.
- 세 가지가 하나의 핵심을 가지고 연결되어 있어야 함 → 중요한 건 "설득"
- 관심 == 경험 == 역량 → 동일한 스토리텔링이 중요함!
- 관심
- 일관적인 스토리텔링!
- A메 관심 -> A' 경험을 함 -> A'' 역량을 갖추게 됨
- 하나의 흐름으로 이어져야 가장 이상적
- 여러 가지를 계속 쌓아야 함 by JD 요구역량
- A 횟사 가고 싶어 -> b,c,d 역량이 필요해 -> 해당 역량을 쌓기 위해 b',c',d' 경험을 했어
- 논문 proposal 디펜스 하듯이 준비하기
- 3C4P
- What → Product
- Why → Customer / Company / Competitor
- How → Price / Place / Promotion
- 3C4P for 신입 지원자
- What → Project
- Why → 대의 / 역할 / 사례
- How → 가격 / 리소스 / 문제 해결 성공 경험
- 가장 중요한 것
- 이력서, 자소서는 결국 면접 질문지와 같다!
- 이번주 과제
- 이력서/자소서 작성 → 조금 먼 미래의
- 미니 프로젝트 공지
- 7월 미니 프로젝트 주제 이번주 공지 예정
- 7월 31일까지 각 조별로 과제 수행 완료 목표
하루 돌아보기
👍 잘한 점
- ReLU, 경사하강법 추가 공부
- 지급 받은 교재를 활용해 머신러닝 복습함
👎 아쉬웠던 점
- 커리어 업 시간에 집중을 잘 못했음
- 이력서를 써야 한다는 건 알겠는데 뭘 쓰면 좋을지 전혀 감이 안 오다 보니 내용을 들어도 좀 뜬구름 잡는 내용처럼 느껴졌음
🔬 개선점
- 이력서 작성 과제 최선을 다하기

2 B R 0 2 B