[인공지능사관학교: 자연어분석A반] 학습 내용 보충
실습: 다양한 조합으로 모델링
활성화 함수, 경사하강법, 은닉층 관련 내용 보충
활성화 함수와 경사하강법 조합별 성능 비교
- 각 조합의 학습 정확도(accuracy), 검증 정확도(val accuracy), 학습 손실(loss), 검증 손실(val loss)에 대한 비교해보기
1. sigmoid + SGD 조합
- 정확도(accuracy): 학습 및 검증 정확도가 매우 낮게 유지됨(약 0.1 수준)
- 손실(loss): 학습 손실과 검증 손실 모두 다른 조합에 비해 매우 높고, 거의 변화가 없음(약 2.3 이상)
- 해석: sigmoid + SGD 조합은 학습이 거의 이루어지지 않으며, 모델이 제대로 수렴하지 못하고 있음 → sigmoid 함수가 깊은 네트워크에서 gradient vanishing 문제를 일으키기 쉽고, SGD가 이를 극복하기 어렵기 때문
2. relu + SGD 조합
- 정확도(accuracy): 학습 정확도와 검증 정확도가 빠르게 상승하여 0.9 이상에 도달함
- 손실(loss): 학습 및 검증 손실이 빠르게 감소하고, 이후에는 완만하게 감소
- 해석: relu + SGD 조합은 sigmoid + SGD에 비해 훨씬 더 좋은 성능을 보임 → ReLU 활성화 함수가 gradient vanishing 문제를 완화하여 더 나은 학습이 가능
3. relu + Adam 조합
- 정확도(accuracy): 학습 및 검증 정확도가 가장 빠르고 안정적으로 0.95~1.0에 도달
- 손실(loss): 손실이 매우 빠르게 감소하며, 다른 조합에 비해 가장 낮은 값을 유지
- 해석: relu + Adam 조합이 세 조합 중 가장 뛰어난 성능을 보임 → Adam 옵티마이저가 학습률을 자동 조절하여 빠르고 안정적인 수렴을 유도
성능 요약 비교표
| 조합 | 학습 정확도 | 검증 정확도 | 학습 손실 | 검증 손실 | 특징 요약 |
|---|---|---|---|---|---|
| sigmoid + SGD | 매우 낮음 | 매우 낮음 | 매우 높음 | 매우 높음 | 학습 불가, 수렴 실패 |
| relu + SGD | 높음 | 높음 | 낮음 | 낮음 | 안정적 학습, 일반적인 성능 |
| relu + Adam | 매우 높음 | 매우 높음 | 매우 낮음 | 매우 낮음 | 가장 빠르고 안정적, 최고 성능 |
결론
- sigmoid + SGD: 실질적으로 학습이 이루어지지 않아 실전에서는 사용이 권장되지 않습니다.
- relu + SGD: 일반적으로 좋은 성능을 내며, 기본적인 조합으로 적합합니다.
- relu + Adam: 가장 빠르고 높은 성능을 보이며, 실무에서 가장 많이 사용되는 조합입니다.
relu + Adam 조합이 가장 우수하며, sigmoid + SGD 조합은 성능이 현저히 떨어집니다.
추가: 은닉층을 항아리 모양(bottleneck, hourglass)으로 만드는 이유
- 항아리 구조의 주요 목적은 입력 데이터의 특성을 점차 압축(bottleneck)했다가 다시 확장하는 과정에서, 중요한 정보를 추출하고 불필요한 노이즈를 줄이기 위함
- 가운데 좁아지는 부분(256)이 정보의 핵심 표현을 담당하며, 이를 통해 데이터의 차원을 줄이고, 이후 다시 확장하며 복잡한 패턴을 복원하거나 생성할 수 있음
- 하지만 설계 과정에서 특정 공식이나 절대적인 규칙이 있는 것은 아님
- 은닉층의 수와 각 층의 노드 수는 주어진 문제, 데이터 특성, 실험적 경험에 따라 결정되며, "항아리 모양"이 반드시 정답이라는 근거나 공식은 없음
- 실제 모델 설계에서는 실험과 경험이 중요 → 데이터의 복잡성, 모델의 과적합/과소적합 여부, 계산 자원 등을 고려해 다양한 구조를 시도하며 최적의 구조를 찾아야 함
딥러닝 모델의 은닉층 노드 수와 구조는 "공식이 없다"는 것이 정설이며, 다양한 구조를 실험하며 최적의 아키텍처를 찾는 것이 일반적입니다.
- 은닉층의 수와 각 층의 노드 수는 주어진 문제, 데이터 특성, 실험적 경험에 따라 결정되며, 특정 공식이나 절대적인 규칙이 있는 것은 아닙니다.
- 실제 모델 설계에서는 실험과 경험이 중요합니다. 데이터의 복잡성, 모델의 과적합/과소적합 여부, 계산 자원 등을 고려해 다양한 구조를 시도하며 최적의 구조를 찾습니다.
- 항아리(bottleneck, hourglass) 구조
- 주요 목적
- 입력 데이터의 특성을 점차 압축(bottleneck)했다가 다시 확장하는 과정에서, 중요한 정보를 추출하고 불필요한 노이즈를 줄이기
- 가운데 좁아지는 부분(256)이 정보의 핵심 표현을 담당하며, 이를 통해 데이터의 차원을 줄이고, 이후 다시 확장하며 복잡한 패턴을 복원하거나 생성
- 대표 예시: 오토인코더(autoencoder) 구조
- 오토인코더는 입력을 점점 줄여가며 잠재 공간(latent space)에 정보를 압축하고, 다시 원래 차원으로 복원합니다.
- 이때 중간의 bottleneck이 데이터의 중요한 특징을 요약하는 역할을 합니다.
- 항아리 구조의 장점: 정보 압축과 특성 추출
- 정보 압축 및 노이즈 제거
- 데이터의 핵심 특성 추출
- 복잡한 패턴 학습에 유리
- 항아리 구조가 항상 최적은 아니라는 점을 기억하기
- 모든 문제에 대해 이 구조가 최선인 것은 아니며, 데이터 특성이나 목적에 따라 다르게 설계할 수 있습니다.
- 예를 들어, 입력 데이터가 매우 복잡하거나, 다양한 패턴을 동시에 학습해야 할 때는 각 층의 노드 수를 다르게 조정할 수 있습니다.
- 주요 목적
units의 수가 2의 제곱인 이유
- Why should the number of neurons in a hidden layer be a power of 2?
- The main reason to pick powers of 2 is tradition in computer science. Provided there is no driver to pick other specific numbers, may as well pick a power of 2 . . . but equally you will see researchers picking multiples of 10, 100 or 1000 as "round numbers", for a similar reason.
- One related factor: If a researcher presents a result for some new technique where the hidden layer sizes were tuned to e.g. 531, 779, 282 etc, then someone reviewing the work would ask the obvious question "Why?" - such numbers might imply the new technique is not generic or requires large amounts of hyperparameter tuning, neither of which would be seen as positive traits. Much better to be seen using an obvious "simple" number...
- There is a hardware based reasoning. Matrix multiplication is one of the central computations in deep learning. SIMD operations in CPUs happen in batch sizes, which are powers of 2.
- Here is a good reference about speeding up neural networks on CPUs by leveraging SIMD instructions: Improving the speed of neural networks on CPUs
- You will notice batch sizes that are powers of 2. This is a good paper to read about implementing neural networks using SIMD instructions.
- The main reason to pick powers of 2 is tradition in computer science. Provided there is no driver to pick other specific numbers, may as well pick a power of 2 . . . but equally you will see researchers picking multiples of 10, 100 or 1000 as "round numbers", for a similar reason.
피라미드 형태 설계
- 딥러닝 구조에서 은닉층 노드 수를 피라미드 형태(점차 줄어드는 구조)로 설계하는 주요 이유
- 특징 추출 및 정보 압축
- 입력층에서 많은 정보를 받아들인 후, 은닉층을 거치며 점점 더 중요한 특징만을 추출하고 불필요한 정보를 걸러내는 효과가 있습니다. 즉, 상위 층으로 갈수록 데이터의 핵심적인 패턴만 남도록 압축하는 역할을 하게 됩니다.
- 과적합 방지
- 은닉층의 노드 수를 점차 줄이면, 모델이 너무 많은 파라미터를 갖지 않게 되어 과적합(overfitting) 위험을 줄일 수 있습니다. 불필요하게 큰 네트워크는 학습 데이터에만 특화되어 새로운 데이터에 일반화가 어렵기 때문입니다.
- 계산 효율성
- 입력에서 출력으로 갈수록 노드 수가 줄어들면 계산량과 메모리 사용량이 줄어들어 효율적입니다. 이는 실제 모델 구현과 운용에서 중요한 요소입니다.
- 문제의 복잡도와 데이터 특성에 맞춘 설계
- 피라미드 구조는 입력 데이터의 차원이 높고, 출력이 상대적으로 단순할 때 자주 사용됩니다. 예를 들어, 이미지 분류 문제에서는 수많은 픽셀(입력)을 받아 점차 압축해 하나의 클래스(출력)로 예측하는 구조가 자연스럽게 피라미드 형태가 됩니다.
- 공식은 없고, 경험적 선택
- 은닉층과 노드 수의 결정에는 정해진 공식이 없으며, 데이터와 문제 특성, 실험적 결과에 따라 달라집니다. 피라미드 구조는 널리 쓰이는 경험적 설계 중 하나입니다.
- 특징 추출 및 정보 압축
- 따라서, 피라미드 형태의 은닉층 구조는 정보 압축, 과적합 방지, 계산 효율성, 그리고 데이터 특성에 맞는 특징 추출을 위해 자주 활용되는 설계 방식입니다. 그러나 모든 문제에 항상 최적은 아니며, 실험과 검증을 통해 구조를 결정하는 것이 일반적입니다.
- 다양한 입력 데이터를 동시에 분석해야 하거나, 데이터의 특징이 계층적으로 뚜렷하지 않은 경우에는 노드 수를 균등하게 하는 것이 더 효과적일 수 있습니다. (입력 데이터의 특성과 문제의 복잡성에 따라, 각 은닉층이 동일한 수준의 표현력을 갖는 것이 더 효과적일 수 있음)
- 균등 구조의 장점
- 설계와 튜닝이 간단: 각 층의 노드 수가 같으면, 하이퍼파라미터 설정과 구조 변경이 단순해집니다.
- 균일한 정보 처리: 모든 은닉층이 비슷한 수준의 정보 처리 능력을 가져, 특정 층에서 정보 손실이나 병목 현상이 발생할 가능성이 줄어듭니다.
- 실험적 접근: 다양한 입력 데이터를 동시에 분석하거나, 데이터의 특징이 계층적으로 뚜렷하지 않을 때는 균등 구조가 더 나은 성능을 보일 수 있습니다.
- 균등 구조도 드롭아웃 등 규제 기법을 활용하면 과적합을 효과적으로 제어할 수 있음
- 균등 구조의 장점
- 문제의 특성, 데이터의 양, 하드웨어 자원, 실험 결과, 문제의 복잡성, 실험적 유연성 등 여러 이유에서 최적의 아키텍쳐를 찾는 것이 일반적
학습 중 loss 값이 None으로 나오는 경우
- input data에 nan이 있지 않나요?
- df.isna().any() 등으로 확인해보기
- 데이터 타입이 float로 변경해 주세요.
- learning rate가 너무 높지는 않나요?
- Optimizer를 바꿔봅시다.
- 특성 스케일 방법을 바꿔 보세요.
- (0, 1)을 (-1,1)fh
- 데이터와 output size가 불일치하지는 않나요?
Pytorch
Tensor 관련 내용 보충
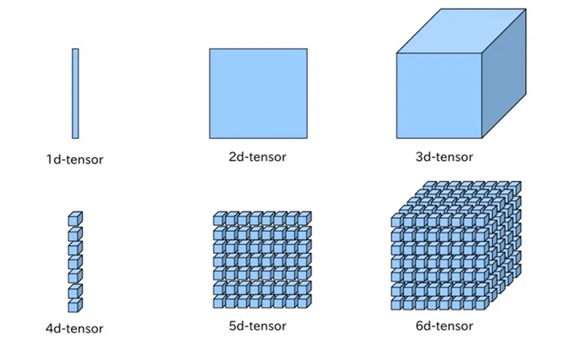
- 스칼라: 숫자가 1개 있을 때
- 벡터: 숫자가 여러 개 나열되어 있을 때
- 행렬
- 텐서: 행렬이 여러 개 모임
- 데이터 사이언스 분야에서는 3차원 이상의 텐서를 다차원 행렬 또는 배열로 간주
| 데이터 타입 | 별칭 | 비트 수 | 설명 |
|---|---|---|---|
| torch.float32 | torch.float | 32 | 단정밀도 부동소수점, 일반적인 딥러닝 연산에 사용 |
| torch.float64 | torch.double | 64 | 배정밀도 부동소수점, 높은 정밀도 필요 시 사용 |
| torch.int16 | torch.short | 16 | 부호 있는 정수, 메모리 효율성 필요 시 사용 |
| torch.int32 | torch.int | 32 | 부호 있는 정수, 일반적인 정수 연산에 사용 |
| torch.int64 | torch.long | 64 | 부호 있는 정수, 큰 정수값이나 인덱싱에 사용 |
| torch.uint8 | - | 8 | 부호 없는 정수 (0~255), 이미지 처리에 사용 |
| torch.bool | - | - | 불리언 (True/False), 논리 연산에 사용 |
| torch.float16 | torch.half | 16 | 반정밀도 부동소수점, 메모리 절약과 속도 향상 시 사용 |
| torch.int8 | - | 8 | 부호 있는 정수 (-128~127), 높은 메모리 효율성 필요 시 사용 |
| torch.complex64 | - | 64 | 32비트 실수부 + 32비트 허수부 복소수 |
| torch.complex128 | - | 128 | 64비트 실수부 + 64비트 허수부 복소수 |

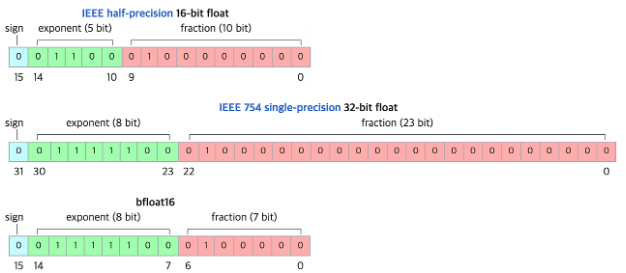
bf16과 fp16은 모두 수치 형식(numerical format)으로, 컴퓨터에서 부동 소수점 수(floating-point numbers)를 표현하는 방법 중 하나
- bf16
- bfloat16의 준말
- 16비트 부동 소수점 형식을 나타냄
- 인공지능 분야에서 널리 사용
- 인텔의 최신 프로세서와 같은 하드웨어에서 지원
- 32비트 부동 소수점 형식보다는 정확도가 떨어지지만, 메모리 요구 사항이 적으므로 모델 학습에 유용
- fp16
- half-precision의 준말
- 16비트 부동 소수점 형식을 나타냄
- 메모리를 적게 사용하므로 딥 러닝 분야에서 매우 인기가 있음
- 그러나 16비트의 정밀도가 낮아서 모델의 정확도가 떨어질 수 있음
- 따라서 모델을 훈련할 때는 일반적으로 fp32(32비트 부동 소수점 형식)를 사용하고, 추론(inference) 단계에서는 fp16을 사용하여 연산 속도를 높이는 경우가 많음
- 간단히 말해서, bf16과 fp16은 모델을 더 빠르게 실행하고 메모리를 절약하는 데 도움이 되는 부동 소수점 형식
- 그러나 정확도는 낮아질 수 있으므로, 모델의 특성에 따라 사용 여부를 결정해야 함
- 언제 bf16, fp16, fp32를 써야할까?
- bf16, fp32, fp16은 각각 메모리 사용량과 연산 속도, 정밀도 등의 측면에서 서로 다른 특성을 가지고 있습니다. 따라서 사용하는 모델의 특성에 맞게 선택하는 것이 중요합니다.
- bf16: 인공지능 분야에서 주로 사용되는 부동 소수점 형식으로, fp32보다 메모리 사용량이 작지만 정밀도가 더 낮습니다. 모델 학습시 fp32 대비 메모리 사용량을 약 50% 줄일 수 있으며, 정확도 손실이 크지 않은 경우에 사용됩니다.
- fp32: 일반적으로 모델 학습에 사용되는 부동 소수점 형식입니다. fp16과 비교하여 정밀도가 높으며, 모델의 정확도를 높일 수 있습니다. 그러나 연산 속도가 느리고 메모리 사용량이 크기 때문에 대규모 모델 학습에는 제한적입니다.
- fp16: 딥 러닝 추론(inference) 분야에서 많이 사용되며, fp32 대비 연산 속도가 빠르고 메모리 사용량이 적습니다. 그러나 정밀도가 낮아서 모델의 정확도가 떨어질 수 있으며, 따라서 학습에는 적합하지 않습니다.
- 따라서, 모델 학습시에는 fp32를 사용하고, 추론시에는 fp16을 사용하는 것이 일반적입니다. 그러나 모델 특성에 따라 bf16이나 다른 형식을 선택할 수도 있습니다. 또한, 하드웨어나 프레임워크의 지원 여부에 따라 선택할 수 있는 형식이 제한될 수 있으므로, 이를 고려하여 선택해야 합니다.
- bf16, fp32, fp16은 각각 메모리 사용량과 연산 속도, 정밀도 등의 측면에서 서로 다른 특성을 가지고 있습니다. 따라서 사용하는 모델의 특성에 맞게 선택하는 것이 중요합니다.
-
Mixed Precision
-
fp16, fp32를 혼합하면서 모델학습에 사용하는 방식
-
학습에 사용되는 메모리 사용량을 최적화하여 학습을 가속화 하면서도 모델의 정확도를 유지할 수있음
-
일반적으로 Mixed precision은 다음과 같은 과정이 존재:
- 모델의 가중치(weight)는 fp32 형식으로 저장
- 입력 데이터는 fp16 형식으로 변환하여 처리
- fp16 형식으로 처리하는 도중에 정밀도가 손실될 가능성이 있으므로, 일정 주기마다 가중치를 fp32로 복사하여 정밀도를 보정
- 역전파(backpropagation) 과정에서도 fp16을 사용하여 연산 속도를 높임
- 학습이 끝나면, 모델의 가중치를 다시 fp32로 변환하여 저장함
-
fp32를 사용할 때보다 많은 메모리 사용을 줄일수가있어서, 일반적으로 대규모 모델 학습에 사용됨
-
'3번에서 가중치를 복사하면 오히려 메모리 사용량이 커질 수 있지 않을까?'라고 생각할 수 있는데 생각보다 이 복사하는 것이 메모리를 크게 잡아먹지 않는다고 함.
-

2 B R 0 2 B