[인공지능사관학교] Pandas (2)
파이썬 공부 보충
- 파이썬 문제
- 교재
- 내용 정리한 및 파이썬 기본 구문 시각화
- 그 외
- 변수에 대해선 종이에 코드나 순서도를 그린 뒤에 변수가 어떻게 변화해 가는지 손으로 써보시면 코드로 바로 쳐보는 거보다 훨씬 직관적으로 이해에 도움이 됩니다.
지난 시간 리뷰
- AX라는 단어가 가지고 있는 함의 이해하기
- 데이터베이스, 운영체제, 네트워크 이해 필수!
Pandas 데이터 응용
- Pandas를 알아두면 데이터 분석에 대한 전반적인 이해가 가능
- Pandas를 활용하면:
- 다양한 형식의 데이터를 쉽게 읽어올 수 있음
- 어떤 분야에서
- 왜
- 어떻게 가져오는지 이해!
- 데이터프레임을 조작하는 다양한 메서드와 속성을 사용할 수 있음
- 다양한 형식의 데이터를 쉽게 읽어올 수 있음
- 배울 내용:
- 데이터 불러오는 방법
- DataFrame의 주요 메서드 및 속성
데이터 읽어오기(Reading Data)
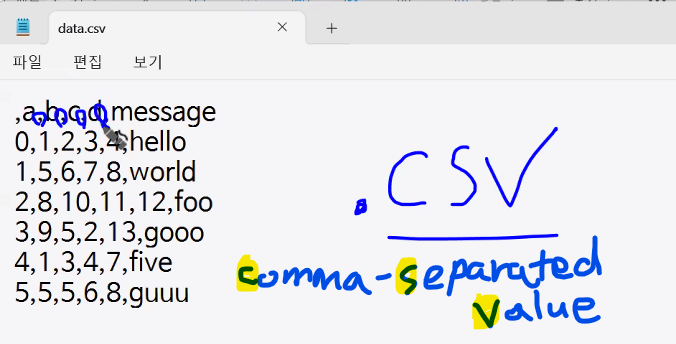
CSV 파일 읽기(pd.read_csv())
- CSV 파일: 데이터 분석에서 가장 많이 사용하는 형식
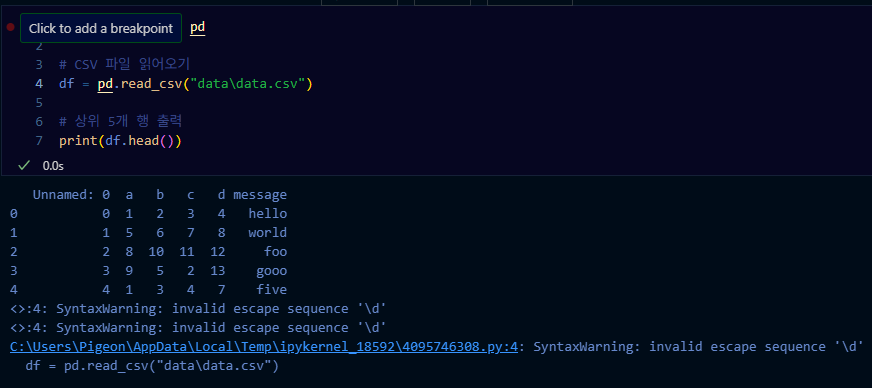
import pandas as pd
# CSV 파일 읽어오기
df = pd.read_csv("data\data.csv")
# 상위 5개 행 출력
print(df.head())
주요 옵션
| 옵션 | 설명 |
|---|---|
| sep=',' | 구분자(기본값: ,) |
| header=0 | 첫 번째 행을 컬럼명으로 사용(기본값) |
| index_col=0 | 첫 번째 행을 인덱스로 설정 |
| encoding="utf-8" | 한글 데이터를 위한 인코딩 설정 |
해당 내용은 경고 메시지고 에러는 아닙니다.
역슬래시를 두번쓰면 경고 메시지가 사라집니다.
#log\\.login > span이런 식으로 말이죠 ㅎㅎ
(1) 셀렉터를 만들때 필요한 \
(2) 문자열에서 역슬래시를 만들때 필요한 \파이썬 이스케이프 시퀀스(escape sequence)
\\백슬래쉬
\'작은 따옴표
\n줄바꿈 → lineFeed, LF, 개행문자, EOL(end-of-line)
\r캐리지 리턴 → Carriage Return, CR
▶ 경로를 표현할 때
path = 'C:\Users\...\project\test.csv'
경로의 구분을 의미하는\가 뒤의 문자와 만나면서\U,\M,\D,\D,\p,\t특수 문자, 즉 이스케이프 시퀀스로 인식
→ 해결 방법 1:\를 하나씩 더 붙여준다.
path = 'C:\\Users\\...\\project\\test.csv'
→ 해결 방법 2: 경로명 앞에 r(raw) 붙여주기(=있는 그대로 쓰겠다는 의미)
path = r'C:\Users\...\project\test.csv'
Excel 파일 읽기(pd.read_excel())
- 엑셀 파일도 읽을 수 있음
df = read_excel(r"data\data.xlsx:, sheet_name="sheet1")
print(df.head())주요 옵션
| 옵션 | 설명 |
|---|---|
| sheet_name="sheet1" | 특정 시트 읽기 |
| usecols="A:C" | 특정 열만 읽기 |
| skiprows=2 | 처음 2줄 건너뛰기 |
sheet_name=0: 첫 번째 시트sheet_name=1: 두 번째 시트

JSON 파일 읽기(pd.read_json())
- JSON 파일을 읽을 때 사용
df = pd.read_json(r"data\data.json")
print(df.head())데이터베이스에서 읽어오기(pd.read_sql())
- 데이터베이스에서 데이터를 가져올 때 사용
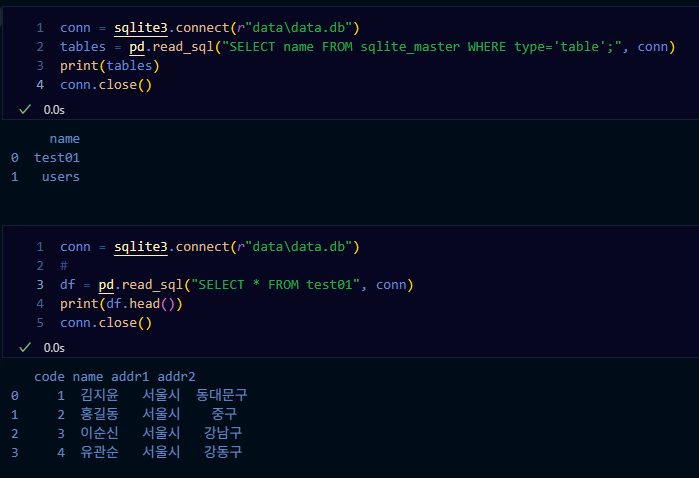
import sqlite3
# SQLite 데이터베이스 연결
conn = sqlite3.connect(r"data\database.db")
# SQL 쿼리 실행하여 데이터 가져오기
df = pd.read_sql("SELECT * FROM users", conn)
print(df.head())
# 연결 종료
conn.close()추가:
MySQL과 연동하기
import pymysql
conn = pymysql.connect(host=’127.0.0.1′, user=’root’, password=’0000′, db=’soloDB’, charset=‘utf8’)
cur = conn.cursor()
cur.execute(“CREATE TABLE userTable (id char(4), userName char(15), email char(20), birthYear int)”)
cur.execute(“INSERT INTO userTable VALUES( ‘hong’ , ‘홍지윤’ , ‘hong@naver.com’ , 1996)”)
conn.commit()
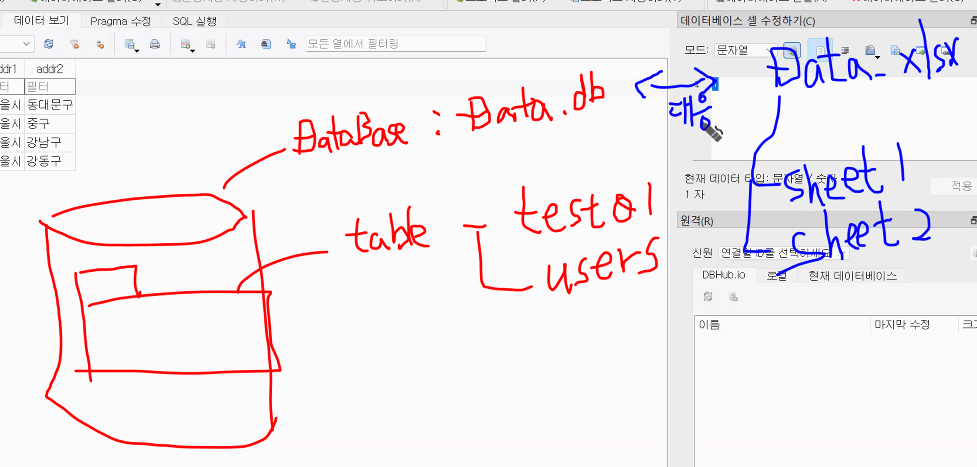
conn.close()sqlite browser
DataBase: 공유성, 실시간성, 백업성
→ 고도화시킨 데이터의 집약체
DataFrame의 메서드와 속성
DataFrame의 주요 속성
- 속성은
()없이 사용 - 데이터프레임의 정보를 확인할 때 유용
df = pd.DataFrame({"이름": ["철수", "영희", "민수"], "나이": [25, 30, 28]})
print("데이터프레임의 크기(행, 열):")
print(df.shape)
print("컬럼명:")
print(df.columns)
print("인덱스 정보:")
print(df.index)
print("각 열의 데이터 타입:")
print(df.dtypes)
print("데이터프레임을 NumPy 배열로 변환:")
print(df.values)# [Out]
데이터프레임의 크기(행, 열):
(3, 2)
컬럼명:
Index(['이름', '나이'], dtype='object')
인덱스 정보:
RangeIndex(start=0, stop=3, step=1)
각 열의 데이터 타입:
이름 object
나이 int64
dtype: object
데이터프레임을 NumPy 배열로 변환:
[['철수' 25]
['영희' 30]
['민수' 28]]데이터프레임 조회 메서드
- 데이터를 빠르게 조회할 때 사용
print("데이터프레임의 상위 3개 행 출력:")
print(df.head(3))
print("데이터프레임의 하위 2개 행 출력:")
print(df.tail(2))
print("데이터프레임의 정보 출력:")
print(df.info())
print("데이터프레임의 수치형 데이터 요약 통계량:")
print(df.descirbe())# [Out]
데이터프레임의 상위 3개 행 출력:
이름 나이
0 철수 25
1 영희 30
2 민수 28
데이터프레임의 하위 2개 행 출력:
이름 나이
1 영희 30
2 민수 28
데이터프레임의 정보 출력:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 이름 3 non-null object
1 나이 3 non-null int64
dtypes: int64(1), object(1)
memory usage: 180.0+ bytes
None
데이터프레임의 수치형 데이터 요약 통계량:
나이
count 3.000000
mean 27.666667
std 2.516611
min 25.000000
25% 26.500000
50% 28.000000
75% 29.000000
max 30.000000특정 열 선택([], .loc, .iloc)
print("특정 열 선택:")
print(df["이름"])
print("여러 열 선택:")
print(df[["이름", "나이"]])
print("인덱스 0번 행 선택:")
print(df.loc[0])
print("두 번째 행 선택:")
print(df.iloc[1])# [Out]
특정 열 선택:
0 철수
1 영희
2 민수
Name: 이름, dtype: object
여러 열 선택:
이름 나이
0 철수 25
1 영희 30
2 민수 28
인덱스 0번 행 선택:
이름 철수
나이 25
Name: 0, dtype: object
두 번째 행 선택:
이름 영희
나이 30
Name: 1, dtype: object데이터 정렬(sort_value(), sort_index())
특정 열 기준 정렬(sort_values())
df_sorted = df.sort_values(by="나이", ascending=False)
print("나이 기준 내림차순 정렬 결과:")
print(df_sorted)# [Out]
나이 기준 내림차순 정렬 결과:
이름 나이
1 영희 30
2 민수 28
0 철수 25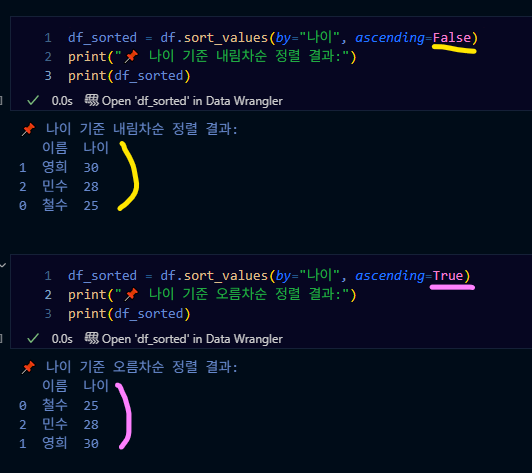
인덱스 기준 정렬(sort_index())
df_sorted_index = df.sort_index(ascending=False)
print("인덱스 기준 내림차순 정렬 결과:")
print(df_sorted_index)# [Out]
인덱스 기준 내림차순 정렬 결과:
이름 나이
2 민수 28
1 영희 30
0 철수 25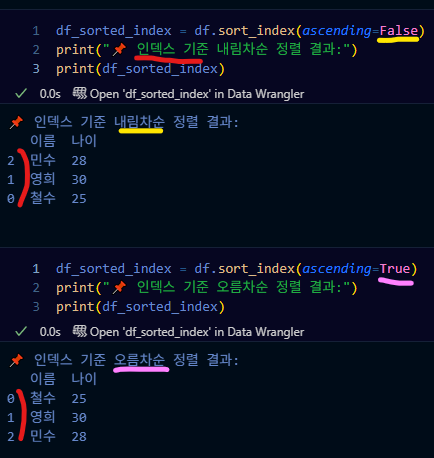
복수 컬럼 정렬(sort_values())
df_sorted_multi = df.sort_values(by=["나이", "이름"], ascending=[True, False])
print("나이 오름차순, 이름 내림차순 정렬 결과:")
print(df_sorted_multi)# [Out]
나이 오름차순, 이름 내림차순 정렬 결과:
이름 나이
0 철수 25
2 민수 28
1 영희 30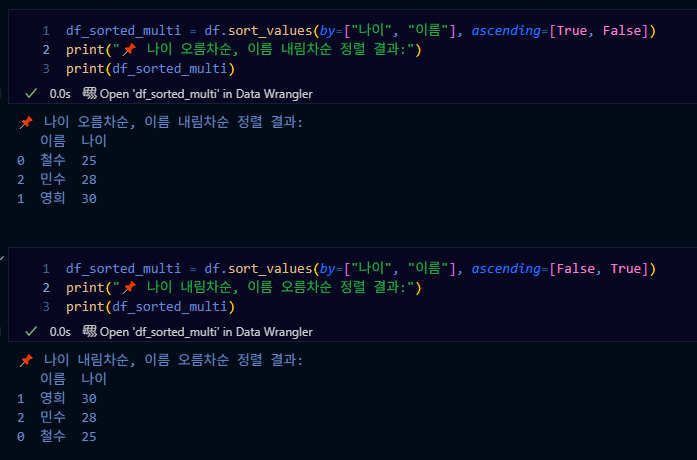

2 B R 0 2 B