지난 시간 복습
- PyTorch에서는 모델에 2차원으로 데이터를 넣어 주어야 함
- 새로운 개념
- batch_size
- 데이터 중 일부를 샘플링하여 학습
- 학습을 위하여 한 번에 신경망에 넣는 데이터 묶음
- 일정한 크기로 잘라 조금씩 학습(데이터 샘플링하여 학습)
- iteration: batch_size로 자른 묶음 단위 → batch_size씩 iteration 묶음 = 전체 데이터 수
- batch_size
- MyModel class 설계: 회귀
def __init__()super().__init__()input_dim,output_dim- 활성화 함수
def forward()- return 잊지 말고 주기
실습: 이진분류
- 유방암 데이터
신경망 학습 구현
model2 = MyModel(X_train.size(-1), y_train.size(-1))
optimizer2 = optim.Adam(model2.parameters())
train_history_2, valid_history_2 = [], []
# 1. 반복 학습 (epoch 루프)
for i in range(n_epochs):
# 2. 훈련 데이터 셔플 → randperm, index_select
indices = torch.randperm(X_train.size(0))
X_ = torch.index_select(X_train, dim=0, index=indices) # X_train[indices]는 텐서가 엉킬 수 있어 추천하지 않습니다.
y_ = torch.index_select(y_train, dim=0, index=indices) #데이터 꼬임 방지
# 3. 미니배치로 분할 → split
X_ = X_.split(batch_size, dim=0)
y_ = y_.split(batch_size, dim=0)
# 훈련을 위한 변수 초기화
train_loss, valid_loss = 0, 0
y_pred_list = [] # 예측 결과를 리스트에 넣어 두지 않으면 다 날아가기 때문
# 4. 훈련
for X_i, y_i in zip(X_, y_):
y_pred_i = model2(X_i)
loss = F.binary_cross_entropy(y_pred_i, y_i)
# 최적화함수 초기화 → zero_grad
optimizer2.zero_grad()
# 오차역전파 진행 → backward
loss.backward()
# 최적화함수 업데이트 → step
optimizer2.step()
# 5. 평균 훈련 손실 계산
train_loss += float(loss)
train_loss = train_loss / len(X_) # 1 epoch에 대한 loss가 담기게 된다.
# 6. 검증
with torch.no_grad():
# 미니배치로 분할
X_ = X_valid.split(batch_size, dim=0)
y_ = y_valid.split(batch_size, dim=0)
# 예측 과정
for X_i, y_i in zip(X_, y_):
y_pred_i = model2(X_i)
loss = F.binary_cross_entropy(y_pred_i, y_i)
valid_loss += float(loss)
y_pred_list.append(y_pred_i) # 나중에 밖에서 평가할 때 쓰려고 저장하는 거라 검증에서만 넣음
# 7. 손실 기록
valid_loss = valid_loss / len(X_)
# 그래프 그리기 위해 값을 리스트에 담아두기
train_history_2.append(train_loss)
valid_history_2.append(valid_loss)
# 8. 진행 상황 출력
if (i+1) % print_interval == 0:
print(f"epoch: {i+1}, train_loss: {train_loss:.4e}, valid_loss: {valid_loss:.4e}, lowest_loss: {lowest_loss:.4e}")
# 9. 베스트 모델 저장
if valid_loss <= lowest_loss:
lowest_loss = valid_loss
lowest_epoch = i
best_model = deepcopy(model2.state_dict())
# 10. 조기 종료 (Early Stopping)
else:
if (early_stop > 0) and (lowest_epoch + early_stop < i+1):
print(f"{early_stop} epochs 동안 모델이 개선되지 않음")
break
# 11. 베스트 모델 복원
model2.load_state_dict(best_model)
# 12. 최종 성능 출력
print(f"{lowest_epoch+1} epochs에서 검증 데이터 최저 손실 값: {valid_loss}")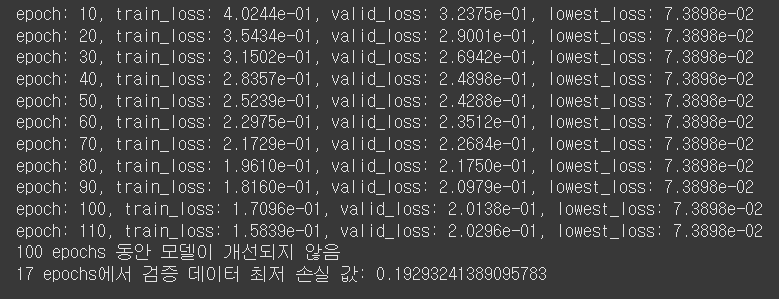
# 시각화
plt.figure(figsize=(7,3))
plt.grid()
plt.plot(range(1, len(train_history_2)+1), train_history_2, label="train_loss")
plt.plot(range(1, len(valid_history_2)+1), valid_history_2, label="valid_loss")
plt.legend()
plt.yscale("log")
plt.show()
# 과대적합 위험이 있음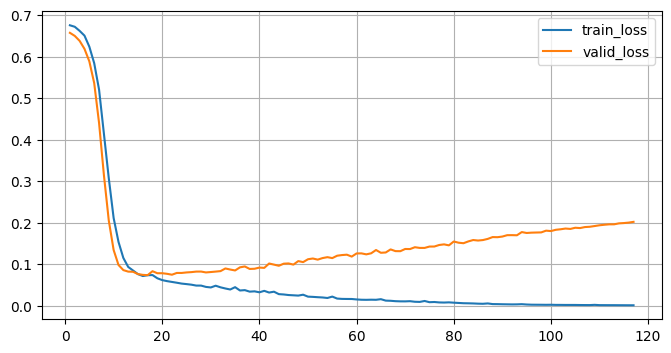
분류 평가 지표
- 정확도 (Accuracy)
- 전체 예측값 중에서 정확히 맞춘 비율
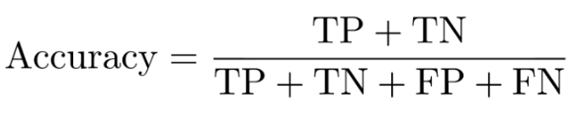
- 전체 예측값 중에서 정확히 맞춘 비율
- 재현율 (Recall)
- 실제 Positive 중에서 예측한 Positive의 비율
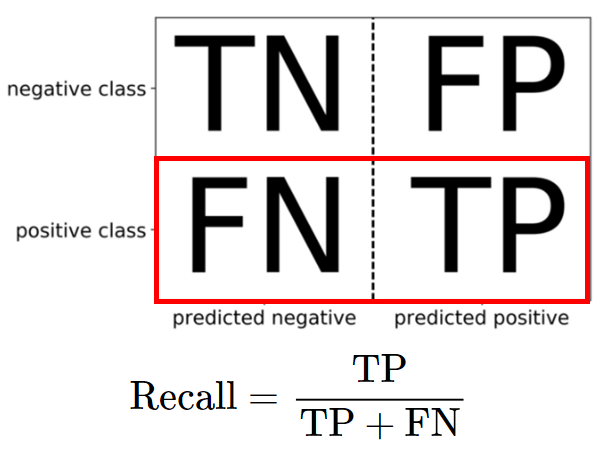
- 실제 Positive 중에서 예측한 Positive의 비율
- 정밀도 (Precision)
- 예측한 Positive 중에서 실제 Positive의 비율
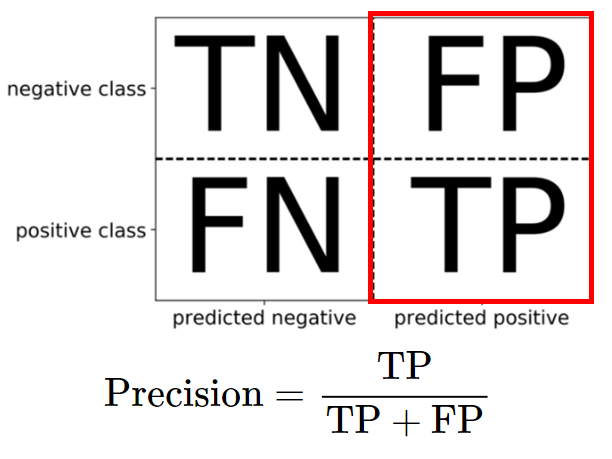
- 예측한 Positive 중에서 실제 Positive의 비율
- F1 스코어
- 정밀도와 재현율의 조화평균
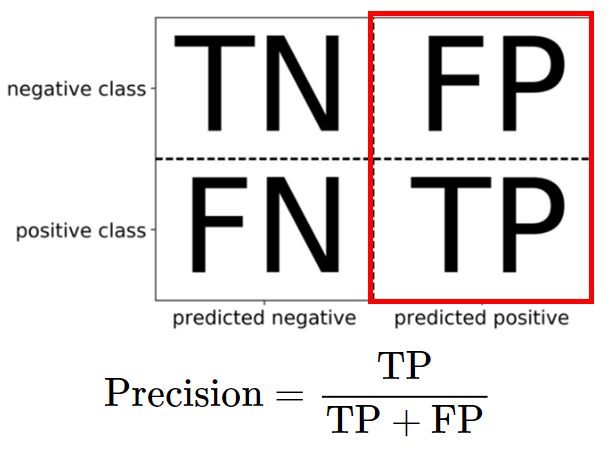
- 정밀도와 재현율의 조화평균
정확도 확인
test_loss = 0
y_pred_test = []
with torch.no_grad():
# 미니배치로 분할
X_ = X_test.split(batch_size, dim=0)
y_ = y_test.split(batch_size, dim=0)
# 예측 과정
for X_i, y_i in zip(X_, y_):
y_pred_i = model2(X_i)
loss = F.binary_cross_entropy(y_pred_i, y_i)
test_loss += float(loss)
y_pred_test.append(y_pred_i)
test_loss = test_loss / len(X_)
y_pred_test = torch.cat(y_pred_test, dim=0)
# 정확도: 맞춘 데이터 수 / 전체 데이터 수
# True → 1, False → 0
# 맞춘 데이터 수 세기
corr_cnt = (y_test == (y_pred_test >= 0.5)).sum()
total_cnt = y_test.size(0)
accuracy = corr_cnt / total_cnt
print(f"accuracy: {accuracy}")accuracy: 1.0→ 과대적합일 가능성이 높다~
실습: 다중분류
- 손글씨 데이터
학습 목표
- PyTorch를 활용하여 다중분류 실습을 진행할 수 있다.
- 다중분류에서 사용하는 loss(오차)에 대해서 알 수 있다.
# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from copy import deepcopy
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report데이터 불러오기
train = datasets.MNIST(
"./data"
, train=True
, download=True
, transform=transforms.Compose([
transforms.ToTensor()
])
)
test = datasets.MNIST(
"./data"
, train=False
, download=True
, transform=transforms.Compose([
transforms.ToTensor()
])
)
def plot(x) :
img = (np.array(x.detach().cpu(), dtype="float")).reshape(28, 28)
plt.figure(figsize=(3, 3))
plt.imshow(img, cmap="gray")
plt.show()
plot(train.data[0])
# 픽셀 값을 0~1 사이의 값으로 정규화하는 과정이 필요: 숫자 크기가 혼자 너무 크면 학습에 손해
X_data = train.data.float() / 255.
y_data = train.targets
X_test = test.data.float() / 255.
y_test = test.targets
print(X_data.shape, y_data.shape)
print(X_test.shape, y_test.shape)torch.Size([60000, 28, 28]) torch.Size([60000])
torch.Size([10000, 28, 28]) torch.Size([10000])# 28x28 2차원 데이터를 1차원으로 변경 → shape 변경: view()
X_data = X_data.view(X_data.size(0),-1) # '-1'이 의미하는 것: 알아서 해줘(남은 모두)
X_test = X_test.view(X_test.size(0),-1)
print(X_data.shape, y_data.shape)
print(X_test.shape, y_test.shape)torch.Size([60000, 784]) torch.Size([60000])
torch.Size([10000, 784]) torch.Size([10000])# 데이터 분리
X_train, X_valid, y_train, y_valid = train_test_split(X_data, y_data, test_size=0.2, random_state=22)
print(X_train.shape, y_train.shape)
print(X_valid.shape, y_valid.shape)
print(X_test.shape, y_test.shape)torch.Size([48000, 784]) torch.Size([48000])
torch.Size([12000, 784]) torch.Size([12000])
torch.Size([10000, 784]) torch.Size([10000])입력 데이터 크기, 출력 크기 설정
# 입력 크기 설정
input_size = X_train.size(-1)
# 출력 크기
# 클래스의 크기만큼 출력 크기를 설정해 주어야 함: 다중 분류니까
output_size = int(max(y_train)+1)
print(input_size, output_size)784 10- 또는 numpy ndarray로 바꾸고 unique 한 다음 개수를 세도 됨
- tensor는 unique 적용 안 됨
정답 데이터 타입 변환
- 다중분류에서는 정답 데이터의 형태를 TensorLong()으로 요청하기 때문
- 다중분류는 output이 무조건 long이어야 한다는 규칙이 있음
y_train = y_train.long()
y_valid = y_valid.long()
y_test = y_test.long()모델 학습 시 사용하는 오차 종류
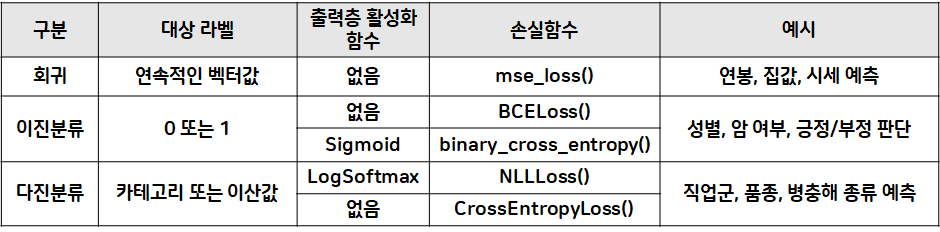
nn.BCELoss(): binary cross entropy loss- 클래스 형태(객체)로 사용하는 손실 함수
F.binary_cross_entropy()- 함수 형태로 사용하는 손실 함수
- 다진분류 LogSoftmax, NLLLoss()는 PyTorch에서 권장하지 않음
- 출력층 활성화 함수를 설정하지 않고
nn.CrossEntropyLoss()를 쓰는 것을 적극 권장
- 출력층 활성화 함수를 설정하지 않고
모델링
nn.Sequential()활용
# 다중분류 → 출력층의 활성화함수를 작성하지 않고 학습 시 손실함수 nn.CrossEntropyLoss()를 사용하는 것을 권장함
model = nn.Sequential(
nn.Linear(input_size, 500)
, nn.ReLU()
, nn.Linear(500, 400)
, nn.ReLU()
, nn.Linear(400, 300)
, nn.ReLU()
, nn.Linear(300, 200)
, nn.ReLU()
, nn.Linear(200, 100)
, nn.ReLU()
, nn.Linear(100, 50)
, nn.ReLU()
, nn.Linear(50, output_size)
# , nn.LogSoftmax(dim=1)
)- class 활용
class MyModel(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.linear1 = nn.Linear(input_dim, 500)
self.linear2 = nn.Linear(500, 400)
self.linear3 = nn.Linear(400, 300)
self.linear4 = nn.Linear(300, 200)
self.linear5 = nn.Linear(200, 100)
self.linear6 = nn.Linear(100, 50)
self.linear7 = nn.Linear(50, output_dim)
self.act_relu = nn.ReLU()
def forward(self, x):
h = self.act_relu(self.linear1(x))
h = self.act_relu(self.linear2(h))
h = self.act_relu(self.linear3(h))
h = self.act_relu(self.linear4(h))
h = self.act_relu(self.linear5(h))
h = self.act_relu(self.linear6(h))
y = self.linear7(h) # 🔥 LogSoftmax 제거
return y
model1 = MyModel(input_size, output_size)GPU 사용 설정
- 런타임 유형 변경해야 함
- T4 GPU
device = torch.device("cpu")
print("GPU 사용 가능 여부:", tqdmorch.cuda.is_available())
if torch.cuda.is_available():
device = torch.device("cuda:0")
print("사용 중인 디바이스:", device)
# GPU 연결 됐으면 GPU로 모델 변경
model = model.to(device)
# gpu로 데이터 복사
X_train = X_train.to(device)
X_valid = X_valid.to(device)
X_test = X_test.to(device)
y_train = y_train.to(device)
y_valid = y_valid.to(device)
y_test = y_test.to(device)
# device 확인
deviceGPU 사용 가능 여부: True
사용 중인 디바이스: cuda:0
device(type='cuda', index=0)- index=0: 사용 가능한 gpu 중 첫 번째를 사용하겠다는 의미
- 우리가
cuda:0으로 지정했기 때문
- 우리가
최적화 함수, 손실 함수 설정
# 최적화 함수
optimizer = optim.Adam(model.parameters())
# 손실 함수 → 출력층 활성화 함수 X
loss_func = nn.CrossEntropyLoss()학습 파라미터 설정
# 학습 파라미터 설정
n_epochs = 1000
batch_size = 256
print_interval = 10
lowest_loss = np.inf
best_model = None
early_stop = 50
lowest_epoch = np.inf학습 구현
# 학습 코드 구현: 학습 반복문
train_history, valid_history = [], []
# 1. 반복 학습 (epoch 루프)
for i in range(n_epochs):
# 2. 훈련 데이터 셔플
indices = torch.randperm(X_train.size(0)).to(device) # 인덱스 gpu 복사
X_ = torch.index_select(X_train, dim=0, index=indices)
y_ = torch.index_select(y_train, dim=0, index=indices)
# 3. 미니배치로 분할
X_ = X_.split(batch_size, dim=0)
y_ = y_.split(batch_size, dim=0)
# 변수 초기화
train_loss, valid_loss = 0, 0
y_pred = []
# 4. 훈련
for X_i, y_i in zip(X_, y_):
y_i_pred = model(X_i)
loss = loss_func(y_i_pred, y_i)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += float(loss)
# 5. 평균 훈련 손실 계산
train_loss = train_loss / len(X_)
# 6. 검증
with torch.no_grad():
X_ = X_valid.split(batch_size, dim=0)
y_ = y_valid.split(batch_size, dim=0)
for X_i, y_i in zip(X_, y_):
y_i_pred = model(X_i)
loss = loss_func(y_i_pred, y_i)
valid_loss += float(loss)
y_pred.append(y_i_pred)
valid_loss = valid_loss / len(X_)
# 7. 손실 기록
train_history.append(train_loss)
valid_history.append(valid_loss)
# 8. 진행 상황 출력
if (i+1)%print_interval == 0:
print(f"epoch: {i+1}, valid_loss: {valid_loss:.4e}, train_loss: {train_loss:.4e}, lowest_loss: {lowest_loss:.4e}")
# 9. 베스트 모델 저장
if valid_loss <= lowest_loss:
lowest_loss = valid_loss
lowest_epoch = i
best_model = deepcopy(model.state_dict())
# 10. 조기 종료 (Early Stopping)
if (early_stop > 0) and (lowest_epoch + early_stop < i+1):
print(f"{early_stop} epochs 동안 모델이 개선되지 않음")
break
# 11. 베스트 모델 복원
model.load_state_dict(best_model)
# 12. 최종 성능 출력
print(f"{lowest_epoch + 1} epochs에서 가장 낮은 검증손실값: {lowest_loss}")epoch: 10, valid_loss: 1.2144e-01, train_loss: 2.3562e-02, lowest_loss: 9.6213e-02
epoch: 20, valid_loss: 1.3192e-01, train_loss: 1.1287e-02, lowest_loss: 9.6213e-02
epoch: 30, valid_loss: 1.2563e-01, train_loss: 7.9283e-03, lowest_loss: 9.6213e-02
epoch: 40, valid_loss: 1.1135e-01, train_loss: 5.5960e-03, lowest_loss: 9.6213e-02
epoch: 50, valid_loss: 1.4229e-01, train_loss: 5.8550e-03, lowest_loss: 9.6213e-02
50 epochs 동안 모델이 개선되지 않음
9 epochs에서 가장 낮은 검증손실값: 0.09621332807743803- 시각화
# 손실 곡선(train_loss, valid_loss)
plt.figure(figsize = (7,3))
plt.grid(True)
plt.plot(range(1,len(train_history)+1), train_history, label = "train loss")
plt.plot(range(1,len(valid_history)+1), valid_history, label = "valid loss")
plt.legend()
plt.show()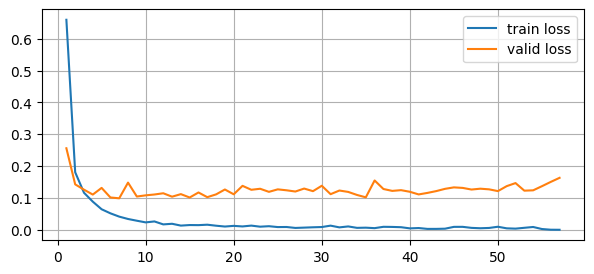
모델 평가
# 테스트 데이터로 모델 평가
test_loss = 0
y_pred_test = []
# 검증
with torch.no_grad():
X_ = X_test.split(batch_size, dim = 0)
y_ = y_test.split(batch_size, dim = 0)
for X_i, y_i in zip(X_, y_):
y_pred_i = model(X_i)
loss = loss_func(y_pred_i, y_i)
test_loss += loss
y_pred_test.append(y_pred_i)
# 손실 기록
test_loss = test_loss / len(X_)
# 기록 합치기
y_pred_test = torch.cat(y_pred_test, dim = 0)
# 다중 분류 정확도 계산
# torch.argmax(y_pred_test, dim=1)
# 1개의 입력 데이터에 대한 정답 카테고리별 확률 → 비교 → 최댓값 → label
corr_cnt = (y_test == torch.argmax(y_pred_test, dim=1)).sum()
total_cnt = float(y_test.size(0))
corr_cnt/total_cnt
# 정확도 0.9760tensor(0.9760, device='cuda:0')다중분류의 confusion matrix
- 직접 그려보기
# gpu로 할당된 데이터를 cpu로 가져와서 출력해줘야 한다
pd.DataFrame(
confusion_matrix(
y_test.cpu() # gpu → cpu: numpy ndarray 값을 넣어야 하기 때문
, torch.argmax(y_pred_test, dim=1).cpu() # gpu → cpu
)
, index = [f"true_{i}" for i in range(10)]
, columns = [f"pred_{i}" for i in range(10)]
)
# 예측과 실제값의 데이터 세트 개수를 표로 표현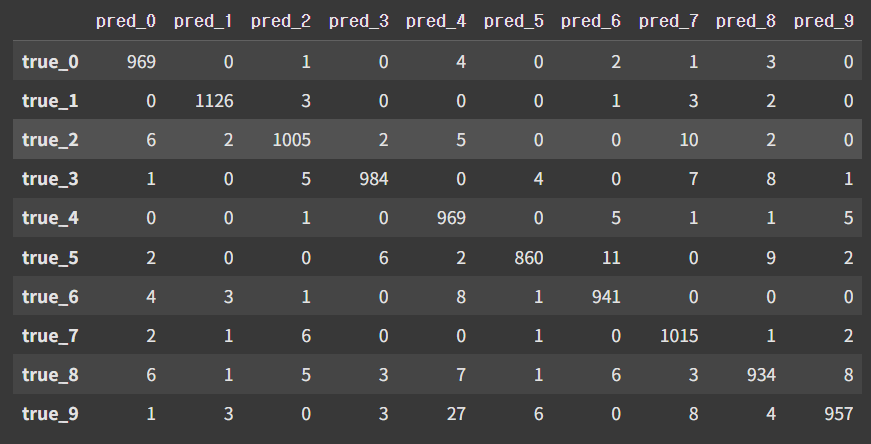
- sklearn 이용
from sklearn.metrics import classification_report
# GPU → CPU
y_true = y_test.cpu()
y_pred = torch.argmax(y_pred_test.cpu(), dim=1)
report = classification_report(y_true, y_pred)
print(report) precision recall f1-score support
0 0.98 0.99 0.98 980
1 0.99 0.99 0.99 1135
2 0.98 0.97 0.98 1032
3 0.99 0.97 0.98 1010
4 0.95 0.99 0.97 982
5 0.99 0.96 0.97 892
6 0.97 0.98 0.98 958
7 0.97 0.99 0.98 1028
8 0.97 0.96 0.96 974
9 0.98 0.95 0.96 1009
accuracy 0.98 10000
macro avg 0.98 0.98 0.98 10000
weighted avg 0.98 0.98 0.98 10000CNN(Convolutional Neural Networks)
- 지금까지는 MLP(Multi Layer Perceptron) 기반
- "선형 모델"에 데이터를 넣어 나온 값을 이용했었음
- 숫자 규칙 패턴을 찾아 학습 (이미지를 학습하는 게 아님)
- 위치에 민감하게 반응함
- CNN == 합성곱 신경망
- 인간의 시신경을 모방
- 이미지의 '특성'을 추출
MLP 이미지 분석
- MLP 신경망을 이미지 처리에 사용 시 이미지의 위치에 민감하게 동작
- 모든 픽셀을 연산하기 때문에 위치 종속적인 결과를 얻게 됨
- MLP는 아래 3개의 7이 서로 패턴이 다르다고 판단함

- MLP로 이러한 숫자 인식을 하려면 숫자의 크기와 위치를 비슷하게 맞춰야 함
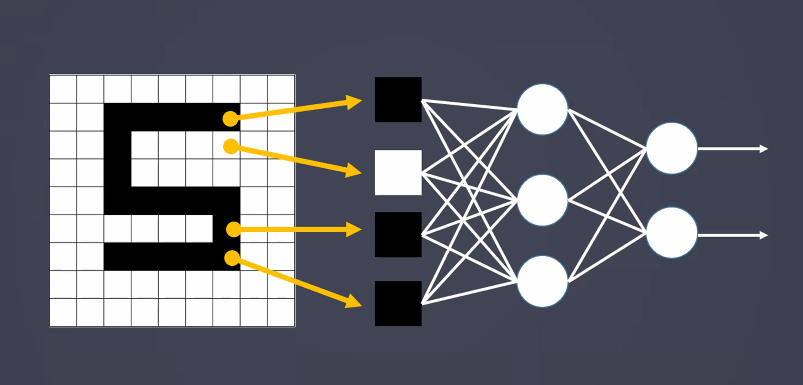
- 조금만 움직여도 다르다고 인식
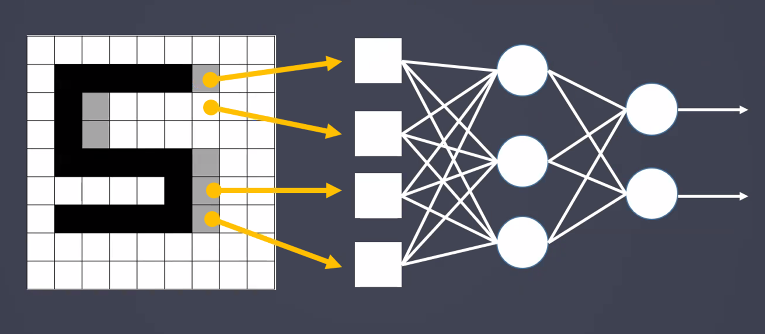
- MLP로 이러한 숫자 인식을 하려면 숫자의 크기와 위치를 비슷하게 맞춰야 함
- MLP의 문제를 해결하려면?
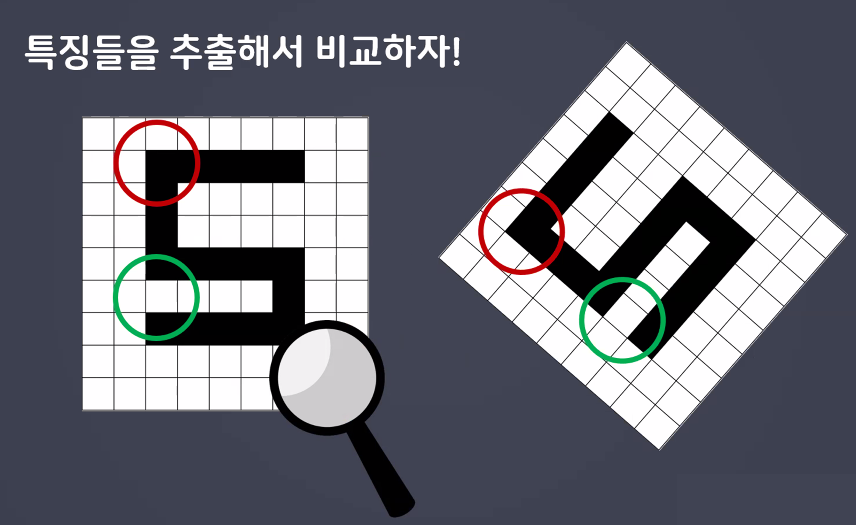
- 사람은 얼굴에서 눈,코,입만 보면 누군지 대충 알 수 있음 → 컴퓨터에도 적용시켜보자~
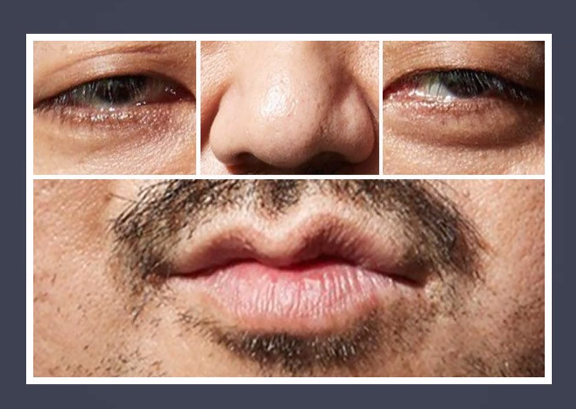
- 사람은 얼굴에서 눈,코,입만 보면 누군지 대충 알 수 있음 → 컴퓨터에도 적용시켜보자~
CNN(Convolutional Neural Network)
- 1950년대 수행했던 고양이 뇌파 실험에 영감을 받은 Yann Lecun 교수에 의해 1998년 이미지 인식을 획기적으로 개선할 수 있는 CNN이 제안됨
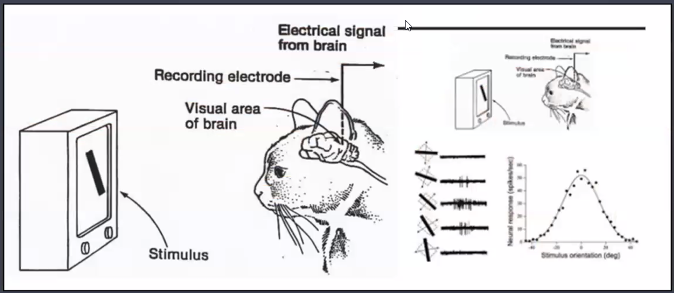
- LeCun initialization의 그 Lecun 맞음
- 고양이의 눈으로 보는 사물의 형태에 따라 '뇌의 특정 영역(뉴런)만 활성화'된다는 실험 결과를 기반으로 제안
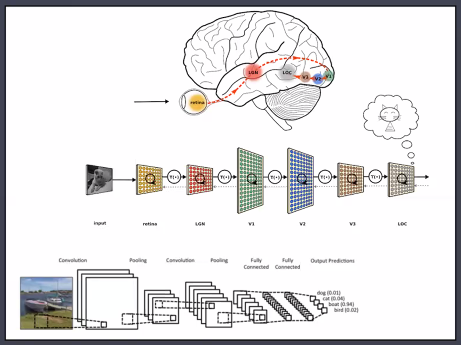
- 2010~2013년도 CNN의 획기적인 발전과 다수의 논문 출시
CNN 구조
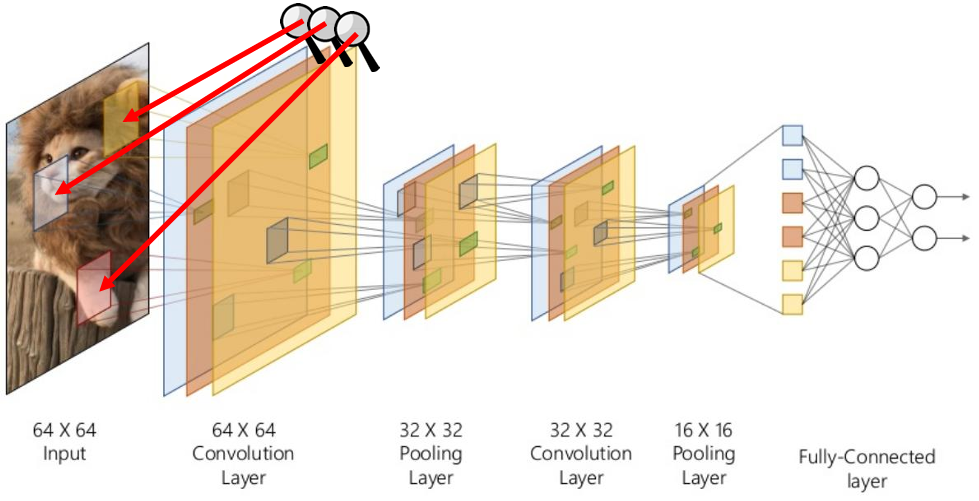
- CNN은 크게 두 부분으로 나뉨:
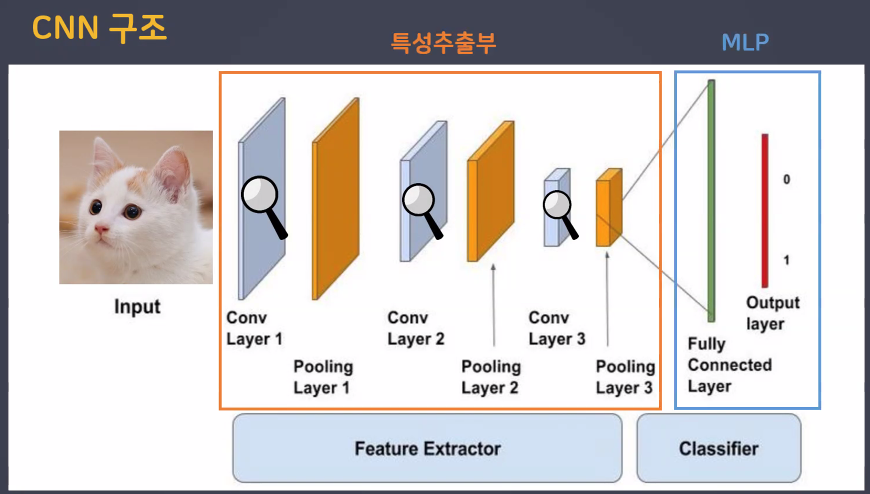
- 특성추출부와 분류부(MLP)
- 특성추출부는 또 다시 두 부분으로 나뉨:
- Conv: 특징을 추출하는 역할
- Pooling: 특징이 아닌 부분을 삭제하는 역할(downsampling)
- 특성추출부의 마지막에는 특징 집약적인 숫자만 남는다
MLP, CNN 구조 비교
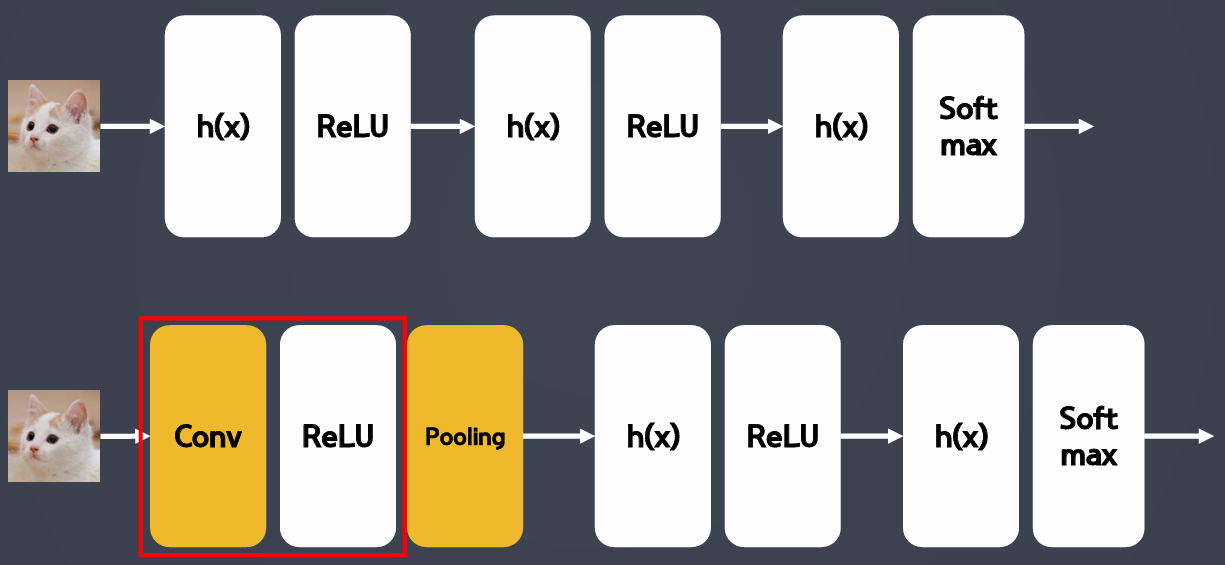
- 1단계
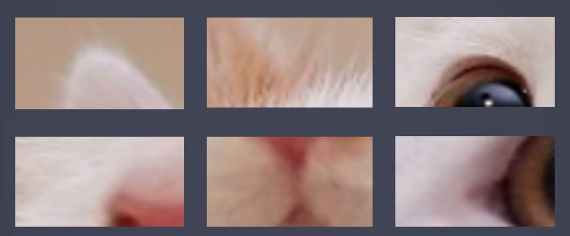
- 특성추출부의 초반 층들이 데이터의 심플한 특징들을 잡아냄 → 세모, 동그라미
- 2단계

- 특성추출부의 층들이 깊어지면서 조금 더 디테일한 특징들을 잡아냄 → 귀, 코, 입, 눈
- 3단계

- 특징들이 모여 최종 판단 → 고양이다!
CNN은 어떻게 특징을 추출할까?
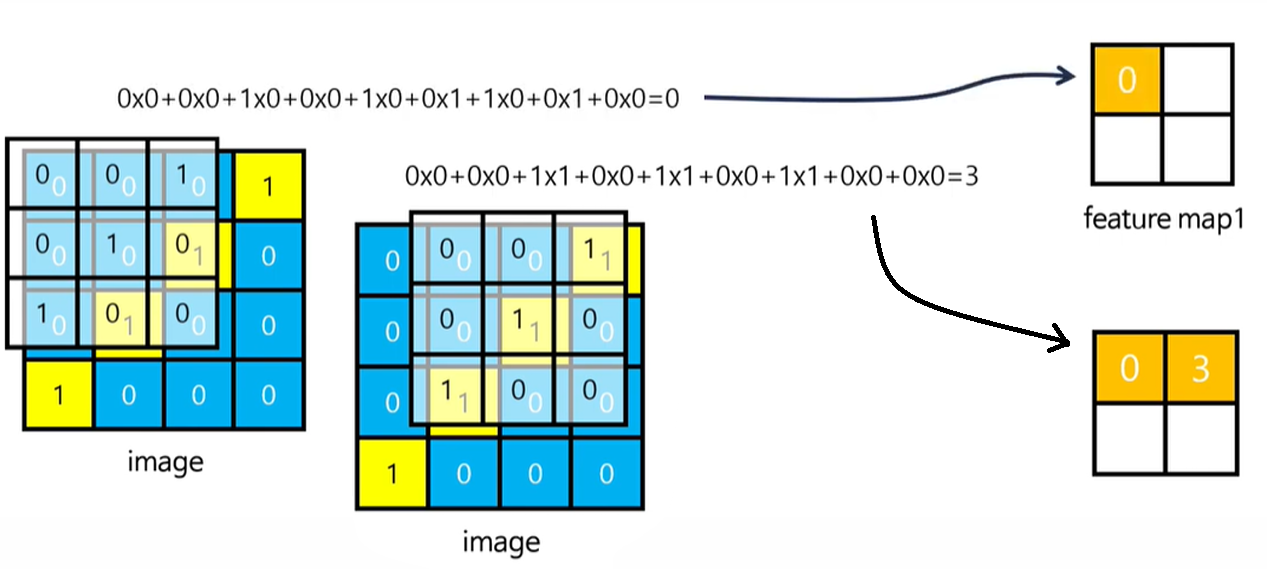
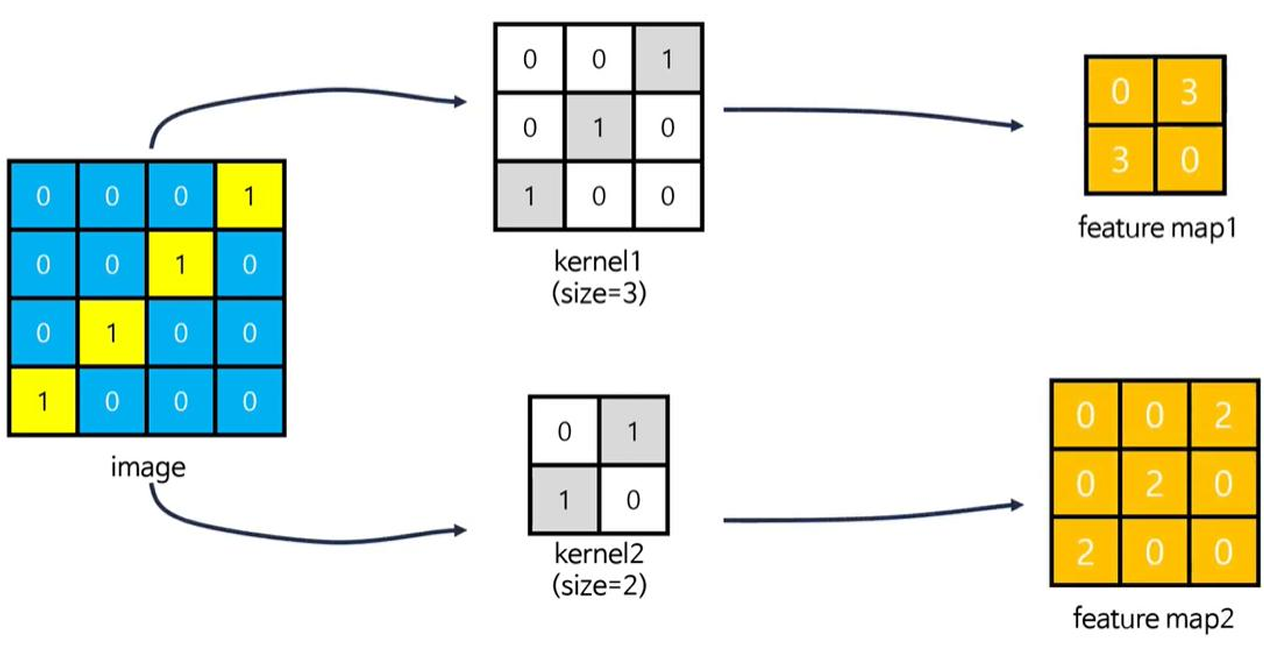
- CNN(합성곱)은 입력된 이미지에서 특징을 추출하기 위해 '필터'의 개념을 도입
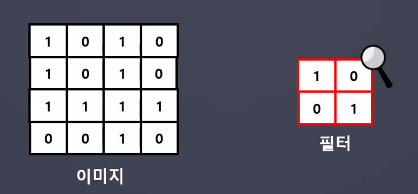
- 필터 크기, 개수 → 하이퍼파라미터(사용자가 조절 가능)
- 이미지 전체 영역(전체 픽셀)에 대해 서로 동일한 연관성으로(동일한 중요도로) 처리하는 대신 특정 범위에 한정해 처리한다면 훨씬 효과적일 것이라는 아이디어에서 착안
이미지 데이터에서 색상의 개념
- 합성곱 계층에서 이미지의 색상 정보를 "채널"이라고 부름
- 흑백으로 코딩된 경우(e.g.MNIST 손글씨 이미지) 흑백의 그레이스케일(0: 검은색, 255: 흰색)만 나타내면 되므로 채널은 1이 됨
- 입력 신호가 RGB 신호로 코딩된 경우, 채널은 세 가지 색을 각각 나타내는 3이 됨

- 데이터의 색상 정보를 유지할 수 있음
패턴을 어떻게 찾는 걸까?
- 아래 이미지에서 모자를 찾는다고 가정:

- 컬러 이미지라 채널은 3
- 다양한 패턴과 비교하며 점수가 가장 높은 패턴 찾기
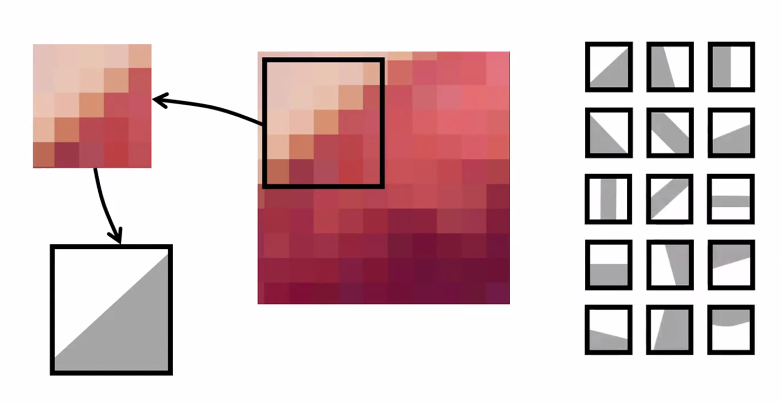
- 점수가 가장 높은 패턴?
- 패턴이 일치하면 점수가 높게 나옴

- feature map 값이 클 수록 패턴과 이미지 일치
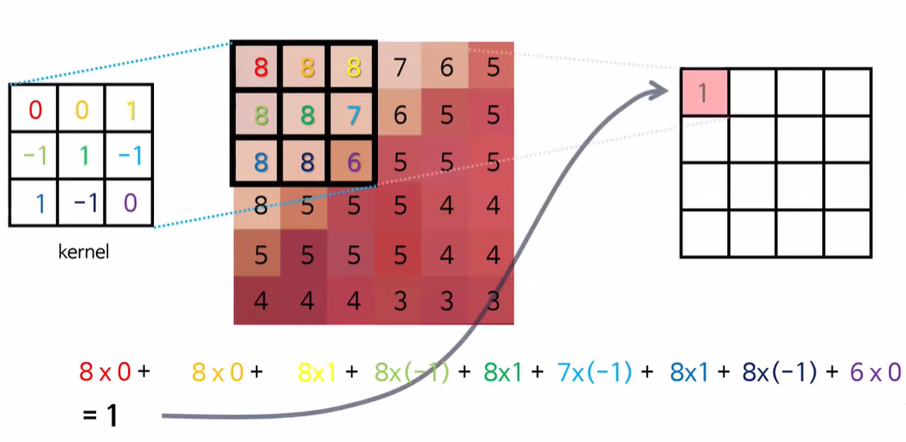
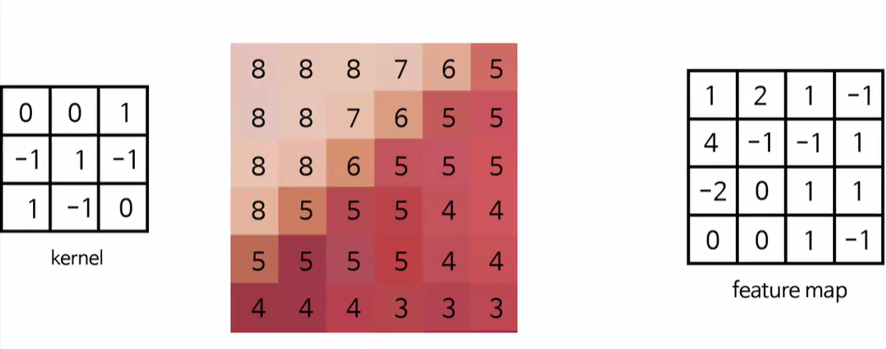
- 전체 픽셀에 대해 feature map을 구함
- 패턴이 일치하면 점수가 높게 나옴
- 컬러 이미지라 채널은 3
- 손글씨 데이터를 생긱해보자:
- 1과 일치하는 패턴
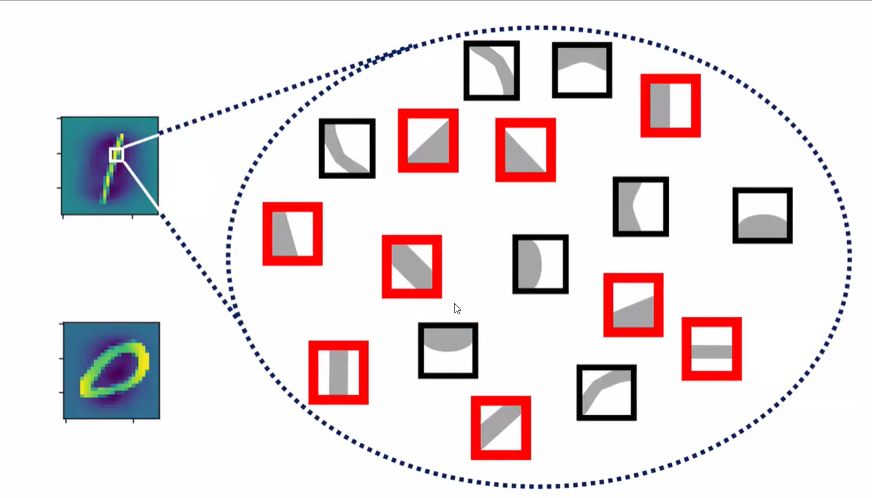
- 0과 일치하는 패턴
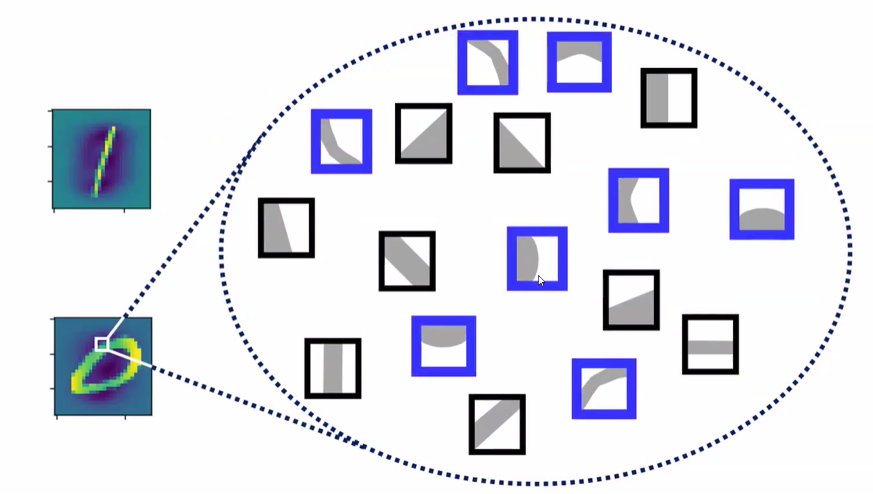
- 이러한 특성의 차이를 통해 1과 0을 구분할 수 있음
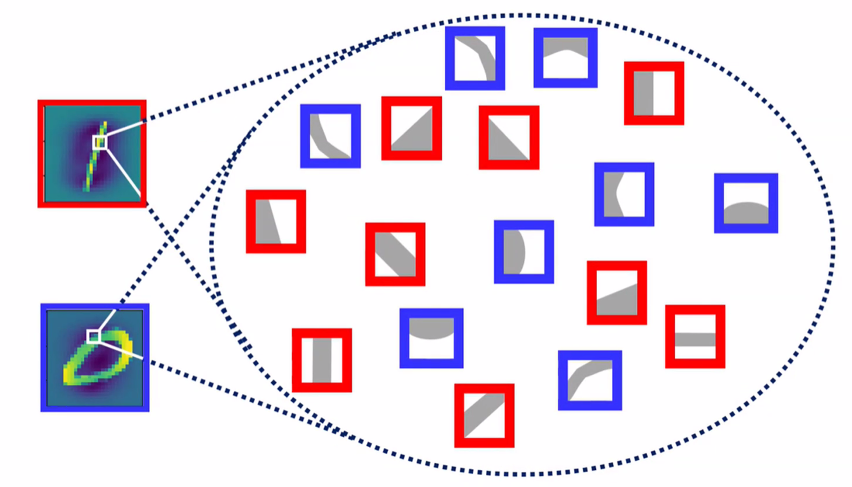
- 1과 일치하는 패턴
feature map 값과 패턴
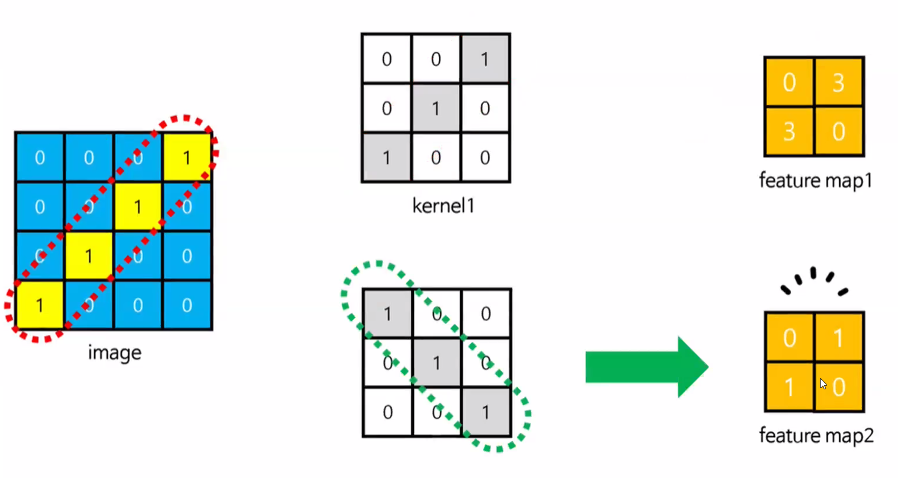
- 층이 깊어질수록 복잡한 형태의 패턴을 처리할 수 있음
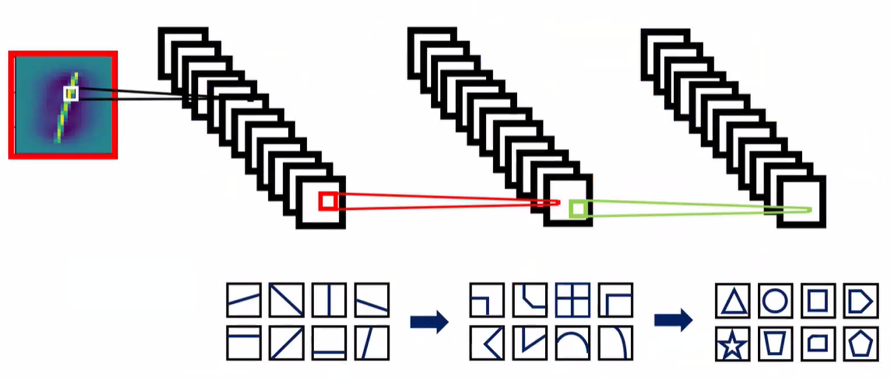
- 커널 크기에 따른 feature map 차이
패딩(padding)
- 출력 데이터의 공간적 크기를 조절하기 위해 사용하는 파라미터
- 필터의 크기가 커질수록 특징 맵의 크기가 작아지고 크기가 작아질수록 모서리에 있는 이미지 데이터의 정보가 사라지는 것을 조절해주기 위한 값
- 사용하면 입, 출력 형태 동일하게 맞춰줄 수 있음 → zero-padding, same-padding
- 이미지 크기 줄어드는 것을 방지
- 사용하면 가장자리 연산 횟수 증가
- 사용하면 입, 출력 형태 동일하게 맞춰줄 수 있음 → zero-padding, same-padding
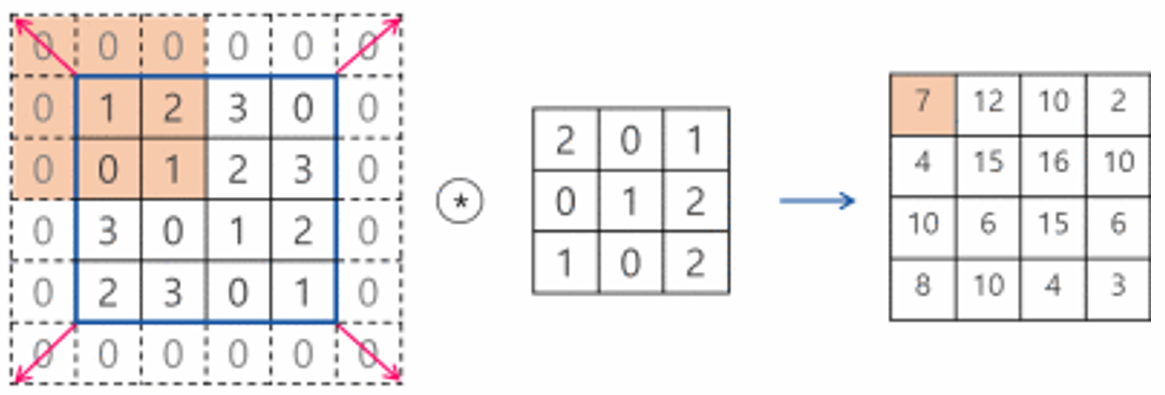
- 필터의 크기로 인해 가장자리 부분의 데이터가 부족해서 입력과 출력의 이미지 크기가 달라지게 되는데 이를 보완하기 위해 입력 데이터의 가장자리 부분에 0을 미리 채워 넣는 것을 zero-padding이라 함
- 패딩을 사용하면 입력과 출력의 크기를 같게 맞춰줄 수 있음
- 층이 깊어지면서 이미지의 크기가 줄어드는 것을 방지
-Conv2D 계층에서는 padding 명령을 사용해 패딩 지정 가능- same을 지정하면 출력과 입력이 같아지게 적절한 수의 패딩을 자동으로 입력
- valid로 설정하면 패딩 미사용
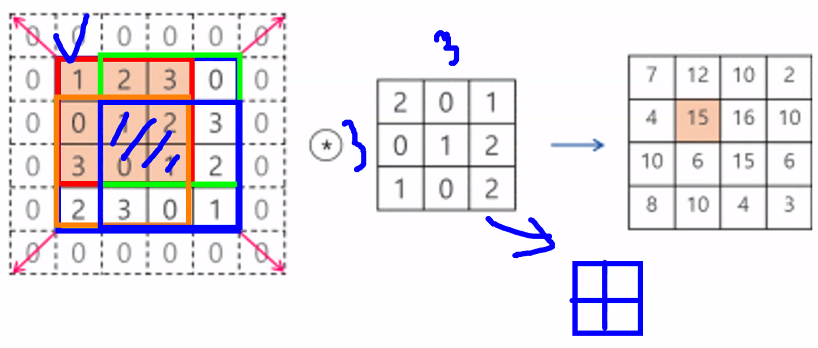
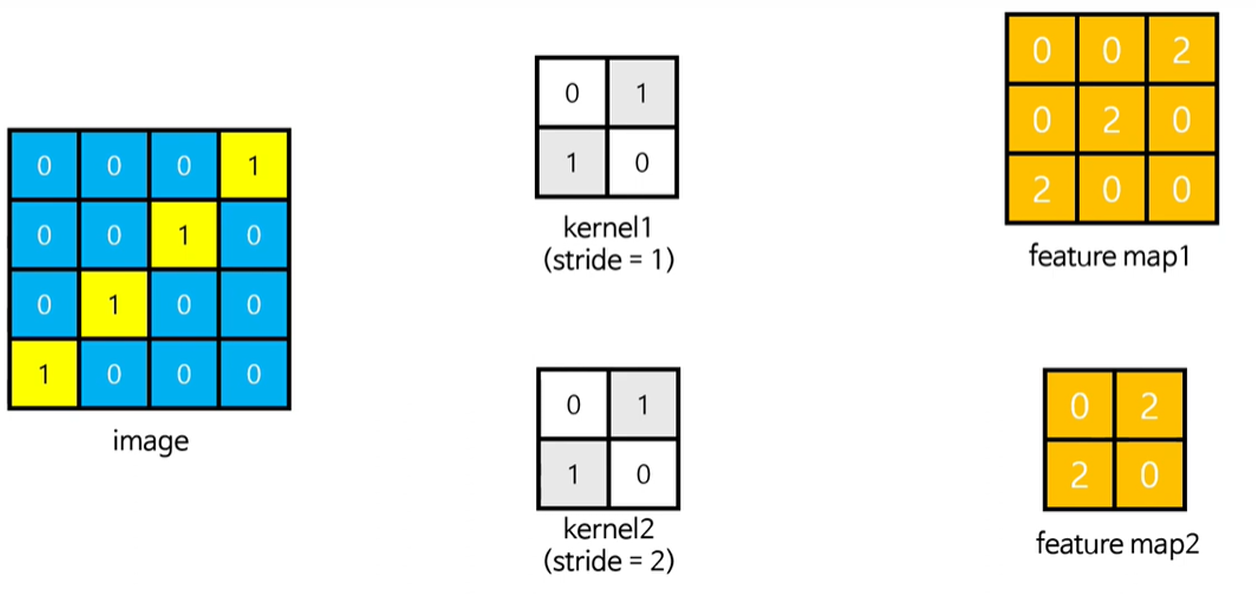
스트라이드(Stride)
- 합성곱 연산을 수행할 때 필터를 한 픽셀씩 옆으로 이동하면서 출력을 얻는 게 아니라, 2 픽셀 또는 2 픽셀씩 건너 뛰면서 합성곱 연산을 수행하는 방법
- 스트라이드 2 또는 스트라이드 3이라고 함
- 이렇게 하면 출력 데이터(특성 맵)의 크기를 1/4 또는 1/9로 줄일 수 있음
- 예시:
실습: 손글씨 데이터
학습 목표
- CNN 알고리즘에 대해 이해하고 PyTorch를 활용하여 CNN 신경망을 구성할 수 있다.
- 주로 이미지 데이터를 분석하는 CNN 알고리즘을 활용하여 이미지를 분석할 수 있다.
- cf. RNN(순환신경망): 텍스트, 주식, 말, 흐름 → 시계열 데이터
- 손글씨 데이터를 CNN 신경망을 통하여 분류할 수 있다.
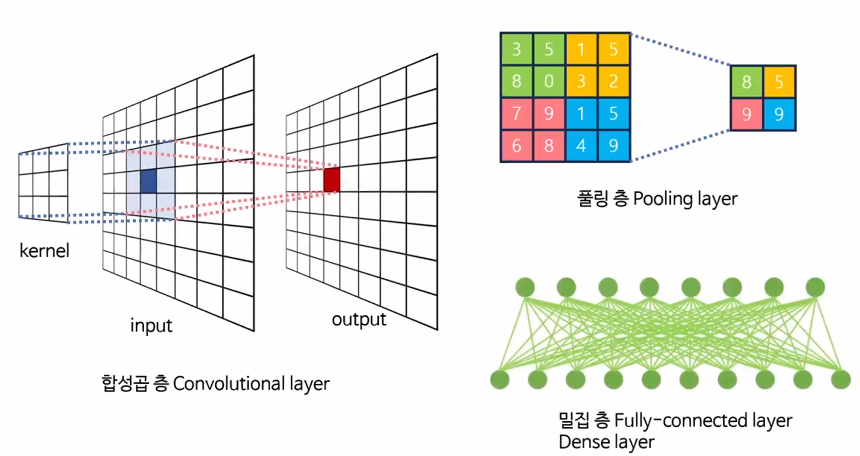
CNN(Convolutional Neural Network, 합성곱 신경망)
- 합성곱을 이용하여 이미지의 특성을 추출하는 싱경망
- CNN은 Convolution 층과 Pooling 층으로 구성
- Convolution: 입력 데이터에서 특성을 추출
- Pooling: 특성이 아닌 부분을 삭제 (크기 축도, downsampling)
- Maxpooling 방법을 주로 사용
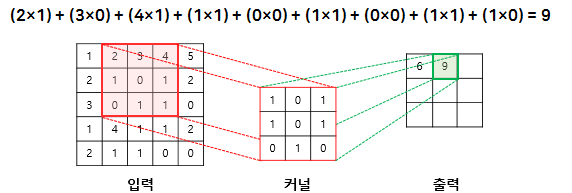
Convolution(합성곱) 원리
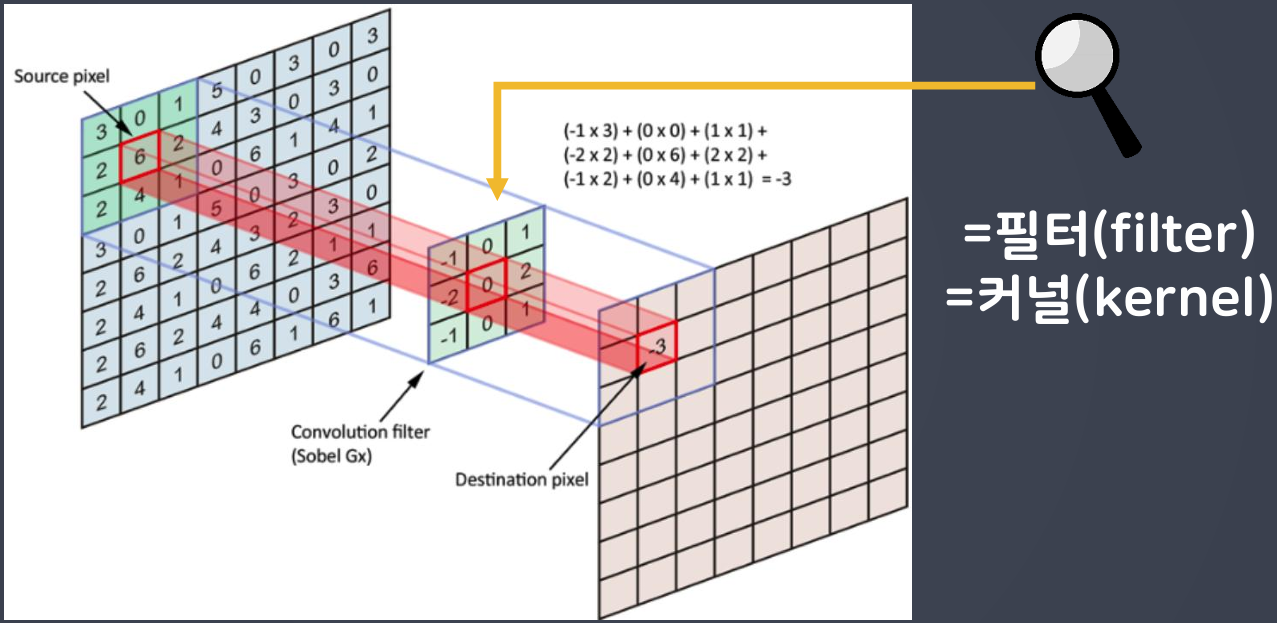
- 커널(kernel) 또는 필터(filter)라는 이름을 가진 행렬로 분석하고자 하는 원본 이미지를 처음부터 끝까지 겹치며 연산(합성곱)
- 이미지에서 커널의 크기는
3*3
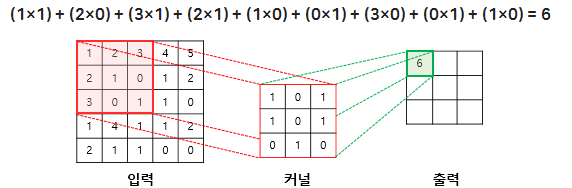
- 1 픽셀 씩 이동하면서 계산
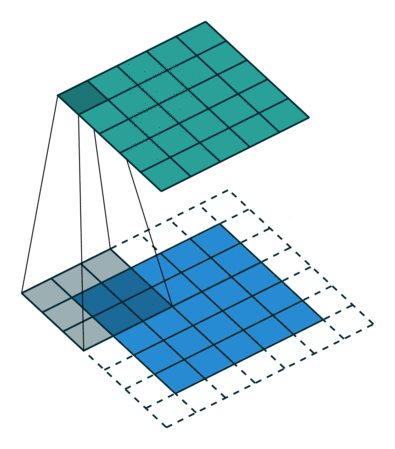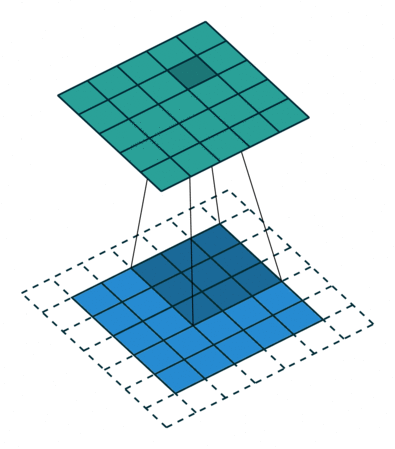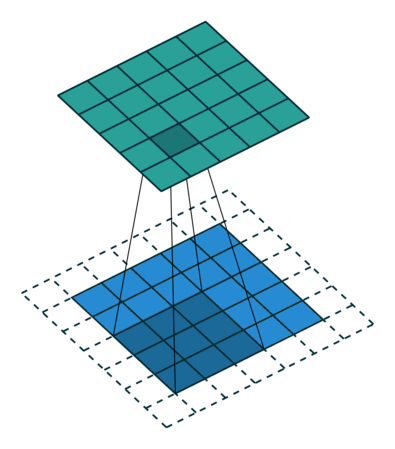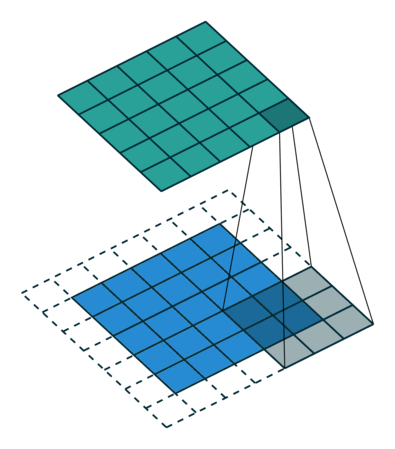
https://blog.joonas.io/196
https://dsbook.tistory.com/72
라이브러리 가져오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
from copy import deepcopy
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import dataloader
from sklearn.model_selection import train_test_splitGPU 사용 설정
device = torch.device("cpu") # 기본값 cpu로 설정
print("GPU 사용 여부:", torch.cuda.is_available())
if torch.cuda.is_available():
device = torch.device("cuda:0")
print("현재 사용 중인 디바이스:", device)GPU 사용 가능 여부: True
사용 중인 디바이스: cuda:0데이터 불러오기
# 데이터 불러오기
train = datasets.MNIST(
"./data"
, train=True
, download=True
, transform=transforms.Compose([
transforms.ToTensor()
])
)
test = datasets.MNIST(
"./data"
, train=False
, transform=transforms.Compose([
transforms.ToTensor()
])
)데이터 로더
- 배치 사이즈에 따라 데이터를 분리 →
randperm,index_select,split으로 수작업 해주지 않아도 됨
# drop_last: 배치 사이즈로 데이터를 분리했을 때 마지막 배치가 맞지 않으면(개수가 부족하면) 제외
train_loader = torch.utils.data.DataLoader(
dataset=train
, batch_size=100
, shuffle=True
, drop_last=True
)
test_loader = torch.utils.data.DataLoader(
dataset=test
, batch_size=100
, shuffle=True
, drop_last=True
)
print(f"훈련 데이터의 총 배치 수: {len(train_loader)}")
print(f"테스트 데이터의 총 배치 수: {len(test_loader)}")훈련 데이터의 총 배치 수: 600
테스트 데이터의 총 배치 수: 100하루 돌아보기
👍 잘한 점
- 헷갈리는 내용 바로 질문한 점
- epoch는 i+1인데 lowest_epoch = i인 이유
- 사용자가 보기 편하려고 +1을 해 주는 것
- 컴퓨터 입장에서는 i이 맞음
- y_pred 리스트는 왜 학습에서는 append 안 하는지 → 학습과
- y_pred 리스트를 만든 이유는 뒤에 평가 단계에서 x_test로 나온 y_pred_test(예측 결과)와 비교하기 위한 것
- 따라서 검증 예측 데이터만 있으면 됨: 모의고사(검증) - 실제 시험(예측)만 서로 비교하면 되지 공부 과정과 비교할 필요는 없기 때문
- epoch는 i+1인데 lowest_epoch = i인 이유
- 미니 프로젝트 모든 컬럼 분석 & Feature Engineering & 머신러닝 교재에 소개된 모델 중 4가지 사용
👎 아쉬웠던 점
- 이번주 목요일 자소서 피드백인데 미니 프로젝트 준비하느라 만족스럽게 준비를 못 했음
- 미니 프로젝트 발표를 위해 페르소나를 정하고 발표 흐름, PPT 만드는 거 하려고 했는데 약간 일정이 꼬여서 내일로 미룸
🔬 개선점
- 미니프로젝트 과제 더 파고들지 말고 하이퍼파라미터 튜닝해서 모델 비교하고 마무리하기
- 내일 아침까지 자소서 내용 더 채우기

2 B R 0 2 B