지난 시간 복습
- CNN(Convolutional Neural Network)
- 합성곱 방식을 사용한 이미지 분석
- MLP 이미지 분석
- 위치에 민감
- 픽셀의 위치가 조금이라도 바뀌면 다르다고 인식
- 숫자의 크기와 위치가 비슷해야지만 인식 가능
- 이는 우리가 원하는 이미지 분석과는 조금 결이 다름 → 개선이 필요: 사람은 어떻게?
- 위치에 민감
- 사람은 이미지를 특징으로 인식한다
- 그림이 돌아가도 뒤집혀도 정확하게 인식 → "특징"을 보기 때문
- 따라서 '특징들을 추출해서' 비교하는 방법을 제안 → CNN
- Convolutional Neural Network (합성곱 신경망)
- 바라보는 사물의 형태에 따라 고양이 뇌의 특정 뉴런(특정 영역)만 활성화되는 걸 보고 개념 고안
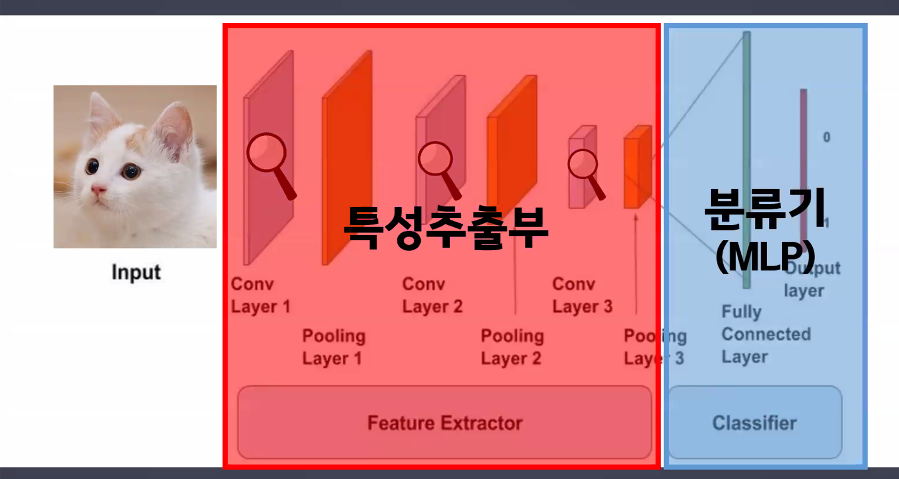
- 구조
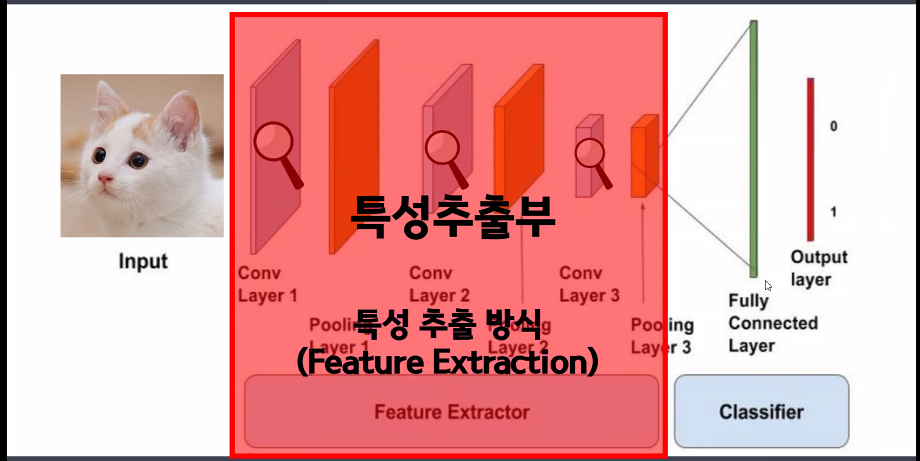
- 특성추출부 → feature extractor
- 특성추출부는 계속 2차원으로 연산 진행(이미지 형태로 연산 진행)
- 분류부 → classifier(단순연산층)
- classifier는 Linear 연산을 해야 하기 때문에 1차원으로 변경 필요
- 따라서 feature extractor에서 classifier로 넘어갈 때 flatten 진행해야 함: view() 사용
- 특성추출부 → feature extractor
- 이미지 데이터는 2차원(가로x세로)
- 흑백 이미지 (가로, 세로) (28,28)
- 컬러 이미지 (가로, 세로, 채널) (28,28,3)
- 특성추출부(Feature Extractor)
- 이미지 형태를 2차원 또는 3차원 형태로 연산
- 내부 층 2가지
- Convolution(Conv): 특성 추출
- Pooling(Pool): downsampling(특성이 아닌 부분을 제거) → 입력의 변화에 영향을 적게 받는다.
- 특성집약되어 있는 최종 결과물을 flatten하여 linear 모델에 넣어 최종 예측
흐름을 이해해야 층을 쌓을 수 있음!
- 모델이 어떻게 디테일한 특징들을 잡아내나요? → 커널(필터)을 통해!
- 커널(필터): 특징을 추출하기 위해 사용
- CNN(합성곱)은 입력된 이미지에서 특징을 추출하기 위해 필터 개념을 도입
- 필터는 초반에 무작위로 사용자가 지정한만큼 생성되며 점점 더 복잡한 필터 형태를 만들어 나가는 게 cnn 알고리즘의 원리
- 커널(필터): 특징을 추출하기 위해 사용
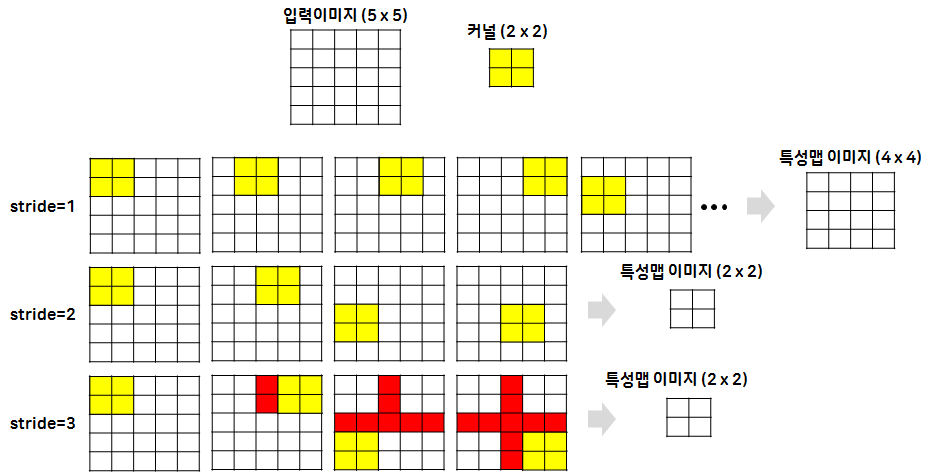
- 보폭(스트라이드, Stride)
- 한 칸씩 이동은 너무 느리고 과한 추출도 우려됨 → 건너뛰면서 진행하자 → 보폭 높이면 됨
- 사용자가 정해줘야 하는 것
- 합성곱 수행 필터 크기
- Stride 크기
- Padding 사용 여부
- Padding은 값 손실을 방지하는 역할
- Padding을 사용하면 입력값과 출력값의 크기가 일치하게 됨
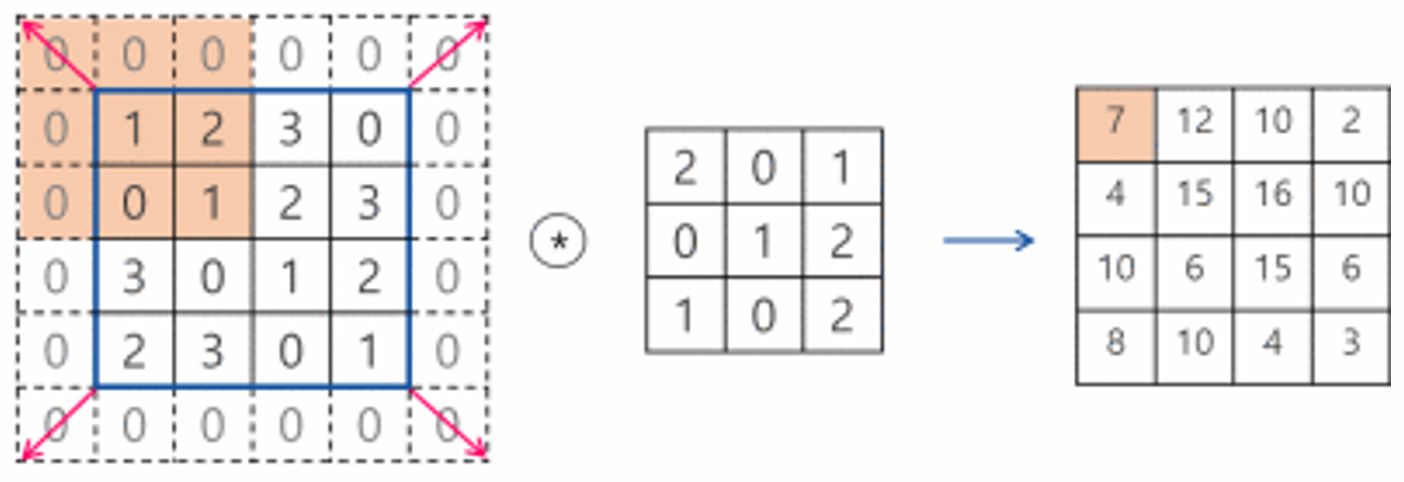
- 합성곱(Convolution)은 두 함수 또는 수열을 결합하여 새로운 함수 또는 수열을 생성하는 수학적 연산입니다. 주로 신호 처리, 이미지 처리, 그리고 딥러닝(특히 합성곱 신경망)에서 사용됩니다. 합성곱 연산은 입력 데이터에 필터(커널)를 적용하여 특징을 추출하는 역할을 합니다.
- CNN에서 합성곱 연산은 여러 개의 필터를 사용하여 이미지나 다른 격자형 데이터에서 특징을 추출하는 핵심적인 역할을 합니다. CNN은 이러한 특징 추출 과정을 반복하여 이미지 분류, 객체 검출 등 다양한 작업을 수행합니다.
- 합성곱 원리
- 필터(커널) 정의: 합성곱 연산에 사용되는 작은 크기의 행렬 또는 배열을 필터 또는 커널이라고 합니다. 이 필터는 이미지나 다른 데이터에서 특정 패턴이나 특징을 감지하는 역할을 합니다.
- 필터 이동: 필터를 입력 데이터 위에서 한 칸씩 이동하며 각 위치에서 겹치는 부분에 대한 연산을 수행합니다.
- 요소별 곱셈 및 합산: 필터의 각 요소와 입력 데이터의 해당 위치의 값을 곱한 후, 모든 결과를 더하여 합성곱 연산의 결과를 계산합니다.
- 특징 맵 생성: 위 과정을 모든 위치에 대해 반복하여 특징 맵(feature map)을 생성합니다. 이 특징 맵은 입력 데이터의 특정 특징이 강조된 새로운 데이터입니다.
합성곱 신경망(CNN, Convolutional Neural Network)
축소 샘플링(subsampling)
- downsampling의 하나
- 합성곱을 수행한 결과 신호를 다음 계층으로 전달할 때 모든 정보를 전달하지 않고 일부만 샘플링하여 넘겨주는 작업
- 좀 더 가치 있는 정보만을 다음 단계로 넘겨주기 위해 축소 샘플링을 함
- 딥러닝에서 원하는 결과를 얻기 위해서는 가치 있는 정보를 줄여가야 함 → 핵심 정보만 다음 계층으로 전달하는 장치가 필요 → 축소 샘플링
- 합성곱(Conv 층)과는 별개로 Pool 층에서 진행됨
- 크게 스트라이드(stride)와 풀링(pooling) 두 가지 기법이 있음
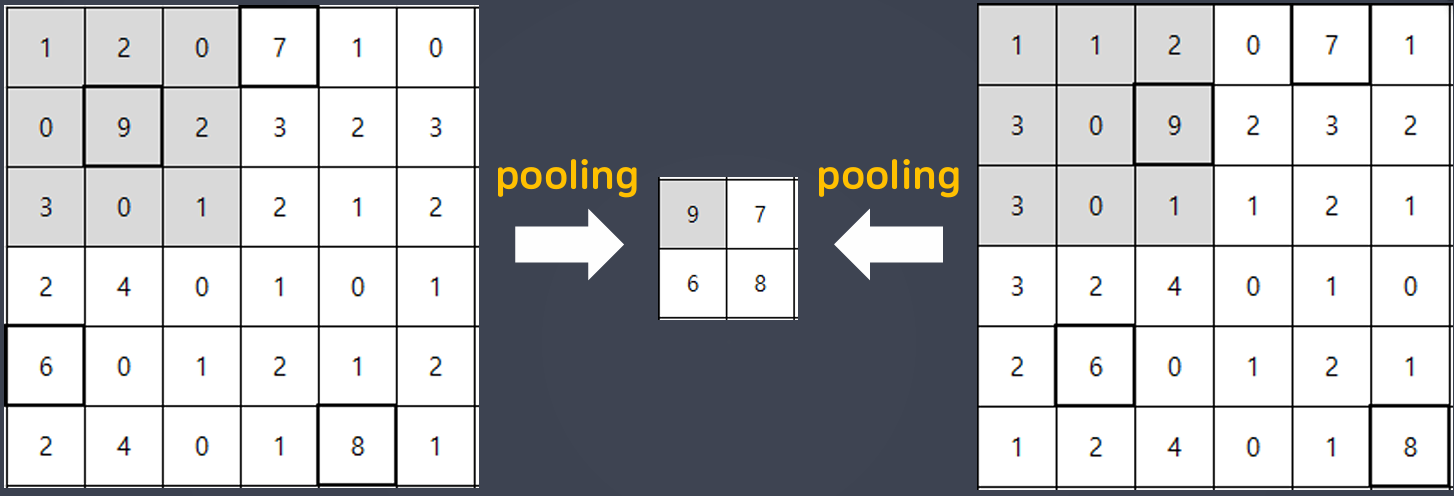
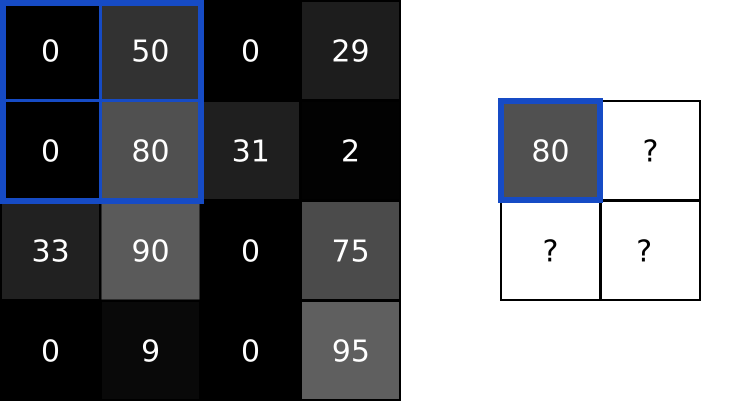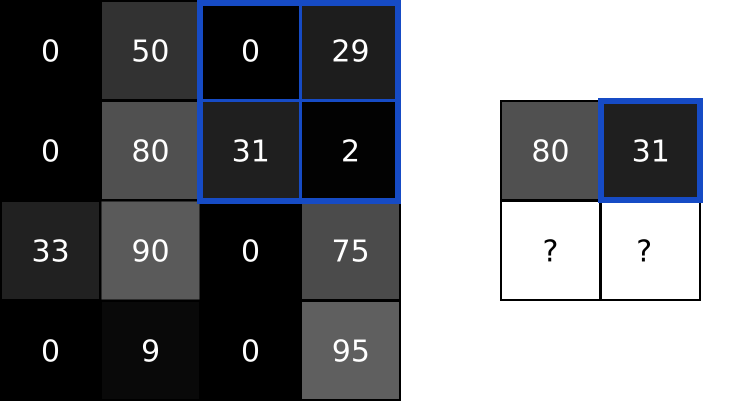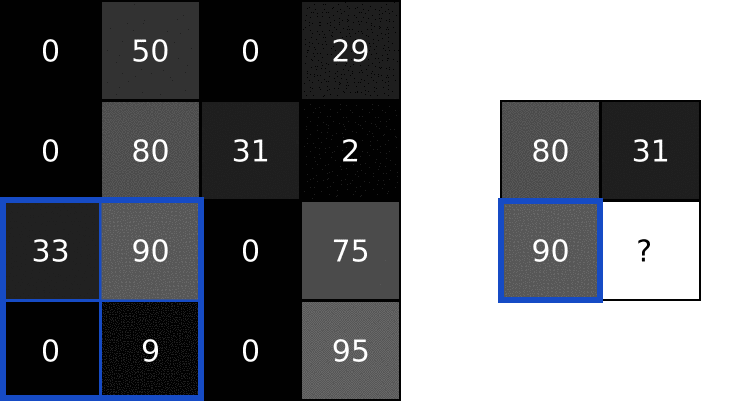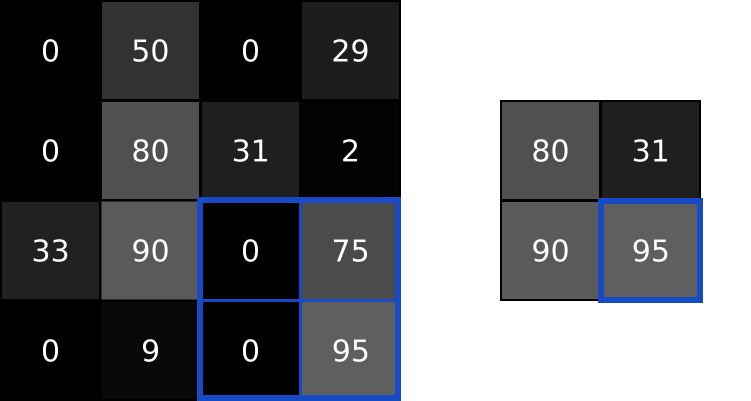
풀링(pooling)
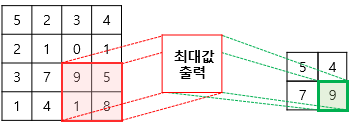
- CNN에서 합성곱 수행 결과를 다음 계층으로 모두 옮기지 않고 일정 범위 내(가로, 세로)에서 가장 큰 값을 하나만 선택하여 넘기는 방법 == 최대풀링(Max Pooling)
- 지역 내 최댓값만 선택하는 풀링을 하면 작은 지역 공간의 대표 정보만 남기고 나머지 신호들을 제거하는 효과를 얻을 수 있음
- 지역 내 평균 값을 선택하는 평균 풀링(Average Pooling)도 있음
- 입력의 변화에 영향을 적게 받는다.
- 풀링 층에서는 특성 맵을 다운샘플링하여 특성 맵의 크기를 줄이는 (downsampling) 풀링 연산 수행
- max pooling : 최대값을 대표값으로 선정
- average pooling : 평균값으로 대표값으로 선정
- Pooling에서도 Stride 설정 가능
- 풀링 연산에서도 스트라이드를 사용하여 크기를 더 줄일 수 있음 (downsampling)
https://blog.joonas.io/196
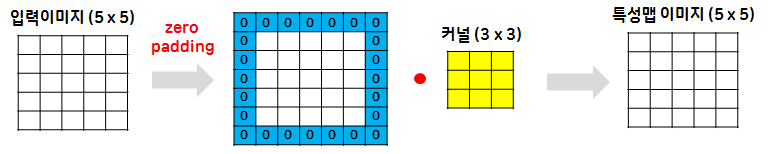
패딩(padding)
- 필터의 크기로 인해 가장자리 부분의 데이터가 부족해서 입력과 출력의 이미지 크기가 달라지게 되는데 이를 보완하기 위해 입력 데이터의 가장자리 부분에 미리 0을 미리 채워넣는 것
- 패딩을 사용하면 입력과 출력의 크기를 같게 맞춰줄 수 있음
- 층이 깊어지면서 이미지의 크기가 줄어드는 것을 방지
- Conv2D 계층에서는 padding 명령을 사용해 패딩을 지정할 수 있음
- same: 출력과 입력이 같아지게 적절한 수의 패딩을 자동 입력
- valid: 패딩을 사용하지 말라는 뜻
- 합성곱 연산의 결과로 얻은 특성 맵은 입력보다 크기가 작아짐
- 합성곱 층을 여러개 쌓았다면 최종적으로 얻은 특성 맵은 초기 입력보다 매우 작아진 상태가 됨
- padding : 합성곱 연산 이후에도 특성 맵의 크기가 입력의 크기와 동일하게 유지되도록 하는 것
- zero padding 합성곱 연산을 하기 전에 입력의 가장자리에 지정된 개수의 폭만큼 0으로 채운 행과 열을 추가해주는 것
stride
- 커널의 이동 범위를 의미
- stride에 따라 특성맵 이미지의 크기가 변경
- Pooling이 속도가 느리므로 stride를 이용해서 크기를 줄이기도 함
파라미터 설정(keras Conv2D)
Conv2D(
filters=32
, kernel_size=(5,5)
, padding="valid"
, input_shape=(28,28,1)
, activation="relu"
, strides=(2,2)
)- filters: Convolution 필터의 수
- Kernel_size: Convolution 필터사이즈 → (행,열)
- padding: 데이터 경계 처리 방법을 정의
- 'valid': 유효한 영역만 출력 → 따라서 출력 이미지 사이즈는 입력 사이즈보다 작음
- 'same': 출력 이미지 사이즈와 입력 이미지 사이즈가 동일 == padding 사용
- input_sample: 샘플 수를 제외한 입력 형태를 정의
- 모델에서 첫 레이어일 때에만 정의 → (가로 픽셀, 세로 픽셀, 채널 수)
- 흑백 영상인 경우 채널이 1이고 컬러(RGB) 영상인 경우에는 채널을 3으로 설정
- activation: 활성화 함수 설정
- 'relu', 'sigmoid', 'softmax', 'linear'
- stride: stride 크기 지정 → (행,열)
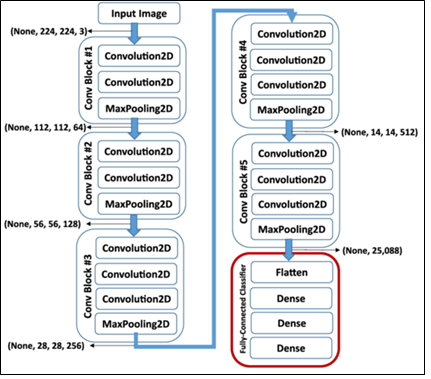
실습: 손글씨 데이터
CNN 신경망 구성
- 출력 크기 =
- ⌋ 기호: 내림 (cf. ⌈ ⌉: 올림): 픽셀 수가 부족하면 합성곱을 못 하니까 내림 진행
class CNN(nn.Module):
def __init__(self): # 이미지 데이터는 크기가 fixed → 굳이 input/output 받을 필요가 없음
super(CNN, self).__init__()
# 특성추출부 (Convolution, Pooling)
self.layer1 = nn.Sequential(
nn.Conv2d( # 2차원의 이미지 데이터를 사용하는 함수: nn.Conv2d(입력, 필터 개수, 필터 크기, 스트라이드, 패딩)
in_channels=1 # 입력 받는 색상 채널을 의미
, out_channels=32 # 필터의 개수를 의미: 한 개의 이미지를 몇 개로 추출할 것인지
, kernel_size=3 # 커널 사이즈(3x3)
, stride=1
, padding=1 # 1: zero padding을 의미
)
, nn.ReLU() # Conv 층은 항상 활성화 함수를 데리고 다님
, nn.MaxPool2d(
kernel_size=2 # 커널 사이즈(2x2)
, stride=2
)
)
# 28*28 → 14*14
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
, nn.ReLU()
, nn.MaxPool2d(kernel_size=2, stride=2)
)
# 14*14 → 7*7
# 분류부 (완전연결층; fully connected layer)
self.fc = nn.Linear(
in_features=7*7*64
, out_features=10
, bias=True
)
# in_features = 가로 픽셀 * 세로 픽셀 * 이전 층의 필터 개수
def forward(self, x):
h = self.layer1(x)
h = self.layer2(h)
h = h.view(h.size(0),-1) # 데이터 구조 변경 → Flatten() 역할
y = self.fc(h)
return y
# CNN 모델 객체 생성 → GPU로 이동
model = CNN().to(device)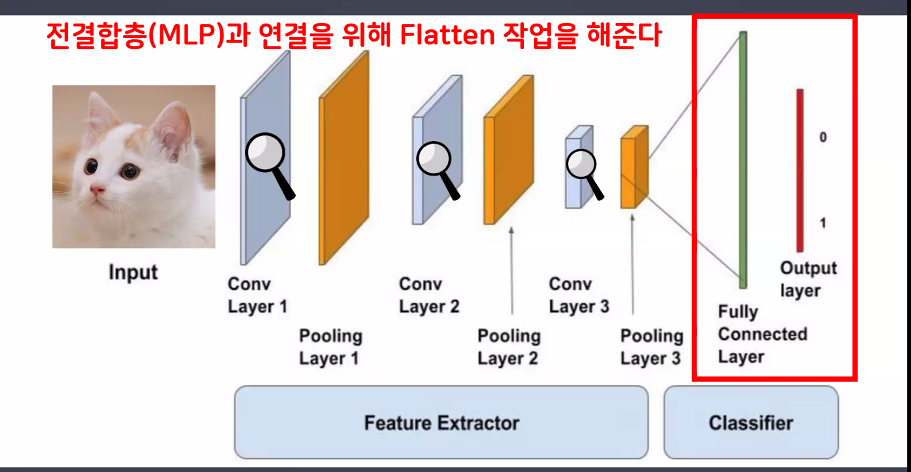
학습 진행
- 학습 파라미터 설정
- 손실 함수
- 최적화 함수
# 학습 파라미터 설정
learning_rate = 0.001
n_epochs = 15
print_interval = 1
lowest_loss = np.inf
lowest_epoch = np.inf
best_model = None
early_stop = 5
# 손실 함수, 최적화 함수
loss_func = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)- 모델 학습
- DataLoader를 활용한 미니 배치 사용
- loss, accuracy를 활용한 시각화
train_loss_his, valid_loss_his = [], []
train_acc_his, valid_acc_his = [], []
for i in tqdm(range(n_epochs)):
train_acc, valid_acc, train_loss, valid_loss = 0, 0, 0, 0
y_pred_list = []
# dataloader 안에 배치 사이즈로 데이터가 분리되어 있음 → 불러오기
for X_train, y_train in train_loader:
# GPU로 이동
X_train = X_train.to(device)
y_train = y_train.to(device)
optimizer.zero_grad()
y_pred = model(X_train)
# loss 계산
loss = loss_func(y_pred, y_train)
# 정확도 계산
corr_cnt = y_pred.argmax(dim=1) == y_train
acc = corr_cnt.float().mean().item() # item(): 값만 추출
# .item() 써야 하는 이유: .mean()까지만 하면 tensor(0.98545, device = 'cuda:0')가 나옴
# 역전파
loss.backward()
# 업데이트
optimizer.step()
train_loss += float(loss)
train_acc += float(acc)
# 미니 배치 결과를 평균 내서 저장
train_loss = train_loss/len(train_loader)
train_acc = train_acc/len(train_loader)
# 검증 → valid 따로 분류하지 않아서 test 데이터로 진행
with torch.no_grad():
for X_test, y_test in test_loader:
X_test = X_test.to(device)
y_test = y_test.to(device)
y_pred = model(X_test)
loss = loss_func(y_pred, y_test)
acc = (y_pred.argmax(dim=1) == y_test).float().mean().item()
valid_loss += float(loss)
valid_acc += float(acc)
y_pred_list.append(y_pred)
valid_loss = valid_loss/len(test_loader)
valid_acc = valid_acc/len(test_loader)
train_loss_his.append(train_loss)
train_acc_his.append(train_acc)
valid_loss_his.append(valid_loss)
valid_acc_his.append(valid_acc)
if (i+1) % print_interval == 0:
print(f"\t epoch {i+1}\n loss: {train_loss:.4f}, acc: {train_acc:.4f}, val_loss: {valid_loss:.4f}, valid_acc: {valid_acc:.4f} lowest_loss: {lowest_loss:.4f}")
if valid_loss <= lowest_loss:
lowest_loss = valid_loss
lowest_epoch = i
best_model = deepcopy(model.state_dict())
else:
if early_stop > 0 and lowest_epoch + early_stop < i+1:
print(f"{early_stop} epochs 동안 모델이 개선되지 않았음")
break
print(f"{lowest_epoch} epoch에서 가장 낮은 검증 손실값: {lowest_loss}")
model.load_state_dict(best_model) 7%|▋ | 1/15 [00:12<02:57, 12.66s/it] epoch 1
loss: 0.2036, acc: 0.9395, val_loss: 0.0584, valid_acc: 0.9819 lowest_loss: inf
13%|█▎ | 2/15 [00:23<02:28, 11.44s/it] epoch 2
loss: 0.0587, acc: 0.9825, val_loss: 0.0551, valid_acc: 0.9812 lowest_loss: 0.0584
20%|██ | 3/15 [00:33<02:12, 11.05s/it] epoch 3
loss: 0.0433, acc: 0.9862, val_loss: 0.0501, valid_acc: 0.9851 lowest_loss: 0.0551
27%|██▋ | 4/15 [00:44<01:59, 10.86s/it] epoch 4
loss: 0.0370, acc: 0.9883, val_loss: 0.0378, valid_acc: 0.9881 lowest_loss: 0.0501
33%|███▎ | 5/15 [00:56<01:51, 11.15s/it] epoch 5
loss: 0.0298, acc: 0.9905, val_loss: 0.0330, valid_acc: 0.9902 lowest_loss: 0.0378
40%|████ | 6/15 [01:06<01:38, 10.99s/it] epoch 6
loss: 0.0245, acc: 0.9925, val_loss: 0.0324, valid_acc: 0.9891 lowest_loss: 0.0330
47%|████▋ | 7/15 [01:17<01:27, 10.92s/it] epoch 7
loss: 0.0214, acc: 0.9928, val_loss: 0.0326, valid_acc: 0.9898 lowest_loss: 0.0324
53%|█████▎ | 8/15 [01:32<01:25, 12.26s/it] epoch 8
loss: 0.0175, acc: 0.9945, val_loss: 0.0342, valid_acc: 0.9889 lowest_loss: 0.0324
60%|██████ | 9/15 [01:43<01:10, 11.72s/it] epoch 9
loss: 0.0139, acc: 0.9953, val_loss: 0.0329, valid_acc: 0.9900 lowest_loss: 0.0324
67%|██████▋ | 10/15 [01:53<00:56, 11.32s/it] epoch 10
loss: 0.0130, acc: 0.9957, val_loss: 0.0357, valid_acc: 0.9897 lowest_loss: 0.0324
67%|██████▋ | 10/15 [02:04<01:02, 12.44s/it] epoch 11
loss: 0.0113, acc: 0.9963, val_loss: 0.0362, valid_acc: 0.9898 lowest_loss: 0.0324
5 epochs 동안 모델이 개선되지 않았음
5 epoch에서 가장 낮은 검증 손실값: 0.032391682291054165
<All keys matched successfully># 시각화
fig, ax = plt.subplots(2,1,figsize=(8,10))
# loss
ax[0].plot(range(1,len(train_loss_his)+1), train_loss_his, label="train loss")
ax[0].plot(range(1,len(valid_loss_his)+1), valid_loss_his, label="valid loss")
ax[0].set_title("loss")
ax[0].set_xlabel("epoch")
ax[0].set_ylabel("loss")
ax[0].grid()
ax[0].legend()
# accuracy
ax[1].plot(range(1,len(train_acc_his)+1), train_acc_his, label="train acc")
ax[1].plot(range(1,len(valid_acc_his)+1), valid_acc_his, label="train acc")
ax[1].set_title("accuracy")
ax[1].set_xlabel("epoch")
ax[1].set_ylabel("accuracy")
ax[1].grid()
ax[1].legend()
plt.tight_layout()
plt.show()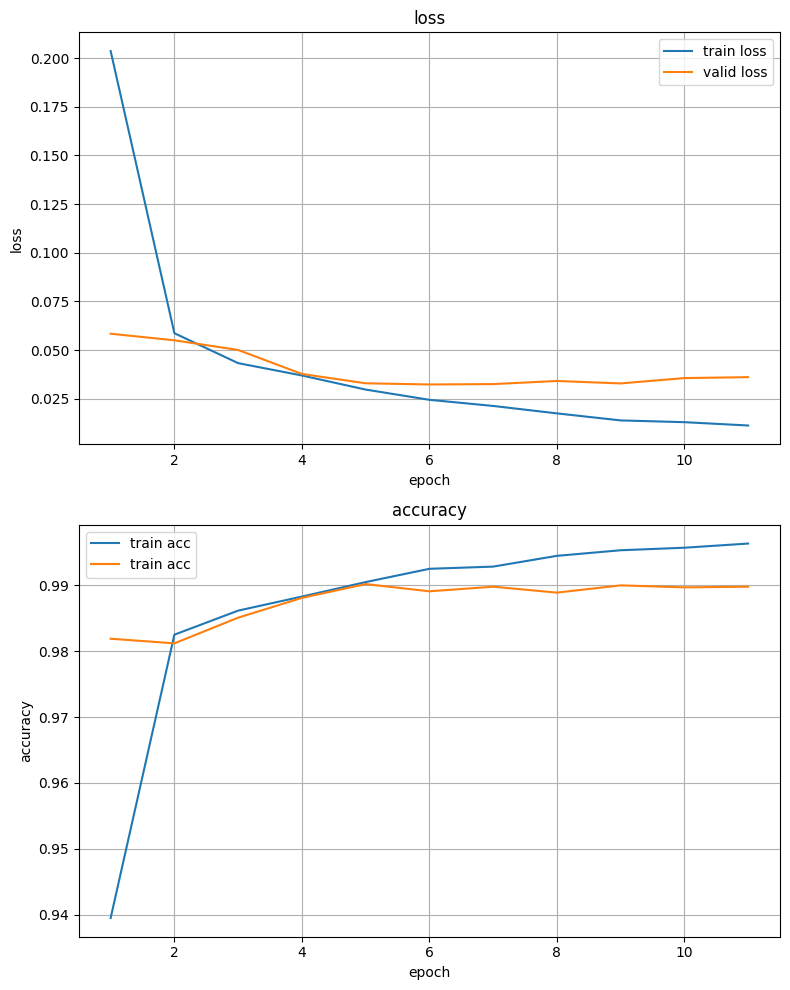
함수화
- 학습 진행 코드를 함수화하여 필요할 때 불러쓸 수 있도록 해 봅시다.
# lib 폴더가 없을 경우 오류가 발생
import os
os.makedirs("lib", exist_ok=True)%%writefile ./lib/util.py # 지금부터 이 셀에 있는 모든 내용을 util.py 파일로 저장하겠다는 코드
from tqdm import tqdm
from copy import deepcopy
import numpy as np
import torch
# 함수 정의
def fit(
model
, train_loader
, test_loader
, loss_func
, optimizer
, device
, n_epochs
, print_interval=1
, lowest_loss=np.inf
, lowest_epoch=np.inf
, early_stop=5
):
train_loss_his,train_acc_his,valid_loss_his,valid_acc_his=[],[],[],[]
best_model=None
# DataLoader 안에 배치 사이즈로 데이터가 분리되어 있음
for i in tqdm(range(n_epochs)):
train_loss,train_acc,valid_loss,valid_acc=0,0,0,0
y_pred_list=[]
# 학습
for X_train,y_train in train_loader:
# GPU로 이동
X_train=X_train.to(device)
y_train=y_train.to(device)
# 최적화 함수 초기화
optimizer.zero_grad()
# 모델 순전파
y_pred=model(X_train)
# loss 계산
loss=loss_func(y_pred,y_train)
# accuracy 계산
acc=(torch.argmax(y_pred,dim=1)==y_train).float().mean().item()
# 역전파
loss.backward()
# w,b 업데이트
optimizer.step()
# 배치별 loss값 모으기
train_loss+=float(loss)
# 배치별 accuracy값 모으기
train_acc+=float(acc)
# epoch 평균 loss, acc 값
train_loss=train_loss/len(train_loader)
train_acc=train_acc/len(train_loader)
# 검증
with torch.no_grad():
for X_test,y_test in test_loader:
X_test=X_test.to(device)
y_test=y_test.to(device)
y_pred=model(X_test)
loss=loss_func(y_pred,y_test)
acc=(torch.argmax(y_pred,dim=1)==y_test).float().mean().item()
valid_loss+=float(loss)
valid_acc+=float(acc)
y_pred_list.append(y_pred)
valid_loss=valid_loss/len(test_loader)
valid_acc=valid_acc/len(test_loader)
train_loss_his.append(train_loss)
train_acc_his.append(train_acc)
valid_loss_his.append(valid_loss)
valid_acc_his.append(valid_acc)
if (i+1)%print_interval==0:
print(f"epoch{i+1} acc:{train_acc:.4f} loss:{train_loss:.4f} val_acc:{valid_acc:.4f} val_loss:{valid_loss:.4f} lowest_loss:{lowest_loss:.4f}")
if valid_loss<=lowest_loss:
lowest_loss=valid_loss
lowest_epoch=i
best_model=deepcopy(model.state_dict())
else:
if early_stop>0 and lowest_epoch+early_stop<i+1:
print(f"{early_stop} epochs 동안 모델이 개선되지 않았음")
break
print(f"{lowest_epoch+1} epoch에서 가장 낮은 검증 손실값: {lowest_loss}")
return best_model, train_acc_his, train_loss_his, valid_acc_his, valid_loss_hisWriting ./lib/util.py
# 기존 파일이 있을 경우: Overwriting ./lib/util.pyclass CNN2(nn.Module):
def __init__(self):
super().__init__()
# layer 1 Conv(필터: 32, 커널: (3,3), 스트라이드: 1, 패딩: zero padding), 폴링(커널: 2, 스트라이드: 2)
self.layer1=nn.Sequential(
nn.Conv2d(1,32,kernel_size=3,stride=1,padding=1)
, nn.ReLU()
, nn.MaxPool2d(kernel_size=2,stride=2)
) # 28x28 → 14x14
# layer 2 Conv(필터: 64, 커널: (3,3), 스트라이드: 1, 패딩: zero padding), 폴링(커널: 2, 스트라이드: 2)
self.layer2=nn.Sequential(
nn.Conv2d(32,64,kernel_size=3,stride=1,padding=1)
, nn.ReLU()
, nn.MaxPool2d(kernel_size=2,stride=2)
) # 14x14 → 7x7
# layer 3 Conv(필터: 128, 커널: (3,3), 스트라이드: 1, 패딩: zero padding), 폴링(커널: 2, 스트라이드: 2, 패딩: zero padding)
self.layer3=nn.Sequential(
nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1)
, nn.ReLU()
, nn.MaxPool2d(kernel_size=2,stride=2,padding=1)
) # 7x7 → 4x4
# 분류기 fc1(입력: ?, 출력: 625), fc2(입력: ?, 출력: ?)
self.fc1=nn.Linear(in_features=4*4*128,out_features=625,bias=True)
self.layer4=nn.Sequential(self.fc1,nn.ReLU(),nn.Dropout(0.2)) # 20퍼센트 비율로 뉴런을 비활성화 해 과대적합을 방지할 때 사용
self.fc2=nn.Linear(625,10,bias=True)
def forward(self, x):
# 특성추출부
h=self.layer1(x)
h=self.layer2(h)
h=self.layer3(h)
# 1차원 변환
h=h.view(h.size(0),-1)
# 분류부
h=self.layer4(h)
y=self.fc2(h)
return y
model2 = CNN2().to(device)Dropout
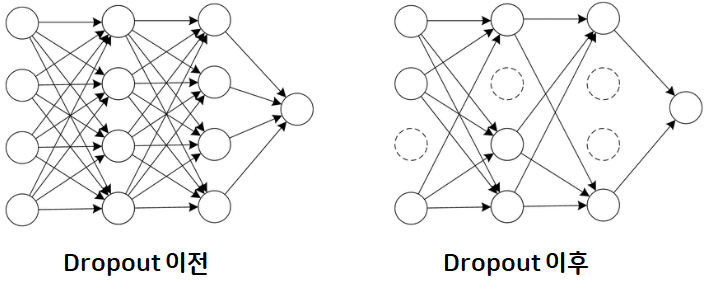
nn.Dropout(비활성화 비율)- 과적합을 방지하고 일반화 성능을 향상시키기 위하여 사용하는 방법 중 하나
- 학습 시 일부 뉴런을 끄는 기법
- 랜덤으로 일부 뉴런 비활성화
신경망에서 해당 층이 퍼셉트론을 일정 확률로 사용하지 않도록 하는 방법 → 복잡도 감소 → 과대적합 감소 - 학습 시에만 사용하고 추론 시에는 사용하지 않음 (모든 퍼셉트론 사용)
- 입력층, 출력층에는 사용 안 함
from lib.util import fit # lib/util.py에 정의된 fit 함수를 사용하겠다는 뜻
# 손실 함수, 최적화 함수
loss_func = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model2.parameters())
b_model, acc, loss, val_acc, val_loss = fit(
model = model2
, train_loader=train_loader
, test_loader=test_loader
, loss_func=loss_func
, optimizer=optimizer
, device=device
, n_epochs=10
, early_stop=3
) 10%|█ | 1/10 [00:12<01:55, 12.87s/it]epoch1 acc:0.9395 loss:0.1890 val_acc:0.9847 val_loss:0.0448 lowest_loss:inf
20%|██ | 2/10 [00:25<01:39, 12.48s/it]epoch2 acc:0.9841 loss:0.0494 val_acc:0.9875 val_loss:0.0414 lowest_loss:0.0448
30%|███ | 3/10 [00:37<01:27, 12.49s/it]epoch3 acc:0.9887 loss:0.0352 val_acc:0.9913 val_loss:0.0303 lowest_loss:0.0414
40%|████ | 4/10 [00:49<01:14, 12.39s/it]epoch4 acc:0.9918 loss:0.0253 val_acc:0.9912 val_loss:0.0295 lowest_loss:0.0303
50%|█████ | 5/10 [01:02<01:01, 12.32s/it]epoch5 acc:0.9930 loss:0.0219 val_acc:0.9906 val_loss:0.0312 lowest_loss:0.0295
60%|██████ | 6/10 [01:14<00:49, 12.39s/it]epoch6 acc:0.9948 loss:0.0165 val_acc:0.9935 val_loss:0.0273 lowest_loss:0.0295
70%|███████ | 7/10 [01:27<00:37, 12.42s/it]epoch7 acc:0.9953 loss:0.0152 val_acc:0.9908 val_loss:0.0340 lowest_loss:0.0273
80%|████████ | 8/10 [01:39<00:24, 12.31s/it]epoch8 acc:0.9959 loss:0.0122 val_acc:0.9915 val_loss:0.0292 lowest_loss:0.0273
90%|█████████ | 9/10 [01:51<00:12, 12.19s/it]epoch9 acc:0.9967 loss:0.0108 val_acc:0.9930 val_loss:0.0243 lowest_loss:0.0273
100%|██████████| 10/10 [02:02<00:00, 12.28s/it]epoch10 acc:0.9970 loss:0.0093 val_acc:0.9861 val_loss:0.0536 lowest_loss:0.0243
9 epoch에서 가장 낮은 검증 손실값: 0.024339423169221844# 시각화
fig, ax = plt.subplots(1,2,figsize=(16,4))
# loss
ax[0].plot(range(1,len(loss)+1), loss, label="train loss")
ax[0].plot(range(1,len(val_loss)+1), val_loss, label="valid loss")
ax[0].set_title("loss")
ax[0].set_xlabel("epoch")
ax[0].set_ylabel("loss")
ax[0].grid()
ax[0].legend()
# accuracy
ax[1].plot(range(1,len(acc)+1), acc, label="train acc")
ax[1].plot(range(1,len(val_acc)+1), val_acc, label="valid acc")
ax[1].set_title("accuracy")
ax[1].set_xlabel("epoch")
ax[1].set_ylabel("accuracy")
ax[1].grid()
ax[1].legend()
plt.tight_layout()
plt.show()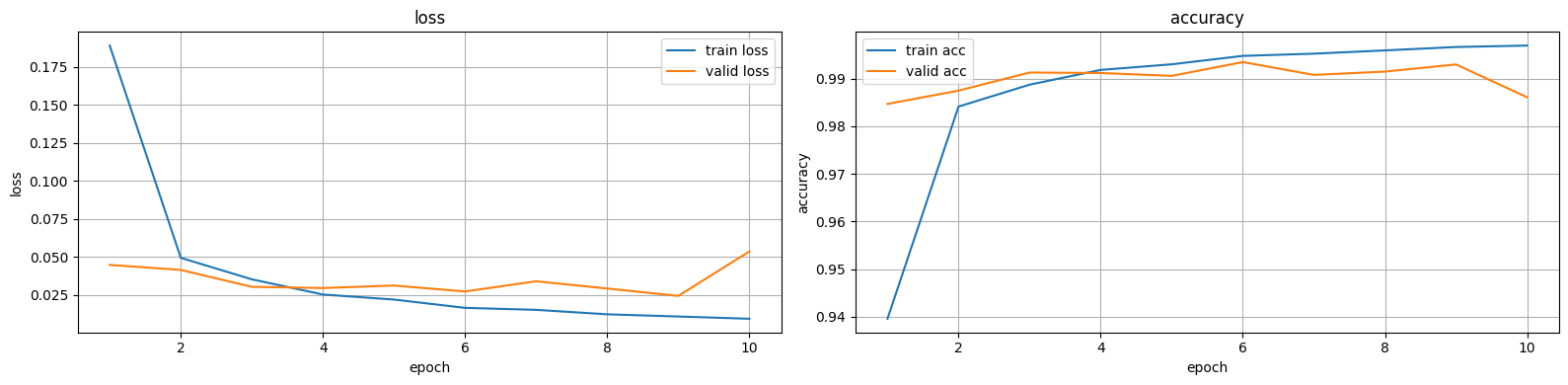
신경망 성능 개선
과대적합 피하는 방법
- 학습 조기 중단(early stopping)
- 과대적합이 되기 전까지 모델 학습
- 드롭아웃(dropout)
- 신경망 중간층 뉴런 일부를 비활성화시켜 과대적합 방지
- 데이터 증강(data augmentation) → 이미지 증식
- 원본과 유사한 데이터를 생성해 폭넓은 학습에 도움
드롭아웃(dropout)
- 일정한 비율만큼 랜덤으로 중간층의 뉴런을 비활성화 → 과도하게 학습되는 현상 방지
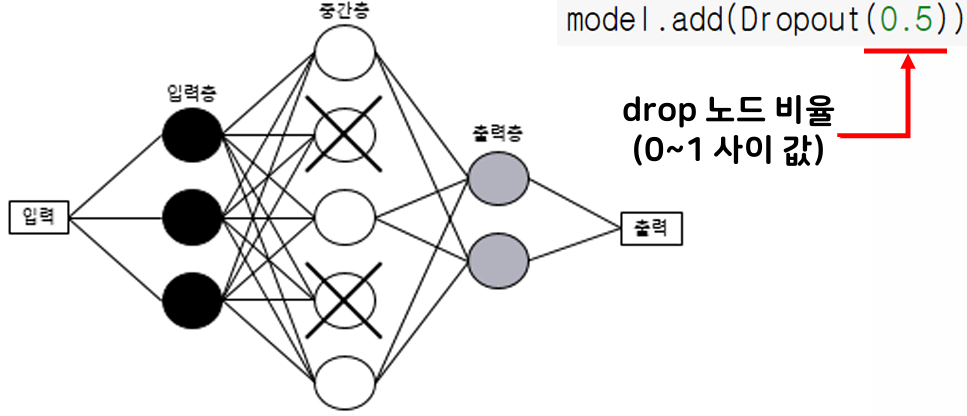
- 학습(역전파)을 하는 동안에만 적용
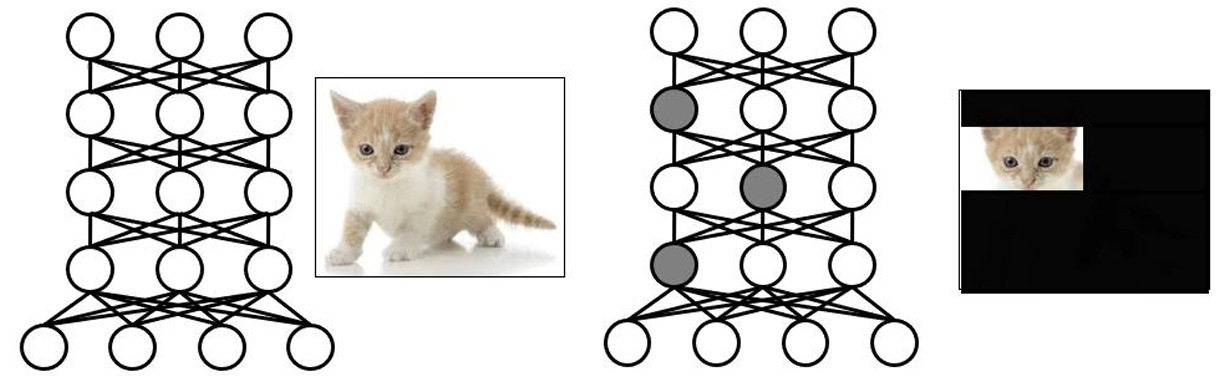
- 학습 종료 후 예측을 하는 단계에서는 모든 유닛을 사용하여 예측함
데이터 증강
- 데이터의 핵심 특성을 유지하면서 다양한 방법으로 데이터 양을 증가시키는 방법
- 훈련 데이터를 유사하고 다양하게 변형하여 새로운 훈련 데이터처럼 추가적으로 사용함으로써 마치 훈련 데이터 수가 늘어난 효과를 얻는 것
이미지 증강(증식)

- 확대, 축소, 상하좌우 이동, 회전, 뒤집기, 기울기 등을 활용하여 이미지 변환 후 저장
- 원본 이미지 데이터를 다양한 이미지 데이터인 것처럼 만들 수 있음
- 한 개의 이미지를 여러 개인 것처럼 만들어 학습
| 증강 기법 | 설명 |
|---|---|
| Horizontal Flip | 이미지를 좌우로 뒤집음 (mirroring) |
| Vertical Flip | 이미지를 상하로 뒤집음 |
| Rotation +45° | 이미지를 +45도 회전 |
| Rotation -45° | 이미지를 -45도 회전 |
| Blur | 이미지에 블러 효과를 적용하여 흐릿하게 만듦 |
| Brighter | 이미지의 밝기를 증가시킴 |
| Noise Added | 이미지에 **잡음(Noise)**를 추가 |
| Darker | 이미지의 밝기를 감소시켜 어둡게 만듦 |
| Grayscale | 이미지를 **흑백(Grayscale)**으로 변환 |
| Crop | 이미지의 일부를 잘라냄(Cropping) |

- 과대적합이 일어나는 이유 중 하나는 훈련 데이터가 부족하기 때문
- 훈련 데이터가 충분히 많다면 과대적합을 줄일 수 있음

- rotation_range = 360
- 0˚에서 360˚ 사이에서 회전
- width_shift_range = 0.1
- 전체에서 10% 내외 수평 이동
- height_shift_range = 0.1
- 전체에서 10% 내외 수직 이동
- shear_range = 0.5
- 0.5 라디안 내외 시계 반대 방향으로 변형
- zoom_range = 0.3
- 0.7 ~ 1.3배로 축소/확대
- horizontal_flip = True
- 수평 방향으로 뒤집기
- vertical_flip = True
- 수직 방향으로 뒤집기
이미지 증강 실습
# 이미지 불러오기
from PIL import Image
pil_image=Image.open("./data/cat.png")
plt.imshow(pil_image)
plt.axis("off")
plt.show()
- 이미지는 'NumPy ndarray'라는 사실 기억하기
plt.axis("off")를 안 하면 아래와 같이 출력된다:

# 파이토치 내부적으로 정의하고 있는 정책을 사용하여 이미지 증식 설정: 이미지 증강 정책
# 이미지에 최적화된 증강 방법들을 조합하여 자동으로 적용(Auto Augment)
transform=transforms.AutoAugment(transforms.AutoAugmentPolicy.IMAGENET) # IMAGENET: 대규모 이미지 데이터셋 이름(약 1,400만 장 정도(2만 1천 개의 카테고리) 제공)
# 증식 결과 출력
for i in range(9):
# NumPy ndarray 형태의 이미지 → tensor 형태로 변환
# NumPy: (Height, Width, Channel) 순으로 배치
# Tensor: (C, H, W) 순으로 배치
# 따라서 shape 변경해 줘야 한다 → permute(): 차원의 순서를 변경
tensor=torch.as_tensor(np.asarray(pil_image)).permute(2,0,1)
# 증식 수행
applied_image=transform(tensor)
# 결과 출력
plt.subplot(3,3,i+1)
plt.imshow(applied_image.permute(1,2,0).numpy()) # permute()는 텐서에만 사용 가능
plt.axis('off')
전이 학습(Transfer Learning) ★★★
- 다른 데이터셋으로 이미 학습한 모델을 가지고 유사한 다은 데이터를 인식하는 데 사용하는 기법
- 특히 새로 훈련시킬 데이터가 충분히 확보되지 못한 경우에 높은 학습 효율을 보여줌
- 다양하고 많은 데이터셋으로 학습한 합성곱신경망을 일부 가져와 내 학습에 활용하는 방법
- 훈련시킬 데이터가 충분히 확보되지 않을 경우 사용
- 학습 성능을 높여줌
- 전이학습 모델을 적절히 이용하는 방법: 두 가지 방식 존재
- 특성 추출 방식(feature extraction)
- 미세 조정 방식(fine tunning)
특성 추출 방식(Feature Extraction)
- CNN 층에서 특성추출부만 가져와서 사용하는 방식
- 특성충추출부 부분만 사용하는 이유: 분류기(MLP)의 경우 우리가 해결하고자 하는 문제에 맞게 새로 설정해 줘야 하기 때문
- 단, 새롭게 분류할 클래스의 종류가 사전 학습에 사용된 데이터와 특징이 매우 다르면, 특성추출부 전체를 재사용해서는 안 되고 심플한 특징들만 추출해내기 위해 앞 단의 일부 계층만을 재사용해야 함
- 미리 학습된 cnn 신경망을 가져와 사용자가 설계한 분류기와 연결 사용
- 특성추출부는 학습 X == 가중치 업데이트 X → 동결
미세 조정(Fine Tunning) ★★★
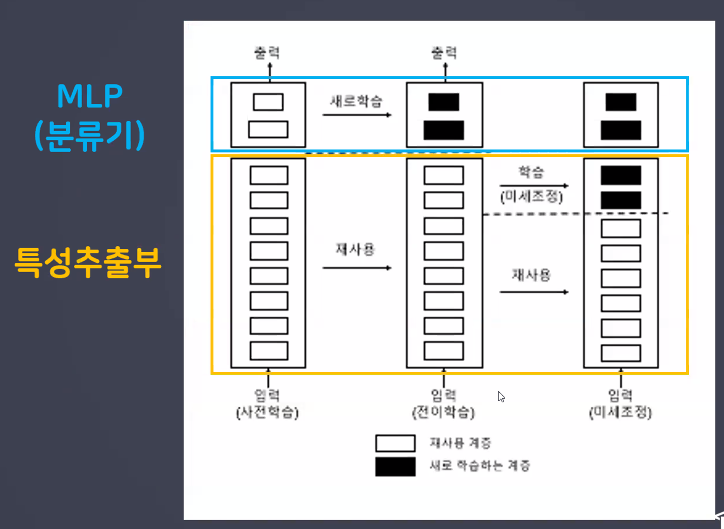
- '사전 학습된 모델의 가중치'를 목적에 맞게 전체 또는 일부를 재학습시키는 방식
- 특성추출부의 층들 중 하단부 몇 개의 계층을 전결합층 분류기(MLP)와 함께 새로 학습시킴
- 처음부터 특성추출부 계층들과 분류기(MLP)룰 같이 훈련시키면 새롭게 만든 분류기에서 발생하는 큰 에러값으로 인해 사전 학습된 가중치가 많이 손실될 수 있음 → 앞 단 계층들을 고정(동결)하고 됫 단의 일부 계층만 학습이 가능하게 설정한 후 MLP와 같이 학습시켜 파라미터(w,b)들을 적당하게 잡아 줌
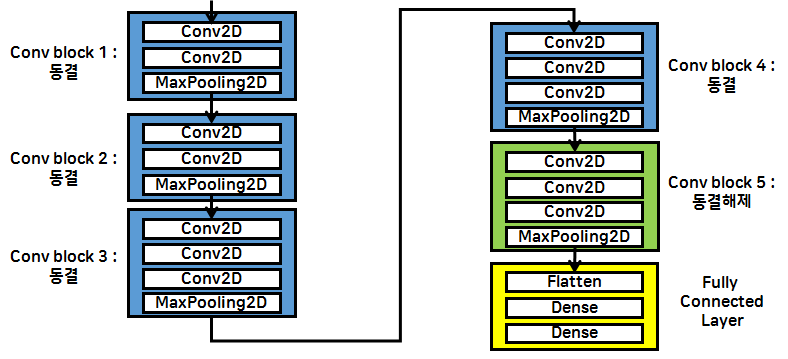
- 미리 학습된 cnn 학습망을 가져와서 사용자가 설계한 분류기와 연결
- 일부 특성추출층은 학습되도록 동결을 풀어주고 나머지 층의 cnn 신경망은 동결
- 동결된 일부 층을 동결 해제하여 가중치 업데이트 진행
- 나의 분류 문제에 더 밀접하게 사용하기 위함
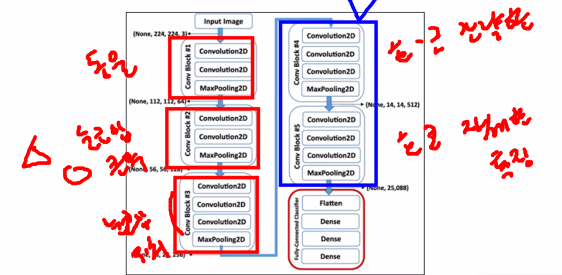
앞으로는 모델을 처음부터 끝까지 만들기보다는 다른 사람들이 만든 모델 가져와서 fine tunning 하는 일이 훨씬 많기 때문에 해당 개념을 잘 알아둬야 함
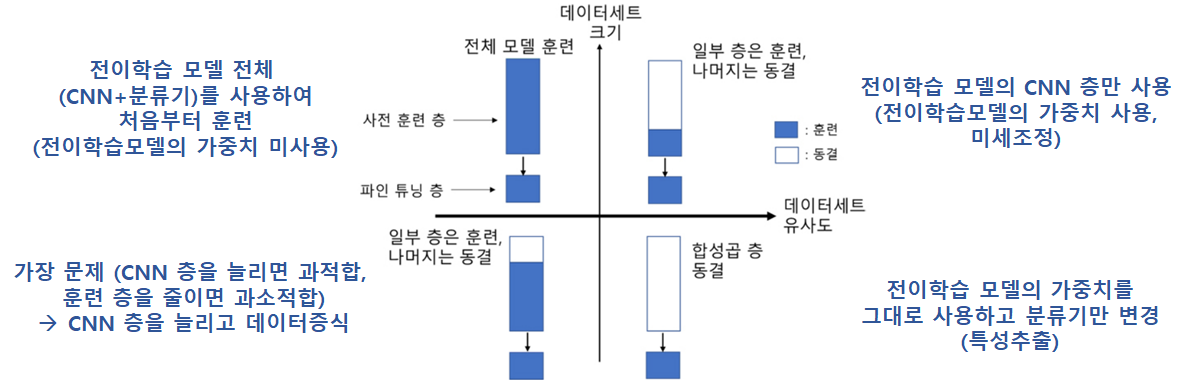
- 데이터 세트 크기와 유사도에 따른 파인튜닝의 유형 ★★★
VGG16 모델
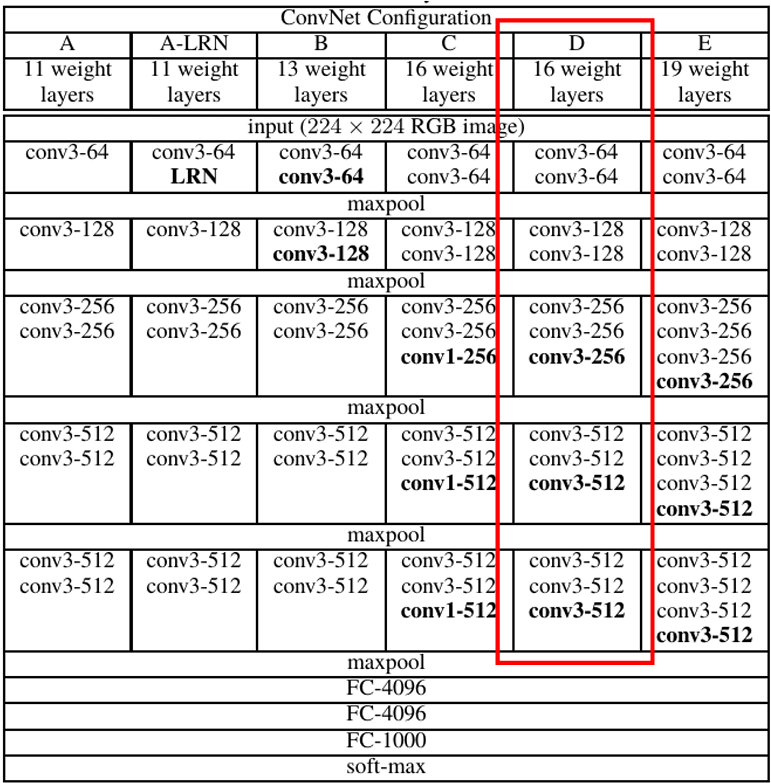
- VGG-16 Architextures
- ImageNet Challenge 2014 (3x3 filter)
- 더 알아보기
하루 돌아보기
👍 잘한 점
- 궁금한 점, 이해 안 되는 지점 바로 질문함
.from_numpy(),.as_tensor()차이- torch.from_numpy()는 NumPy 배열을 PyTorch Tensor로 변환: 기존 NumPy 배열과 데이터를 공유
- 따라서 반환된 Tensor를 수정하면 NumPy 배열도 수정됨 (즉, NumPy 배열과 Tensor가 메모리 상에서 동일한 위치를 참조하고 있음)
- as_tensor는 파이썬 리스트에서 바로 텐서로 갈 수 있음
- 꽤 큰 사이즈의 list라면 as_tensor를 쓰는 게 더 빠르고, np.array에는 from_numpy를 사용하는 쪽이 더 좋다고 함 (자세한 내용은 여기 참고)
- torch.Tensor나 torch.tensor로 캐스팅해 텐서를 만드는 방법도 있는데, 이들은 위에서 소개한 방법들과는 달리 데이터를 복사해 새로 텐서를 만드는 방식이다. 반면 위에서 소개한 방법들은 데이터 복사 없이 데이터의 view만을 바꾸어 주는 방법들이다.
.permute().permute()는 텐서에만 적용 가능함- only used to swap the axes (vs.
view(): reshapes the tensor to a different but compatible shape)
subplot()- for 문 안에서 plot을 여러 개 만드는 것이니 subplots() 아니고 subplot() 써야 함
- subplots()는 figure()랑 비슷하다고 생각하면 됨 (혼자도 쓸 수 있고 여러 개를 큰 묶음으로 감쌀 수도 있음)
- 야간자율학습 진행
👎 아쉬웠던 점
- 별로 안 중요한 것들을 물어봐서 수업 흐름을 방해한 게 아닐까 좀 걱정됨
- 질문할 때 말투도 좀 개선이 필요해 보임
🔬 개선점
- 질문 잘 하는 법을 익히자

2 B R 0 2 B