텍스트 마이닝(Text Mining)
학습 목표
- 텍스트 마이닝의 개념과 프로세스 이해
- 텍스트 데이터를 이용한 머신러닝 학습 수행
Conception
텍스트 마이닝(Text Mining)이란?
- Data Mining의 한 종류
- Data Mining: 빅데이터 안에서 규칙이나 패턴을 분석하여 가치 있는 정보를 추출하는 과정
- 텍스트 데이터로부터 유용한 인사이트를 발굴
- 자연어 처리 방식(Natural Language Processing, NLP)과 문서처리 방법을 적용해 유용한 정보를 추출/가공하는 것을 목적으로 하는 기술
자연어(Natural Language)
- 인간이 일상생활에서 사용하는 언어
- 인간이 정보를 전달하는 수단
- 특정 집단에서 사용되는 모국어의 집합
- 한국어, 영어, 일본어, 중국어 등
- '인공 언어'와 대비되는 개념
- 인공 언어란?
- 특정 목적을 위해 인위적, 의도적으로 만든 언어
- 예: 프로그래밍 언어(Python 등), 형삭 언어(수학식), 에스페란토 등
- 특정 법칙들에 따라 적절하게 구성된 문자열들의 집합
- 인공 언어란?
- 자연어(Natural language) 처리
- 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 과정
- 자연어를 입력받아서 해당 입력이 특정 범주일 확률을 구함
자연어처리 응용 분야
- 인간의 언어가 사용되는 실세계의 모든 영역
- 정보 검색, 질의응답 시스템
- Google, Naver, iPhone Siri, Galaxy Bixby, IBM Watson
- 기계번역, 자동통역
- Google Translator, Naver Papago, ETRI 지니톡
- 문서 작성, 문서 요약, 문서 분류, 철자 오류 검색 및 수정, 문법 오류 검사 및 수정
기업 활용 사례
- 지식 경영
- 많은 양의 텍스트 문서 중 의미 있는 데이터만 뽑아내어 효율적으로 관리
- 예시:

- 사이버 범죄 예방
- 특정 단어 분류를 통한 범죄 예측, 예방 어플리케이션 등
- 고객 관리 서비스
- 고객에게 빠르고 자동화된 응답을 제공하기 위해 활용
- 예시: 챗봇
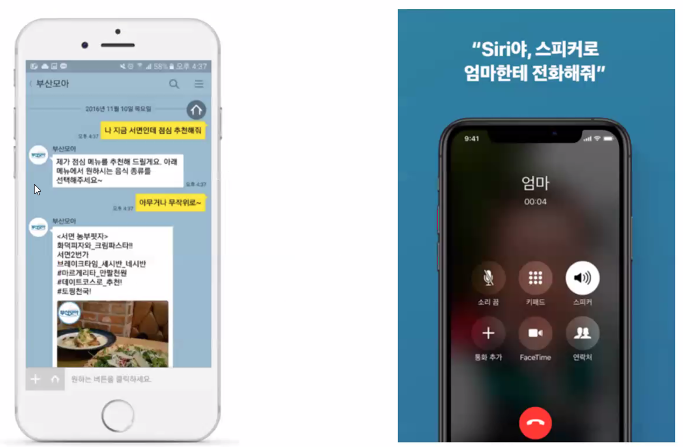
- 컨텐츠 요약
- 다양한 목적에 따라 그에 적합한 내용으로 정리하고 요약
- 예시: 텍스트 마이닝 기술을 활용한 농산물 주문 정리 시스템
- 실제 사용자가 주문 내용을 복사해 붙여넣기만 하면 일정한 형식의 주문서가 자동으로 생성되는 방식
- 비정형 주문 메시지를 간단하게 편집, 저장해 농가의 주문 처리 시간 단축

- 소셜 미디어 데이터 분석
- 해당 브랜드나 제품에 대한 다양한 의견과 감성반응을 살핌
- 예시:
텍스트 마이닝의 영역
- 텍스트 분류(Text Classification)
- 텍스트 요약(Summarization)
- 감성 분석(Sentiment Analysis) ★
- 긍정/부정
- 7가지 감정(기쁨, 슬픔, 두려움, 분노, 자신감, 적대감, 분석적)
- 텍스트 군집화 및 유사도 분석(Clustering)
Process
텍스트 데이터의 구조
말뭉치 >> 문서 >> 문단 >> 문장 >> 단어 >> 형태소
→ 텍스트를 데이터 관점에 바라보면 크기 순으로 문서(document), 단락(paragraph), 문장(sentence), 단어(word), 형태소(morpheme)로 분류할 수 있다.
더 알아보기
- 말뭉치(corpus)
- 분석을 위해 수집한 문서들의 전체 집합(Large and structured set of texts)
- 특정 언어의 정형화된 대용량 텍스트 표본들의 집합
- 여러 개의 문서로 구성
- 문서
- 여러 개의 문단으로 구성
- 문단
- 여러 개의 문장으로 구성
- 줄을 바꾸고, 들여쓰기를 하는 단위
- 하나의 주제를 이끌어 내는 중심 문장과 그 중심 문장을 설명하거나 보충하거나 하는 문장들이 있음
- 하나의 글에서 내용이나 형식을 기준으로 하여 크게 나누어 끊은 단위 == 하나의 주제만을 표현하는 문장들을 묶은 것
- 한 편의 글에는 여러 개의 문단이 들어 있다.
- 문장
- 여러 개의 단어로 구성
- 문법상의 용어로 단어, 구, 절이 포함됨
- 주부와 술부로 나눔
- 생각, 감정, 움직임 모양 등을 표현하는 최소 단위
- 종류: 평서문, 의문문, 감탄문, 명령문 등
- 단어
- 여러 개의 형태소로 구성
- 하나 이상의 글자로 되어 뜻을 나타내는 말
- 형태소
- 일정한 의미가 있는 가장 작은 말의 단위
- 언어학 차원에서는 다시 여러 개의 음소(phoneme)로 나누지만 자연어처리와 빅데이터 분석에서는 형태소 차원까지만 다룸
- 예: 첫사랑 → 첫, 사랑, 애늙은이 → 애, 늙은이
- 첫사랑: 토큰(token) 두 개 → 첫, 사랑
- 토큰(token): 텍스트 분석을 위해 쪼개 놓은 가장 작은 단위 (텍스트 분석의 분석 단위)
- 토큰의 단위는 사용자가 직접 지정 → 띄어쓰기, 단어, 문장 등
대개의 경우 토큰은 단어를 의미하기도 하지만 하나의 글자 단위일 수도 있고 형태소 단위일 수도 있다. 토큰은 통계적인 기법을 적용하여 빈도를 분석하여 전체적인 맥락을 분석하던지, 문서에 나타난 주제(topic)나 감정(Sentiment)을 추정하는 기법들이 개발되어 있다.
→ 탐색적 접근방법으로 형태소 분석기로 명사들을 추출하여 특정 단어들의 빈도를 카운트하여 시각화해서 보여주는 워드클라우딩 기법 등을 통하여 전체 문서의 맥락이나 말뭉치를 파악하는 방법들을 사용하기도 한다.
텍스트 마이닝 분석 프로세스
텍스트 수집 ⇨ 전처리 ⇨ 토큰화 ⇨ 특성 추출 ⇨ 데이터 분석
- 텍스트 데이터 수집
- Crawing을 이용한 Web 데이터 수집: SNS/블로그/카페 등
- 빅카인즈(BIG Kinds): 뉴스 데이터 제공 사이트
- NDSL(www.ndsl.kr): 국내외 논문, 특허, 연구보고서 통합 정보 제공 사이트
- 텍스트 전처리
- 전처리는 용도에 맞게 텍스트를 사전에 처리하는 작업
- 오탈자 제거, 띄어쓰기 교정 등
- 불용어 제거: 데이터에서 큰 의미가 없는 단어 제거
- e.g., 음, 뭐, 아 등
- 불용어(stop words): 사용하지 않는 단어라는 의미
- 불용어 꾸러미(사전) 사용
- 정제(cleaning): 가지고 있는 코퍼스(corpus, 말뭉치)로부터 노이즈 데이터(noise data)를 제거
- corpus: 수집된 문서들의 집합
- noise data: 등장 빈도가 적은 데이터, 의미 없는 특수문자 등
- 정규화(normalization): 표현 방법이 다른 언어들을 통합하여 같은 단어로 만듦
- e.g. 사투리: "대끼리", "기가 막히다", "죽인다", "억수로 좋다", "귀하다", "좋겄다" → 표준어: "좋다"로 바꾸기
- 동일한 의미인데 단어 형태가 달라(사투리) 중요한 단어인데 중요도가 낮아지면 안 되기 때문에 하나(표준어)로 통일
- 비슷한 단어는 하나로 묶어서 힘을 실어줘야 함
- 어간 추출(Stemming): 단어의 핵심 부분(어간)만 추출
- e.g., 먹다, 먹고, 먹지, 먹어서 등 → '먹'
- 용언: 형용사, 동사 → 어간, 어미 존재 → 어간만 추출
- 표제어 추출(Lemmatization): 유사한 단어들에서 대표 단어를 추출
- e.g., am/are/is → be동사
- 토큰화(tokenization)
- 작은 단위로 나누는 작업(공백 기준, 형태소 기준, 명사 기준, 단어 기준 등)
- 토큰의 기준은 사람이 선택하기에 따라 다름 == 기준은 분석 방법에 따라 다름 → 공백, 형태소, 명사, 단어 등
- 한국어의 경우 '형태소 기준'을 주로 적용 ∵교착어라서
- 감성 분석을 한다면:
- 한글에서 감성을 나타내는 품사: 동사, 형용사 쪽에 가까움 → 한글 형태소 분석기를 사용해 동사, 형용사 위주로 추출(by 품사 tagging)
- 토큰화 도구들도 종류별로(만든 사람에 따라) 결과물 다름: 데이터에 따라 다르게 사용
- 서울대학교 토큰화 도구(Kkma) → 논문 분석
- X(구 트위터) 토큰화 도구(Okt) → 리뷰 데이터 분석, Social Media 글 분석 등
- 학습을 위해서 주어진 코퍼스(corpus, 말뭉치)에서 토큰(token)이라 불리는 단위로 나누는 작업
- 말뭉치: 수집된 문서들의 집합
기준은 "내가 어떤 데이터를 분석하느냐"에 따라 다름!
- 특칭 추출(특징 값 추출)
- '중요한 단어'를 선별하는 과정
- '중요 단어'란?
- 많이 나오는 단어가 중요한 단어(단순 빈도수 기반) → CounterVectorize
- 모든 문서에서 많이 나오는 건 오히려 덜 중요(문서 내 등장 횟수 반영) → TF-IDF
- '중요한 단어'로서의 특징: 적은 수의 문서에 분포되어 있어야 하고, 문서 내에서도 빈번하게 출연해야 함(TF-IDF)
- 특정 텍스트를 통해 문서를 구분 짓는 것이기 때문에 어떤 단어가 모든 문서에 분포되어 있다면 개수가 많더라도 차별성 없는 일반적인 단어
- '중요 단어'란?
- 토큰화된 걸 숫자로 변환하는 과정
- 단순 수치화 X → 의미를 내포하고 수치화하기 때문에 '특징 추출'이라 함
- 인간은 읽으면 중요도 자동 파악하지만 컴퓨터는 그렇지 못함 → 숫자 형태로 특징을 다르게 줌
- 예: CounterVectorize, TF-IDF
- '중요한 단어'를 선별하는 과정
- 데이터 분석
- 머신러닝
- Linear Regression
- Logistic Regression
- Random Forest
- XGBoosting
- 딥러닝
- CNN
- RNN
- LSTM
- GRU
- 머신러닝
텍스트 데이터를 분석하려면 무조건 "전처리 - 토큰화 - 수치화" 과정 거쳐야 함 (필수)
토큰화(tokenize)의 종류
- 단어(word) 단위
- 텍스트를 단어로 나누고 각 단어를 하나의 백터로 변환
- 문자(Character) 단위
- 텍스트를 문자로 나누고 각 문자를 하나의 벡터로 변환
- n-gram 단위
- 텍스트에서 단어나 문자의 n-gram을 추출하여 n-gram을 하나의 벡터로 변환
나눈다 == 토큰화한다, 하나의 벡터로 변환 == 수치화한다
- 단어: 자립해서 쓸 수 있음(띄어 쓸 수 있는 것) vs. 문자: 자음, 모음으로 쪼개진 것
- 영어는 띄어쓰기 단위 분석, 한국어는 형태소 단위 분석이 훨씬 더 유의미한 결과 추출 가능
- 토큰화 n-gram
- 묶음 단위
- n개의 연속된 단어를 하나로 취급하는 방법
- n: KNN의 K와 같은 의미(정해져 있지 않은 숫자) → 사용자가 정의하는 하이퍼파라미터
- n=2인 경우를 bi-gram이라고도 부름
- 묶음 단위를 "추가로" 제공하는 것 → 단어 개수가 늘어난 효과
- 예: "러시아 월드컵"이라는 표현을 "러시아"와 "월드컵" 두 개의 독립된 단어로만 취급하지 않고 두 단어로 구성된 하나의 토큰으로 취급

수치화
- 토큰화 결과를 수치로 변경하는 과정
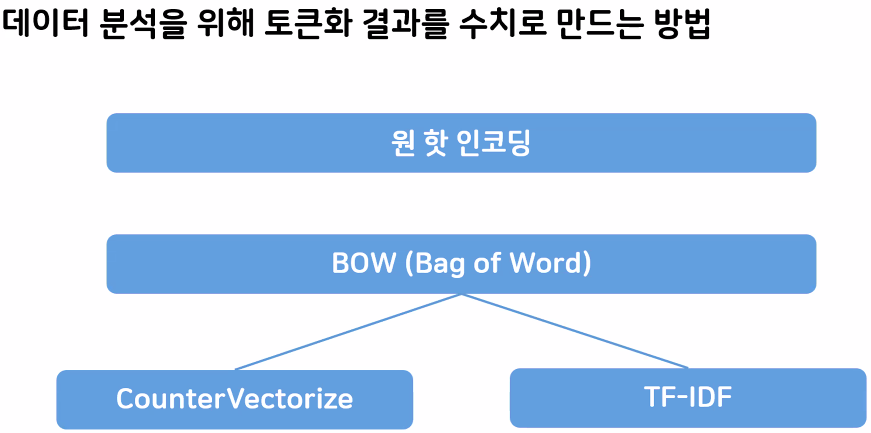
- 원핫 인코딩(One-Hot Encoding)
- 토큰에 고유 번호를 배정하고 모든 고유 번호 위치의 한 컬럼만 1, 나머지 컬럼은 0인 벡터로 표시하는 방법
- 예:
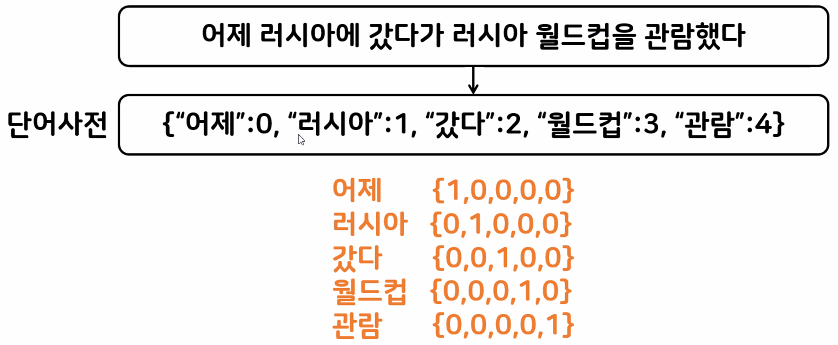
- 예:
- '희소 형렬(sparse matrix)' 문제: 의미 없는 데이터(0)가 너무 많이 메모리를 차지하고 있어 메모리에 문제 발생할 수 있음
- 따라서 텍스트 데이터에서는 많이 사용하지 않음
- 토큰에 고유 번호를 배정하고 모든 고유 번호 위치의 한 컬럼만 1, 나머지 컬럼은 0인 벡터로 표시하는 방법
- BOW(Bag of Words)
- 모든 문서의 모든 단어를 추출하여 피처로 만듦

- 단어의 의미적 연관성은 고려하지 않음
- 두 가지 방식
- CounterVectorize: 단순 카운트 기반의 백터화
→ 카운트 벡터화는 카운트 값이 높을수록 중요한 단어로 인식: 분별성 x - TF-IDF(Term Frequency - Inverse Document Frequency): 카운트 백터화 보완 (패널티 부여)
→ 하나의 문서에만 많이 나오는 단어가 중요하다! → 모든 문서에서 많이 나오는 단어에 inverse(패널티)
- CounterVectorize: 단순 카운트 기반의 백터화
- 모든 문서의 모든 단어를 추출하여 피처로 만듦
BOW: CounterVectorize
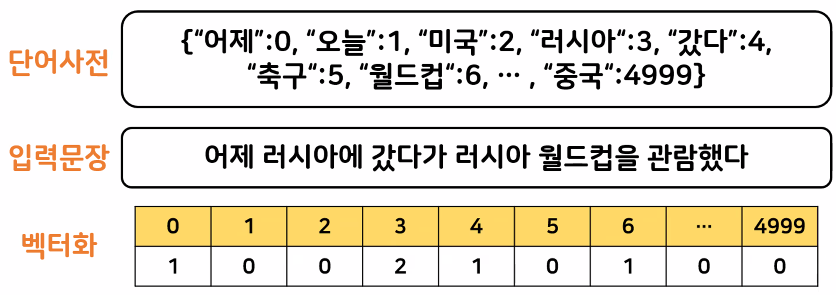
- 단어들의 문맥이나 순서를 무시하고, 빈도 수를 기반으로 백터화시키는 방식
- 단어의 순서나 중요도를 고려하지 않기 때문에 문맥의 의미를 반영하기 힘듦
BOW: TF-IDF(Term Frequency - Inverse Document Frequency)
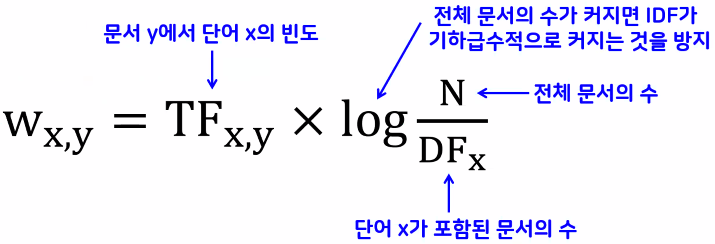
- 개별 문서에서 자주 등장하는 단어에는 높은 가중치를 주되, 모든 문서에 자주 등장하는 단어에는 패널티를 주는 방식 → 단어의 중요도를 반영
- TF: 단어가 각 문서에서 발생한 빈도
- DF: 단어가 등장한 문서의 수
- 적은 문서에서 상대적으로 많이 발견될수록 가치 있는 정보
- 많은 문서에 자주 등장하는 단어일수록 일반적인 단어
- e.g., 나, 그, 했다 등
- 단어가 특정 문서에서만 나타나는 '희소성'을 반영하기 위해 TF에 DF의 역수(IDF)를 곱한 값을 사용
단어사전은 항상 만들어야 함!
추가: 용어 정리
- parsing : 문장을 분해하는 것
- tagging: 품사의 레이블을 달아주는 것
- stopwords = common words
- stemming: 단어의 뿌리/줄기를 찾는 법
- 다양한 접미사를 제거하고 단어의 수를 감소시키기 위해 사용
- Term-Document Matrix: parsing, stopwords 처리, stemming 후 아래와 같은 matrix로 정리
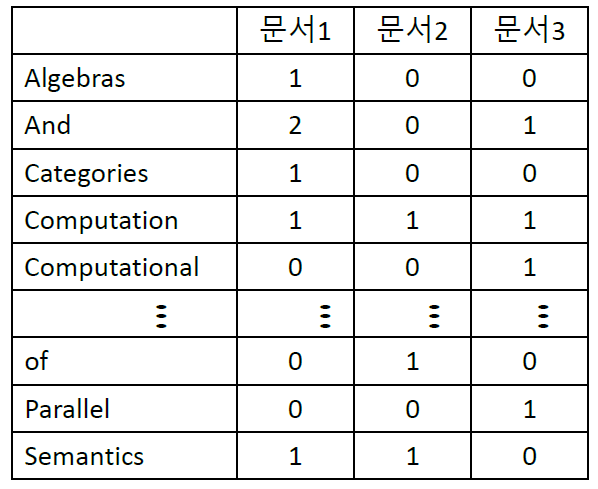
- 어절: 문장을 띄어쓰기 단위로 나눈 것
- ex) 공부는/어렵지만/재미있었습니다.
- 정규식: 규칙을 입력하여 규칙에 해당하는 텍스트를 매칭시켜주는 프로그래밍 언어의 일종

- Weighting: Term-Document Matrix 결과에 가중치를 부여
- 문서 내의 빈도가 높은 용어에 높은 가중치 부여 → 문서를 잘 설명함
- 코퍼스 내 빈도가 낮은 용어에 높은 가중치 부여 → 코퍼스 내 문서를 더 잘 식별함
- TF-IDF 가중치:
- TF(Term Frequency) =
- IDF(Inverse Document Frequency) =

- = 2, = 5 → 따라서 IDF = log(5/2)
- = 5, = 5 → 따라서 IDF = log(5/5)
- TF-IDF는 전체 문서들 중에서 단어 i가 적은 수의 문서에서 발생 횟수가 많으면 큰 값을 가짐
- 큰 값을 가지는 단어일수록 높은 식별력을 가진다고 할 수 있음
- morphology: 형태론
- 단어와 형태소를 연구
- 의미가 있는 작은 단위로 자르는 것
- Part-Of-Speech(POS) tagging: 각 문장에서 품사를 tagging 해주는 것(대명사, 명사...)
- Phrase Chunking: 명사구(noun phrases, NPs)와 동사구(verb phrases, VPs)를 자르는 것(형용사구/부사구/전치사구)
phrases: 구(의미 있는 단위) / clause: 절(주어와 동사가 같이 있는 문장 성분)
- syntax: 구문론/통사론
- 문법적 구조분석(Parsing)
- semantics: 의미론
- Word Sense Disambiguation: 동음이의어들로 인한 모호성
- 뉘앙스, 톤, 의도(긍/부정) 등 단어 의미 차이를 연구
- pragmatics: 화용론(Dialog Knowledge)
- discourse: 담화론
- 음운론(Phonology) : 음성인식 등 말소리를 연구
- 추리론(Reasoning) : 전문용어, 세대별 용어 등 도메인 특성을 연구
추가: 자연어 처리 시스템
- 구성도
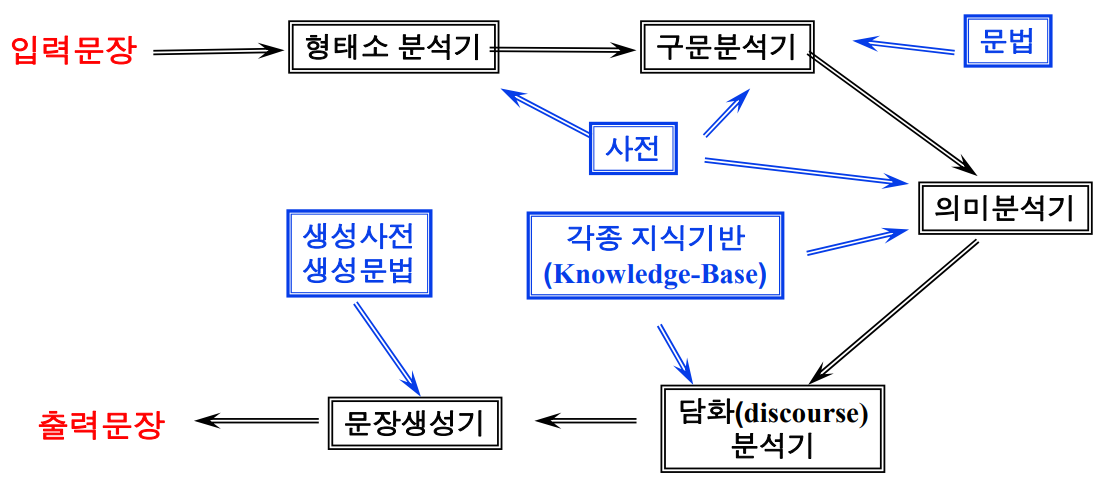
- 자연어 처리가 어려운 이유
- 불규칙한 Linguistic Rules
- e.g., 복수형의 불규칙: ox (황소) - oxen (황소들), person (사람) - people (사람들), mouse (쥐) - mice (쥐들)
- ambiguity
- Complex and subtle
- Fuzzy, probabilistic
- Involves reasoning about the world(경험/사회적 지식이 필요)
- Changing over time
- 불규칙한 Linguistic Rules
- Learning Approach의 장점
- 많은 양의 데이터에 접근이 가능해짐
- tagging하는 것의 난이도가 분석 규칙을 만드는 것보다 쉬움
- 다양한 방식의 알고리즘이 생성됨
- 형태소
- 뜻을 가진 가장 작은 단위
- 좌우접속정보란?
- 한 어절을 이루는 형태소들의 품사간의 접속
여부를 행렬로 표현한 것 - 80년데 일본에서 처음 시도
- 좌/우측에 붙을 수 있는 것을 기준으로
- 좌접속범주: 홍길동씨에서 "씨" → 인명고유명사, 한자형접두사(보통명사 좌측에 접속 가능)
- 우접속범주
- 지금은 많은 형태소 분석기들이 우접속범주와 좌접속범주로 나누지 않고 일반적인 품사로 좌우접속정보를 만들어 사용하고 있음
- 한 어절을 이루는 형태소들의 품사간의 접속
- 용언의 불규칙 활용의 예시
- 돕다 → 도와서
- 파랗다 → 파란
- 사전검색방법 3가지
- ISAM
- Hashing
- Trie
- ISAM과 그 사용의 장/단점
- ISAM은 Index 부분과 Data 부분을 분리하여 저장한 사전임
- B+Tree를 이용한 Index 방식
- 장점: 다른 응용 프로그램과 쉽게 공유 가능
- 단점: 모든 가능성에 대하여 사전 검색을 실시, 불필요한 사전 검색이 과다(사전 검색 속도는 빠르지만 검색해야 하는 양이 많고 한 단어를 검색하더라도 너무 많은 시퀀스가 나옴)
- TRIE(트라이)를 이용한 사전검색 특징
- 한번의 사전 검색으로 prefix를 모두 검색
- 음운축약으로 인한 철자 변화 예측가능
- 장점: 불필요한 사전검색을 억제, 불규칙과 음운축약으로 인한 철자변화에 능동적 대처
- 단점: TRIE index 저장을 위한 공간 낭비, 사전 구조에 의존적인 사전 탐색 알고리즘 필요
- 형태소 분석기의 구성 모듈
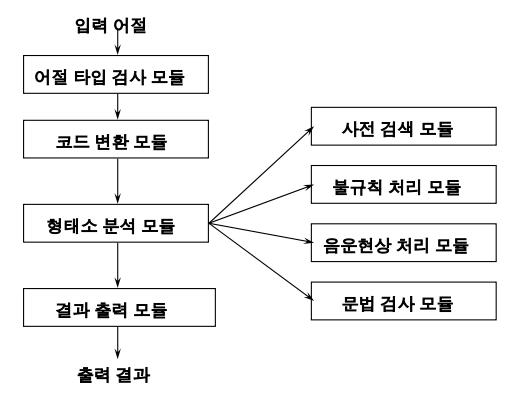
- 순서: 불규칙처리 & 음운현상 처리모듈 → 사전검색 → 문법검사
- 어절 타입 검사모듈:
- 어절분리(영어/숫자 등을 분리)
- 코드변환모듈:
- 완성형코드(음절)를 자소단위의 조합형으로 변형
- 형태소분석기 돌림
- 다시 자소단위의 조합형을 완성형코드로 변형 (다시 최종적으로는 음절 입출력 표준코드로 변환시킴)
- 한글을 표현하는 코드시스템(완성형 vs. 조합형)
- 완성형 표준: 2byte사용
- 각 byte의 첫번째 bit가 항상1, ASCII의 경우 0
- 그러므로 16bit-2bit = 14bit로 표현
- 조합형 표준: 2byte 사용
- 2byte별 첫번째 bit가 항상 1
- 그러므로 16bit-1bit = 15bit로 표현
- 완성형 표준: 2byte사용
- 형태소 분석 방법
- 어절을 형태소 단위로 분절
- 형태소 분석 문법 검사
- 형태소 분석기 구현의 예(형태소 추출 방법): Tabular Parsing 법 (문법검사 모듈)
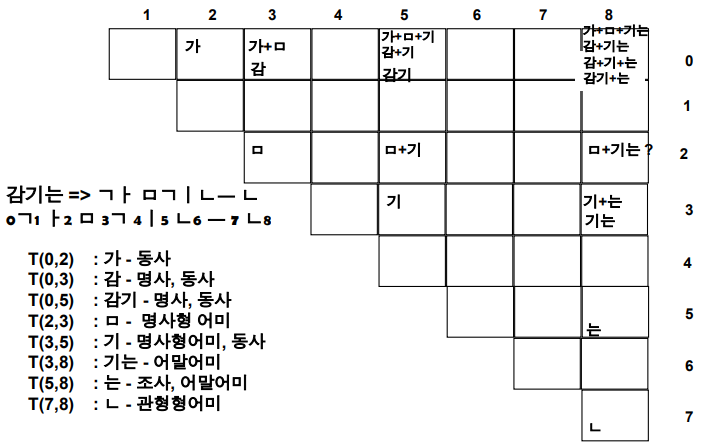
- 우리가 찾아낸 품사들이 서로 연결될 수 있는지를 찾는 알고리즘
실습: 네이버 영화 리뷰 분석
학습 목표
- 자연어 처리를 위하여 텍스트 데이터를 처리하는 과정 학습
- 텍스트 데이터를 처리하여 감성 분석 진행
텍스트 데이터 분석 순서
- 텍스트 데이터 수집
- 텍스트 전처리
- 오탈자 처리, 띄어쓰기 교정, 정규화, 어간 추출, 표제어 추출, 불용어(stop words) 제거 등
- 토큰화
- 문서, 문장의 특징을 추출하기 위해 잘게 쪼개주는 작업
- 데이터 분석의 목적에 따라 다르게 설정
- 단위: 띄어쓰기 단위(단어 단위), 형태소 단위(형태소분석기 활용)
- 특징값 추출 (토큰화 된 데이터를 수치화, 백터화)
- 원핫 인코딩
- 단어 사전에 있는 텍스트 데이터들을 있으면 1, 없으면 0으로 표기
- 문제점: 희소 행렬(A sparse matrix) 문제를 발생시킨다.
- BOW(Bag of Words)
- CounterVectorizer: 단순 카운트 기반
- TF-IDF: 특정 문서에서만 자주 등장하는 단어에 가중치, 모든 문서에서 자주 등장하는 단어에 패널티 부여
- 원핫 인코딩
- 데이터 분석
데이터 불러오기
- 영화 리뷰 데이터를 통해 텍스트 분석 → 감성분석
# 라이브러리 불러오기
import numpy as np
import pandas as pd
# 데이터 불러오기
text_train = pd.read_csv("./data/ratings_train.txt", delimiter="\t")
text_test = pd.read_csv("./data/ratings_test.txt", delimiter="\t")
# 데이터 크기 확인
text_train.shape, text_test.shape((150000, 3), (50000, 3))- 학습용 데이터: 15만 개
- 평가용 데이터: 5만 개
- id, document, label
- id: 리뷰를 작성한 사용자 id
- document: 리뷰
- label: 정답 데이터
- 긍정/부정 → 1: positive / 0: negative
# 데이터 정보 확인
text_train.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150000 entries, 0 to 149999
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 150000 non-null int64
1 document 149995 non-null object
2 label 150000 non-null int64
dtypes: int64(2), object(1)
memory usage: 3.4+ MB- train 데이터 결측치 5개 확인 → 삭제 필요
text_test.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50000 entries, 0 to 49999
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 50000 non-null int64
1 document 49997 non-null object
2 label 50000 non-null int64
dtypes: int64(2), object(1)
memory usage: 1.1+ MB- test 데이터 결측치 3개 확인 → 삭제 필요
# 정보를 확인했을 때 train에 5개의 결측치, test에 3개의 결측치 확인 → 결측치 제거: dropna
text_train.dropna(inplace=True)
text_test.dropna(inplace=True)
text_train.shape, text_test.shape((149995, 3), (49997, 3))워드 클라우드: 단어 빈도 분석 활용
- 단어 빈도 분석을 통해 워드 클라우드 생성하기
# 리뷰 데이터 추출
rv_train = text_train["document"]
# 토큰화 작업: 띄어쓰기 단위로 모든 문장을 쪼개서 리스트에 담아주자!
temp = [i.split(' ') for i in rv_train]
# CounterVectorize를 위해 2차원 리스트를 1차원으로 변경
token_list = []
for i in temp:
token_list += i
# Counter 기능을 활용하여 단어 빈도 측정
from collections import Counter
cnt = Counter(token_list)
# 의미 있는, 자주 등장하는 단어 확인: 상위 40개 정도
cnt.most_common(40)[('영화', 10825),
('너무', 8239),
('정말', 7791),
('진짜', 5929),
('이', 5059),
('영화.', 3598),
('왜', 3285),
('더', 3260),
('이런', 3249),
('그냥', 3237),
('수', 2945),
('영화를', 2759),
('잘', 2644),
('다', 2615),
('보고', 2557),
('좀', 2449),
('영화는', 2426),
('그', 2421),
('영화가', 2418),
('본', 2298),
('최고의', 2219),
('ㅋㅋ', 2019),
('내가', 2000),
('없는', 1957),
('이건', 1889),
('이렇게', 1828),
('완전', 1780),
('평점', 1760),
('봤는데', 1746),
('있는', 1739),
('좋은', 1726),
('이거', 1710),
('이게', 1676),
('보는', 1600),
('평점이', 1595),
('내', 1595),
('다시', 1583),
('그리고', 1547),
('참', 1508),
('많이', 1478)]- 워드 클라우드 생성
# 워드 클라우드 설치
!pip install wordcloud
# 시각화를 위한 한국어 설치: 설치 후 반드시 세션 다시 시작해야 함
!apt-get install -y fonts-nanum*
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
# 세션 다시 시작할 때에는 위 코드 주석 처리하기!
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 워드 클라우드 객체 생성
wc = WordCloud(
background_color="white"
, font_path="/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf"
, random_state=23
)
# 워드 클라우드는 한 문장을 받아 띄어쓰기 기준으로 알아서 분석하기 때문에 token_list 형태를 바꿔야 함
one_str = ' '.join(token_list)
cloud = wc.generate_from_text(one_str)
plt.imshow(cloud)
plt.axis("off")
plt.show()
- 단순 카운트 → 의미 없는 단어(부속어)가 너무 많음
추가: 파이썬 리스트 차원 축소(평탄화) 방법
- sum() 함수 사용
- sum() 함수의 두 번째 인자로 빈 리스트 [] 를 전달하여 리스트 덧셈을 수행, 중첩된 리스트를 하나의 리스트로 합칩니다.
my_list = [[1, 2], [3, 4], [5]]
flattened_list = sum(my_list, [])
print(flattened_list) # 출력: [1, 2, 3, 4, 5]- 리스트 컴프리헨션 사용
- 리스트 컴프리헨션을 사용하여 각 하위 리스트의 요소들을 순회하며 새로운 리스트에 추가합니다.
my_list = [[1, 2], [3, 4], [5]]
flattened_list = [item for sublist in my_list for item in sublist]
print(flattened_list) # 출력: [1, 2, 3, 4, 5]- itertools.chain() 사용
- itertools.chain() 은 여러 iterable 객체를 하나의 iterator로 연결해주는 함수입니다. *my_list 는 리스트를 언패킹하여 각 하위 리스트를 인수로 전달합니다.
import itertools
my_list = [[1, 2], [3, 4], [5]]
flattened_list = list(itertools.chain(*my_list))
print(flattened_list) # 출력: [1, 2, 3, 4, 5]- NumPy 사용
- NumPy 배열의 flatten() 메서드를 사용하여 차원을 축소할 수 있습니다.
import numpy as np
my_list = [[1, 2], [3, 4], [5]]
flattened_array = np.array(my_list).flatten()
print(flattened_array.tolist()) # 출력: [1, 2, 3, 4, 5]- 재귀 함수 사용 (다차원 리스트)
- 다차원 리스트의 경우 재귀 함수를 사용하여 중첩된 모든 리스트를 순회하며 평탄화합니다.
def flatten_list_recursive(data):
result = []
for item in data:
if isinstance(item, list):
result.extend(flatten_list_recursive(item))
else:
result.append(item)
return result
my_list = [[1, [2, 3]], [4, [5, [6]]]]
flattened_list = flatten_list_recursive(my_list)
print(flattened_list) # 출력: [1, 2, 3, 4, 5, 6]→ 위에서 소개된 방법 외에도 다양한 방법으로 리스트의 차원을 축소할 수 있습니다. 상황에 맞게 적절한 방법을 선택하여 사용하면 됩니다.
워드 클라우드: 형태소 분석기 활용
- 형태소 분석기를 활용하여 토큰화 후 품사 매칭하여 리뷰를 확인하는 데 필요한 품사만을 활용하여 워드 클라우드 재생성
- KoNLPy 공식 문서
- Kkma: 서울대에서 개발한 형태소 분석기
- ntag = 56
- Okt: 트위터(X)에서 개발한 형태소 분석기
- ntag = 19
- Mecab: 일본에서 개발한 형태소 분석기
- Kkma: 서울대에서 개발한 형태소 분석기
- 한국어 토큰화 도구 비교
| 토큰화 도구 | 설명 | 장점 | 단점 | 사용하면 좋은 글 유형 |
|---|---|---|---|---|
| KoNLPy - Okt | 트위터에서 개발한 한국어 형태소 분석기 | - 속도가 빠름 - 줄임말, 신조어에 강함 - 명사, 동사, 형용사 태깅 지원 | - 분석 정확도가 상대적으로 낮음 - 긴 문장에서 오탈자나 오류 발생 가능 | - SNS 댓글, 트위터, 카톡 대화 등 구어체 데이터 |
| KoNLPy - Mecab | 일본 Mecab을 한국어에 맞게 수정한 형태소 분석기 | - 속도가 가장 빠름 - 비교적 높은 정확도 - 메모리 사용량 적음 | - 윈도우 환경에서 설치가 까다로움 - 사용자 사전 추가 필요 | - 뉴스, 문서 요약, 법률 문서 등 정형 데이터 |
| KoNLPy - Kkma | 서울대에서 개발한 형태소 분석기 | - 구문 분석 기능 포함 - 문장 분리 기능 제공 | - 속도가 느림 - 명사 추출 시 과도한 분할 발생 가능 | - 학술 논문, 문서 분석, 보고서 |
| KoNLPy - Komoran | Shineware에서 개발한 형태소 분석기 | - 딥러닝 기반으로 정확도 높음 - 사용자 사전 확장 가능 | - 속도가 느린 편 | - 뉴스 기사, 공식 문서, 챗봇 |
| KoNLPy - Hannanum | KAIST에서 개발한 한국어 형태소 분석기 | - 어절 분석 및 띄어쓰기 보정 기능 제공 - 구문 분석 가능 | - 속도가 느림 - 비교적 오래된 기술로 최신 트렌드 반영 부족 | - 논문, 신문 기사, 공식 문서 |
| Kiwi | 한국어 형태소 분석기 (KyTea 기반) | - 최신 기술 적용 - 속도와 정확도 균형 잡힘 - 신조어, 띄어쓰기 보정 기능 제공 | - 비교적 새로운 도구라 참고 자료 부족 | - 검색 엔진, 챗봇, 감성 분석 |
# 한국어 형태소 분석기 -> 코엔엘파이(KoNLPy): 분석기 모음집
!pip install konlpy
# 다양한 형태소 분석기 도구 사용해보기: Kiwi는 KoNLPy 안에 없어서 설치해야 함
!pip install kiwipiepy
# Mecab 설치하기: KoNLPy에 있지만 사용하려면 추가 설치 필요
!git clone https://github.com/SOMJANG/Mecab-ko-for-Google-Colab.git
!bash ./Mecab-ko-for-Google-Colab/install_mecab-ko_on_colab_light_220429.sh
# 다양한 형태소 분석기 불러오기 (분석 용도에 맞게 사용)
from kiwipiepy import Kiwi
from konlpy.tag import Kkma
from konlpy.tag import Okt
from konlpy.tag import Mecab
# kiwi → 띄어쓰기 교정이 가능!
kiwi = Kiwi()
kiwi.space("띄어쓰기없이작성된텍스트입니다.키위형태소분석기의띄어쓰기성능을파악해보겠습니다.")띄어쓰기 없이 작성된 텍스트입니다. 키위 형태소 분석기의 띄어쓰기 성능을 파악해 보겠습니다.- 리뷰에서 비교적 의미를 가지는 특정 품사만 추출하여 워드 클라우드 생성
- 동사(VV), 형용사(VA), 일반명사(NNG)
# 첫 번째 리뷰 데이터를 가지고 간단하게 확인
rv_train[0]아 더빙.. 진짜 짜증나네요 목소리kiwi.tokenize(rv_train[0])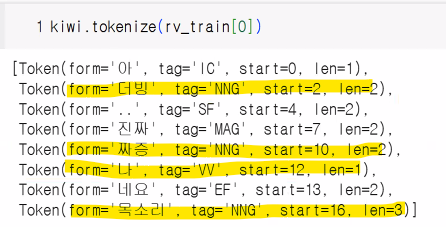
# 유의미한 품사들만 리스트에 담기
from tqdm import tqdm
from kiwipiepy.utils import Stopwords # 키위가 제공하는 불용어 사전 활용
stopwords = Stopwords()
total = []
for doc in tqdm(rv_train):
result = kiwi.tokenize(doc, stopwords=stopwords)
temp = [] # 일반 명사, 형용사, 동사만을 담아줄 리스트
for token in result:
if token.tag in ["NNG", "VV", "VA"]:
temp.append(token.form) # 토큰화된 텍스트 데이터 누적 저장
total.append(temp)
# 워드 클라우드 생성을 위하여 하나의 문자열로 변경
token_list = []
for token in total:
token_list += token # token_list.append(" ".join(token))
cnt = Counter(token_list)
cnt.most_common(40)[('영화', 58375),
('좋', 12535),
('재밌', 9031),
('있', 7438),
('연기', 7192),
('나오', 7030),
('만들', 6937),
('최고', 6634),
('평점', 6302),
('주', 5544),
('생각', 5519),
('스토리', 5350),
('드라마', 5235),
('배우', 4928),
('감동', 4877),
('나', 4772),
('가', 4342),
('내용', 4238),
('알', 4227),
('재미', 4169),
('감독', 4165),
('재미있', 3992),
('시간', 3647),
('쓰레기', 3554),
('재미없', 3427),
('사랑', 3420),
('모르', 3234),
('보이', 3043),
('작품', 2984),
('정도', 2778),
('마지막', 2736),
('액션', 2692),
('기대', 2596),
('남', 2561),
('많', 2502),
('장면', 2439),
('느끼', 2437),
('처음', 2275),
('최악', 2261),
('돈', 2260)]# 워드 클라우드 객체 생성
wc = WordCloud(
background_color="white"
, font_path="/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf"
, random_state=23
)
one_str = ' '.join(token_list)
cloud = wc.generate_from_text(one_str)
plt.imshow(cloud)
plt.axis("off")
plt.show()
- 4개의 형태소 분석기 모두 사용해보기
- kiwi 말고 나머지 3개도 써 봅시다:
# 형태소 분석기 객체 생성
kkma = Kkma()
okt = Okt()
mecab = Mecab()- 토큰화
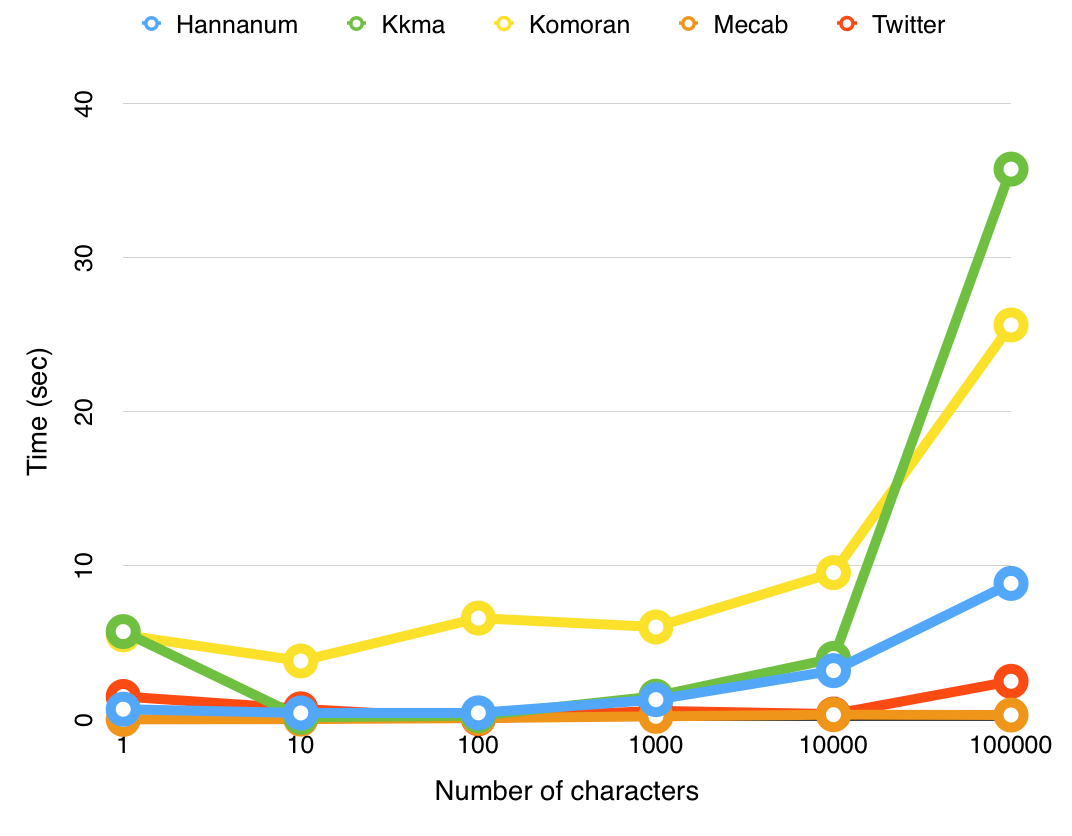
- 연산 속도: mecab(0초) - okt(10초) - kkma(15초)
# 문장 내에서 품사 분류 진행(각 형태소 분석기마다 알아서 추출)
# morphs() 함수: 입력 값을 형태소 단위로 토크나이징
kkma.morphs("아버지가 방에 들어가신다.")
# 높임을 나타내는 선어말어미 '-시-'까지 쪼갬 → 잘게 쪼개는 대신 연산 속도가 느리다.['아버지', '가', '방', '에', '들어가', '시', 'ㄴ다', '.']okt.morphs("아버지가 방에 들어가신다.")['아버지', '가', '방', '에', '들어가신다', '.']mecab.morphs("아버지가 방에 들어가신다.")['아버지', '가', '방', '에', '들어가', '신다', '.']- 품사 확인
- 형태소 분석기에 따라 결과가 다르게 나옴
- 한국어 품사 태그 비교표
# 토큰화된 단어들 품사 확인
kkma.pos("아버지가 방에 들어가신다.")[('아버지', 'NNG'),
('가', 'JKS'),
('방', 'NNG'),
('에', 'JKM'),
('들어가', 'VV'),
('시', 'EPH'),
('ㄴ다', 'EFN'),
('.', 'SF')]okt.pos("아버지가 방에 들어가신다.")[('아버지', 'Noun'),
('가', 'Josa'),
('방', 'Noun'),
('에', 'Josa'),
('들어가신다', 'Verb'),
('.', 'Punctuation')]mecab.pos("아버지가 방에 들어가신다.")[('아버지', 'NNG'),
('가', 'JKS'),
('방', 'NNG'),
('에', 'JKB'),
('들어가', 'VV'),
('신다', 'EP+EF'),
('.', 'SF')]머신러닝 기반 감성분석 ★★
토큰화, 수치화
- BOW
- 단순 카운트 기반
- TF-IDF
임베딩(Embedding): 자연어를 벡터로 바꾼 결과 → 문맥 간 의미를 파악해 수치화
예시
# 단순 카운트 기반 벡터화 도구
from sklearn.feature_extraction.text import CountVectorizer
# 객체 생성
cv = CountVectorizer()
test_list = [
"안녕하세요 저는 최영화입니다"
, "오늘 점심은 미니돈까스입니다."
, "오늘 날씨가 너무 좋아요!"
, "즐거운 월요일이지만 집에 가고 싶어요"
, "수업이 너무 재미있어요 즐거워용~"
]
# 토큰화(띄어쓰기(단어) 단위로 토큰화), 단어사전 구축
cv.fit(test_list)
# 단어사전 확인 → 띄어쓰기로 토큰화 한 후 한 개의 토큰에 1개의 인덱스 부여
cv.vocabulary_
# 문맥 무시{'안녕하세요': 6,
'저는': 10,
'최영화입니다': 16,
'오늘': 7,
'점심은': 11,
'미니돈까스입니다': 3,
'날씨가': 1,
'너무': 2,
'좋아요': 12,
'즐거운': 13,
'월요일이지만': 8,
'집에': 15,
'가고': 0,
'싶어요': 5,
'수업이': 4,
'재미있어요': 9,
'즐거워용': 14}# 단어 사전을 기반으로 벡터화
test_transform = cv.transform(test_list)
test_transform<Compressed Sparse Row sparse matrix of dtype 'int64'
with 19 stored elements and shape (5, 17)># 텍스트 데이터 벡터화 결과
test_transform.toarray()array([[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0],
[0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0]])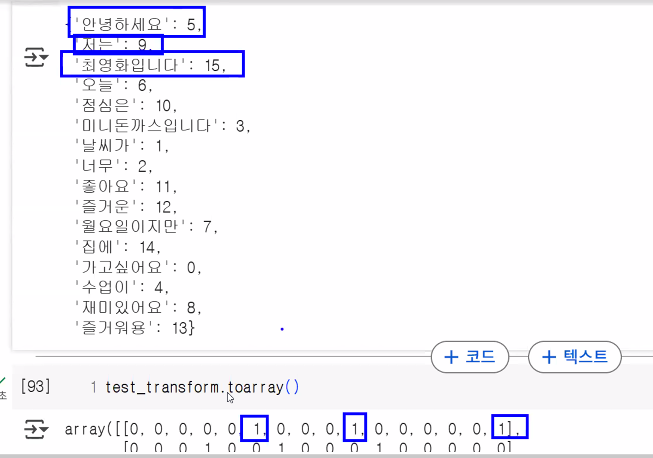
영화 리뷰 데이터 벡터화
# 'rv_cv' 이름을 가지는 벡터화 도구 생성
rv_cv = CountVectorizer()
# 단어사전 구축
rv_cv.fit(rv_train)
train_dic = rv_cv.vocabulary_
len(train_dic)
# 약 30만 개의 단어 사전 구축
# 벡터화
X_train = rv_cv.transform(text_train["document"])
X_test = rv_cv.transform(text_test["document"]) # test 데이터에만 있는 단어는 모두 0으로 처리됨- fit → 단어 사전을 구축하는 과정
- transform → 단어 사전을 바탕으로 텍스트를 수치화
- text_test는 별도의 fit 과정 없이 train으로 만들어진 단어 사전을 기준으로 transform 진행해야 함 → 왜?
- 평가 데이터를 미리 학습시키면 안 됨
- 입력 벡터의 차원이 달라질 수 있음
- train과 test의 차원이 서로 달라지면 안 됨
- 데이터 누수(평가 데이터를 확인해 버리는 실수)가 일어날 수 있음
- train에 없는 데이터가 test에 있으면 무시, 벡터에 0으로 처리됨
# 정답 데이터
y_train = text_train["label"]
y_test = text_test["label"]
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)(149995, 293366) (149995,)
(49997, 293366) (49997,)- 문제 데이터 크기:
.shape- (행, 열, ) = (문장 수, 단어 사전 수, )
- (문장의 개수, 단어사전의 길이) = (len(text_train), len(train_dic))
X_train<Compressed Sparse Row sparse matrix of dtype 'int64'
with 1074805 stored elements and shape (149995, 293366)>X_train.toarray()array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])모델링 ★★
# 분류 모델(긍정/부정) → 이진분류
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score # 교차 검증 진행 ★★★
# 모델 객체 생성
model = LogisticRegression(max_iter=1000)
# max_iter: 최대 반복 횟수 → 기본 100, 데이터가 많을 경우 제대로 학습 X
# max_iter = 1000으로 늘려서 학습
# 모델 학습
model.fit(X_train, y_train)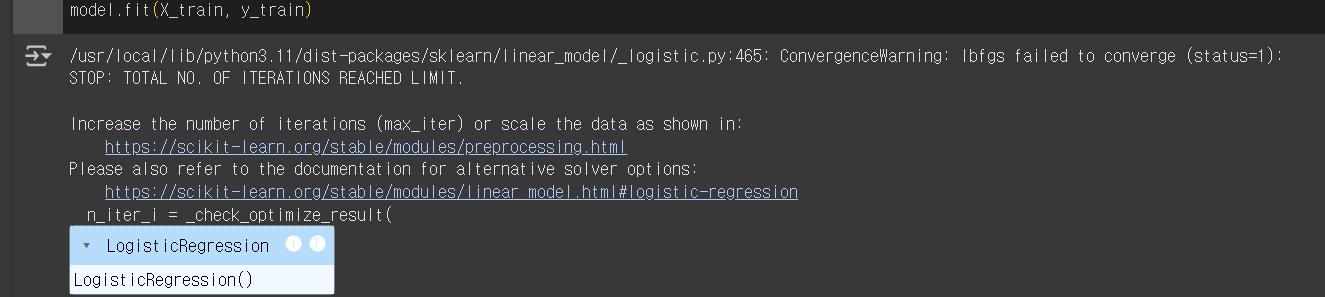
- 'max_iter: 최대 반복 횟수'의 크기가 작아 모델 학습 결과가 수렴하지 않는다는 경고 메시지
- max_iter 값을 크게 주면 해결됨(1000 정도)
# 교차검증 → 평가
cv_score = cross_val_score(model, X_train, y_train, cv=5)
cv_score, cv_score.mean()(array([0.81332711, 0.81222707, 0.8089603 , 0.80932698, 0.81622721]),
np.float64(0.8120137337911263))# 평가 → 정확도 확인~
model.score(X_test, y_test)0.814868892133528# 우리가 작성한 리뷰를 통한 확인
test = [
"즐거운 월요일 행복하고 재밌는 수업 중입니다~"
, "힘듭니다"
, "너무 좋습니다"
]
# 수치화
sample = rv_cv.transform(test)
# 0: 부정, 1: 긍정
model.predict(sample)array([1, 0, 1])실습: 스마일게이트 혐오 표현 데이터 분류
학습 목표
- 혐오 표현 데이터 전처리를 할 수 있다.
- 이모지, 인터넷 용어(ㅋㅋㅋ, ㅎㅎ 등) 등을 전처리
- TF-IDF를 활용하여 혐오 표현 데이터를 분류할 수 있다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
train = pd.read_csv("./data/unsmile_train_v1.0.tsv", sep="\t")
test = pd.read_csv("./data/unsmile_valid_v1.0.tsv", sep="\t")
train.shape, test.shape((15005, 12), (3737, 12))github에서 바로 불러오는 것도 가능합니다.
# 학습 데이터 다운로드 & 불러오기 train_url = "https://raw.githubusercontent.com/smilegate-ai/korean_unsmile_dataset/main/unsmile_train_v1.0.tsv" train = pd.read_csv(train_url, sep='\t') # 검증 데이터 다운로드 & 불러오기 valid_url = "https://raw.githubusercontent.com/smilegate-ai/korean_unsmile_dataset/main/unsmile_valid_v1.0.tsv" valid = pd.read_csv(valid_url, sep='\t')
train.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 15005 entries, 0 to 15004
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 문장 15005 non-null object
1 여성/가족 15005 non-null int64
2 남성 15005 non-null int64
3 성소수자 15005 non-null int64
4 인종/국적 15005 non-null int64
5 연령 15005 non-null int64
6 지역 15005 non-null int64
7 종교 15005 non-null int64
8 기타 혐오 15005 non-null int64
9 악플/욕설 15005 non-null int64
10 clean 15005 non-null int64
11 개인지칭 15005 non-null int64
dtypes: int64(11), object(1)
memory usage: 1.4+ MBtest.info()0초
test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3737 entries, 0 to 3736
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 문장 3737 non-null object
1 여성/가족 3737 non-null int64
2 남성 3737 non-null int64
3 성소수자 3737 non-null int64
4 인종/국적 3737 non-null int64
5 연령 3737 non-null int64
6 지역 3737 non-null int64
7 종교 3737 non-null int64
8 기타 혐오 3737 non-null int64
9 악플/욕설 3737 non-null int64
10 clean 3737 non-null int64
11 개인지칭 3737 non-null int64
dtypes: int64(11), object(1)
memory usage: 350.5+ KB이모지 제거
- 삭제하거나(replace_emoji) 글자로 바꿔서 분석에 사용(demojize) 중 선택
!pip install emoji
import emoji
emoji.demojize("DM으로 연락 바랍니다🙏🙏")DM으로 연락 바랍니다:folded_hands::folded_hands:emoji.replace_emoji("DM으로 연락 바랍니다🙏🏻🙏")DM으로 연락 바랍니다emoji.demojize("너무 재미있었어요 😊🤣😍")너무 재미있었어요 :smiling_face_with_smiling_eyes::rolling_on_the_floor_laughing::smiling_face_with_heart-eyes:emoji.replace_emoji("너무 재미있었어요 😊🤣😍")너무 재미있었어요 데이터 분리
- 문제와 정답으로 분리
X_train = train["문장"]
X_test = test["문장"]
y_train = train.loc[:, "여성/가족":"clean"].values.argmax(axis=1)
y_test = test.loc[:, "여성/가족":"clean"]
X_train.shape, y_train.shape # 머신러닝: 출력 값 1이어야 함 → 10을 1로 줄여주기((15005,), (15005, 10))y_train = train.loc[:, "여성/가족":"clean"].values.argmax(axis=1) # 최댓값을 가지는 인덱스 번호 반환
y_test = test.loc[:, "여성/가족":"clean"].values.argmax(axis=1) # 정답 데이터를 1차원으로 변경
print(y_train)
X_train.shape, y_train.shape, X_test.shape, y_test.shape[9, 6, 9, ..., 0, 8, 4]
((15005,), (15005,), (3737,), (3737,))텍스트 데이터 전처리
- 형태소 단위로 분리
- 한 글자 토큰 삭제(ㅋㅋㅋ, ㅎㅎㅎ 등)
- 기호 데이터 삭제(!, ?, ... 등)
- 이모지 제거
# 형태소 분석 도구 불러오기
!pip install konlpy
# Mecab 설치하기
!git clone https://github.com/SOMJANG/Mecab-ko-for-Google-Colab.git
!bash ./Mecab-ko-for-Google-Colab/install_mecab-ko_on_colab_light_220429.sh
from konlpy.tag import Kkma, Okt, Mecab
kkma = Kkma()
okt = Okt()
mecab = Mecab()형태소 단위로 토큰화
- okt 사용
- 어간 추출, 정규화 과정을 포함시켜 진행하면 더 좋음
okt.morphs(X_train[0])['일안하는', '시간', '은', '쉬고싶어서', '그런게', '아닐까']okt.morphs(X_train[0], norm=True, stem=True)['이다', '시간', '은', '쉬다', '그렇다', '아니다']from tqdm import tqdm
X_train_morphs = []
for doc in tqdm(X_train):
result = okt.morphs(doc, norm=True, stem=True)
X_train_morphs.append(result)100%|██████████| 15005/15005 [01:55<00:00, 129.46it/s]X_test_morphs = [] # 형태소 분리가 끝난 문장이 담길 리스트
for doc in tqdm(X_test):
result = okt.morphs(doc, norm=True, stem=True)
X_test_morphs.append(result)100%|██████████| 3737/3737 [00:25<00:00, 144.92it/s]정규 표현식 ★★★
정규 표현식(Regular Expression) 위키독스
- 한 글자 제거
- 문장 부호 제거
- 반복적인 글자 제거
예시: 전화번호를 검출하는 정규 표현식
- 추출하고 싶은 휴대폰 번호 형식을 지정
- 010-1234-5678
- 01012345678
- 010-12345678
- 0101234-5678
- 하이픈이 있거나 없거나 하는 모든 패턴을 검출해보자!
?:-(하이픈)이 있을수도 없을수도 있다 (선택적){숫자}: 숫자만큼 반복[ ]: 대괄호 안의 문자 하나와 매칭
# 정규 표현식 사용을 도와주는 라이브러리
import re
# 규칙 설정
p = re.compile("010-?[0-9]{4}-?[0-9]{4}") # ?: 앞의 문자가 존재할 수도 있고, 존재하지 않을 수도 있습니다. (문자가 0개 또는 1개)
# 해당 문자열 내에 포함되어 있는 모든 일지하는 패턴 추출
p.search("내 전화번호가 궁금하니? 내 전화번호는 010-0000-0000이야")<re.Match object; span=(22, 35), match='010-0000-0000'>p.search("내 전화번호가 궁금하니? 내 전화번호는 010-00000000야")<re.Match object; span=(22, 34), match='010-00000000'>p.search("내 전화번호가 궁금하니? 내 전화번호는 010-00000000야") # 마지막 숫자가 3개뿐이라서 작동 안 함✅ 정규 표현식 문법
| 특수 문자 | 설명 |
|---|---|
. | 한 개의 임의의 문자 (단, 줄바꿈 문자 \n 제외) |
? | 앞의 문자가 있을 수도, 없을 수도 있음 (0개 또는 1개) |
* | 앞의 문자가 0개 이상 반복됨 |
+ | 앞의 문자가 1개 이상 반복됨 |
^ | 문자열의 시작을 의미 |
$ | 문자열의 끝을 의미 |
{숫자} | 정확히 해당 숫자만큼 반복함 |
{숫자1, 숫자2} | 숫자1 이상 숫자2 이하 만큼 반복함 |
{숫자,} | 숫자 이상 반복함 |
[...] | 대괄호 안의 문자들 중 하나와 매치. 예: [abc] → a 또는 b 또는 c |
[a-z] | 소문자 알파벳 범위와 매치 |
[a-zA-Z] | 모든 알파벳과 매치 |
[^문자] | 해당 문자를 제외한 문자와 매치 |
A\|B | A 또는 B (논리적 OR) |
\\\ | 역 슬래쉬 문자 자체를 의미 |
\\d | 모든 숫자를 의미 == [0-9] |
\\D | 숫자를 제외한 모든 문자를 의미 == [^0-9] |
\\s | 공백을 의미 == [ \t\n\r\f\v] |
\\S | 공백을 제외한 문자를 의미 == [^ \t\n\r\f\v] |
\\w | 문자 또는 숫자를 의미 == [a-zA-Z0-9] |
\\W | 문자 또는 숫자가 아닌 문자를 의미 == [^a-zA-Z0-9] |
포인트:
- 파이썬에서 정규식 패턴을 문자열로 쓸 때 역슬래시를 올바르게 표현해야 합니다.
- 보통
r"\s"처럼 raw string(앞에 r을 붙임) 형식으로 쓰는 게 좋습니다.
- raw string을 쓰면 역슬래시를 두 번 안 써도 돼서 헷갈림이 적어요.
pattern = re.compile("\\s")처럼 써도 작동하지만, 추천하는 방법은re.compile(r"\s")입니다.
정리:- 공백(스페이스, 탭, 줄바꿈 등)을 찾고 싶으면 re.compile(r"\s") 사용!
✅ 정규 표현식 모듈 함수
| 함수 | 설명 |
|---|---|
re.compile() | 정규표현식을 컴파일하는 함수입니다. 패턴이 빈번하게 사용될 경우 미리 컴파일하여 속도와 편의를 높일 수 있습니다. |
re.search() | 문자열 전체에 대해 정규표현식과 매치되는지를 검색합니다. |
re.match() | 문자열의 시작 부분이 정규표현식과 매치되는지를 검색합니다. |
re.split() | 정규표현식을 기준으로 문자열을 분리하여 리스트로 반환합니다. |
re.findall() | 문자열에서 정규표현식과 매치되는 모든 경우의 문자열을 리스트로 반환합니다. 없다면 빈 리스트를 반환합니다. |
re.finditer() | 문자열에서 정규표현식과 매치되는 모든 경우의 문자열에 대한 이터레이터 객체를 반환합니다. |
re.sub() | 문자열에서 정규표현식과 일치하는 부분을 다른 문자열로 대체합니다. |
re.compile()과re.search()는 꼭 기억해 주세요.
# 패턴 생성 → 한 개의 자음이 반복되는 패턴 삭제
s = re.compile("[ㅋㅎㄷㅇㅠㅜ?.,!~><^\'\"-_)(*@ㄱ-ㅎㅏ-ㅣa-z0-9]+")
# []: 대괄호 내부에 포함된 문자 중 하나와 일치한다면
# +: 대괄호 내의 문자들이 한 번 이상 반복된다면
# ㅋㅎㄷㅇ: 하나의 자음
# 0-9, a-z, ㄱ-ㅎ: 범위를 주어 해당 데이터를 추출
s.search("안녕하세요ㅎㅎㅎ")<re.Match object; span=(5, 8), match='ㅎㅎㅎ'># cf. findall() 함수: 전체 다 찾음 (.search()는 처음 나온 것만 찾음)
s.findall("ㅋㅋㅋ알겠습니다.... *^^*")['ㅋㅋㅋ', '....', '*^^*']# 위의 패턴에 맞춰 전처리 후 깨끗한 문장 만들기
X_train_clean = []
for doc in X_train_morphs: # 형태소 단위로 분리된 데이터를 반복
temp = []
for token in doc:
if len(token)<2: # 한 글자의 데이터
continue
if s.search(token): # 제거할 패턴에 매칭이 되는지 검출
continue
temp.append(token) # 정상적인 토큰만 임시 리스트에 추가
X_train_clean.append(' '.join(temp)) # 다시 하나의 문자열로 만들어 전체 리스트에 추가
# 위의 패턴에 맞춰 전처리 후 깨끗한 문장 만들기
X_test_clean = []
for doc in X_test_morphs: # 형태소 단위로 분리된 데이터를 반복
temp = []
for token in doc:
if len(token)<2: # 한 글자의 데이터
continue
if s.search(token): # 제거할 패턴에 매칭이 되는지 검출
continue
temp.append(token) # 정상적인 토큰만 임시 리스트에 추가
X_test_clean.append(' '.join(temp)) # 다시 하나의 문자열로 만들어 전체 리스트에 추가하루 돌아보기
👍 잘한 점
- 정규 시간 안에 당일 학습 내용 복습 완료
- 지난 주 미니 프로젝트로 복습 못했던 부분 복습 완료
- 수업 시간에 대답 많이 함
👎 아쉬웠던 점
- 정보처리기사 공부도 막막한데 리눅스마스터… 신청해버렸다…
- 리눅스 하나도 모드는데 괜찮을까?
🔬 개선점
- 시험 보기 전까지는 수업 복습은 딱 필요한 부분만 하고 나머지 시간은 전부 시험 공부에 투자하기
