지난 시간 복습
- TextMining Process
- 텍스트 데이터의 구조: corpus(말뭉치) >> 문서 >> 문단 >> 문장 >> 단어 >> 형태소
- 코퍼스: 특정 목적을 위해 수집된 언어 자료의 집합
- 한국어 → 교착어 특징: 조사에 따라 의미 달라짐(단어의 어근에 접사가 붙어 문법적 의미를 나타냄)
- 분석 프로세스: 텍스트 수집 🡆 전처리 🡆 토큰화 🡆 특징 추출 🡆 데이터 분석
- 토큰화: 잘게 쪼개는 과정
- 특징 추출: 토큰화된 데이터를 숫자 형태로 바꾸는 것
- 텍스트 전처리: 용도에 맞게 텍스트를 처리
- 오탈자 제거, 띄어쓰기 교정
- 불용어 제거
- 정제: 노이즈 데이터(등장 빈도 적은 데이터, 의미 없는 특수문자 등) 삭제
- 정규화
- 어간 추출
- 표제어 추출
- 토큰화: 목적에 맞는 토큰화 도구 선택
- 특징 값 추출(특징 추출): 중요 단어 선별 → 어떻게 추출할 것인가?(토큰 조각을 어떻게 수치화하는지가 주요)
- 원핫 인코딩: 단어사전에 있으면 1, 없으면 0 → 희소 행렬 문제(연산의 증가가 너무 커짐)
- BOW: CounterVectorizer(단어 사전 내 단어가 몇 번 나왔는지 카운팅), TF-IDF(개별 문서 자주 나오는 단어는 가중치, 모든 문서 자주 나오는 단어는 패널티)
→ 단점: 순서, 문맥, 중요도 고려 X - n-gram
- 텍스트 데이터의 구조: corpus(말뭉치) >> 문서 >> 문단 >> 문장 >> 단어 >> 형태소
- 실습: 네이버 영화 리뷰 감정분석
- 워드 클라우드: 빈도 분석 → 많이 나오는 단어 크게 표시
- 다양한 형태소 분석기: Kiwi, Kkma, Okt, Mecab
- Kiwi 띄어쓰기 교정
- Kkma: 품사 태깅이 상세함 → 시간이 너무 오래 걸림
- Okt: 인터넷 용어에 강함
- Mecab: 빠름
- 토큰화: `.morphs'
- 품사 태깅된 토큰화:
.pos() - 토크나이저가 가지는 품사 종류를 확인:
.tagset- kiwi는 지원 안 함
- 머신러닝 기반 감성분석
- 입력 벡터의 크기 == 단어 사전의 크기
- fit: 단어 사전 구축 과정
- train 데이터로만!
- text_test는 train으로 만들어진 단어 사전을 기준으로 transform 진행
- 평가 데이터는 학습시키면 안 됨
- 입력 벡터의 차원이 달라질 수 있음
- 데이터 누수(평가 데이터를 확인해 버리는 실수)가 일어날 수 있음
- train에 없는 데이터가 test에 있으면 무시, 벡터에 0으로 처리됨
- 실습: 스마일게이트 혐오 표현 데이터 분류
argmax():가장 큰 숫자의 index 추출- 정답 데이터 10개의 클래스 각각 컬럼 있는 걸 하나로 합쳐줘야 하기 때문에 사용함
okt.morphs(X_train[0], norm=True, stem=True)- norm: 정규화 과정 → 표현 방법이 다른 단어들을 같은 단어로 변경
- stem: 어간 추출 → 단어의 어간을 추출(유의미한 정보만 추출)
실습: 스마일게이트 혐오 표현 데이터 분류
워드 클라우드 확인
- 한 개의 클래스만 뽑아서 워드 클라우드 만들기
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 텍스트 데이터 기준으로 레이블 연결
df_wc = pd.DataFrame({'text':X_train_clean, 'label':y_train})
# 워드 클라우드 객체 생성
wc = WordCloud(
background_color="white"
, font_path="/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf"
, random_state=42
)
# 'clean'에 해당하는 class 9만 확인
label_9 = ' '.join(df_wc["text"][df_wc["label"]==9])
cloud_label_9 = wc.generate_from_text(label_9)
plt.figure()
plt.imshow(cloud_label_9)
plt.axis("off")
plt.show()
# 강사님 방식
# 텍스트 데이터 기준으로 레이블 연결
class_texts = {} # 딕셔너리 형태로 데이터 묶기
for label in sorted(set(y_train)):
docs = [X_train_clean[i] for i in range(len(y_train)) if y_train[i] == label]
class_texts[label] = ' '.join(docs)
# 레이블별 워드 클라우드 확인
def draw_wc (text, label_name=""):
wc = WordCloud(
font_path="/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf"
, background_color="white"
, random_state=24
)
wordcloud_img = wc.generate_from_text(text)
plt.imshow(wordcloud_img)
plt.axis("off")
plt.title(f"WordCloud - {label_name}", fontsize=16)
plt.show()
# 레이블 번호와 실제 레이블 이름 매핑
label_map = {
0: "여성/가족"
, 1: "남성"
, 2: "성소수자"
, 3: "인종/국적"
, 4: "연령"
, 5: "지역"
, 6: "종교"
, 7: "기타 혐오"
, 8: "비하"
, 9: "clean"
}
# matplotlib 한글 출력 설정
!pip install koreanize-matplotlib
import koreanize_matplotlib
# 워드 클라우드 출력
for label in class_texts:
draw_wc(class_texts[label], label_name=label_map[label])강사님 방식을 참고해 내 코드도 함수로 만들어보았음:
def plot_label_wordclouds(df_wc, wc, label_map): for label_num, label_desc in label_map.items(): texts = df_wc["text"][df_wc["label"] == label_num] if texts.empty: continue # 해당 라벨이 없으면 넘어감 label_str = ' '.join(texts) cloud = wc.generate_from_text(label_str) plt.figure() plt.imshow(cloud) plt.axis("off") plt.title(f"WordCloud: {label_desc}") plt.show()→ 잘 작동한다!
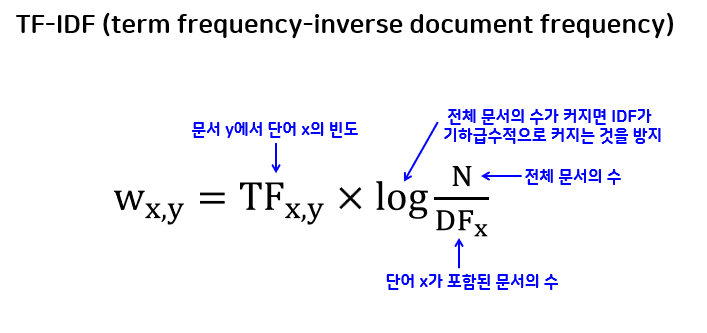
벡터화(수치화) → 특성 추출
- TF-IDF 방식 활용
from sklearn.feature_extraction.text import TfidfVectorizer
# 벡터화 도구 객체 생성
tfidf_vc = TfidfVectorizer()
# 단어사전 구축
tfidf_vc.fit(X_train_clean)
len(tfidf_vc.vocabulary_)16664# 단어사전을 기반으로 TF-IDF 수치화
vec_train = tfidf_vc.transform(X_train_clean)
vec_test = tfidf_vc.transform(X_test_clean)
# 벡터화 결과를 DataFrame으로 변환하여 출력
pd.DataFrame(
vec_train.toarray()
, columns=tfidf_vc.get_feature_names_out() # 단어사전의 단어를 컬럼으로 사용
)TF-IDF 예시
corpus = ["you know I want your love",
"I like you",
"what shoud I do",
"I love you"]
test_tfidf = TfidfVectorizer().fit(corpus)
print(test_tfidf.vocabulary_)
print(test_tfidf.transform(corpus).toarray()){'you': 7, 'know': 1, 'want': 5, 'your': 8, 'love': 3, 'like': 2, 'what': 6, 'shoud': 4, 'do': 0}
[[0. 0.49819711 0. 0.39278432 0. 0.49819711
0. 0.31799276 0.49819711]
[0. 0. 0.84292635 0. 0. 0.
0. 0.53802897 0. ]
[0.57735027 0. 0. 0. 0.57735027 0.
0.57735027 0. 0. ]
[0. 0. 0. 0.77722116 0. 0.
0. 0.62922751 0. ]]vec_result = test_tfidf.transform(corpus).toarray()
pd.DataFrame(
vec_result
, columns = test_tfidf.get_feature_names_out() # 단어사전의 단어를 컬럼으로 사용
) do know like love shoud want what you your
0 0.00000 0.498197 0.000000 0.392784 0.00000 0.498197 0.00000 0.317993 0.498197
1 0.00000 0.000000 0.842926 0.000000 0.00000 0.000000 0.00000 0.538029 0.000000
2 0.57735 0.000000 0.000000 0.000000 0.57735 0.000000 0.57735 0.000000 0.000000
3 0.00000 0.000000 0.000000 0.777221 0.00000 0.000000 0.00000 0.629228 0.000000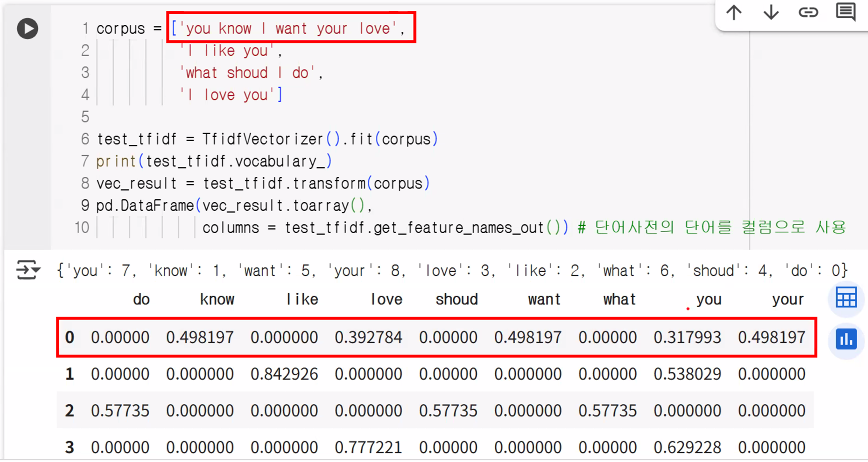
모델 학습 및 예측
# 모델 생성 → LogisticRegression
from sklearn.linear_model import LogisticRegression
# 교차 검증
from sklearn.model_selection import cross_val_score
# 모델 학습
model = LogisticRegression(max_iter=1000)
model.fit(vec_train, y_train)
# 교차검증
cv_score = cross_val_score(model, vec_train, y_train, cv=5)
cv_scorearray([0.60013329, 0.58413862, 0.58613795, 0.57580806, 0.58447184])cv_score.mean()np.float64(0.5861379540153282)# 평가
model.score(vec_test, y_test)0.6157345464276157BOW는 문맥적 의미를 반영하지 않음 & 딥러닝 모델이 아닌 머신러닝 모델을 사용해 0.6 정도만 나옴
(완전하게 좋은 방식은 아님)
Word2Vec
- 단어 간 유사도 확인
- Korean Word2Vec
- 단어의 효율적인 의미 추정 기법(Word2Vec 알고리즘)을 우리말에 적용해 볼 수 있음
- 한국어 단어에 대해서 벡터 연산을 해볼 수 있는 사이트
- Korean Word2Vec
학습 목표
- 워드임베딩 과정 이해
- 워드임베딩 도구 중 하나인 Word2Vec 이해
워드임베딩(WordEmbedding)
- 단어를 벡터화하는 과정
- 벡터화: 의미를 가지는 수치화된 값으로 변경하는 과정 (수치화보다 더 상세)
- 텍스트 데이터 분석을 위하여 "의미적 유사성"이 반영된 벡터화로 변경하는 과정
- 워드투벡터(Word2Vec)
- 워드임베딩 중 하나
- 단어끼리의 유사도 확인
앞으로 진행될 내용:
- Word2Vec, Doc2Vec → WordEmbedding
- Transformer
- LangChain
- 시계열 음성 데이터: 악보 예측 등
- Agentic AI
Word2Vec
- 단어(Word) 단위를 임베딩하는 방법 중 하나
- 개별 단어를 벡터화
- 단어 간 유사도 계산
- 예: man - king : woman - ?
- ? → queen
- Word2Vec 도구 설치
- Gensim 라이브러리
- 자연어를 벡터로 변환하는데 필요한 대부분의 편의 기능을 제공하고 있는 라이브러리
- 설치 후 세션 다시 시작해야 함
- Gensim 라이브러리
!pip install gensim실습: 네이버 쇼핑 리뷰
import numpy as np
import pandas as pd
data = pd.read_csv("./data/naver_shopping.txt", delimiter="\t", header=None)
data.columns = ["평점", "리뷰"]
data.head() 평점 리뷰
0 5 배공빠르고 굿
1 2 택배가 엉망이네용 저희집 밑에층에 말도없이 놔두고가고
2 5 아주좋아요 바지 정말 좋아서2개 더 구매했어요 이가격에 대박입니다. 바느질이 조금 ...
3 2 선물용으로 빨리 받아서 전달했어야 하는 상품이었는데 머그컵만 와서 당황했습니다. 전...
4 5 민트색상 예뻐요. 옆 손잡이는 거는 용도로도 사용되네요 ㅎㅎdata.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200000 entries, 0 to 199999
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 평점 200000 non-null int64
1 리뷰 200000 non-null object
dtypes: int64(1), object(1)
memory usage: 3.1+ MB텍스트 데이터 전처리
- 형태소 분석기를 통하여 품사별 데이터 토큰화 (Kiwi)
- 품사를 지정하여 명사, 동사, 형용사 추출
- Kiwi : 지능형 한국어 형태소 분석기(Korean Intelligent Word Identifier)
- Python3 Wrapper: Kiwipiepy, Python용 Kiwi 패키지
- 품사 태그는 여기에서 확인
- Python3 Wrapper: Kiwipiepy, Python용 Kiwi 패키지
# 키위 라이브러리 불러와서 객체 생성
from kiwipiepy import Kiwi
kiwi = Kiwi()
from kiwipiepy.utils import Stopwords
stopwords = Stopwords()
from tqdm import tqdm
text = data["리뷰"]
# 리뷰 데이터에서 유의미한 결과를 가지는 품사 3개(명사, 동사, 형용사) 추출
total = []
for doc in tqdm(text):
tokens = kiwi.tokenize(doc, stopwords=stopwords) # 형태소 단위 분리 → 품사 태깅
temp = []
for token in tokens:
if token.tag in ["NNG", "VV", "VA"]:
temp.append(token.form) # 토큰화된 텍스트 데이터 누적 저장
total.append(temp)100%|██████████| 200000/200000 [06:34<00:00, 507.32it/s]Word2Vec
- Gensim: 워드 임베딩을 위한 파이썬 라이브러리
- 자연어 처리를 위한 모델을 쉽게 구현할 수 있도록 모델 제공, 지원
- 대규모 텍스트 데이터를 처리하고 벡터화하는 데 최적화 된 라이브러리
- Word2Vec, Doc2Vec 사용
- 토큰화된 데이터를 가지고 Word2Vec을 거쳐 벡터화 진행
# 원본 데이터와 작업 후 데이터 비교
print(data.head())
print(total[:5]) 평점 리뷰
0 5 배공빠르고 굿
1 2 택배가 엉망이네용 저희집 밑에층에 말도없이 놔두고가고
2 5 아주좋아요 바지 정말 좋아서2개 더 구매했어요 이가격에 대박입니다. 바느질이 조금 ...
3 2 선물용으로 빨리 받아서 전달했어야 하는 상품이었는데 머그컵만 와서 당황했습니다. 전...
4 5 민트색상 예뻐요. 옆 손잡이는 거는 용도로도 사용되네요 ㅎㅎ
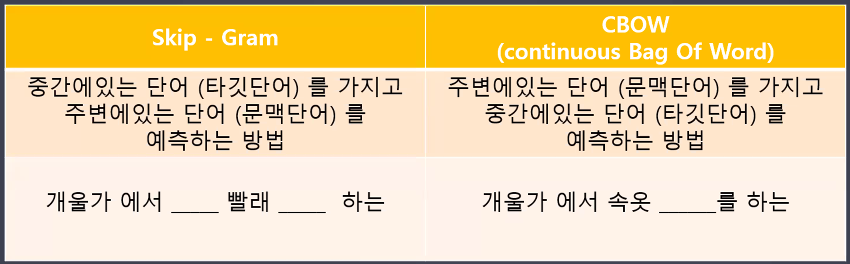
[['배공빠르고', '굿'], ['택배', '엉망', '집', '밑', '층', '놔두', '가'], ['좋', '바지', '좋', '구매', '가격', '박', '바느질', '편하', '가성비', '최고'], ['선물', '전달', '상품', '컵', '오', '당황', '전화', '주', '배송', '누락', '확인', '선물', '큰일', '나', '배송', '걸리', '생각'], ['민트', '색상', '예쁘', '옆', '손잡이', '용도', '사용']]- Word2Vec의 두 가지 방식: 의미적 유사성을 어떻게 볼 것인가?
- CBOW: 주변 단어를 활용하여 중심 단어 예측
- Skip-gram: 중심 단어를 활용하여 주변 단어 예측
- word embedding과 word2vec
- Word embedding
- 사람이 사용하는 자연어를 컴퓨터가 이해할 수 있는 숫자의 나열 형태인 밀집 벡터(dense vector)로 변환하는 방법
- 임베딩 벡터(Embedding vector): 워드 임베딩을 통해 나온 밀집 벡터
- 임베딩 벡터를 구성하기 위한 모델: word2vec, GloVe, fasttext
- Word2vec
- 2013sus google researcher 팀이 논문으로 발표
- 2가지 형태 제시
- Continuous Bag-of-words Model(CBOW)
- Continuous Skip-gram Model(Skip-gram)
- 입력 벡터의 가중합을 평균내는 CBOW에 비해 skip-gram 성능이 더 좋음
- 대표적인 Self supervised learning 방법 중 하나
- Word embedding
# 임베딩 모델 불러오기
from gensim.models import Word2Vec
w2v = Word2Vec(
window=3 # 중심 단어 기준 앞뒤 학습할 단어의 수
, sg=1 # skip-gram: 1, CBOW: 0 (skip-gram 사용할 경우 1로 설정)
, vector_size=50 # 임베딩할 벡터의 크기 → 한 단어를 50차원의 벡터로 변환하겠다는 의미
, sentences=total # 학습할 문장 데이터 → 토큰화해서 담아 둔 total
)
# 한 단어의 벡터 확인
w2v.wv.get_vector("택배") # 벡터 형태로 출력됨을 확인(벡터 크기는 사용자가 지정)array([ 0.9393262 , -0.09928488, 0.15836957, 0.37824717, 0.24986461,
0.122871 , 0.05666041, 1.4834561 , -0.33922613, 0.04195247,
-0.3393438 , -0.1590156 , 0.5056061 , 0.06158517, 0.28427163,
0.61351514, 0.12612882, 0.19897623, -0.576398 , -0.3844005 ,
-0.02390574, -0.45188367, 0.4180767 , 0.7247626 , -0.1109901 ,
-0.20051262, -0.46404058, 0.4862995 , -0.47010696, -0.33342066,
-0.69808537, -0.45066056, -0.00205645, -0.20656696, -0.13575077,
0.20901485, 0.6762187 , 0.4681133 , 0.43147212, -0.46927512,
0.25414446, 0.16842708, 0.6905566 , -0.2288075 , 0.89036274,
-0.75571054, 0.18386365, -0.8763067 , -0.2243519 , -0.3721438 ],
dtype=float32)
# 유사도가 비슷한 단어 출력
w2v.wv.most_similar("택배", topn=5)[('회사', 0.7998321652412415),
('물류', 0.7885609865188599),
('배달', 0.7834726572036743),
('거래', 0.7787017226219177),
('천일', 0.7777529954910278)]시각화: 네트워크 그래프
!pip install pyvis
from pyvis.network import Network
from IPython.display import HTML
keyword = "배송"
network_keyword = w2v.wv.most_similar(keyword, topn=20)
net = Network(notebook=True, cdn_resources="in_line")
net.add_node(keyword, shape="database", color="#FFE400") # 메인 키워드 노드 추가
for word, sim in network_keyword :
net.add_node(word, shape="box", color="#A566FF") # word2vec을 이용해 도출한 연관단어 추가
net.add_edge(word,keyword, value=sim) # 메인키워드와 연관단어의 연관성을 연결
net.save_graph("my_gragh.html")
HTML(filename="my_gragh.html")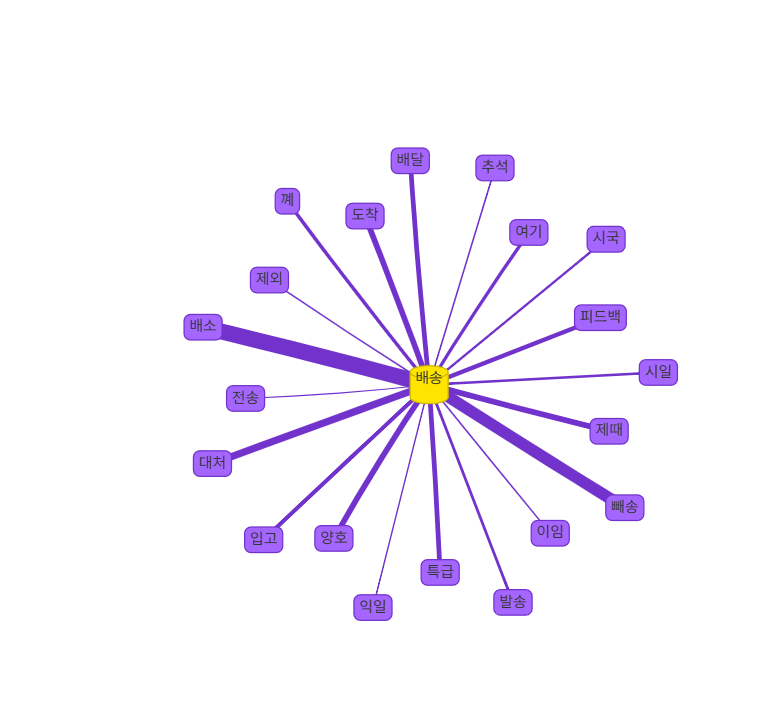
실습: Word2Vec을 이용한 음악 추천
# 데이터 업로드
import json
with open ("./data/train.json", "rb") as f:
data = json.load(f)
# train.json: 노래들을 담은 플레이리스트 데이터
# song_meta.json: 노래에 대한 정보
len(data)115071- tag: 해당 플레이리스트의 주제를 나타내는 키워드
- id: 플레이리스트를 구분하는 고유 id
- plylst_title: 플레이리스트의 제목
- songs: 곡의 목록(숫자로 표현)
# 노래 데이터만 추출하여 숫자 형태의 데이터를 문자 형태로 변환 후 Word2Vec 학습을 진행하자!
play_list = []
for s in tqdm(data):
songs = np.array(s["songs"], dtype="str") # 숫자 → 문자: Word2Vect 학습을 위해
play_list.append(list(songs))100%|██████████| 115071/115071 [00:08<00:00, 13532.23it/s]# w2v 학습시키기
# music_w2v: 앞뒤 3단어 참고, skip_gram 방식 사용, 벡터 크기 50, 데이터 ?
music_w2v = Word2Vec(
window=3
, sg=1
, vector_size=50
, sentences=play_list
)- 메타 데이터를 사용해 실제 어떤 노래인지 확인
- 유사도 → 같은 플레이리스트에 자주 등장하는 곡 == 유사한 곡 (취향이 비슷한 곡)
- 벡터 거리를 가깝게 학습: 사람들이 비슷한 플레이리스트에 수록 → 패턴 학습
# 음악 메타 데이터 불러오기
with open("./data/song_meta.json", "rb") as f:
song_meta = json.load(f)
# 음악 메타 데이터: 음악에 대해 설명해주고 있는 데이터
# 각 음악에 대해서 상세한 정보를 담고 있음
print(song_meta[14]["id"])
print(song_meta[14]["song_name"])14
Knock You Out- song_meta의 id 값과
song_name을 활용하여 음악의 유사도를 판단 후 추출

# 노래 id와 노래 제목(song_name)을 서로 변환할 수 있도록 매핑
# 두 개의 딕셔너리 생성: 1. id: song_name 2. song_name:id
id2song, song2id = {}, {}
for song in song_meta:
id2song[song["id"]] = song["song_name"] # id를 song_name과 매칭
song2id[song["song_name"]] = song["id"] # song_name을 id와 매칭
# Word2Vec 모델 학습, 유사도 계산 → id
# 추천 결과로 나온 id를 통해 사람이 알 수 있는 곡명(노래 제목)으로 출력해주기 위함- 딕셔너리 컴프리헨션으로도 가능
id2song = {song["id"]:song["song_name"] for song in song_meta}
song2id = {song["song_name"]:song["id"] for song in song_meta}# 내가 원하는 노래 검색 → id
song_keys = song2id.keys()
keyword = "그남자 그여자"
# 전체 노래 제목을 반복
for key in song_keys:
if keyword in key:
print(key, song2id[key])
print("검색 끝")그남자 그여자 698986
그남자 그여자 (바이브) 548656
그남자 그여자 (Remix Ver.) 676107
검색 끝# id → 유사도 검색 → id → 노래 제목
find_song_id = 548656
result = music_w2v.wv.most_similar(
str(find_song_id) # 단어 유사도 계산(Word2Vec)이므로 문자열로 변환해야 함
, topn = 15
)
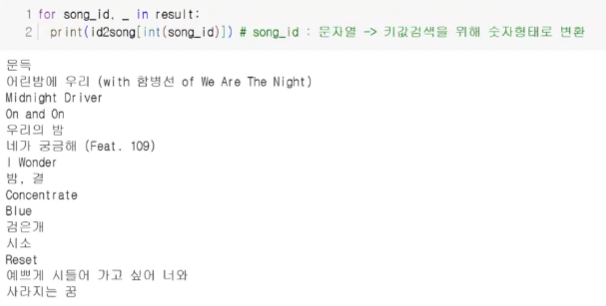
for song_id, _ in result:
print(id2song[int(song_id)]) # song_id: 문자열 → 키 값 검색을 위해 숫자 형태로 변환거짓말이야
여러분
Tears
사랑이 이런거였니
어느 소녀의 사랑이야기
사랑남녀 (Feat. 태인)
사랑에 취해 (Feat. 주석)
마리아 (Live) (미녀는 괴로워)
Never Say Goodbye (라라의 스타일기 中)
Super Star
끌려
산골소년의 사랑이야기
순애보
내 오랜 그녀와 해야 할 일
Live Wire다른 곡으로도 해 보기!
실습: Doc2Vec
- Word2Vec: 단어 간 유사도
- Doc2Vec: 문서 간 유사도
- 하나의 문서 == 하나의 댓글
Doc2Vec 실습
- Doc2Vec: 문서 간의 유사도를 계산하여 고정된 크기의 벡터로 변환하는 도구
- 문서 간의 유사도를 포함하여 학습
- 활용 예시
- 뉴스 기사 → 비슷한 기사 추출
- 리뷰 → 비슷한 감성의 리뷰 추출
- 영화 줄거리 → 영화 추천
data = pd.read_csv("./data/naver_shopping.txt", delimiter="\t", header=None)
data.columns = ["평점", "리뷰"]
# Doc2Vec 진행을 위해 사전 작업 필요
# 문서마다 고유 ID를 태깅 → 인덱스 값 매칭
# 라이브러리 불러오기
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from gensim.utils import simple_preprocess
# 문서마다 고유 ID 태깅
tagged_data = [
TaggedDocument(words=simple_preprocess(doc), tags=[i])
for i, doc in enumerate(data["리뷰"])
]- TaggedDocument: 문서와 문서 ID를 태깅(묶어줌)
- 우리 데이터에서 문서 == 댓글 1개
- 즉, 문서 == 리뷰 / 문서 ID == 리뷰 인덱스
- simple_preprocess: 간단한 전처리 도구
- 토큰화
- 특수 문자 제거
text = data["리뷰"]
tagged_data = []
# enumerate: 리스트를 순환하며 인덱스와 해당 값, 2개의 원소를 반환
for idx, rv in enumerate(text):
result = TaggedDocument(simple_preprocess(rv), [idx]) # 인덱스 번호 매칭
tagged_data.append(result)
tagged_data[:5][TaggedDocument(words=['배공빠르고'], tags=[0]),
TaggedDocument(words=['택배가', '엉망이네용', '저희집', '밑에층에', '말도없이', '놔두고가고'], tags=[1]),
TaggedDocument(words=['아주좋아요', '바지', '정말', '좋아서', '구매했어요', '이가격에', '대박입니다', '바느질이', '조금', '엉성하긴', '하지만', '편하고', '가성비', '최고예요'], tags=[2]),
TaggedDocument(words=['선물용으로', '빨리', '받아서', '전달했어야', '하는', '상품이었는데', '머그컵만', '와서', '당황했습니다', '전화했더니', '바로주신다했지만', '배송도', '누락되어있었네요', '확인안하고', '바로', '선물했으면', '큰일날뻔했네요', '이렇게', '배송이', '오래걸렸으면', '사는거', '다시', '생각했을거같아요', '아쉽네요'], tags=[3]),
TaggedDocument(words=['민트색상', '예뻐요', '손잡이는', '거는', '용도로도', '사용되네요', 'ㅎㅎ'], tags=[4])]d2v = Doc2Vec(
tagged_data
, vector_size=100
, window=5
, epochs=20
)
print("두 번째 리뷰의 벡터:\n", d2v.dv[1])두 번째 리뷰의 벡터:
[ 0.0340198 0.03873591 0.02607547 -0.06398793 0.08588135 -0.02635806
0.01955347 0.08468386 -0.06896103 -0.03613569 -0.01144601 -0.01066573
-0.04051626 0.04458256 0.02743706 -0.0386607 -0.0448806 -0.05377957
-0.01057706 -0.02621201 0.02311138 -0.00369156 0.05784164 0.05183682
-0.07613422 -0.04882483 0.05321817 0.00244164 -0.04496778 -0.06603763
-0.04075604 -0.01786816 -0.01328168 0.03894557 -0.06969234 0.00808495
-0.0081734 0.0116658 0.01742444 -0.00212821 0.10084623 0.04020555
0.0487115 0.01510361 0.05391318 0.03102955 -0.02590489 0.00290631
0.00634011 0.06745894 -0.02591064 0.05098363 0.05043837 -0.00937482
0.02486932 0.00040003 0.03215399 0.03242001 -0.04818692 -0.03914394
-0.04096085 0.02863622 -0.01211881 -0.03619497 0.01973216 0.01948936
-0.06880806 -0.03076852 -0.01481503 0.00839291 0.00643053 -0.01460526
0.05824193 0.03677118 0.02688894 0.06845522 0.03654817 0.04730884
0.01983235 0.03855741 -0.00571188 0.02192751 0.04380937 -0.00300712
-0.00917802 0.02606891 -0.02169781 0.02129749 0.01038707 0.0134828
0.01299533 -0.06384868 -0.05714686 -0.03155119 0.06105438 0.00196193
-0.00044829 -0.08822972 0.03701563 0.03972816]# 특정 리뷰의 유사 리뷰 출력하기
text[100]생각외로 모기가 안잡혀요# 위 리뷰의 유사 리뷰 출력
rs_sim = d2v.dv.most_similar(100, topn=5)
# 출력 결과: (인덱스 번호, 유사도)
# 실제 리뷰 출력
for idx, sim in rs_sim:
print(f"리뷰 인덱스: {idx}, 리뷰 내용: {text[idx]}")리뷰 인덱스: 89810, 리뷰 내용: 진동이 너무 쎄서 그런가~~모기가 들어가질 않네요
리뷰 인덱스: 79297, 리뷰 내용: 모기가 통속으로 들어가는게 미미해요 별루에요
리뷰 인덱스: 11256, 리뷰 내용: 한마리도 안들어가네요
리뷰 인덱스: 59729, 리뷰 내용: 잘모르겠어요... 저한텐 안맞는듯
리뷰 인덱스: 100963, 리뷰 내용: 주름이 잘 안잡혀요rs_sim = d2v.dv.most_similar(500, topn=5)
print(f"검색 리뷰:\n", text[500])
print("--- 유사도 검색 ---")
for idx, sim in rs_sim:
print(f"리뷰 인덱스: {idx}, 리뷰 내용: {text[idx]}")검색 리뷰:
재구매 항상 여기 쇼핑몰 이용합니다. 흑 배송비가 흑흑. . 슬퍼요. . 배송비만아니라면 최고로저렴한곳. .
--- 유사도 검색 ---
리뷰 인덱스: 18779, 리뷰 내용: 스누즈기능을 매번 알람오프 스위치로 꺼야하기 땜에 불편해서 반품할려고 하다가 배송비가 5천원이라서 걍 씀 참고하세요
리뷰 인덱스: 2206, 리뷰 내용: 좋 아요 여기서 또 구매합니다 품질대비 가격이 좋은것 같아요 그래서 ㄸ느 구매합니자 다음에 또 구매하겠습니다
리뷰 인덱스: 17052, 리뷰 내용: 재구매 재구매하는데 배송비 생각해서 4개 구매해요ㅎㅎ
리뷰 인덱스: 84995, 리뷰 내용: 늘 먹던거라 신뢰를 갖고 주문합니다.
리뷰 인덱스: 188296, 리뷰 내용: 배송비가 없으면 더 좋았겠지만 저렴히 잘샀어요.워드 임베딩(Word Embedding)
- 텍스트를 벡터화하는 과정
- 벡터화: 유의미한 결과로 수치화하는 것
- 대표적인 모델 2가지
- Word2Vec
- 단어 간 유사도를 계산하여 벡터화
- Doc2Vec
- 문서 간 유사도를 계산하여 벡터화
- 단어 임베딩도 함께 진행
- Word2Vec
- 위 두 모델의 단점
- 의미적 유사도는 반영하나 문맥을 반영하지 못함
- '배'와 '사과' / '배'와 '항구' → 사과, 배, 항구를 함께 묶어버림 → 먹는 '배'와 타는 '배'를 같은 것이라 판단하기 때문
- 문맥 반영을 못 한다는 의미는 같은 단어라도 다른 의미를 가지는 단어는 반영을 못한다는 뜻
- 배: 먹는 배, 신체 배, 운송수단 배
- 밤: 먹는 밤, 깜깜한 밤
- 눈: 신체 눈, 내리는 눈
→ 같은 글씨라서 같은 단어라고 판단: 문맥의 반영이 불가
- 의미적 유사도는 반영하나 문맥을 반영하지 못함
문맥의 의미도 함께 포함해서 학습시켜야 함! → 문맥 벡터
최신 모델들은 다 임베딩 도구까지 가지고 있어(문맥 벡터 내장) 알아서 학습함
하루 돌아보기
👍 잘한 점
- 쉬는 시간 활용해서 오늘 수업 복습 1회차 완료해서 정보처리기사 공부할 시간을 벌었음
- 수업 녹화본 올라오면 복습 2회차 돌리기
- 수업에 적극적으로 참여함
- 대답 5번 이상
👎 아쉬웠던 점
- 기껏 Colab Pro 구독해놓고 CPU로 코드 돌렸다
🔬 개선점
- 수업 시작 전에 설정 T4 GPU로 해 높기

2 B R 0 2 B