지난 시간 복습
- 워드 임베딩
- 자연어 처리를 위해 다양한 가정을 거침: 텍스트 수집 → 텍스트 전처리 → 토큰화 → 특징값 추출 → 데이터 분석
- 텍스트 데이터만의 특징: 토큰화와 벡터화
- 토큰화: 잘게 쪼개주는 작업. 주어진 코퍼스(corpus)에서 토큰(token; 보통 의미있는 단위로 토큰을 정의 → 단어, 문장, 형태소 등)이라 불리는 단위로 나누는 작업
- 수치화: 텍스트를 컴퓨터가 이해할 수 있는 숫자로 변환하는 과정
- 벡터화: 토큰화된 결과를 숫자 형태로 바꿔주는 과정. 머신러닝 모델이 텍스트에 있는 패턴을 쉽게 감지할 수 있도록 의미있는 정보를 가진 수치 표현으로 변환
- 벡터화 기본
- 의미적인 내용을 담지 못하고 단순 숫자로 변경: 원핫 인코딩, BOW: CounterVectorize, BOW: TF-IDF → 카운트 기반
- 의미적인 내용 추가하는 방법
- 워드 임베딩: 의미적 유사성 반영
- Word2Vec
- 단어간 유사도
- Doc2Vec
- 문서간 유사도
- 단어 임베딩 함께 진행
- 단점
- 의미적 유사도는 반영하나 문맥 반영 X
- BERT나 최신 모델들은 이를 보완한 임베딩 기법 사용
실습: 자연어 딥러닝 모델링
- 네이버 영화 리뷰 데이터 사용: 이진분류
학습 목표
- 자연어(텍스트) 데이터를 딥러닝 모델링(RNN)을 통하여 학습 및 결과 시각화
- 모델의 성능을 향상시키고(RNN → LSTM) 그 결과를 확인 및 비교
- 텍스트 데이터를 GPU 학습시키고 텐서 형태로 변환
복습: RNN(Recurrent Neural Network) 모델링
- 순차적인 데이터 입력
- 시계열 데이터 학습 시 사용
- 과거에 입력된 데이터와 나중에 입력된 데이터 사이의 관계를 고려
- 과거에 입력된 데이터 == 기억벡터
- cf. DNN, CNN은 공간적 내용(지역적 특성) 내포 / RNN은 기억
- 과거에 입력된 데이터 == 기억벡터
- 단어 마지막 알파벳 맞추기, 항공사 승객 수 예측 실습 진행했었음
텍스트 전처리: 토큰화, 벡터화
- 토큰화: 문장을 특정 기준에 맞춰 자르는 과정
- 글자 단위
- 단어 단위(= 띄어쓰기 단위)
- 형태소 단위: 명사, 동사, 형용사 등
- 벡터화: 잘라진 토큰을 일정 기준에 맞춰 숫자로 변경하는 과정
- 원핫 인코딩: 단순 수치화
- BOW: 단어 빈도 기반 수치화
- CounterVectorize
- TF-IDF
- 단어 사전의 수만큼 → 단일 숫자
- 워드 임베딩: 학습 기반으로 수치화하는 방법
- 단순 수치화가 아닌 단어 간/문서 간 유사도 학습을 통한 수치화
- 의미적 유사성을 학습화여 벡터화 → 유사한 단어끼리는 비슷한(가까운) 벡터
- Word2Vec
- Doc2Ved
- 벡터가 커지면 학습량이 많아짐
- 내가 설정한 수(지정해준 벡터 크기)만큼 → 문서 속 단어가 특정 크기의 벡터를 각각 가짐
추가: 단어사전(vocabulary)
- 텍스트 입력을 수치형으로 변환하기 위해서 만들
- 빈도수 기반(BOW, TF-IDF 등)이든, 임베딩 기반(Embedding)이든 모두 사전을 만들어야 함
- 차이점:
- 빈도수 기반 벡터화(BOW, TF-IDF)는 말 그대로 "사전에 있는 모든 단어"를 기준으로 각 문서에서 해당 단어가 몇 번 나왔는지(빈도), 혹은 TF-IDF 값을 계산해 벡터를 만듦 → 사전 크기(전체 단어 개수)만큼의 고정 크기 벡터를 문서별로 생성
- Embedding 기반 벡터화에서도 사전을 만듦 → 임베딩은 단어마다 고정된 차원의 벡터(예: 50차원, 100차원)를 할당해야 하기 때문에 각 단어의 고유 인덱스(사전상 위치)를 만들어서 임베딩 테이블 인덱스를 바탕으로 벡터화 진행
- BOW → 문서당 사전 크기(D) 길이의 1D 벡터 (빈도수, TF-IDF 등)
- BOW는 문서당 사전 크기만큼 고정 길이 벡터를 만듭니다.
- 문서 표현 벡터 크기: (사전 크기 D, ) — 고정 길이 1D 벡터
- 벡터 타입: 정수 또는 실수형
- Embedding → 문서의 단어 개수(N)만큼 고정 차원(embedding_dim)의 벡터를 가진 2D 텐서
- Embedding 기반은 문서에 나온 단어 수만큼의 임베딩 벡터(고정 차원)를 나열한 시퀀스를 만들어 모델에 입력합니다.
- (문서 내 단어 개수 N, 임베딩 차원 embedding_dim) — 2D 시퀀스 벡터
- 벡터 타입: 실수 벡터(embedding vector)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
train_df = pd.read_csv("./data/ratings_train.txt", delimiter="\t")
test_df = pd.read_csv("./data/ratings_test.txt", delimiter="\t")
# 결측치 제거
train_df.dropna(inplace=True)
test_df.dropna(inplace=True)
# 데이터 분리: 문제와 정답
X_train = train_df["document"]
y_train = train_df["label"]
X_test = test_df["document"]
y_test = test_df["label"]
# 텍스트 데이터 전처리: 문장을 학습용 수치 데이터로 변환(토큰화, 수치화 동시 진행)
from tensorflow.keras.layers import TextVectorization # 간단하게 텍스트 자르고 변환할 때 사용
# 벡터화 도구 생성
vectorizer = TextVectorization(
max_tokens=5000 # 사용할 최대 단어 토큰 수 (빈도수 기반)
, output_mode="int" # 빈도 기반으로 랭킹화하고 싶을 때 → 숫자로 지정
, standardize="lower_and_strip_punctuation" # 대문자를 소문자로 변경, 문장 기호 제거
, output_sequence_length=10 # 각 문장의 길이를 통일 (문장별로 토큰 10개씩만 쓰겠다는 뜻)
# 긴 문장은 10개만 사용 후 뒤 토큰은 자름, 짧은 문장은 0으로 채운다(패딩)
)output_sequence_length=10
- 왜 문장의 길이를 통일하나요?
- RNN(순환신경망) → 샘플의 수가 같은 순환 횟수를 가져야 함! (순환 횟수 통일)
- 토큰 10개 통일 → 순환 횟수를 통일하는 작업
# 벡터화 적용
vectorizer.adapt(X_train) # 훈련 데이터를 기반으로 전처리, 토큰화, 단어사전 구축
vectorizer.get_vocabulary() # 단어사전 확인: 단순 띄어쓰기 기반 토큰화가 진행된 것을 확인
# 단어사전의 수 확인
vectorizer.vocabulary_size()TensorShape([149995, 10])TenorShape([리뷰 개수, 한 리뷰의 토큰 개수])output_sequence_length=10설정했기 때문에 10개 토큰
# 벡터화 진행 → 결과 담아주기
X_train_vec = vectorizer(X_train)
X_train_vec.shape
# test 데이터 벡터화
X_test_vec = vectorizer(X_test)
X_test_vec.shapeTensorShape([149995, 10])
TensorShape([49997, 10])- 1번 문장(
X_train[0]아 더빙.. 진짜 짜증나네요 목소리)을 통한 벡터화 결과 확인- 5개의 토큰으로 분리됨 → 수치화, 문장부호 제거(strip), 5개 이후는 0으로 채워 10개 맞춤(padding)
X_train_vec[0]<tf.Tensor: shape=(10,), dtype=int64, numpy=array([ 37, 914, 5, 1, 1077, 0, 0, 0, 0, 0])>입력 데이터 형태 변경 ★★★
- 입력 텐서의 형태를 RNN 계열의 모델이 원하는(기대하는) 입력 형태로 변경
- (batch_size, time_step, input) == (sample, timesteps, features)
- batch_size: sample의 수 (한 번에 학습할 데이터의 수 → 32, 64, 128, ...)
- timestep: 반복 횟수(시퀀스 길이 - 순환횟수)
- input: 각 timestep마다 들어가는 데이터 수 (입력 벡터의 차원 수)
- (batch_size, time_step, input) == (sample, timesteps, features)
- 우리의 데이터는 (전체 배치 크기, 10, 1) 형태여야 함
# np.reshape 사용: 벡터화 결과물이 numpy=array([ 37, 914, 5, 1, 1077, 0, 0, 0, 0, 0]) 형태이기 때문
X_train_vec_reshape = np.reshape(X_train_vec, (-1, 10, 1))
X_train_vec_reshape.shape
X_test_vec_reshape = np.reshape(X_test_vec, (-1, 10, 1))
X_test_vec_reshape.shape(149995, 10, 1)
(49997, 10, 1)모델링을 위한 tensor화 및 GPU 설정
- Colab: 런타임 유형 변경 → T4 GPU
import torch
# gpu 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)cuda- NumPy ndarray 데이터를 PyTorch Tensor로 변경
- 출력층의 기대 형태는 2차원 tensor인데 현재 shape은 1차원임 → unsqueeze(-1)
X_train_tensor = torch.tensor(X_train_vec_reshape, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).unsqueeze(-1)
X_test_tensor = torch.tensor(X_test_vec_reshape, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32).unsqueeze(-1)- 데이터 배치 사이즈로 분리하기
from torch.utils.data import TensorDataset, DataLoader
# DataLoader를 위한 객체 생성
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
test_dataset = TensorDataset(X_test_tensor, y_test_tensor)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True) # shuffle=True → 무작위 추출 → 과대적합 방지
test_loader = DataLoader(test_dataset, batch_size=128) # 검증/평가용 데이터는 무작위 추출할 필요 없음1. SimpleRNN
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# RNN 모델 정의: SimpleRNN
class SimpleRNNModel(nn.Module):
def __init__(self, input_dim=1, hidden_size=64, output_dim=1):
super(SimpleRNNModel, self).__init__()
self.input_dim = input_dim
self.hidden_size = hidden_size
self.output_dim = output_dim
self.rnn = nn.RNN(input_size=input_dim, hidden_size=hidden_size, batch_first=True)
self.fc = nn.Linear(in_features=hidden_size, out_features=output_dim) # 이진분류 → 출력 1개
self.act = nn.Sigmoid() # 만약 nn.BCEWithLogitsLoss를 쓸 경우 sigmoid를 추가하지 말고, loss가 알아서 처리하게 두세요.
def forward(self, x):
output, h_n = self.rnn(x) # output: 모든 시점의 출력값
out = self.fc(output[:, -1, :])
y = self.act(out)
return y
- 이번 실습에서는 loss function으로
F.binary_cross_entropy()를 사용했기 때문에 class 정의 과정에서 반드시 activation function으로 Sigmoid를 사용해 주어야 함
F.binary_cross_entropy는 입력값 y_pred가 probability (0~1 사이)라고 가정하기 때문- 다른 실습에서 했던 것처럼
loss_func=nn.BCELoss()하고 오차 출력 부분에서loss = loss_func(y_pred, y_batch)해도 됨- 하지만 더 흔한 방식은 출력층에 활성화 함수를 적용하지 않고 linear layer를 바로 출력한 뒤
loss_func=nn.BCEWithLogitsLoss()를 사용하는 것이라고 함
학습 및 검증
# 모델 객체 생성
model_simple = SimpleRNNModel().to(device)
# 손실 함수, 최적화 함수 설정
# loss: F.binary_cross_entropy()
# optimizer: Adam, lr = 0.001
optimizer = optim.Adam(model_simple.parameters(), lr=0.001)
# 학습 파라미터 설정
n_epochs = 20
# loss, acc 저장 → 시각화
rnn_train_loss_his, rnn_train_acc_his = [], []
rnn_val_loss_his, rnn_val_acc_his = [], []
for epoch in range(n_epochs):
model_simple.train()
total_loss, correct = 0, 0
# 학습
for X_batch, y_batch in train_loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
# 모델 학습
y_pred = model_simple(X_batch)
# 오차 출력
loss = F.binary_cross_entropy(y_pred, y_batch)
# 최적화 과정
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 오차, 정확도 계신
total_loss += loss.item() # tensor 형태이기 때문에 .item() 꼭 써야 함
correct += ((y_pred>=0.5).float() == y_batch).sum().item()
train_loss = total_loss / len(train_dataset)
train_acc = correct / len(train_dataset)
rnn_train_loss_his.append(train_loss)
rnn_train_acc_his.append(train_acc)
# 검증 → test_loader
model_simple.eval()
val_loss, val_correct = 0, 0
with torch.no_grad():
for X_batch, y_batch in test_loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model_simple(X_batch)
loss = F.binary_cross_entropy(y_pred, y_batch)
val_loss += loss.item()
val_correct += ((y_pred>=0.5).float() == y_batch).sum().item()
rnn_val_loss_his.append(val_loss/len(test_dataset))
rnn_val_acc_his.append(val_correct/len(test_dataset))
print(f"epoch{epoch +1} - "
f"train loss: {train_loss:.4f}, train acc: {train_acc:.4f}")epoch1 - train loss: 0.0054, train acc: 0.5066
epoch2 - train loss: 0.0054, train acc: 0.5096
epoch3 - train loss: 0.0054, train acc: 0.5122
epoch4 - train loss: 0.0054, train acc: 0.5115
epoch5 - train loss: 0.0054, train acc: 0.5159
epoch6 - train loss: 0.0054, train acc: 0.5145
epoch7 - train loss: 0.0054, train acc: 0.5148
epoch8 - train loss: 0.0054, train acc: 0.5155
epoch9 - train loss: 0.0054, train acc: 0.5171
epoch10 - train loss: 0.0054, train acc: 0.5159
epoch11 - train loss: 0.0054, train acc: 0.5150
epoch12 - train loss: 0.0054, train acc: 0.5173
epoch13 - train loss: 0.0054, train acc: 0.5189
epoch14 - train loss: 0.0054, train acc: 0.5175
epoch15 - train loss: 0.0054, train acc: 0.5166
epoch16 - train loss: 0.0054, train acc: 0.5188
epoch17 - train loss: 0.0054, train acc: 0.5181
epoch18 - train loss: 0.0054, train acc: 0.5194
epoch19 - train loss: 0.0054, train acc: 0.5190
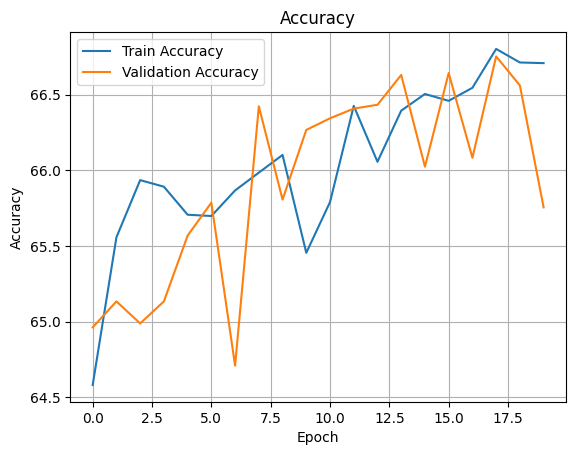
epoch20 - train loss: 0.0054, train acc: 0.5199결과 시각화
# 결과 시각화 진행
plt.figure()
plt.plot(rnn_train_acc_his, label="RNN Train Accuracy")
plt.plot(rnn_val_acc_his, label="RNN Validation Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.title("Accuracy")
plt.legend()
plt.grid()
plt.show()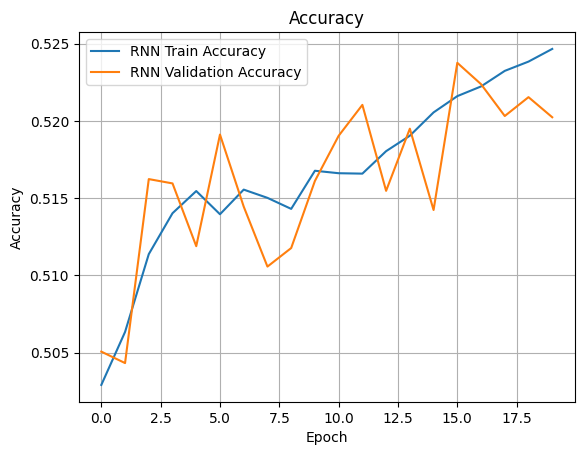
2. LSTM
-
RNN의 문제점을 극복하기 위한 대안
-
순환 횟수가 많더라도 앞에서 연산한 결과를 장기간 유지할 수 있는 '구조'가 필요 → RNN에 메모리 셀(cell) 추가
- sigmoid는 단기간 유지만 됨
-
메모리 셀(cell)
- 시각 t에서 메모리 셀(c)에는 과거로부터 현재 시각 t까지의 필요한 대부분의 정보가 저장
- 오차역전파 시 tanh와 같은 활성화 함수를 통과하지 않아 기울기 소실이 일어나지 않음
- 데이터를 LSTM 계층 내에서만 주고 받으며 다른 계층으로는 전달하지 않음
-
새로운 데이터 4개 등장:
- 메모리 셀
- forget gate
- input gate
- output gate
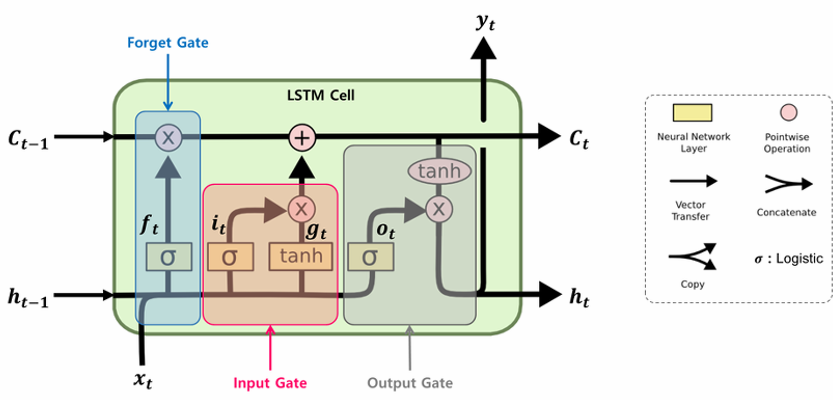
- LSTM
- RNN 모델의 장기 기억 손실의 문제점을 해결한 모델
- 장기 기억, 단기 기억을 가지며 오래 가져갈 기억과 금방 사라져도 되는 기억을 구분하여 학습
- memory cell: 장단기 기억(Long Short-Term Memory) 네트워크의 핵심 구성 요소
- LSTM 셀은 입력 게이트, 망각 게이트, 출력 게이트라는 세 가지 게이트를 사용하여 정보를 선택적으로 관리(선택적으로 기억하고 잊도록 제어) → 장기 의존성 문제를 해결하여 순환 신경망의 성능을 향상시킴
- LSTM 1개는 3개의 gates로 구성
- forget gate: 이전 상태 정보를 얼마나 버리고 얼마만큼을 저장할지 결정
- input gate: 입력되는 새로운 정보를 얼마만큼 저장할지 결정
- output gate: 현재 LSTM 셀의 어떤 부분을 다음 LSTM 셀로 전달할지 결정
class LSTMModel(nn.Module):
def __init__(self, input_dim=1, hidden_size=64, output_dim=1):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size=input_dim, hidden_size=hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_dim)
self.act = nn.Sigmoid()
def forward(self,x):
output, h_n = self.lstm(x)
out = self.fc(output[:,-1])
y = self.act(out)
return y
# 모델 객체 생성
model_lstm = LSTMModel().to(device)
optimizer = optim.Adam(model_lstm.parameters(), lr=0.001)
loss_func = nn.BCELoss()
lstm_train_loss_his, lstm_train_acc_his, lstm_val_loss_his, lstm_val_acc_his = [], [], [], []
n_epochs=20
for epoch in range(n_epochs):
model_lstm.train()
total_loss, correct = 0, 0
# 학습
for X_batch, y_batch in train_loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
# 모델 학습
y_pred = model_lstm(X_batch)
# 오차 출력
loss = loss_func(y_pred, y_batch)
# 최적화 과정
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 오차, 정확도 계신
total_loss += loss.item() # tensor 형태이기 때문에 .item() 꼭 써야 함
correct += ((y_pred>=0.5).float() == y_batch).sum().item()
train_loss = total_loss / len(train_dataset)
train_acc = correct / len(train_dataset)
lstm_train_loss_his.append(train_loss)
lstm_train_acc_his.append(train_acc)
# 검증 → test_loader
model_lstm.eval()
val_loss, val_correct = 0, 0
with torch.no_grad():
for X_batch, y_batch in test_loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model_lstm(X_batch)
loss = loss_func(y_pred, y_batch)
val_loss += loss.item()
val_correct += ((y_pred>=0.5).float() == y_batch).sum().item()
lstm_val_loss_his.append(val_loss/len(test_dataset))
lstm_val_acc_his.append(val_correct/len(test_dataset))
print(f"epoch{epoch +1} - "
f"train loss: {train_loss:.4f}, train acc: {train_acc:.4f}")epoch1 - train loss: 0.0054, train acc: 0.5218
epoch2 - train loss: 0.0054, train acc: 0.5315
epoch3 - train loss: 0.0054, train acc: 0.5326
epoch4 - train loss: 0.0054, train acc: 0.5339
epoch5 - train loss: 0.0054, train acc: 0.5343
epoch6 - train loss: 0.0054, train acc: 0.5362
epoch7 - train loss: 0.0054, train acc: 0.5378
epoch8 - train loss: 0.0054, train acc: 0.5378
epoch9 - train loss: 0.0054, train acc: 0.5408
epoch10 - train loss: 0.0054, train acc: 0.5426
epoch11 - train loss: 0.0054, train acc: 0.5432
epoch12 - train loss: 0.0054, train acc: 0.5449
epoch13 - train loss: 0.0054, train acc: 0.5460
epoch14 - train loss: 0.0054, train acc: 0.5470
epoch15 - train loss: 0.0054, train acc: 0.5472
epoch16 - train loss: 0.0054, train acc: 0.5480
epoch17 - train loss: 0.0053, train acc: 0.5480
epoch18 - train loss: 0.0053, train acc: 0.5474
epoch19 - train loss: 0.0053, train acc: 0.5490
epoch20 - train loss: 0.0053, train acc: 0.5489추가: LSTM 메모리 셀의 주요 구성 요소
- 셀 상태(Cell State):
- LSTM의 핵심이며, 과거 정보를 저장하는 역할을 합니다.
- 마치 컨베이어 벨트와 같이 정보를 다음 시간 단계로 전달합니다.
- 입력 게이트(Input Gate):
- 현재 입력과 이전 은닉 상태를 기반으로 어떤 정보를 셀 상태에 저장할지 결정합니다.
- 망각 게이트(Forget Gate):
- 이전 셀 상태에서 어떤 정보를 잊을지 결정합니다.
- 이전 정보의 중요성에 따라 정보를 선택적으로 삭제합니다.
- 출력 게이트(Output Gate):
- 현재 셀 상태에서 어떤 정보를 출력할지 결정합니다.
- 은닉 상태를 계산하고 다음 시간 단계로 전달하는 역할을 합니다.
LSTM 셀의 작동 원리:
- 망각 게이트: 이전 셀 상태(Ct-1)와 현재 입력(xt)을 기반으로 어떤 정보를 잊을지 결정합니다.
- 입력 게이트: 현재 입력(xt)과 이전 은닉 상태(ht-1)를 기반으로 어떤 정보를 셀 상태에 추가할지 결정합니다.
- 셀 상태 업데이트: 이전 셀 상태에서 망각 게이트가 결정한 정보를 삭제하고, 입력 게이트가 결정한 정보를 추가하여 새로운 셀 상태(Ct)를 생성합니다.
- 출력 게이트: 현재 셀 상태(Ct)와 현재 입력(xt)을 기반으로 어떤 정보를 출력할지 결정합니다.
- 은닉 상태 계산: 새로운 셀 상태(Ct)와 출력 게이트를 이용하여 새로운 은닉 상태(ht)를 계산하고 다음 시간 단계로 전달합니다.
LSTM의 장점:
- 장기 의존성 문제 해결:
- 기울기 소실 문제를 효과적으로 해결하여 장기적인 패턴을 학습하고 기억할 수 있습니다.
- 다양한 시퀀스 데이터 처리:
- 다양한 길이의 시퀀스 데이터를 처리하는 데 적합하며, 자연어 처리, 음성 인식, 비디오 분석 등 다양한 분야에서 활용됩니다.
# 시각화
plt.figure()
plt.plot(rnn_train_acc_his, label = 'rnn train acc')
plt.plot(rnn_val_acc_his, label = 'rnn val acc')
plt.plot(lstm_train_acc_his, label = 'lstm train acc')
plt.plot(lstm_val_acc_his, label = 'lstm val acc')
plt.grid()
plt.legend()
plt.show()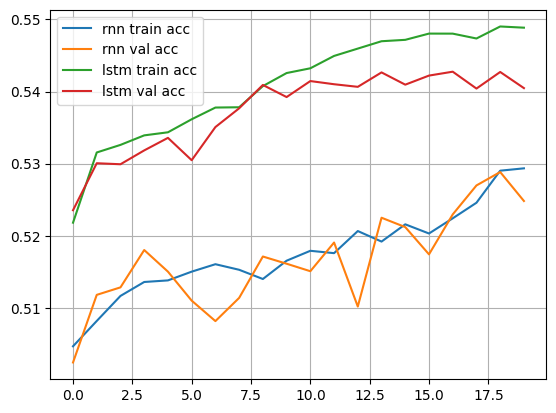
3. GRU
- LSTM 모델의 단점 중 연산 시간이 오래 걸린다는 점을 보완
class GRUModel(nn.Module):
def __init__(self, input_dim=1, hidden_size=64, output_dim=1):
super(GRUModel, self).__init__()
self.gru = nn.GRU(input_size=input_dim, hidden_size=hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_dim)
self.act = nn.Sigmoid()
def forward(self,x):
output, h_n = self.gru(x)
out = self.fc(output[:,-1])
y = self.act(out)
return y
# 모델 객체 생성
model_gru = GRUModel().to(device)
optimizer = optim.Adam(model_gru.parameters(), lr=0.001)
gru_train_loss_his, gru_train_acc_his, gru_val_loss_his, gru_val_acc_his = [], [], [], []
n_epochs=20
for epoch in range(n_epochs):
model_gru.train()
total_loss, correct = 0, 0
# 학습
for X_batch, y_batch in train_loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
# 모델 학습
y_pred = model_gru(X_batch)
# 오차 출력
loss = F.binary_cross_entropy(y_pred, y_batch)
# 최적화 과정
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 오차, 정확도 계신
total_loss += loss.item() # tensor 형태이기 때문에 .item() 꼭 써야 함
correct += ((y_pred>=0.5).float() == y_batch).sum().item()
train_loss = total_loss / len(train_dataset)
train_acc = correct / len(train_dataset)
gru_train_loss_his.append(train_loss)
gru_train_acc_his.append(train_acc)
# 검증 → test_loader
model_gru.eval()
val_loss, val_correct = 0, 0
with torch.no_grad():
for X_batch, y_batch in test_loader:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model_gru(X_batch)
loss = F.binary_cross_entropy(y_pred, y_batch)
val_loss += loss.item()
val_correct += ((y_pred>=0.5).float() == y_batch).sum().item()
gru_val_loss_his.append(val_loss/len(test_dataset))
gru_val_acc_his.append(val_correct/len(test_dataset))
print(f"epoch{epoch +1} - "
f"train loss: {train_loss:.4f}, train acc: {train_acc:.4f}")epoch1 - train loss: 0.0054, train acc: 0.5179
epoch2 - train loss: 0.0054, train acc: 0.5286
epoch3 - train loss: 0.0054, train acc: 0.5317
epoch4 - train loss: 0.0054, train acc: 0.5318
epoch5 - train loss: 0.0054, train acc: 0.5366
epoch6 - train loss: 0.0054, train acc: 0.5400
epoch7 - train loss: 0.0054, train acc: 0.5436
epoch8 - train loss: 0.0054, train acc: 0.5430
epoch9 - train loss: 0.0054, train acc: 0.5435
epoch10 - train loss: 0.0054, train acc: 0.5406
epoch11 - train loss: 0.0054, train acc: 0.5438
epoch12 - train loss: 0.0054, train acc: 0.5462
epoch13 - train loss: 0.0054, train acc: 0.5463
epoch14 - train loss: 0.0054, train acc: 0.5459
epoch15 - train loss: 0.0054, train acc: 0.5463
epoch16 - train loss: 0.0054, train acc: 0.5465
epoch17 - train loss: 0.0053, train acc: 0.5482
epoch18 - train loss: 0.0053, train acc: 0.5488
epoch19 - train loss: 0.0053, train acc: 0.5496
epoch20 - train loss: 0.0053, train acc: 0.5489# 시각화
plt.figure()
plt.plot(rnn_train_acc_his, label = "rnn train acc")
plt.plot(rnn_val_acc_his, label = "rnn val acc")
plt.plot(lstm_train_acc_his, label = "lstm train acc")
plt.plot(lstm_val_acc_his, label = "lstm val acc")
plt.plot(gru_train_acc_his, label = "gru train acc")
plt.plot(gru_val_acc_his, label = "gru val acc")
plt.grid()
plt.legend()
plt.show()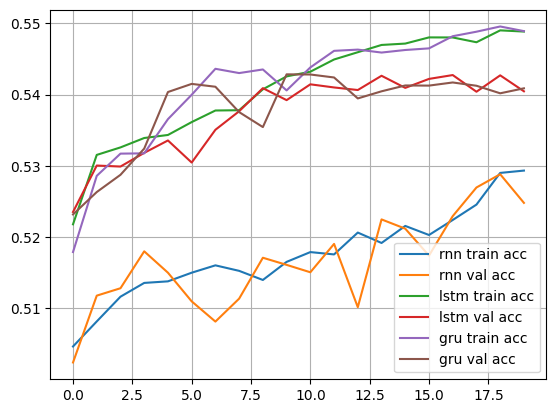
성능이 많이 향상되지는 않았음
4. 모델 정확도 개선
- Embedding Vector / Embedding Layer
- 자연어 처리에서 성능을 높이기 위한 방법이 다양하게 존재
- 모델의 구조 개선, 입력 데이터 변경 등
- 위의 RNN, LSTM, GRU 방법은 빈도수에 따른 단순 벡터화 데이터
- 워드 임베딩 기법을 활용하여 성능을 향상시켜보자!
- 단어 유사도를 통하여 학습
LSTM + Embedding
- <주의> 임베딩 데이터를 사용할 때 입력 데이터: 정수 텐서로 기대
- 정수형 64 bit → long 타입
- TextVectorizer → long() 형태로 변경해주기
# 텐서로 변환할 때 Embedding Layer가 기대하는 long 타입으로 변경
# 불필요한 차원 제거
X_train_embedding = torch.tensor(X_train_vec_reshape.squeeze(-1), dtype=torch.long)
X_test_embedding = torch.tensor(X_test_vec_reshape.squeeze(-1), dtype=torch.long)
y_train_embedding = torch.tensor(y_train.values, dtype=torch.float).unsqueeze(-1)
y_test_embedding = torch.tensor(y_test.values, dtype=torch.float).unsqueeze(-1)
# 배치 사이즈 조절
train_dataset_embed = TensorDataset(X_train_embedding, y_train_embedding)
test_dataset_embed = TensorDataset(X_test_embedding, y_test_embedding)
train_loader_embed = DataLoader(train_dataset_embed, batch_size=128, shuffle=True)
test_loader_embed = DataLoader(test_dataset_embed, batch_size=128)
class EmbeddingLSTM(nn.Module):
def __init__(
self
, vocab_size=5000 # 전체 단어사전의 크기(우리는 max_tokens=5000으로 상한선을 정했음)
, embedding_dim=50 # embedding vector의 size를 의미(한 개의 단어를 몇 차원의 벡터로 표현할 것인지 사용자가 직접 정의)
, hidden_size=64
, output_dim=1
):
super(EmbeddingLSTM, self).__init__()
# Embedding Layer 추가: 단어 간 의미 유사도 학습
self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim)
self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_dim)
self.act = nn.Sigmoid()
def forward(self, x):
x = self.embedding(x.long())
output, h_n = self.lstm(x)
out = self.fc(output[:,-1])
y = self.act(out)
return y
# 모델 객체 생성
model_em = EmbeddingLSTM().to(device)
optimizer = optim.Adam(model_em.parameters())
em_train_loss_his, em_train_acc_his, em_val_loss_his, em_val_acc_his = [], [], [], []
n_epochs=20
for epoch in range(n_epochs):
model_em.train()
total_loss, correct = 0, 0
# 학습
for X_batch, y_batch in train_loader_embed:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
# 모델 학습
y_pred = model_em(X_batch)
# 오차 출력
loss = F.binary_cross_entropy(y_pred, y_batch)
# 최적화 과정
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 오차, 정확도 계신
total_loss += loss.item() # tensor 형태이기 때문에 .item() 꼭 써야 함
correct += ((y_pred>=0.5).float() == y_batch).sum().item()
train_loss = total_loss / len(train_dataset)
train_acc = correct / len(train_dataset)
em_train_loss_his.append(train_loss)
em_train_acc_his.append(train_acc)
# 검증 → test_loader_embed
model_em.eval()
val_loss, val_correct = 0, 0
with torch.no_grad():
for X_batch, y_batch in test_loader_embed:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model_em(X_batch)
loss = F.binary_cross_entropy(y_pred, y_batch)
val_loss += loss.item()
val_correct += ((y_pred>=0.5).float() == y_batch).sum().item()
em_val_loss_his.append(val_loss/len(test_dataset))
em_val_acc_his.append(val_correct/len(test_dataset))
print(f"epoch{epoch +1} - "
f"train loss: {train_loss:.4f}, train acc: {train_acc:.4f}")epoch1 - train loss: 0.0045, train acc: 0.6692
epoch2 - train loss: 0.0037, train acc: 0.7542
epoch3 - train loss: 0.0034, train acc: 0.7706
epoch4 - train loss: 0.0033, train acc: 0.7799
epoch5 - train loss: 0.0032, train acc: 0.7857
epoch6 - train loss: 0.0032, train acc: 0.7916
epoch7 - train loss: 0.0031, train acc: 0.7971
epoch8 - train loss: 0.0030, train acc: 0.8039
epoch9 - train loss: 0.0029, train acc: 0.8099
epoch10 - train loss: 0.0028, train acc: 0.8168
epoch11 - train loss: 0.0027, train acc: 0.8232
epoch12 - train loss: 0.0026, train acc: 0.8300
epoch13 - train loss: 0.0025, train acc: 0.8363
epoch14 - train loss: 0.0024, train acc: 0.8419
epoch15 - train loss: 0.0023, train acc: 0.8482
epoch16 - train loss: 0.0022, train acc: 0.8529
epoch17 - train loss: 0.0021, train acc: 0.8578
epoch18 - train loss: 0.0020, train acc: 0.8628
epoch19 - train loss: 0.0020, train acc: 0.8661
epoch20 - train loss: 0.0019, train acc: 0.8692# 시각화
plt.figure()
plt.plot(rnn_train_acc_his, label = "rnn train acc")
plt.plot(rnn_val_acc_his, label = "rnn val acc")
plt.plot(lstm_train_acc_his, label = "lstm train acc")
plt.plot(lstm_val_acc_his, label = "lstm val acc")
plt.plot(gru_train_acc_his, label = "gru train acc")
plt.plot(gru_val_acc_his, label = "gru val acc")
plt.plot(em_train_acc_his, label = "embedding train acc")
plt.plot(em_val_acc_his, label = "embedding val acc")
plt.grid()
plt.legend(bbox_to_anchor=(1.05, 1), loc="upper left")
plt.show()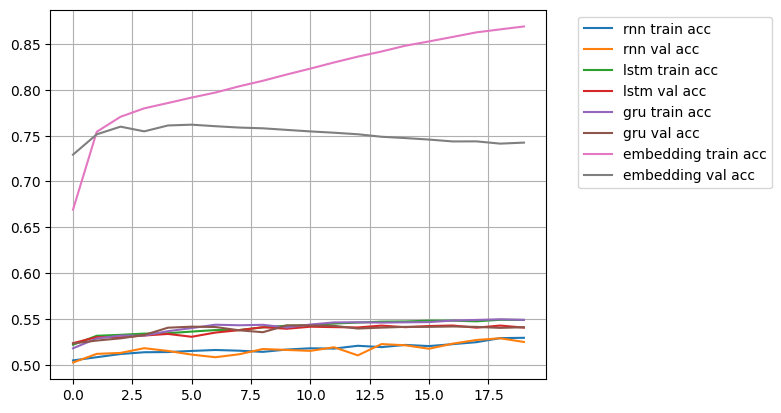
5. 임베딩 레이어 + 다층 LSTM
- 리뷰 데이터를 활용하여 임베딩 레이어 + LSTM + LSTM 층을 구성하여 학습 및 시각화
- multi-layered LSTM (Stacked LSTM)
class EmbedLSTMStacked(nn.Module):
def __init__(self, voca_size=5000, embedding_dim=50, hidden_dim=64, num_layers=2, output_dim=1):
super(EmbedLSTMStacked, self).__init__()
self.embedding = nn.Embedding(voca_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=num_layers, batch_first=True, dropout=0.2)
self.fc = nn.Linear(hidden_dim, output_dim)
self.act = nn.Sigmoid()
def forward(self,x):
x = self.embedding(x.long())
output, h_n = self.lstm(x)
out = self.fc(output[:,-1])
y = self.act(out)
return y
# 모델 객체 생성
model_stacked = EmbedLSTMStacked().to(device)
optimizer = optim.Adam(model_stacked.parameters())
stacked_train_loss_his, stacked_train_acc_his, stacked_val_loss_his, stacked_val_acc_his = [], [], [], []
n_epochs=20
for epoch in range(n_epochs):
model_stacked.train()
total_loss, correct = 0, 0
# 학습
for X_batch, y_batch in train_loader_embed:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
# 모델 학습
y_pred = model_stacked(X_batch)
# 오차 출력
loss = F.binary_cross_entropy(y_pred, y_batch)
# 최적화 과정
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 오차, 정확도 계신
total_loss += loss.item() # tensor 형태이기 때문에 .item() 꼭 써야 함
correct += ((y_pred>=0.5).float() == y_batch).sum().item()
train_loss = total_loss / len(train_dataset)
train_acc = correct / len(train_dataset)
stacked_train_loss_his.append(train_loss)
stacked_train_acc_his.append(train_acc)
# 검증 → test_loader_embed
model_stacked.eval()
val_loss, val_correct = 0, 0
with torch.no_grad():
for X_batch, y_batch in test_loader_embed:
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model_stacked(X_batch)
loss = F.binary_cross_entropy(y_pred, y_batch)
val_loss += loss.item()
val_correct += ((y_pred>=0.5).float() == y_batch).sum().item()
stacked_val_loss_his.append(val_loss/len(test_dataset))
stacked_val_acc_his.append(val_correct/len(test_dataset))
print(f"epoch{epoch +1} - "
f"train loss: {train_loss:.4f}, train acc: {train_acc:.4f}")epoch1 - train loss: 0.0044, train acc: 0.6794
epoch2 - train loss: 0.0037, train acc: 0.7548
epoch3 - train loss: 0.0034, train acc: 0.7703
epoch4 - train loss: 0.0033, train acc: 0.7789
epoch5 - train loss: 0.0032, train acc: 0.7837
epoch6 - train loss: 0.0032, train acc: 0.7892
epoch7 - train loss: 0.0031, train acc: 0.7955
epoch8 - train loss: 0.0030, train acc: 0.7999
epoch9 - train loss: 0.0029, train acc: 0.8061
epoch10 - train loss: 0.0028, train acc: 0.8127
epoch11 - train loss: 0.0027, train acc: 0.8183
epoch12 - train loss: 0.0026, train acc: 0.8242
epoch13 - train loss: 0.0025, train acc: 0.8303
epoch14 - train loss: 0.0024, train acc: 0.8345
epoch15 - train loss: 0.0024, train acc: 0.8400
epoch16 - train loss: 0.0023, train acc: 0.8439
epoch17 - train loss: 0.0022, train acc: 0.8483
epoch18 - train loss: 0.0022, train acc: 0.8517
epoch19 - train loss: 0.0021, train acc: 0.8564
epoch20 - train loss: 0.0020, train acc: 0.8594# 시각화
plt.figure()
plt.plot(lstm_train_acc_his, label = "lstm train acc")
plt.plot(lstm_val_acc_his, label = "lstm val acc")
plt.plot(em_train_acc_his, label = "embedding train acc")
plt.plot(em_val_acc_his, label = "embedding val acc")
plt.plot(stacked_train_acc_his, label = "stacked train acc")
plt.plot(stacked_val_acc_his, label = "stacked val acc")
plt.grid()
plt.legend(bbox_to_anchor=(1.05, 1), loc="upper left")
plt.show()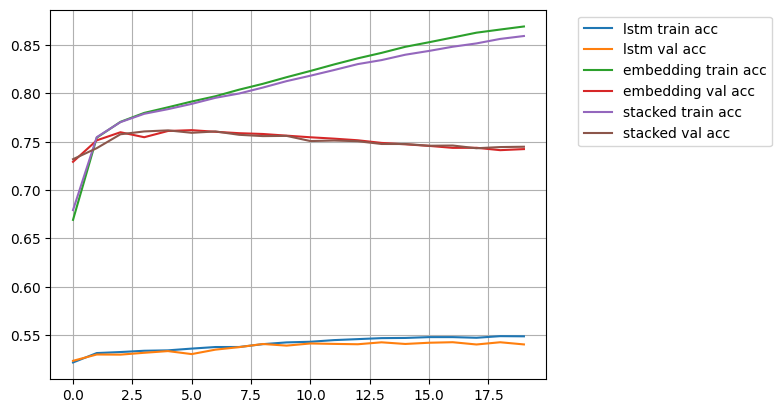
하루 돌아보기
👍 잘한 점
- 쉬는 시간 활용해서 커리어 업 시간 전에 오늘 수업 내용 1회차 복습 완료
- 수업 시간에 대답 많이 하고 질문도 했음
- '빈도수' 기반 벡터화 과정 결과물과 "Embedding" 기반 백터화 과정 결과물 차이
👎 아쉬웠던 점
- 머신러닝, DNN, CNN, RNN 내용이 뒤섞여있어서 대답할 때 많이 버벅거림
- 학습 방법을 기준으로 ML, DNN, CNN, RNN별 코드와 내용 정리하기(지난 주부터 정리 시작했는데 이것 저것 일이 많아서 아직 다 못했음)
🔬 개선점
- 복습하면서 개념 정리하고 보기 쉽게 기록해서 잊어버렸을 때나 헷랄릴 때 바로 찾아볼 수 있도록 만들기
- 8월 13일 오후에 어차피 머신러닝, 딥러닝 시험 보니까 시험 공부 한다고 생각하고 정리 진행하기

2 B R 0 2 B