목표
- 선형회귀와 로지스틱회귀 외에 자주 쓰는 알고리즘 알아보기
의사결정나무와 랜덤 포레스트
- 의사결정나무 알고리즘 알아보기
- 랜덤 포레스트 알아보기
- 데이터의 부족을 해결하기 위한 방안
의사결정나무 이론
타이타닉 생존예측 문제를 풀때, 성별에 따른 예측을 진행했던 것을 기억하시나요? 그 idea를 적용하는 것이 의사결정나무 알고리즘입니다.
의사결정나무(Decision Tree, DT)
- 의사결정규칙을 나무 구조로 나타내어 전체 자료를 몇 개의 소집단으로 분류하거나 예측을 수행하는 분석 방법
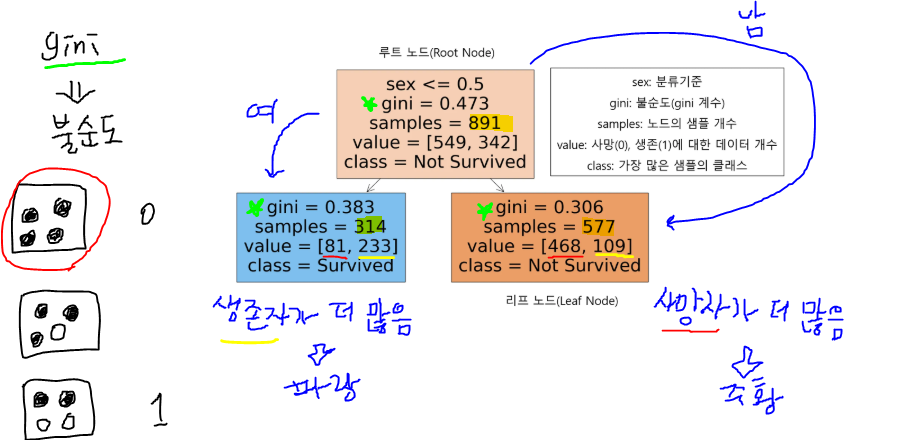
예시: 타이타닉 데이터
- 성별을 기준으로 의사결정나무 시각화

- 명칭
- 루트 노드(Root Node)
- 의사결정나무의 시작점. 최초의 분할조건
- 리프 노드(Leaf Node)
- 루트 노드로부터 파생된 중간 혹은 최종 노드
- 분류기준(criteria)
- sex는 여성인 경우 0, 남성인 경우 1로 인코딩
- 여성인 경우 좌측 노드로, 남성인 경우 우측 노드로 분류
- 불순도(impurity)
- 불순도 측정 방법 중 하나인 지니 계수는 0과 1사이 값으로 0이 완벽한 순도(모든 샘플이 하나의 클래스), 1은 완전한 불순도(노드의 샘플의 균등하게 분포) 됨을 나타냄
- 리프 노드로 갈수록 불순도가 작아지는(한쪽으로 클래스가 분류가 잘되는)방향으로 나무가 신장함(자람)
- 샘플(samples)
- 해당 노드의 샘플 개수(891개의 관측치)
- 값(value)
- Y변수에 대한 배열
- 549명이 죽었고(Y = 0), 342명이 살았음(Y = 1)
- 클래스(class)
- 가장 많은 샘플을 차지하는 클래스를 표현
- 위에서는 주황색(Y = 0 다수), 파란색(Y=1 다수)를 표현
- 루트 노드(Root Node)
실습
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier, plot_tree
titanic_df = pd.read_csv("train.csv")
X_features = ["Pclass", "Sex", "Age"]
# Pclass: LabelEncoder
# Sex: LabelEncoder
# Age: 결측치 → 평균으로 대치
le_Pclass = LabelEncoder()
titanic_df["Pclass"] = le_Pclass.fit_transform(titanic_df["Pclass"])
le_Sex = LabelEncoder()
titanic_df["Sex"] = le_Sex.fit_transform(titanic_df["Sex"])
age_mean = titanic_df["Age"].mean()
titanic_df["Age"] = titanic_df["Age"].fillna(age_mean)
X = titanic_df[X_features]
y = titanic_df["Survived"]
model_dt = DecisionTreeClassifier(max_depth=1)
model_dt.fit(X, y)
plt.figure(figsize=(10, 5))
plot_tree(model_dt, feature_names=X_features, class_names=["Not Survived", "Survived"], filled=True)
plt.show()
model_dt = DecisionTreeClassifier(max_depth=1)에서 max_depth=10으로 바꾸면 이렇게 됨
- max_depth 설정 안 하고 돌리면 돌릴 때마다 달라질 수 있다고 함 → 설정에서
random_state를 고정하면 해결!
정리
- 장점
- 쉽고 해석하기 용이
- 다중분류와 회귀에 모두 적용이 가능
- 이상치에 견고하며 데이터 스케일링이 불필요(데이터의 상대적인 순서를 고려해서)
- 단점
- 나무가 성장을 너무 많이하면 과대 적합의 오류에 빠질 수 있음
- 훈련 데이터에 민감하게 반응하여 작은 변화가 노이즈에도 나무의 구조가 크게 달라짐(불안정성)
- Python 라이브러리
sklearn.tree.DecisionTreeClassifiersklearn.tree.DecisionTreeRegressor
의사결정나무의 이론에 대해서 이해가 잘 되었나요?
하지만 의사결정나무는 단점에 있는 것처럼 나무가 성장을 너무 많이하면 과대적합의 오류에 빠질 수 있어요.
이를 보완하기 위반 방법론을 알아볼게요.
랜덤 포레스트 이론
의사결정 나무는 과적합과 불안정성 대한 문제가 대두 되었어요.
이를 해결하기 위한 아이디어는 바로 나무(tree)를 여러 개 만들어 숲(Forest)를 만드는 것이에요.
배깅(Bagging)의 원리
- 언제나 머신러닝은 데이터의 부족이 문제
- 이를 해결하기 위한 Bootstrapping + Aggregating 방법론
- Bootstrapping
- 데이터를 복원 추출해서 유사하지만 다른 데이터 집단을 생성
- Aggregating
- 데이터의 예측,분류 결과를 합치기
- Ensemble(앙상블)
- 여러 개의 모델을 만들어 결과를 합치기
- Bootstrapping
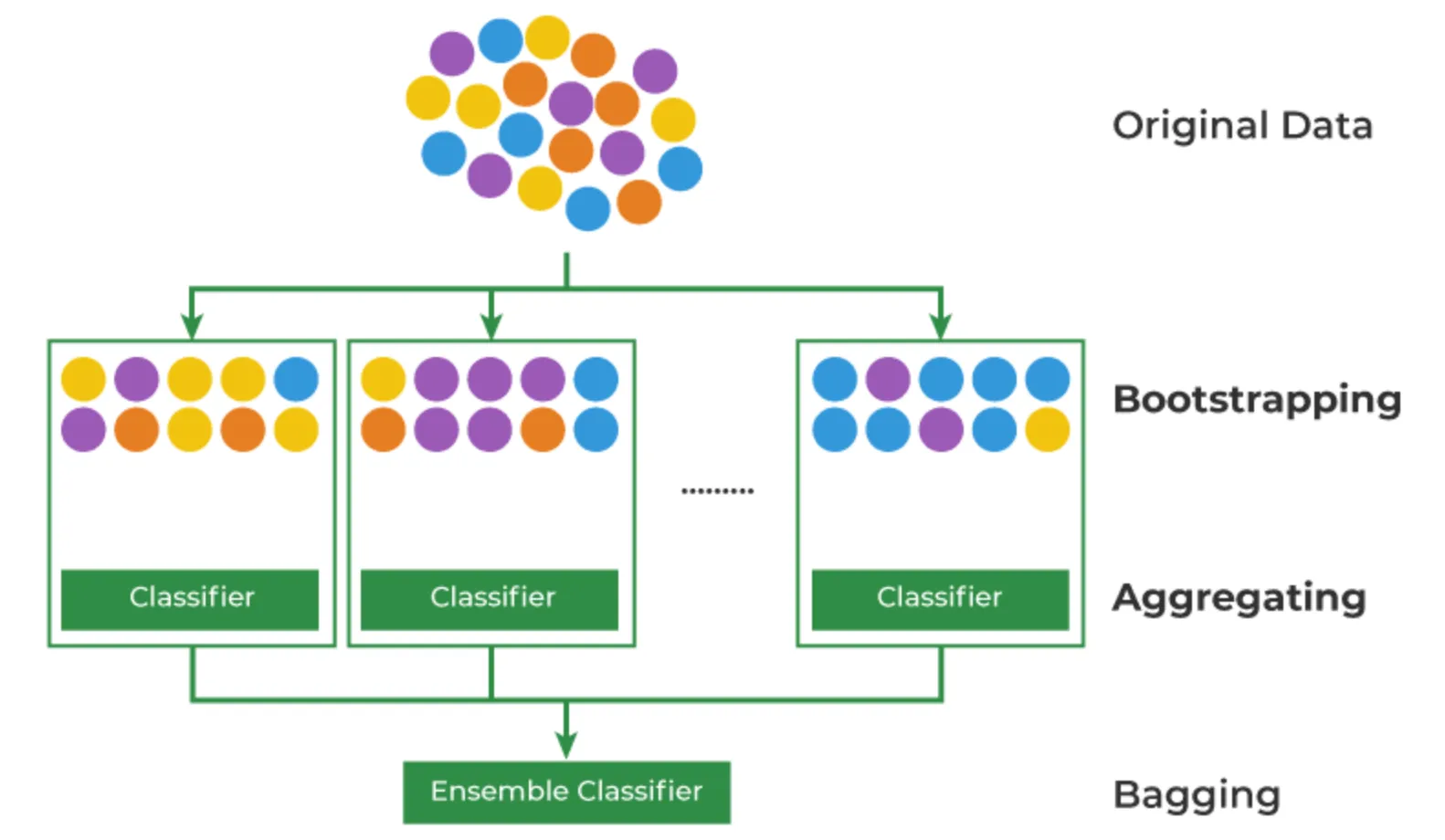
Bootstrap은 부츠 신발의 끈을 의미하고 “자기 스스로 해낸다”의 뜻의 유래를 가지고 있어요.
이를 차용하여 데이터를 복원 추출한다(→ 스스로 데이터의 부족을 해결)는 뜻을 가지게 되었고, 이렇게 생성한 데이터 샘플들은 모집단의 분포를 유사하게 따라가고 있으니 다양성을 보장하면서 데이터의 부족한 이슈를 해결하게 되었어요.
Tree를 Forest로 만들기
- 여러 개의 데이터 샘플에서 각자 의사결정트리를 만들어서 다수결 법칙에 따라 결론을 냄
(예) 1번 승객에 대해서 모델 2개는 생존, 모델 1개는 사망을 분류하였다면, 1번 승객은 최종적으로 생존으로 분류
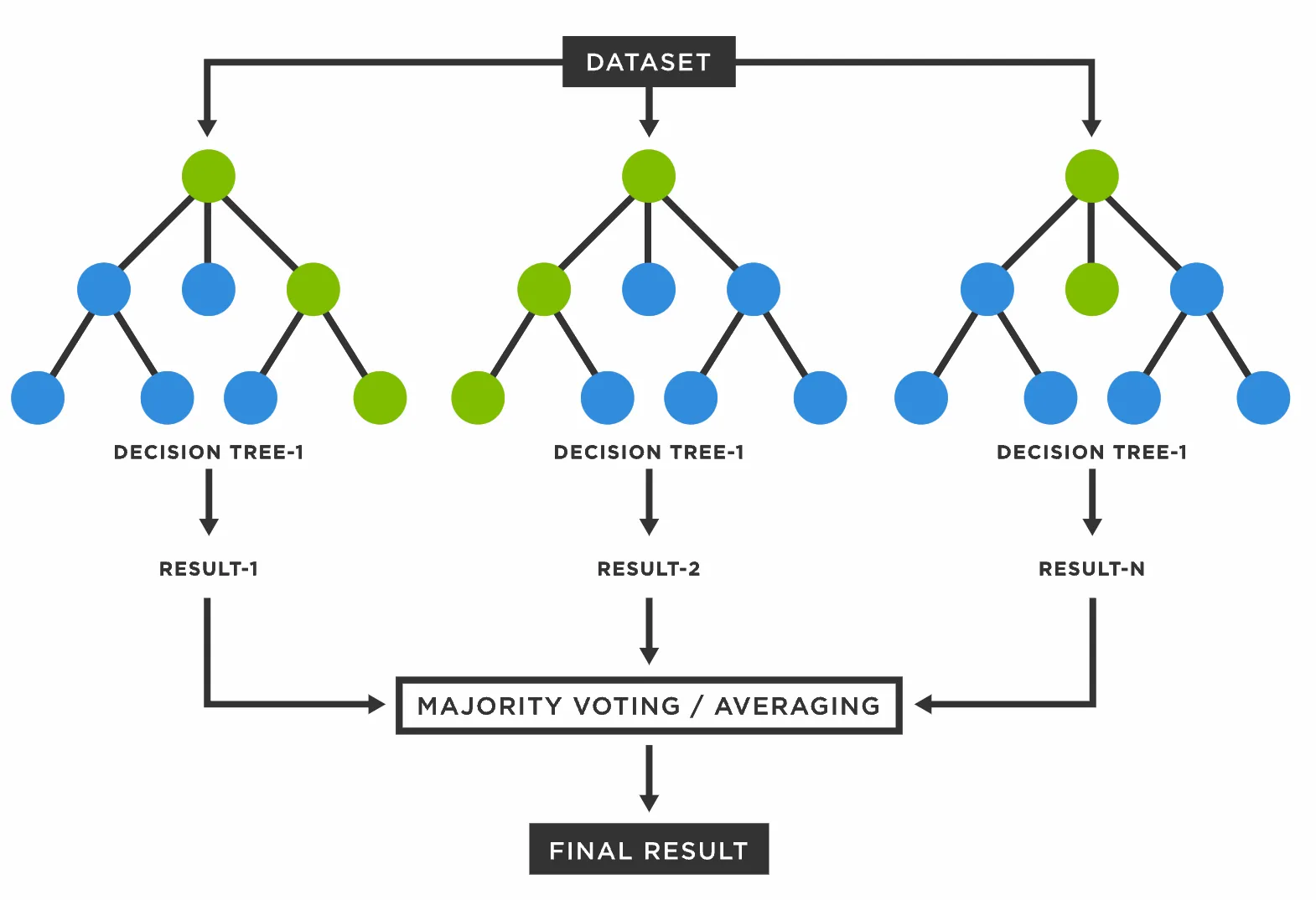
- 이로써 의사결정모델이 훈련 데이터에 민감한 점을 극복
의사결정나무의 장점은 수용하고 단점은 보완했기 때문에, 랜덤 포레스트는 일반적으로 굉장히 뛰어난 성능을 보여서 지금도 자주 쓰이는 알고리즘이랍니다.
실습
# 로지스틱회귀, 의사결정나무, 랜덤 포레스트 비교
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score
model_lor = LogisticRegression()
model_dt = DecisionTreeClassifier(random_state=42)
model_rf = RandomForestClassifier(random_state=42)
model_lor.fit(X,y)
model_dt.fit(X,y)
model_rf.fit(X,y)
y_pred_lor = model_lor.predict(X)
y_pred_dt = model_dt.predict(X)
y_pred_rf = model_rf.predict(X)
def get_score(model_name, y_true, y_pred):
acc = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"{model_name}의 acc 스코어는 {round(acc, 3)}, f1 스코어는 {round(f1, 3)}")
get_score('lor', y, y_pred_lor)
get_score('dt', y, y_pred_dt)
get_score('rf', y, y_pred_rf) → 실행 결과:
lor의 acc 스코어는 0.8, f1 스코어는 0.732
dt의 acc 스코어는 0.88, f1 스코어는 0.833
rf의 acc 스코어는 0.88, f1 스코어는 0.836
# RandomForest는 feature importances를 확인할 수 있어 좋음
model_rf.feature_importances_→ 실행 결과:
array([0.17077185, 0.40583981, 0.42338834])
🡆 각각 ['Pclass', 'Sex', 'Age']에 해당
정리
- 장점
- Bagging 과정을 통해 과적합을 피할 수 있음
- 이상치에 견고하며 데이터 스케일링이 불필요
- 변수 중요도를 추출하여 모델 해석에 중요한 특징 파악 가능
- 단점
- 컴퓨터 리소스 비용이 큼
- 앙상블 적용으로 해석이 어려움
- Python 패키지
sklearn.ensemble.RandomForestClassifersklearn.ensemble.RandomForestRegressor
최근접 이웃
- K-Nearest Neighbor(KNN) 알고리즘 알아보기
최근접 이웃 알고리즘 이론
유유상종이란 같은 집단끼리 서로 따르고 사귄다는 뜻이죠.
이와 비슷한 아이디어에서 착안한 것이 바로 K-Nearest Neighbor(KNN, KNN)입니다. 주변의 데이터를 보고 내가 알고 싶은 데이터를 예측하는 방식입니다.
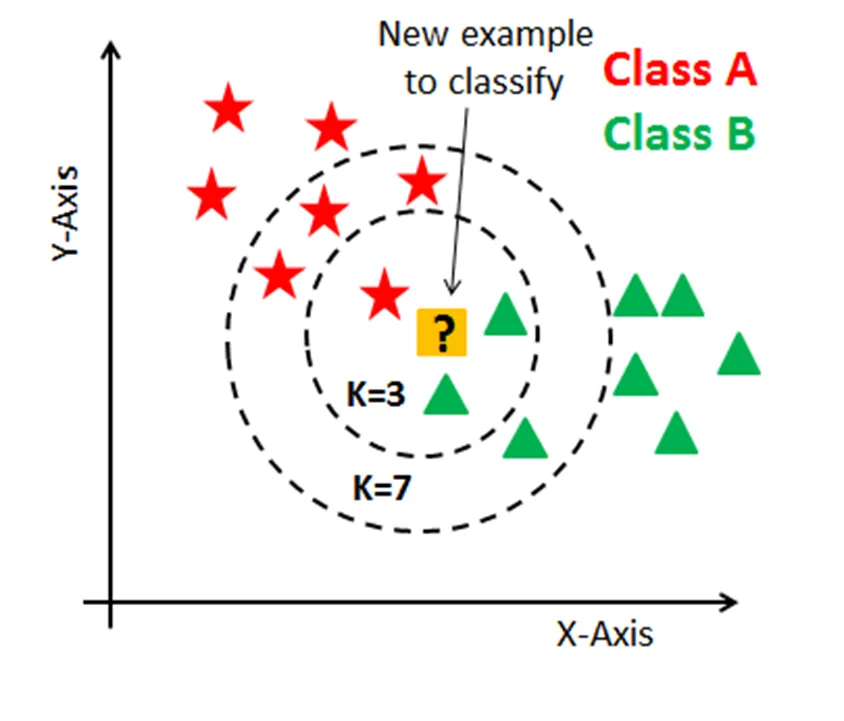
- K=3이라면 별 1개와 세모 2개이므로 ? 는 세모로 예측될 것
- K=7이라면 별 4개와 세모 3개이므로 ?는 별로 예측될 것
위와 같이 확인할 주변 데이터 K개를 선정 후에 거리 기준으로 가장 많은 것으로 예측하는 것이 바로 KNN의 기본 원리예요.
그럼 K는 몇으로 정해야 하는 걸까요? 또 거리는 어떻게 측정해야 하는 것일까요?
하이퍼 파라미터의 개념
-
파라미터(Parameter)
- 머신러닝 모델이 학습 과정에서 추정하는 내부 변수
- 자동으로 결정 되는 값
(예) 선형회귀에서 가중치와 편향
🡆 , , ,
※혼동주의※
Python에서 파라미터는 함수 정의에서 함수가 받을 수 있는 인자(입력 값)를 지정하는 개념:def 함수명 (파라미터, 파라미터)
-
하이퍼 파라미터(Hyper parameter)
- 데이터 과학자가 기계 학습 모델 훈련을 관리하는 데 사용하는 외부 구성변수 → KNN의 'K값'
- 모델 학습과정이나 구조에 영향을 미침
여기서 Data Science 학문과 연관되는 것이 바로 하이퍼 파라미터예요. 근래의 머신러닝 모델은 정확성과 동시에 복잡성이 증가해서, 왜 좋은 결과가 나왔는지 그 원리는 정확하게 파악하지 못하는 경우가 생기거든요.
이때 모델의 하이퍼 파라미터 변수를 바꾸면서 좋은 평가 지표가 나올 때까지 실험하고 원리를 밝혀내는 것이 바로 데이터 사이언스의 기반이고 과학이라는 단어가 붙은 이유랍니다.
🡆 GridSearch
거리의 개념
2차원 그래프에서 두 점의 거리를 설정하는 것은 쉬워 보입니다. 바로 직선의 거리를 구하면 됩니다. 우리는 두 점의 좌표가 주어지면 피타고라스의 정리로 거리를 구할 수 있습니다. 어려운 말로 유클리드 거리(Euclidean Distance)라고 합니다.
그 외에도 맨해튼 거리 등 다양한 거리의 계산 방법이 있습니다. 거리 개념은 머신러닝에서 데이터간의 유사도를 측정할 때 자주 등장하는 개념이니 한번 이해해봅시다.
-
유클리드 거리 공식
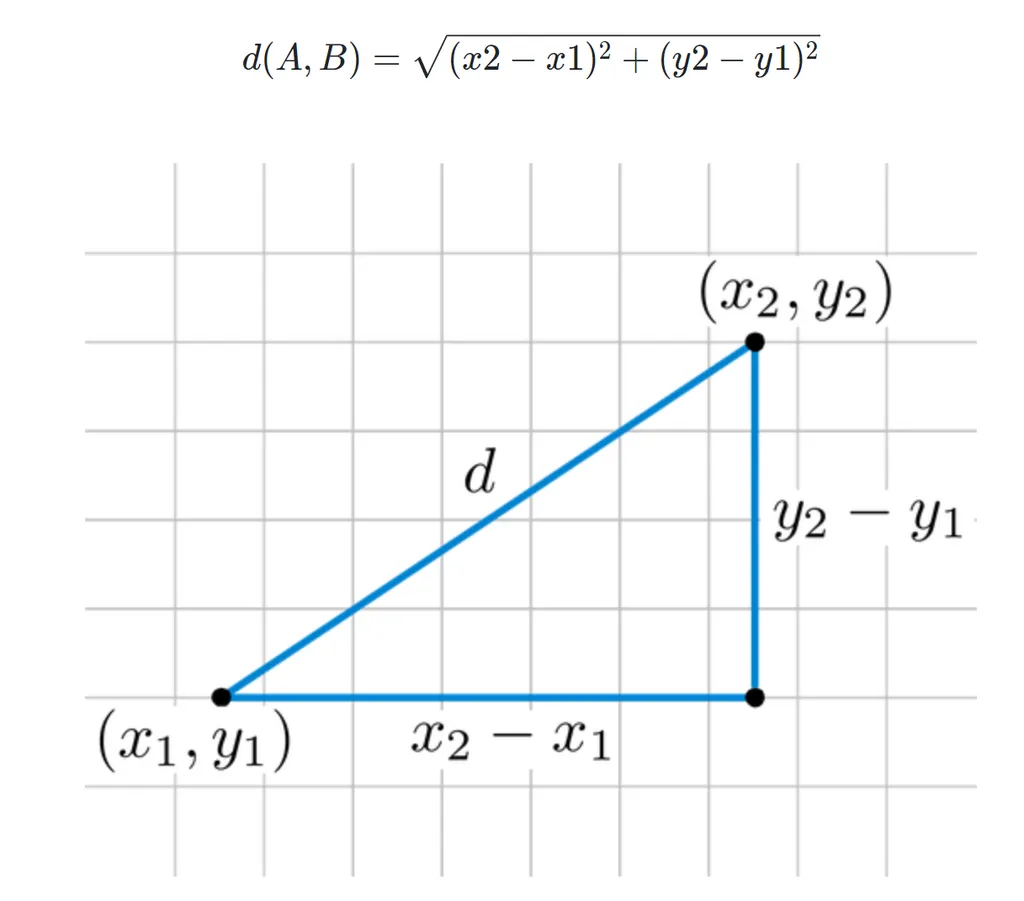
-
표준화는 필수
기본적으로 거리 기반의 알고리즘이기 때문에 단위의 영향을 크게 받습니다. 따라서 피처에 대한 표준화가 반드시 수반되어야 합니다.
이 부분은 데이터분석 프로세스 - 스케일링 부분에서 다루었으니 넘어가겠습니다!
정리
- 장점
- 이해하기 쉽고 직관적
- 모집단의 가정이나 형태를 고려하지 않음
- 회귀, 분류 모두 가능함
- 단점
- 차원 수가 많을 수록 계산량이 많아짐
- 거리 기반의 알고리즘이기 때문에 피처의 표준화가 필요함
- Python 라이브러리
sklearn.neighbors.KNeighborsClassifiersklearn.neighbors.KNeighborsRegressor
부스팅 알고리즘
- 최신 알고리즘인 부스팅 알고리즘 알아보기
부스팅 알고리즘 이론
부스팅 알고리즘 수행 방법
- 부스팅(Boosting) 알고리즘
- 여러 개의 약한 학습기(weak learner)를 순차적으로 학습하면서 잘못 예측한 데이터에 가중치를 부여하여 오류를 개선해나가는 학습 방식
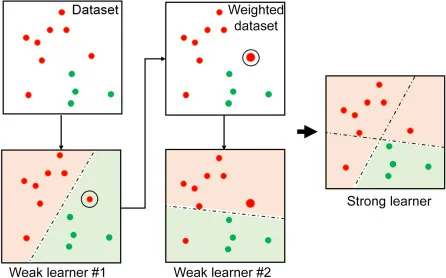
빨간색과 초록색을 분류하는 문제의 경우 1개의 선(learner)으로 구별되지 않는 경우가 있습니다.
이를 통해 여러 개의 learner를 합친 ensemble을 통해 성능을 올리는 방법입니다.
부스팅 알고리즘 종류
- Gradient Boosting Model
- 특징
- 가중치 업데이트를 경사하강법 방법을 통해 진행
- Python 라이브러리
sklearn.ensemble.GradientBoostingClassifiersklearn.ensemble.GradientBoostingRegressor
- 특징
- XGBoost
- 특징
- 트리기반 앙상블 기법으로, 가장 각광받으며 Kaggle의 상위 알고리즘
- 병렬학습이 가능해 속도가 빠름
- Python 라이브러리
xgboost.XGBRegressorxgboost.XGBRegressor
- 특징
- LightGBM
- 특징
- XGBoost와 함께 가장 각광받는 알고리즘
- XGBoost보다 학습시간이 짧고 메모리 사용량이 작음
- 작은 데이터(10,000건 이하)의 경우 과적합 발생
- Python 라이브러리
lightgbm.LGBMClassifierlightgbm.LGBMRegressor
- 특징
심화 모델 실습
- 의사결정나무와 랜덤포레스트, KNN, 부스팅을 실습해보기
- 타이타닉 데이터로딩
- 모델 적용
- 평가 & 모델별 비교
XGBoost, LightGBM 설치
!pip install xgboost
!pip install lightgbm
# 최근접 이웃, 부스팅 모델
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
model_knn = KNeighborsClassifier()
model_gbm = GradientBoostingClassifier()
model_xgb = XGBClassifier()
model_lgb = LGBMClassifier()
model_knn.fit(X,y)
model_gbm.fit(X,y)
model_xgb.fit(X,y)
model_lgb.fit(X,y)
y_pred_knn = model_knn.predict(X)
y_pred_gbm = model_gbm.predict(X)
y_pred_xgb = model_xgb.predict(X)
y_pred_lgb = model_lgb.predict(X)
get_score('lor', y, y_pred_lor)
get_score('dt', y, y_pred_dt)
get_score('rf', y, y_pred_rf)
get_score('knn', y, y_pred_knn)
get_score('gbm', y, y_pred_gbm)
get_score('xgb', y, y_pred_xgb)
get_score('lgb', y, y_pred_lgb)→ 실행 결과:
(전략 🡆 LightGBM 모델이 무조건 출력하는 정보 일람)
lor의 acc 스코어는 0.8, f1 스코어는 0.732
dt의 acc 스코어는 0.88, f1 스코어는 0.833
rf의 acc 스코어는 0.88, f1 스코어는 0.836
knn의 acc 스코어는 0.833, f1 스코어는 0.77
gbm의 acc 스코어는 0.855, f1 스코어는 0.805
xgb의 acc 스코어는 0.87, f1 스코어는 0.822
lgb의 acc 스코어는 0.862, f1 스코어는 0.812
의사결정나무 스코어 올려보기
# 의사결정나무 스코어 올려보기
X_features = ["Pclass", "Sex", "Age", "Fare", "Embarked"]
# Pclass: LabelEncoder
# Sex: LabelEncoder
# Age: 결측치 → 평균으로 대치
# Embarked: 결측치 → 최빈값으로 대치하고 LabelEncoder
le_pclass = LabelEncoder()
titanic_df["Pclass"] = le_pclass.fit_transform(titanic_df["Pclass"])
le_sex = LabelEncoder()
titanic_df["Sex"] = le_sex.fit_transform(titanic_df["Sex"])
age_mean = titanic_df["Age"].mean()
titanic_df["Age"] = titanic_df["Age"].fillna(age_mean)
# Embarked 대푯값: 최빈값이 S였음
titanic_df["Embarked"] = titanic_df["Embarked"].fillna('S')
le_embarked = LabelEncoder()
titanic_df["Embarked"] = le_embarked.fit_transform(titanic_df["Embarked"])
X = titanic_df[X_features]
y = titanic_df["Survived"]
model_lor = LogisticRegression()
model_dt = DecisionTreeClassifier(random_state=42)
model_rf = RandomForestClassifier(random_state=42)
model_lor.fit(X,y)
model_dt.fit(X,y)
model_rf.fit(X,y)
y_pred_lor = model_lor.predict(X)
y_pred_dt = model_dt.predict(X)
y_pred_rf = model_rf.predict(X)
def get_score(model_name, y_true, y_pred):
acc = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"{model_name}의 acc 스코어는 {round(acc, 3)}, f1 스코어는 {round(f1, 3)}")
get_score('lor', y, y_pred_lor)
get_score('dt', y, y_pred_dt)
get_score('rf', y, y_pred_rf)→ 실행 결과:
lor의 acc 스코어는 0.79, f1 스코어는 0.723
dt의 acc 스코어는 0.98, f1 스코어는 0.973
rf의 acc 스코어는 0.98, f1 스코어는 0.97
🡆 0.88에서 0.98로 상승
