CodeKata
SQL
126. Find Users With Valid E-Mails
- 작성한 쿼리
SELECT
*
FROM
Users
WHERE
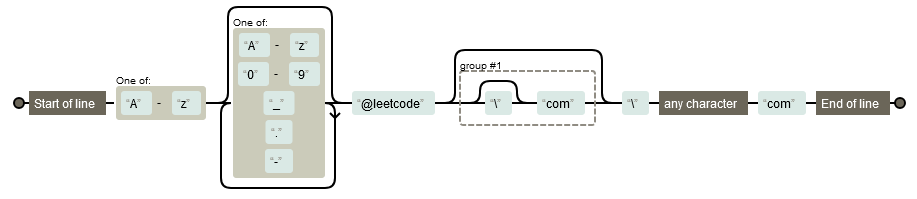
mail REGEXP '^[a-zA-Z]{1}[a-zA-Z0-9-/./_]*@leetcode[.]com$'
;→ 사용한 Pattern
^(carat): 라인의 처음이나 문자열의 처음$(dollar): 라인의 끝이나 문자열의 끝[](bracket)- 문자의 집합이나 범위를 나타냄
- 두 문자 사이의 범위는 "-" 사용
[]내에서 "^"이 선행되면 not을 나타냄
e.g.
^[a-zA-Z]: 영문자로 시작하는 문자열
[A-Za-z0-9]: 모든 알파벳과 숫자
-
{}(brace): {}내의 숫자는 직전의 선행문자가 나타나는 횟수, 범위를 뜻함 -
*(asterisk): "*" 직전의 선행문자가 0번 또는 여러 번 나타나는 문자열 -
\(backslash): pattern에서 사용되는 특수 문자들을 정규식 내에서 문자로 취급하고 싶을 때\(\)를 선행시켜 사용
e.g. [\?\[\\\]]: ‘?’, ‘[‘, ‘\’, ‘]’ 중 하나
- 정규표현식 패턴을 입력하면 대상 문자열에서 어떠한 원리로 매칭시키게 되는지 도식화해서 보여줌
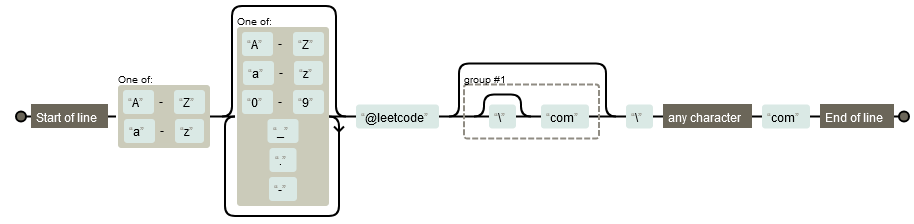
왜
^[A-z][A-z0-9_\.\-]*@leetcode(\\?com)?\\.com$로 쓰면 안 될까?
→[A-z]또는[:alpha:]또는\a: 알파벳 대문자 또는 소문자 문자열
이니까 똑같이 작동해야 하는 거 아닌가?
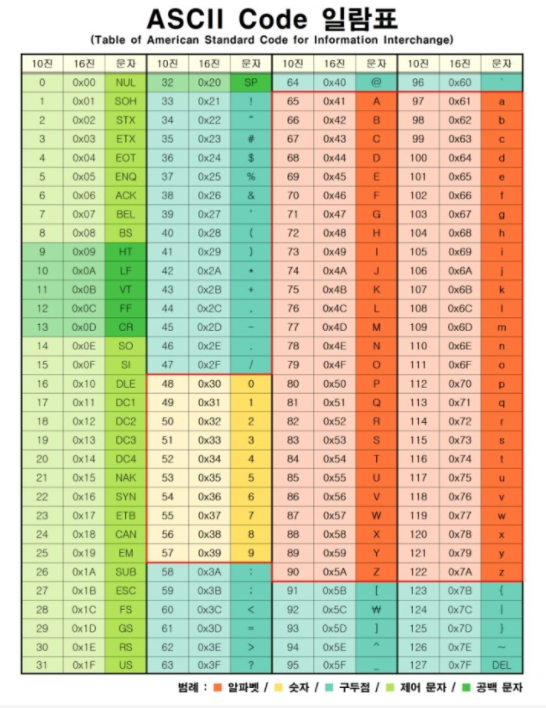
🡆[A-z]로 쓰면 아스키코드 65번부터 122번까지 범위가 지정되는데 91~96번이 알파벳이 아니라 구두점임

참고할 만한 다른 풀이
SELECT
*
FROM
Users
WHERE
mail REGEXP "^[A-Za-z][A-Za-z0-9_\.\-]*@leetcode(\\?com)?\\.com$"
;→ ?(question mark): "?" 직전의 선행 문자가 0번 또는 1번 나타나는 문자열
()(parenthesis): 정규식 내에서 패턴을 그룹화 할 때 사용
SELECT *
FROM Users
WHERE mail REGEXP '^[a-zA-Z][a-zA-Z0-9._-]*@leetcode.com'
AND mail like '%leetcode.com'128. Revising the Select Query I
- 작성한 쿼리
SELECT
*
FROM
city
WHERE
countrycode = 'USA'
AND population > 100000
;Python
53. 명예의 전당 (1)
- 작성한 코드
def solution(k, score):
answer = []
hall_of_honor = []
for i in score:
if len(hall_of_honor) < k:
hall_of_honor.append(i)
else:
if i > min(hall_of_honor):
hall_of_honor.remove(min(hall_of_honor))
hall_of_honor.append(i)
hall_of_honor.sort()
answer.append(min(hall_of_honor))
return answer참고할 만한 다른 풀이
def solution(k, score):
q = []
answer = []
for s in score:
q.append(s)
if (len(q) > k):
q.remove(min(q))
answer.append(min(q))
return answerimport heapq
def solution(k, score):
max_heap = []
answer = []
for sc in score:
heapq.heappush(max_heap, (-sc, sc))
answer.append(max(heapq.nsmallest(k, max_heap))[1])
return answer아티클 스터디
머신 러닝 특강
회고
- 정규표현식을 깊이 파고들면 정말 알아야 할 게 많은 것 같음
- 잘 익혀두면 상당히 유용하겠다는 생각
- 내일부터 프로젝트… 토할 것 같다…

2 B R 0 2 B