원본링크 : https://arxiv.org/pdf/2212.04089
0. Abstract
이 논문은 특정 pre-trained model의 행동을 바꾸는, 즉 새로운 downstream task의 성능을 높이거나 편향을 제거하는 등의 일을 하기 위해 task vector라는 새로운 개념을 제안한다. task vector는 pre-train된 모델의 파라미터들을 fine-tune된 모델의 파라미터들에서 빼는 것으로 정의되며, 일종의 task를 위한 weight space에서의 방향으로도 해석할 수 있다. 이 논문에서는 이러한 task vector들을 더하거나 빼는 간단한 산술 연산으로 pre-trained 모델을 원하는 대로 조종할 수 있음을 보인다. 이는 뺄셈으로 원래 모델의 target task 기능을 잊는 것, 덧셈으로 원래 모델에 target task의 기능을 더해주는 것 그리고 “A is to B as C is to D” 라는 “analogy relationship”을 이용해 A,B,C의 task vector를 알고 있고 모델이 전혀 알지 못하는 D의 기능을 원할 때 A,B,C만으로도 D의 기능을 얻을 수 있는 것을 포함한다.
1. Introduction
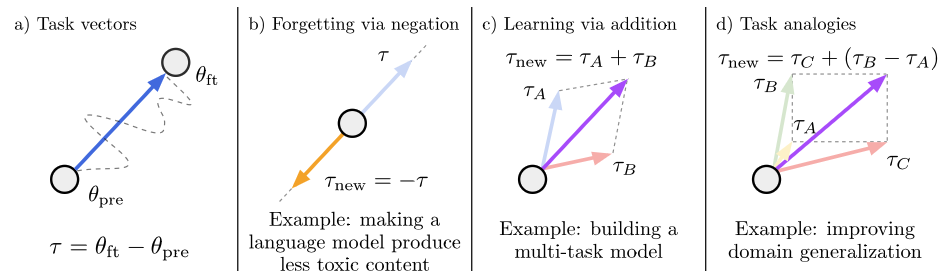
Forgetting via negation
b)에서 보는 것처럼 task vector를 뺌으로써 target task를 잊게 만들 수 있다.
Learning via addition
c)에서 보는 것처럼 task vector Ta, Tb를 더함으로써 두 가지 task를 모두 수행하는 multi-task model도 만들 수 있다.
Task Analogies
d)에서 보는 것처럼 모델이 전혀 알지 못하는 어떤 task Tnew를 만들고 싶을 때, 이 Tnew에 대한 analogy relationship이 있다면 Tnew = Tc + (Tb-Ta)로 정의하여 새로운 task를 향상시킬 수도 있다.
2. Task Vectors
앞서 task vector가 fine-tune 된 모델의 파라미터에서 pre-trained 모델의 파라미터를 빼서 나온 것이라고 설명했는데, 수식으로는 다음과 같다.
즉, task vector는 특정 task를 fine-tune한 모델에서부터 정의되고, 이때, 이러한 task vector (앞으로는 ) 를 이용해 새로운 모델의 파라미터들을 다음과 같이 정의할 수 있게 된다.
( = 1일 때는 fine-tuned model)
논문에서 는 held-out(보류된) validation set 으로부터 정해진다고 한다.
3. Forgetting via Negation
어떤 task를 뺄 때는 원래의 task를 해치지 않는 것이 관건이기 때문에, 논문에서는 control tasks와 target tasks의 정확도를 모두 평가한다.
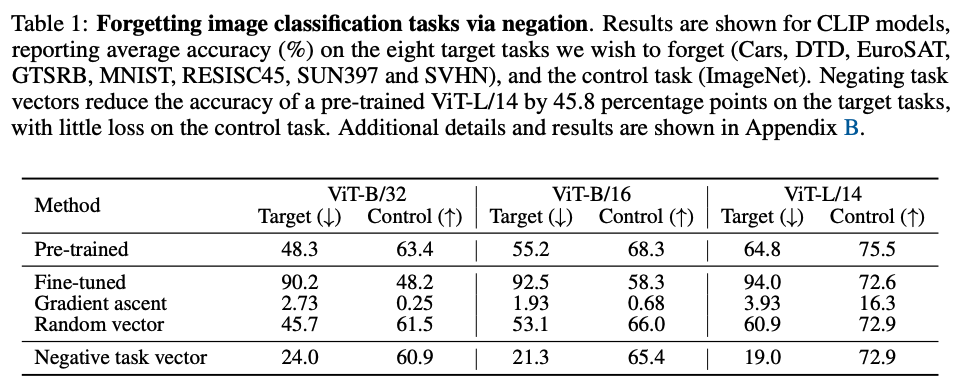
3.1. Image Classification
CLIP 모델과 fine-tune된 다른 8개의 fine-tuned model로부터 task vector를 얻어 실험을 해보았다고 한다. (control task dataset으로 ImageNet 사용) Baseline으로 사용된 방법들은 fine-tuning을 할 때 gradient ascent를 사용해 loss가 increasing되는 방향으로 학습한 모델과 task vector의 각 layer와 같은 magnitude를 가지는 random vector (N(0,1)에서 샘플링됨) 로 이루어진 vector를 pre-trained model에 더한 모델을 사용한다. 그 결과, 이 논문에서 사용한 negating task vector가 가장 효과적인 방법을 보였음을 알 수 있다.
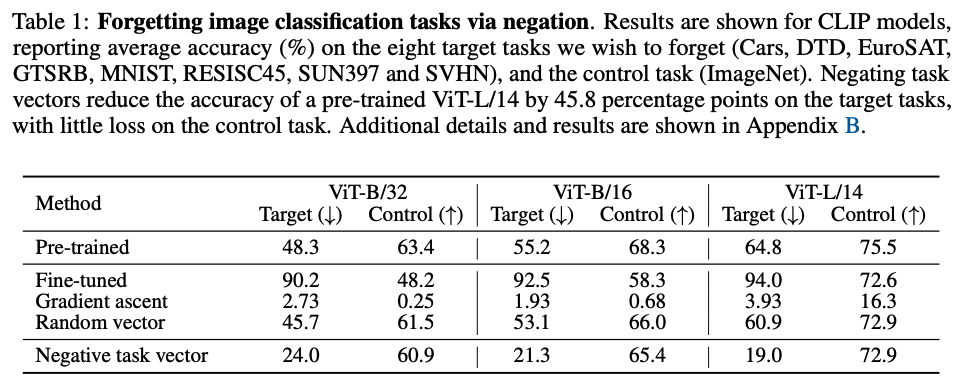
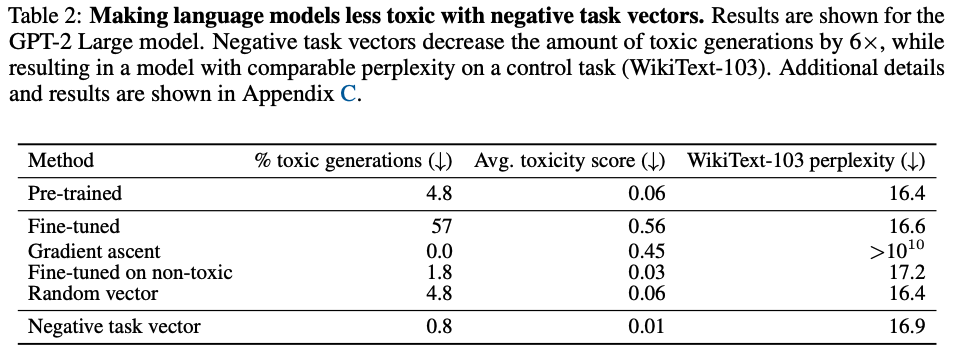
3.2. Text Generation
Text Generation은 GPT-2를 pre-trained model로 활용하여, “toxic generation”을 만들도록 fine-tune하고, task vector를 생성하여 (Civil Comments 기준 toxicity score 가 0.8보다 높은 데이터셋 활용) 3.1.과 같이 두 개의 baseline과 비교하였고, 추가적으로 Civil Comments 기준 toxicity score가 0.2보다 낮은 non-toxic dataset을 이용해 fine-tune한 모델까지 비교해주었다.
4. Learning Via Addition
taks vector 여러 개를 더해서 새로운 task를 만드는 것과 동시에, 여러 task vector들을 더하여 multi-task model을 구성한다.
4.1. Image classification
3.1.과 같은 8개의 task 중 임의의 2개의 task를 더해 구성한 모델들에 대해 정확도를 측정하였고, 이때 더해진 2개의 task 각각에 대해서 accuracy를 측정한 후 normalize 해주었다. (아래 그림)
여기서 zero-shot과 fine-tuned는 각각 아무 추가적인 훈련 없는 초기 모델의 성능과 해당 태스크에 fine-tune된 모델의 성능을 나타낸다.
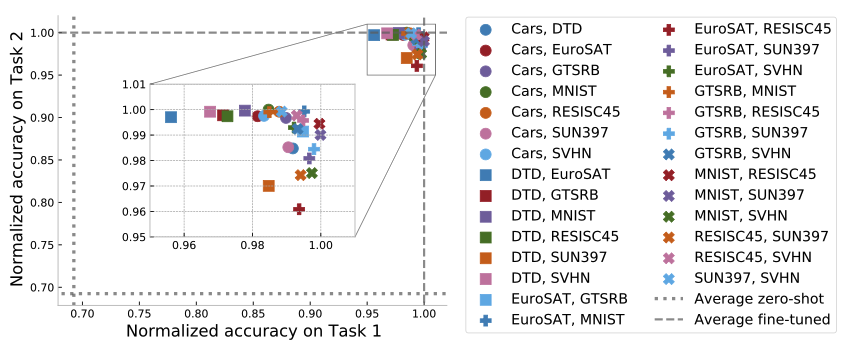
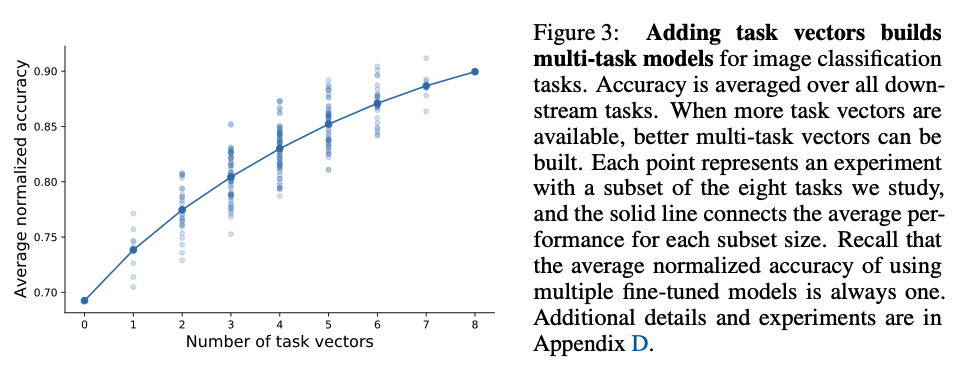
또한, 8개의 task로 가능한 모든 경우의 수들(2^8개)에 대해 실험을 해본 결과, 더해지는 task vector의 개수를 늘림에 따라 더 좋은 multi-task model을 만들어낼 수 있었다. 모든 task vector를 더하자 여러 모델을 압축하는 것에 해당함에도 높은 performance를 보여주었다. (91.2%)
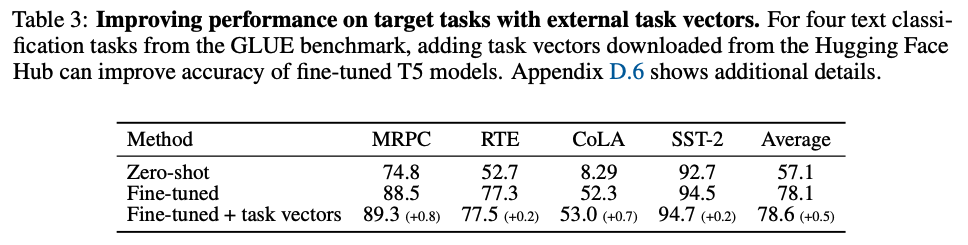
4.2. Natural Language Processing
GLUE benchmark의 네 가지 task(MRPC, RTE, CoLA,SST-2)에 대해 fine-tune된 T5-base model을 먼저 만들고, Hugging Face Hub에서 427개의 기존 모델을 찾아 각각의 task vector를 생성한 후 보류된 validation set에 따라 를 조정하여 fine-tune된 모델에 더해줌으로써 fine-tune된 모델을 단독으로 사용하는 것보다 task vector를 사용했을 때 더 성능이 좋아짐을 보였다.
5. Task Analogy
“A is to B as C is to D”라는 관계가 성립하는 task A,B,C,D에 대해 A,B,C의 task vector를 이용해 task D를 수행하는 새로운 모델을 만들어낸다.
5.1. Domain Generalization
target task의 labeled data를 구할 수 없을 때, labeled data가 구해져 있는 auxiliary(보조) task들을 이용해 target task를 구할 수 있다. 여기선 예시로 Yelp dataset에서 감정 분석을 하는 task를 위해 Yelp를 이용해 (unsupervised) language modeling이 되어있는 task vector와 Amazon dataset 에서 (unsupervised) language modeling이 되어있는 task vector, Amazon dataset에서 감정분석이 되어 있는 task vector를 이용한다. 이를 통해 다음과 같이 task analogy가 유의미한 정확도를 보임을 증명했다.
여기서 lm은 모두 unlabeled, unsupervised learning. 이를 통해 레이블되지 않은 데이터를 통해 얻은 도메인 관련 지식을 레이블된 보조 task의 지시고가 결합함으로써, 레이블된 데이터가 없는 target task에 대해서도 성능을 확인할 수 있었다.
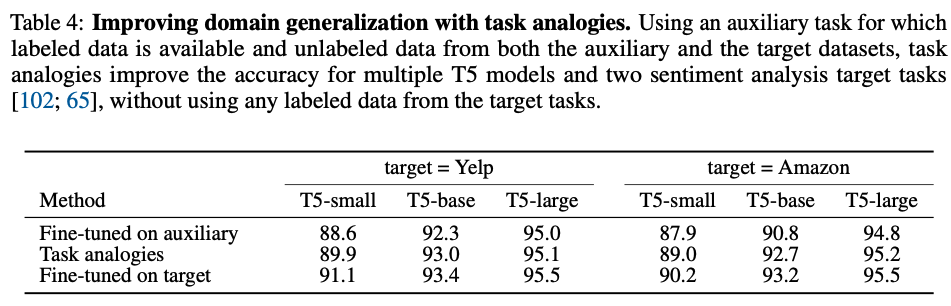
여기서, 특히 감정분석 task vector에 weight를 더 줄 때 더 좋은 결과를 내었다고 한다.
5.2. Subpopulations with little data
데이터 자체가 희귀한 경우, 이미 데이터가 있는 학습결과를 통해 희귀한 데이터의 task를 수행할 수 있다.
예를 들어, “실내의 사자”의 데이터는 “야외의 사자”보다 적을 것이기 때문에, “실내의 강아지”와 “야외의 강아지” 정보를 이용해 만든다고 볼 수 있다.
실험에서는 총 125개의 class를 이용해 dataset을 생성하고, 예를 들면 “real dog”, “real lion”, “sketch dog” 을 이용해 “sketch lion”이라는 task를 생성한다. 즉,
이러한 구성이 총 125개의 클래스에 대해 생성되었다고 보면 된다.

4개의 target subpopulation에 대해 정확도를 평균낸 그래프. task vector가 없을 때보다 좋은 성능을 보인다.
6. Discussion
위와 같은 결과는 어떻게 만들어질 수 있었을까?
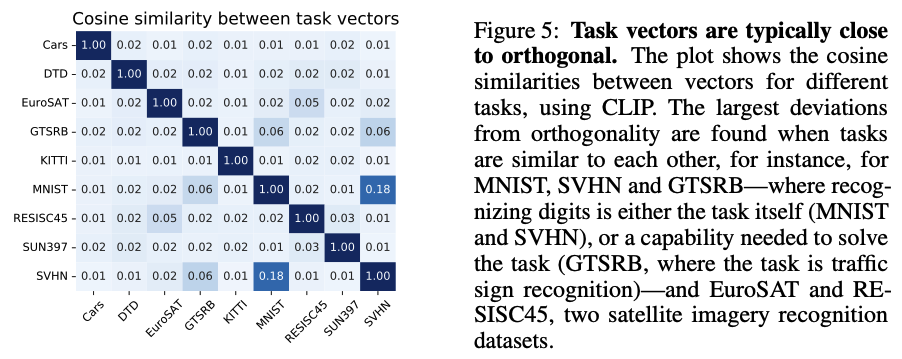
6.1. Similarity between task vectors
서로 다른 여러 task의 cosine similarity를 분석해본 결과, 연관 없는 task일수록 orthogonal 하다는 결과를 얻을 수 있었으며, 이를 통해 task vector 간의 addition이 서로 간에 영향을 적게 준다고 볼 수 있다. 의미론적으로 비슷한 task는 cosine similarity가 높게 나온 것을 볼 수 있으며, 이에 따라 하나의 task vector만 적용해도 비슷한 task의 정확도가 높아진 것을 관찰할 수도 있었다.
6.2. The impact of the learning rate
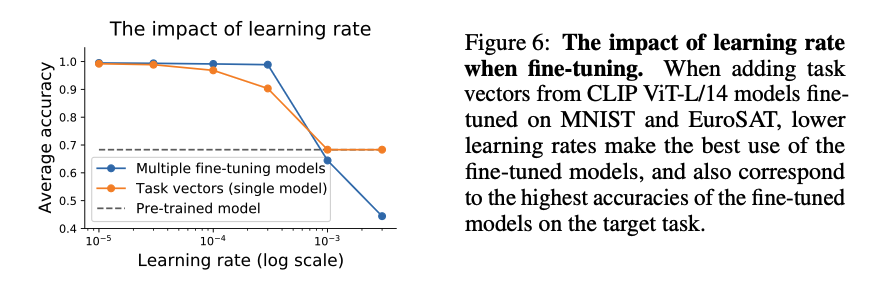
learning rate를 증가하는 것이 task vector 와 fine-tune multi tasking 모델을 만들 때 둘 다 정확도를 낮추는 결과를 가지고 왔다고 한다. (individual fine-tune model을 만들 때는 상관 없다?)
6.3. The evolution of task vectors throughout fine-tuning
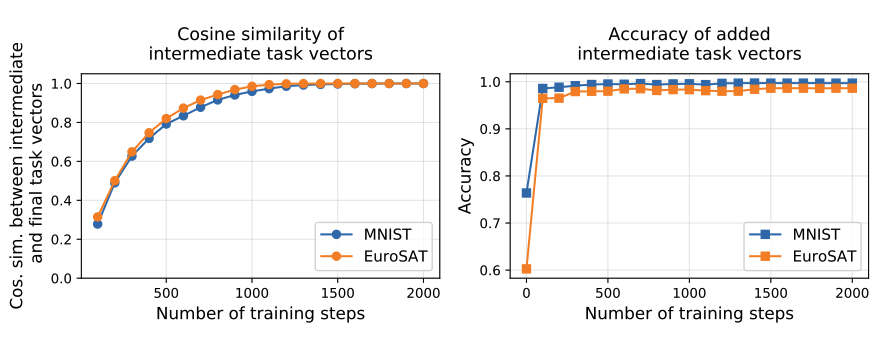
fine tuning을 진행할 때 보면 task vecetor의 cosine similiarity와 accuaracy 모두 step초반에 빠르게 증가하는 것을 볼 수 있다. 즉, 꼭 모든 step을 진행하지 않고 적당히 중간 값을 가지고 와도 유의미한 task vector를 얻을 수 있다는 것이다.
6.4. Limitation
이 방법의 한계는 같은 architecture의 모델에 대해서만 작용한다는 것이다. 또한, 같은 pre-trained model에서 시작한 fine-tuned 모델이어야 한다. 그렇지 않은 경우 weight space가 달라질 위험이 있다.
