0. Abstract
Long-form video understanding은 video data의 높은 반복과 video에 있는 query와 무관련한 정보들 때문에 어려운 task이다. 이를 해결하기 위해 video에 query를 적용하여 계층적인 구조로 represent하는 새로운 training-free framework인 VideoTree를 제안한다.
- VideoTree는 input video에서 반복적으로 input video에서 query와 연관된 정보들을 모은다. 이때, query와의 연관성에 따라 keyframe들을 계속 다듬는다.
- 또한, 기존의 LLM-based 방법론들이 놓치고 있는 long form video의 고유한 계층적 구조를 이용하여 representation을 만든다.
- 다중 세분성(multi-granularity) 정보를 tree-based representation에 통합하여 coarse-to-fine 방식으로 쿼리 관련 세부 정보를 추출한다. (coarse-to-fine : 거친 → 세밀한) → 이를 통해 다양한 수준의 세부 정보를 가진 광범위한 비디오 쿼리를 효과적으로 처리할 수 있도록 한다.
- 마지막으로, VideoTree는 쿼리와 관련된 정보들을 계층적으로 취합하여 tree structure 형태로 LLM 추론 모델에 제공한다.
- 실험을 통해 추론 정확도와 효율성 모두 향상됨을 알 수 있었다.
1. Introduction
최근 접근 가능한 long-form video가 급증함에 따라, long-form video를 이해하고 질문에 대답하는 모델을 개발하는 것이 매우 중요해졌다.
이에, 최근 연구들은 LLM의 long sequence 추론 능력을 활용하여 training-free 방식으로 문제를 해결하고 있다. 이러한 방법들은 보통 VLM을 이용해 sampling된 frame들에 caption을 생성하고, 이를 통해 영상을 텍스트 형식으로 표현하며, 이는 LLM에게 넣어져 질문에 답변하도록 한다. 이러한 전략이 long-form video 이해에 큰 발전을 가져왔으나 다음과 같은 두 가지 문제가 있다:
- 정보 과부하 긴 영상들은 필연적으로 많은 정보의 불필요한 중복이 일어나는데, 최근 연구들은 이 문제를 효율적으로 해결하고 있지 못하다. 중복적이고 관련없는 정보들의 대홍수는 LLM을 압도하며 정확도가 낮아진다.
- Coarse-to-Fine Video 구조 포착 불가 최근 연구들은 자주 영상을 아무런 구조 없이 단순히 caption의 나열로 표현하고는 하는데, 이는 video information이 가지고 있는 계층적인 구조를 설명할 수 없게 된다. 특히, 긴 영상에서는 어떤 영역은 정보가 밀집되어 있어 세밀한 시각적 이해를 필요로 하고, 쿼리와 상관없거나 정보가 희미한 영역도 있다. 이 때문에, 현존하는 방법들은 과부하 문제뿐만 아니라 caption들에서 중요한 정보들을 무시하여 세부 정보를 놓치는 문제도 생긴다.
이러한 문제점을 해결하기 위해 이 논문에서는 긴 영상 이해를 위한 training-free framework VideoTree를 제안한다. VideoTree는 쿼리와 연관된 keyframe들을 coarse-to-fine 방식으로 동적으로 추출하며 이를 자식 노드가 더 세부적인 정보를 담고 있는 tree 구조로 정렬한다. 즉, VideoTree는 Adaptive(적응적)이며, Hierarchical(계층적)이다.
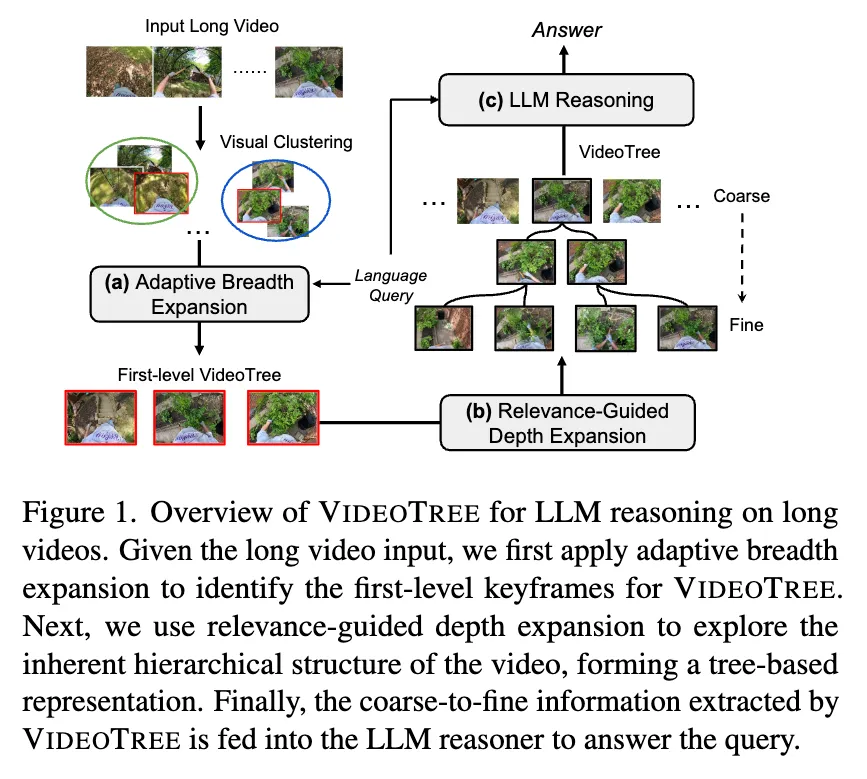
VideoTree는 다음과 같은 세 가지 핵심적인 단계를 거친다:
-
Adaptive Breadth Expansion (적응적 너비 확장)
우선, adaptive breadth expansion module을 이용해 쿼리와 관련된 정보를 추출하고, tree representation의 첫 번째 층을 구성한다. 이때, 충분한 정보가 모일 때까지 visual clustering, keyframe captioning, relevance scoring을 반복적으로 수행한다. 기존 방법들이 많은 수의 frame caption에 의존한 것에 비해 VideoTree는 적은 양의 keyframe만을 사용한다.
-
Relevance-Guided Depth Expansion (관련성 기반 깊이 확장)
더 세밀한 정보를 얻기 위해 relevance-guided depth expansion을 사용하며, 이를 통해 계층 구조에 쿼리에 더 특화되어 있고 자세한 정보들을 추가하여 tree 구조 표현을 구성한다.
-
LLM Reasoning (LLM 기반 추론)
마지막으로, captioner를 이용해 위에서 만들어진 구조적인 표현에서 영상 설명을 생성하여 쿼리와 함께 LLM에게 제공하며 긴 영상 추론을 하도록 한다.
이 연구에서는 두 개의 주요한 LVQA 데이터셋인 EgoSchema와 NExT-QA를 사용하여 평가를 진행하였으며, 기존의 training-free 방법에 비해 더 적은 시간과 LLM 호출로 각각 2.1%와 4.3%의 성능 향상을 보였다. 또한, 아주 긴 영상들에 대한 효과를 실험해보기 위해 Video-MME 벤치마크를 실험해본 결과 GPT-4V 모델보다 더 좋은 성능을 보였으며 ablation study를 통해 VideoAgent와 LLoVi보다 모든 caption 개수에서 좋은 성능을 보였음을 알 수 있었다. 마지막으로, VideoTree는 서로 다른 여러 언어 모델에 대해서도 일반적으로 강력한 성능을 보였다.
2. Related Work
2.1. Structural Video Representation
최근 연구들은 video frame들의 구조화된 이해를 통해 압축적이고 효율적인 장면 문맥 이해를 이루어냈다. 예를 들어, HierVL은 영상 표현을 짧고 긴 시간 단위에 걸쳐 만드는 bottom-up hierarchical video-language embedding을 제안했으며, VideoReCap에서는 짧은 clip 수준의 caption을 생성하여 더 긴 segment로 요약하는 방법을 소개했다. 이러한 방법들은 긴 영상을 세분화된 시간적 정보들로부터 높은 수준의 지식을 생성하는데, 이런 경우 계산과 시간 과부하가 발생한다. 이에 반해, 여러 coarse-to-fine 비디오 이해 연구들에 영감을 받아, VideoTree는 효율적이고 효과적인 긴 비디오 이해가 가능한 novel top-down 방법을 제안한다.
2.2. Video Understanding with LLMs
LLM의 뛰어난 추론 능력에 영감을 받아, 최근 연구들은 LLM을 복잡한 비디오 과제에 적용하기 시작했다. LLM이 텍스트를 우선적으로 처리함에 따라, 수많은 연구들이 multimodal projector를 훈련하여 visual encoder와 LLM을 연결하거나 caption 중심 정보들을 만들어내기 위해 노력해왔다. captioner와 LLM을 연결한 training-free 방법론도 연구되어 왔는데, 특히 LLoVi는 captioning model을 이용해 영상을 설명하고 LLM이 이 수많은 cpation들을 요약하여 프롬프트에 대답하는 간단한 방법을 제안했으며, VideoAgent는 LLM agent를 이용해 frame 검색을 위해 여러 반복적인 라운드를 거치는 방법을 제안하였다. 이러한 방법들과 달리, VideoTree는 주요 정보를 agent를 이용해 adaptive(적응적)이고 coarse-to-fine의 방식으로 추출하여 효율과 성능을 둘 다 높였다. 또한, VideoTree는 LLM 추론에 인간이 읽을 수 있는 tree 구조의 시각적 단서를 제공함으로써 해석가능성(interpretability)도 높였다.
3. VideoTree Method

full algorithm of VideoTree
3.1. Adaptive Breadth Expansion
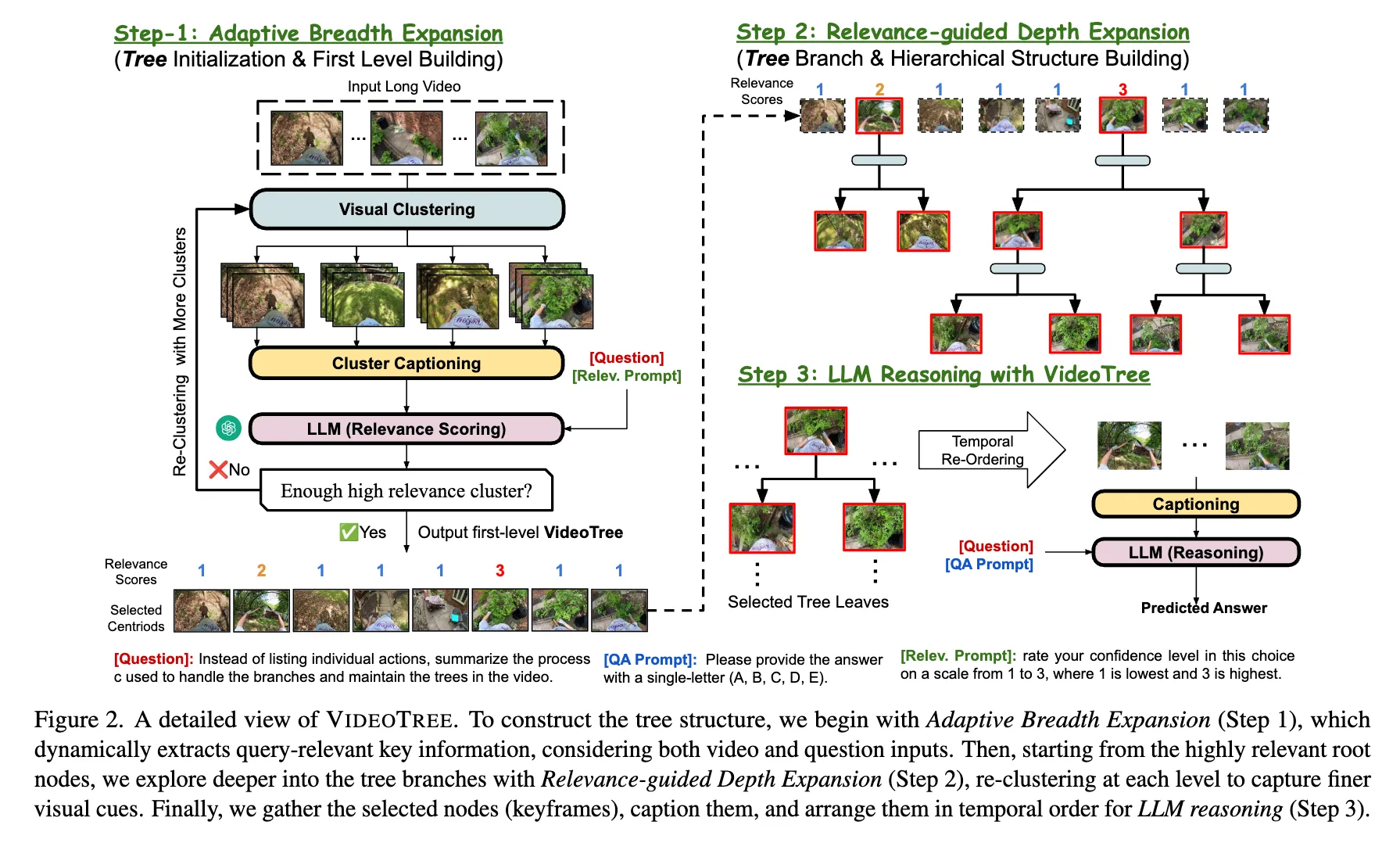
이 과정의 목표는 반복되는 정보를 없애고 관련없는 내용을 필터링하는 것이다. 기존 방법들은 고정된 개수의 keyframe들을 주요 정보로 선정하였다. 하지만 영상의 frame마다 정보의 밀집도가 다양하기 때문에 이 방법은 최적의 방법이 아니라고 할 수 있다. 이를 해결하기 위해 Adaptive Breadth Expansion (적응적 너비 확장) 방법을 제안하며, 이는 주어진 쿼리와 연관된 frame을 동적으로 찾아내며 tree 구조의 첫 번째 층을 구성한다. Fig.2의 step-1처럼, 주어진 영상과 쿼리에 대해서 다음과 같은 세 단계를 반복적으로 수행하며 tree의 첫 번째 층을 만들어낸다. 이 과정은 우선 비슷한 frame들을 그룹짓고, 각 cluster에 대해 caption을 생성하며, LLM을 이용해 각 cluster가 쿼리와 얼마나 연관있는지 결정짓는다. VideoTree는 이 과정을 쿼리와 연관된 충분한 정보가 주어졌을 때까지 적응적으로 반복한다.
3.1.1. Visual Clustering
정보의 반복성을 줄이기 위해, 우선 video frame들을 의미론적 유사성에 따라 그룹지으며, 모델의 각 cluster의 대표 frame에 대해서만 집중할 수 있도록 하여 반복적이고 의미 없는 내용을 제거한다. 특히, 주어진 video sequence 에 대해, pre-trained visual encoder(Eva-clip-18b)를 통해 각 frame에서 visual feature를 로 추출하며, 이 feature들은 frame이 담고 있는 의미론적 영상 정보(장면과 물체 등)을 압축적으로 포함한다. 그 후 K-Means Clustering을 통해 frame featuere들을 유사도에 따라 k개의 독립적인 cluster로 변환한다. 이를 다음과 같이 표시하자:
여기서, 는 i번째 cluster를 의미하며 는 i번째 cluster의 centroid vector를 의미한다. 이 과정은 n개의 frame들을 k개의 cluster로 변환하여 효과적으로 영상을 k개의 keyframe으로 변환한다.
3.1.2. Cluster Captioning
각 cluster에서 주요 문맥을 추출하기 위해 captioner를 이용해 각 cluster에서 keyframe information을 textual description으로 변환한다. (하나의 frame일 수도 있고, keyframe 주변의 짧은 clip일 수도 있음) 이를 위해 cluster 에 대해 centroid 와 가장 가까운 keyframe 를 찾아 이를 i번째 cluster 의 keyframe이라고 간주한다. 이렇게 추출된 keyframe을 VLM 기반 captioner에 통과시켜 text caption 를 각 cluster에 대해 얻어낸다.
3.1.3. Relevance Scoring
모델이 쿼리와 연관된 정보들을 잘 추출하기 위해, cluster caption t를 얻어낸 이후에 LLM의 추론 능력을 이용해 추출된 정보가 쿼리에 대답하기 충분한지 알아낸다. 우선 모든 cluster caption 과 video query 를 LLM에 넣고 각 caption의 relevance score 를 얻어낸다. 특히, relevance score를 얻어내기 위해 LLM에 caption들과 query를 프롬프팅하고, relevance score를 3 단계로 구분한다.

EgoSchema에서 relevance score를 얻기 위한 prompt
이제, 쿼리와 연관된 정보를 추출하기위해 clustering, captioning, relevance scoring을 반복적으로 수행한다. 특히, 주어진 각 cluster의 relevance score들에 대해 이 반복을 멈출 수 있는 “highly relevant cluster” 개수 기준을 rele_num_thresh 로 정한다. 또한, 무한 루프를 방지하기 위해 최대 cluster 개수를 max_breadth로 제한한다. 만약 “highly relevant cluster” 개수가 부족하다고 판단되면 cluster의 개수 k를 2배하여 clustering. captioning, relevance scoring을 반복한다. “highly relevant cluster” 개수가 threshold에 도달하거나 cluster의 개수가 max_breadth에 도달하면 추출된 cluster들과 그들의 keyframe을 tree의 첫 번째 layer에 추가하고 다음 단계로 넘어간다. (알고리즘 2-11줄)
3.2. Relevance-Guided Depth Expansion
tree 구조의 첫 번째 층을 완성한 후에, VideoTree는 video input으로부터 쿼리와 관련된 더 높은 수준의 정보들을 포집한다. 여기서, 특정 비디오 구간은 정보가 밀집되어 있고 쿼리에 대답하기에 중요한 비디오 구간들이 있으므로, 해당 keyframe들에 대한 더 자세한 분석을 필요로 한다.
SeViLA, VideoAgent 등의 기존 방법들은 위와 같이 밀집되어 선택된 frame들을 구조화 되어있지 않은 배열로 표현하며, 비디오 데이터가 가지는 내부 구조를 무시한다. 이를 해결하기 위해 Fig2. 의 step2처럼 계층적인 영상 표현을 만들며, 가장 상위 층은 breadth expansion step에서 주어진 cluster들이다. 특히, 첫 번째 단계에서 얻어진 relevance score가 높은 cluster들을 sub-cluster하여 tree의 깊이를 확장한다.
계층 구조를 구성하기 위해 top-level의 cluster의 relevance를 이용해 몇 단계의 더 세부적인 정보를 얻을지 결정한다. relevance score r이 3개의 level로 구성됨에 따라, 2단계인 “somewhat relevant” cluster들에 대해서는 w개의 sub-cluster들로 나누고, “highly relevant” cluster들에 대해서는 w의 width를 가지고 2개의 level을 가지는 tree로 re-cluster한다. (아래 그림 참고) 이러한 coarse-to-fine 전략은 복잡한 쿼리에 대해서도 연관된 세부 정보를 획득하는 것을 돕는다. 이러한 과정을 모든 최상위 노드들의 2,3 relevance score cluster에 대해 반복하며, 이를 통해 tree-based representation을 생성한다. (알고리즘 12-15줄)
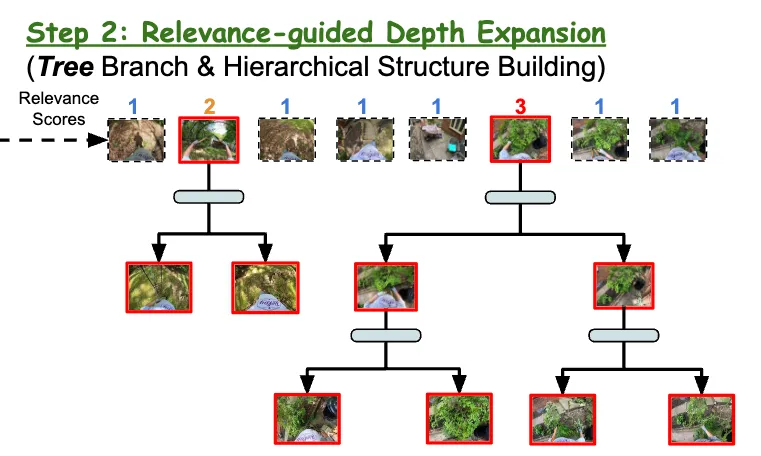
3.3. LLM Video Reasoning
마지막으로, LLM의 추론 능력을 활용하기 위해 LLM에게 text-based video representation을 제공해야 할 필요가 있다. 이를 위해 root에서 시작하여 tree의 모든 노드들을 탐색하며, 모든 level의 cluster로부터 keyframe들을 추출하고 이를 captioner로 넘겨 caption을 얻어낸다. 그리고 이 caption들을 시간 순서로 정렬하고 연결하여 textual description을 만들어낸다. 마지막으로, 이 description과 input query를 LLM에게 제공하여 정답을 만들어낸다. (알고리즘 16~18줄) 전체 프롬프트는 다음과 같다.

4. Experimental Setup
4.1. Tasks & Datasets
VideoTree는 세 가지의 LVQA benchmark에서 테스트되었다.
- EgoSchema : long-range video의 Question-Answering 벤치마크, 500개의 객관식 문답을 제공하며 인간 활동의 영상들을 주로 포함한다. 평균적으로 180초의 길이이다.
- NExT-QA : 인과관계 및 시간적 추론을 위한 video QA benchmark. 평균 44초의 5440개 영상을 포함하며 약 5200개의 문답을 포함한다. NExT-QA는 시간적, 인과적, 설명적 문답으로 나뉜다.
- Video-MME : 최근에 제안된 영상 분석을 위한 포괄적인 벤치마크. VideoTree는 “long-term videos” subset에 대해 실험되었고, 평균적으로 44분의 길이를 가진다.
4.2. Implementation Details
LLM으로 GPT-4를 사용하였고, Open-Source LLM과 다른 저작권이 있는 LLM에 대한 실험값도 제공한다. VideoAgent를 따라, visual encoder로는 EVA-CLIP-8B를 사용하며 더 작은 다른 visual encoder로의 실험값도 제공한다. 또한, 마찬가지로 VideoAgent를 따라 NExT-QA 벤치마크에서는 CogAgent를 사용했고, EgoSchema에서는 LaViLa를 captioner로써 사용했다. (LaViLa의 ego-centric한 영상 훈련으로 인해 human centric한 데이터셋을 더 잘 이해할 수 있으므로) 또한, general한 하나의 captioner에 대해서 실험한 결과도 제공한다. Video-MME 벤치마크에 대해서는 general captioner인 LLaVA1.6-7B를 사용했다.
EgoSchema와 NExT-QA에 대해서는 1FPS로 샘플링했고, Video-MME에 대해서는 0.125FPS로 샘플링했다.
그 결과, EgoSchema subset, NExT-QA, Video-MME 각각에 대해서 가장 좋은 성능을 보이는 caption의 평균 개수는 각각 62.4, 12.6, 128개였다.
4.3. Evaluation Metrics
모든 데이터셋에 대해 다중 객관식 질의응답 세팅을 하며, 올바른 답을 맞히는 비율을 정확도로 사용한다.
5. Results
5.1. Comparison with Existing Approaches
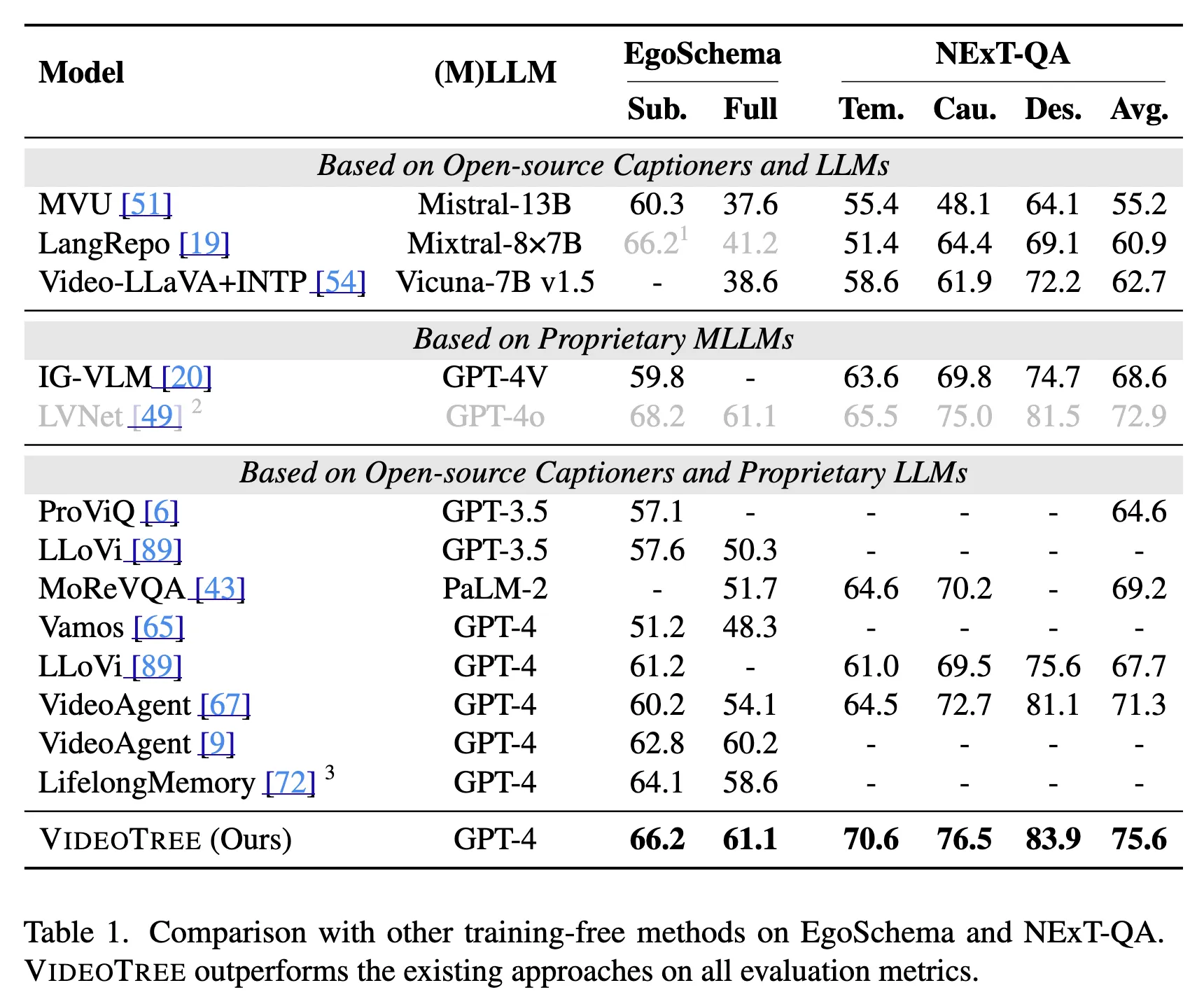
Comparison with training-free methods
이 논문에서는 VideoTree와 세 가지 종류의 기존 training-free 방법을 비교한다. 이 세 가지 방법은 각각 open-source LLM을 사용하는 방법, proprietary MLLM(Multimodal Large Language Model)을 사용하는 방법, open-source captioner와 proprietary LLM을 사용하는 방법을 포함한다. 특히, 같은 VLM과 LLM을 사용하는 방법들에 대해 VideoTree는 EgoSchema와 NExT-QA 모두에서 유의미하게 좋은 성능을 보였다.
- Video에 특화된 모델들을 사용한 VideoAgent에 비교해서는 EgoSchema 데이터에 대해 더 좋은 성능을 보였다.
- mLLM을 사용하는 방법들과 비교하면 VideoTree는 IG-VLM(GPT-4V기반)을 EgoSchema와 NExT-QA 모두에서 능가했다.
- LVNet과 EgoSchema에서 비슷한 성능을 내었고, NExT-QA에서는 더 좋은 성능을 보였다.
또한, 다른 open-source LLM 기반 방법들에 비해 더 좋은 성능을 보여 VideoTree에서 사용된 LLM 추론 모듈의 필요를 보였다.
공평한 비교를 위해 open source LLM을 사용한 경우와도 비교해본 결과, 유의미한 성능 향상을 보였다.
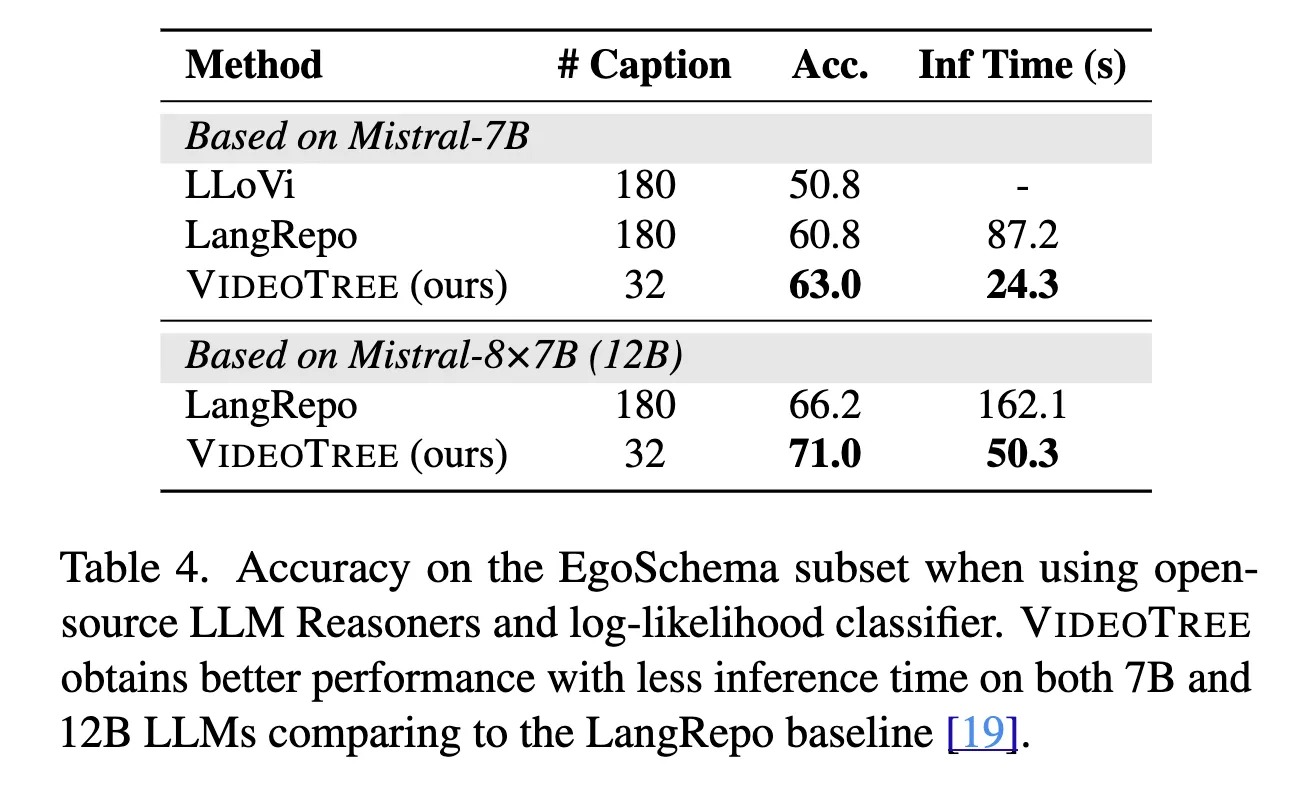
또한, 사용된 caption의 수와 추론 시간을 측정해본 결과, VideoTree가 다른 방법보다 효율적이라는 것도 증명되었다.
Evaluating on Very Long Videos
아주 긴 길이의 영상에 대한 평가를 위해, Video-MME의 long-split(평균 44분, 다양한 아주 긴 길이의 동영상들) 벤치마크에서도 평가를 진행한다. 이 평가는 세 가지의 baseline과 비교되는데, 각각 large scale data로 훈련된 proprietary MLLMs와 open source LLM, training-free baseline LLoVi이다.

- GPT-4V와 같은 MLLM보다 좋은 성능을 보임
- 하지만, GPT-4o와 같은 강력한 long-context 보다는 안 좋은 성능을 보임
- 긴 길이의 영상에 대해 훈련된 여러 open-source LLM(ViLA-1.5-40B, Intern-VL2)보다도 좋은 성능을 보였다.
5.2. Analysis
아래의 모든 분석에 대해서는 EgoSchema의 validation subset을 사용하였다.
5.2.1. Efficiency-Effectiveness Analysis
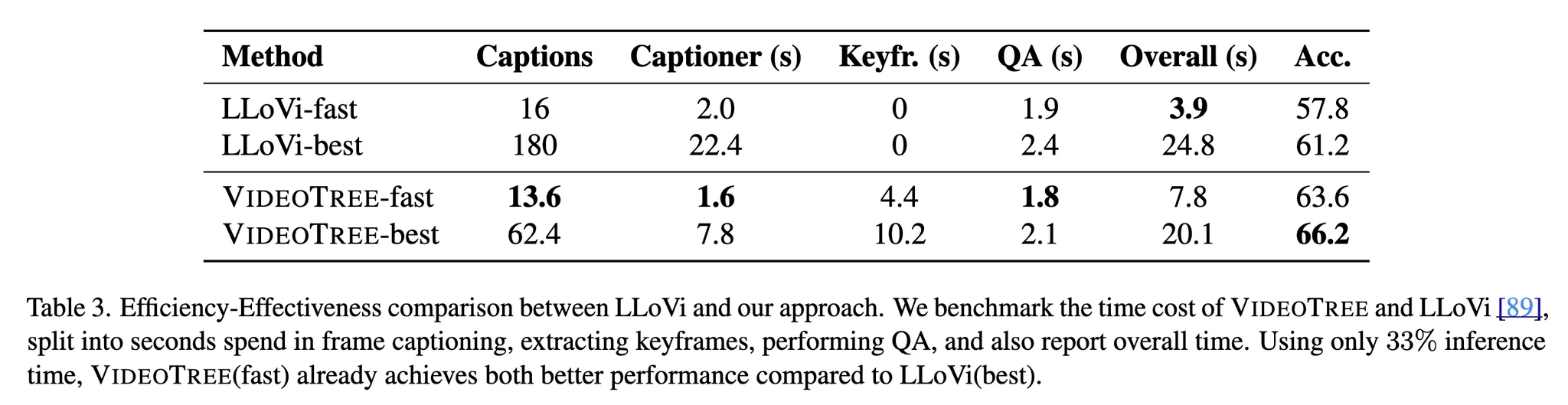
기존 연구들에 비해 효율성과 효과의 trade-off를 확인하기 위해 LLoVi와의 비교를 진행하되, LLM모델로 GPT-4를 사용하고 같은 capationer를 사용하는 조건에서 비교해보았다. 그 결과 Tab.3과 같이 VideoTree-fast(하이퍼 파라미터의 조절로 적은 frame을 사용하는 모델)가 시간적 측면에서 33%만의 시간만 사용하고도 2.4%의 정확도 향상을 보였다. 게다가, 하이퍼 파라미터를 조절한 여러 모델 중 가장 좋은 효과를 보인 VideoTree-best는 기존의 성능보다 5.0% 좋은 성능을 보이면서도 더 적은 추론 시간을 요구했다.
여기서, 각 단계(keyframe selection, caption summarizing, performing QA) 각각의 소요시간을 측정해본 결과 captioning 단계에서의 시간을 유의미하게 줄인 동시에 keyframe selection에 가장 높은 비율의 시간을 사용했음을 알 수 있었다.
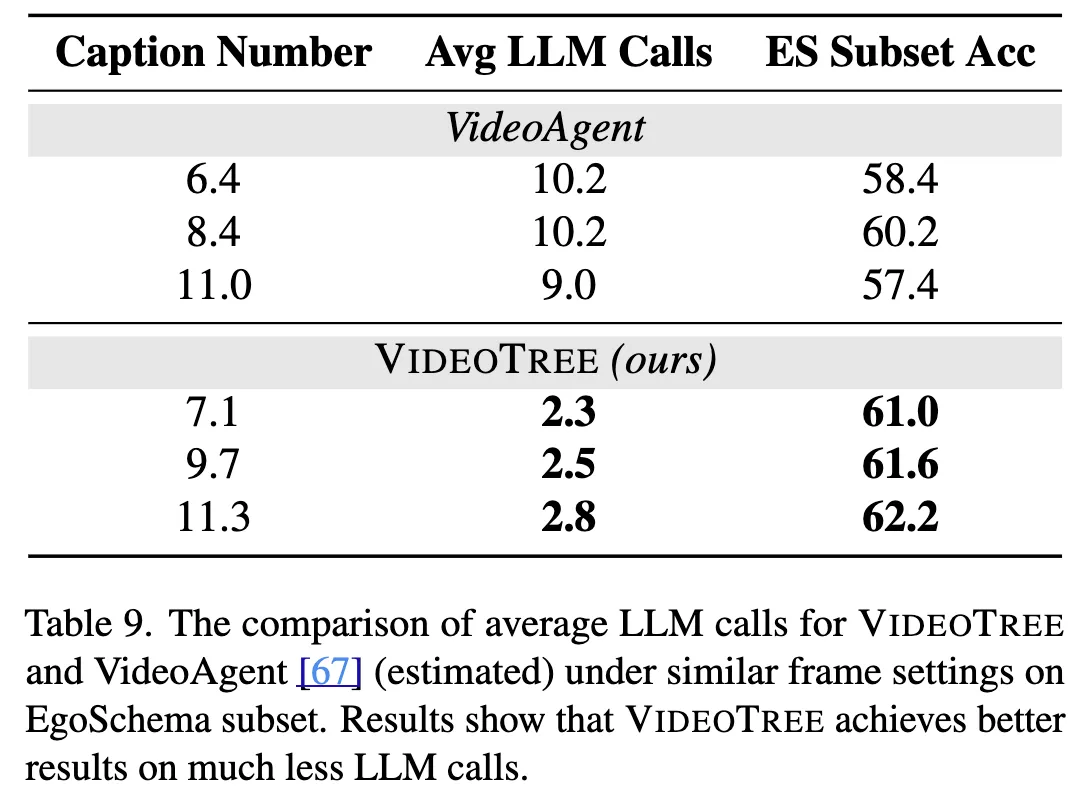
또한, LLM 호출의 횟수를 제어하여 VideoAgent와 비교한 결과 VideoTree가 더 적은 LLM 호출만 가지고도 더 좋은 결과를 만들어냈음을 알 수 있었다. 이는 VideoTree가 기존 연구들에 비해 효율-효과 측면에서 좋은 성능을 냈다는 것을 뜻한다.
5.2.2. Ablation Study
EgoSchema subset에서 VideoTree의 여러 요소(caption의 개수, captioner/LLM/vision encoder의 구조)를 절제한 ablation study를 진행해보았다.
-
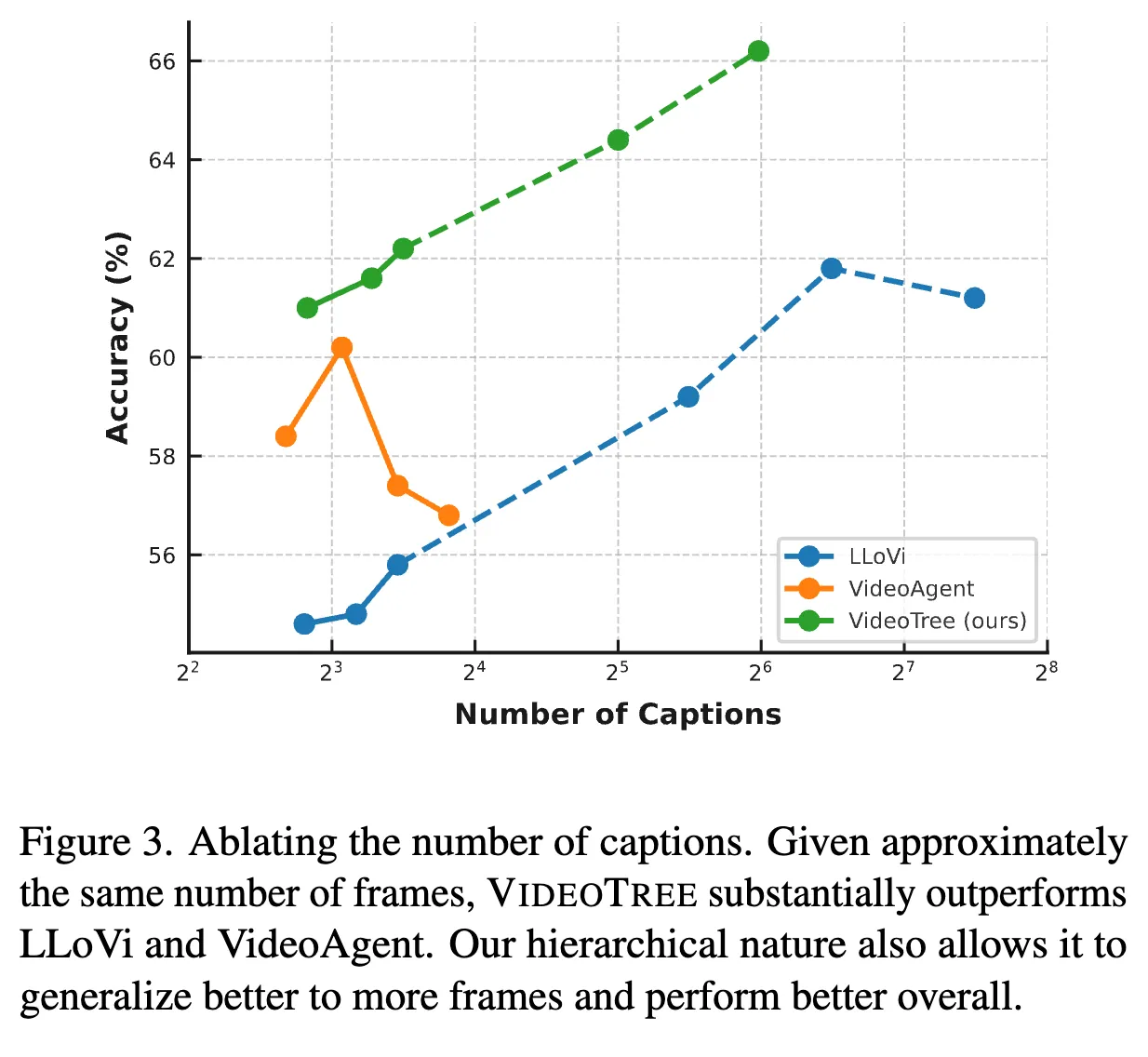
Number of Captions
기존의 방법들과 함께 여러 caption 개수(7,9,11) 에 대해 실험해본 결과 Fig.3과 같이 VideoTree가 LLoVi와 VideoAgent보다 평균적으로 6.5%, 2.0% 높은 정확도를 보임을 알 수 있었다. 특히, non-hierarchical 방법을 사용하는 VideoAgent가 11개의 caption이후로 오히려 낮은 정확도를 보임과 다르게 계층적 구조를 사용하는 VideoTree는 caption 수가 증가할수록 높은 정확도를 보였으며, 최대 6%까지 증가하는 것을 관찰할 수 있었다.
-
Open-Source LLM Reasoner
open-source LLM reasoner에서도 효과적으로 작동함을 보이기 위해 Mistral model의 7B,12B 버전을 사용하여 LLoVi와 LangRepo에서 실험해보았다. 공평한 비교를 위해 LangRepo의 평가 방식을 따르며, 이는 모든 선택지들에 점수를 매기고 그 중에 가장 높은 점수를 택하는 log-likelihood 방식이다. 그 결과, VideoTree는 7B와 12B 모두에 대해서 성능을 향상했을 뿐만 아니라 요구하는 frame caption의 개수도 20%에 불과함을 할 수 있었다. 특히, 복잡한 textual summarization module을 사용하는 LangRepo에 비해, VideoTree는 7B와 12B각각에 대해 72.5%와 69.0% 줄어든 추론 시간을 달성했음에도 성능이 각각 2.2%, 4.8% 좋아짐을 알 수 있었다. (Tab.4 참고)
-
VideoTree Components

위의 표에서 VideoTree의 각 요소에 따른 효과를 관찰할 수 있다. 특히, depth expansion module을 없앤 경우를 관찰하면 1.8%의 정확도가 낮아진 것을 보아 계층적 구조의 중요성을 확인할 수 있다. Adaptive breadth expansion을 제거한 경우에는 3.2%의 정확도 감소를 가져왔으며, VideoTree의 적응적 요소에 대한 효과를 암시한다.
5.2.3. Qualitative Analysis

위의 그림처럼 VideoTree의 정성적 분석이 가능하다. 특히, adaptive tree expansion을 통해 선정된 keyframe들과 그 captions을 볼 수 있다. 앞선 전략에서 소개했듯이, 다양한 장면을 포함하는 영상을 여러 주요 장면들로 나눈 후에 쿼리와 가장 유사한 장면을 relevance score로 판단한다.
위를 보면 32개의 baseline input caption중에 오직 절반만 주어진 질문에 관련 있는 것이라고 선택되는 것을 볼 수 있다. 이에 반해 고정된 개수의 uniform sampling을 진행하는 LLoVi은 많은 수의 중복되거나 관련 없는 frame을 선택함으로써 대답하기에 실패했다.
6. Conclusion
본 논문은 긴 영상에 대해 LLM 추론을 진행하는 적응적이고 계층적인 framework를 제안하는 VideoTree를 제안한다. VideoTree는 주어진 영상에서 쿼리와 연관된 정보들을 적응적으로 추출하여 coarse-to-fine하게 keyframe을 생성하고, 이를 계층적인 표현법으로 정리하여 LLM이 효과적으로 복잡한 쿼리를 다룰 수 있도록 한다. VideoTree는 3개의 대표적인 벤치마크(EgoSchema, NExT-QA, Video-MME) 모두에 대해 강력한 성능을 보이며 동시에 추론시간과 LLM 호출횟수를 유의미하게 줄인다. VideoTree는 쿼리와 관련된 주요한 장면을 뽑아내고 이를 집중하여 자세한 정보를 알아내는 것에 특화되어 있으며, 더 발전된 captioner와 LLM이 등장하면 VideoTree의 구조는 더 좋은 성능을 보일 것이다.
7. Limitation
모든 LLM-based 비디오 추론 시스템이 그렇듯이, 본 연구는 captioner의 성능에 따라 성능이 제한된다. 하지만 VideoTree의 modular한 구조는 새로운 captioner가 등장하였을 때, 이를 쉽게 적용할 수 있도록 돕는다. 비슷하게, 발전된 LLM도 쉽게 사용 가능하다.
VideoTree는 training-free한 기법이므로 hyperparamter의 개수가 적다. 이 hyperparameter들을 절제하여 ablation study를 해보면, sub-optimal한 세팅으로도 uniform sampling의 성능을 압도하는 것을 확인할 수 있다.
Questions
- According to Fig.3, increase of number of captions brings increase of accuracy, which contradicts the assumption: exceeding captions could overwhelms LLM. Any further analysis?
- Simply setting “rele_num_thresh” and “max_breadth” as a hyperparameter is not convincing. How are they set, and how can it handle the diversity of required information throught queries?
- Why is VideoTree not omitting clusters with relevance score 1, if it is not used in depth expansion?
IDEAS
- tree 자체의 구조를 잘 이해하지 못한 것 같다. BST의 빠른 검색처럼 tree 자체의 장점을 잘 이해할 수 있는 방법이 있을 텐데 아쉽다.
