CheckEval: A reliable LLM-as-a-Judge framework for evaluating text generation using checklists
[NLP] papers
EMNLP 2025 [Paper] [Github]
Yukyung Lee, Joonghoon Kim, Jaehee Kim, Hyowon Cho, Jaewook Kang, Pilsung Kang, Najoung Kim
Boston University · SK Telecom · Seoul National University · KAIST · NAVER
27 Mar 2024
Introduction
자연어 생성(NLG) 태스크의 성능을 평가하는 것은 분류나 회귀 태스크와 달리 정량화가 어렵다. 전통적으로 BLEU, ROUGE, BERTScore 같은 어휘 중복 기반 지표가 널리 사용되었지만, 이들은 인간 평가와의 상관관계(correlation)가 낮다는 한계가 있다. 또한 Human Evaluation은 gold standard로 인정받지만 시간과 비용이 크게 소모된다. 이에 최근에는 LLM을 평가자로 활용하여 텍스트 품질을 자동으로 판단하는 LLM-as-a-Judge가 대안으로 주목받고 있다.
대표적인 LLM-as-a-Judge 프로토콜인 G-Eval은 LLM에 평가 기준을 입력해 Auto-CoT로 평가 절차를 생성하고, 1~5점 Likert Scale 각 점수 토큰의 확률 분포를 기반으로 가중합을 계산해 최종 점수를 산출한다.
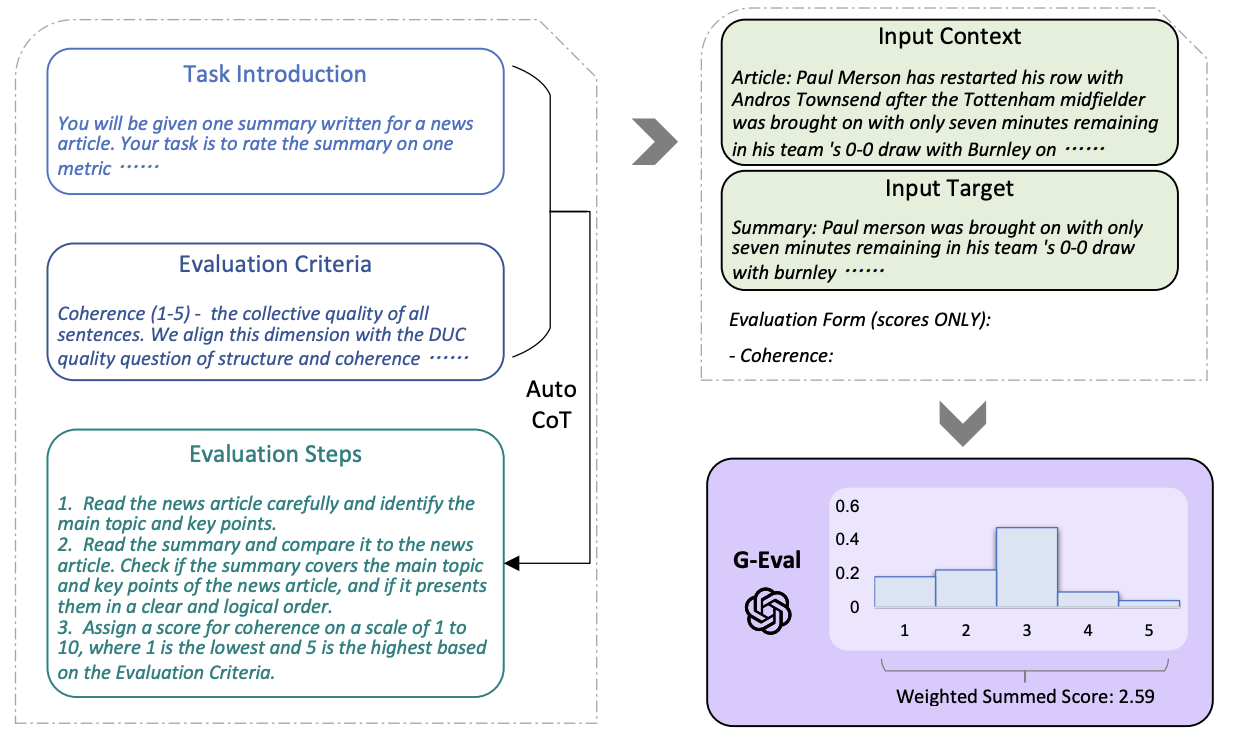
G-Eval은 인간 평가와 높은 상관관계를 보이며, LLM이 고비용의 Human Annotation을 대체할 수 있는 가능성을 제시했다.
그런데, 높은 상관관계(Correlation)가 높은 신뢰도(Reliability)를 보장할까?
Motivation
기존 LLM-as-a-Judge 프로토콜에는 두 가지 한계가 있다.
첫째, Likert Scale의 인접 점수 간 경계가 모호하다. Coherence를 1~5점으로 평가하세요와 같은 평가 프롬프트가 주어질 때, 3점과 4점의 기준은 모델마다 다르게 해석된다. 또한 하나의 평가 차원(e.g., Fluency) 안에 여러 세부 기준(e.g., formatting, grammar, readability, ...)이 혼재되어 있어, 평가자마다 초점을 맞추는 기준이 달라진다. 이는 낮은 Inter-Evaluator Agreement(IEA, 평가자 간 일치도)와 높은 점수 분산으로 이어진다.
둘째, 기존 연구들은 Reliability 지표에 대한 분석이 부재하다. LLM-as-a-Judge 연구 대부분이 인간 평가와의 Correlation만을 주요 지표로 사용하는데, Correlation이 높아도 모델 간 절대 점수가 서로 다를 수 있다. IEA나 Stability 같은 신뢰도 지표에 대한 체계적 분석이 필요하다.
주의할 점은, Correlation과 Agreement는 서로 다른 개념이라는 것이다.
두 개념에 대해서는 이 글에서 자세히 다룬다.
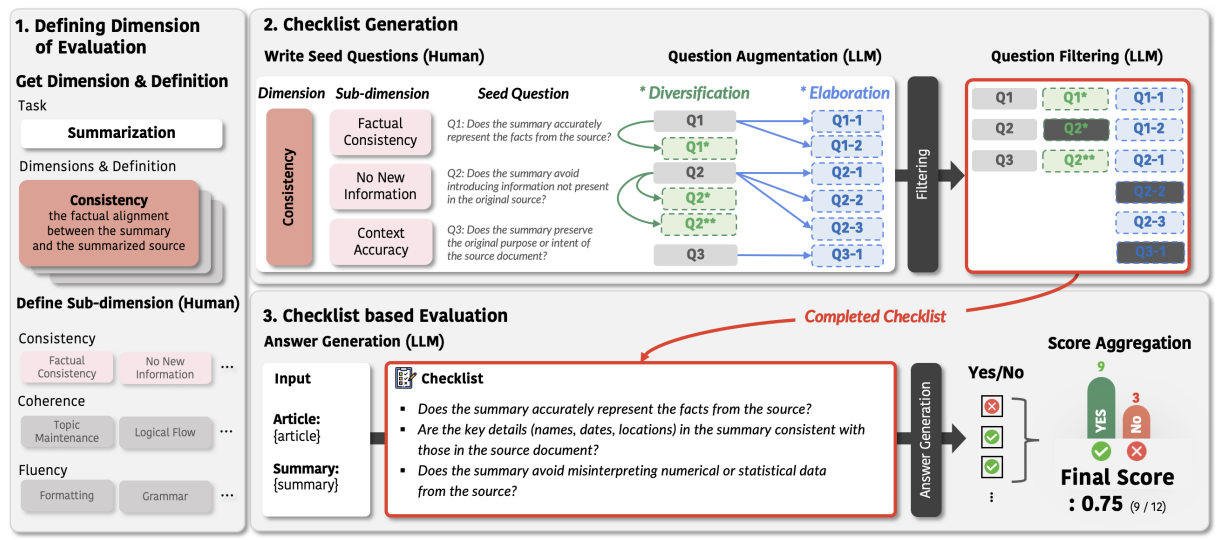
Method: CheckEval
CheckEval은 평가 기준을 Fine-grained Boolean Question으로 분해하여 평가하는 프레임워크다. 3단계 파이프라인으로 구성된다.
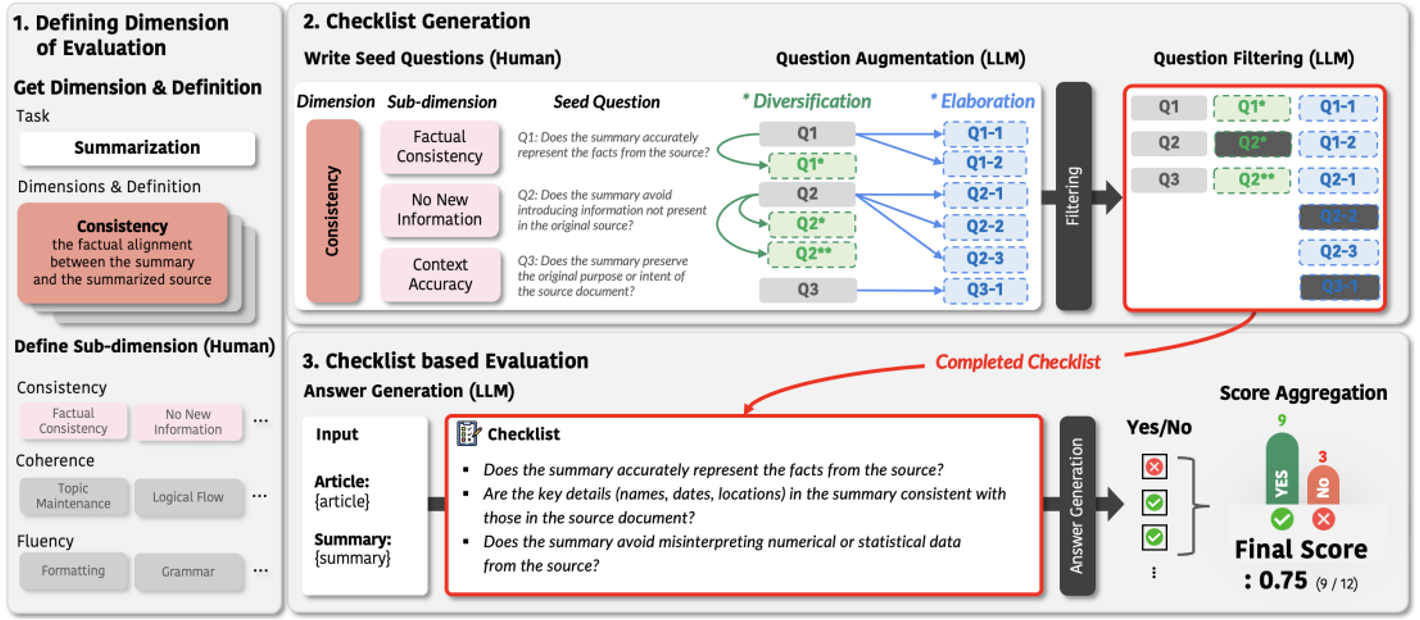
Stage 1: 평가 차원 정의

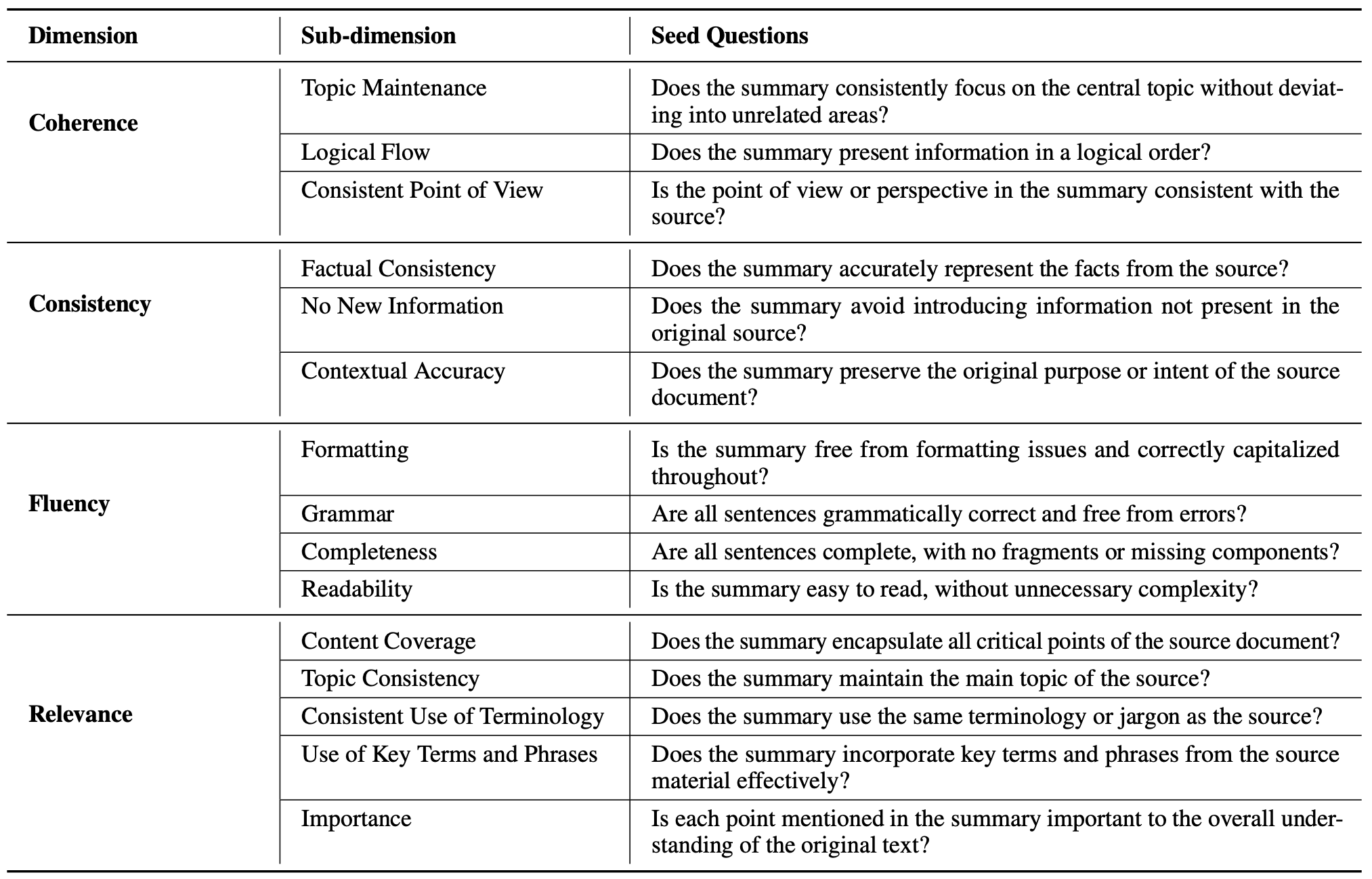
먼저 평가할 Dimension을 선정한다. 기존 벤치마크의 정의를 채택하거나 Task에 맞게 직접 정의할 수 있다. 이후 각 Dimension을 Sub-dimension으로 분해한다.
이때 Sub-dimension 정의는 LLM이 아닌 인간이 직접 수행한다. 실험 결과, Sub-dimenssion 생성을 LLM에게 맡기면 Dimension을 혼동하는 문제가 발생했으며, 이는 벤치마크의 원래 설계 의도와 어긋나 잘못된 평가 결과를 초래할 수 있기 때문이다.
Stage 2: 체크리스트 생성
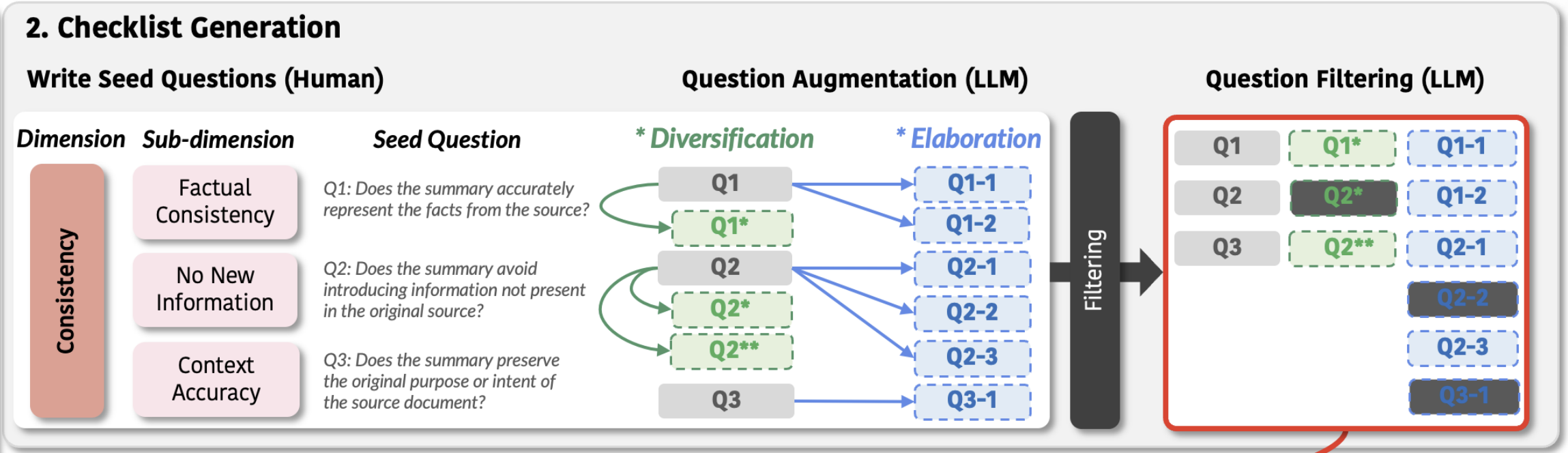
① Seed Question 작성
앞서 정의한 각 Sub-dimension별로 Yes or No로 답변할 수 있는 질문을 한 개씩 작성한다. 반드시 인간이 작성하며, "Yes"가 높은 품질을 의미하도록 설계한다.
e.g.,
- Task: Summarization
- Dimension: Consistency
- Sub-dimension: Factual Consistency
→ Seed Question: "요약문이 원문의 사실을 정확하게 반영하고 있나요?"
② Question Augmentation (LLM)
Seed Question을 두 가지 전략으로 확장한다.
- Diversification (다양화): 같은 Sub-dimension을 다른 관점에서 평가하는 질문을 생성한다. 평가의 폭을 넓히는 것이 목적이다.
- Seed: "문장 속 단어들의 철자가 모두 정확한가?"
→ Diversification: "모든 문장이 완전하며, 불완전하거나 빠진 요소가 없는가?"
- Seed: "문장 속 단어들의 철자가 모두 정확한가?"
- Elaboration (정교화): Seed Question을 더 구체적으로 분해한다. 평가의 깊이를 높이는 것이 목적이다.
- Seed: "문장 속 단어들의 철자가 모두 정확한가?"
→ Elaboration: "고유명사(사람, 장소 등의 이름)의 철자가 올바른가?"
- Seed: "문장 속 단어들의 철자가 모두 정확한가?"
두 전략을 순차로 적용하면 원래 Seed Question의 의도에서 멀어질 수 있으므로, 독립적으로 수행한다.
③ Question Filtering (LLM)
3가지 기준으로 부적절한 질문을 제거한다.
- Alignment (정합성): "Yes" 응답이 높은 품질을 의미하는가?
- Dimension Consistency (차원 일관성): 해당 질문이 의도한 차원을 실제로 측정하고 있는가?
- Redundancy Removal (중복 제거): 의미적으로 겹치는 질문을 제거한다.
Stage 3: 체크리스트 기반 평가

LLM이 Checklist의 각 질문에 Yes or No로 응답한다. 비용 효율을 위해 Sub-dimension별로 여러 질문을 한 번에 제시한다. (파일럿 실험에서 개별로 질문을 제시했을 때와 큰 성능 차이가 없음을 확인했다.)
최종 점수는 전체 질문 중 Yes 답변의 비율로 계산된다. 모든 질문에 동일한 가중치를 적용한다. (이와 관련해 Appendix C.2에서 다룬다.)
이 방식의 핵심 장점은 설명 가능성과 일관성이다. G-Eval과 같은 기존 LLM-as-a-Judge 프로토콜이 단순히 Naturalness: 2"처럼 점수만 달랑 출력하는 것에 비해, CheckEval은 "반복이 없는가?: Yes", "문법이 정확한가?: Yes", "주제와 관련이 있는가?: No" 와 같이 점수의 근거를 바로 추적할 수 있다. 또한 Binary 응답으로 3점 vs 4점 같은 모호한 판단을 제거하여 모델 간 변동을 최소화한다.
Experimental Setup
데이터셋: SummEval (뉴스 요약), Topical-Chat (대화 응답), QAGS (사실 일관성)
평가 모델 (12개):
- Large (70~123B): Llama3.1-70B, Mistral-Large, Qwen2.5-72B
- Medium (22~32B): Mistral-Small, Gemma2-27B, Qwen2.5-32B
- Small (7~9B): Llama3.1-8B, Gemma2-9B, Qwen2.5-7B
- GPT: GPT-4-Turbo, GPT-4o, GPT-4o-mini
비교 대상: G-Eval (CoT + Likert), SEEval (Self-Explanation + Likert), non-LLM metrics (ROUGE-L, BERTScore, BARTScore, UniEval)
평가 지표: Correlation (Spearman ρ, Kendall τ, Pearson r), IEA (Krippendorff α, Fleiss κ), Stability (상관 분포의 평균/분산)
Results
1. Correlation with Human Evaluation
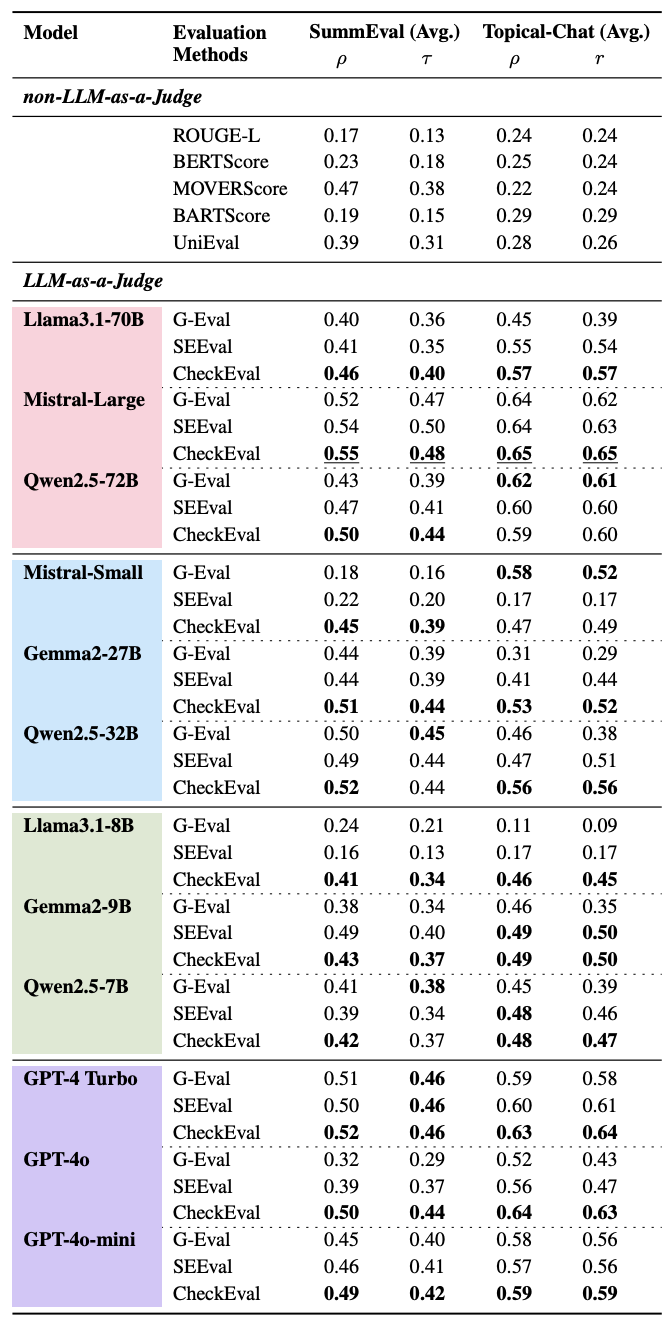
- 12개 모델 중 대부분에서 CheckEval이 최고 Correlation을 달성함.
- 특히 소형 모델에서 개선 폭이 큼.
- Llama3.1-8B: SummEval에서 ρ가 0.24(G-Eval) → 0.41(CheckEval)로 대폭 향상
- 최고 성능은 Mistral-Large + CheckEval 조합
- SummEval ρ=0.55, Topical-Chat r=0.65를 기록했다.
2. Inter-Evaluator Agreement (IEA)
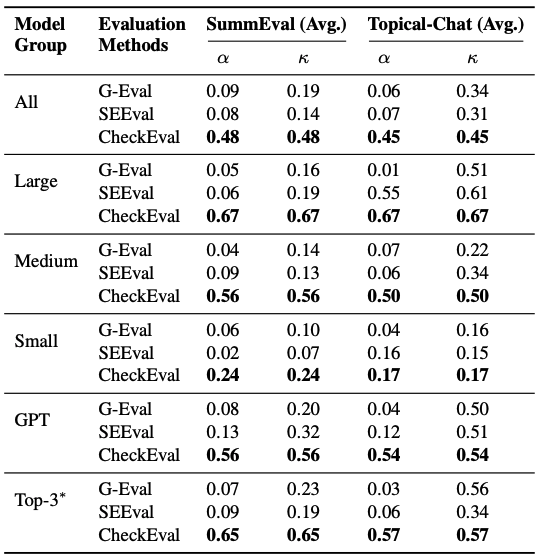
- G-Eval의 α=0.09, SEEval의 α=0.08은 사실상 우연 수준의 Agreement임.
- 반면 CheckEval은 α=0.48로, 평균 Agreement를 0.45 이상 향상함.
- Large 모델 그룹에서는 α=κ=0.67
- 이는 SummEval에서 보고한 인간 평가자 3명 간 일치도(κ≈0.7)와 거의 동등한 수준임.
- 이는 단순히 출력 형식(binary vs Likert)의 차이에서 기인한 것이 아님을 Appendix C.3에서 검증함.
- G-Eval의 Likert 점수를 강제로 binary로 변환해도 IEA는 소폭만 개선됨. (0.09→0.11)
- CheckEval (0.48)과의 격차가 여전히 압도적임.
3. 평가 안정성 분석 (Stability)
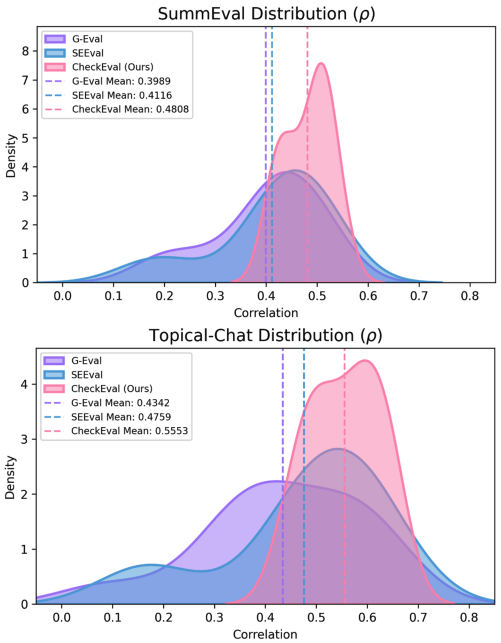
- (SummEval 데이터셋에서) CheckEval의 분산이 G-Eval 대비 약 5배 작음. (G-Eval 0.0100 vs CheckEval 0.0019)
- 즉, 어떤 모델을 평가자로 선택하더라도 안정적으로 높은 상관과 낮은 분산을 유지함.
- CheckEval은 IEA와 Stability 모두에서 G-Eval, SEEval을 상회함.
- IEA: 동일 샘플에 대해 Evaluator Model 간 점수가 일치하는가?
- Stability: Evaluator Model을 바꿔도 인간과의 상관이 유지되는가?
4. 체크리스트 생성 품질 검증
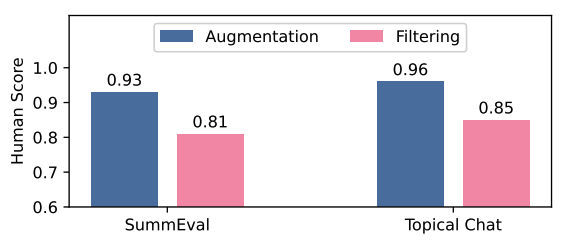
- 인간 평가자가 Augmentation과 Filtering 각 단계의 질문을 Yes/No로 직접 검증해봤음.
- Augmentation 단계에서 93~96%의 높은 점수를 기록함.
- Filtering 단계(81~85%)에서는 Dimension당 1~2개 정도의 의미적 중복이 남아있다는 피드백이 있었음.
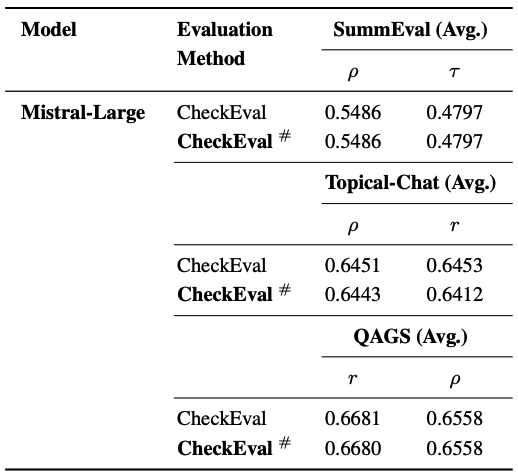
- 이러한 중복을 추가로 제거해도 성능 변화가 거의 없었음. (SummEval ρ: 0.5486 → 0.5486)
- 이는 CheckEval이 개별 질문 몇 개의 추가/제거에 민감하지 않고 robust하다는 것을 보여줌.
5. CheckEval 프로토콜 인간 검증
CheckEval 체크리스트를 인간이 직접 사용해도 LLM과 같은 판단을 이끌어낼 수 있는지 검증했다.
Correlation 분석
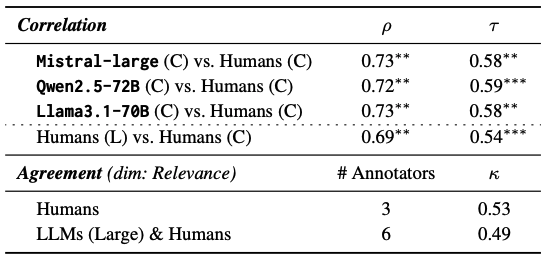
- 3명의 인간 평가자가 동일 Checklist로 20개 요약을 평가했을 때, LLM(CheckEval) vs 인간(CheckEval) 간 ρ=0.72~0.73을 기록함.
- 인간(Likert) vs 인간(CheckEval) 간 ρ=0.69로, CheckEval 프로토콜을 사용한 LLM이 Likert Scale을 사용한 인간보다 더 높은 상관을 보임.
- 이는 평가 주체(인간 vs LLM)보다 평가 프로토콜(CheckEval vs Likert)이 더 큰 영향을 미친다는 것을 시사함.
Agreement 분석
- Relevance 차원에서 100개 요약 × ~100개 질문을 평가한 결과, 인간 3명의 일치도 κ=0.53에서 LLM 3개를 추가해도 κ=0.49(-0.04)로 거의 하락하지 않았음.
- CheckEval 프로토콜 하에서 인간 평가자를 LLM으로 대체할 수 있는 수준임을 확인함.
Conclusion
Contribution
- 평가 기준을 세분화된 Yes/No 질문으로 분해하여 신뢰도(Reliability) 향상
- Large 모델에서 인간 평가자 수준의 Agreement 달성
- 평가 점수의 분산을 약 5배 감소시켜 안정성(Stability) 확보
- 별도의 rationale 생성 없이도 개별 binary 질문의 응답으로 점수 근거를 추적할 수 있어 해석 가능성(Interpretability) 확보
Limitations
- Sub-dimension과 Seed Question은 사람이 직접 작성해야 하며, 새로운 Task에 적용할 때 소요되는 시간과 노력을 예측하기 어렵다.
- Prompt 최적화, Multi-agent 토론, Meta-evaluator 훈련 등 최신 기법들과의 체계적 비교가 부재하며, 이들과 조합 가능한지 검증하지 않았다.
- 긴 텍스트에서 앞부분은 좋고 뒷부분은 나쁜 경우처럼, Yes/No 이진 판단으로는 부분적 품질 차이를 포착하기 어렵다.
- 실험이 요약과 대화 응답 생성에 집중되어 있어, 스토리 생성, 기계 번역, 장문 QA 등 다른 Task로의 일반화는 추가 검증이 필요하다.
다만, 이미 essay scoring (Chu et al., 2025), creative writing evaluation (Lee et al., 2024), healthcare evaluation (Mallinar et al., 2025) 등 후속 연구에서 CheckEval이 다른 Task로 확장되고 있다는 점은 고무적이다.
Comment
여러모로 내게 의미 있는 논문이다.
최근 Semantic Leakage 논문의 후속 연구를 진행하면서, 내가 제안한 method의 평가 방식을 두고 고민이 많았다. Rubric 기반의 Likert Scale 평가를 시도했는데, 평가 모델 간 Agreement가 잘 나오지 않아 한동안 막혀 있었다.
그러던 와중에 랩실 세미나 발표 순서가 돌아왔고, 발표할 논문을 찾아 돌아다니다 DSBA 연구실 유튜브에 도달했다. 거기서 "A reliable LLM-as-a-Judge framework for evaluating text generation ..." 이라는 제목이 눈에 띄었고, Abstract와 Introduction을 읽어보니 나를 살려줄 논문이다 싶어 쭉 정독했다.
이 논문의 1저자가 네부캠 첫 멘토셨던 유경 멘토님이었다. 신이 존재하는 건지 유경님이 신인 건지 모르겠다. 논문을 성공적으로 완성하면 멘토님께 연락해서 감사 인사를 드리고 싶다.
세미나에서 30분 정도 발표했는데, 교수님께서 '어떻게 저런 논문을 쓰는 거지'라며 극찬하셨다. 개인적으로는 어떤 지적이 들어와도 방어할 수 있도록 Appendix에서 다양한 검증 실험을 수행한 점이 특히 인상적이었다.
