1. RNN (Recurrent Neural Network)
가변적인 길이의 Sequence 자료를 입력으로 받아, 매 Timestep마다 동일한 함수를 사용해 입력을 처리함.

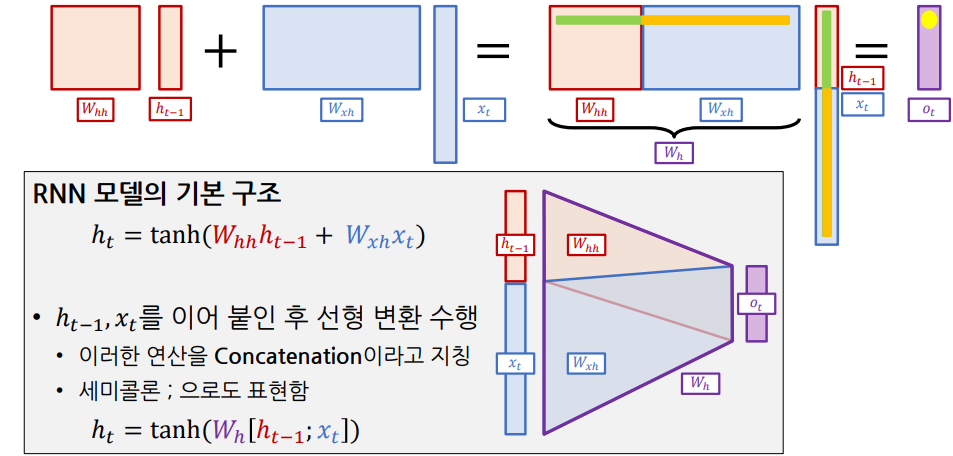
* : 로 선형 변환하기 위한 가중치 행렬
- 활성 함수로는 주로 Zero-Centered인 Tanh를 사용
- Target 예측을 위해 를 활용해 를 구할 수 있음. (e.g. )
RNN의 Hidden-State Vector 계산
과 를 Concatenation한 뒤, 로 선형 변환하여 를 구할 수 있음.
Rolled / Unrolled RNN
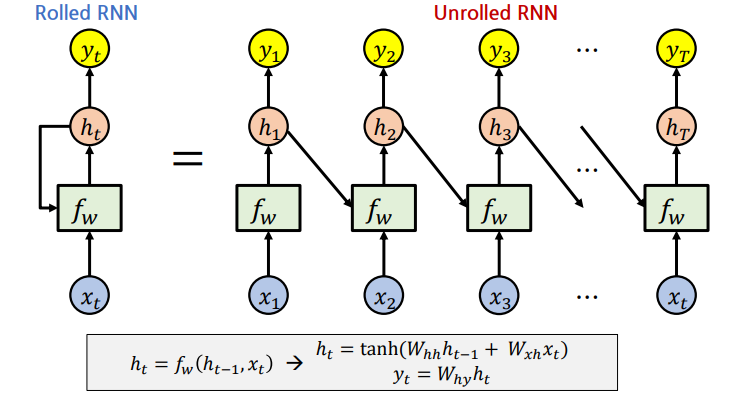
* 은 일반적으로 0으로 채워진 벡터(zero-vector)를 사용함.
RNN의 응용
* 참고: 이렇게 모델의 출력을 다시 입력으로 사용해 순차적으로 예측하는 모델을 Auto-regressive 모델이라고 함.
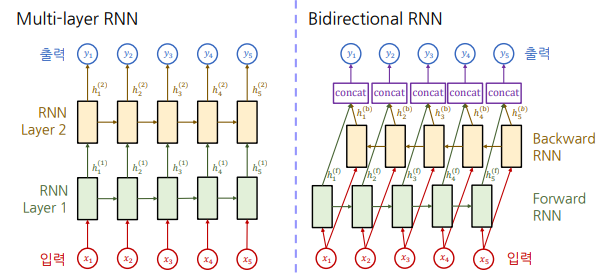
- 기본적인 RNN은 왼쪽에서 오른쪽 방향으로 정보를 축적함.
- Multi-layer RNN
- 최초 입력 시퀀스의 길이를 유지하면서
- Sequence 내의 정보를 계속 축적해 만들어진 RNN의 Hidden State를 바탕으로, 보다 유의미한 벡터로 변환 가능
- Bidirectional RNN
- 왼쪽→오른쪽, 오른쪽→왼쪽 방향으로 각각 정보를 축적한 뒤 Concat
- 오른쪽에서 나타나는 정보를 반영해야 하는 경우에 유리 (e.g. I read books that he gave.)
RNN의 형태
one-to-one, one-to-many, many-to-one, many-to-many 형태가 존재함.
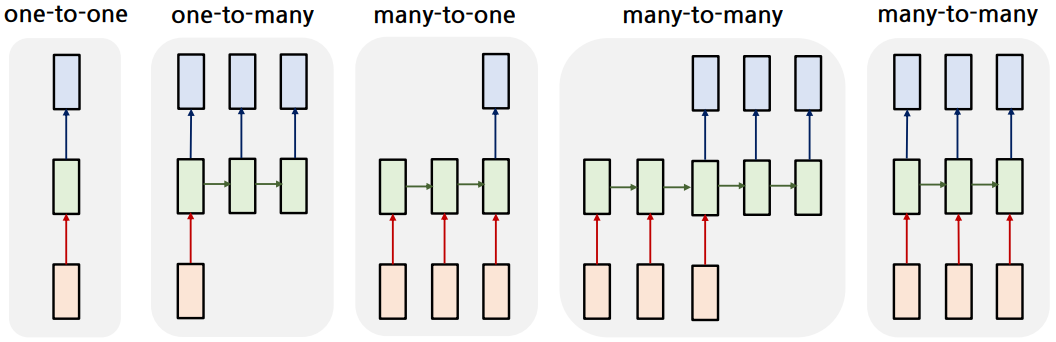
* one-to-many의 는 0으로 채워진 벡터(zero-vector)를 사용함.
- one-to-one: 평범한 Neural Network (e.g. 자동차 사진 -> "자동차")
- one-to-many: Image captioning 등에 사용 (e.g. 자동차 사진 -> "전시장", "의", "자동차")
- many-to-one: 감정 분류 등에 사용 (e.g. "재미있는", "영화", "였어요" -> "긍정")
- many-to-many(1): 기계 번역 등에 사용 (e.g. "I", "love", "you" -> "당신을", "사랑", "합니다")
- many-to-many(2): 지연이 없어야 하는 실시간 처리에 사용
-> Frame 단위 Video classification, Language Modeling 등
2. Language Modeling
Language Modeling은 다음에 어떤 단어(혹은 토큰)이 올 지 예측하는 task를 의미함.
예시: 문자열 단위 Language Model
- 학습 문자열: "hello"
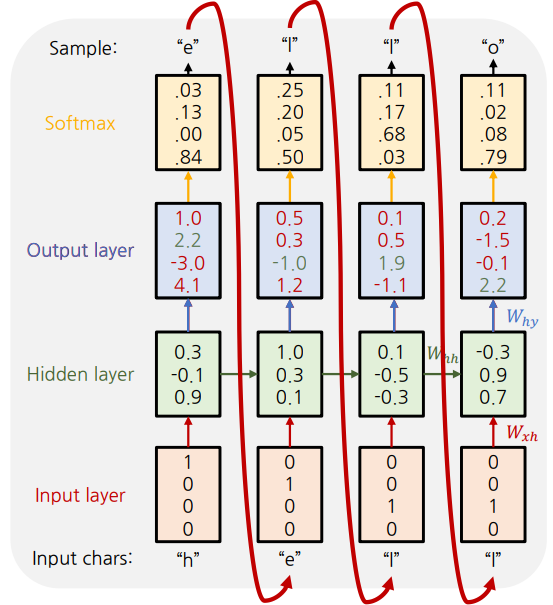
- 각 문자를 One-hot encoding으로 입력
* <참고> 각 문자를 One-hot encoding으로 표현하는 이유
- 'h': 1, 'e': 2, 'l': 3, ... 으로 표현하면 각 문자에 Continuous한 순서가 생김.
- 실제론 순서가 존재하지 않으며, 2.5같은 index는 존재하지 않음.
-> One-hot encoding으로 표현하면 각 문자는 독립성을 유지하며, 일종의 Categorical variable로 생각할 수 있음.
- 입력 로 Hidden State 계산
-> ) - Hidden state 에서 출력 계산
-> - Softmax를 통해 다음에 나올 문자의 확률을 계산
- Cross-Entropy Loss 계산 및 학습
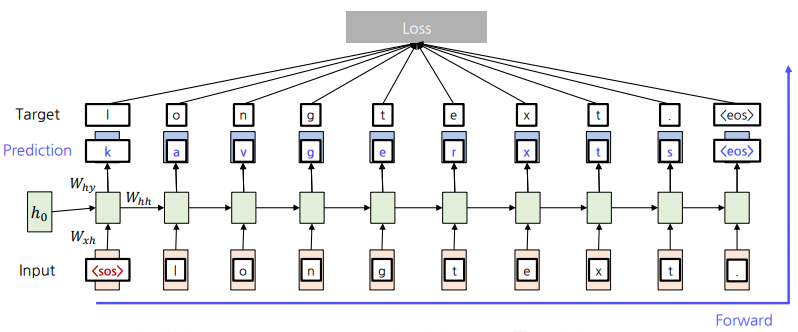
문자열 단위 Language Model의 학습
-
Forward 과정에서 예측값과 Ground-truth값의 Softmax Loss를 계산함.
-
Backward 과정에서 가중치()를 Update함.
Backpropagation Through Time
-> Timestep을 거슬러 올라가면서 Gradient를 계산해 가중치를 Update함.
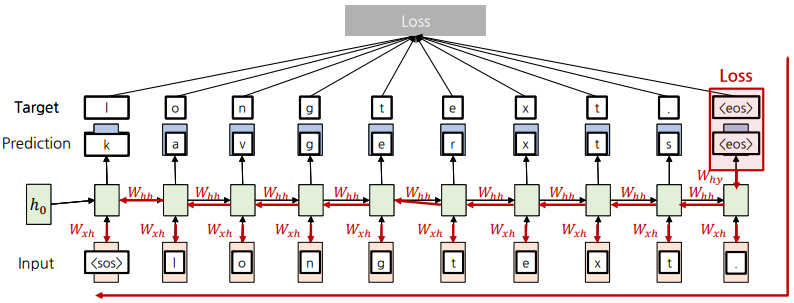
-> 문제점: Sequence가 길어질수록 계산 비용 및 메모리 요구량이 커짐.
Truncated Backpropagation Through Time
-> Sequence를 Chunk 단위로 나눠 Forward와 Backward를 진행함.
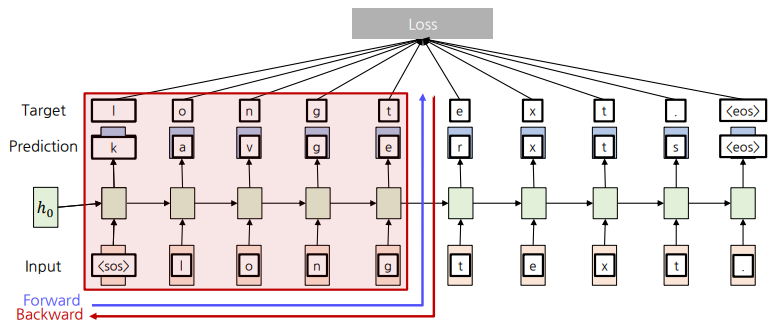
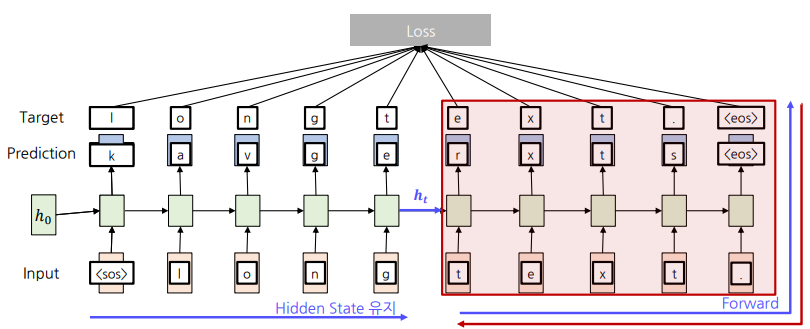
-> Backpropagation을 Chunk 안에서만 진행해 계산량을 줄임.

AI Safety 일짱이 되겠다.