1. Vector Representation
1.1. One-Hot Encoding
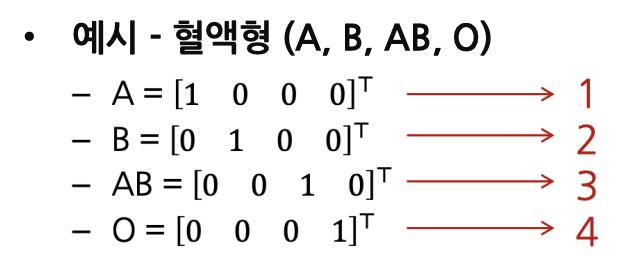
- 단어를 Categorical variable로 Encoding한 벡터로 표현
- 하나의 차원이 각 단어를 뜻하도록 표현 가능
- 이를 Sparse Representation이라고 함.

- 단어들 간의 내적 유사도(Dot-product Similarity): 항상
- 단어들 간의 유클리드 거리: 항상
- 단점) 단어들 간의 의미가 유사하거나 반대여도 유사도 차이가 없음.
- Dimension index만을 사용해 메모리 절약 가능
- 다른 모든 차원은 0으로 표현되므로, non-zero값이 포함된 차원의 index만으로 표현 가능

- (non-zero값이 포함된 차원의 index, 값)으로도 표현 가능
1.2. Distributed Vector Representation
Distributed vector
- 단어의 의미를 여러 차원에 non-zero값의 형태로 표현
- 이를 Dense Representation라고도 함.
- 장점) 유클리드 거리, 내적, 코사인 유사도가 단어들 간의 의미적 유사성을 나타냄.
Word2Vec
- 단어들을 Dense vector로 표현하는 Word embedding의 대표적인 방법론
- 주변 단어의 정보들을 이용해 단어 벡터를 표현
- "You shall know a word by the company it keeps" - J. R. Firth 1957
2. Word2Vec
2.1. 핵심 아이디어
- 특정 단어의 주변에 나타날 수 있는 단어들의 확률 분포를 모델링하는 것
- 예시) "Cat"이라는 단어의 앞뒤로 올 확률, 이 높은 단어는?
- "Meow" - 0.57
- "Potato" - 0.03
- "Paris" - 0.05
- "Pet" - 0.34
- "Baquette" - 0.01
-> "Cat"의 의미는 확률 분포 에 의해 결정된다.
Word2Vec의 두 가지 예측 Task
- Continuous Bag of Words (CBoW)
- Skip-gram
-> Skip-gram 형태의 Word2Vec이 더 많이 쓰임.
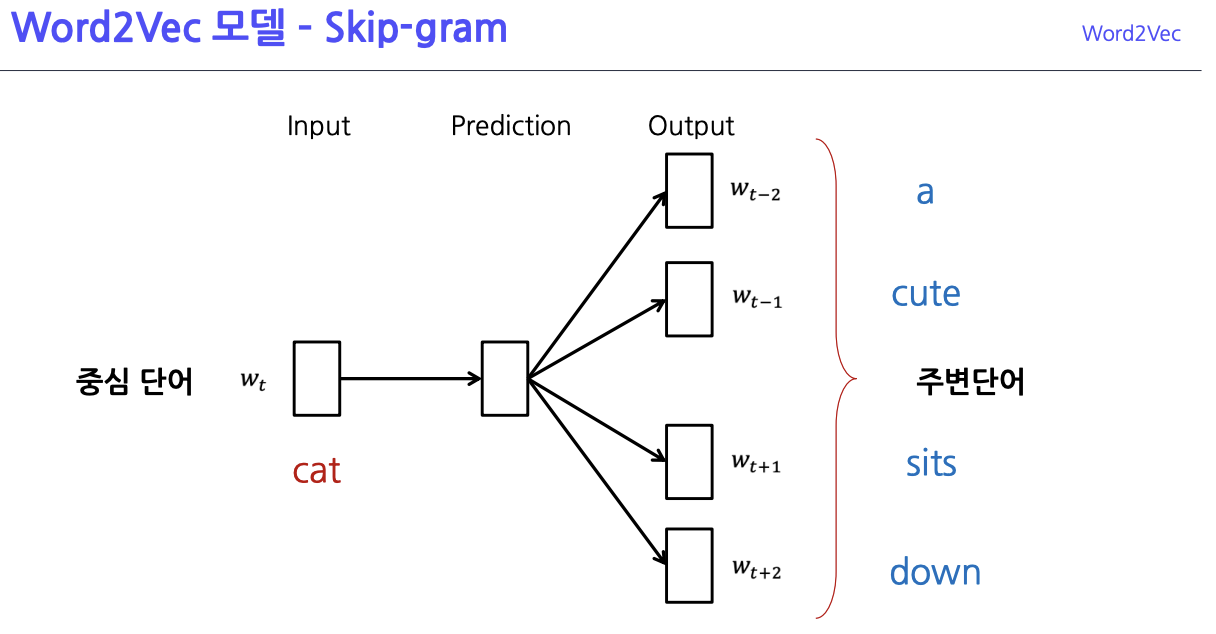
2.2. 알고리즘 작동 원리
- Window Size를 정하고, 해당 크기만큼 주변 단어의 정보를 학습
- 중심 단어를 이용해 주변 단어를 예측
- (입력) 중심 단어 -[Hidden Layer]-> (출력) 주변 단어
- 주변 단어의 개수만큼 학습 기회가 주어짐
- (예시) Window Size = 3
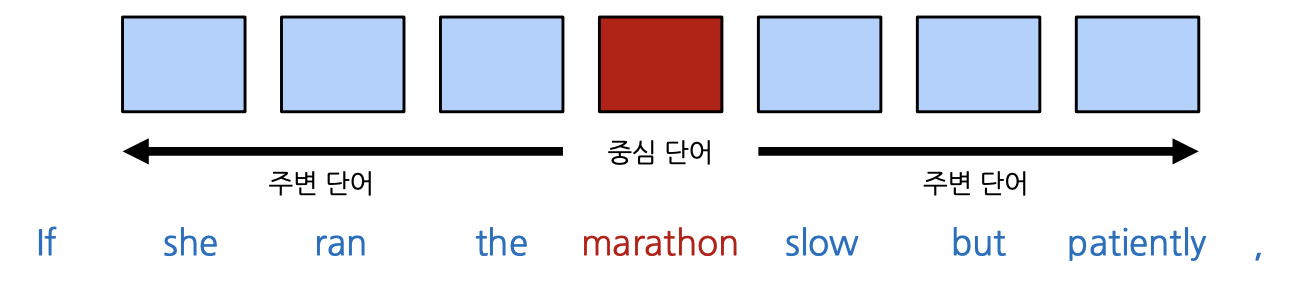
- 2-layer NN을 통해 예측을 수행
- Hidden Layer의 차원은 Vocab Size보다 훨씬 작은 수로 설정

- 예시 문장: "I study math"
- Vocab: {"math", "study", "I"}
- 입력-출력 쌍: (I, study), (study, I), (study, math), (math, study)
- 이웃한 단어의 Embedding은 높은 내적 값을 가져야 함
-> 'study' 벡터와 'math' 벡터의 내적은 높은 값
- Hidden Layer의 차원은 Vocab Size보다 훨씬 작은 수로 설정
2.3. 동작 과정

https://ronxin.github.io/wevi/
- 두 벡터의 평균을 내서 Word Embedding으로 사용하기도 하고, 만을 최종 벡터로 사용하기도 함.
- 후자가 더 일반적.
2.4. 속성
Summary

AI Safety 일짱이 되겠다.