1. Tokenization
Token (토큰): 자연어 처리 모델에 각 타임스텝마다 주어지는 입력 단위
- Tokenization (토큰화): 주어진 Text를 Token 단위로 분리하는 방법
- Vocalbulary (단어 사전): 모델이 처리할 수 있는 단어들
Tokenization은 크게 3가지 방식으로 구분
- 입력 예시:
"Tommorrow is Christmas"
- Word-level Tokenization
['Tomorrow', 'is', 'Christmas'] - Character-level Tokenization
['T','o','m','m','o','r','r','o','w',' ','i','s',' ','C','h','r','i','s','t','m','a','s'] - Subword-level Tokenization
['To', 'morrow', 'is', 'Christ', 'mas']
1.1. Word-Level Tokenization
-> Token을 단어 (Word) 단위로 구분
- 일반적으로 단어는 띄어쓰기 기준으로 구분
['Tomorrow', 'is', 'Christmas']
- 한국어에서는 형태소 기준으로 단어를 구분하기도 함.
['내일', '은', ' ', '크리스마스', '다']
단점
- 추론 단계에서, 학습 단계에서 보지 못한 단어, 즉 Vocab에 없는 단어가 등장하면 모두
Unknown토큰으로 처리함.- Out-Of-Vocabulary (OOV)
1.2. Character-Level Tokenization
-> Token을 철자 (Character) 단위로 구분['T','o','m','m','o','r','r','o','w',' ','i','s',' ','C','h','r','i','s','t','m','a','s']
장점
- 다른 언어라도 같은 철자를 사용한다면 Token으로 처리가 가능
- Word-Level Tokenization의 단점인 OOV 문제가 근본적으로 발생하지 않음.
단점
- Token의 개수가 지나치게 많아짐.
- 각 토큰이 유의미한 정보를 가지지 않아 성능이 낮음.
1.3. Subword-Level Tokenization
-> Token을 Subword 단위로 구분
'preprocessing' -> ['pre', 'process', 'ing]
- 방법론에 따라 Subword 단위는 다양하게 결정
- 예시: Byte Pair Encoding (BPE)
장점
- 한 단어에 포함된 여러 의미를 효과적으로 분리해 성능이 뛰어남
- Character-Level Tokenization에 비해 사용되는 Token의 개수가 적음
- Character-Level Tokenization과 마찬가지로 단일 Character도 Vocab에 포함하여 OOV가 발생하지 않음.
1.3.1. Byte Pair Encoding (BPE)
-> Subword-Level Tokenization의 대표적인 예시
- 철자들로만 이루어진 단어장을 구성한다.
- 가장 빈번하게 등장하는 n-gram 쌍을 Token으로 추가한다.
- 이를 사전에 설정한 최대 Vocab Size에 도달할 때까지 반복한다.
예시
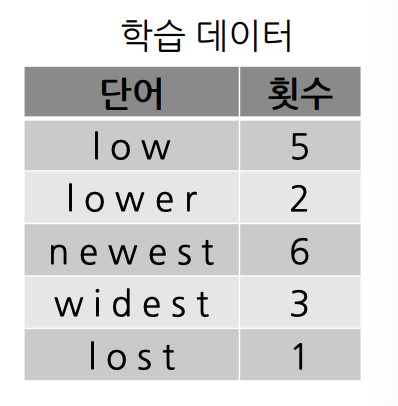
- BPE 결과로 생성된 Vocab:
[l, o, w, e, r, n, s, t, i, d, st, lo, est, low]
- 입력 예시:
"newest" - 입력된 String을 Character 단위로, 왼쪽에서부터 차례로 사전에 정의된 가장 긴 문자열을 토큰으로 매칭
1) Vocab에n으로 시작하는 길이가 3, 2짜리인 Subwordnew,ne가 없으므로 단일 길이의n을 token으로 매칭
2) Vocab에e로 시작하는 길이가 3, 2짜리인 Subwordewe,ew가 없으므로 단일 길이의e를 token으로 매칭
3) ... 이렇게w,est까지 매칭 - Tokenization 결과
[n, e, w, est]으로 인코딩됨.
1.4. Other Subword Tokenization Methods
WordPiece
- 학습 데이터 내의 Likelihood 값을 최대화하는 워드 쌍을 Vocab에 추가
- 활용 모델: BERT, DistilBERT, ELECTRA
SentencePiece
- 공백을 Token으로 활용
- Subword의 위치가 띄어쓰기 뒤에 등장하는지, 다른 Subword에 이어서 등장하는지 구분
- 활용 모델: ALBERT, XLNet, T5
Summary
- Tokenization이란?
- 대표적인 Tokenization 방법 3개는?
- 각 Tokenization의 장단점과 대표적인 알고리즘은?
- 참고 자료: 주재걸 마스터님 수업자료

AI Safety 일짱이 되겠다.