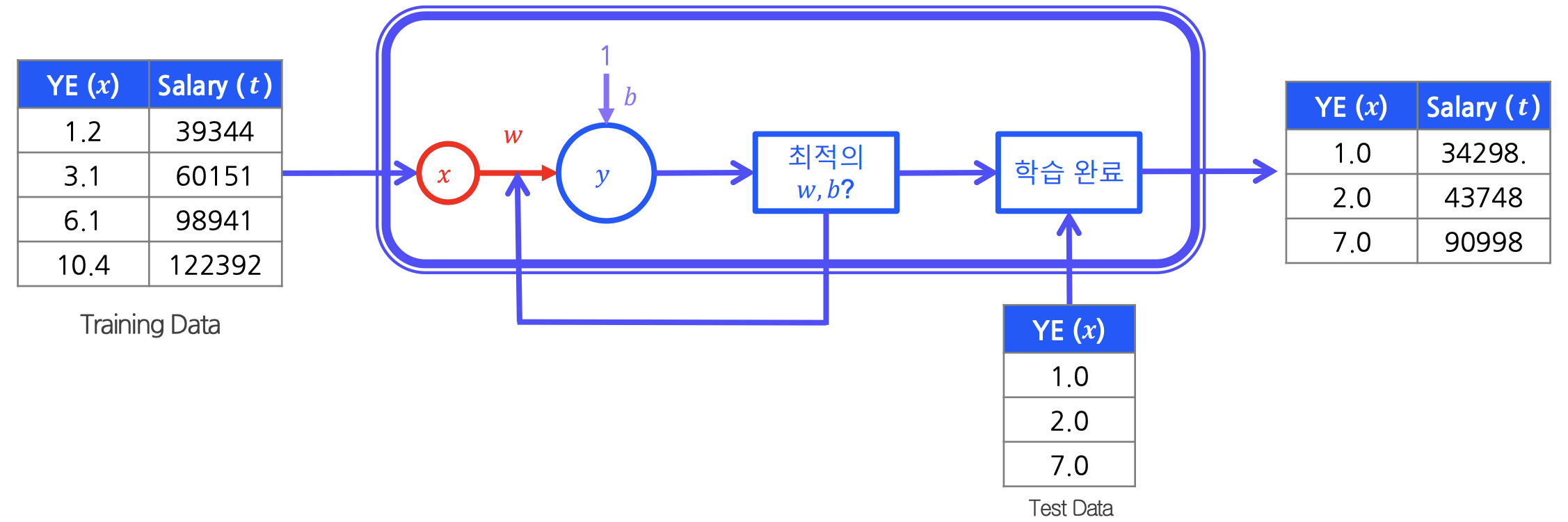
1. 선형 회귀 복습
2. 이진 분류 모델
이진 분류란?
- 주어진 트레이닝 데이터를 사용하여 특징 변수와 목표 변수 사이의 관계를 학습하고, 이를 바탕으로 새로운 데이터를 사전에 정의된 두 가지 범주 중 하나로 분류하는 모델을 구축하는 과정이다.
- 활용 예시:
- 붓꽃의 종류 분류: Iris-versicolor(1) 또는 Iris-setosa(0)
- 이메일 스팸 분류: Spam(1) 또는 Ham(0)
- 금융 사기 탐지: 사기 거래(1) 또는 정상 거래(0)
- 의료 진단: 암 조직(1) 또는 정상 조직(0)
트레이닝 데이터 구성
- 특징 변수: PetalLengthCm(꽃잎 길이)
- 목표 변수: Species(종류)
- Iris-setosa와 Iris-versicolor 두 종류만 필터링하여 이진 분류 문제를 구성

import pandas as pd
# 데이터 불러오기 (PetalLengthCm과 Species 열만 선택)
df = pd.read_csv("Iris.csv", sep=",", header=0)[["PetalLengthCm", "Species"]]
# Iris-setosa와 Iris-versicolor만 필터링
filtered_data = df[df['Species'].isin(['Iris-setosa', 'Iris-versicolor'])]
filtered_df = filtered_datadf['Species'].isin([...]): Species 열의 각 값이 리스트 내 값과 일치하면 True, 아니면 False를 가지는 Boolean Series를 반환한다. 이를 인덱싱에 사용하여 해당 행만 필터링한다.
목표 변수를 이산형 레이블로 매핑
Salary Dataset에서는 목표 변수가 연속형 값이었기 때문에 따로 변환이 필요 없었다. 하지만 Iris Dataset의 목표 변수는 텍스트 데이터이므로, 모델이 처리할 수 있도록 이산형 레이블(0, 1)로 매핑해야 한다.
# Iris-setosa → 0, Iris-versicolor → 1로 매핑
filtered_df.loc[:, 'Species'] = filtered_df['Species'].map({'Iris-setosa': 0, 'Iris-versicolor': 1})특징 변수와 목표 변수 추출
# 특징 변수: 2차원 배열로 추출
x = filtered_df[['PetalLengthCm']].values
# 목표 변수: 1차원 배열로 추출 후 정수형 변환
t = filtered_df['Species'].values.astype(int)[['PetalLengthCm']](이중 대괄호): DataFrame 형태를 유지하여 2차원 배열로 추출됨.['Species'](단일 대괄호): Series 형태로 1차원 배열을 추출함.
데이터 분할
데이터를 학습용과 평가용으로 분리한다.
- 트레이닝 데이터: 모델을 학습시키는 데 사용. 가중치와 바이어스를 최적화하기 위해 사용함.
- 테스트 데이터: 최종 모델의 성능을 평가하는 데 사용. 모델의 실제 성능을 확인하기 위해 사용함.
- 검증 데이터: 학습 과정 중 성능을 평가하는 데 사용. 매 에폭마다 과적합을 확인하기 위해 사용함.
from sklearn.model_selection import train_test_split
# 80% 학습, 20% 테스트로 분할 (random_state=42로 재현성 확보)
x_train, x_test, t_train, t_test = train_test_split(x, t, test_size=0.2, random_state=42)random_state=42에서 42는 "은하수를 여행하는 히치하이커를 위한 안내서"에서 유래한, 관습적으로 자주 사용되는 시드 값이다.
데이터 표준화
이진 분류 모델 구축에서도 데이터 표준화가 필요하다. 주의할 점은 fit_transform은 트레이닝 데이터에만 적용하고, 테스트 데이터에는 transform만 사용하는 것이다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train) # 트레이닝: 통계량 계산 + 표준화
x_test = scaler.transform(x_test) # 테스트: 트레이닝 통계량으로 표준화만Tensor 변환
x_train = torch.tensor(x_train, dtype=torch.float32)
x_test = torch.tensor(x_test, dtype=torch.float32)
t_train = torch.tensor(t_train, dtype=torch.float32).unsqueeze(1)
t_test = torch.tensor(t_test, dtype=torch.float32).unsqueeze(1)unsqueeze(1): 목표 변수를 1차원[N]에서 2차원[N, 1]로 변환한다. 이유는 다음과 같다.- 배치 처리를 위해 목표 변수의 형태가
[N, 1]이어야 함. - 특징 변수가
[데이터 수, 특징 수]로 이미 2차원이므로, 일관된 형태를 위해 맞춰줌. - 손실 함수가 2차원 Tensor 형태를 기대하므로 호환성을 위해 변환함.
- 배치 처리를 위해 목표 변수의 형태가
3. Dataset & DataLoader 클래스
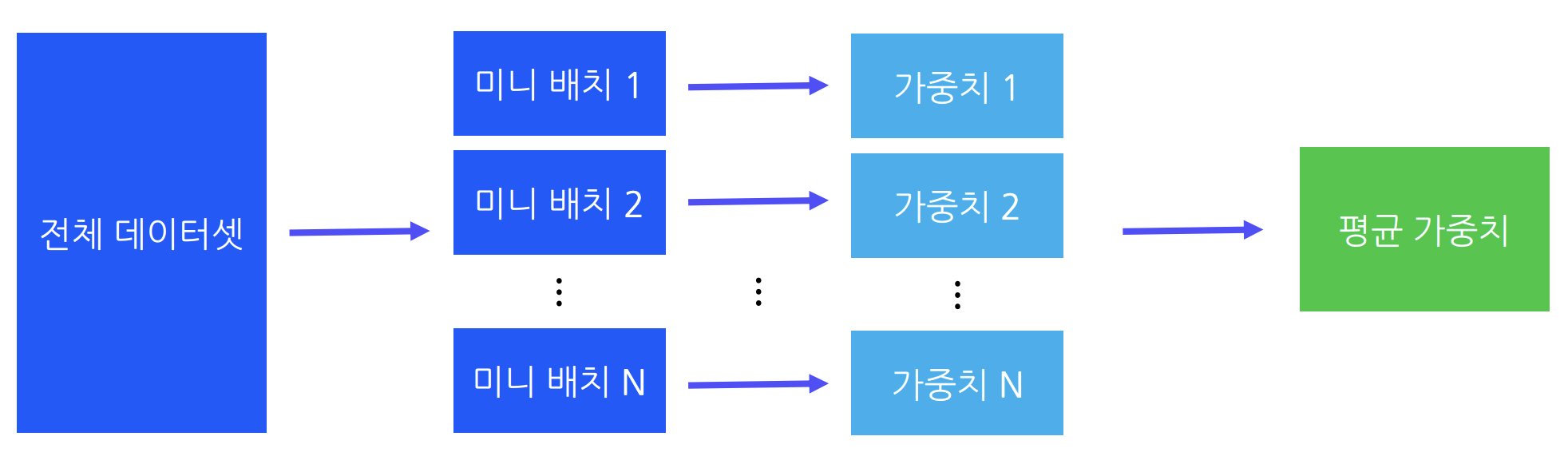
배치(Batch)란
배치란 머신러닝과 딥러닝에서 데이터를 처리하는 묶음 단위를 의미한다. 일반적으로 16, 32, 64개 등의 단위로 나눠서 모델에 입력한다.
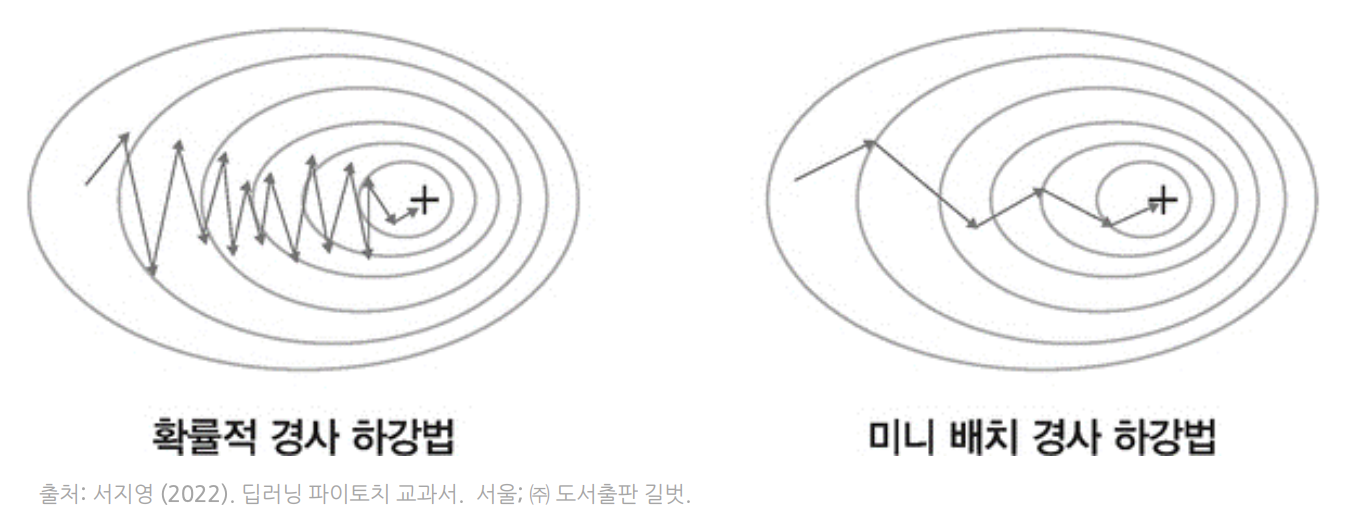
미니 배치 경사하강법
기존 경사하강법 알고리즘들의 장점과 단점을 비교하면 다음과 같다:
- 경사하강법(GD)
- 전체 데이터셋을 사용하여 가중치를 업데이트한다.
- 안정적이지만, 로컬 미니마 문제와 대규모 데이터셋에서의 계산 비용 문제가 있다.
- 확률적 경사하강법(SGD)
- 각 데이터 하나에 대해 가중치를 업데이트한다.
- 빠르고 메모리 효율적이지만, 노이즈가 많고 학습이 불안정함.
- 미니 배치 경사하강법
- 위 두 알고리즘의 장단점을 보완한 것이다.
- 데이터를 배치 단위로 묶어 확률적 경사하강법보다 노이즈를 줄여 안정적이고, 전체 데이터를 한 번에 사용하는 경사하강법보다 계산 속도가 빠르다.
Dataset 클래스
PyTorch에서 Dataset 클래스는 데이터셋을 정의하는 기본 클래스이다. Dataset을 상속받아 커스텀 데이터셋을 만들며, 다음 세 가지 메서드를 구현해야 한다.
__init__: 데이터를 초기화__len__: 데이터의 크기를 반환__getitem__: 특정 인덱스의 데이터 샘플을 반환
from torch.utils.data import Dataset, DataLoader
class IrisDataset(Dataset):
def __init__(self, features, labels):
self.features = features # 특징 변수 저장
self.labels = labels # 목표 변수 저장
def __len__(self):
return len(self.features) # 데이터셋 크기 반환
def __getitem__(self, idx):
return self.features[idx], self.labels[idx] # 인덱스에 해당하는 (특징, 레이블) 쌍 반환DataLoader 클래스
DataLoader 클래스는 Dataset 인스턴스를 감싸서 배치 단위로 데이터를 로드하고, 데이터 셔플 등의 작업을 수행한다.
- 모델 훈련 시에는 데이터 순서에 따른 편향을 줄이기 위해
shuffle=True로 데이터를 섞는다. - 모델 평가 시에는 데이터 순서를 유지하는 것이 일반적이므로
shuffle=False로 설정한다.
# CustomDataset 인스턴스 생성
train_dataset = IrisDataset(x_train, t_train)
test_dataset = IrisDataset(x_test, t_test)
# DataLoader 생성
batch_size = 4
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 훈련용: 셔플 O
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 평가용: 셔플 X4. 이진 분류 모델 (로지스틱 회귀)
로지스틱 회귀 알고리즘
로지스틱 회귀란 트레이닝 데이터의 특성과 분포를 바탕으로 데이터를 잘 구분할 수 있는 최적의 결정 경계를 찾아, 시그모이드 함수를 통해 이 경계를 기준으로 데이터를 이진 분류하는 알고리즘이다. 딥러닝의 기본적인 구성요소로 널리 사용된다.
- 트레이닝 데이터 에서 선형 결정 경계를 찾음
: - 시그모이드 함수를 통해 0~1 사이의 확률값으로 변환
: - 임계값(0.5)을 기준으로 이진 분류
: 이면 1, 이면 0
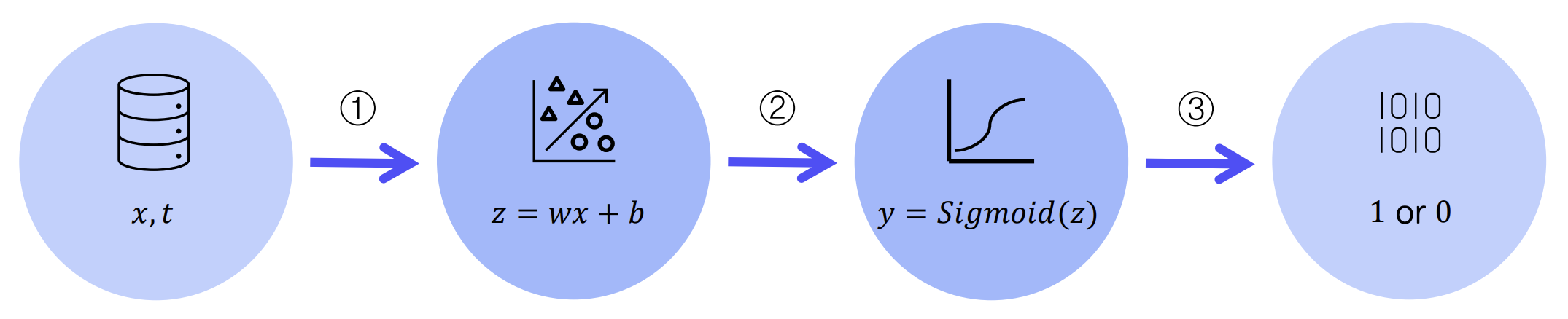
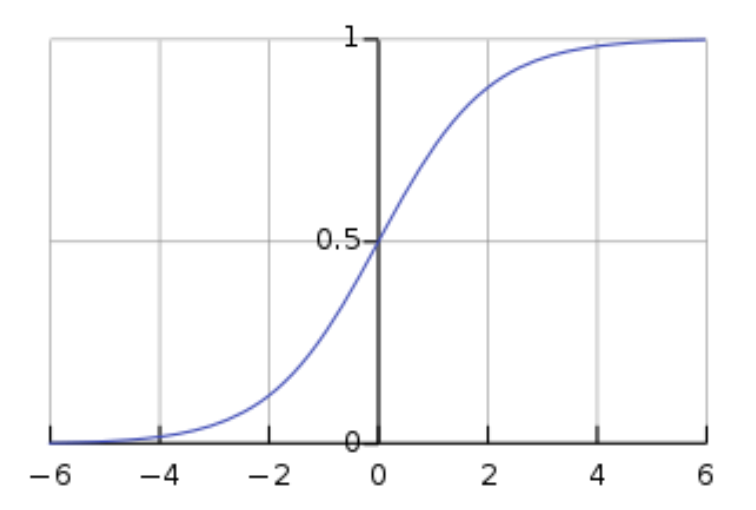
시그모이드 함수
시그모이드 함수는 비선형 함수로, 입력 값을 0과 1 사이의 값으로 변환한다.
- 출력이 0~1 사이이므로 확률로 해석 가능하다.
(예: 출력이 0.64면 해당 클래스일 확률이 64%) - 가 양의 큰 값이면 1에 가까워지고, 음의 큰 값이면 0에 가까워진다.
이진 분류 모델 구현
import torch.nn as nn
class BinaryClassificationModel(nn.Module):
def __init__(self):
super(BinaryClassificationModel, self).__init__()
self.layer_1 = nn.Linear(1, 1) # 입력 차원 1, 출력 차원 1인 선형 계층
self.sigmoid = nn.Sigmoid() # 시그모이드 활성화 함수
def forward(self, x):
z = self.layer_1(x) # 선형 변환: z = wx + b
y = self.sigmoid(z) # 시그모이드 적용: y = sigmoid(z)
return y
# 모델 초기화
model = BinaryClassificationModel()nn.Linear(1, 1): 입력 차원과 출력 차원이 모두 1인 선형 계층. 를 계산함.nn.Sigmoid(): 선형 계층의 출력 를 0~1 사이의 이진 분류 확률 로 변환함.forward(): 특징 변수 를 받아 선형 계층 → 시그모이드를 순차적으로 통과시켜 최종 이진 분류 확률을 반환함.
학습 정리
- 이진 분류란 특징 변수와 목표 변수(두 가지 범주) 사이의 관계를 학습하여, 새로운 데이터를 두 가지 범주 중 하나로 분류하는 과정이다.
- 데이터는 트레이닝, 테스트, 검증 데이터로 분할할 수 있다.
- PyTorch에서는 Dataset과 DataLoader 클래스를 사용하여 데이터 전처리와 배치 처리를 효율적으로 수행한다.
- 로지스틱 회귀는 선형 결정 경계 + 시그모이드 함수를 결합하여 이진 분류를 수행하는 알고리즘이다.

AI Safety 일짱이 되겠다.