
지금 이 그림을 보는 사람들은 도대체 이건 뭐지? 싶을 수도 있는데,,,,
사실 저건 이번주 월요일부터 사용하고 있는 목 디스크 소프트 칼라 즉, 목 보호대다...
목이 왼쪽으로 뱡향은 오른쪽에 비해 돌리는데 자주 문제가 있었고, 꾸준히 목을 스트레칭과 필라테스 학원에서 풀고 돌렸다. 하지만 도저히 왼쪽 목이 예전처럼 통증없이 시원하게 돌아가지 않았다.
2,3주 가까이 지속되고, 심지어 필라테스 학원에서 근력 운동시에도 한 쪽 목으로 인해서 힘을 쓰지 못하는 상황이 되었다. 병원을 다녀왔고, 결론적으로 목디스크 초기 증상일 확률이 높다는 소견을 받았다. 염증이 일단 심했고, 목 두께도 왼쪽이 더 두꺼운 상황이었다.
일단 월요일에 C-ARM, 프롤로 주사 치료를 받았고, 통증이 지속적이어서 물리치료를 앞으로 하기로 했다. 이 주사치료가 문제였는지 월요일에 주사 치료를 받고서, 3일간 내 목 같지 않은 느낌으로 살고 있다. 논문 스터디부터 Lv.1 피어세션까지 정말 통증을 넘어서서 그냥 목에 힘이 안 들어간다. 누워서 영상을 시청하고 있고, 앉아 있으면 도저히 힘이 들어가지 않는다. 지금 현재 포스팅 또한 월화수 컨디션이 너무 안 좋았기에 금요일에 하나씩 작성하고 있다. 금요일부터 주말 동안 제대로 공부하지 못한 것들을 다시 한 번 정리하고 나의 몸 컨디션을 하나씩 바로 잡아 보려고 한다.
Deep Learning - Historical Review

Denny Britz의 블로그 에 딥러닝이 최근까지 오는 있는데 있어서 중요했던 아이디어(논문, 연구 결과)에 대해 시간 순으로 정리되어 있다. 실제로 블로그에 연도 별로 정리되어있는데 실제 publish된 논문도 정리되어 있다. 간단하게 나열만 해보려고 한다.
(2012) - Tackling ImageNet with AlexNet and Dropout
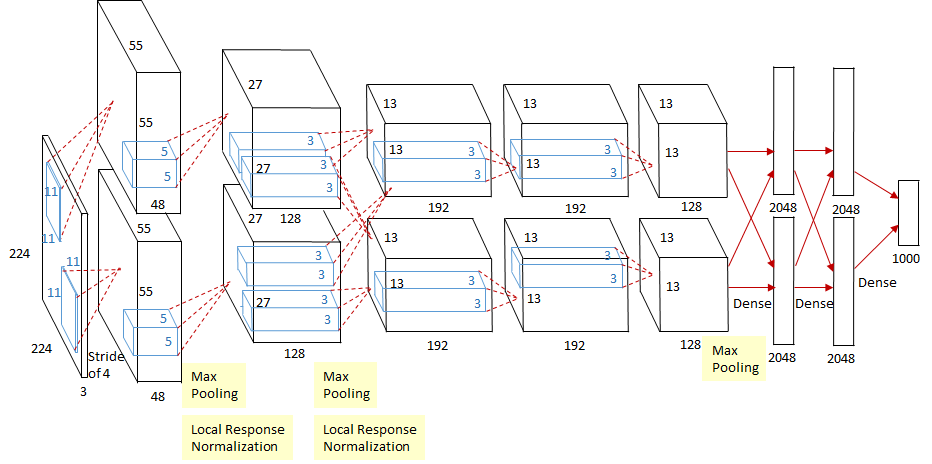
ImageNet 대회에서 처음으로 딥러닝 모델로 1등을 안겨준 AlexNet 모델이다. 어떻게 보면 지금까지 AI Boom을 일으킬수 있는 계기가 된 모델이 아닌가 싶다. AlexNet은 GPU 성능과 알고리즘 발전의 조합을 통해 ImageNet 데이터 세트의 이미지를 분류하는 데 있어 이전 방법보다 훨씬 뛰어났다. AlexNet은 또한 Dropout이 사용된 최초의 사례 중 하나였으며 이후 모든 종류의 딥러닝 모델의 일반화 능력을 향상시키는 데 중요한 구성 요소가 되었다. AlexNet에서 사용하는 architecture, sequence of Convolutional layers, ReLU nonlinearity, max-pooling은 미래의 Computer Vision 아키텍처가 확장되고 구축될 표준으로 받아들여졌습니다.
(2013) - Playing Atari with Deep Reinforcement Learning ; DQN
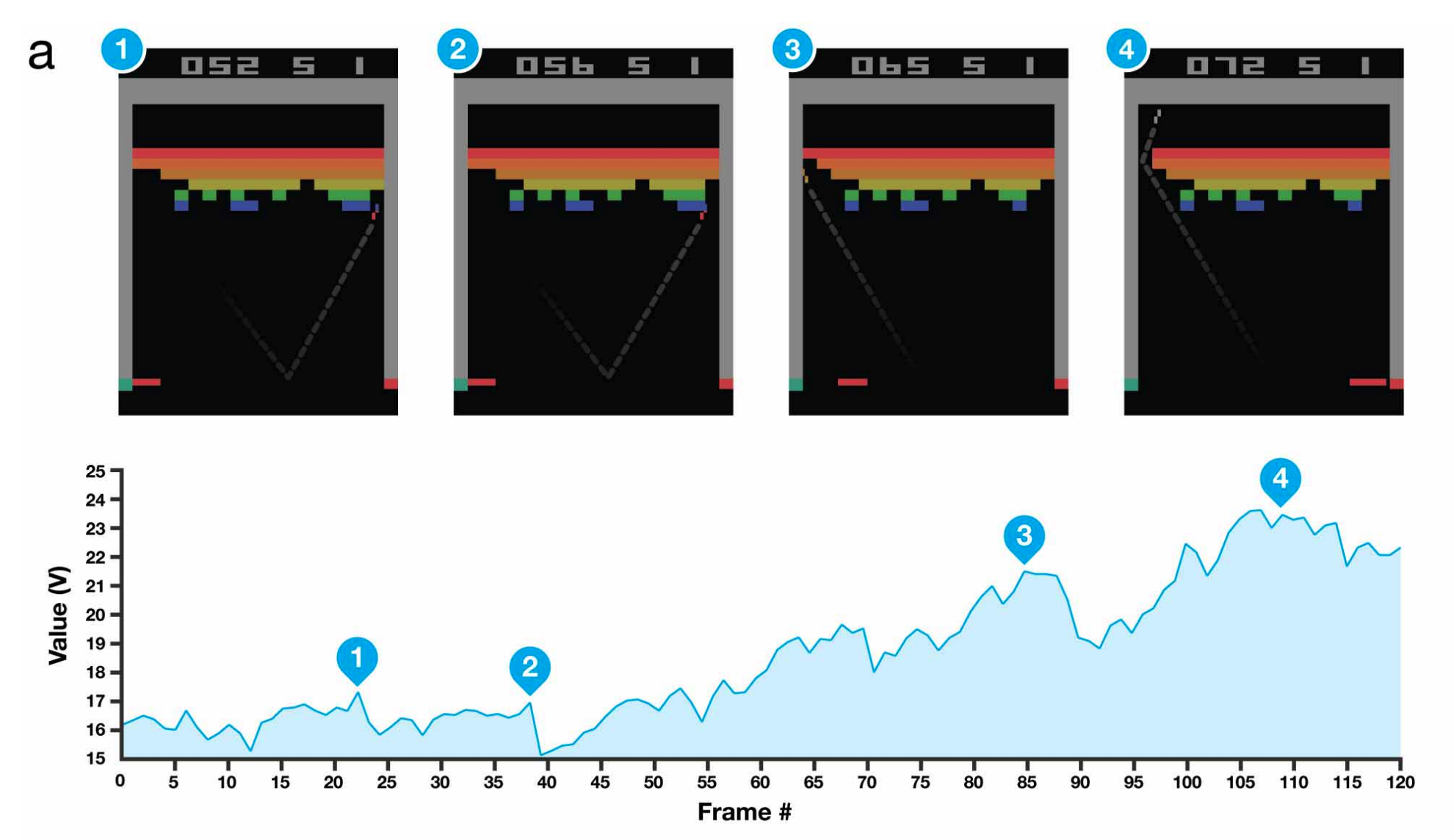
DQN은 오늘날의 DeepMind를 있게한 모델이다. 실제 유튜브 영상에 들어가면 강화학습 모델 DQN 모델이 학습 시간에 따라서 성능이 얼마나 향상되는지 확인할 수 있다. 이 연구는 기존 기술, GPU에서 훈련된 convolutional neural networks 및 experience replay을 몇 가지 데이터 처리 트릭과 교묘하게 결합하여 대부분의 사람들이 예상하지 못한 인상적인 결과를 얻었다. 후에 Go, Dota 2, Starcraft 2 에 Deep Reinforcement Learning technique을 적용하는 연구로 이어졌다.
(2014) - Encoder-Decoder Networks with Attention
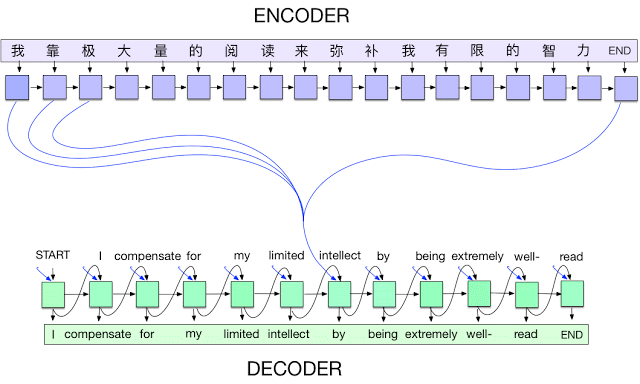
딥러닝의 적용이 이미지를 넘어서 문자열, 시퀀스 데이터로 트렌드가 변하면서 Encoder-Decoder 네트워크는 지금의 자연어 모델들이 있기까지 가장 중요한 부분이 되었다. 연구 논문("Sequence to Sequence Learning with Neural Networks")에선, 다층 장단기 메모리(LSTM)를 사용하여 입력 시퀀스를 고정 차원의 벡터에 매핑한 다음 또 다른 심층 LSTM을 사용하여 벡터에서 대상 시퀀스를 디코딩하였다고 한다. Seq-Seq 아키텍처에 대한 내용은 추후에 더 자세히 정리하려고 한다.
(2014) - Adam Optimizer
SGD 옵티마이저보다 나은 옵티마이저로 흔히 Adam를 그냥 결과가 좋으니까 쓴다고 표현한다. 학습률을 조정하는 옵티마이저라고 간단히 설명할 수 있을 거 같다.
(2015) - Generative Adversarial Networks ; GANs

- 생성의 시대가 왔고, 이미지 생성에서 가장 중요한 모델로 GAN을 뺄 수 없다. 판별기와 생성기 부분으로 구성되어 있다. 생성기의 목표는 실제 이미지와 생성된 이미지를 구별하도록 훈련된 판별기를 속이는 샘플을 생성하는 것이다. 시간이 지남에 따라 판별자는 가짜를 더 잘 인식할 수 있지만 생성자는 판별자를 더 잘 속일 수 있으므로 더욱 현실적으로 보이는 샘플을 생성할 수 있다.
- GAN의 첫 번째 반복은 흐릿한 저해상도 이미지를 생성했으며 훈련하기에 상당히 불안정했다. 시간이 지남에 따라 DCGAN(Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks), Wasserstein GAN, CycleGAN(Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks), StyleGAN(v2)과 같은 변형 및 개선이 이루어졌다.
(2015) - Residual Networks ; ResNet
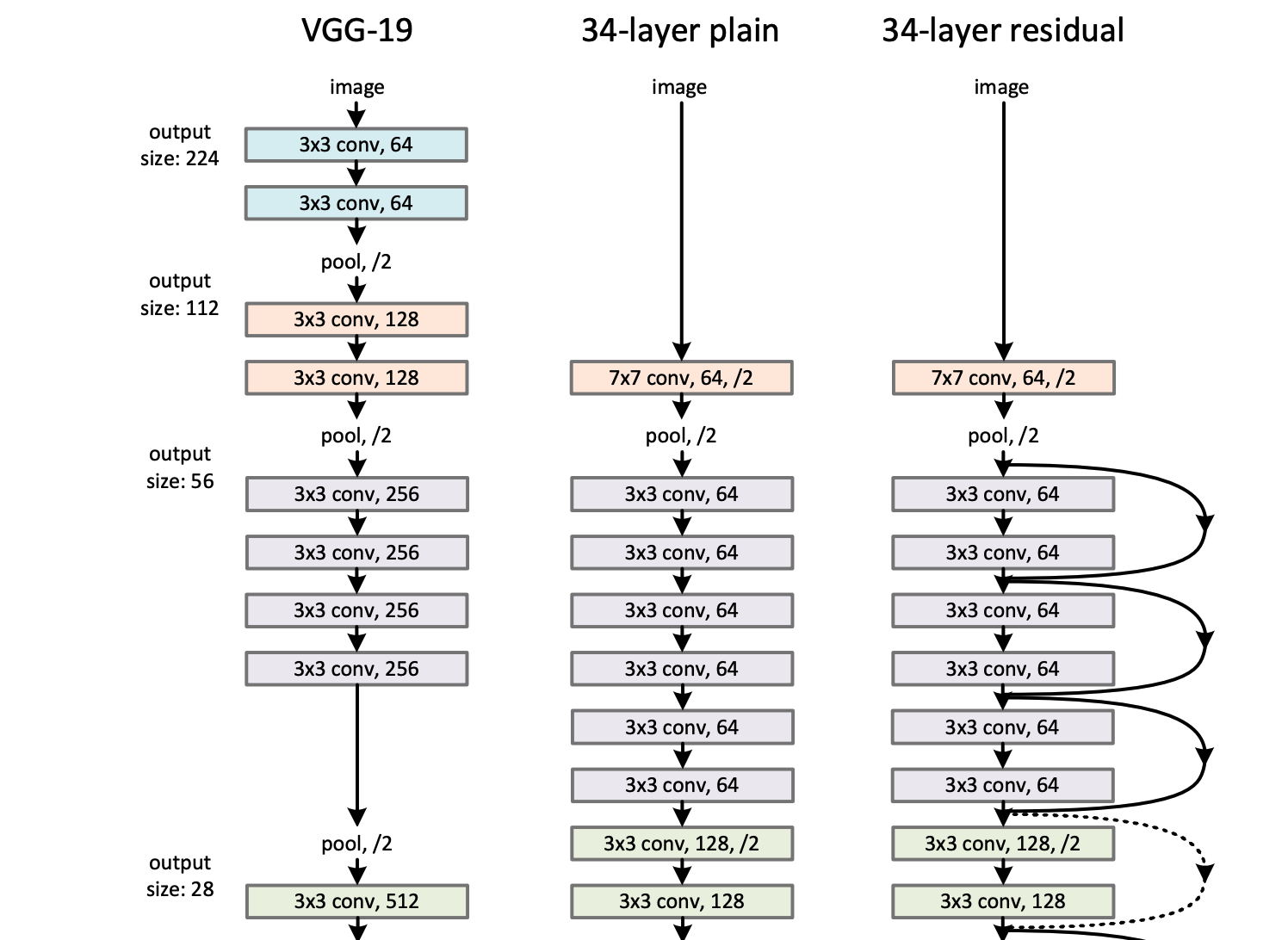
흔히 딥러닝 레이어 아키텍처 이미지를 구글에서 검색하면, 엄청난 수의 layer을 쌓은거 같은 모델 아키텍처 사진이 검색된다. 대다수는 ResNet 이전의 깊은 신경망 모델이거나, ResNet 모델일거다. ResNet 모델은 기존의 주장("Layer을 깊게 쌓으면 train 성능은 오르지만, test 성능은 더 이상 오르지 않는다")을 해결하는 계기가 되었다. ResNet 모델은 layer을 깊게 쌓아도 테스트셋 성능을 보장한다.
(2017) - Transformers
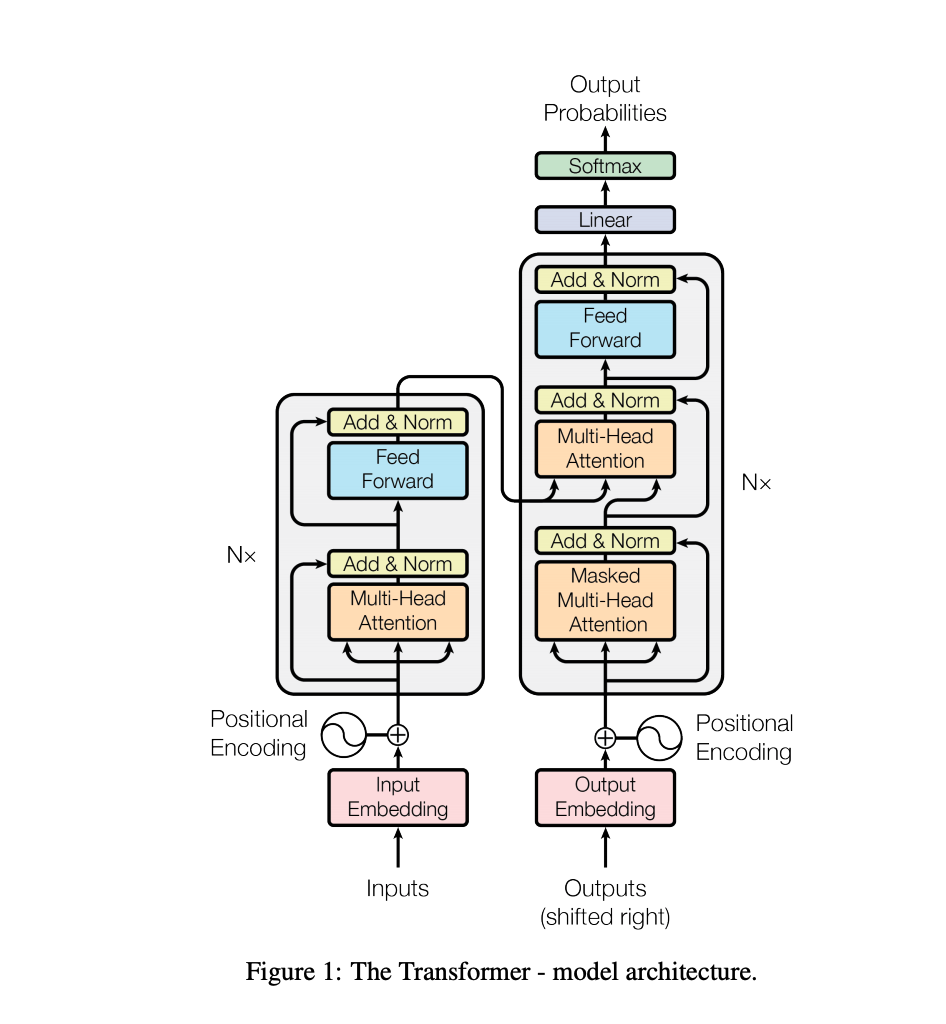
"Attention is all you need"논문으로 유명한 Transformer를 구글에서 2017년에 발표했고 딥러닝의 역사를 Transformer 이전과 이후로 봐도 되지 않을까 싶다. 위의 저 복잡한 아키텍처는 항상 볼 때마다 정말 어렵지만... 하나하나 논문 리뷰를 통해서 추후 벨로그에 정리하려고 한다.
사실상 2017년 이후에 나온 모델 중에 T로 끝나는 모델은 거의 다 Transformer 기반 모델이다.
(2018) - BERT and fine-tuned NLP Models
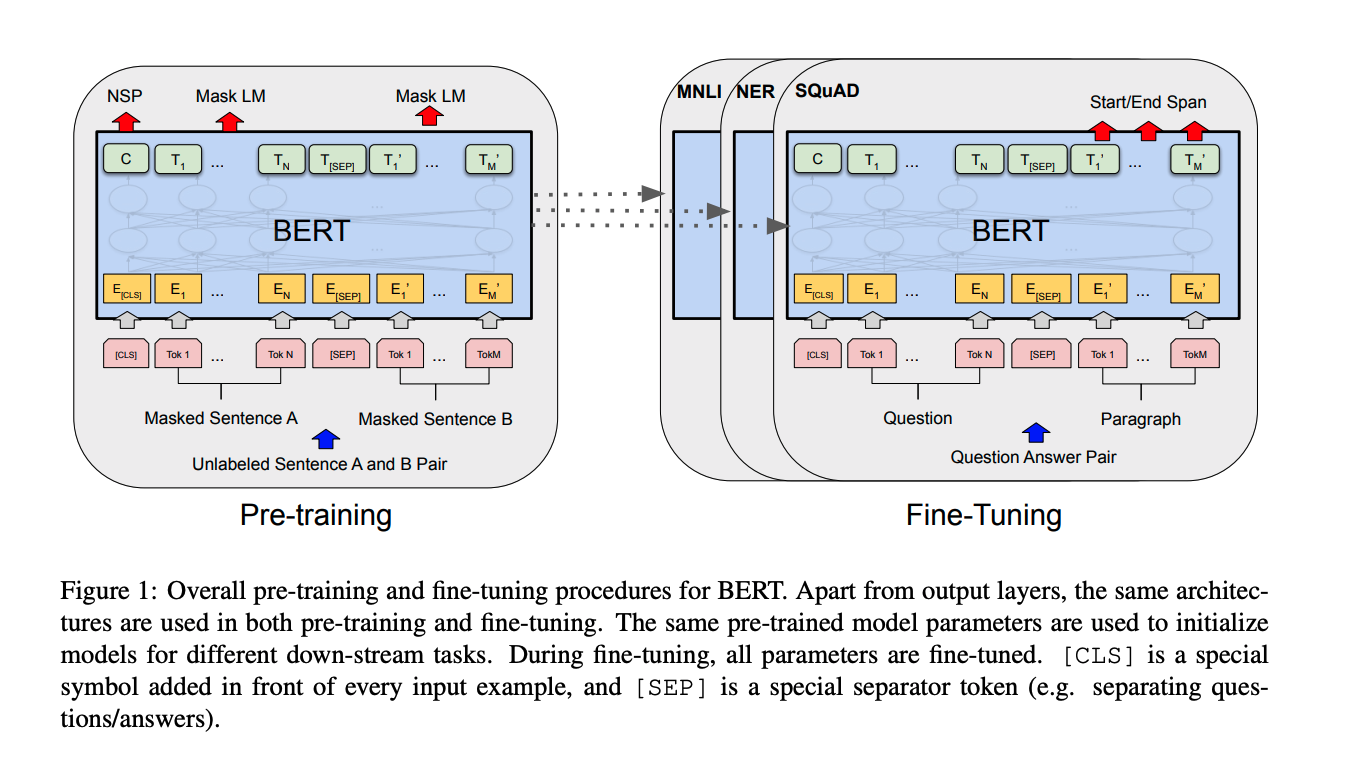
점점 발전하는 컴퓨팅 파워와 함께 대규모 데이터셋 학습으로 범용적 모델을 만들기 시작했다. Pre-trained 모델에 내가 원하는 Task에 대해서 fine tunning을 시켜 모델을 만드는 과정이 지금은 흔한 일이 되어 버렸다. BERT, GPT 같은 fine-tuned NLP Model들이 등장하였다.
(2019) - BIG Language Models
LLM(Large Language Model)같은 방대한 양의 텍스트 데이터를 학습한 모델들이 대거 출현하였다. 이러한 추세는 OpenAI의 거대한 1,750억 매개변수 언어 모델인 GPT-3이 단순한 훈련 목표와 표준 아키텍처에도 불구하고 예상외로 좋은 일반화 능력을 보여주면서 현재 2023년까지 지속되고 있다. 하지만, LLM 모델의 시대가 오면서 대학, 연구 기관의 연구는 기업의 연구 성과를 도저히 따라갈 수 없는 수준이 되어버렸다고 생각한다.
(2020) - Self-Supervised Learning?
동일한 경향을 활용하는 것은 contrastive self-supervised learning(SimCLR) 같은 접근 방식이다. 레이블이 지정되지 않은 데이터를 더 효과적으로 활용하는 SimCLR 모델이 더 커지고 훈련 속도가 빨라짐에 따라 웹에서 레이블이 지정되지 않은 방대한 데이터 세트를 효율적으로 사용하고 다른 작업으로 전송할 수 있는 범용 지식을 학습할 수 있는 기술이 더욱 가치 있고 널리 채택되고 있다.
✨Genealization Gap
❗Training error와 test error의 차이로 인해 실제 테스트 결과가 검증 결과와 차이가 생기는 것
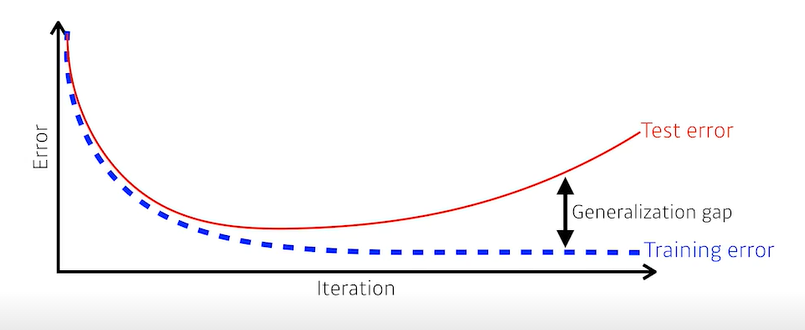
- 새로운 데이터에 대해서도 예측 성능이 잘 나온다는 것은 말 그대로 Generalization Gap이 작다는 것이고, Generalization Performance 가 높다는 것이다.
- Generalization Performance가 잘 나오는 점이 모델 선택에 있어서 중요하다고 본다.
🤔 Bias and Variance Trade-Off with Overfitting, Underfitting
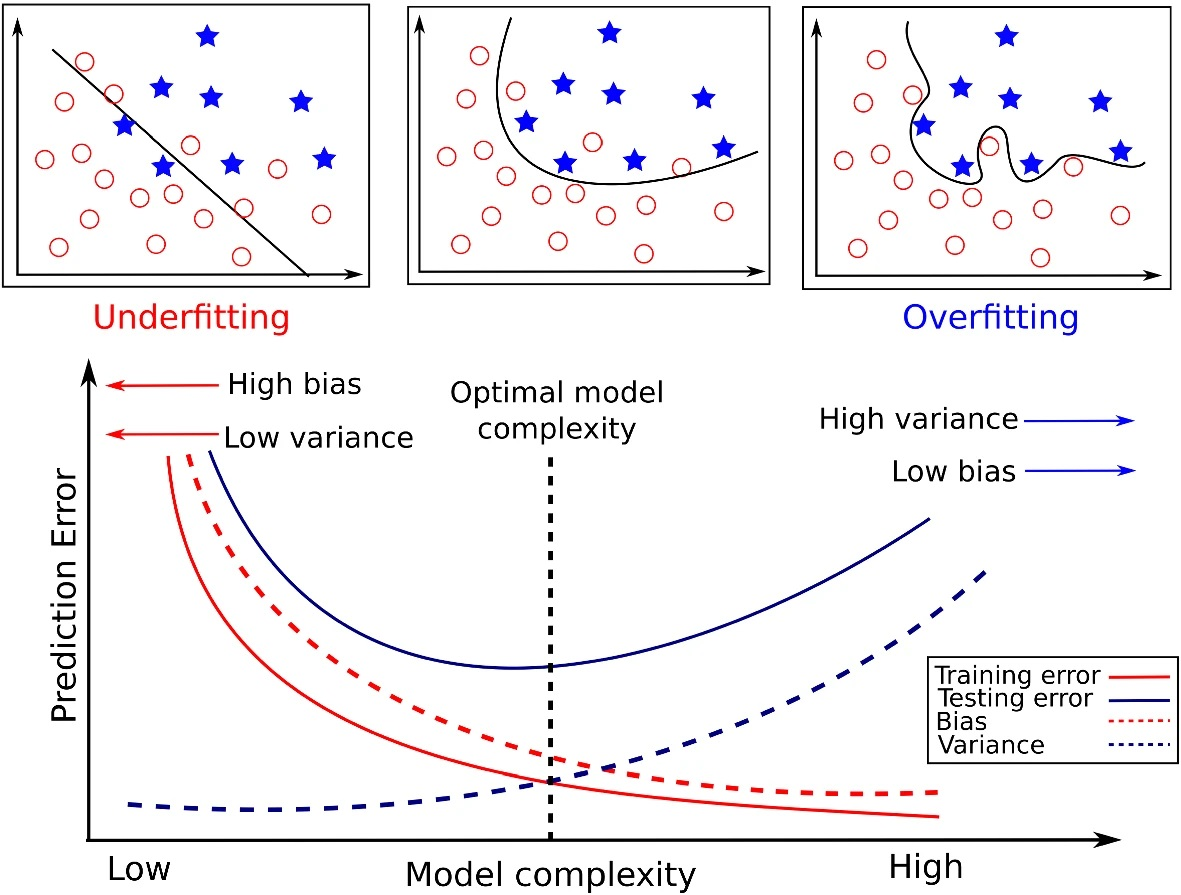
-
Variance(분산)는 데이터의 작은 변화에 대한 모델의 민감도인데, 모델이 훈련 데이터에 대해 이미 알고 있기 때문에 테스트 데이터에 변경이 발생하고, 따라서 분산이 높다는 것은 테스트 오류가 높다는 것을 의미한다.
high variance => high test error => Overfitting
-
모델의 bias(편향)가 높으면 훈련 및 테스트 성능이 모두 저하된다. 예를 들어 항상 일정한 예측을 출력하는 모델은 편향이 높고(문제가 있을 수 있음) 분산이 낮고 분산이 0이다. 이 경우에는 낮은 테스트 오류를 기대하지 않는다.
-
variance와 bias는 trade-off 관계기 때문에 적절한 optimal 지점을 찾는게 중요하다.
🤔 Bagging vs Boosting vs Voting
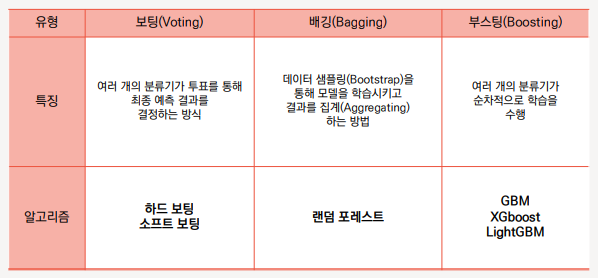
앙상블(Ensemble)
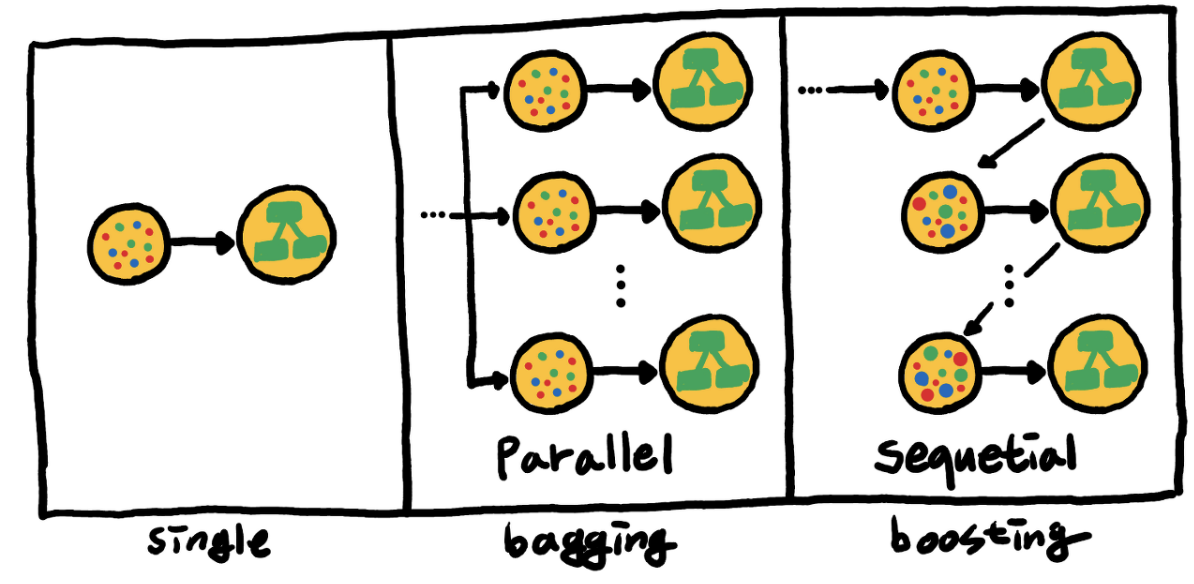
앙상블은 여러 개의 의사 결정 트리(Decision Tree)를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신러닝 기법이다. 앙상블 학습의 핵심은, 여러 개의 약 분류기(Weak Classifier)를 병렬 또는 직렬로 결합하여 강 분류기(Strong Classifier)로 만드는 것이다.
- 배깅(Bagging) : 동일 알고리즘의 약 분류기를 병렬로 사용
- 부스팅(Boosting) : 동일 알고리즘의 약 분류기를 직렬로 사용
- 보팅(Voting) : 다른 알고리즘의 약 분류기를 병렬로 사용
1) Bagging
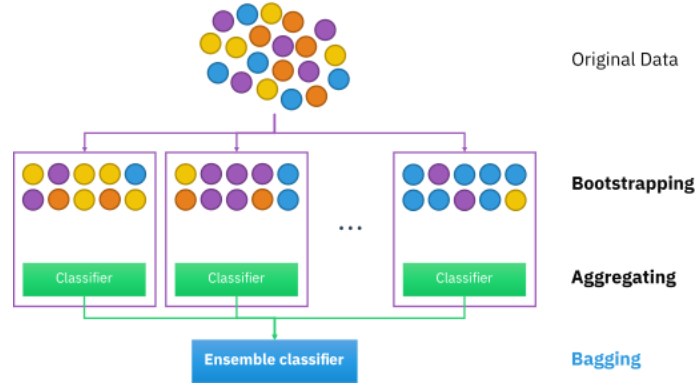
- 배깅(Bagging) = Bootstrap aggreagting (즉, 부트스트랩을 집계함)
- 원본 데이터를 random sampling해, 크기가 동일한 n개의 샘플 데이터(bootstrap)를 생성
- 각 샘플 데이터를 기반으로 동일한 알고리즘 기반의 모델을 병렬적으로 학습,각각의 분류기들이 학습시 상호영향을 주지 않은 상황에서 (독립적으로) 학습함
- 각 모델의 학습 결과를 결합하는 방식입니다.
- <학습 결과를 결합 방법>
- 회귀 문제라면 평균(average)
- 분류 문제라면 다중 투표(majority vote)
- 장점 : 배깅(Bagging)은 부트스트랩(bootstrap)을 집계(Aggregating)하여 학습 데이터가 충분하지 않더라도 충분한 학습효과를 주어 높은 bias의 underfitting 문제나, 높은 variance로 인한 overfitting 문제를 해결하는데 도움을 줌
2) Boosting
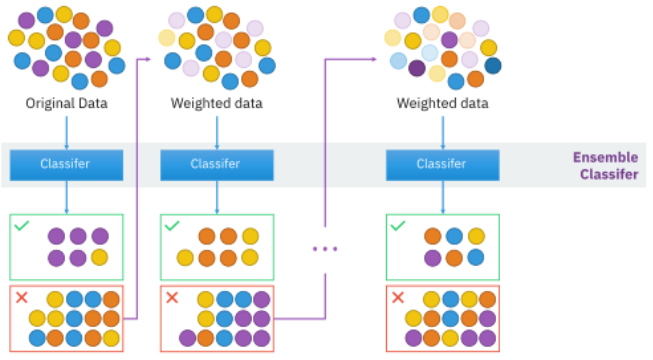
- 순차적으로, 복원추출로 가중치를 줌
- 부스팅(Boosting)의 경우도 Bagging과 크게 다르지 않으며 거의 동일한 매커니즘을 갖고 있음
- 이전 분류기의 학습 결과를 토대로 다음 분류기의 학습 데이터의 샘플 가중치를 조정해 학습을 진행하는 방법
- 일반적으로 오답에 대해 높은 가중치를 부여하므로 정확도가 높게 나타남
- 하지만 그렇기 때문에, outlier에 취약할 수 있음
3) Voting
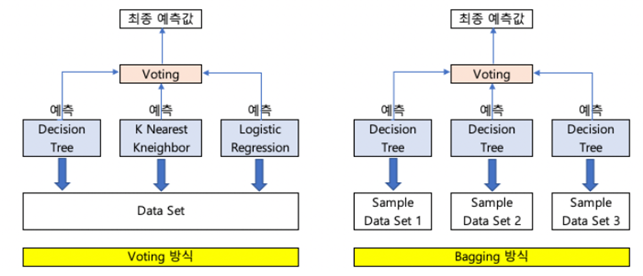
- Bagging 은 동일한 알고리즘 기반의 여러 weak learner를 사용
- Voting 은 다른 알고리즘 기반의 여러 weak learner를 사용
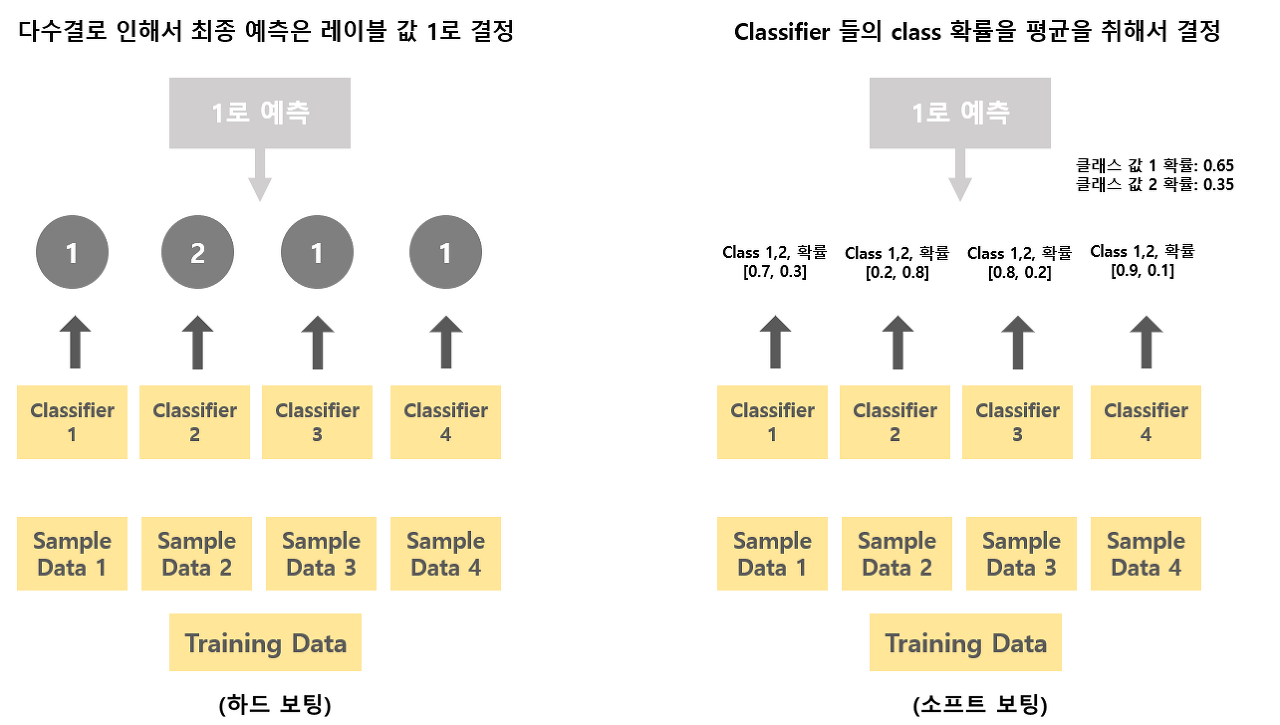
Soft voting, Hard voting
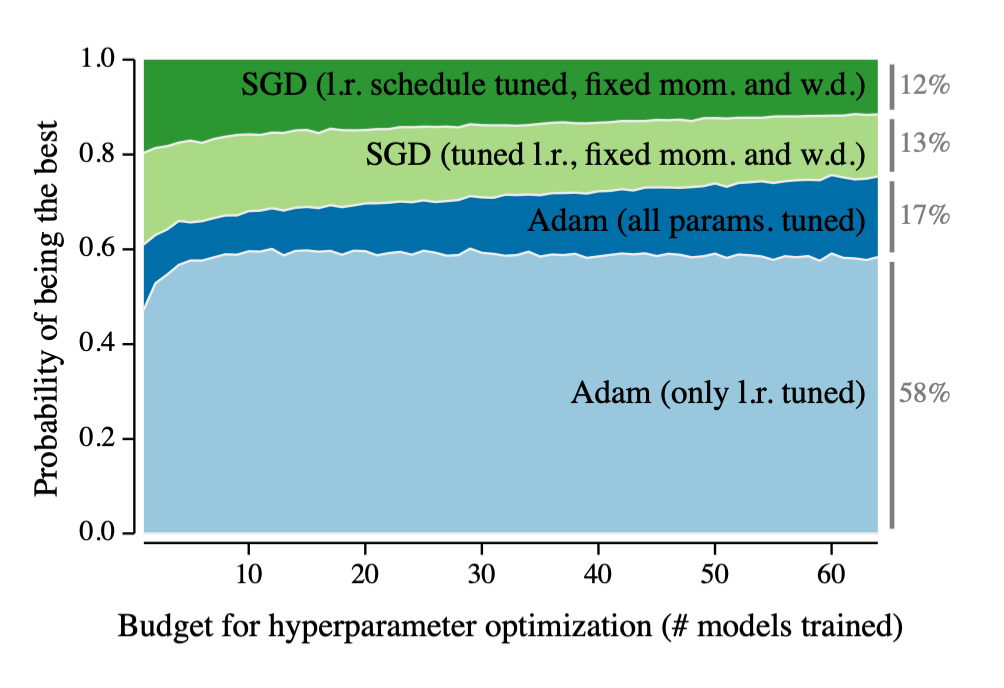
🙄 Adam Optimizer를 왜 가장 많이 쓰나?
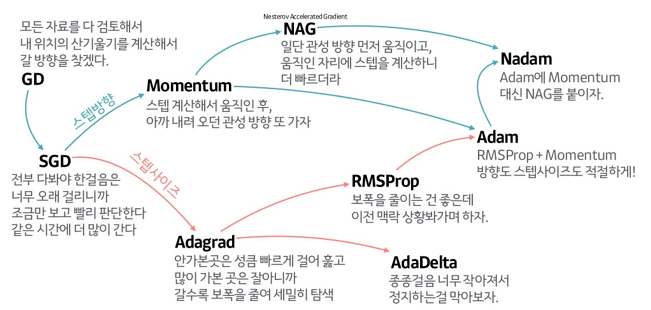
Optimizer의 발전사를 보여주는 위 그릠을 보면 Adam이 가장 best 모델로 보이고, 여러 강의에서도 Adam은 가장 결과가 잘나오니까 Adam을 그냥 써요,, 라고 하는데,
Adam Optimizer가 정확히 어떠한 계산으로 작동하는지, 그래서 왜 결과가 다른 Optimizer보다 좋은지 알고 싶어서 논문을 실제로 읽어보기로 했다.
❗논문 리뷰를 정리하고 있는 내 벨로그에 이 부분을 정리하였다.
🔖 Reference
bias-variance-trade-off
(ML)배깅,부스팅,보팅 차이
(DL)배깅,부스팅,보팅 차이
