
일주일의 부캠을 끝냈다. 월요일을 맞았지만 날씨도 급격하게 추워지면서 피곤은 말할 수 없을 정도로 심해졌다.
다행인 점은 이번주 강의는 전보다 확연히 적다는 것이다. 6시간 정도면 모든 일주일치의 강의를 수강할 수 있기에, 저번주에 제대로 못 정리했던 강의를 하나하나 다시 보면서 벨로그를 채워 나가려고 한다.
📖공부내용 간단 정리
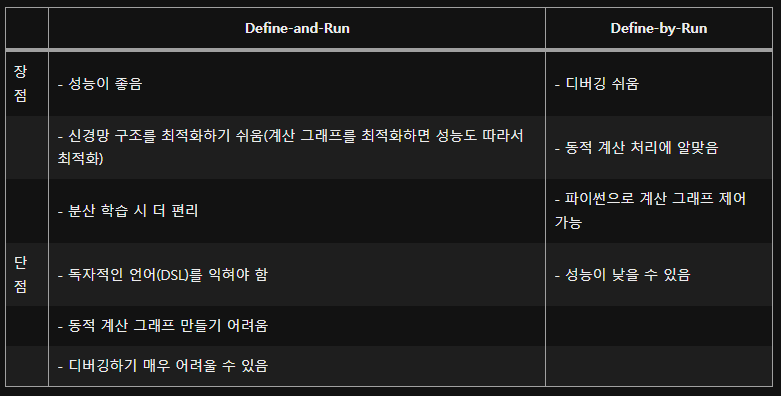
Define and Run 방식과 Define by Run 방식
텐서플로우(TensorFlow)와 파이토치(PyTorch)와의 가장 큰 차이이지 않을까 싶은데 강의자료 만으로는 이해가 완벽하지 않아서 좀 더 찾아보았다.
파이토치는 Define by Run 방식으로 동작하는데, 연산 정의와 값 초기화가 동시에 되는 것입니다.
동적 계산 그래프 방식인데, 데이터를 흘려보냄으로써 계산 그래프 정의하고 데이터 흘려보내기와 계산 그래프 구축이 동시에 이루어진다.
ex) 파이토치, MXNet, DyNet, 텐서플로(2.0 이상)
반면에 텐서플로우는 Define and Run 방식으로 동작하는데, 먼저 모델을 만들어주고 값을 따로 다 넣어주는 방식이다. 정적 계산 그래프 방식인데, 계산 그래프를 정의한 다음 데이터를 흘려보내는 식으로 계산 그래프 정의하고 컴파일하고 데이터 흘려보내기는 식으로 진행된다.
(실제 데이터가 아닌 기호를 사용하여 추상적인 계산 절차를 코딩해야 하기 때문에 기호 프로그래밍이라고 함)
CUDA ?
파이토치에서 GPU를 쓸 수 있게 되면서, CUDA라는 단어를 많이 들어봤을 것이다.
CUDA (Computed Unified Device Architecture)는 NVIDIA에서 개발한 GPU 개발 툴이다. 사실 CUDA는 c, c++기반으로 짜여진 완전 기초적 H/W 접근을 해야하는데, 많은 연구자들이 딥러닝에 사용할 수 있도록, 쉽게 설치할 수 있도록 오픈하였다. 현재는 nvidia-driver, CUDA, CUDNN만 설치하면 딥러닝을 쉽게 사용할 수 있다.
기존의 컴퓨터 연산은 CPU를 사용하고, RAM에 의존하여 연산을 진행하였다. CPU를 이용한 연산은 대부분 Single-Core(Human-Brain)를 사용하고 MultiProcessing, Multi-Threading 등을 이용하여 CPU가 보유한 코어 갯수 만큼의 Multi-Core를 이용하여 연산을 할 수 있다. 일반적으로 딥러닝에서 사용하는, 특히 pytorch나 tensorflow 에서, data loader 파트에서, core 갯수를 주고 데이터 loading 하는 부분이 여기에 속한다.
이에 반해 GPU는 Core 갯수가 엄청나다. CPU는 8~16개인데 비해 GPU는 몇 천개 이상이다. 즉 이를 이용한 Many-Core dependent 연산을 진행하고, Video RAM에 있는 데이터를 연산한다.
많은 연구자들이 사용하는 python, matlab 같은 경우 행렬 연산을 사용할 수 밖에 없다. 이 때 쓰이는 것이 재귀연산 (recursive 연산)인데, 이 함수는 '직렬' 연산을 해야한다. 하지만 이런 경우가 아니고 단순 계산, 예를 들어 backpropagation을 진행하며 보는 미적분 같은 경우 병렬 연산을 해주는 것이 훨씬 효과적이다.
- 어떻게 gpu를 사용하는가?
tensorflow에서는 1.15 이후의 버전부터는 gpu에 자동으로 tensor들이 할당되지만 pytorch에서는 gpu에 해당 tensor를 올리라고 코드를 작성해야한다.
# tensor를 gpu에 할당하는 3가지 방법 ("cuda" -> default cuda device (default gpu device))
x = torch.tensor([1., 2.], device="cuda")
x = torch.tensor([1., 2.]).cuda()
x = torch.tensor([1., 2.]).to("cuda")
# 현재 개발 환경에서 cuda 사용이 가능한 경우, tensor를 cuda 버전으로 변경합니다.
if torch.cuda.is_available():
x_data_cuda = x_data.to('cuda')View와 Reshape의 차이
- torch.view()

torch.view()를 보면 마치 b가 a의 메모리를 그대로 가져왔나 싶다. 그 이유는 torch.view()는 원래 텐서의 뷰를 생성하기만 하는 것이기에, 새 텐서는 항상 데이터를 원래 텐서와 공유하기 때문이다. 즉, 원래 텐서를 변경하면 재구성 된 텐서가 변경되고 그 반대도 마찬가지이다.view는 contiguous 속성이 만족되지 않는 경우 일부 사용이 제한될 수 있습니다.
특히, 새 텐서가 항상 원본과 데이터를 공유하도록 하기 위해 torch.view()는 두 텐서의 모양에 몇 가지 연속성 제약 조건(Contiguous)를 따지는데 뒤에서 얘기하겠지만, torch.view()는 contiguous 속성이 만족되지 않는 경우 일부 사용이 제한될 수 있다.
- torch.reshape()
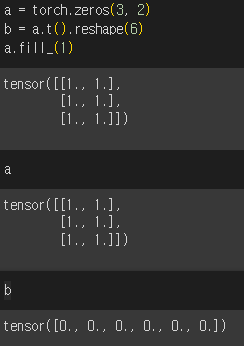
torch.reshape() 을 보면 마치 파이썬의 deepcopy() 같은 느낌이 난다. b는 a를 그냥 copy만 해서 온 느낌이다. torch.view()와 달리 torch.reshape()는 연속성 제약을 부과하지 않기 때문이다. 쉽게 말하자면 데이터 공유를 보장 하지도 않는다는 거다. 즉, 새로운 텐서는 원래 텐서의 view 일 수도 있고, 완전히 새로운 텐서일 수도 있다.
- Tensor의 contiguous(연속성) ??
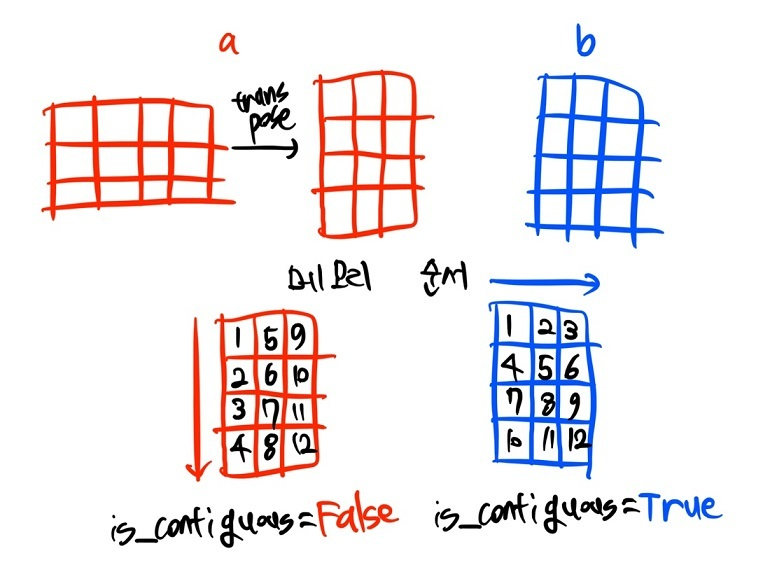
위의 그림이 가장 확실한 설명이지 않을까 싶다.
여기서, b처럼 axis 순서대로 자료가 저장된 상태를 contiguous = True 상태라고 부르며, a같이 자료 저장 순서가 원래 방향과 어긋난 경우를 contiguous = False 상태라고 한다.
텐서의 shape을 조작하는 과정에서 메모리 저장 상태가 변경되는 경우가 있는데, Tensor.narrow(), Tnesor.view(), Tensor.expand(), Tensor.transpose() 등 메소드를 사용하는 경우에 메모리 저장 상태가 변경되어 contiguous를 만족하지 않게 된다.
✨ 관련 메소드
Tensor.stride() : 데이터의 저장 방향을 조회
Tensor.is_contiguous() : contiguous = True 여부도 확인
Tensor.contiguous() : contiguous 여부가 True인 상태로 메모리 상 저장 구조를 바꿈
❗텐서의 모양을 변경하고 싶다면, torch.reshape()를 사용하는게 가장 잘 작동할거다.
❗만약, 메모리 사용량도 염려하고 두 텐서가 동일한 데이터를 공유하도록 하려면 torch.view()를 사용하는게 나을 거 같다.
🔖 Reference
Define-by-Run
CUDA (쿠다) 란, 왜 사용하는 것인가.
Pytorch에서 GPU 사용하기
torch.view, torch.reshape의 사용법과 차이 비교
contiguous 원리와 의미
pytorch에서 reshape와 view 간에 차이점은 무엇입니까?
