1. Seq2seq Model
1.1 Seq2seq 개요
- RNN에서 many-to-many(입력 출력 둘다 sequence)에 해당되는 모델이다. 입력 문장을 읽어오는 부분을 'encoder', 출력 문장을 생성하는 부분을 'decoder'라고 한다. 인코더 디코더 둘다 RNN 모델이다.
- 인코더와 디코더 각각의 파라미터는 다르다. 파라미터를 공유하지 않는다.
- 인코더 들여다보면 LSTM을 쓴 것을 알 수 있다.
1.2 Seq2seq 모델의 구조
-
인코더의 마지막 타임 스텝의 hidden state vector는
디코더 RNN의 , 즉 첫번쩨 타임 스텝의 입력으로 주어지는 역할을 한다. (디코터의 입장에서는 이전 타임 스텝의 hidden state vector로서의 역할을 해주는 것이다.) -
디코더의 가장 첫 타임 스텝에 SOS (Start of Sequence) 토큰의 word embedding vector을 입력값(input)으로 주면 결과값을 생성하기 시작하고, EOS(End of Sequence) 토큰이 디코더의 출력값(output)으로 나오면 생성을 멈추게 된다.
-
디코터 RNN은 디코더 RNN의 마지막 hidden state vector와 SOS 토큰의 word embedding vector를 입력으로 받는다. 이것으로 디코터의 hidden state vector를 만들고 그 hidden state vector를 다음 단어 예측에 사용한다.
1.3 Attention이 등장한 배경
- hidden state vector의 dimension이 RNN의 특성상 고정되어 있어 인코더의 마지막 타임스텝의 hidden state vector에 앞의 많은 정보를 다 우겨넣어야 했다.
- 또한 아무리 LSTM이 long term dependency를 해결했다 해도 앞쪽의 정보는 LSTM 구조를 지나면서 정보가 소실되기도 했다.
- ex) I go home (기계 번역)
여기서 주어 I 가 가장 먼저 나와야 하는데 가장 앞쪽 정보인 I가 유실될 수 있어 정작 첫번째 단어부터 잘 번역해내지 못해 번역 품질이 낮아지기도 했다.
따라서 attention이 나오기 전 연구자들의 트릭으로는 차라리 문장 순서를 뒤집어서 초반 정보가 hidden state 에 잘 담기게끔 하는 방법이 있었다.
2. Seq2seq Model with Attention
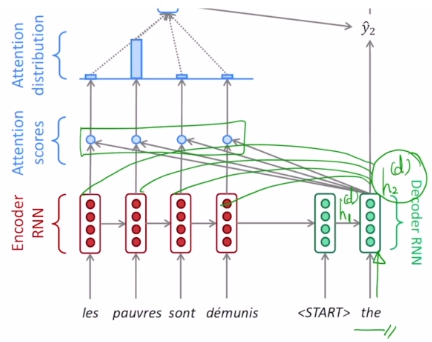
💡 Attention이란, 디코더(Decoder)가 각 타임 스텝(time step)에서 결과를 생성할 때에 인코더(Encoder)의 몇번째 타임스텝을 더 집중(Attention)해야하는지를 스코어 형태로 나타내는 것이다. 디코더는 인코더의 모든 hidden state vector를 고려하되, 몇 번째 타임스텝에 얼만큼씩 집중할지 골라서 단어를 생성하게 된다.
2.1 Attention 동작 원리
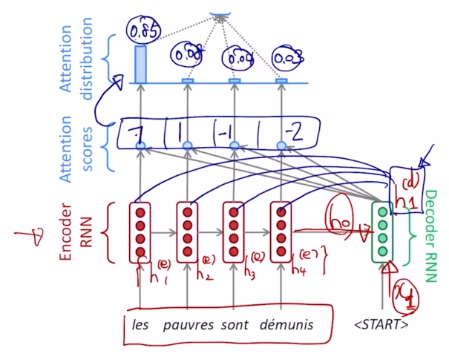
- Attention scores : 디코더의 현재 타임스텝의 hidden state vector와 인코더의 각 타임 스텝의 hidden state vector를 내적해서 유사도를 구한다.
- Attention distribution : 내적으로 계산된 값들을 softmax를 통과시켜 이 값들을 각각의 인코더 hidden state에 대응되는 확률값 또는 logit state vector로 생각할 수 있게 해준다. 즉 인코더의 hidden state vector에 부여되는 가중치로 생각할 수 있다. 가중치 각각은 디코더의 현재 타임 스텝에서 단어를 생성할 때 les에 85%, pauvres에 8%, sont에 4%, demunis에 3%만큼 집중한다는 것을 의미한다.
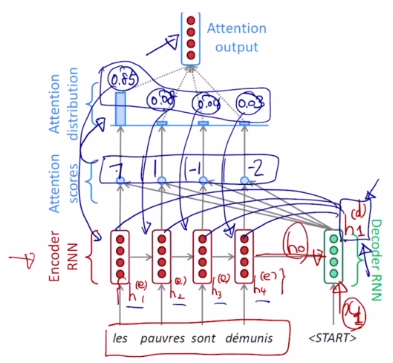
- Attention output (context vector) : 각각의 가중치와 인코더의 각각의 hidden state vector의 가중평균으로서 구해지는 하나의 인코딩 벡터이다. 이것을 context vector, attention vector 라고 부른다.
Attention output = - 마지막으로 디코더의 hidden state vector와 context vector(attention vector)가 concat되어서 output layer의 입력으로 들어간다. 이 입력을 가지고 현재 타임 스텝에서의 단어를 예측한다. 그리고 예측한 단어는 곧 다음 타임스텝의 입력으로 들어간다.
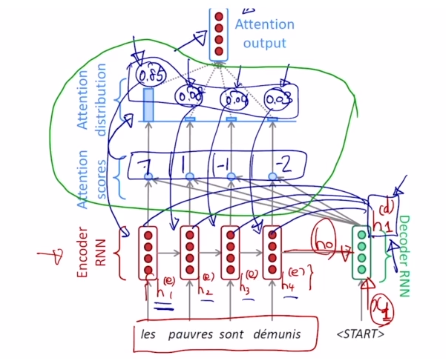
- 이 과정에서 attention module을 정의할 수 있다.
(초록색 동그라미에 해당됨) - 이 모듈의 입력 : 디코더 hidden state vector 하나와 encoder hidden state vector의 세트.
- 이 모듈의 출력 : 인코더 hidden state vector들의 가중 평균 벡터 하나.
단어 생성의 진행 과정은 다음과 같다.
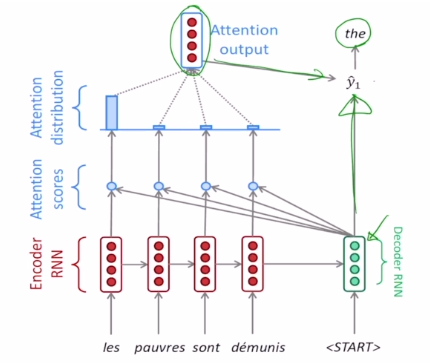
-
가장 첫 번째 타임스텝에서 SOS 토큰을 입력받아 를 얻는다. 이 hidden state vector와 인코더의 hidden state vector들의 유사도를 계산해 context vector를 얻고 이 context vector와 를 output layer의 입력으로 받아 the 라는 단어를 예측한다.
-
이전 타임스텝에서 예측한 단어인 the와 를 입력으로 받아 hidden state vector 를 얻는다. 와 인코더의 hidden state vector들의 유사도를 계산해 새로운 context vector를 얻고 이 context vector와 를 output layer의 입력으로 받아 poor 라는 단어를 예측한다.
-
End 토큰이 나올 때까지 이 과정을 반복 수행한다.
💡 의 두 가지 역할
t 시점에서의 decoder RNN의 output인 는 두 가지 역할을 한다.
1) 이 hidden state vector는 output layer의 input이 되어 다음에 등장하는 단어가 된다.
2) 현재 타임스텝에서 단어를 생성할 때, 주어진 sequence의 단어 중 어떤 단어를 중점적으로 가져와야 할지 결정하는 가중치를 구하는 역할을 한다.
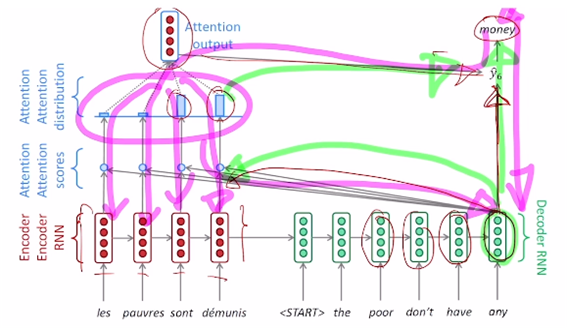
- 가중치가 잘못 학습된 경우 backpropagation을 통해서 가중치를 업데이트한다.
2.2 Teacher forcing
- 디코더의 다음 타임스텝에 입력값으로 이전 타임스텝의 결과값이 아닌 정답값(ground truth)을 넣어 학습하는 형태를 말한다.
- 학습 초기에는 start 바로 다음부터도 잘못된 예측을 할 수 있어 그 잘못된 예측을 그 다음 스텝의 입력값으로 준다면 연이어 잘못된 예측을 이어갈 수 있다. teacher forcing은 이전 타임의 예측값이 아닌 ground truth를 input으로 줌으로써 이와 같은 경우를 방지할 수 있다.
- teacher forcing의 장점 : 디코더에서 추론(inference)할 때, 틀린 값이 입력값으로 들어가지 않으므로 학습이 빨라진다.
- teachr forcing의 단점 : test time에서의 환경과 괴리가 있을 수 있다.
- 해결 방안 : 학습 초반에는 teacher forcing만으로 모든 batch를 구성해서 학습을 진행하다가 모델의 예측이 어느 정도 정확해지면 실제로 예측한 값을 다음 타임스텝의 input으로 줌으로써 실제 이 모델이 사용되는 test time에서의 상황에 부합되게끔 변화시켜주는 방식이 존재한다.
3. Attention Mechanisms
3.1 Luong Attention
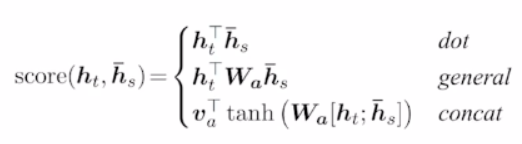 attention score를 얻는 방식에는 몇 가지의 형태가 있다.
attention score를 얻는 방식에는 몇 가지의 형태가 있다.
- : 디코더의 hidden state vector
- : 인코더의 특정 word의 hidden state vector
- dot product : 단순 내적
- generalized dot product :
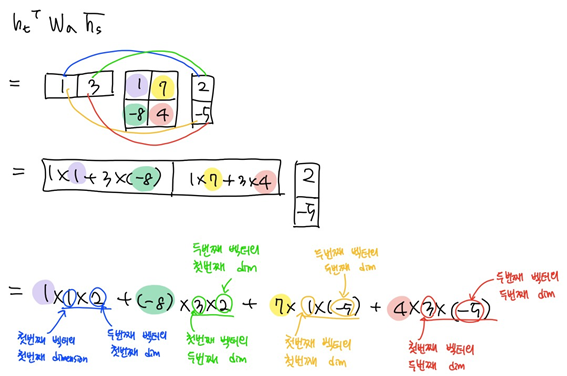 유사도를 구하고자 하는 두 벡터 사이에 학습 가능한 파라미터로 구성된 행렬 를 곱해줌으로써 와 의 몇 번째 dimension을 곱하느냐에 따라 다른 가중치를 곱해 유사도를 계산하게 해준다.
유사도를 구하고자 하는 두 벡터 사이에 학습 가능한 파라미터로 구성된 행렬 를 곱해줌으로써 와 의 몇 번째 dimension을 곱하느냐에 따라 다른 가중치를 곱해 유사도를 계산하게 해준다. - concat 기반 :
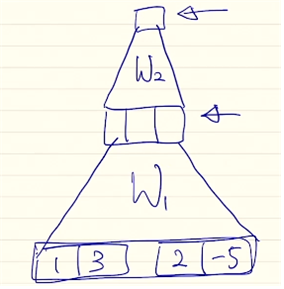 추가적인 학습 가능한 neural network를 사용해 와 의 유사도를 계산한다. 이때 input으로 와 를 concatenate한 벡터를 사용한다. 하나의 layer를 사용할 수도 있고 그림과 같이 layer를 더 쌓아서 사용할 수도 있다.
추가적인 학습 가능한 neural network를 사용해 와 의 유사도를 계산한다. 이때 input으로 와 를 concatenate한 벡터를 사용한다. 하나의 layer를 사용할 수도 있고 그림과 같이 layer를 더 쌓아서 사용할 수도 있다.
그림의 은 수식의 에 해당하고, 이 과의 곱으로 선형변환해준 뒤 tanh를 non-linear unit으로 적용해준다. 마지막으로 수식의 에 해당하는 와의 선형변환을 통해 하나의 스칼라값을 얻는다.
(* 대문자가 아닌 로 표기된 이유는 최종 값으로 스칼라 값을 얻기 때문에 row vector 형태이기 때문이다.) - 등의 파라미터 튜닝 방법 : backpropagation 과정에서 유사도를 구하는 모듈에 포함된 선형변환 행렬들(내적에서 필요로 하는 등의 가중치 행렬)을 업데이트한다.
3.2 Attention의 장점
1) Seq2seq 모델이 활발하게 연구되고 사용되던 NMT 분야에서의 주목할 만한 성능 향상
2) information의 bottleneck을 해결
인코더의 마지막 타임스텝의 hidden state vector만을 사용해 번역을 수행할 경우 긴 번역에 대해서는 번역이 잘 되기 어려운 문제를 해결
3) 학습의 관점에서 gradient vanishing을 해결
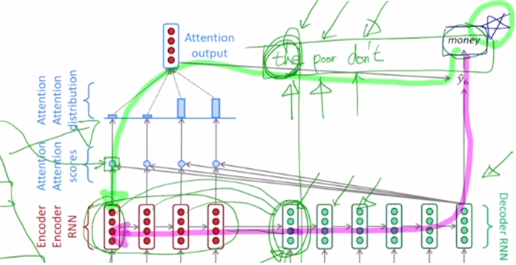
- attention 이 없을 경우
발생한 gradient가 인코더의 초반 타임스텝까지 전달되어야 하는 경우 디코더 타임스텝과 인코더 타임스텝을 쭉 거슬러 올라가야 해서 long term dependency 등의 문제가 있었음. (분홍 경로) - attention 사용 시
attention을 계산하는 모듈을 바로 통과해서 인코더의 특정 타임스텝의 hidden state vector까지 gradient를 큰 변질 없이 전달 가능해짐. (초록 경로)
4) 해석 가능성을 제공해줌 (interpretability)
attention의 패턴이 어떤 식으로 나왔는지 조사함으로써 디코더가 각 단어를 생성할 때 입력 시퀀스의 어떤 단어에 집중했는지 알 수 있다.
Reference
부스트코스 '자연어 처리의 모든 것' 3강
https://www.boostcourse.org/ai330/lecture/1455756?isDesc=false
