cf) 앙상블의 두 방식 비교 (Bagging vs Boosting)
퀴즈 대회 출전을 준비하는 두 팀을 생각해보자.
Team A)
a, b, c, d, e 다섯 명의 팀원이 각각 B1, B2, B3, B4, B5 책을 구입해 공부.
대회에서 각 팀원이 내놓은 5개의 답 중 voting 등을 통해 답 선택.
Team B)
ㄱ, ㄴ, ㄷ, ㄹ, ㅁ 다섯 명의 팀원. ㄱ부터 시작해 순차적으로 공부.
ㄱ) 한 책을 사서 공부했는데, 과학 관련 문제를 잘 맞추고 예술 문제에 대한 정답률이 낮았음.
ㄴ) 앞 사람인 ㄱ이 예술 문제에 취약했으므로 예술 문제를 주로 수록한 책을 사서 공부. 그 결과 ㄴ은 예술 문제는 잘 맞췄는데, 정치 문제를 잘 맞추지 못했음.
ㄷ) ㄷ은 ㄴ이 잘 맞추지 못하는 정치 문제를 주로 수록한 책으로 공부.
...
이러한 순서로 순차적으로 공부한 뒤, 대회에 나가서 5명의 답을 aggregate.
Bagging 방식이 Team A, Boosting 방식이 Team B라고 할 수 있다.
따라서 Bagging 방식은 parallel processing이 가능하지만, Boosting 방식은 앞선 모델에 대한 평가가 선행되어야 하므로 parallel processing 불가.
1. AdaBoost의 idea
- weak model의 성능을 boost(개선)시킬 수 있다.
- weak model: random guessing보다 약간 나은 모델 - weak model을 어떻게 boost?
1) weak model이 잘 맞추는 케이스가 있고, 잘 못 맞추는 케이스가 존재.
2) 그 다음 단계 학습에서는 모델이 잘 맞추지 못하는 데이터의 가중치를 높이고, 잘 맞추는 데이터의 가중치는 낮춰서 새로운 train dataset을 만들어 학습. (모델이 잘 맞추지 못하는 데이터에 집중해 학습을 진행)
3) 이를 충분히 반복한 뒤, 반복 과정에서 찾아낸 규칙들을 적절히 결합하여 높은 성능의 모델을 얻는다.
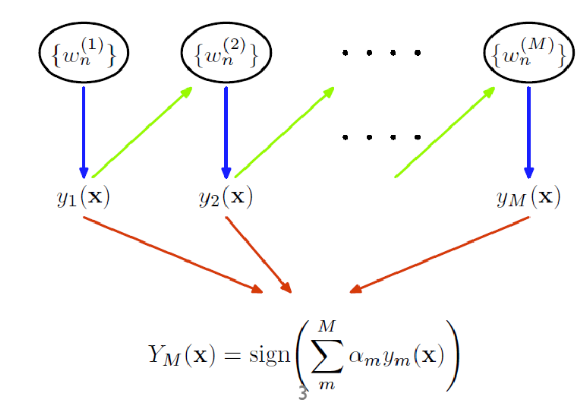
2. AdaBoost의 알고리즘
- 개념 설명을 위해 이진 분류로 가정.
- Input
- 앙상블 사이즈 T : 몇 개의 individual learner를 사용할 것인지.
- Training set : {}
- 레이블 : {} (계산상 편의를 위함. 중요한 의미는 X)
- 를 uniform distribution으로 정의.
- : 첫번째 dataset에서 example 가 선택될 확률.
- 부터 까지
- 분포를 사용해 모델 를 학습시킨다.
- 이때 는 stump tree이다. (1개의 분할만 하는 모델. 노드 두개짜리 트리 모델.)- =
- 오분류율
- if : break
- = : 가 정확한 모델일수록 sampling rate의 변동성이 커짐.
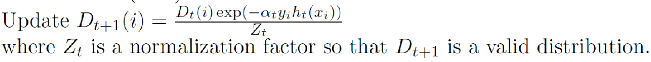
- example 에 대해 정확하게 예측했다면, exp의 부호가 음수가 되므로 에 example 가 포함될 확률은 낮아짐.
- example 에 대해 잘못 예측했다면, exp의 부호가 양수가 되므로 에 example 가 포함될 확률이 높아짐.
- =
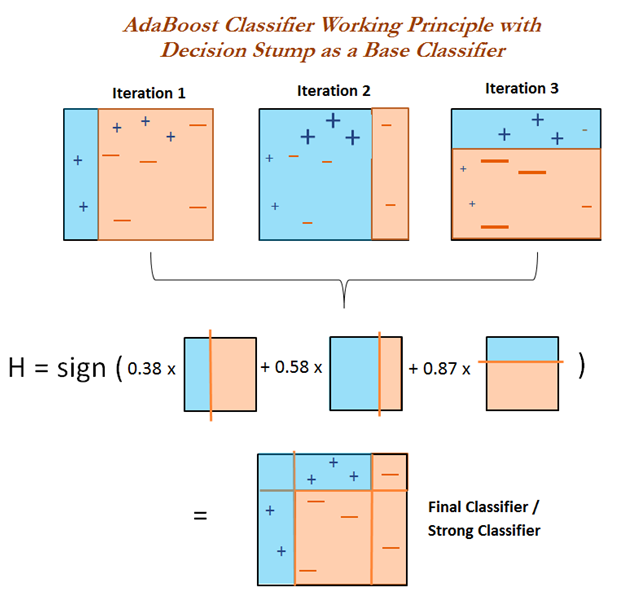
3. 예시