[Linguistic Probing] DagoBERT: Generating Derivational Morphology with a Pretrained Language Model
Linguistic Probing
목록 보기
6/6
저자: Valentin Hofmann, Janet B. Pierrehumbert (University of Oxford), Hinrich Schutze (LMU Munich)
연도: 2020
제출: EMNLP
링크: https://aclanthology.org/2020.emnlp-main.316/
목표
- 사전학습된 언어모델이 파생어를 잘 생성하는가 ?
- 파생 형태론에 대한 PLM 지식을 분석한 최초의 연구
- 예시: the coat is ___ + wear -> wearable
- PLM의 subword 단위 단어 분절 (e.g. BERT WordPiece) 의 token 중 파생 접사가 많으므로 파생형태론 지식을 보유하고 있을 가능성이 높다
- 모델의 단어 집합을 형태론적 정보를 반영하여 구성할 경우 모델의 성능을 개선할 가능성이 높아짐을 제시
- 파생 형태론에 대한 PLM 지식을 분석한 최초의 연구
배경
- 접사의 생산성: 한 형태소를 새로운 어휘소를 만드는 데 사용 가능한 정도
- 본 연구는 생산적으로 형성된 파생어 (생산적인 접사로 만든 단어)에 한정
- 저빈도 어휘가 전체 코퍼스에서 생산적인 접사로 파생되는 경우가 많다
- 파생어 생성 (DG) task
- context sentence, base -> 모델 -> 파생어
설계
- 모델
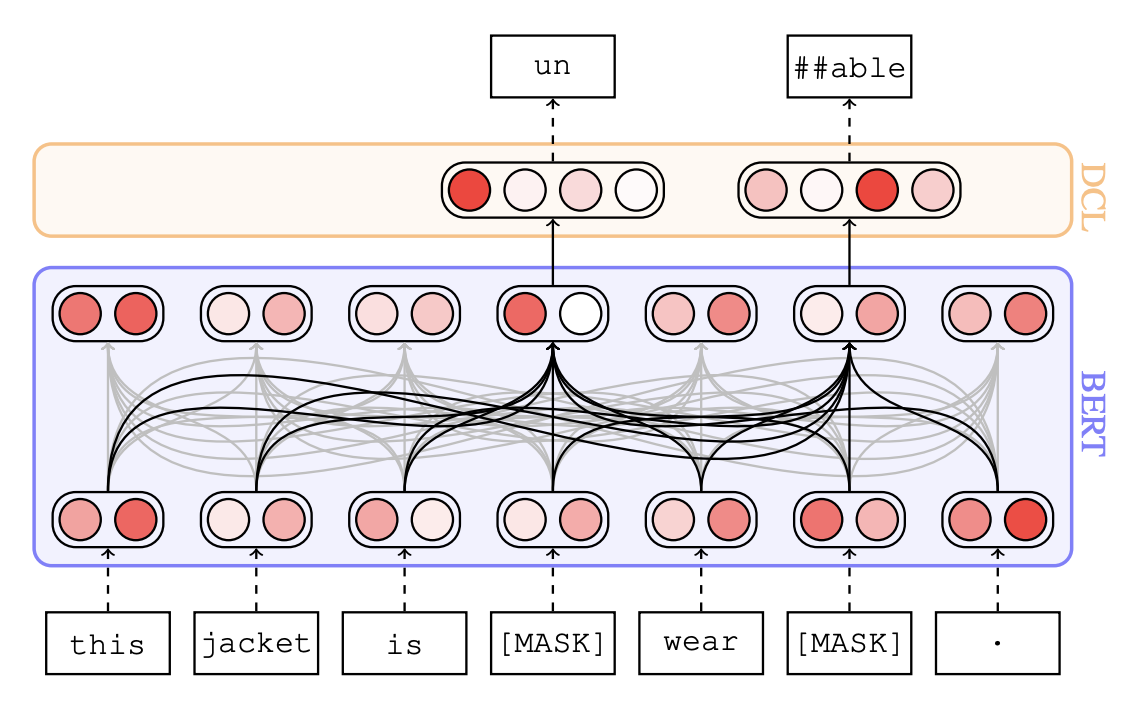
- BERT-base + DCL (Derivational Classifiation Layer)
- BERT+: only train DCL
- BERT
- LSTM
- Random Baseline
- 데이터
- 구축
- [파생어가 마스킹된 context sentence, base, 파생어]
- 파생어 판단 알고리즘
- 접두사, 접미사, base 를 입력 받아 단어가 파생 가능한 지 여부를 체크
- BERT 의 단어 집합을 활용하여 파생어 판단 알고리즘의 input을 만듦
- 접사
- base 중 3음절 이상의 항목 중 이미 접사로 식별된 항목을 토대로 추출
- reddit 데이터 활용
- context sentence
- 기존의 언어 규범을 따르지 않기 때문에 생산적으로 형성된 파생어 추출에 적합하다
- base에 접사를 최소 1개 결합하여 파생 가능한 단어를 포함하는 문장 중 10~100 단어인 문장을 추출
- 분류
- 빈도
- 구성 요소: P (접두사 1개), S (접미사 1개), PS (접두사 1개, 접미사 1개)
- test, val, test 에 중복되는 것(SHARED)과 안되는 것(SPLIT)으로 분류
- 구축
- 실험
- Cloze test 를 분류 문제로 수행
- 주어진 문장과 base 를 보고 빈칸에 나타날 가능성이 가장 높은 접사를 예측
- MRR (Mean Reciprocal Rank): 정답이 예측된 순위의 역수의 총합의 평균
- 접사 a에 대한 MRR 값 / 전체 접사에 대한 최종 MRR 값
- input segmentation 의 다양화
- HYP: un,-,allowed
- INIT: un, allowed
- TOKEN: un, all##, ##owed
- PROJ
- Cloze test 를 분류 문제로 수행
결과
-
Overall Performance
- Suffix 를 Prefix 보다 잘 맞춘다
- Suffix 가 품사 정보와 연관된 경우가 많기 때문일 것
- 빈도 효과
- Shared 에서 모델이 고빈도 파생어를 더 잘 맞춤 (저빈도에서 고빈도로 갈 수록 점수가 높아지는 경향이 있다)
- 특정 접사를 base와 어떻게 연결할 수 있는지 익힐 기회가 많았기 때문일 것
- PS 는 DagoBERT 가 다른 것들과의 성능 차가 크지 않다
- LSTM 과의 구조 차이
- Suffix 를 Prefix 보다 잘 맞춘다
-
오류 분석
-
confusion matrix 를 clustering
- confusion matrix C 계산
- confusion graph g, adjacency matrix G 계산
- clustering algorithm (Girvan and Newman) 적용
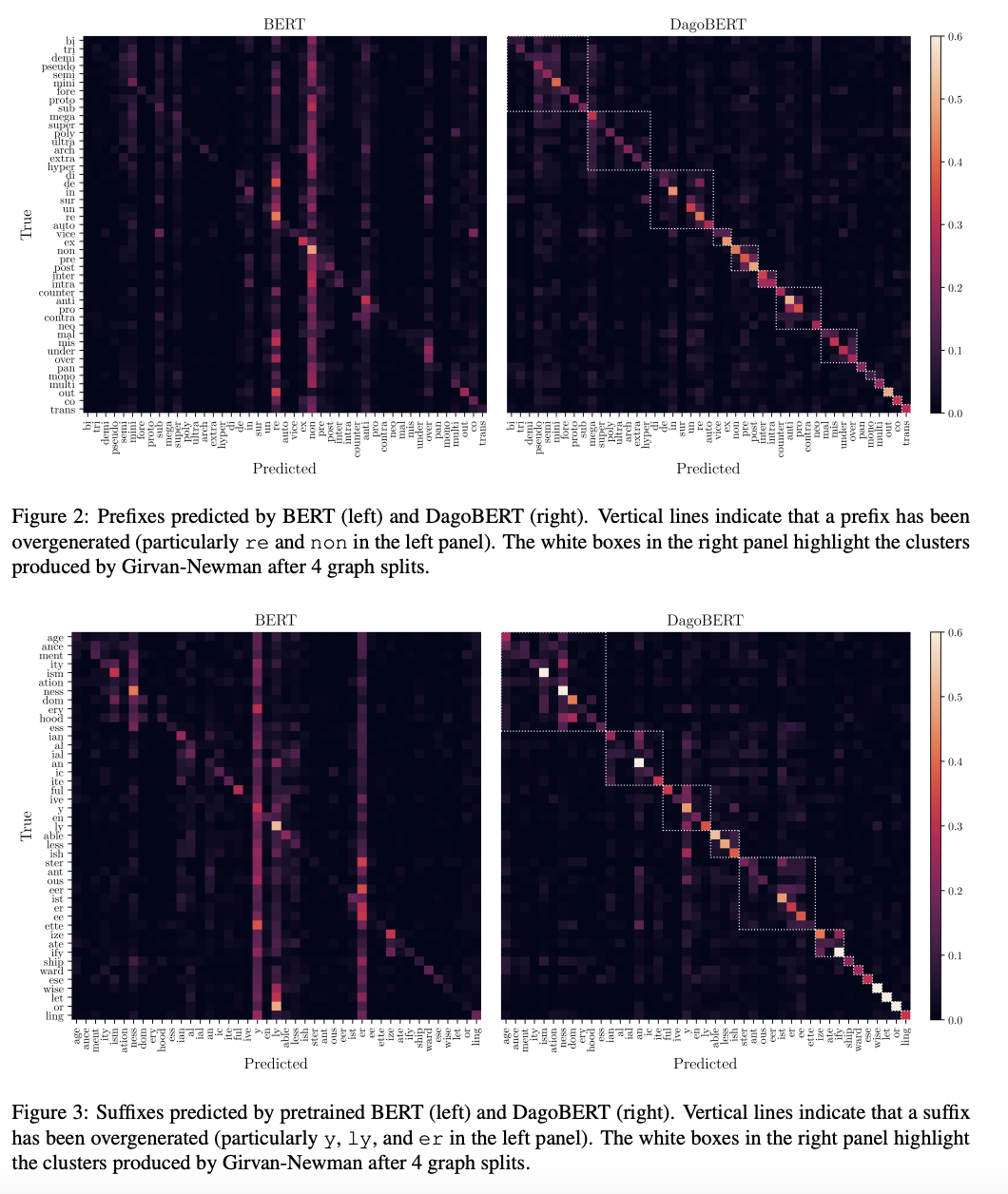
-
DagoBERT
- 군집화 결과가 언어학적으로 해석 가능한 접사들의 집단을 반영
- 접미사: 같은 PoS 인 것 끼리 clustered
- 접두사: {extra, ultra, ...}, {inter, intra}
- 정답과 통사/의미적으로 일치하는 접사를 오류로 예측
- 생산성이 높은 접사들이 낮은 접사보다 더 많이 예측됨
- confused with the point on the same scale
- 군집화 결과가 언어학적으로 해석 가능한 접사들의 집단을 반영
-
pretrained BERT
- 몇몇 특정 접사를 과도하게 예측하는 경향
-
-
생산성 과의 상관관계 분석
- 접사의 생산성과 MRR 간 양의 상관관계가 존재
-
input segmentation 방식이 파생어 지식에 중대한 영향
- BERT 의 파생어를 만드는 지식이 input segmentation 에 영향을 받는지 확인
- 이진 분류기
- SPLIT 이용하여 이진 분류 데이터셋 구성, negative example 추가
- 주어진 context sentence 에서 특정 파생어가 출현 가능한지 0, 1 로 return
- 결과
- HYP segmentation 을 활용하면 WordPiece 에 비해 형태소 단위 분절의 정확도 향상
