[Linguistic Probing] What Does BERT Learn about the Structure of Language?
Linguistic Probing
목록 보기
5/6
저자: Jawahar et al.
연도: 2019
제출: ACL
링크: https://aclanthology.org/P19-1356/
목표
- BERT 가 언어의 구조적 정보를 가지고 있는가 ?
- lower layer 에서 phrase-level information 이 capture 된다
- intermediate layer 는 여러 층위의 언어 정보를 capture 한다
- surface features at the bottom, syntactic features in the middle and semantic features at the top
배경
- Liu et al. (2019)
- Peter et al. (2019)
- Tenney et al. (2019)
- Hewitt and Manning. (2019)
- linear transformation of contextual word representation으로부터 non-contextual baselines보다 parse trees 를 더 잘 알아낼 수 있다
- BERT 의 compositional modeling 이 전통적 통사 분석을 모사한다
설계 및 결과
- Phrasal Syntax
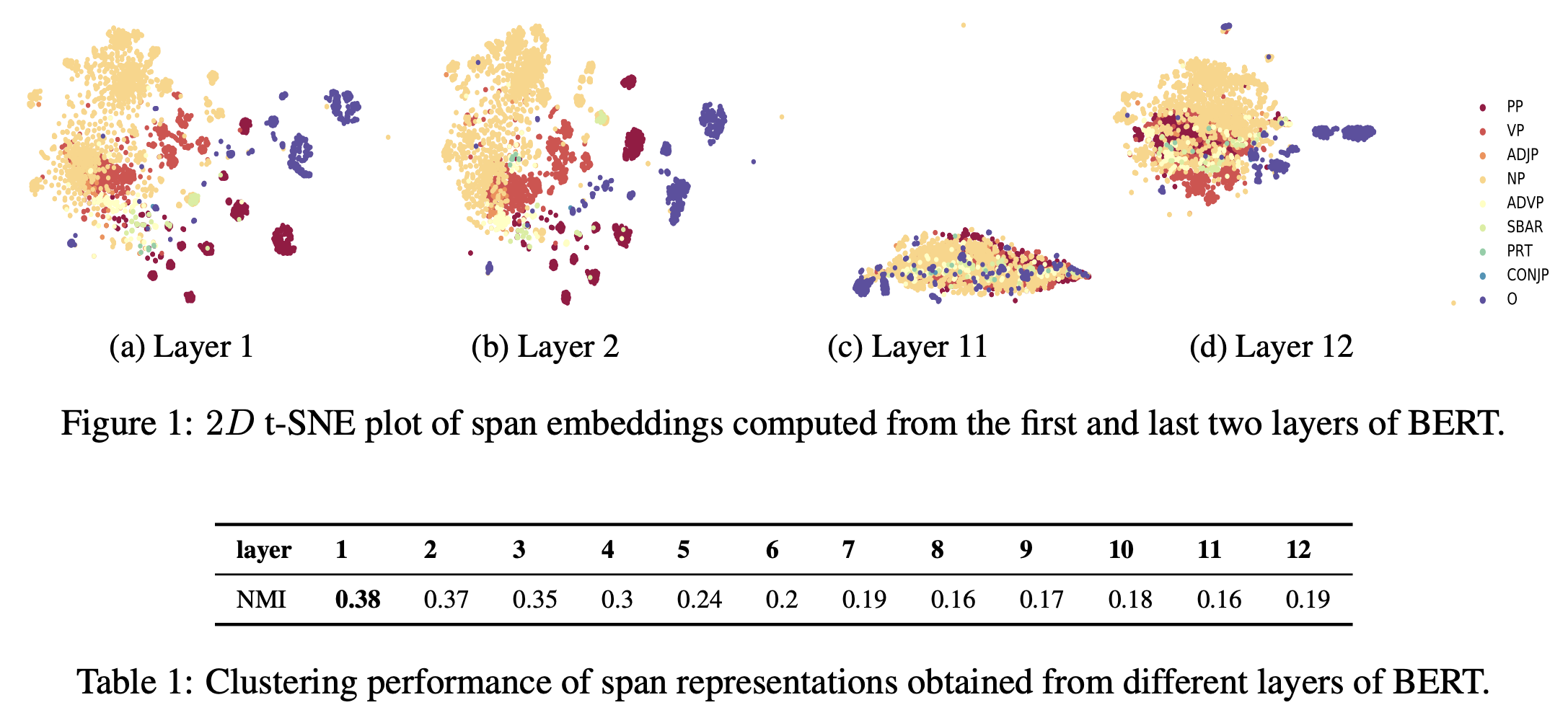
- LSTM 기반의 모델과 마찬가지로 phrase-level information 을 capture 하는가?
- capture는 하지만
- clustering performance 가 l-layer의 l이 증가하면서 감소한다. phrasal info는 lower layer 가 더 잘 capture 한다.
- probing tasks
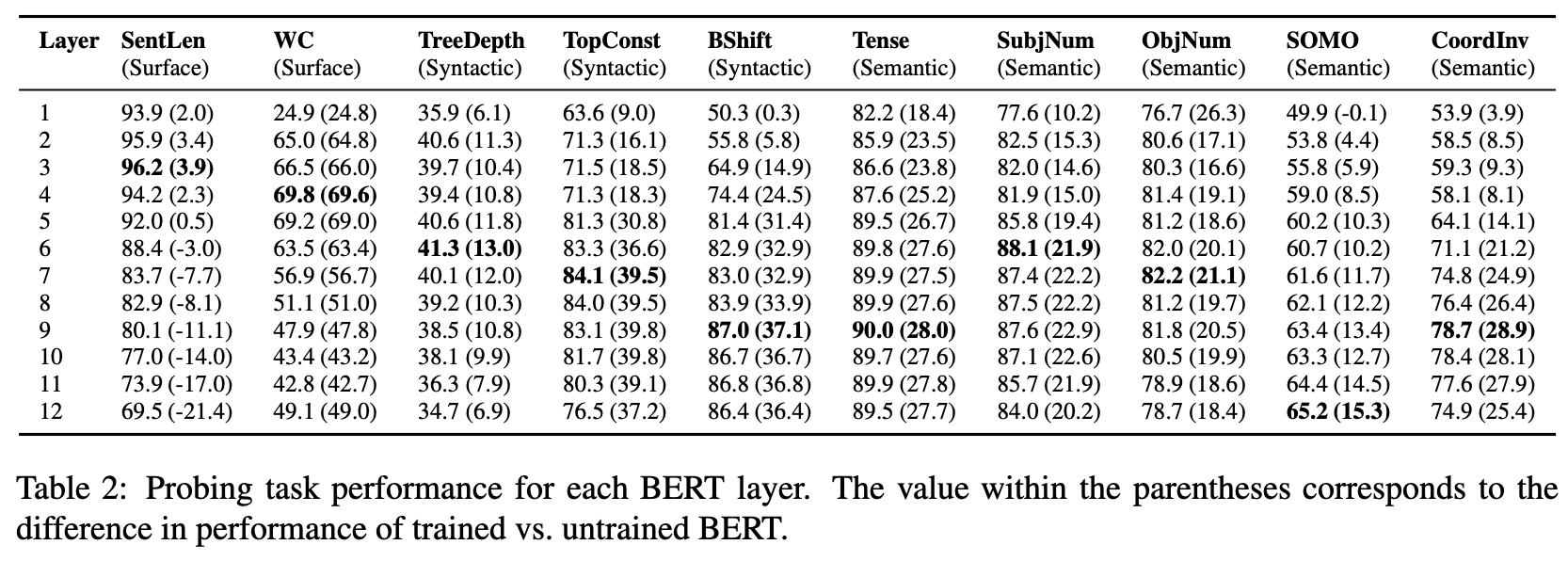
- auxiliary classification task: 주 목적인 classification task의 성능 향상을 위해 보조적인 classification task를 활용한다
- evaluate each layer of BERT using ten probing sentence-level datasets/tasks
- surface tasks: sentence length (SentLen), presence of words in the sentence (WC)
- syntactic tasks: sensitivity to word order (Bshift), depth of the syntactic tree (tree depth), sequence of toplevel constituents in the syntax tree (TopConst)
- semantic tasks: tense (Tense), the subject (resp. direct object) number in the main clause (SubjNum, resp. ObjNum), the sensitivity to random replacement of a noun/verb (SOMO), the random swapping of coordinated clausal conjuncts (CoordInv)
- rich hierarchy of linguistic signals
- Bshift, BoordInv 에서 기존 모델들의 성능 증가
- evaluate each layer of BERT using ten probing sentence-level datasets/tasks
- untrained version도 평가
- Untrained Model도 basic structure feature 예측하기에는 충분 (cf. SentLen task 에서 untrained 가 trained 보다 성능이 좋다.)
- Subject-Verb Agreement
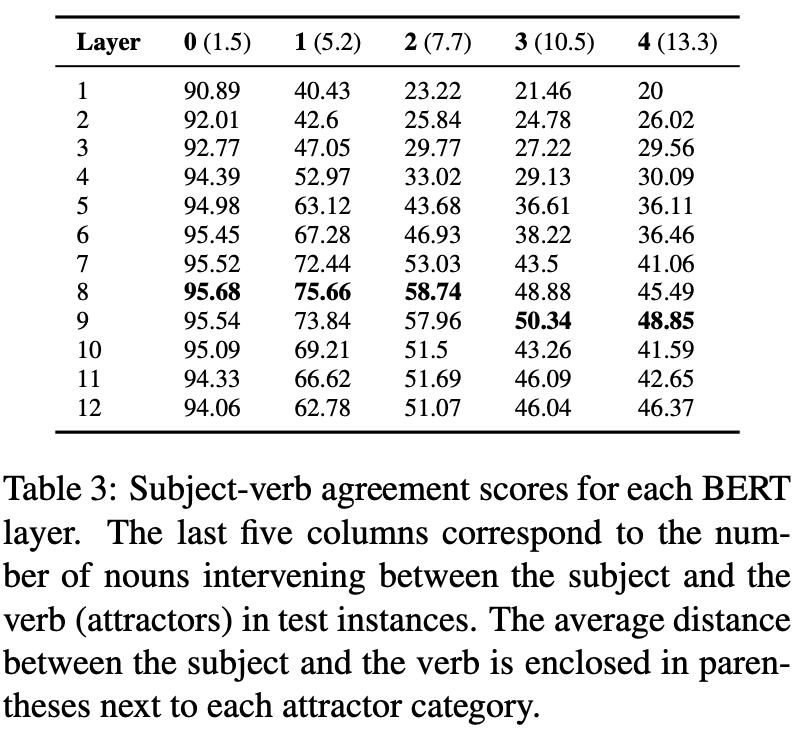
- to test syntactic structure
- 각 layer 에 대해 평가, controll the number of attracters(주어와 동사 사이에 삽입되는 단어들의 수)
- stimuli from Linzen et al.(2016), SentEval toolkit
- middle layers perform well in most cases
- attrractors 늘어날수록 layer 8 이 long-distance dependecy problem 을 잘 다룬다
- NLP task 를 잘 다루기 위해서는 Deep Layer 가 필요하다
- Compositional Structure

- to understand BERT's compositional nature of representation
- SNLI corpus 를 TPDN model (Tensor Product Decomposition Networks) 을 사용해 평가
- 각 scheme 에 따라 임베딩을 근사해내는 model
- 5 role schems: left-to-right, right-to-left, BoW, bidirectional ,tree
- BERT와 TPDN의 차이를 MSE loss funciton 을 사용해 평가
- tree-based scheme 과의 MSE loss 가 가장 적다.
- BERT 가 tree-based scheme 을 내부적으로 사용한다. attention에만 의존하는 것이 아니다.
