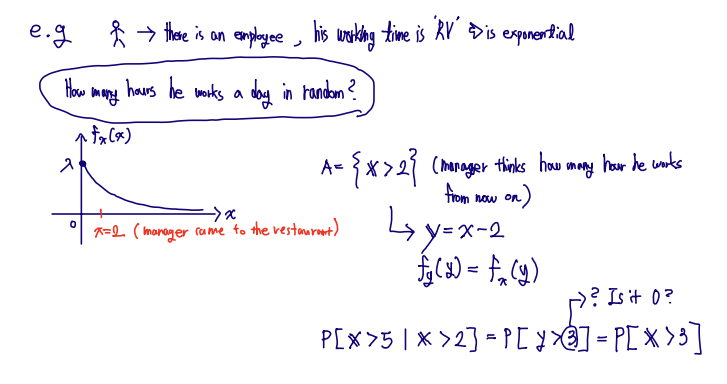Interestingly, the result shows that variance does not change by the bias 'b'
If the RV shift by b, Mean also shift.
Therefore the devariation(length) does not change.
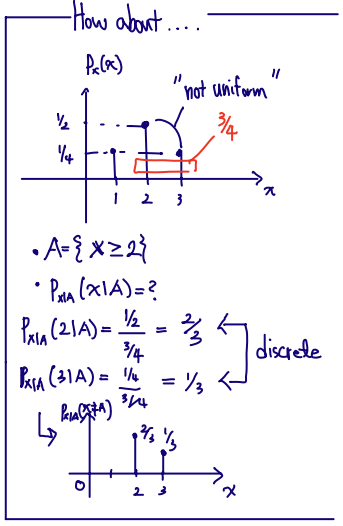
fX(x)=∑ifX∣Ai(x∣Ai)×P(Ai) // ( If multiply the δ each of equation, the result is P[X=x] ) E[X]=−∞∫∞x×fX(x)dx ⇔∑i−∞∫∞x×fX∣Ai(x∣Ai)×P(Ai)dx ⇔∑iEX∣Ai[x∣Ai]×P(Ai) ~ Total Expectation or Expected value of EX∣Ai(x∣Ai)
Notice ... E(X) is determined, but the E(X∣Ai) is different assumption. Value is changed! which event assume depending on Ai
■ Memorylessness of a Geometric Random Variable
X~ number of independent coin tosses until first head
PX(x)=(1−p)x−1×p ~ Probability Mass Function of Geometric Random Variable
For a PX∣A(x∣A), we have to apply the normalization to make an area is 1. PX∣A(x∣A)=(1−p)2(1−p)x−1×p ∴(1−p)x−3
✏️ Example
Using the above condition, we have Head for five times ⇒{T,T,T,H,H}
At this time, RV X is 5.
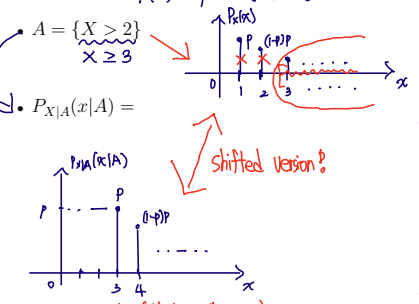
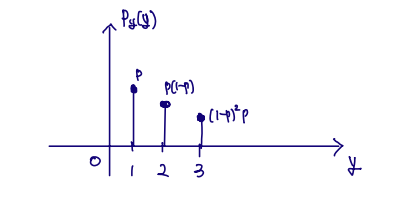
We make a condition Y is X>2 => Let Y=X−2(Y>0), then PY(y)=PX(y)
It is like the same case of X=3,4,5(∵X is X>2)⇒Y=1,2,3
Given that X>2, random variable Y=X−2 has the same geometric PMF as X
In X pmf, the probability same as Y.
(ex) X=Y=1, probability is same as p
Hence, the geometric random variable is said to be memoryless, because the past has no bearing on its future behavior.
It means even though we pick more and more the Tail, the probability of Head does not increase.
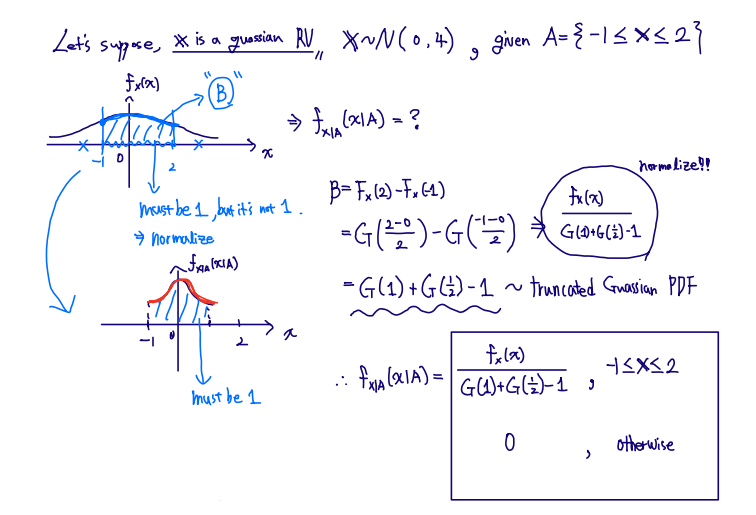
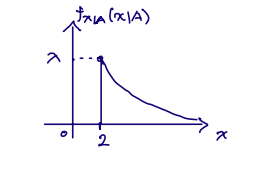
■ Memorylessness of exponential random variable
X ~ exponential random variable
fX(x)=λ×e−λx,(x>0)
A={X>2}
fX∣A(x∣A)=e−2λλ×e−λx=λ×e−λ(x−2),(x>2)
Let Y=X−2(Y>0), then fY(y)=fX(y)(y>0)
Given that X>2, random variable Y=X−2 has the same exponential PDF as X
Hence, the exponential random variable is also memoryless
✏️ Example
■ Total Probability
Event A and {X=x}(If X is continuous, this probability is 0)
−∞∫∞P(A∣X=x)×fX(x)dx⋯(1) ⇔−∞∫∞fX∣A(x∣A)×P(A)dx ⇔P(A)×−∞∫∞fX∣A(x∣A)dx(∵P(A) is constant.) ∴P(A)
It means that (1) equation is Total Probability Theorem in continuous of P(A)
✏️ Example
In Coin tossing, probability that coin's face show head is P, with fP(p),p∈[0,1] Find P(head). (Notice that it is uniform value)
We know that P(head∣P=x)=x (∵ That conditional probability means we get P(head), but P(head) is P and that conditional told us P is x. )
Now we define P(head) to use the total probability theorem. P(head)=0∫1P(head∣P=x)×fP(x)dx
If P is uniform on [0, 1].... 0∫1x×1dx=[21x2]01=1/2 ∴P(head)=1/2
■ Bayes' theorem (continuous version)
From the equation (1), fX∣A(x∣A)=P(A)P(A∣X=x)×fX(x) ∵−∞∫∞P(A∣X=x)×fX(x)dxP(A∣X=x)×fX(x)
It is used by Total Probability.
본 글은 HGU 2023-2 확률변수론 이준용 교수님의 수업 필기 내용을 요약한 글입니다.