BFS(Breadth-First Search)
BFS란?
원래는 그래프에서 모든 노드를 방문하는 알고리즘. 현재는 그래프를 학습하지 않았으므로 여기에서는 다차원 배열에서 각 칸을 방문할 때 너비를 우선으로 방문하는 알고리즘으로 학습한다.
- 시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법이다.
- 즉, 깊게(deep) 탐색하기 전에 넓게(wide) 탐색하는 것이다.
- 두 노드 사이 최단 경로 혹은 임의 경로를 구할 시 자주 사용
- 큐 사용하여 구현
BFS의 특징
- 직관적이지 않은 면이 있다.
- BFS는 시작 노드에서 시작해서 거리에 따라 단계별로 탐색한다고 볼 수 있다. => 가중치가 없는 그래프에서는 시작점과 끝점의 최단경로를 알아 낼 수 있다.
- BFS는 재귀적으로 동작하지 않는다.
- 이 알고리즘을 구현할 때 가장 큰 차이점은, 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사 해야 한다는 것이다.
- 이를 검사하지 않을 경우 무한루프에 빠질 위험이 있다.
- BFS는 방문한 노드들을 차례로 저장한 후 꺼낼 수 있는 자료 구조인 큐(Queue)를 사용한다.
- 즉, 선입선출(FIFO) 원칙으로 탐색
- 일반적으로 큐를 이용해서 반복적 형태로 구현하는 것이 가장 잘 동작한다.
- ‘Prim’, ‘Dijkstra’ 알고리즘과 유사하다.
BFS의 과정
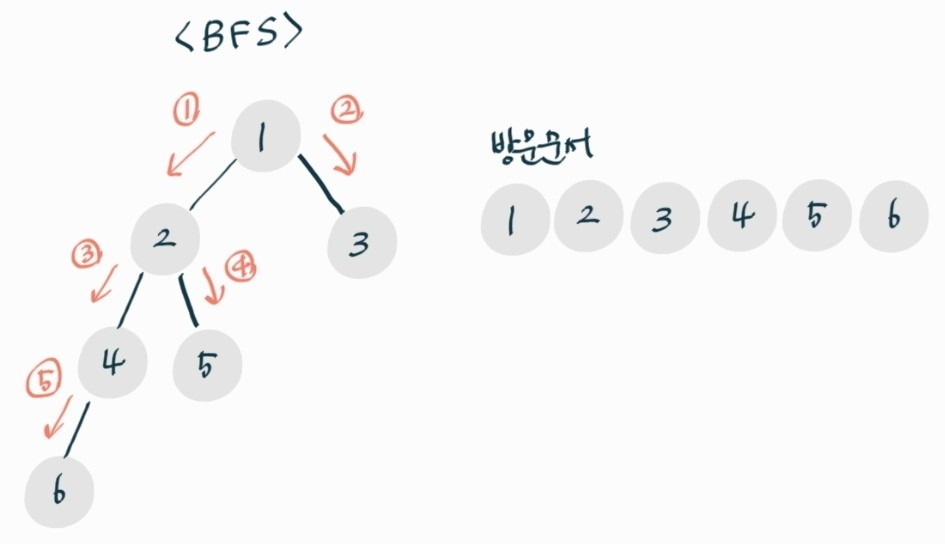
1. 첫 번째 노드 1을 방문하고, 큐에 삽입한 뒤 방문처리한다.
2. 큐에서 1을 꺼내고, 인접 노드인 2,3을 큐에 삽입한 뒤 방문 처리한다.
3. 큐는 FIFO이므로 큐에서 2를 꺼내고, 큐에 4,5를 삽입한다. 방문처리한다.
4. 큐에서 3을 꺼낸다.
5. 큐에서 4를 꺼내고 6을 큐에 삽입한뒤 방문처리한다.
6. 모두 방문 처리가 되었으니 큐에서 차례대로 5,6을 꺼낸다.
BFS의 구현
여기서는 이중 배열에 대한 BFS의 구현을 해보겠다. BFS를 구현하면서 주의 해야 할 점도 기억하도록 하자.
1. 시작점에 방문했다는 표시를 남기지 않는다.
2. 큐에 넣을 때 방문했다는 표시를 하는 대신 큐에서 빼낼 때 방문 표시를 한다
3. 이웃한 원소가 범위를 벗어났는지에 대한 체크를 잘못했다.
from collections import deque
# 1이 파란 칸, 0이 빨간 칸에 대응
board = [
[1, 1, 1, 0, 1, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 1, 0, 0, 0, 0, 0],
[1, 1, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
]
n, m = 7, 10 # n = 행의 수, m = 열의 수
vis = [[False] * m for _ in range(n)] # 해당 칸을 방문했는지 여부를 저장
dx = [1, 0, -1, 0]
dy = [0, 1, 0, -1] # 상하좌우 네 방향을 의미
def bfs():
q = deque()
vis[0][0] = True # (0, 0)을 방문했다고 명시
q.append((0, 0)) # 큐에 시작점인 (0, 0)을 삽입
while q:
cur_x, cur_y = q.popleft()
print(f'({cur_x}, {cur_y}) -> ', end='')
for dir in range(4): # 상하좌우 칸을 살펴볼 것이다.
nx = cur_x + dx[dir]
ny = cur_y + dy[dir] # nx, ny에 dir에서 정한 방향의 인접한 칸의 좌표가 들어감
if nx < 0 or nx >= n or ny < 0 or ny >= m:
continue # 범위 밖일 경우 넘어감
if vis[nx][ny] or board[nx][ny] != 1:
continue # 이미 방문한 칸이거나 파란 칸이 아닐 경우
vis[nx][ny] = True # (nx, ny)를 방문했다고 명시
q.append((nx, ny))DFS(Depth-First Search)
DFS란?
다차원 배열에서 각 칸을 방문할 때 깊이를 우선으로 방문하는 알고리즘.
DFS의 특징
- DFS는 Depth-First Searh, 깊이 우선 탐색이라고도 불린다.
- 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이다.
- 코드에서 그래프는 인접 행렬(Adjacency Matrix)과 인접 리스트(Adjacency List)로 표현될 수 있다.
- DFS는 스택이나 재귀함수를 이용해 구현 할 수 있다.
- 장점
- 최선의 경우 빠르게 해를 찾음
- 단점
- 찾은 해가 최적 해 아닐 가능성 있음
- 최악의 경우 해 찾는데 가장 오랜 시간 걸림
구현
def dfs_stack(graph, start):
visited = set() # 방문한 노드를 추적하기 위한 집합
stack = [start] # 시작 노드를 포함하는 스택 초기화
while stack: # 스택이 비어있지 않을 동안 반복
node = stack.pop() # 스택의 맨 위 노드를 꺼냄
if node not in visited: # 해당 노드가 방문되지 않았다면
print(node, end=' ') # 노드를 출력 (방문 순서 확인용)
visited.add(node) # 방문한 노드 집합에 추가
# 인접한 노드를 스택에 추가 (재귀적 순서와 동일하게 하기 위해 역순으로 추가)
for neighbor in reversed(graph[node]):
if neighbor not in visited:
stack.append(neighbor) # 방문하지 않은 인접 노드를 스택에 추가
# 사용 예제:
graph = {
0: [1, 2],
1: [0, 3, 4],
2: [0],
3: [1],
4: [1]
}
dfs_stack(graph, 0)이진탐색(Binary Search)
정렬 등과 함께 가장 기초인 알고리즘으로 꼽히는 문제. 검색 범위를 줄여 나가면서 원하는 데이터를 검색하는 알고리즘이다.
정렬된 배열에서 특정 값을 찾는 효율적인 알고리즘입니다. 이진 탐색은 배열의 중간 요소와 검색 키를 비교하여 작거나 큰지에 따라 검색 범위를 절반으로 줄여가며 찾습니다. 이러한 특성 때문에 이진 탐색의 시간 복잡도는
O(logn)입니다.
이진 탐색은 정렬된 배열에서 빠르게 값을 찾을 수 있는 강력한 알고리즘이다.
이진탐색의 동작원리
- 중간 요소 찾기:
배열의 중간 요소를 선택합니다.
- 비교:
중간 요소가 찾고자 하는 값과 같은지 비교합니다.
같다면 검색이 성공하고 인덱스를 반환합니다.
다르다면 중간 요소가 찾고자 하는 값보다 큰지 작은지 확인합니다. - 범위 좁히기:
- 찾고자 하는 값이 중간 요소보다 작으면, 배열의 왼쪽 반을 검색합니다.
- 찾고자 하는 값이 중간 요소보다 크면, 배열의 오른쪽 반을 검색합니다.
- 반복:
이 과정을 값을 찾을 때까지 반복하거나 검색 범위가 없어질 때까지 반복합니다.
이진탐색의 과정
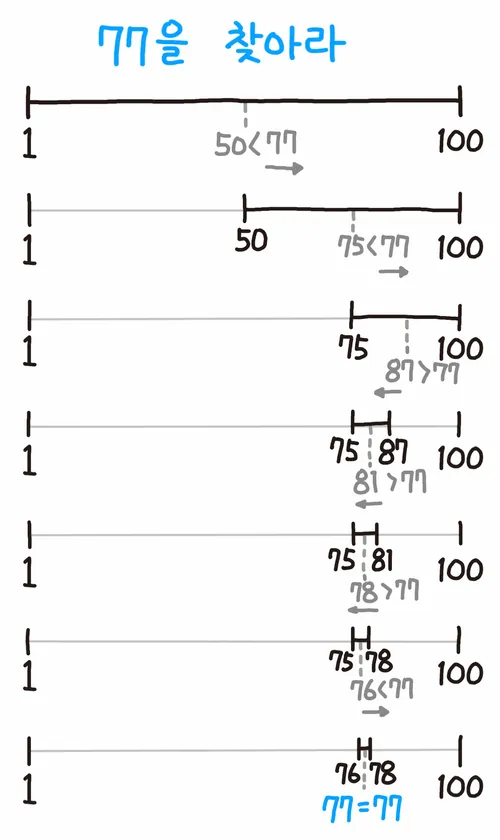
우리가 흔히 아는 술자리에서의 up/down게임의 효율적 전략과 완벽히 일치한다.
1. 50부터 탐색을 시작한다.
2. target이 50보다 크므로 오른쪽으로 이동한다.
3. 50과 100의 중간값인 75로 탐색한다. 75보다 크므로 또 오른쪽으로 이동한다.
4. 75와 100의 중간값 87로 이동해서 탐색한다. 작으니까 왼쪽
5. 75와 87의 중간값 81의 왼쪽으로 이동
6. 이런식으로 범위를 점점 좁혀나가면 7번만에 77을 찾을 수 있다.
구현
반복적 이진 탐색
def binary_search_iterative(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] > target:
right = mid - 1
else:
left = mid + 1
return -1 # 값이 배열에 존재하지 않음참고자료
