Apple.py-코딩테스트스터디
1.[Apple.py] 7월 3회차 - MST(prim), 플로이드
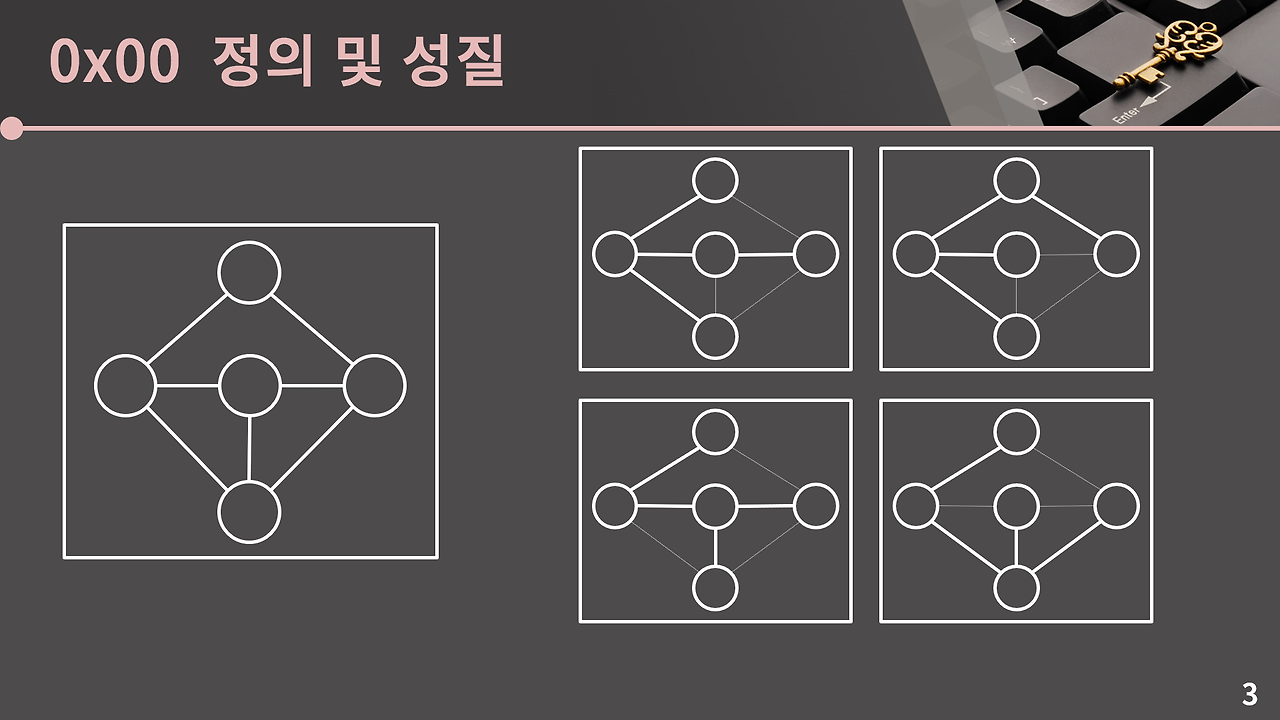
신장트리는 그래프 내의 모든 노드를 포함하면서 사이클이 없는 부분 그래프를 신장트리라고 한다.트리의 성질로부터 주어진 그래프의 정점이 V개일 때 신장 트리는 V-1개의 간선을 가지고 있음을 알 수 있습니다.위에서의 오른쪽에 있는 그래프들은 간선이 없는 노드가 있다던가,
2.[Apple.py] 7월 1주차 - 그래프
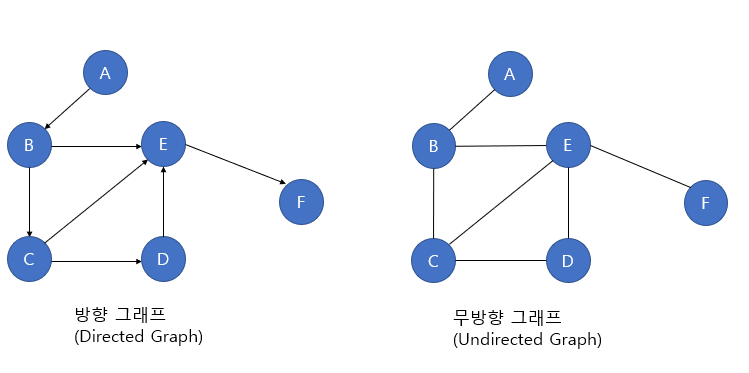
그래프 예시그래프는 연결되어 있는 원소 사이의 다대다 관계를 표현하는 자료구조이다.그래프 G는 객체를 나타내는 정점 V(vertex)와 객체를 연결하는 간선 E(edge)의 집합이다.트리도 그래프의 한 종류이며, 그 중 사이클(cycle)이 허용되지 않는 그래프를 말한
3.[Apple.py] 7월 1주차 - 그리디
그리디 알고리즘(욕심쟁이 알고리즘, Greedy Algorithm)이란 "매 선택에서 지금 이 순간 당장 최적인 답을 선택하여 적합한 결과를 도출하자"라는 모토를 가지는 알고리즘 설계 기법이다.즉, 현재 내가 내린 선택이 나중에 어떤 결과를 가져올지는 고려하지 않고,
4.[Apple.py] 6월 4주차 - BFS, DFS, 이진탐색
BFS(Breadth-First Search) BFS란? 원래는 그래프에서 모든 노드를 방문하는 알고리즘. 현재는 그래프를 학습하지 않았으므로 여기에서는 다차원 배열에서 각 칸을 방문할 때 너비를 우선으로 방문하는 알고리즘으로 학습한다. 시작 정점으로부터 가까운 정점을
5.[Apple.py] 6월 3주차 - 합병정렬, 퀵정렬, 기수정렬

합병정렬(Merge Sort) 병합정렬은 분할 정복 (Divide and Conquer) 방식을 이용해서 하나의 리스트를 두 개의 리스트로 분할한 다음 각각의 분할된 리스트를 정렬한 후에 합해서 정렬된 하나의 리스트로 만드는 정렬 알고리즘이다. 재귀 알고리즘을 이용해서
6.[Apple.py] 3주차 - 정렬(버블정렬, 선택정렬, 삽입정렬)
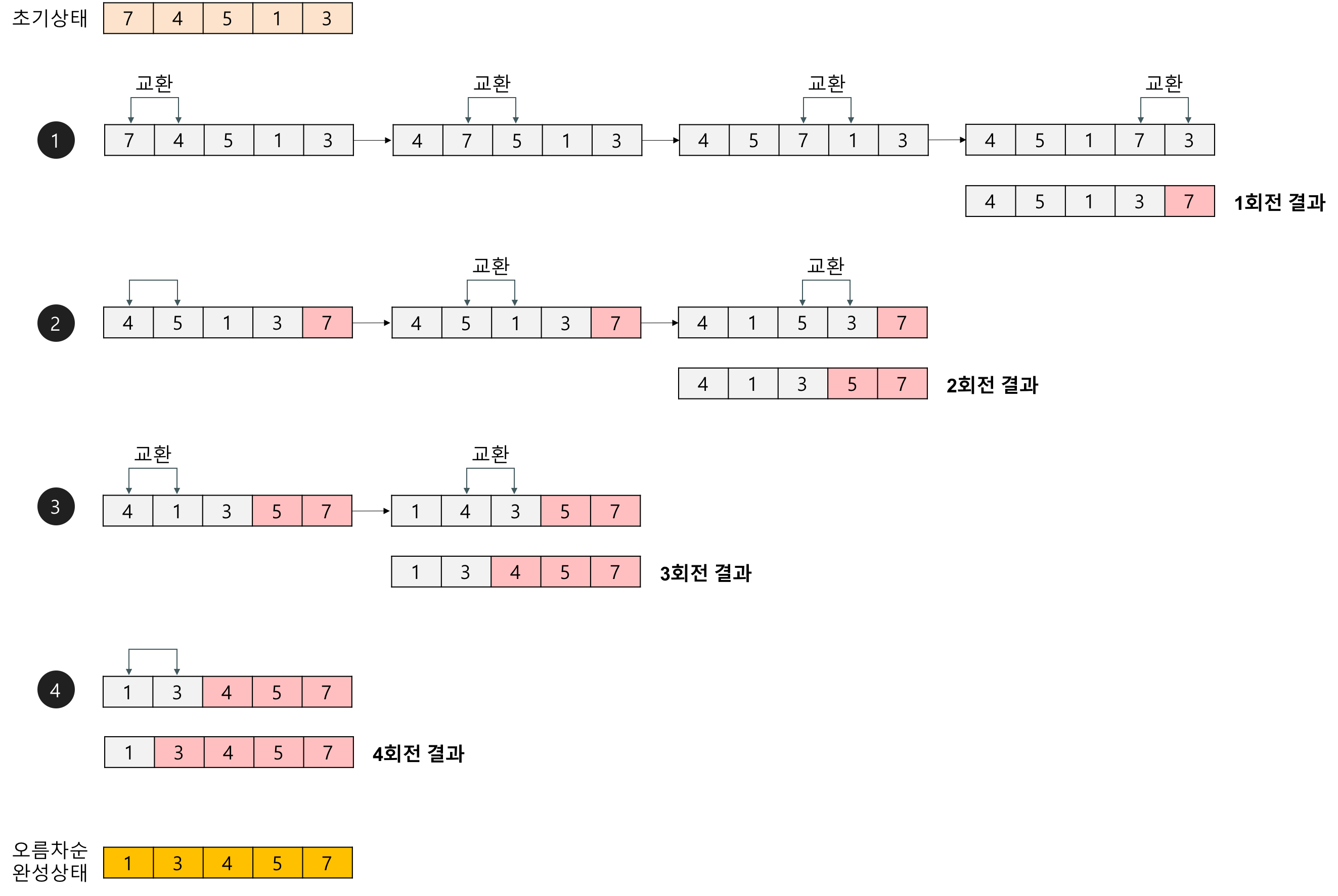
정렬 整列 / Sorting 뭔가가 주어졌을 때 이것을 정해진 순서대로 가지런하게 나열하는 것을 의미한다. 정렬 알고리즘 컴퓨터 분야에서 중요시되는 문제 가운데 하나로 어떤 데이터들이 주어졌을 때 이를 정해진 순서대로 나열하는 문제이다. 실제 컴퓨터 분야에서 사용하는
7.[Apple.py] 2주차 - 투포인터, 슬라이딩 윈도우
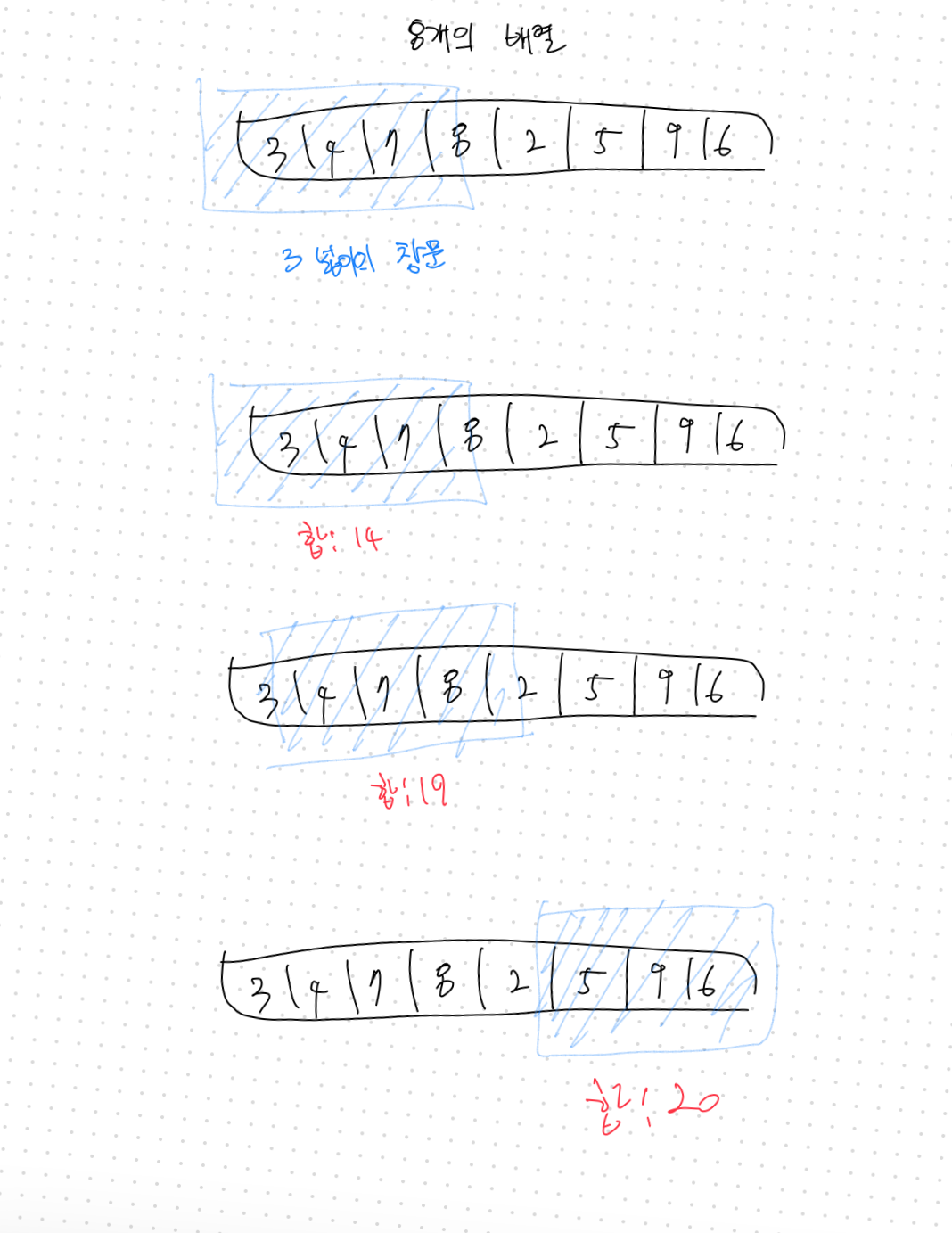
투 포인터 알고리즘은 리스트에 순차적으로 접근해야 할 때 두개의 점의 위치를 기록하면서 처리하는 알고리즘을 의미한다. 리스트에 담긴 데이터에 순차적으로 접근해야 할 때는 시작점과 끝점 2개의 점으로 접근할 데이터의 범위를 표현 할 수 있다.리스트의 시작위치에서 투포인터
8.[Apple.py] 2주차 - 스택, 큐
스택 스택(Stack)은 자료를 쌓아놓은 것이다. 한쪽에서만 데이터를 삽입/삭제 할 수 있는 자료구조이다. 후입선출(Last In First Out, LIFO) 원칙에 따라 자료를 관리한다. 스택의 성질 원소의 추가/삭제의 시간복잡도 O(1) 제일 상단의 원소 확인
9.[Apple.py] 1주차 - 배열, 연결리스트, 누적합
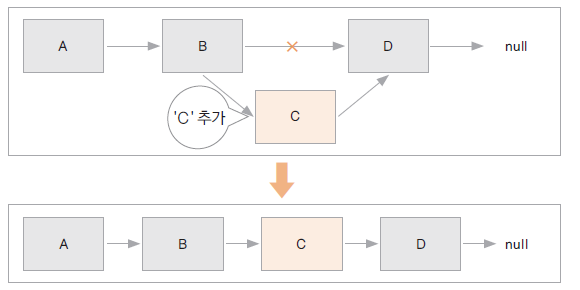
배열은 연속적인 메모리 공간에 순차적으로 데이터를 저장하고, 배열을 선언 할 때의 크기로 고정이 된다.1\. O(1)에 k번쨰 원소를 확인/변경 가능2\. 추가적으로 소모되는 메모리의 양(=overhead)가 거의 없음3\. Cache hit rate가 높음4\. 메모