합병정렬(Merge Sort)
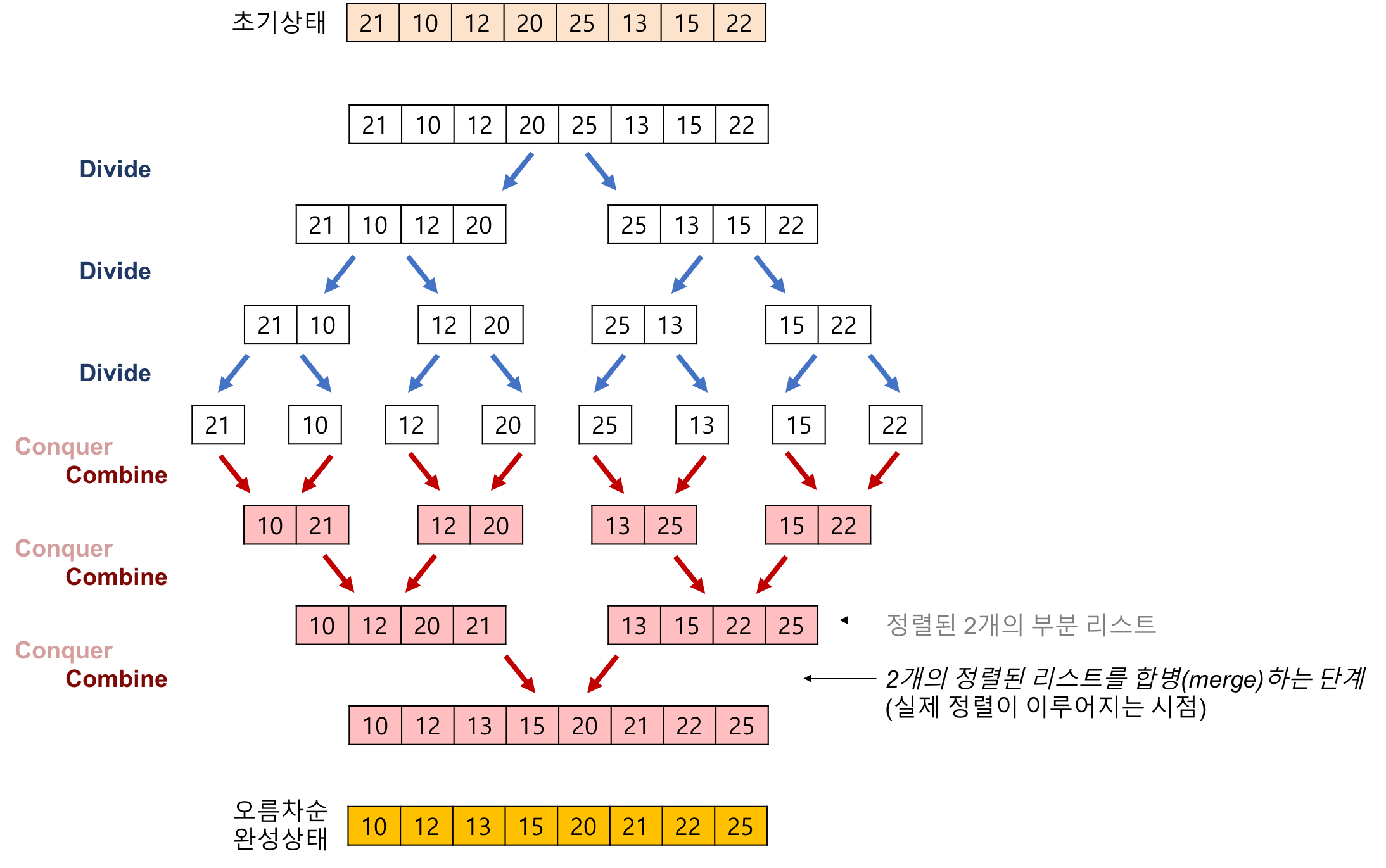
병합정렬은 분할 정복 (Divide and Conquer) 방식을 이용해서 하나의 리스트를 두 개의 리스트로 분할한 다음 각각의 분할된 리스트를 정렬한 후에 합해서 정렬된 하나의 리스트로 만드는 정렬 알고리즘이다. 재귀 알고리즘을 이용해서 구현 할 수 있다.
개념
- 분할(Divide) : 리스트를 두 개의 리스트로 분할한다
- 정복(Conquer) : 분할된 리스트를 정렬한다.
- 결합(Combine): 정렬된 두 개의 리스트를 하나의 정렬된 리스트로 결합한다.
시간 복잡도
평균 : O(nlog₂n)
최악 : O(nlog₂n)
최선 : O(nlog₂n)
❓ 퀵정렬보다 병합정렬이 유리한 경우가 있을까? (자바)
만약 레코드를 연결 리스트(Linked List)로 구성하면, 링크 인덱스만 변경되므로 데이터의 이동은 무시할 수 있을 정도로 작아진다. 합병 정렬은 순차적인 비교로 정렬을 진행하므로, LinkedList의 정렬이 필요할 때, 사용하면 효율적이다. LinkedList를 퀵 정렬에 사용해 정렬하면 성능이 좋지 않다. 이유는 퀵 정렬은 순차 접근이 아닌 임의 접근이기 때문이다. LinkedList는 삽입과 삭제 연산에서는 유용하지만, 접근 연산에서는 비효율적이다.
👉 따라서 크기가 큰 레코드를 정렬할 경우에 연결 리스트를 사용한다면, 합병 정렬은 퀵 정렬을 포함한 다른 어떤 정렬 방법보다 효율적이다.
구현
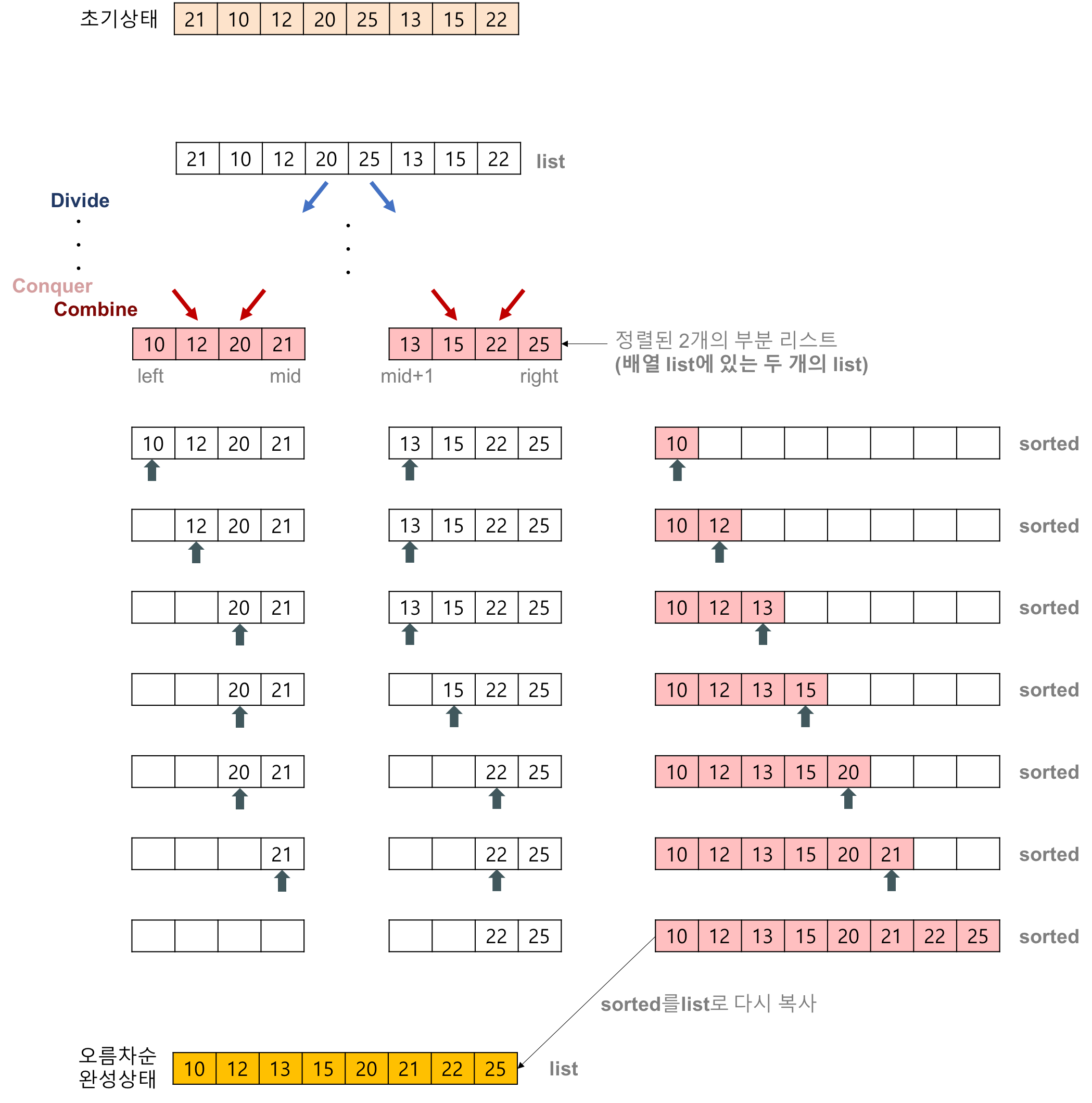
- 2개의 정렬된 리스트를 합병(merge)하는 과정
- 2개의 리스트의 값들을 처음부터 하나씩 비교하여 두 개의 리스트의 값 중에서 더 작은 값을 새로운 리스트(sorted)로 옮긴다.
- 둘 중에서 하나가 끝날 때까지 이 과정을 되풀이한다.
- 만약 둘 중에서 하나의 리스트가 먼저 끝나게 되면 나머지 리스트의 값들을 전부 새로운 리스트(sorted)로 복사한다.
- 새로운 리스트(sorted)를 원래의 리스트(list)로 옮긴다.
코드
def mergeSort(arr):
if len(arr) < 2:
return arr
mid = len(arr)//2
low_arr = mergeSort(arr[:mid])
high_arr = mergeSort(arr[mid:])
merge_arr = []
l = h = 0
while l < len(low_arr) and h < len(high_arr):
if(low_arr[l] < high_arr[h]):
merge_arr.append(low_arr[l])
l += 1
else:
merge_arr.append(high_arr[h])
h += 1
merge_arr += low_arr[l:]
merge_arr += high_arr[h:]
return merge_arr최적화 코드
위 코드의 경우 리스트를 분할 할 때마다 새로운 배열을 파이썬의 slice를 이용해서 생성하므로 메모리의 사용효율이 좋지 않다. 아래 코드에서는 인덱스의 값을 참조
def mergeSort(arr):
def sort(low, high):
if high - low < 2:
return
mid = (low + high) // 2
sort(low, mid)
sort(mid, high)
merge(low, mid, high)
def merge(low, mid, high):
temp = []
l, h = low, mid
while l < mid and h < high:
if arr[l] < arr[h]:
temp.append(arr[l])
l += 1
else:
temp.append(arr[h])
h += 1
while l < mid:
temp.append(arr[l])
l += 1
while h < high:
temp.append(arr[h])
h += 1
for i in range(low, high):
arr[i] = temp[i - low]
return sort(0, len(arr))퀵 정렬(Quick Sort)
- 병합 정렬과 마찬가지로 퀵 정렬도 분할 정복 (Devide and Conquer) 기법과 재귀 알고리즘을 이용하고, 평균적으로 매우 빠른 수행 속도를 자랑하는 정렬 알고리즘.
- 퀵 정렬은 불안정 정렬 에 속하며, 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬 에 속한다.
- 합병 정렬(merge sort)과 달리 퀵 정렬은 리스트를 비균등하게 분할한다.
개념
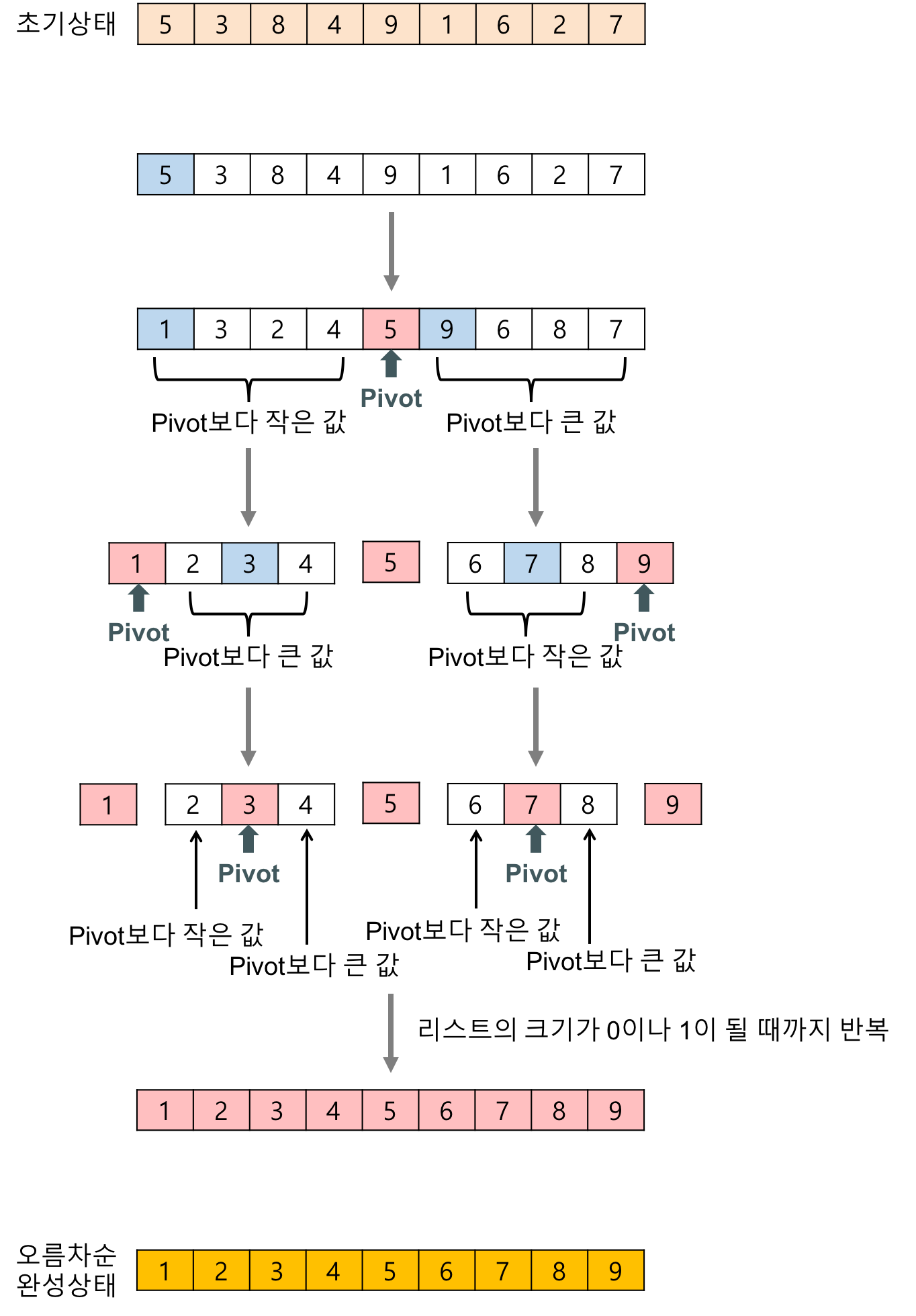
- 분할(Divide): 입력 배열을 pivot을 기준으로 왼쪽은 pivot보다 작은요소들, 오른쪽은 pivot보다 큰 요소들로 하여 2개의 부분 배열로 분할한다.
- 정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출 을 이용하여 다시 분할 정복 방법을 적용한다.
- 결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.
순환 호출이 한번 진행될 때마다 최소한 하나의 원소(pivot)는 최종적으로 위치가 정해지므로, 이 알고리즘은 반드시 끝난다는 것을 보장할 수 있다.
특징
- 파이썬의 list.sort(), 자바의 Arrays.sort()등 프로그래밍 언어에서 기본적으로 지원되는 내장 정렬 함수는 대부분은 퀵 정렬을 기본으로 합니다.
- 일반적으로 원소의 개수가 적어질수록 나쁜 중간값이 선택될 확률이 높아지기 때문에, 원소의 개수에 따라 퀵 정렬에 다른 정렬을 혼합해서 쓰는 경우가 많습니다.
- 병합 정렬과 퀵 정렬은 분할 정복과 재귀 알고리즘을 사용한다는 측면에서는 유사해보이지만, 내부적으로 정렬을 하는 방식에서는 큰 차이가 있습니다.
- 병합 정렬은 항상 정 중앙을 기준으로 단순 분할 후 병합 시점에서 값의 비교 연산이 발생하는 반면, 퀵 정렬은 분할 시점부터 비교 연산이 일어나기 때문에 그 이후 병합에 들어가는 비용이 매우 적거나 구현 방법에 따라서 아예 병합을 하지 않을 수도 있습니다.
복잡도
- 쿽 정렬의 성능은 pivot 값을 어떻게 선택하느냐에 크게 달라질 수 있습니다. 이상적인 경우에는 pivot 값을 기준으로 동일한 개수의 작은 값들과 큰 값들이 분할되어 병합 정렬과 마찬가지로 O(nlog(n))의 시간 복잡도를 가지게 됩니다.
- 하지만 pivot 값을 기준으로 분할했을 때 값들이 한 편으로 크게 치우치게 되면, 퀵 정렬은 성능은 저하 되며, 최악의 경우 한 편으로만 모든 값이 몰리게 되어 O(n^2)의 시간 복잡도를 보이게 됩니다.
- 따라서 상용 코드에서는 중앙값(median)에 가까운 pivot 값을 선택할 수 있는 섬세한 전략이 요구되며, 배열의 첫값과 중앙값 그리고 마지막값 중에 크기가 중간인 값을 사용하는 방법이 많이 사용됩니다.
- 퀵 정렬은 공간 복잡도는 구현 방법에 따라 달라질 수 있는데, 입력 배열이 차지하는 메모리만을 사용하는 in-place sorting 방식으로 구현을 사용할 경우, O(log n)의 공간 복잡도를 가진 코드의 구현이 가능합니다.
구현
코드
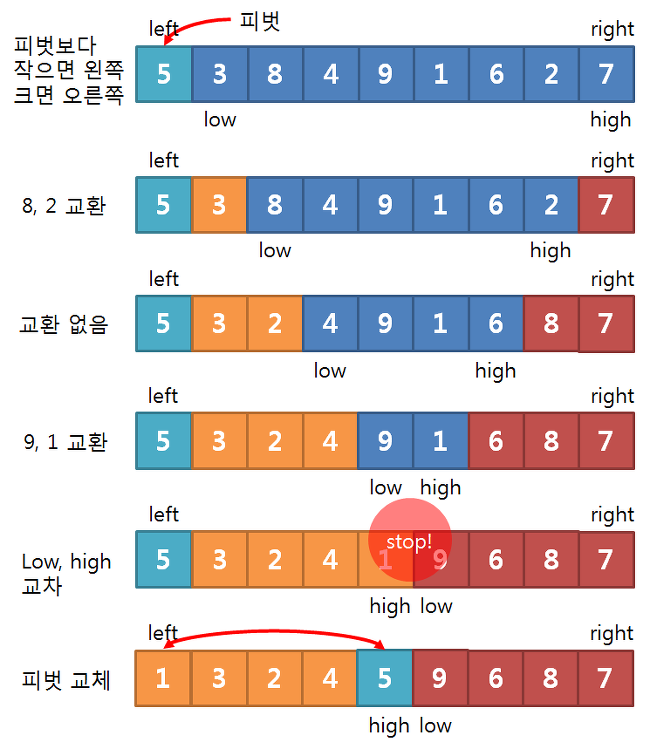
- 첫 번째 구현: In-Place Quick Sort
이 구현은 제자리 정렬(in-place sorting) 방식으로, 추가적인 리스트를 사용하지 않고 입력 배열 내에서 정렬을 수행합니다.
def quick_sort(array, start, end):
if start >= end:
return
pivot = start # 피벗 초기값은 첫 번째 요소
left = start + 1
right = end
while left <= right:
while left <= end and array[left] <= array[pivot]:
left += 1
while right > start and array[right] >= array[pivot]:
right -= 1
if left > right: # 엇갈렸다면 작은 데이터를 피벗과 교체
array[right], array[pivot] = array[pivot], array[right]
else: # 엇갈리지 않았다면 작은 데이터와 큰 데이터를 교체
array[left], array[right] = array[right], array[left]
quick_sort(array, start, right - 1)
quick_sort(array, right + 1, end)- 두 번째 구현: Functional Quick Sort
이 구현은 함수형 프로그래밍 스타일로, 새로운 리스트를 생성하여 정렬을 수행합니다.
def quick_sort(array):
if len(array) <= 1:
return array
pivot = array[0] # 피벗은 첫 번째 원소
tail = array[1:] # 피벗을 제외한 리스트
left_side = [x for x in tail if x <= pivot] # 분할된 왼쪽 부분
right_side = [x for x in tail if x > pivot] # 분할된 오른쪽 부분
return quick_sort(left_side) + [pivot] + quick_sort(right_side)효율성 비교
공간 복잡도
- In-Place Quick Sort: 제자리 정렬이므로 추가적인 리스트를 생성하지 않아 공간 효율성이 높습니다. 공간 복잡도는 O(log n)으로, 재귀 호출 스택의 깊이에 비례합니다.
- Functional Quick Sort: 새로운 리스트를 생성하므로 추가적인 메모리 공간이 필요합니다. 공간 복잡도는 O(n log n)으로, 리스트가 분할되고 합쳐질 때마다 새로운 리스트가 생성되기 때문입니다.
시간 복잡도
두 구현 방식 모두 평균 시간 복잡도는 O(n log n)입니다. 그러나 In-Place Quick Sort는 추가적인 리스트를 생성하지 않으므로 실제 실행 시간에서 약간 더 효율적일 수 있습니다.
구현 난이도 및 코드 이해
In-Place Quick Sort: 구현이 약간 더 복잡하고, 특히 피벗을 기준으로 요소를 교환하는 과정에서 실수를 할 가능성이 있습니다. 그러나 메모리를 덜 사용합니다.
Functional Quick Sort: 구현이 더 직관적이고 이해하기 쉽습니다. 파이썬의 list comprehension을 사용하여 간결하게 작성할 수 있습니다. 그러나 메모리 사용량이 더 많습니다.
결론
- In-Place Quick Sort: 메모리 사용량을 최소화하고자 할 때 적합합니다. 다만, 구현이 약간 더 복잡할 수 있습니다.
- Functional Quick Sort: 구현이 간단하고 이해하기 쉬워 교육 목적으로 적합합니다. 다만, 메모리 사용량이 더 많아질 수 있습니다.
실제 사용에서는 메모리 사용량이 큰 문제가 되지 않는 한, 코드의 가독성과 유지보수성을 고려하여 함수형 스타일의 구현을 사용하는 것도 좋은 선택일 수 있습니다. 성능이 중요한 상황에서는 In-Place Quick Sort를 사용하는 것이 더 효율적일 수 있습니다
기수정렬
기수 정렬(Radix Sort)은 정수나 문자열과 같은 비교가 아닌 정렬 방식을 사용하는 알고리즘입니다. 이 알고리즘은 데이터의 자릿수나 문자의 위치를 기준으로 그룹을 나누어 정렬하는 방식을 취합니다. 기수 정렬은 특히 정수를 정렬할 때 효율적이며, 내부적으로 안정적인 카운팅 정렬(Counting Sort)이나 버킷 정렬(Bucket Sort)을 사용하여 각 자릿수별로 정렬을 수행합니다. 기수 정렬의 시간 복잡도는 O(nk)로, n은 정렬할 원소의 수, k는 원소의 최대 자릿수를 의미합니다.
핵심 설명
기수 정렬의 과정은 다음과 같습니다:
1. 가장 낮은 자릿수부터 시작하여 가장 높은 자릿수까지 순차적으로 정렬을 수행합니다.
2. 각 자릿수에 대해 안정적인 정렬 알고리즘(예: 카운팅 정렬)을 사용하여 정렬합니다.
3. 모든 자릿수에 대한 정렬이 완료되면, 전체 데이터가 정렬됩니다.
구현
- 예시 데이터
정렬하기 전: [170, 45, 75, 90, 802, 24, 2, 66]
코드
def counting_sort(arr, exp1):
n = len(arr)
output = [0] * n
count = [0] * (10)
for i in range(0, n):
index = arr[i] // exp1
count[index % 10] += 1
for i in range(1, 10):
count[i] += count[i - 1]
i = n - 1
while i >= 0:
index = arr[i] // exp1
output[count[index % 10] - 1] = arr[i]
count[index % 10] -= 1
i -= 1
for i in range(0, len(arr)):
arr[i] = output[i]
def radix_sort(arr):
max1 = max(arr)
exp = 1
while max1 // exp > 0:
counting_sort(arr, exp)
exp *= 10
arr = [170, 45, 75, 90, 802, 24, 2, 66]
radix_sort(arr)
print(arr)참고자료
https://www.daleseo.com/sort-quick/
https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
https://akdl911215.tistory.com/386
https://hyen4110.tistory.com/55
https://wikidocs.net/233714
https://10000cow.tistory.com/entry/%EC%A0%95%EB%A0%AC-7-%EA%B8%B0%EC%88%98-%EC%A0%95%EB%A0%ACradix-sort
