그래프
그래프란?

그래프 예시
- 그래프는 연결되어 있는 원소 사이의 다대다 관계를 표현하는 자료구조이다.
- 그래프 G는 객체를 나타내는 정점 V(vertex)와 객체를 연결하는 간선 E(edge)의 집합이다.
- 트리도 그래프의 한 종류이며, 그 중 사이클(cycle)이 허용되지 않는 그래프를 말한다.
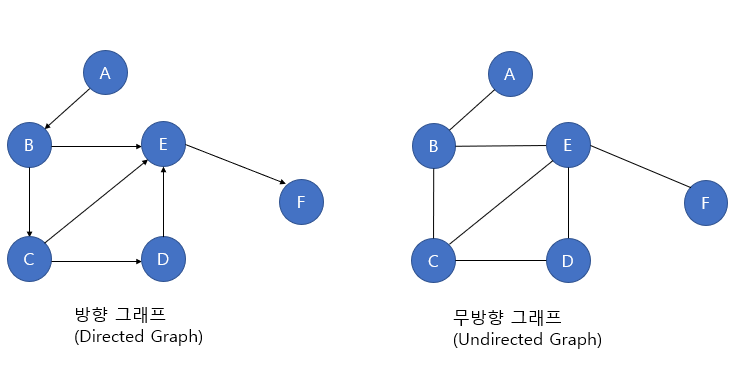
그래프의 종류
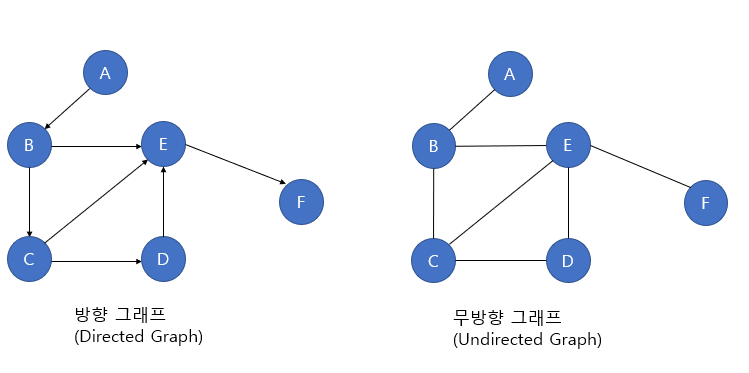
방향이 있는 방향 그래프(Directed Graph) vs 방향이 없는 무방향 그래프(Undirected Graph)
완전 그래프
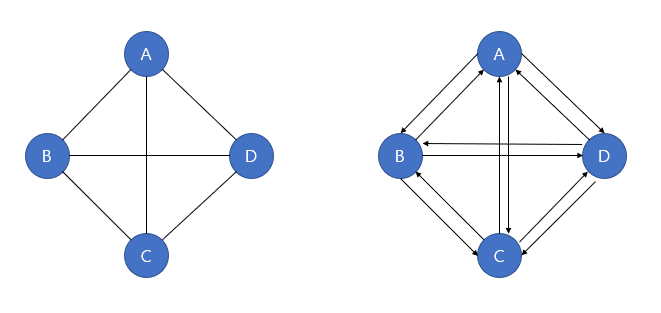
완전 그래프(Complete Graph)는 각 정점에서 다른 모든 정점이 연결된, 최대한 많은 간선 수를 가진 그래프를 뜻한다.
정점이 N개인 무방향 그래프에서 최대 간선 수 : N(N-1)/2 개 ( ex : 위 그림에서 4(4-1)/2 = 6개 )
정점이 N개인 방향 그래프에서 최대 간선 수 : N(N-1)개 ( ex : 위 그림에서 4(4-1) = 12개 )
부분 그래프
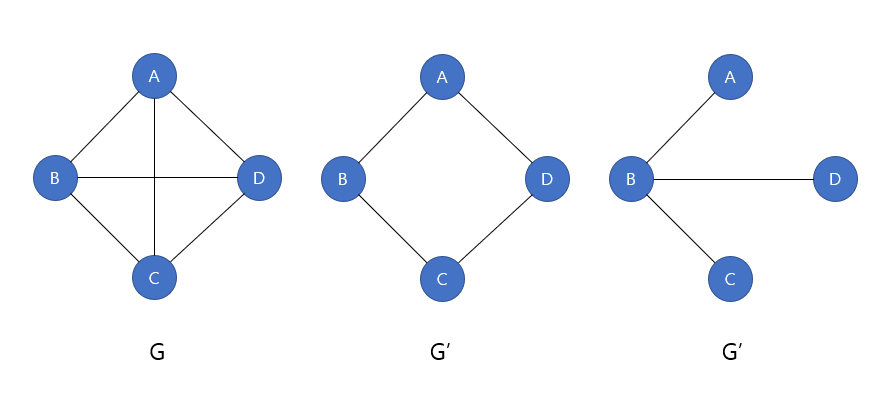
부분 그래프(Subgraph)는 원래 그래프에서 일부 정점이나 간선을 제외하고 만든 그래프이다.
가중치 그래프
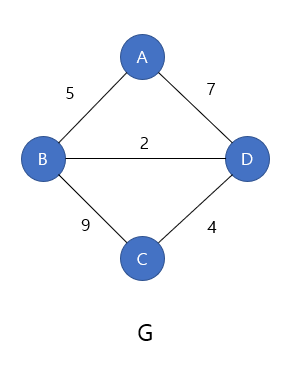
가중치 그래프(Weighted Graph)는 간선에 가중치가 부여되어 있는 그래프를 뜻한다. 지도를 그래프로 표현했다고 생각하면 이해가 쉽다. 예를 들어 'A도시에서 B도시는 5Km, C에서 D도시는 4Km 거리이다' 를 나타내려면 간선에 가중치를 부여하면 된다. 가중치 그래프는 네트워크(Network) 라고도 한다.
연결그래프 vs 비연결그래프
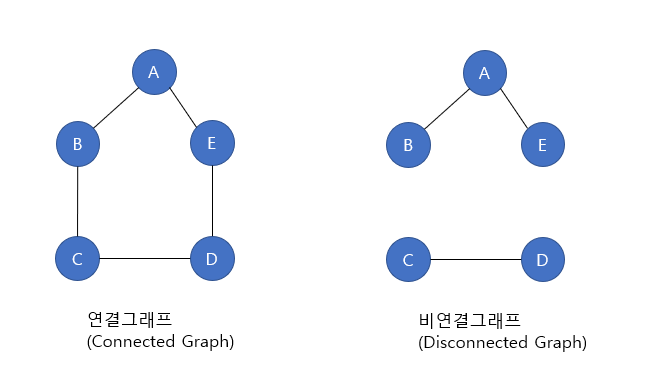
연결그래프(Connected Graph)는 서로 다른 모든 쌍의 정점들 사이에 경로가 있는 그래프를 말한다. 비연결그래프는 연결되지 않은 정점이 있는 그래프를 뜻한다.
그래프 용어
- 인접(adjacent) : 두 정점을 연결하는 간선이 있을 때 서로 인접하다고 한다. (ex : A와 B는 인접되어있다.)
- 부속(incident) : 인접한 두 정점사이의 간선은 두 정점에 부속되었다고 한다.
-
차수(degree) : 차수는 정점에 부속되어 있는 간선의 수를 뜻한다. 무방향그래프에서는 단순히 정점에 연결된 간선의 수를 뜻하지만, 방향 그래프에서는 진입차수(in-degree) 와 진출차수(out-degree)가 다르다. 예를 들어 무방향 그래프에서 E의 차수는 4이지만, 방향 그래프에서는 진입차수는 3이고 진출차수는 1이다. 즉, 진입차수는 들어오는 간선의 개수를 뜻하고, 진출차수는 나가는 간선의 개수를 뜻한다.
-
경로(path) : 그래프에서 간선을 따라 갈 수 있는 길을 정점으로 나열한 것( ex : A->B->C->E->F )
-
경로 길이(path length) : 경로를 구성하는 간선의 수
-
단순 경로 (simple path) : 모두 다른 정점으로 구성된 경로를 뜻한다.
-
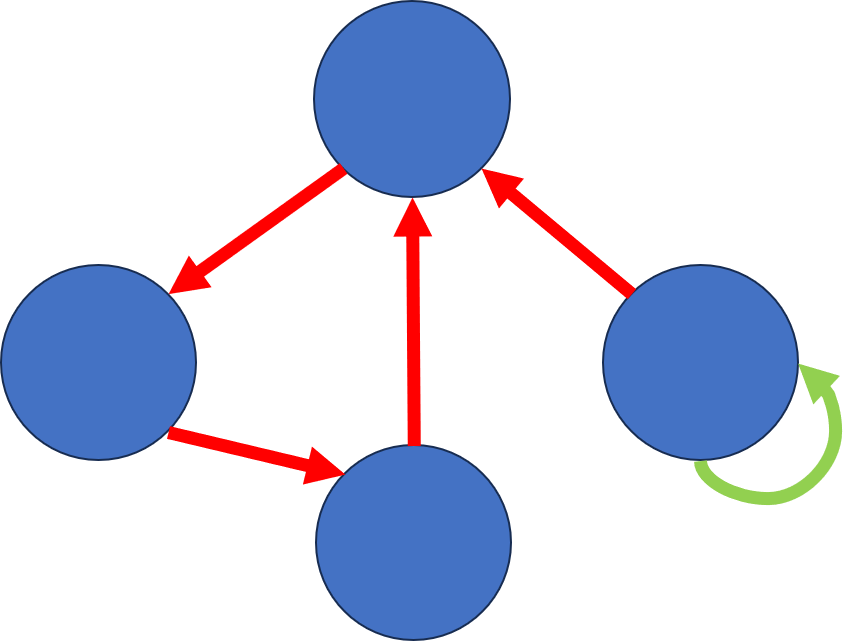
순환Permalink
그래프에서는 순환(cycle)이라는 개념이 있는데 노드간 간선으로 인해 하나의 cycle을 만들 수 있으면 cyclic graph, 만들 수 없다면 acyclic graph라고 합니다.
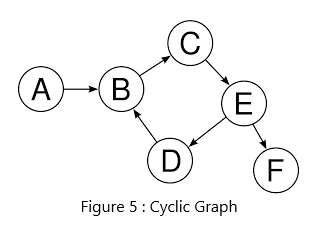
(출처 : study.com)
위 그래프에서는 노드 B-C-E-D에서 cycle을 형성하므로 cyclic graph라고 할 수 있습니다.
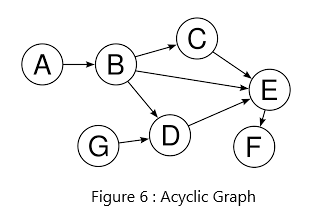
*(출처 : [study.com](http://study.com/))*그에 반해 위 그래프는 cycle이 없으므로 acyclic graph입니다.
얼핏 보면 노드 B-C-E-D가 cycle을 형성하는 것처럼 보이지만, 간선의 방향을 잘 보시면 B에서 뻗어나간 간선들이 다시 B로 돌아오는 케이스가 없습니다.
위에 예시로 붙여넣은 cyclic graph는 B에서 출발하여 C → E → D 경로를 거쳐 다시 D에서 B로 오기 때문에 cyclic graph입니다.
그러나 acyclic graph의 예시 이미지는 B에서 출발하여 C와 D와 E로 가고, C와 D는 무조건 E, E는 무조건 F로만 가므로 다시 B로 돌아오지 않으니, cyclic graph라고 할 수 없습니다.
따라서, cyclic graph인지 판별할 때는 간선의 방향도 유심히 살펴보아야 합니다.
여기서, 하나 더 첨언하자면 트리는 부모-자식 관계만 성립하기에 절대 사이클이 생길 일이 없습니다. 따라서, acyclic graph의 한 종류라고 할 수 있을 것 같습니다.
그래프를 표현하는 방법
Adjacency Matrix 와 Adjacency List
- Adjacency Matix : 2차원 배열을 이용하여 표현한다. 연결이 있으면 ‘1’ , 연결이 없으면 ‘0’
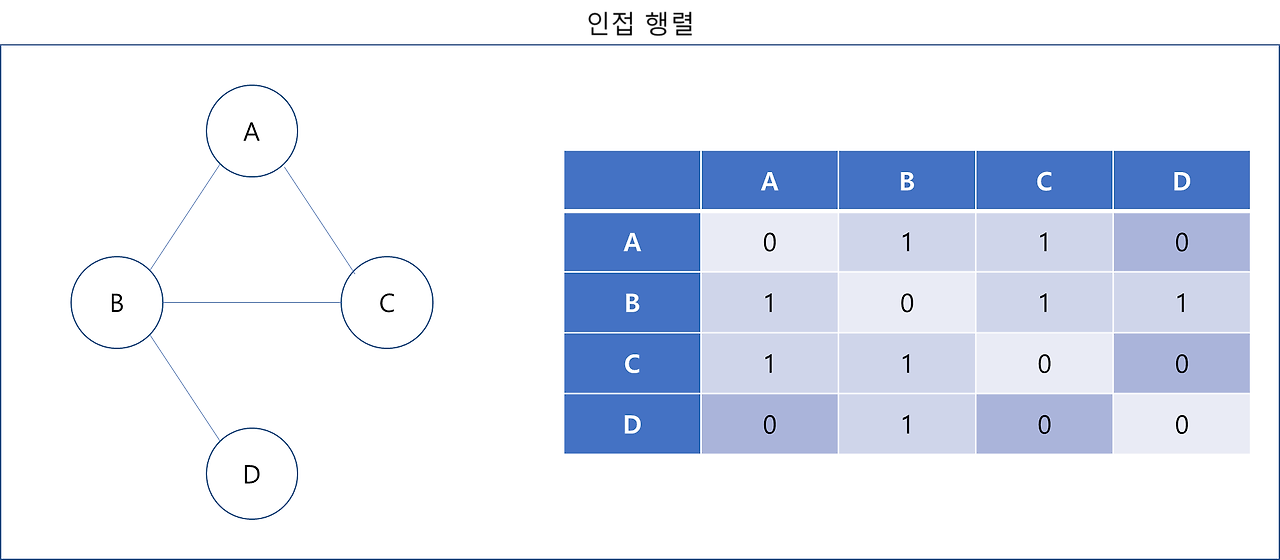
인접 행렬은 2차원 배열에 각 노드가 연결된 형태를 기록하는 방식이다. A와 A끼리는 자기 자신이니 0으로 표현하고, 연결되어 있다면 1로, 아니라면 0으로 표현한다. 이걸 코드로 쓰면 다음과 같다.
코드
graph = [
[0, 1, 1, 0],
[1, 0, 1, 1],
[1, 1, 0, 0],
[0, 1, 0, 0]
]❗ Adjacency의 뜻은 ‘인접’이란 뜻으로 ‘2’와 ‘3’의 경우 ‘1’을 통해 간접적으로 연결 되었어도 직접적으로 연결되지 않았기에 0 으로 표현한다.
- Adjacency List : 배열의 노드를 나열하고 관계를 링크드 리스트로 표현한다.
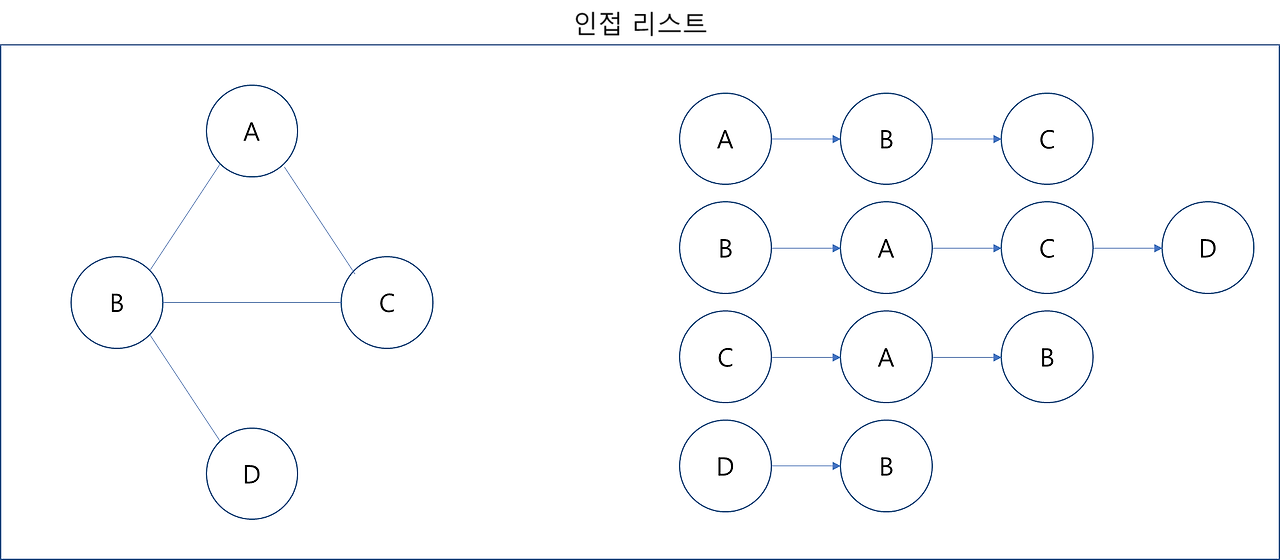
인접 리스트는 모든 노드에 연결된 노드들의 정보를 차례대로 기록하는 방식이다. C나 Java같은 언어들은 배열을 사용할 때 미리 배열의 크기를 지정하고 선언해야 하는데, 파이썬의 리스트는 append()와 같은 메소드를 가지고 있음으로 배열과 연결 리스트의 기능은 모두 제공한다. 그리하여 파이썬으로는 2차원 배열로도 그래프를 표현하기 충분하다.
코드
graph = [[] for _ in range(4)]
# 노드 A
graph[0].append('B')
graph[0].append('C')
# 노드 B
graph[1].append('A')
...
graph = [['B', 'C'], ['A', 'C', 'D'], ['A', 'B'], ['B']]❗ 여기서 노드들의 갯수는 엣지의 개수를 m이라고 할 때 노드의 개수는 2m이된다.
인접행렬 vs 인접리스트
그렇다면 그래프를 인접리스트와 인접행렬 중 어떤 것으로 구현하는게 효율적일까? 둘을 비교해보자.
밀집 그래프 vs 희소 그래프
만약 정점은 1000개가 있는데 간선은 5개 뿐인 그래프가 있다고 하자. 이렇게 간선의 수가 적은 그래프를 희소 그래프(sparse graph)라고 한다. 이때 이 그래프를 인접행렬로 구현한다면, 오직 5개의 연결(간선)을 나타내기 위해 1000x1000행렬을 사용해야한다. 하지만 인접리스트로 구현하게 되면 1005개의 노드만 있으면 충분하다. ( 정점노드(head) 1000개 + 연결된 간선노드 5개) 정확히 따지자면 인접행렬의 공간복잡도(Space Complexity)는 O(V^2) 이고 연결리스트의 공간복잡도(Space Complexity)는 O(V+E) 이다 (V-정점의개수, E-간선의 개수) 따라서 인접리스트는 희소 그래프를 표현하는데 적당한 방법이다.
반면 1000개의 정점이 있고, 간선이 2000개가 있는 그래프가 있다고 하자. 이렇게 간선의 수가 많은 그래프를 밀집 그래프(dense graph)라고 한다. 이 때는 인접행렬로 그래프를 구현하는게 더 효과적이다. 그 이유가 무엇일까? 그것은 바로 행렬의 접근성 때문이다. 어떤 정점이 다른 정점과 연결되었는지 파악할 때 인접행렬은 인덱스를 이용하므로 O(1) 이면 충분하지만, 인접리스트는 head로부터 시작해서 해당 노드를 찾을 때까지 탐색을 진행해야 하므로 시간이 더 많이 걸린다.
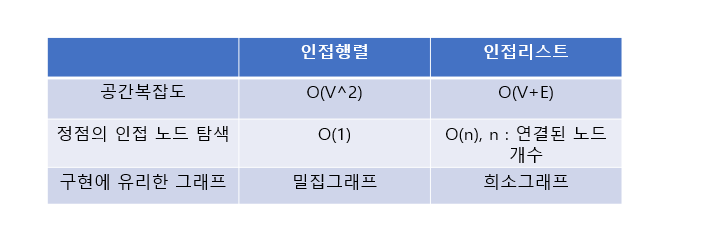
정리하자면 다음과 같다.
인접 행렬 vs 인접 리스트
- 인접 행렬
- 장점: 두 노드의 간선의 존재 여부를 바로 알 수 있음
- 단점: 모든 관계를 기록함으로 노드의 개수가 많을 수록 불필요한 메모리 낭비가 일어남
- 인접 리스트
- 장점: 연결된 것들만 기록함 / 어떤 노드의 인접한 노드들을 바로 알 수 있음
- 단점: 두 노드가 연결되어 있는지 확인이 인접 행렬보다 느림