문제 상황
S3의 데이터를 우리의 Data Mart인 Postgresql로 옮기는 ETL job을 run하면 중복 데이터가 계속 쌓인다.
예를 들어, 어제 100줄짜리 user테이블이 담긴 parquet 파일이 S3에 담겨있었고, 이걸 postgresql로 옮기는 ETL job을 실행했다고 치자. 그러면 S3의 user테이블도 100줄, postgresql의 user테이블도 100줄이다.
그리고 오늘, 20줄이 더 쌓여서 120줄짜리 user테이블이 담긴 parquet 파일이 S3에 담겨있고, 이걸 postgresql로 옮기는 ETL job을 실행한다. 그러면 S3의 user테이블은 120줄, postgresql의 user테이블은 100줄(어제 데이터)+120줄(오늘 데이터) 해서 총 220줄이 쌓인다.
즉, CDC(change data capture)가 전혀 안 되고 있다는 뜻이다.
현재 상황
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node Data Catalog table
DataCatalogtable_node1 = glueContext.create_dynamic_frame.from_catalog(
database="<S3 데이터가 담긴 catalog 데이터베이스>",
table_name="<S3 데이터가 담긴 catalog 데이터베이스안의 테이블>",
transformation_ctx="DataCatalogtable_node1"
)
coalesced_catalog1 = DataCatalogtable_node1.coalesce(1)
# Script generated for node Data Catalog table
DataCatalogtable_node7 = glueContext.write_dynamic_frame.from_catalog(
frame=coalesced_catalog1,
database="<postgresql 데이터가 담긴 catalog 데이터베이스>",
table_name="<postgresql 데이터가 담긴 catalog 데이터베이스안의 테이블>"",
transformation_ctx="DataCatalogtable_node7",
)
job.commit()이런 코드에 Job Details는 어떠한 추가 설정도 하지 않은 상태이다.
해결 방법
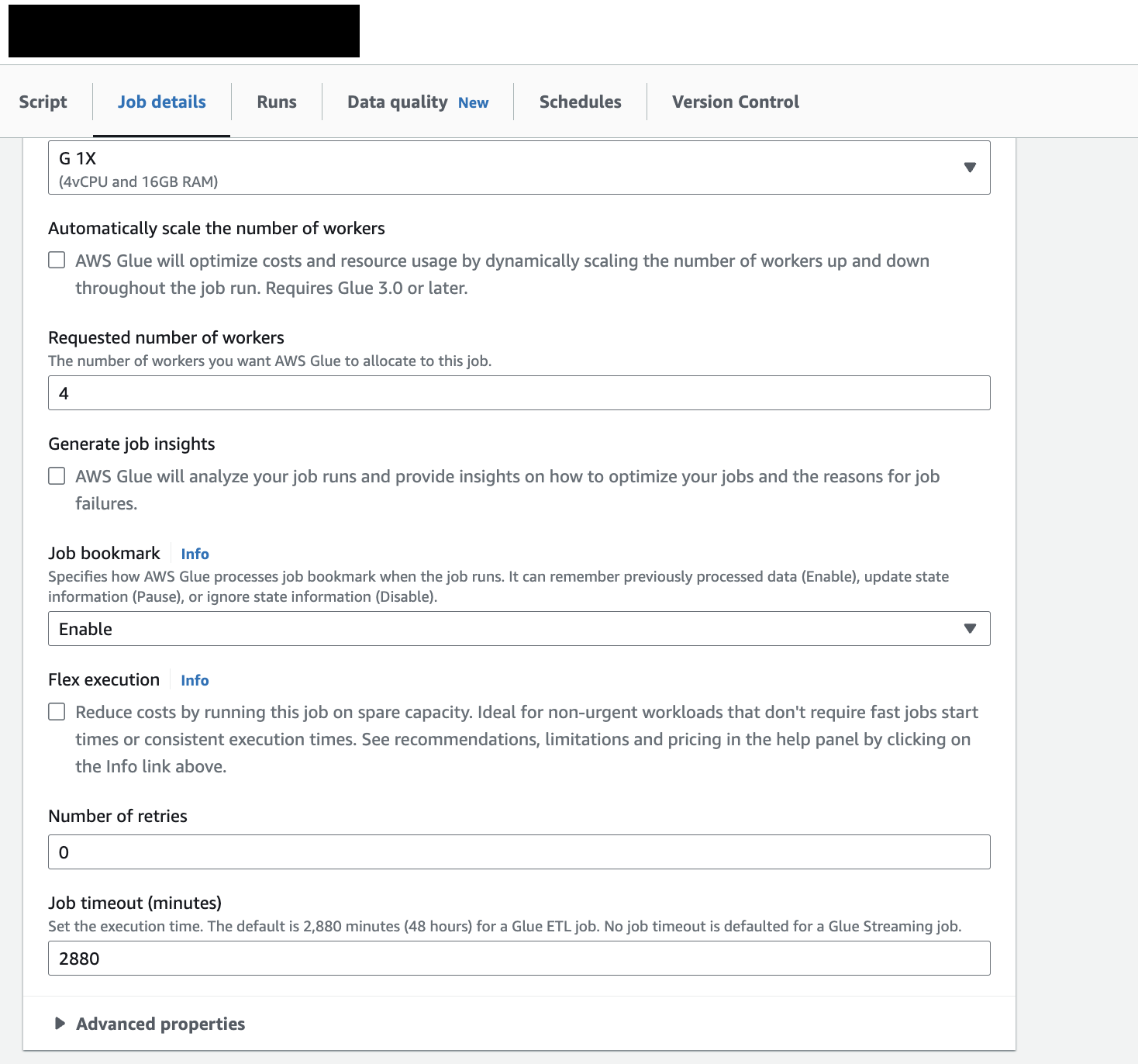
bookmark기능을 활성화 하면 된다.
Glue의 bookmark란, ETL 작업을 이전 실행에서 처리한 데이터를 추적하기 위해 작업 실행에서 상태 정보를 유지하는 기능이다. 즉, 전날 ETL job을 할 때 마지막 줄에다가 책갈피를 꽂아놓고 오늘 실행할 때는 책갈피를 꽂은 그 다음부터만 데이터를 처리하는 것이다. 참고
기본 default는 Disable인데 이걸 Enable로 바꿔주면 된다.
| Status | Description |
|---|---|
| Enable | 작업을 실행한 후 상태를 업데이트하여 이전에 처리한 데이터를 추적하도록 하는 역할을 합니다. 작업에 작업 북마크를 지원하는 소스가 있는 경우, 처리된 데이터를 추적하며 작업이 실행될 때 마지막 체크포인트 이후의 새로운 데이터를 처리합니다. |
| Disable | 작업 북마크가 사용되지 않으며, 작업은 항상 전체 데이터 집합을 처리합니다. 이전 작업 실행의 출력을 관리하는 것은 사용자의 책임입니다. 이것이 기본 설정입니다. |
| Pause | 마지막 성공한 실행 이후 또는 다음 하위 옵션에 의해 식별된 범위 내의 데이터를 처리하기 위해 작업 북마크의 상태를 업데이트하지 않고 처리합니다. 이전 작업 실행의 출력을 관리하는 것은 사용자의 책임입니다. 이 두 가지 하위 옵션이 있습니다. job-bookmark-from, job-bookmark-to |
이러한 옵션들이 있는데, 예를 들어, 그제 100줄, 어제 130줄, 오늘 150줄이 된 데이터가 있다고 가정하면
Enable: 어제의 130줄까지는 이미 처리했기 때문에 책갈피를 오늘 추가된 20줄만 처리한다.Disable: 그제고 어제고 모르겠고 무조건 오늘 기준으로 150줄이기 떄문에 150줄 모두 처리한다.Pausejob-bookmark-from: 만약 오늘 ETL job을 실행할 때job-bookmark-from 어제옵션을 설정한다면, 그제 실행한 100번째부터 오늘기준으로 50줄을 처리한다.job-bookmark-to:job-bookmark-to 어제옵션을 설정한다면, 어제까지의 130줄을 처리한다.
즉, 매번 Full Refresh를 할거면 -> Disable, Incremental Update를 할거면 -> Enable, 범위를 설정하고 Update를 할거라면 Pause로 설정하면 된다.
나의 경우, Incremental Update였기 때문에 아래와 같이 Job bookmark를 Enable로 해주면 된다.