공식 튜토리얼에 나오는 내용을 기반으로 하되, 직접 MLflow를 사용해보면서 유의할 점들에 더 집중해서 작성한다.
MLflow란?
머신러닝의 생애주기를 위한 오픈 소스 플랫폼
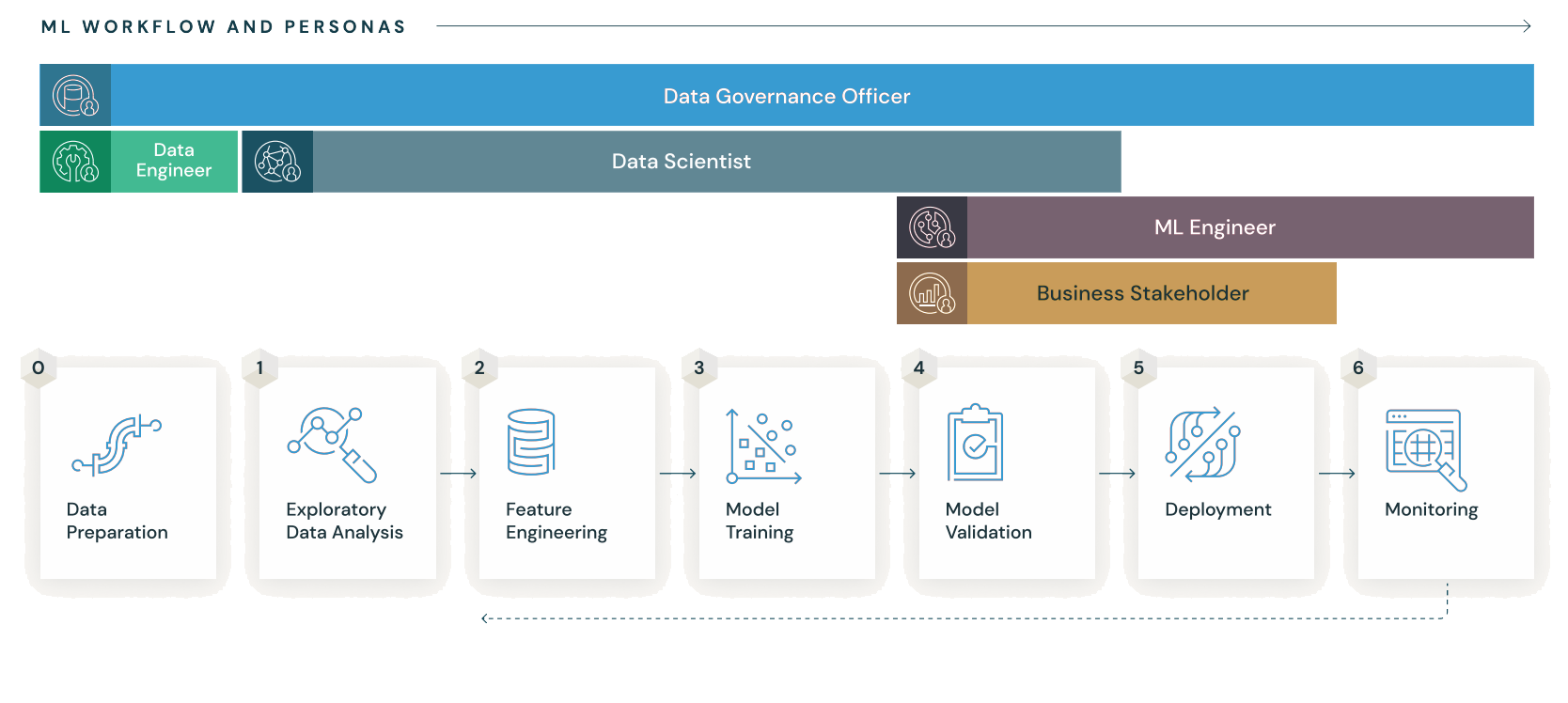
간단하게 말해서, ML 모델의 CI/CD/CT를 위한 툴이라고 생각하면 된다. ML 모델을 배포하기 위한 툴(Torch Serve, SageMaker, Kubeflow 등)은 여러가지 있지만, 그 중에서 모델 관리 측면에서 가장 쉬우면서도 강력한 기능을 제공하는 툴이라고 생각한다.
주요 컴포넌트
- MLflow Tracking
- 모델 파라미터 기록 및 비교, 성능 평가, 아티팩트 관리
- MLflow Models
- 다양한 모델 서비스 및 추론 플랫폼으로 모델 패키징 및 배포
- MLflow Model Registry
- 중앙 모델 관리소.
- MLflow Projects
- 다른 사람과 공유하거나 프로덕션으로 전송하기 위해 재사용 가능하고 재현 가능한 형태로 ML 코드 패키징
- MLflow Recipes
- 다양한 공통 모델링을 위한 템플릿 및 스크립트 재사용 가능한 사전 정의된 템플릿
이렇게 말해도 감이 오기 어렵기 때문에 아래와 같이 정리해보았다.
ML 학습 코드를 작성하고 코드를 실행한 뒤 MLflow Tracking을 통해 확인하고 → MLflow Models 형태로 묶어 -> MLflow Model Registry에 저장하고 → 다른 사람과 공유하기 위해 MLflow Projects로 패키징되어 → 필요에 따라 MLflow Recipes에 저장하여 재사용성을 높힌다.
설치 방법
기본적으로는 공식문서를 따르면 된다.
필자는 ubuntu 22.04 서버에서 진행하였으며, sklearn의 LGBM 모델을 배포하는 것이 글의 목적이다.
- MLflow 설치
$ pip install mlflow- MLflow는 가상환경 설치가 필수다. 다만, 공식문서에는 conda를 설치하라고 했지만, 개인적으로는 무겁다 판단하여 pyenv를 설치하여 진행하였다. 평소엔 virtualenv를 많이 사용하지만, 어째서인지 MLflow를 실행하면 virtualenv로 설치한 가상환경을 못 잡아서 그냥 pyenv를 사용했다.
# pyenv 설치
$ curl -L https://raw.githubusercontent.com/yyuu/pyenv-installer/master/bin/pyenv-installer | bash
# ~/.bashrc에 추가
export PATH="~/.pyenv/bin:$PATH"
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
# 파이썬 설치
$ pyenv install <version-you-want>
# 가상환경 생성
$ pyenv virtualenv <version-you-want> <virtualenv-name-you-want>
# 가상환경 실행
$ pyenv activate <virtualenv-name-you-want>모델 학습
이제 train.py 파일을 작성하고 데이터셋만 불러오면 학습을 시작할 수 있다.
- 모델을 위한 폴더를 하나 만든다.
$ mkdir my_lgbm
$ cd my_lgbm- 폴더에 총 3개의 파일을 만든다.
train.py: 모델 학습 시킬 파일MLproject: 전체적인 프로젝트 관리를 위한 파일python_env.yaml: 설치한 라이브러리 의존성 관리를 위한 파일
train.py파일을 작성한다.
import warnings
import pandas as pd
import re
import lightgbm as lgb
from sklearn.model_selection import train_test_split
import mlflow
from mlflow.models import infer_signature
def main():
warnings.filterwarnings("ignore")
# 데이터셋 준비
X = pd.read_csv('X_train.csv',encoding ='utf-8')
y = pd.read_csv('y_train.csv',encoding ='utf-8')
df = pd.concat([X, y], axis=1)
train, test = train_test_split(df, test_size=0.25, random_state=42)
# autolog 로드
mlflow.lightgbm.autolog()
# train.py 파일 실행시 자동으로 학습
with mlflow.start_run() as run :
# 학습
regressor = lgb.LGBMClassifier(learning_rate = 0.5, max_depth = 20, n_estimators = 256)
regressor.fit(X=train.iloc[:, :-1], y=train.target)
# 모델 저장
model_info = mlflow.sklearn.log_model(regressor, "model")
# 모델 평가
model_uri = mlflow.get_artifact_uri("model")
result = mlflow.evaluate(
model_uri,
targets,
targets = "target",
model_type = "classifier",
evaluators = ["default"]
)
if __name__ == "__main__":
main()한 가지 주의사항은, 데이터셋을 로드할 때 컬럼명에 주의해야 한다. 나의 경우, _ 와 -, (스페이스)가 많아 lightgbm.basic.LightGBMError: Do not support special JSON characters in feature name. 에러가 발생했는데, 컬럼명을 수정해주는 것으로 에러를 해결할 수 있었다.
import re
X = X.rename(columns = lambda x:re.sub('[^A-Za-z0-9_]+', '', x))좀 더 자세히 코드를 설명하자면 아래와 같다.
# 데이터셋 준비
X = pd.read_csv('X_train.csv',encoding ='utf-8')
y = pd.read_csv('y_train.csv',encoding ='utf-8')
df = pd.concat([X, y], axis=1)
train, test = train_test_split(df, test_size=0.25, random_state=42)위의 코드는 train 데이터셋을 불러오는 코드인데, 여기서 주의할 점이 X_train, X_test, y_train, y_test로 나눌 것인지, train, test로만 나눌 것인지이다. 보통은 전자의 경우가 더 많겠지만, 만약 모델 평가 metric을 mlflow.evaluate 메서드를 이용하고 싶다면 train 데이터셋과 test 데이터셋을 하나의 데이터프레임으로 만들어두는 게 편하다.
예를 들어, X_train, X_test, y_train, y_test 이렇게 나누면 나중에 mlflow.evaluate에 인자를 넘길 때 train 데이터셋(X_train, y_train)의 컬럼수와 test 데이터셋(X_test, y_test)의 컬럼수가 다르다고 에러가 나온다. 나의 경우엔 51개의 컬럼으로 1개를 예측하는 것이었는데, train 데이터셋은 컬럼수를 51개로 잡고, test 데이터셋은 컬럼수를 52개로 잡아버렸다.
따라서, 안전하게 train 데이터셋과 test 데이터셋을 묶음으로 만들어두고 mlflow.evaluate 메서드를 날로 먹기로 했다. 물론 metric을 본인이 꼼꼼하게 커스텀하고 싶다면 이렇게 안 해도 괜찮다.
# autolog 로드
mlflow.lightgbm.autolog()MLflow의 정말 좋은 점은 알아서 모델마다 필요한 parameter와 metric을 잡아준다는 것이다. 예를 들어, 위의 학습 코드를 실행하고 MLflow가 제공하는 ui를 타고 들어가면 아래와 같이 알아서 파라미터를 잡아주는 것을 볼 수 있다. 다만, 아래와 같이 자동으로 잡아주는 깔쌈한 걸 보고 싶다면 mlflow.evaluate 메서드를 써줘야 한다. LGBM의 경우 기본 metric으로는 logloss만 보여줬었다.
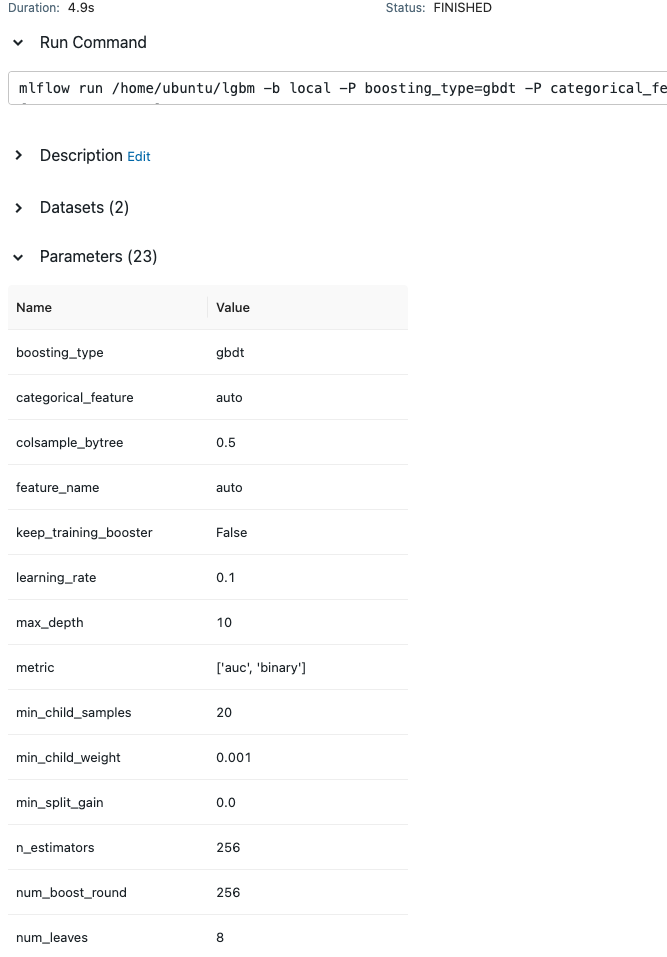
# train.py 파일 실행시 자동으로 학습
with mlflow.start_run() as run :
# 학습
regressor = lgb.LGBMClassifier(learning_rate = 0.5, max_depth = 20, n_estimators = 256)
regressor.fit(X=train.iloc[:, :-1], y=train.target)
# 모델 저장
model_info = mlflow.sklearn.log_model(regressor, "model")
# 모델 평가
model_uri = mlflow.get_artifact_uri("model")
result = mlflow.evaluate(
model_uri,
targets,
targets = "target",
model_type = "classifier",
evaluators = ["default"]
)위의 코드는 train.py 파일을 실행하거나 experiments를 지정한 뒤 run을 실행하면 자동으로 실행되는 부분이다.
다음 포스팅 ⏭️
