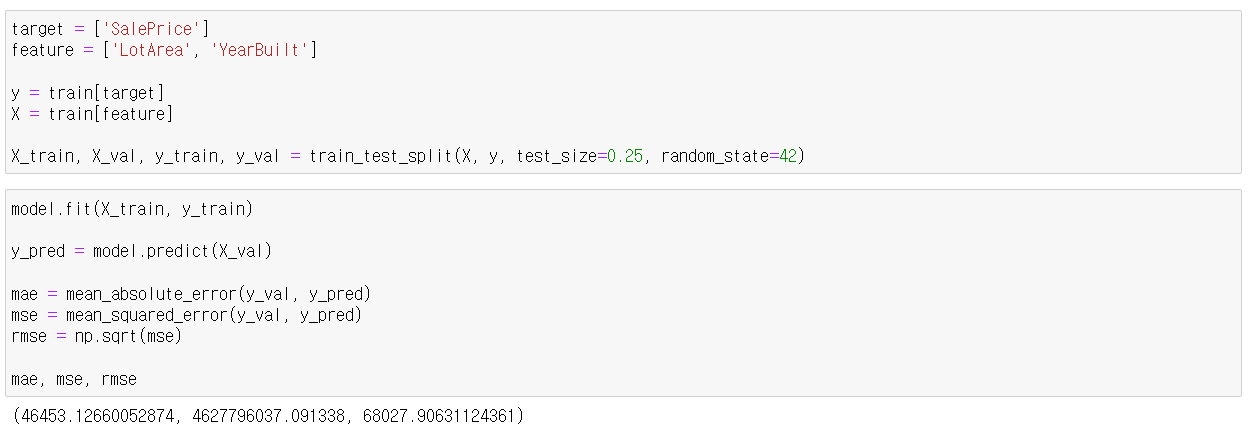
다중선형회귀
train과test데이터셋은 분리해야한다.- 단순선형회귀와 크게 다를 것은 없고, feature 지정해 줄 때 피쳐를 여러개 넣어주면 된다.
from sklearn.linear_model import LinearRegression
#모델 설정
model = LinearRegression()
feature = ['궁금한 피쳐1', '궁금한 피쳐2', '궁금한 피쳐3'...]
target = ['예측할 타겟']
X_train = df[feature]
y_train = df[target]
#모델 학습
model.fit(X_train, y_train)
#테스트 및 성능
y_pred = model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
#회귀 계수 확인
model.coef_
model.intercept_
#시각화
plt.scatter(X_train, y_train, color='black', linewidth=1)
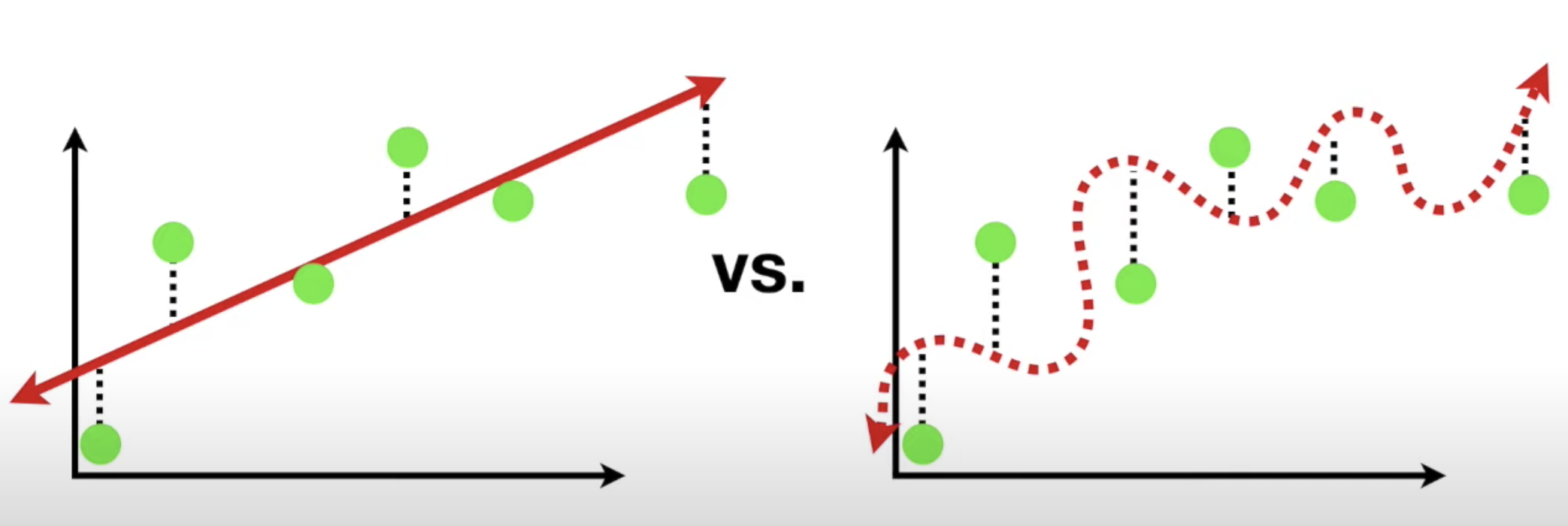
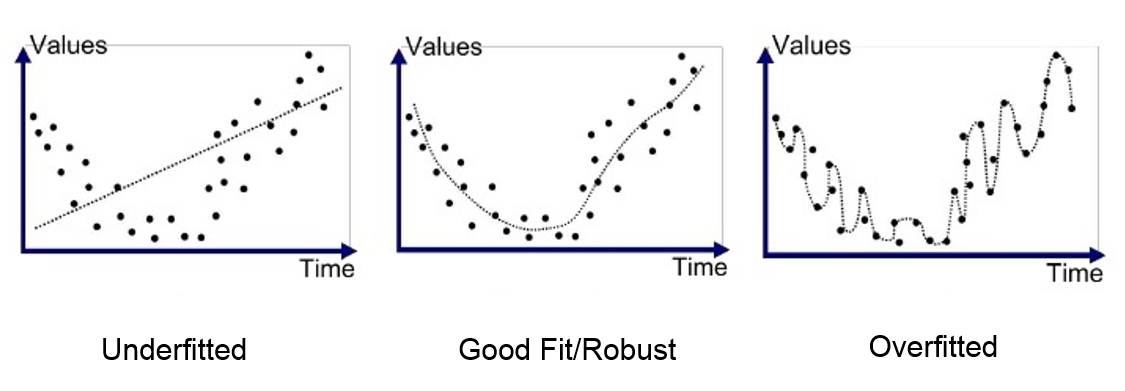
plt.scatter(X_test, y_pred, color='blue', linewidth=1)r2 score가 -1에 가까울수록 쓰레기, 1에 가까울수록 보물MAE는 단위 유닛이 같으므로 보다 해석이 용이하고,MSE는 제곱을 하기 때문에 특이값에 민감하게 반응한다. MSE에 루트를 씌워준게RMSE다.과적합은 일반화가 잘 안 되는 것,과소적합은 예측을 어느 쪽도 잘 못 하는 것(난데....?).- 분산과 편향
- 분산이 높으면 과적합
- 편향이 높으면 과소적합
- 둘은 Trade-off 관계라 둘을 적당히 타협보는 게 좋다.
- 회귀 문제의 평가 지표 코드
def MAE(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred)))
MAE(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)def MSE(y_true, y_pred):
return np.mean(np.square((y_true - y_pred)))
MSE(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)np.sqrt(MSE(y_test, y_pred))
rmse = np.sqrt(mse)def MAPE(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
MAPE(y_test, y_pred)
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) * 100
MPE(y_test, y_pred)MPE의 좋은 점은 모델이 underperformance 인지 overperformance 인지 판단 할 수 있다는 점이다.
실습
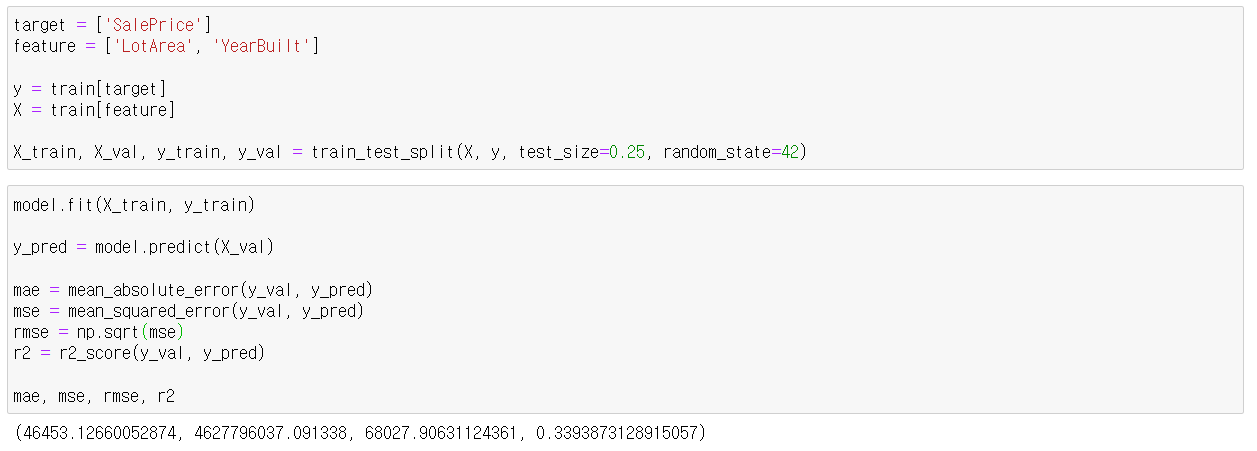
단순선형회귀만으로는 mae : 49200.40041508609, mse : 5037617329.528072, rmse : 70976.17437935121가 나왔는데 조금 성능이 개선된 것을 볼 수 있다.
또한, r2 score도 0.34정도로 나쁘지 않은 정도!

완료주의