릿지 회귀와 인코딩
- 범주형 자료는 명목형(norminal)과 순서형(ordinal)로 나뉜다.
- 명목형은 onehot encoding으로, 순서형은 ordinal encoding으로 처리 해주면 된다.
- 다만, onehot 인코딩을 해주면 high cardinality가 될 수 있기 때문에 유의한다.
from category_encoders import OneHotEncoder
encoder = OneHotEncoder(use_cat_names=True)
X_train = encoder.fit_transform(X_train)
X_test = encoder.transform(X_test)- 특성 선택(feature selection) : 모든 특성을 쓴다고 성능이 좋은 것은 아니다. 따라서, 제일 영향력이 높은 특성만 골라서 사용하는 것도 방법이다.
from sklearn.feature_selection import f_regression, SelectKBest
#학습
selector = SelectKBest(score_func=f_regression, k='선택할 특성수')
X_train_selected = selector.fit_transform(X_train, y_train)
X_test_selected = selector.transform(X_test)
#선택된 특성과 그렇지 않은 특성 확인
all_names = X_train.columns
selected_mask = selector.get_support()
selected_names = all_names[selected_mask]
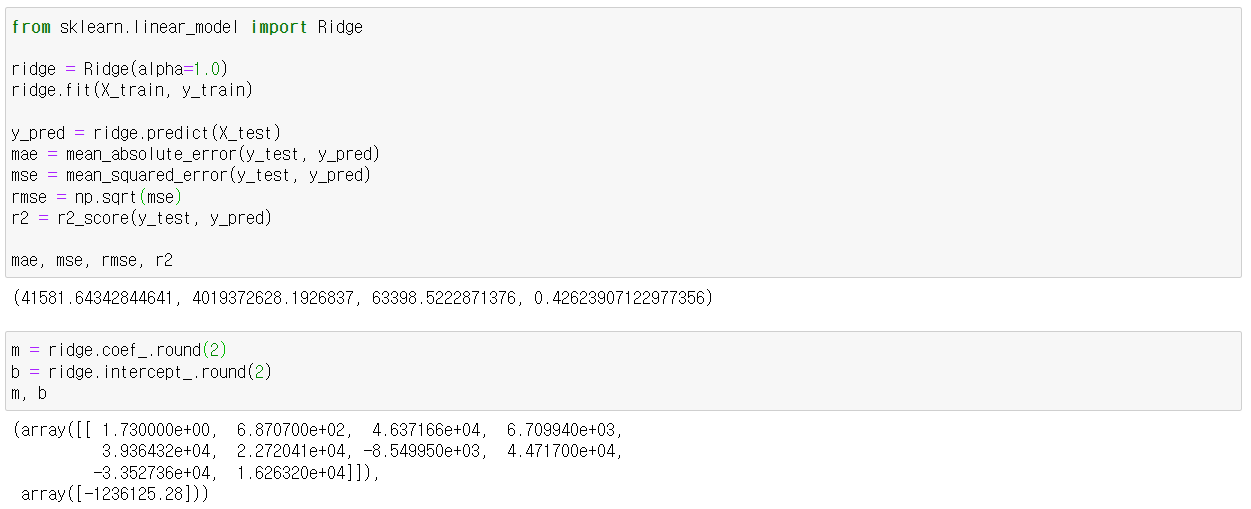
unselected_names = all_names[~selected_mask] - 릿지회귀(ridge regression)은 과적합을 막기 위해 규제(=alpha, penalty, lambda)를 가하는 것. alpha의 default는 1.0이다.
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=1.0)
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)
#회귀 계수
b(특성 순서) = ridge.coef_['원하는 특성']
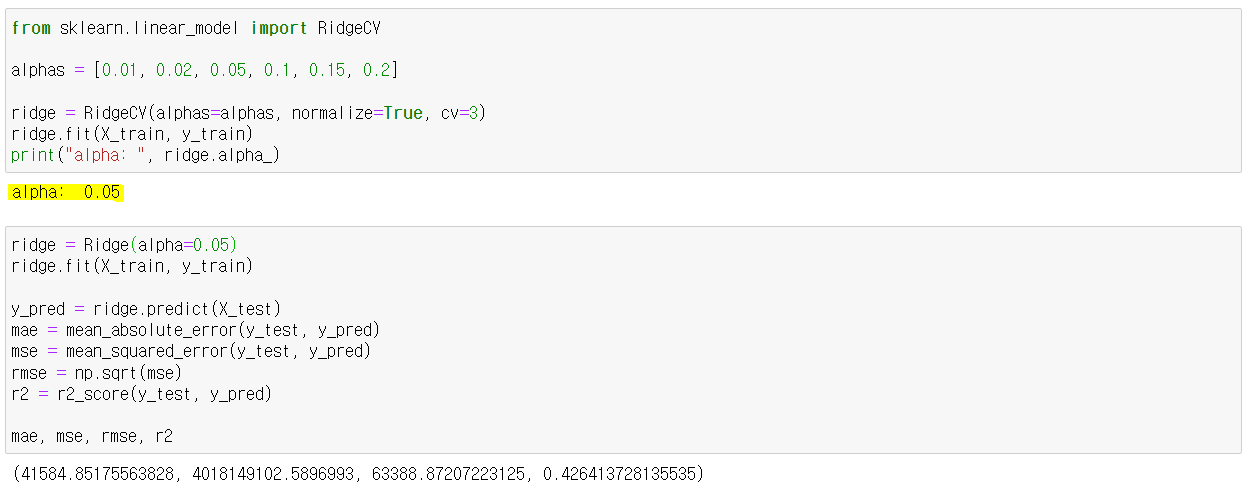
b0 = ridge.intercept_- ridgeCV를 통해 최적의 alpha값을 찾을 수 있다.
from sklearn.linear_model import RidgeCV
alphas = [0.01, 0.02, 0.05, 0.1, 0.15, 0.2]
ridge = RidgeCV(alphas=alphas, normalize=True, cv=3)
ridge.fit(X_train, y_train)
print("alpha: ", ridge.alpha_)실습
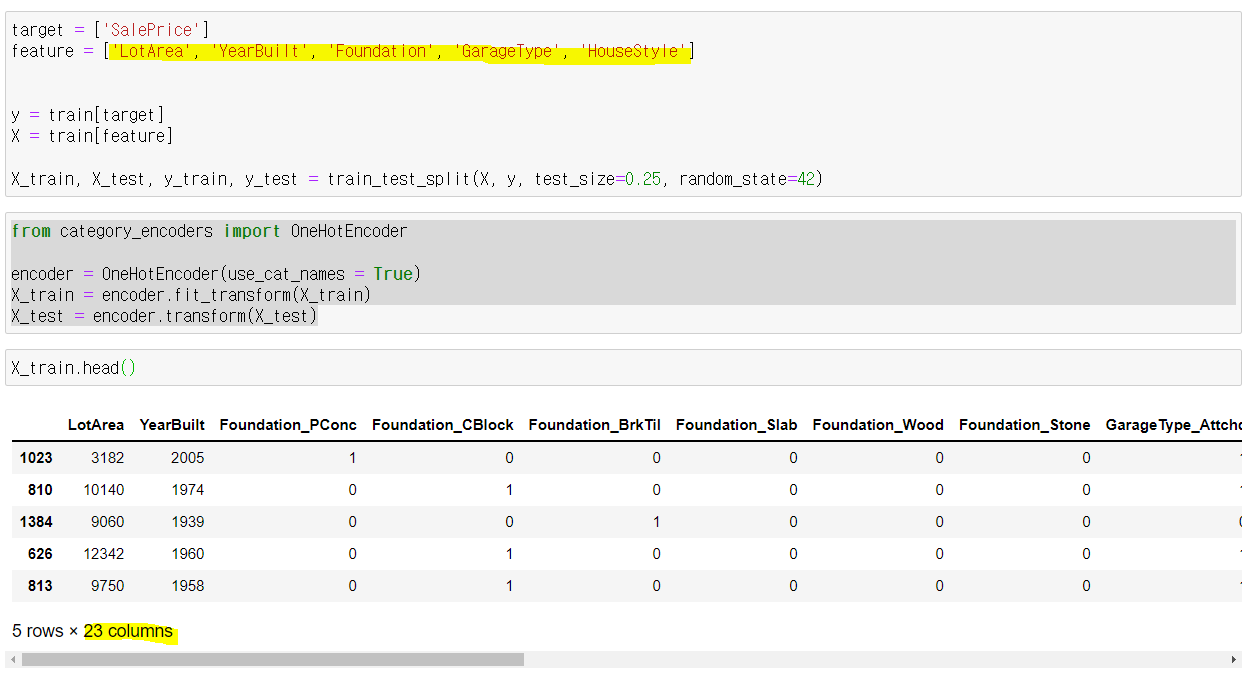
원핫 인코딩
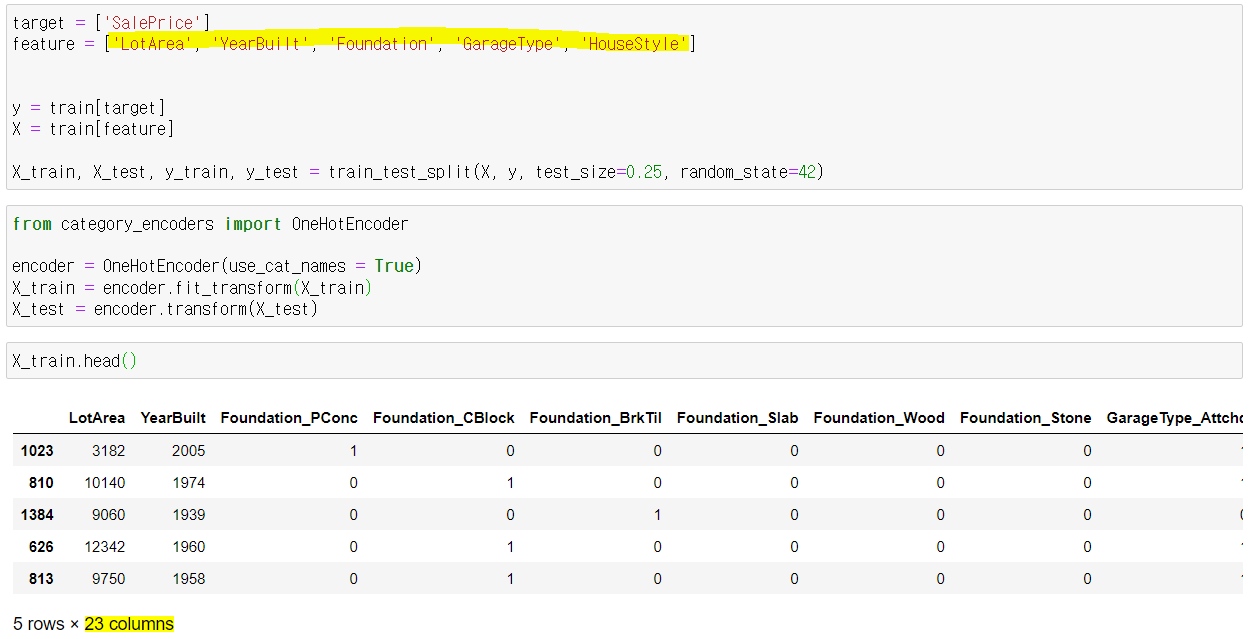
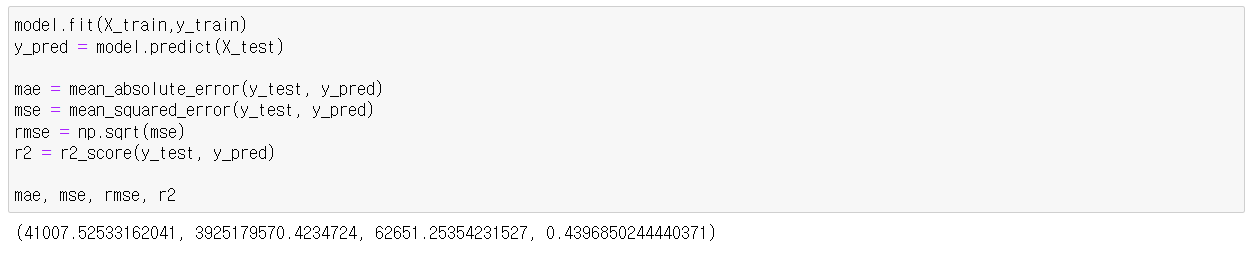
원핫인코딩을 해주긴 전엔 피쳐가 5개였지만, 해주고 나니 23개로 늘어난 것을 볼 수 있다.
성능도 개선된 것을 볼 수 있다.
특성 선택
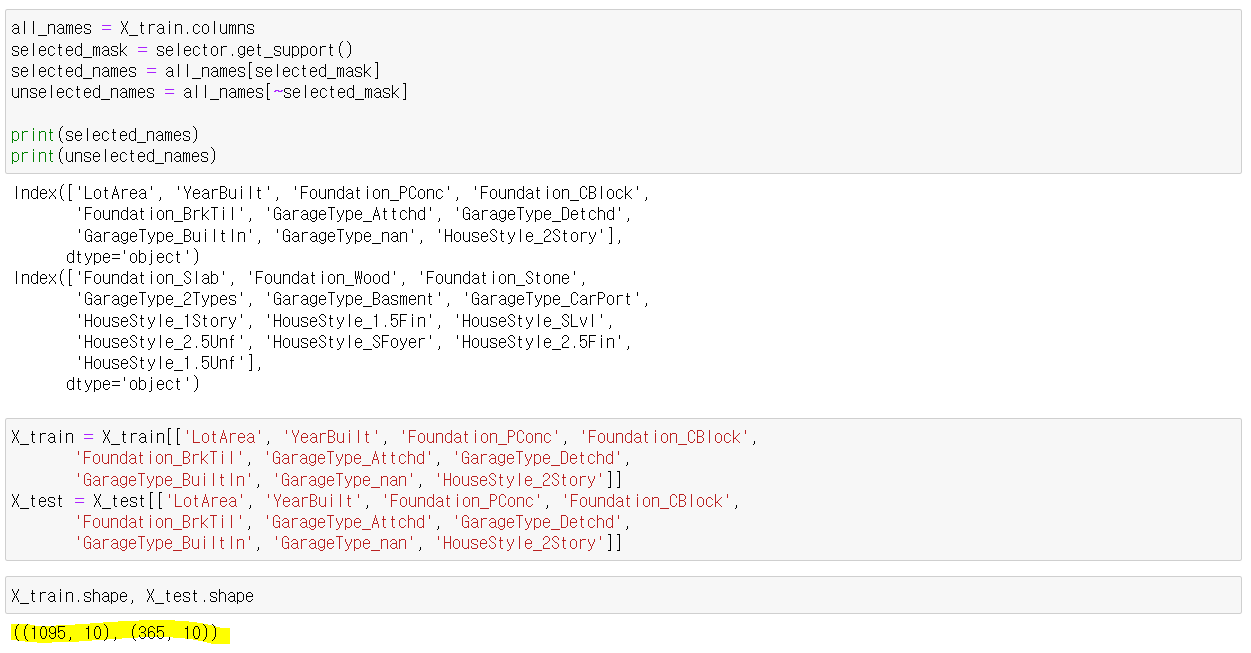
특성 선택을 해주고 10개의 특성만 가지고 선형 모델을 다시 예측해보니 미묘한 차이가 생겼다. (좋아지지도 나빠지지도..?)
릿지 모델
ridgeCV를 통한 최적의 alpha값 도출
실습 최종 성능 비교
단순선형회귀의 경우
(feature = ['YearBuilt'])
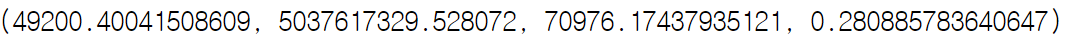
다중선형회귀의 경우
(feature = ['LotArea', 'YearBuilt'])
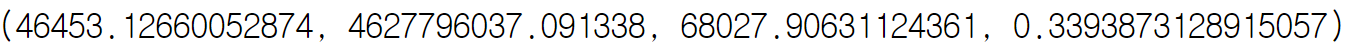
원핫인코딩 수행 한 경우
(feature = ['LotArea', 'YearBuilt', 'Foundation', 'GarageType', 'HouseStyle'])
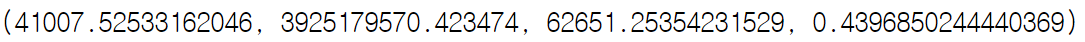
특성 선택 한 경우
(feature = ['LotArea', 'YearBuilt', 'Foundation_PConc', 'Foundation_CBlock',
'Foundation_BrkTil', 'GarageType_Attchd', 'GarageType_Detchd',
'GarageType_BuiltIn', 'GarageType_nan', 'HouseStyle_2Story'])
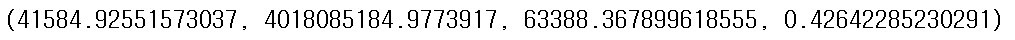
특성 선택 + 릿지 모델의 경우
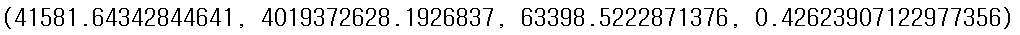
특성 선책 + 릿지 모델 + 릿지 알파값 조정의 경우
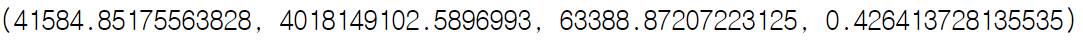
놀랍게도 원핫인코딩 + 다중선형모델의 경우가 가장 성능이 좋았다. 🙄

완료주의