[논문리뷰] Refined Feature-Space Window Attention Vision Transformer for Image Classification
논문스터디
요약
최근 Vision Transformer(ViT) 모델은 이미지 분류에서 뛰어난 성능을 보여주며 주목받고 있다. 특히, Transformer의 강력한 전역적 학습 능력 덕분에 복잡한 이미지에서도 우수한 분류 성능을 발휘할 수 있다. 하지만, ViT의 계산량과 자원의 소모는 실용적인 문제를 야기하며, 이를 개선하기 위한 다양한 연구가 진행되고 있다.
Refined Feature-space Window Attention Vision Transformer는 이러한 문제를 해결하기 위해 Vision Transformer 구조를 개선하여 이미지 분류 성능을 높이고, 계산 효율성을 향상시키는 새로운 접근법이다.
연구목적
기존 Vision Transformer의 높은 연산 비용과 비효율성을 개선하면서도, 정밀한 이미지 분류 성능을 유지하는 것
방법
이미지 공간이 아닌 특징 공간(feature space)에서 유사한 특징을 가진 픽셀들을 하나의 윈도우로 군집화하고, 이를 기반으로 어텐션을 계산한다. 이는 이미지 상에서 물리적으로 떨어져 있어도 특징적으로 유사한 정보를 함께 처리할 수 있도록 한다.
핵심 기술
윈도우 기반 어텐션 메커니즘은 이미지를 여러 개의 윈도우로 나누어 각 윈도우 내에서 어텐션을 계산함으로써, 기존 Transformer의 전역적 계산 비용을 크게 줄인다.
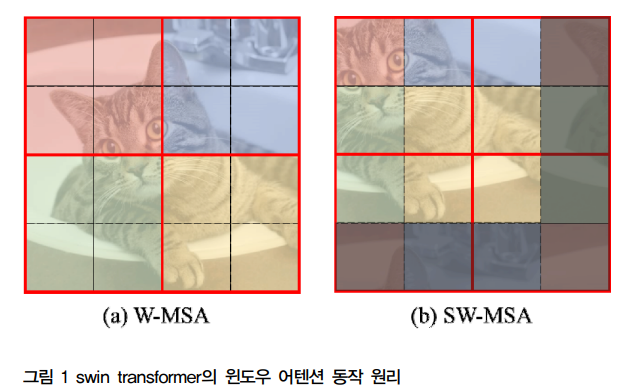
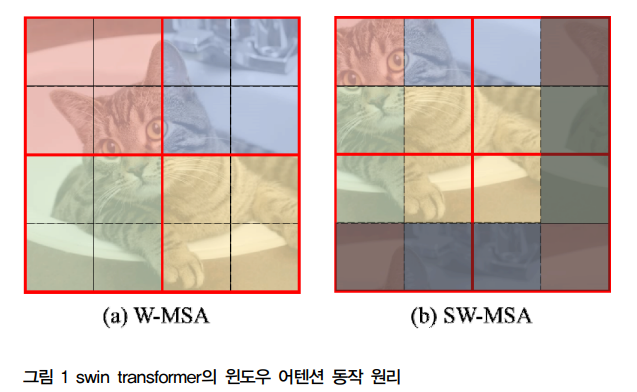
기존의 Swin Transformer는 윈도우 간의 정보 교환이 제한적이라는 단점이 있다. 이를 해결하기 위해 특징 공간에서 윈도우를 분할하는 방식을 도입한 것이 Refined Transformer이다.
Refined Transformer는 BOAT transformer에서 영감을 받아 이미지를 윈도우로 분할할 때 특징 공간에서의 거리를 기준으로 하여 이미지상 거리가 멀지만 서로 연관성 있는 특징 벡터가 유사한 토큰들끼리 하나로 묶는 방법을 채택한다.
정제된 특징 공간에서의 유사도에 따라 군집화된 토큰끼리 어텐션하는 Refined Feature-space window Multi-head Self-Attention(RF-M SA)을 적용하여 거리가 먼 토큰 간의 관계성을 포착한다.
이 모델을 ImageNet-1K로 학습한 결과 기존의 Swin transformer보다 분류 성능이 개선되었다.
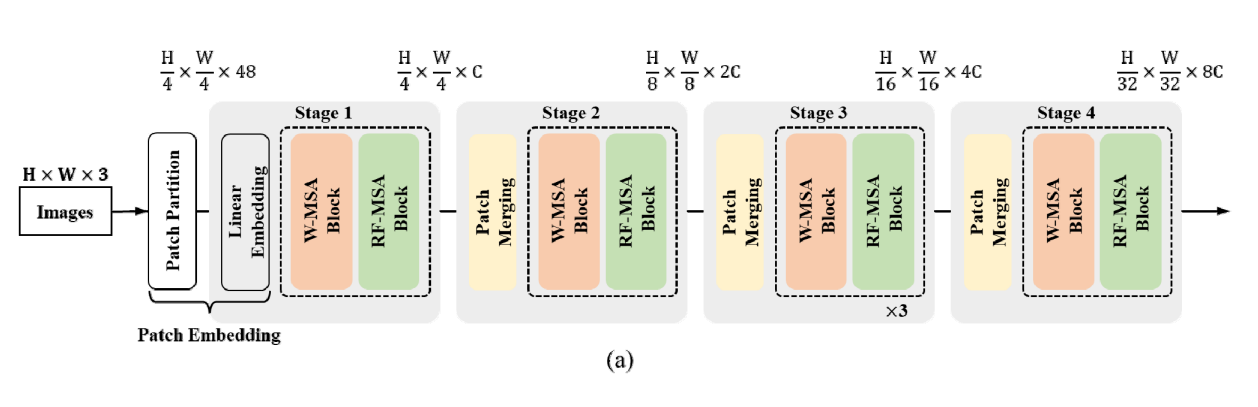
Refined transformer의 전체 구조는 총 4단계로 구성되어 있으며 각 단계는 패치 병합층, W-MSA 블록, RF-MSA 블록으로 구성되어 있다. 네트워크의 가장 앞 단에는 패치 임베딩 층이 위치하여 입력 이미지를 트랜스포머에 입력할 수 있는 형태로 변환한다.
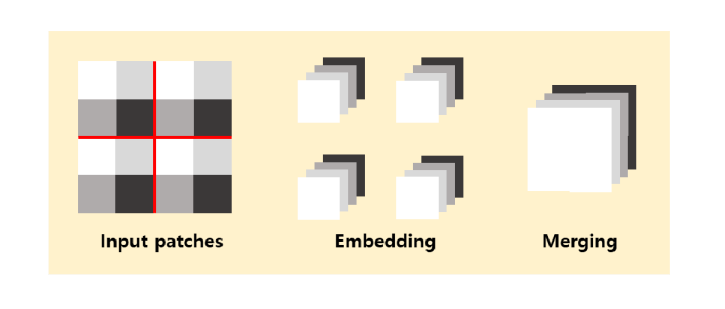
패치 임베딩은 입력으로 받은 이미지를 겹치지 않는 이미지 패치로 분할하고 차원을 조정하여 트랜스포머 인코더에 입력할 수 있는 형태로 바꾸는 과정이다.
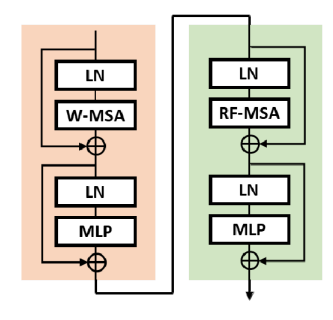
패치 병합층은 W-MSA블록, RF-MSA블록과 연속적으로 이어진다.
W-MSA블록은 Swin transformer에서 제안된 것인데 이는 이미지를 패치로 나눈 후 고정 크기의 윈도우로 패치들을 묶는다. 그리고 나서 같은 윈도우 내에 속한 패치들끼리 어텐션 연산을 하고 윈도우별 어텐션 결과를 잇는 방식으로 전체 이미지에 대한 어텐션 결과를 얻는다.
이 연구에서는 이를 RF-MSA로 대체하였다.
RF-MSA는 크게 세 단계로 나눌 수 있다.
먼저 특징 공간을 정제하여 중요한 부분은 강조하고 아닌 곳은 억제한다. 그리고 정제된 특징 공간에 대해 유사한 토큰끼리 군집화하고 마지막으로, 군집 내에서 어텐션을 수행한다.
이 연구는 모델의 표현력을 향상시키기 위해 CBAM(convolutional block attention model)을 사용하여 특징 공간을 정제하는 방법을 채택했다.
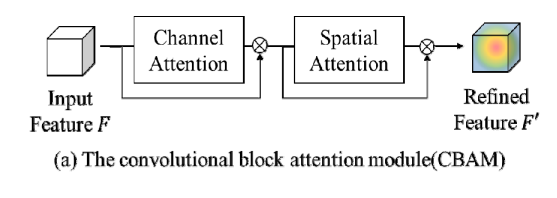
CBAM은 풀링과 합성곱으로 구현된 어텐션 메커니즘을 포함하며 채널 어텐션과 공간 어텐션으로 구성되어 있다.
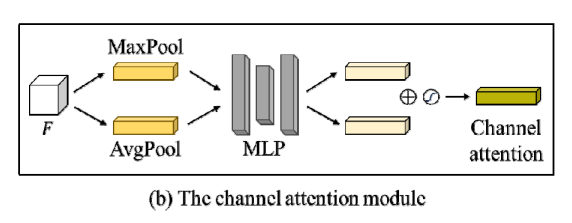
채널 어텐션에서는 입력 특징의 각 채널이 갖는 특징 맵을 취합하기 위해 최대 풀링과 평균 풀링을 동시에 적용하여 공간 차원을 압축한다.
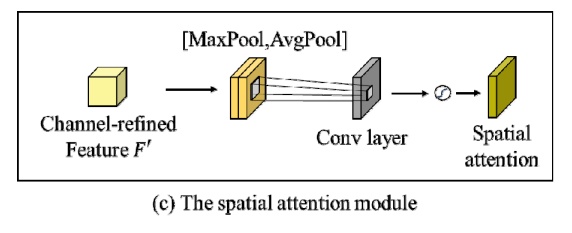
채널 어텐션을 통해 얻은 채널-정제된 특징 맵을 공간 어텐션 모듈에 통과시킨다.
실험 결과
ImageNet-1K 데이터셋에 학습한 결과, Refined transformer는 Swin Transformer를 포함한 기존의 윈도우 기반 어텐션 모델들보다 더 높은 정확도를 기록했다.
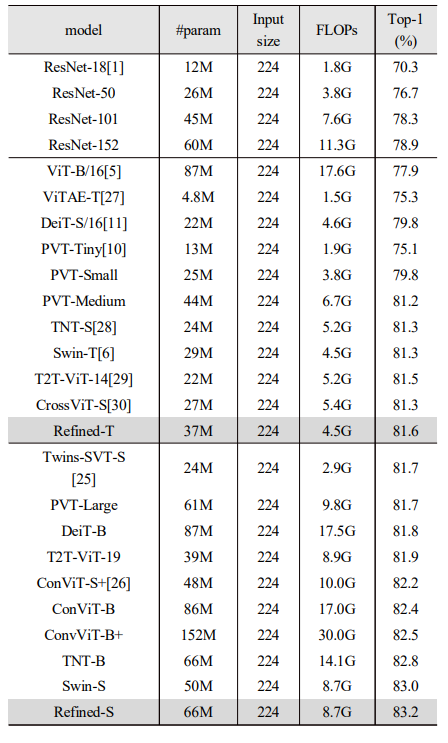
Swin-T와 비교했을 때, Refined-T는 0.3%의 성능 향상을 보였고, Swin-S와 비교했을 때 Refined-S는 0.2% 성능이 개선되었다.
결론
비전 트랜스포머는 복잡한 상황과 다양한 크기의 물체를 인지하는데 이점이 있으므로 향후 자율주행과 같은 분야에 활용할 수 있다.
그러나 고도화된 자율주행을 위해서는 다양한 상황에 대한 학습이 필요한데 비전 트랜스포머의 성능 향상을 위해서는 학습에 많은 양의 데이터를 사용해야 하므로 데이터셋의 확보가 중요한 과제로 남아있다.
