요약
윈도우 기반의 Vision transformer(ViT)는 이미지 크기에 따라 2차 계산복잡도를 나타낸다. 이 문제를 해결하기 위해 윈도우 기반의 self-attention ViT는 attention영역을 특정 윈도우로 제한하여 계산 복잡도를 완화시킨다. 그러나 윈도우 간의 관계를 효과적으로 포착할 수는 없기 때문에 대표적인 윈도우 기반 ViT인 Swin transformer는 SW-MSA(Shifted-window Multi-head Self-attention)를 도입했다.
그러나 SW-MSA는 서로 가까이 있는 토큰을 하나의 창으로 묶기 때문에 멀리 있는 토큰과의 관계를 포착할 수 없다. 그래서 이 연구에서는 멀리 떨어져 있지만 유사한 토큰을 하나의 윈도우에 포함하는 Feature-space Window Attention ViT를 제안하였다.
FSwin transformer는 특징 공간을 기반으로 멀리 떨어져 있지만 유사한 토큰을 클러스터링하고 클러스터 내에서 self-attention을 수행한다.
따라서 이미지 공간을 기반으로 윈도우가 설정될 때 포착할 수 없는 장거리 토큰 간의 global context를 이해하는데 도움이 된다. 또한 channel attention, spatial attention과 함께 특징 공간 정제 방법을 통하여 핵심 부분을 강조하고 불필요한 부분을 억제하면 특징 공간에서 정제된 맵은 모델의 표현력을 향상시켜 분류 성능을 향상시킨다.
연구목적
Swin transformer의 SW-MSA가 가진 멀리 있는 토큰끼리의 관계 포착에 어려움이 있다는 단점을 보완하여 이미지 분류의 정확도와 속도를 향상시키는 것
방법
유사한 특징 벡터를 윈도우로 그룹화하고 그 안에서 이미지 공간뿐만 아니라 특징 공간에서도 어텐션을 작동시킴으로써 관련되어 있지만 멀리 떨어져 있는 이미지 토큰 간의 관계를 포착한다.
소개
기존 CNN과 달리 트랜스포머는 전역 장거리 종속성 기능을 모델링할 수 있으므로 전역적으로 이미지를 이해하고 다양한 규모로 이미지를 처리할 수 있다. 그러나 바닐라 ViT는 이미지를 구성하는 모든 토큰에 대해 어텐션 매커니즘을 채택하므로 이미지 크기에 따라 2차 계산복잡도가 발생한다.
이 문제를 해결하기 위해 Swin transformer 같은 로컬 윈도우 기반 self-attention을 사용하는 트랜스포머 네트워크가 구축되어 어텐션 영역을 특정 영역으로 제한한다. 전역 MSA 및 W-MSA에 필요한 계산량은 다음과 같다.
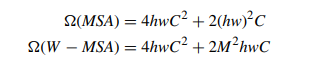
M은 윈도우의 크기를 나타내고 기본값이 7로 설정된다. 그리고 hw는 이미지 크기를 패치 크기로 나누어 얻은 패치 수를 나타낸다. MSA에서 hw에 대해 2차 계산복잡도를 보이는 반면 W-MSA는 hw에 대해 선형 계산복잡도를 보이므로 W-MSA는 계산 효율성이 높다고 볼 수 있다.
Swin transformer는 윈도우 내에서만 어텐션 연산을 수행하므로 계산량이 줄어들지만 동일한 윈도우에 포함되지 않은 토큰 간의 관계를 효과적으로 포착할 수 없다.

이 문제를 해결하기 위해 이 연구에서는 SW-MSA(shifted-window multi-head self-attention)를 제안한다.
SW-MSA는 W-MSA에서 동일한 윈도우로 그룹화하지 않은 패치를 포함하도록 윈도우 분할을 오른쪽 아래로 이동한다. 이렇게 하면 윈도우 간 방식으로 정보를 공유할 수 있다. 그러나 토큰이 이미지 공간에서 먼 거리에 위치한다면 유사하더라도 하나의 윈도우에 묶일 수 없다.
이 연구에서는 BOAT(bilateral local attention transformer)에 영감을 받아 FS-MSA(feature space multi-head self-attention)매커니즘을 채택한 특징 공간 윈도우 어텐션 트랜스포머를 만들었다.
이는 이미지 공간 대신 특징 공간의 이미지 패치 컨텐츠에서 파생된 유사성을 기반으로 윈도우를 분할하고 이러한 패치 내에서만 지역적인 어텐션 연산을 수행한다.
FSwin transformer는 이미지 공간 윈도우 어텐션과 특징 공간 윈도우 어텐션을 순차적으로 적용하여 멀리 떨어져 있지만 유사한 토큰 간의 정보를 포착하고 LayerNorm(LN) 및 multi-layer perceptron(MLP)과 같은 구성 요소를 사용하여 성능을 향상 시킨다.
이 연구에서는 특징 공간을 기반으로 클러스터링을 수행하고 그 안에서 self-attention을 하도록 구현했는데 그 특징 공간은 이미지의 중요한 부분을 강조하고 필수적이지 않은 부분을 억제하는 간단한 어텐션 모듈인 CBAM(convolutional block attention module)을 사용하여 정제된다. CBAM은 채널 어텐션과 공간 어텐션으로 구성되어 있으며 채널 및 공간 측면 모두에서 어텐션할 영역을 강조함으로써 표현력을 향상시키는 데 도움을 준다.
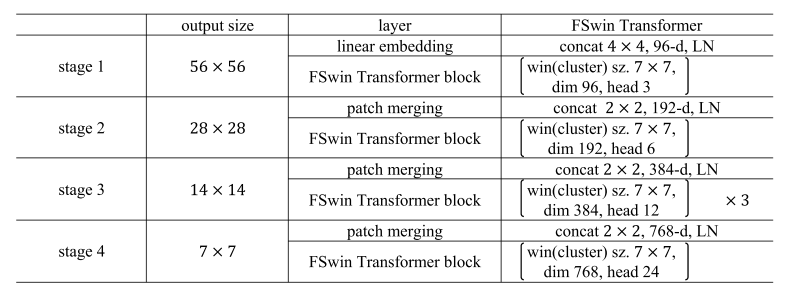
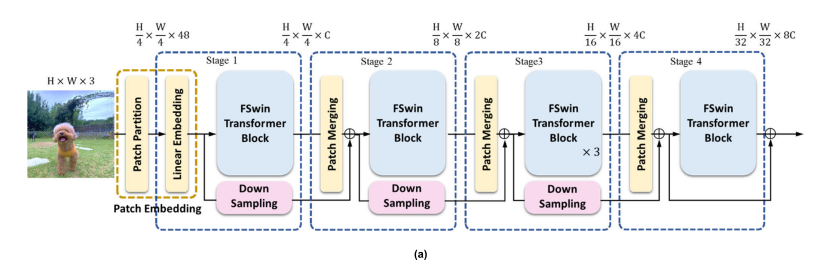
FSwin transformer의 전체적인 구조는 4단계의 스테이지로 구성되어 있다. 각 스테이지는 비중첩 4x4 패치로 이미지를 나누고, 선형 임베딩을 통해 차원을 조정한 후 FSwin Transformer 블록으로 전달된다.
패치 파티셔닝 및 선형 임베딩을 통해 토큰화된 이미지는 1단계의 첫 번째 FSwin transformer 블록에 대한 입력 역할을 한다. 후속 단계에서는 패치 병합 계층과 L FSwin transformer 블록 스택이 있다. 더 깊은 연결 안정성을 위해 skip connection이 스테이지 사이에 적용된다.
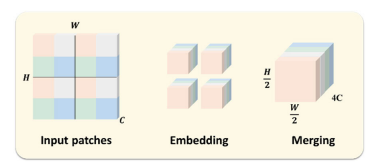
이것은 패치 병합 계층인데 각 단계의 출력이 다음단계의 입력으로 활용되기 전에 지나가는 중요한 구성요소이다. 이 계층은 인접한 이미지 패치를 결합하고 down-sampling하여 모델이 다중 스케일 객체를 학습할 수 있도록 한다.
한 윈도우에 포함되는 패치의 수는 고정되어 있기 때문에 패치가 병합됨에 따라 이미지를 나누는 윈도우의 수가 줄어들게 되므로 적은 계산복잡도와 빠른 계산속도를 얻을 수 있다.
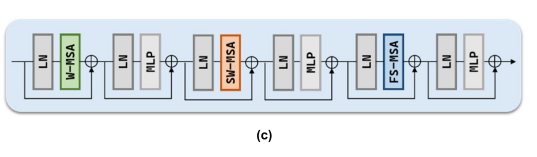
이것은 FSwin transformer 블록이다. 기존의 Swin transformer 블록에 FS-MSA를 적용하였다.
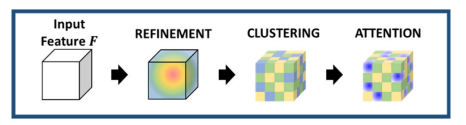
위와 같이 FS-MSA는 세 단계의 절차를 밟는다.
1. Feature Refinement
SW-MSA에서 만든 어텐션 맵을 CBAM을 통해 미세조정하는 작업을 한다.
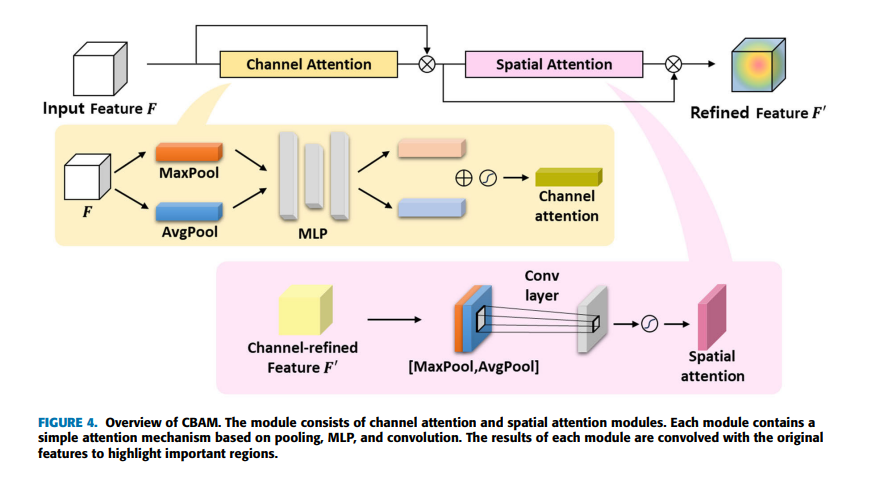
CBAM은 채널 어텐션과 공간 어텐션모듈로 구성된다. 각 모듈에는 풀링, MLP 및 convolution을 기반으로 하는 간단한 어텐션 매커니즘이 포함되어 있다. 각 모듈의 결과는 중요한 영역을 강조하기 위해 기존의 특징들과 컨볼루전 된다.
2. Binary Clustering
정제된 특징 맵에서 유사한 토큰들을 클러스터링하고, 각 클러스터 내에서 multi-head self-attention을 수행하여 멀리 떨어져 있지만 유사한 토큰들 간의 관계를 파악한다.
3. Attention Within Clusters
클러스터링된 토큰들 간의 관계를 self-attention으로 계산하여 최종적으로 합친다.
실험결과
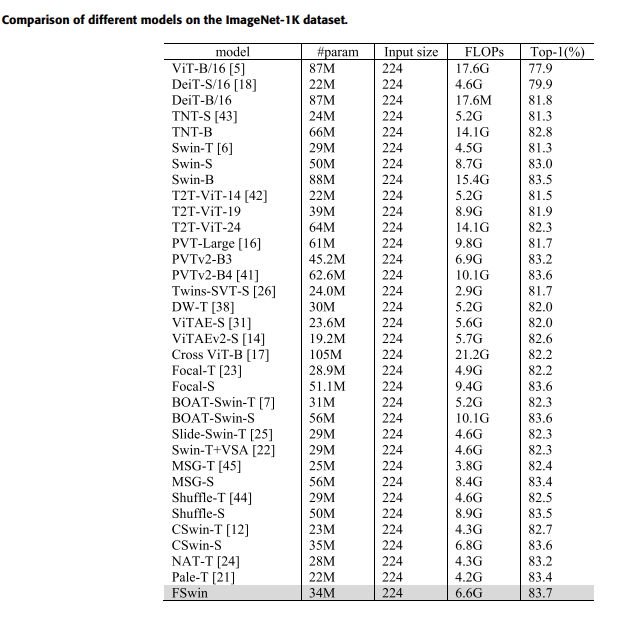
SW-MSA를 보완한 CBAM기반 FS-MSA를 구축한 FSwin transformer는 83.7%의 분류 성능을 보였고 ImageNet-1k의 이미지 분류 작업에서 Swin transformer보다 2.4% 향상된 성능을 달성했다.
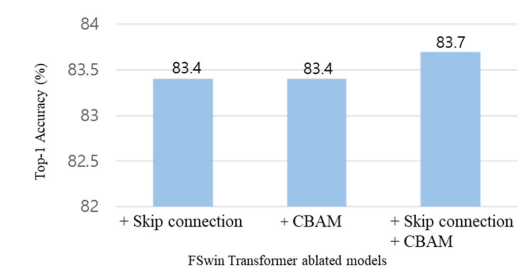
추가적인 실험으로 CBAM 및 Skip connection을 적용하면 정확도가 향상됨을 확인할 수 있었다. 특히 CBAM과 Skip connection을 함께 적용하면 모델의 표현력이 향상되어 분류 정확도가 가장 크게 나타났다.
결론
FSwin Transformer는 기존 윈도우 기반 attention 모델들의 한계를 극복하고, 이미지 내 전역적인 관계를 포착하는 능력을 개선함으로써 이미지 분류에서 뛰어난 성능을 발휘한다. CBAM과 FS-MSA의 결합을 통해, 멀리 떨어져 있어도 유사한 특징을 가진 토큰 간의 관계를 효과적으로 모델링하여, 모델의 표현력과 정확도를 크게 향상시켰다.
이 연구는 Vision Transformer의 발전에 기여하며, 더 효율적이고 효과적인 방법으로 전역적인 이미지 정보를 포착할 수 있는 가능성을 보여준다.
