요약
컴퓨터 비전 분야는 주로 CNN(Convolutional Neural Networks)이 지배해왔다. 그러나 NLP(Natural Language Processing)에서 성공을 거둔 Transformer 모델을 비전 분야에 적용하려는 시도가 계속되어 왔으며 이에 따라 다양한 연구가 진행되었다. Swin transformer는 Transformer 구조를 비전 작업에 맞게 효율적으로 변형한 모델이다. 이 논문에서는 Swin transformer가 이미지 분류, 객체 탐지, 의미 분할 등 다양한 비전 작업에서 뛰어난 성능을 보이는 것을 다루고 있다.
연구목적
Transformer 모델을 컴퓨터 비전 분야에서 효과적으로 사용할 수 있는 일반적인 backbone아키텍처로 확장하는 것이다. 기존의 Transformer는 주로 자연어처리(NLP) 작업에서 뛰어난 성능을 보였으나 비전 작업에 적합하지 않은 몇 가지 한계가 있었다고 한다. 특히 시각 데이터의 경우 다양한 크기의 객체를 다루고 높은 해상도를 처리해야 하는 문제들이 있었기 때문에 이를 해결하기 위해 계층적 특징 맵과 Shifted window self-attention기법을 적용한 Swin transformer를 제안하였다.
소개
컴퓨터 비전은 오랫동안 CNN을 기본 백본으로 사용해왔으나 최근 NLP에서 Transformer의 성공에 힘입어 이를 비전 작업에 적용하려는 시도가 이어져 왔다. NLP에서 쓰이는 Transformer는 시퀀스 모델링 및 트랜스덕션 작업을 위해 설계되었으며 긴 범위의 종속성을 모델링할 수 있는 self-attention 매커니즘 덕분에 큰 성과를 냈지만 이미지 처리에서는 픽셀 해상도가 높고 객체 크기가 다양하게 변하는 비전 작업에서의 계산 복잡도가 이미지 크기에 대해 제곱만큼 증가하여 효율성이 떨어졌다.
이를 해결하기 위해 제안된 Swin transformer는 두가지 특징을 가진다.
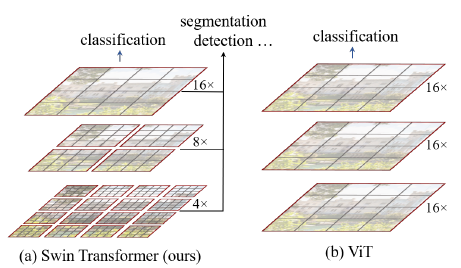
1. 계층적 특징 맵 구축: Swin transformer는 이미지 패치를 점진적으로 병합하며 계층적 특징 맵을 생성하여 다양한 스케일의 시각적 요소를 효과적으로 처리한다.
이러한 계층적 특징 맵을 통해 Swin Transformer 모델은 feature pyramid network (FPN) 또는 U-Net과 같은 조밀한 예측을 위한 고급 기술을 편리하게 활용할 수 있다.
이미지를 분할하는 겹치지 않는 window(빨간선 영역) 내에서 로컬로 self-attention 연산을 하여 선형 계산 복잡도를 달성한다. 각 window의 패치(회색선 영역) 수는 고정되어 있으므로 계산 복잡도는 이미지 크기에 비례한다. 이러한 장점으로 인해 Swin Transformer는 단일 해상도의 특징 맵을 생성하고 2차 계산 복잡도를 갖는 이전 Transformer 기반 아키텍처와 달리 다양한 비전 task를 위한 범용 backbone으로 적합하다.
2. Shifted Window self-attention: 계산 복잡도를 선형적으로 줄이기 위해 Swin transformer는 비중첩 윈도우 내에서 self-attention 연산을 하고 윈도우 경계를 넘는 정보를 교환하기 위해 윈도우를 이동시킨다.
self-attention연산은 트랜스포머의 인코더와 디코더 블록 모두에서 수행되며 쿼리, 키, 밸류 3개 요소 사이의 문맥적 관계성을 추출하는 과정이다.
먼저 쿼리, 키, 밸류를 만든다. 입력 벡터 수열에 쿼리, 키, 벨류를 만들어주는 행렬곱하여 각각의 행렬을 만들고 이는 태스크를 가장 잘 수행하는 방향으로 학습이 업데이트된다고 한다.
다음으로 쿼리의 셀프 어텐션 출력값 계산은 쿼리와 키를 행렬곱한 뒤 해당 행렬의 모든 요소값을 키 차원수의 제곱근 값으로 나눠주고 이 행렬을 행 단위로 소프트맥스를 취해 스코어 행렬을 만들어준다.
그 다음 스코어 행렬에 V를 행렬곱해줘서 셀프 어텐션 계산을 마친다.
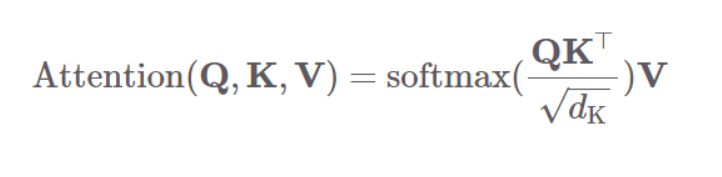
Swin Transformer의 핵심 설계 요소는 아래 그림과 같이 연속적인 self-attention Layer 사이의 window 파티션의 이동이다. Shifted window는 이전 Layer의 window를 연결하여 모델링 능력을 크게 향상시키는 연결을 제공한다. 이 전략은 또한 실제 지연 시간과 관련하여 효율적이다. Window 내의 모든 쿼리 패치는 하드웨어에서 메모리 액세스를 용이하게 하는 동일한 키 세트를 공유한다.
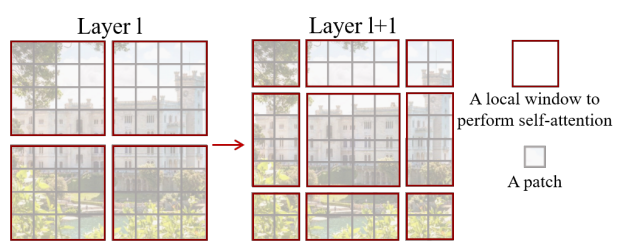
이전의 슬라이딩 window 기반 self-attention 접근 방식은 다른 쿼리 픽셀에 대한 다른 키 세트로 인해 일반 하드웨어에서 낮은 지연 시간으로 어려움을 겪고 있다. 제안된 shifted window 방식이 sliding window 방식보다 지연 시간이 훨씬 짧지만 모델링 능력은 비슷하다. 또한 shfted window 접근 방식은 모든 MLP 아키텍처에도 유익하다.
방법
1. Swin transformer 구조
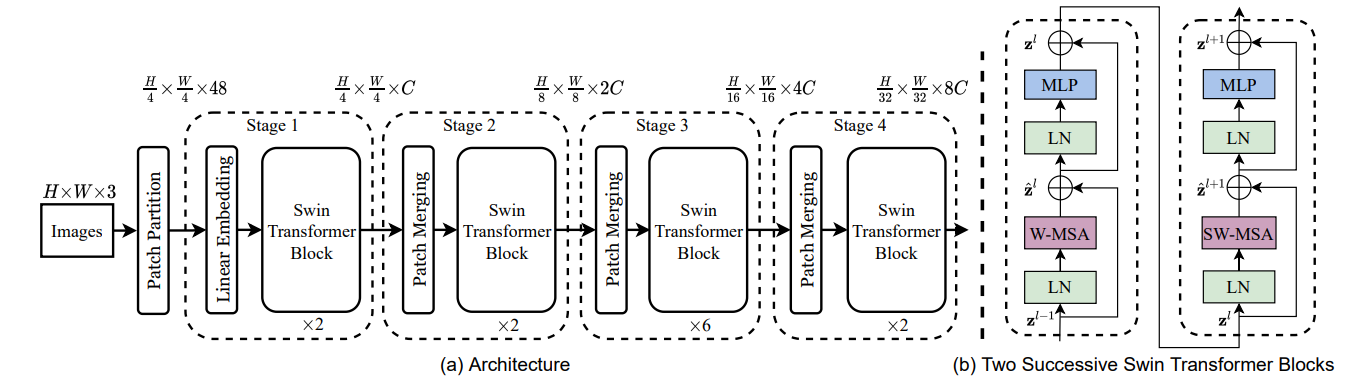
위 그림은 Swin Transformer의 모델 구조와 transformer block을 나타낸다. ViT와 같은 patch partition에 의해 입력 RGB 이미지를 겹치지 않는 패치로 분할한다.
patch partition에서는 가장 작은 grid 단위로 image를 partition 한다. 이 패치들은 토큰으로 간주된다. 본 연구에서는 4x4 크기의 patch를 사용하여 각 패치의 feature 차원은 4x4x3=48 이라고 한다.
선형 임베딩 layer에서는 feature를 임의의 크기의 차원 C로 정사영 시킨다. 이러한 패치 토큰에는 수정된 self-attention 연산이 포함된 여러 Transformer 블록이 이러한 패치 토큰에 적용된다. 이는 선형 임베딩과 함께 1단계라고 한다.
계층적인 구조를 위해 네트워크의 계층이 깊어질수록 patch merging layer에 의해 토큰의 수가 감소한다.
첫번째 patch merging layer는 2개x2개의 neighboring patch로 구성된 각 그룹의 특징을 concat하여 4C-dimentional feature에 선형layer를 적용한다.
feature 변환은 patch merging과 함께 2단계라고 하며 feature변환 이후 Swin transformer block이 적용된다.
Swin Transformer block에서는 두 개의 연속된 Swin Transformer block이 적용되며, 각 patch에 대한 attention을 연산한다.
첫 번째 transformer block에서는 window based self-attention 이 계산되고, 두번째 block에서 shifted window based self-attention이 적용된다.
이 process는 3단계와 4단계에서도 반복되는 구조이다.
2. Shifted Window based Self-Attention
표준 Transformer 아키텍처와 image classification을 위한 버전은 토큰과 다른 모든 토큰 간의 관계가 계산되는 글로벌 self-attention을 수행한다. 글로벌 계산은 토큰 수와 관련하여 2차 복잡도를 초래하여 조밀한 예측이나 고해상도 이미지를 나타내기 위해 막대한 토큰 세트가 필요한 많은 비전 문제에 적합하지 않다.
1. Self-attention in non-overlapped window
효율적인 모델링을 위해 전체영역이 아닌 local window내에서 self-attention을 계산하였다.
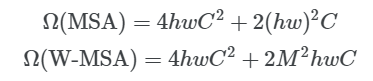
기존의 self-attention과 window based self-attention의 계산식이며 window내에는 MxM개의 패치가 존재하는데 MSA는 패치 수 인 hw에 대해 2차이고 W-MSA는 M이 고정된 경우 hw에 대해 선형이다.
2. Shifted window partitioning in successive blocks
window based self-attention은 window간의 연결이 부족하여 모델링 능력이 제한된다고 한다. 따라서 겹치지 않는 효율적인 계산을 유지하면서 window사이의 연결을 위해 연속되는 Swin transformer블록에서 두 개의 파티션 구성을 번갈아 가며 전환하는 Shifted window partitioning 방식을 제안했다.
Shifted window partitioning 접근법은 이전 레이어에서 인접한 겹치지 않는 window 사이의 연결을 도입하고 image classification, object detection, semantic segmentation에 효과적이라고 한다.
3. Efficient batch computation for shifted configuration
shifted window partitioning의 문제는 더 많은 window를 만들며 일부 창은 MxM보다 작아야 하기 때문에 효율적인 계산을 위해 본 논문에서는 cyclic-shift를 적용하였다고 한다.
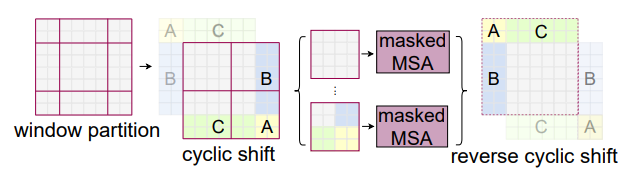
위의 그림과 같이 왼쪽 위 방향으로 cyclic-shifting하여 보다 효율적인 배치 계산 방식을 제안하여 배치된 window의 수가 일반 window partition과 동일하게 유지되어 효율적이라고 한다.
4. Relative position bias
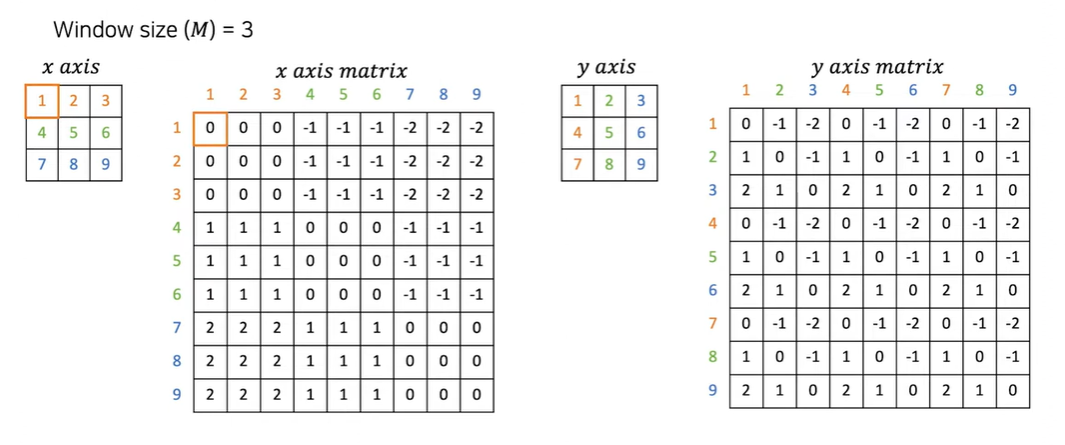
Swin Transformer에서는 패치들 간의 상대적인 위치 정보를 수집하여 저장한다. 이 정보를 활용하면 패치 간 거리에 따라 가중치를 부여하여 자연어 처리에서 사용되는 어텐션 메커니즘과 유사하게,
이미지 내에서 더 먼 패치들과의 상호작용을 조절할 수 있다.

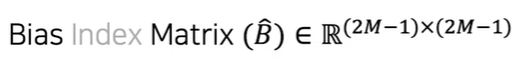
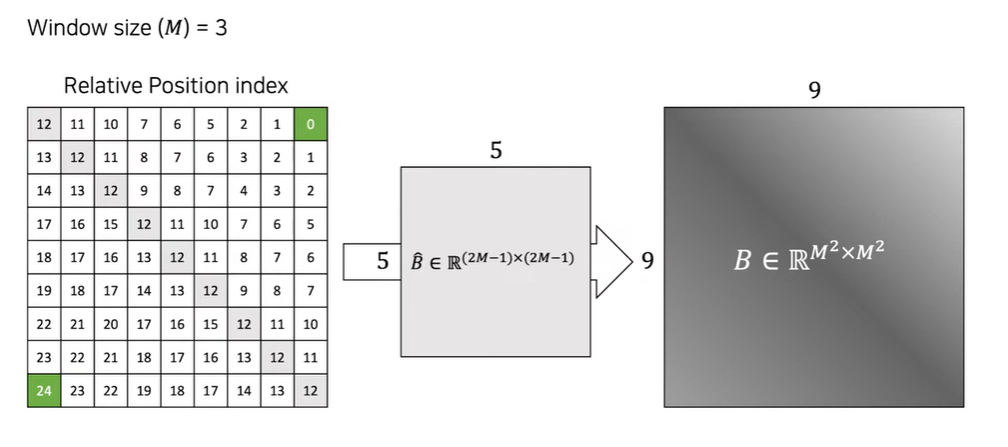
두 축마다 relative Position의 범위는 [-M + 1, M - 1]이다.
윈도우 크기가 3인 matrix의 범위는 [-2 , 2]가 된다.
실험결과
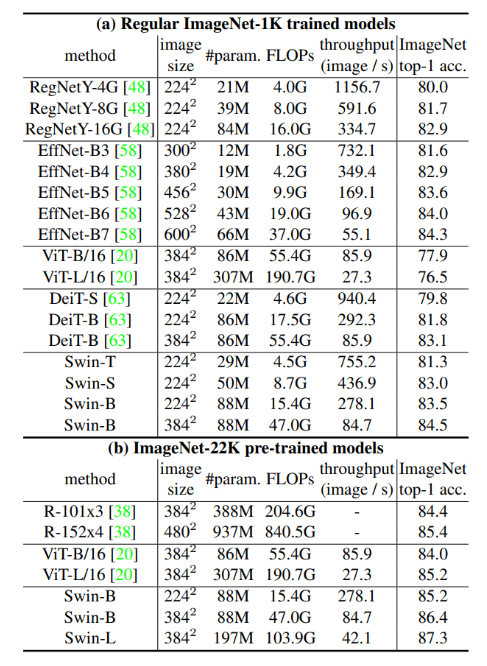
- Image Classification
- 데이터셋: ImageNet-1k
- 모델 구성: Swin-T, Swin-S, Swin-B, Swin-L 등의 다양한 크기의 모델을 사용하여 실험
- 훈련 방법: AdamW 옵티마이저, 300 에포크 동안 학습, cosin decay 학습률 스케줄러 사용. 데이터 증강과 정규화 기법도 적용
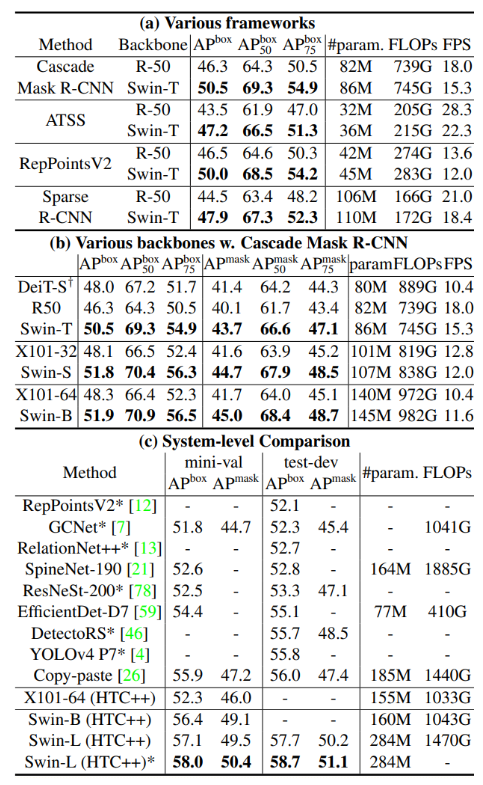
- Object detection
- 데이터셋: COCO 2017
- 모델 구성: Cascade Mask R-CNN, ATSS, RepPoints V2, Sparse R-CNN 등 다양한 객체 탐지 프레임워크와 Swin Transformer를 결합해 성능을 측정.
- 평가 방법: AP (Average Precision) 기준으로 성능 비교.
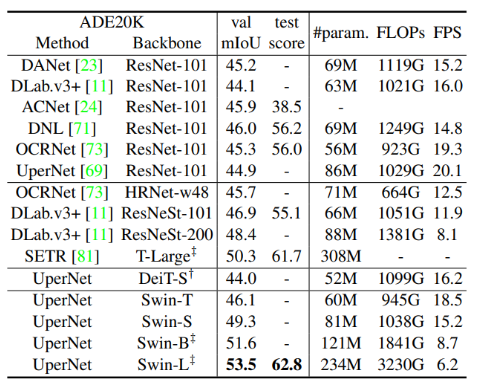
- Sementic Segmentation
- 데이터셋: ADE20k
- 모델 구성: UperNet을 기반으로 Swin Transformer와 결합하여 실험.
- 평가 방법: mIoU (mean Intersection over Union) 기준으로 성능 비교.
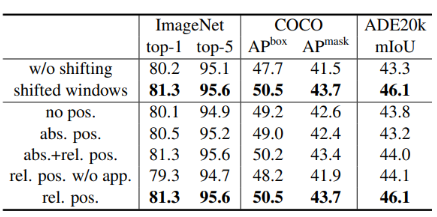
- Ablation Study
shifted window 접근법과 다양한 위치 임베딩 방법에 대한 ablation study 결과
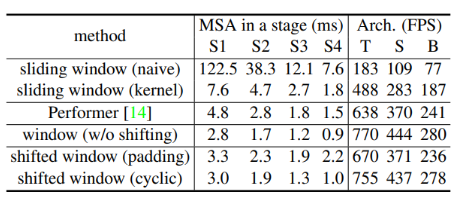
다양한 self-attention 계산 방법에 대한 실제 속도 비교
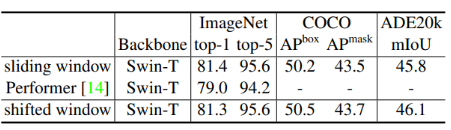
다양한 self-attention 계산 방법을 사용한 Swin transformer의 정확도 비교
결론
Swin Transformer는 기존 ViT의 한계점을 보완한 연구로써 classification문제 외에도 detection이나 segmentation과 같은 복잡한 CV Task에도 Transformer를 성공적으로 적용할 수 있는 가능성을 보여주었다. 특히 Hierarchical Feature map과 Shifted Window 기법을 통해 classification, object detection, semantic segmentation과 같은 CV Task에서 기존 모델을 뛰어넘은 것은 물론이며 ResNet과 같은 CNN기반의 모델들보다 우수한 성능을 보여주어 SOTA 백본을 차지했다.
