Seaborn라이브러리 소개
Staticstical Data Visualization(통계를 기반으로 한 데이터 시각화)
PDF(Probability Density Function) : 확률밀도함수
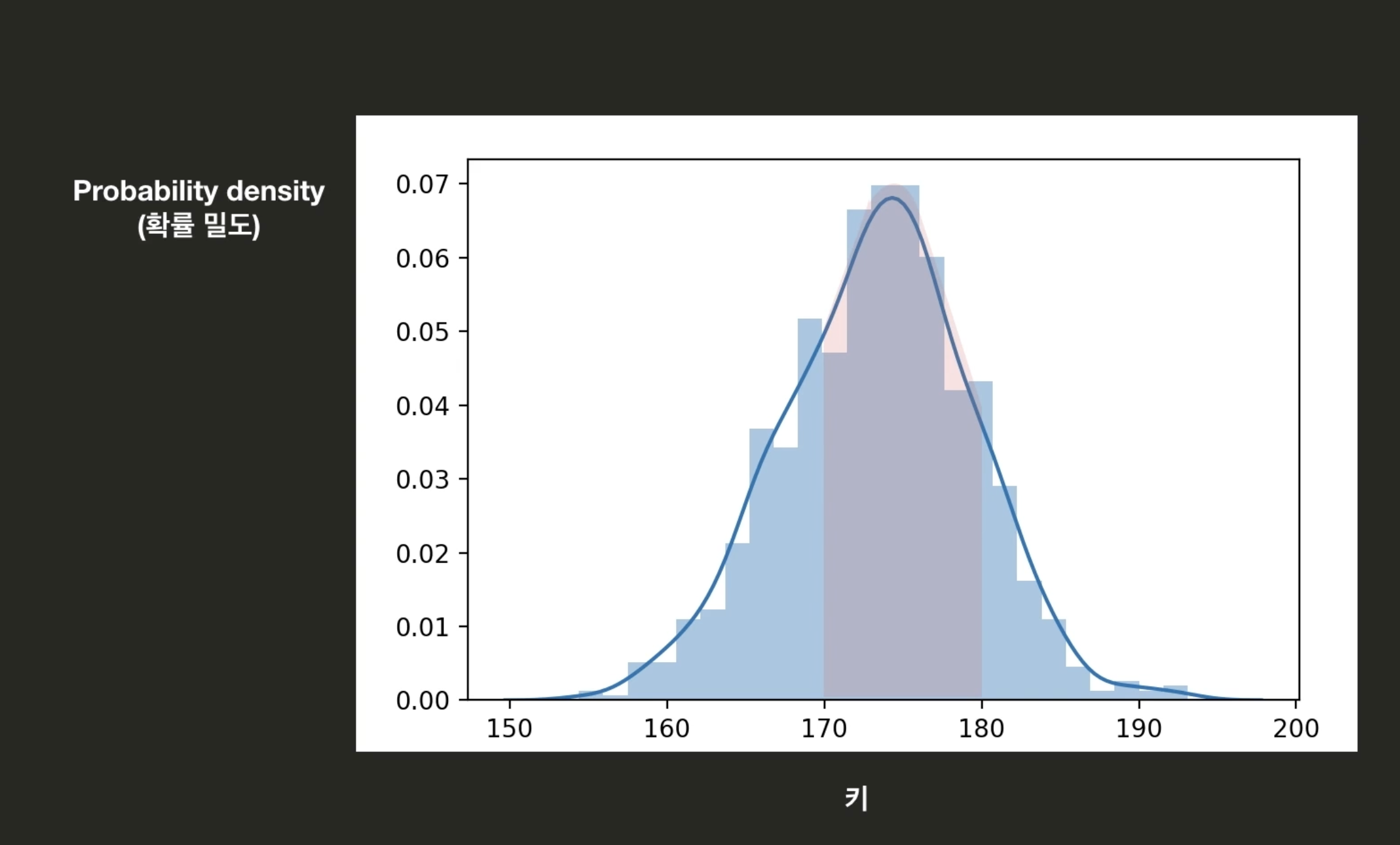
- 확률 밀도 함수는 데이터셋의 분포를 나타낸다.
- 특정 구간의 확률은 그래프 아래 그 구간의 면적과 동일하다.
- 그래프 아래의 모든 면적을 더하면 1이 된다.
- 173.5일 확률은 0이다.( 왜냐 173.500100101 처럼 나옴, 선은 넓이가 없음)
- PDF에서 특정 값이 일어날 확률은 0%이다. 특정 범위에 대해서만 0이 넘는 확률을 가질 수 있다.
KDE plot(Kernel Density Estimation)
우리가 가진 데이터 추측을 해, 부드러운 곡선이 나옴
Seaborn==0.9.0 설치
키순으로 정렬 (pandas Series에 있는 sort_index 메소드 쓰면 인덱스 순으로 정렬)
body_df['Height'].value_counts().sort_index().plot()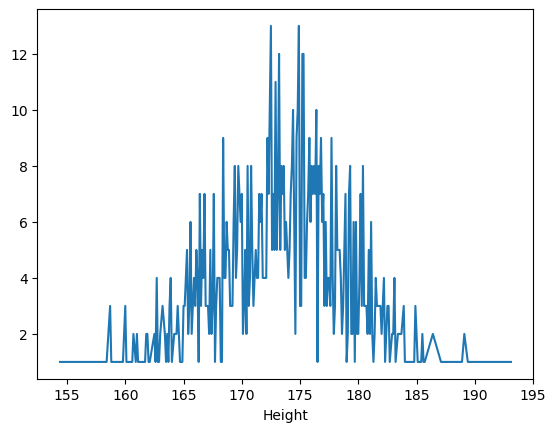
sns.kdeplot(body_df['Height']
seaborn 라이브러리에 kdeplot이라는 함수에 파라미터로 키 데이터 넘겨줌
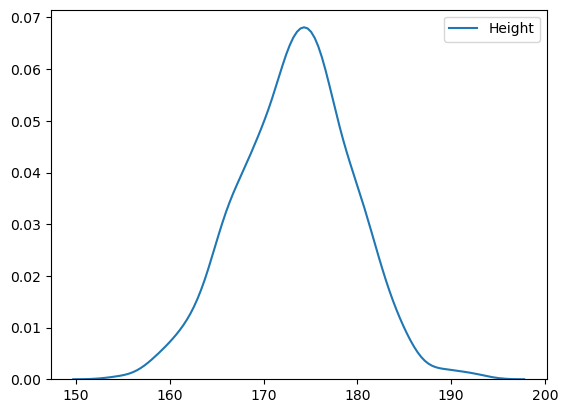
당연히 실제 분포와 다름 (추측으로 한거임)
bw로 추측력 설정가능
sns.kdeplot(body_df['Height'],bw=0.05)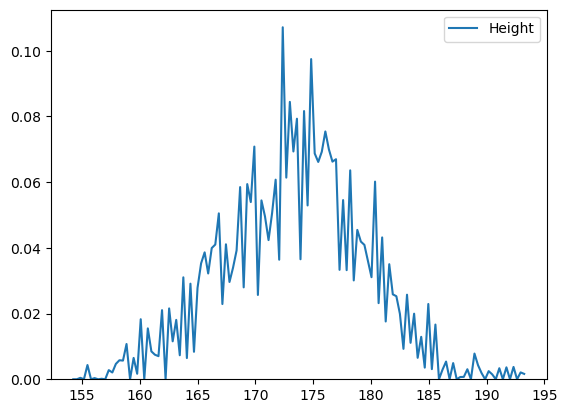
sns.kdeplot(body_df['Height'],bw=0.5)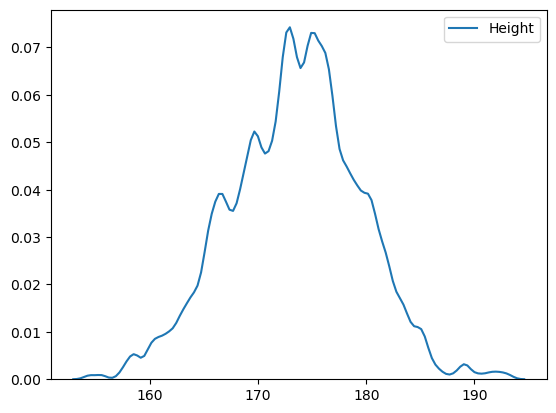
Kde 활용
body_df.plot(kind='hist', y='Height',bins=15)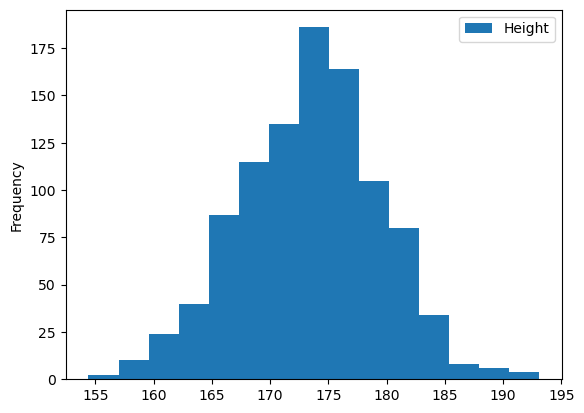
seaborn을 사용하면 히스토그램 위에 kde 얹을 수 있음.
sns.distplot(body_df['Height'], bins=15)
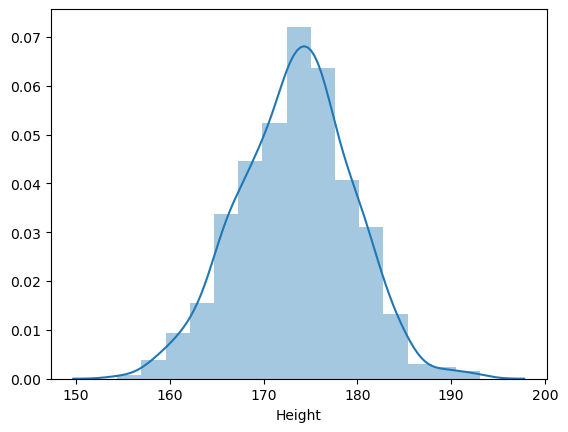
박스 플롯을 그려보자
body_df.plot(kind='box', y='Height')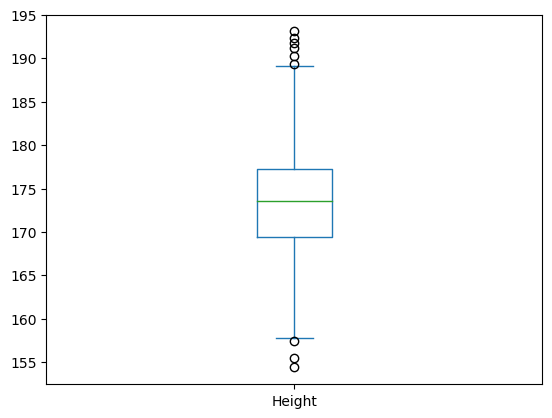
sns.violinplot(y=body_df['Height'])
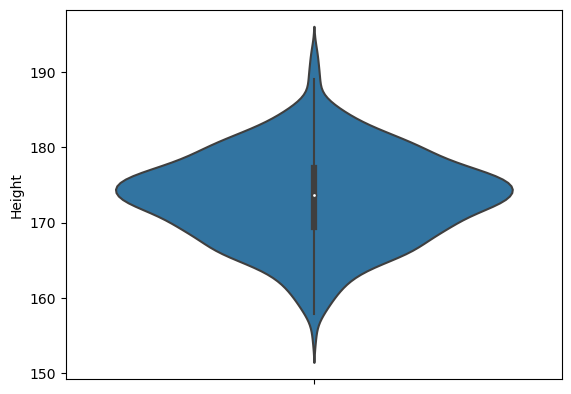
90도 돌려서 보면, 위에서 본 kde 분포이다. 바이올린 처럼 생겨서 violin plot이라 부른다.
키와 몸무게의 상관 관계를 알아보자(산점도가 적합함)
body_df.plot(kind='scatter', x='Height', y='Weight')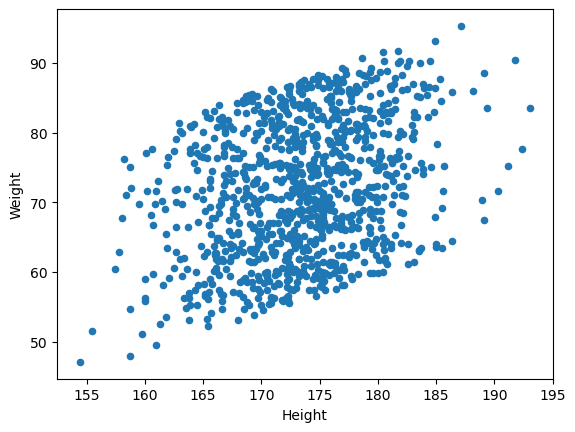
sns.kdeplot(body_df['Height'], body_df['Weight'])
최신 seaborn 라이브러리에서는 다음과 같이 쓰는 것은 권장함.
sns.kdeplot(data=body_df, x='Height', y='Weight') 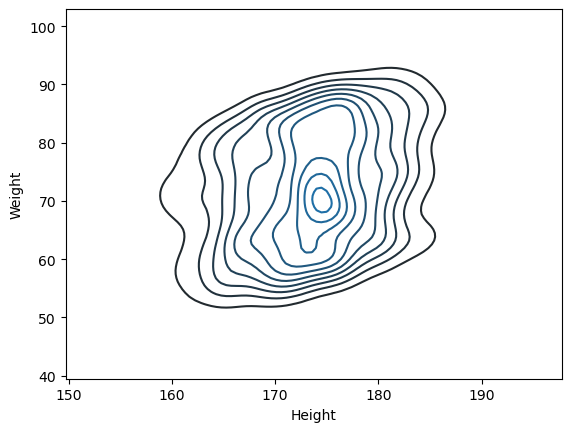
등고선( 어떤 것의 높낮이를 표현함)
x축은 키 y축은 몸무게 3차원으로 만듬. 선이 가파르게 올라오다 평평해지고를 반복
LM Plot
sns.lmplot(data=body_df,x='Height', y='Weight')
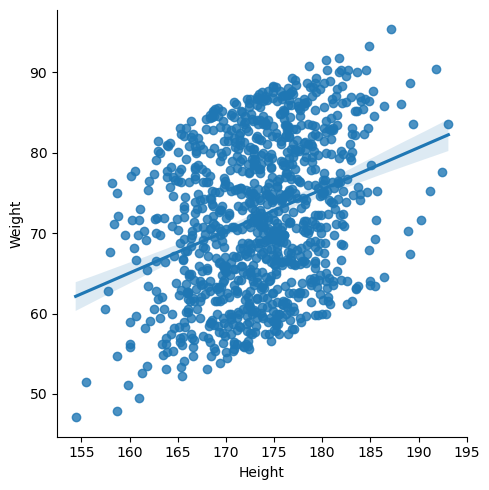
회귀선의 예측
카테고리별 시각화
카테고리별 시각화 하고 싶으면 catplot 사용(categorical plot)
sns.catplot(data=laptops_df, x='os', y='price', kind='box')
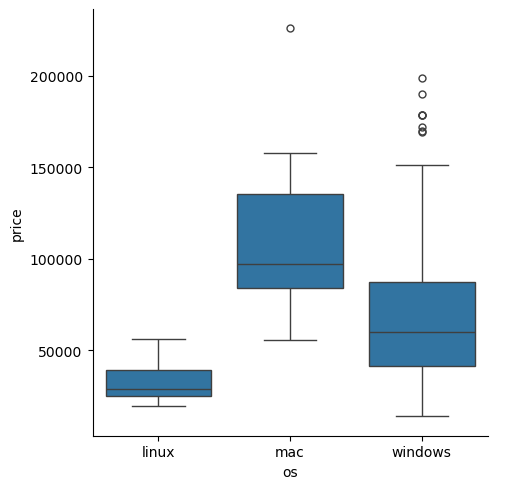
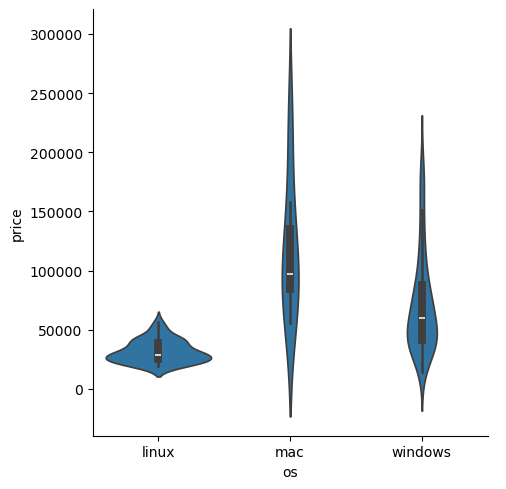
Kind를 violin으로 바꾸면
sns.catplot(data=laptops_df, x='os', y='price', kind='violin')
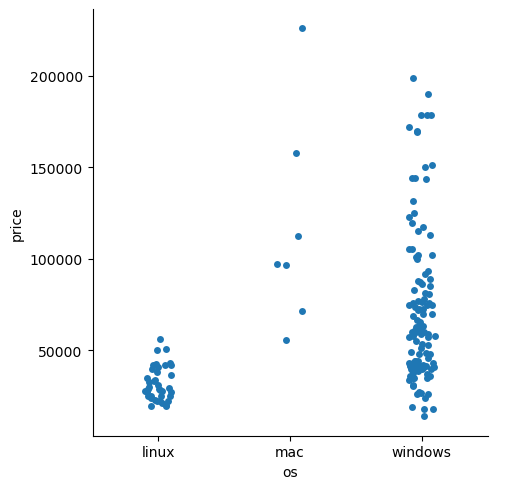
kind를 strip으로 바꾸면 data를 하나하나씩 다 볼 수 있음.
sns.catplot(data=laptops_df, x='os', y='price', kind='strip')
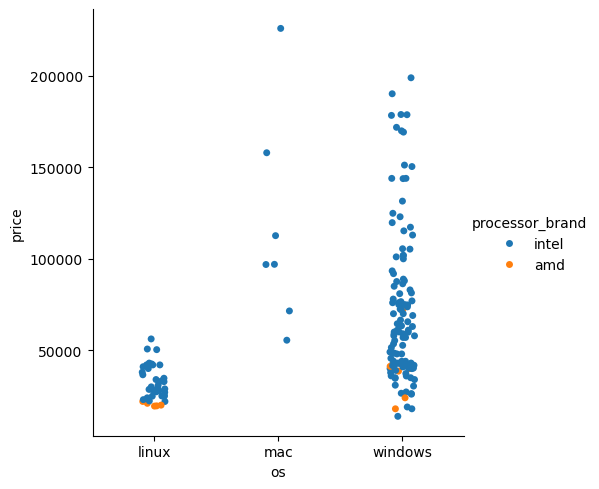
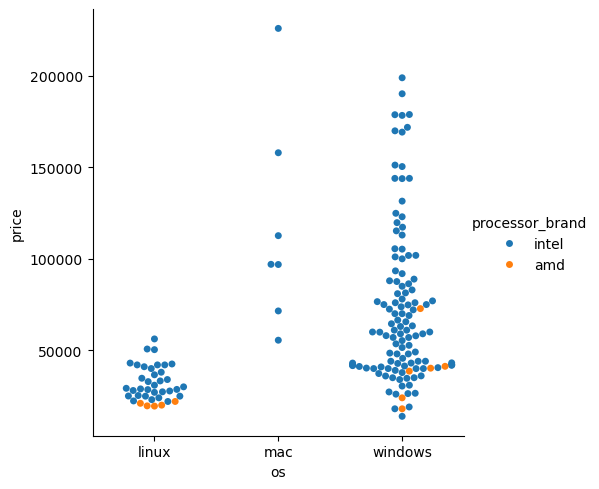
데이터들 중에 어떤 것이 인텔, amd 쓰는지 알고 싶음

sns.catplot(data=laptops_df, x='os', y='price', kind='strip', hue='processor_brand')
여기서 hue는 색을 의미함
점들이 많이 몰려있는 부분 해결하기 위해서는 swarm 플롯 쓰면 해결됨.
sns.catplot(data=laptops_df, x='os', y='price', kind='swarm', hue='processor_brand')

미래개발자