
Image Classification
- Problem
- Semantic Gap(의미적 차이)
grid(격자)를 통해 인식 - challenge
- Viewpoint variation (시점의 다양성)
- illumination (조명 변화)
- Deformation (다양한 포즈)
- Occlusion (객체의 일부만)
Data-Driven Approach
- 이미지 데이터와 라벨 모으기
- 머신러닝을 이용한 분류기 학습
- 새로운 이미지를 학습된 분류기를 통해 예측
- Nearest Neighbor
def train모든 데이터와 라벨들을 기억def predict예측하는 이미지와 가장 비슷한 이미지의 라벨 출력- image 비교 방법
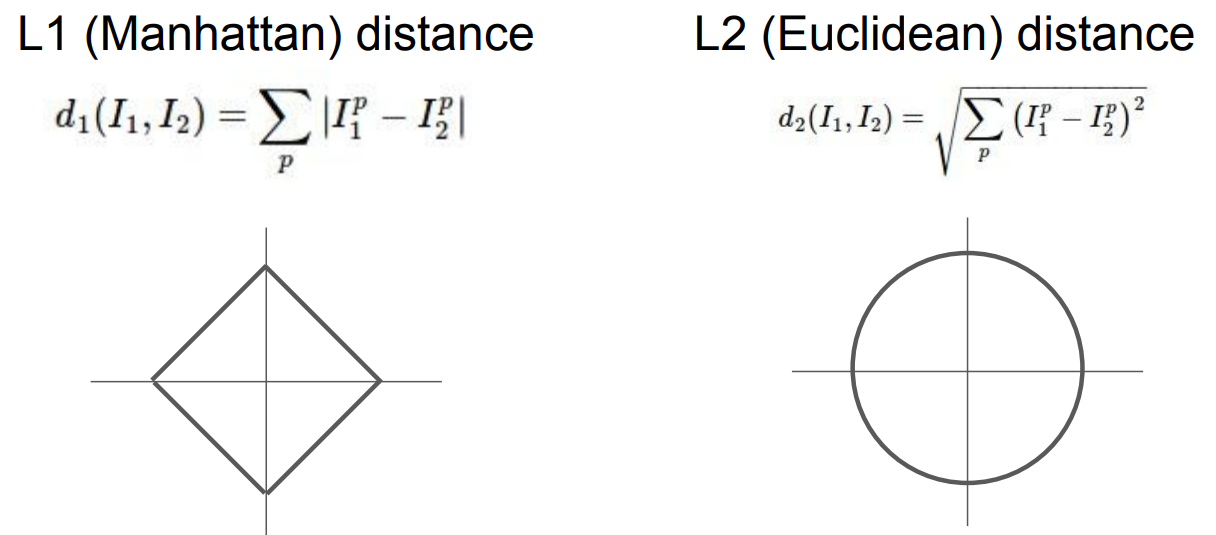
- L1 distance(Manhattan distance)
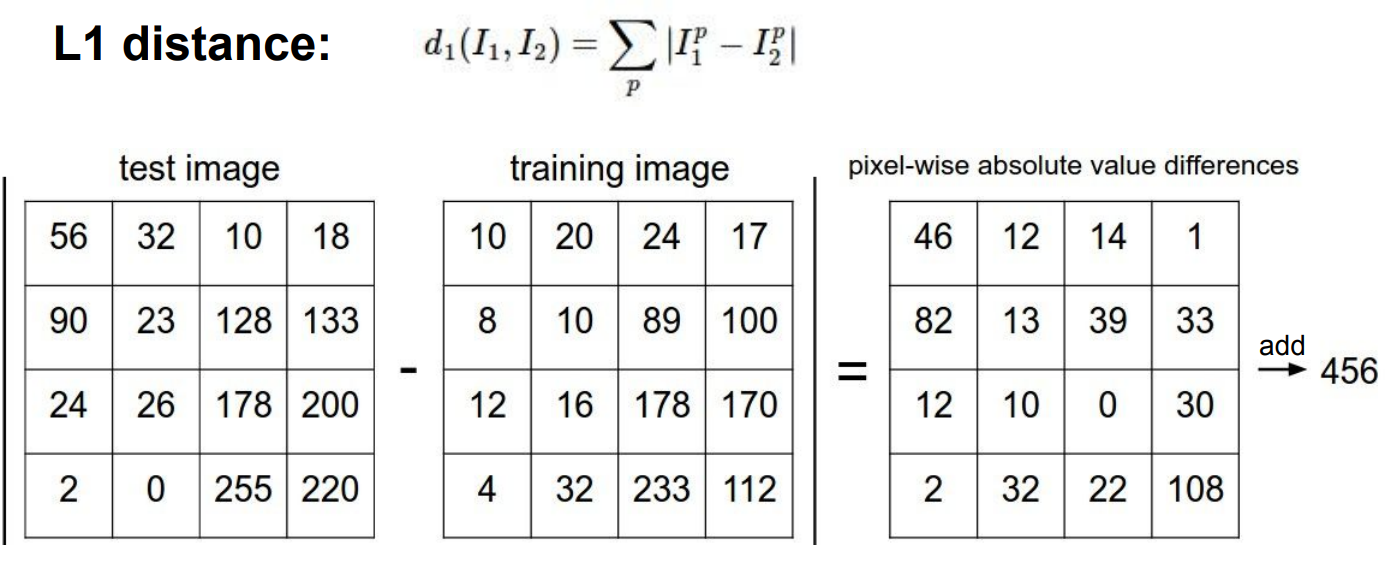
- 시간 = Train O(1), predict O(N)
=> Train 속도보다 Prediction 속도가 느림
- K-Nearest Neighbors
K는 Boundary에 들어있는 값의 개수- Distance Metric
Setting Hyperparameters
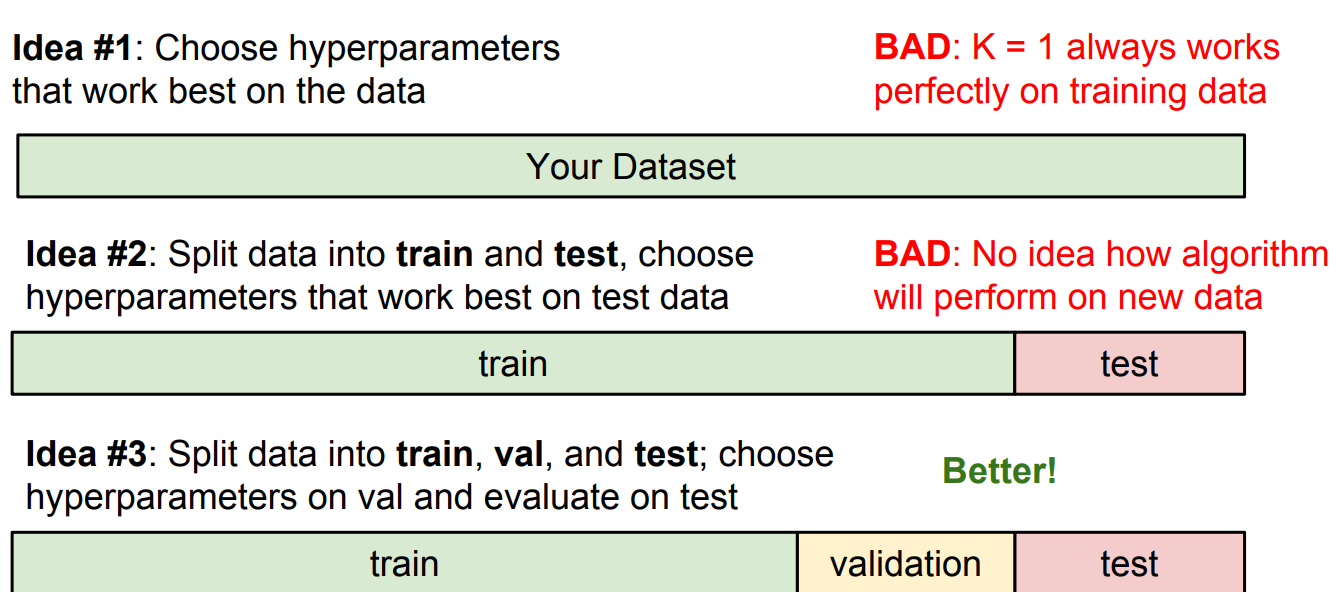
- idea #1 - k=1일때 예측값 100%가 나오기 때문에 다른 test셋을 예측하면 정확도가 낮아질 수 있음
- idea #2 - test데이터를 통해 얻은 최적의 하이퍼 파라미터의 성능을 측정 할 수가 없음
- idea #3 - 데이터를 train/test/validation으로 나눔
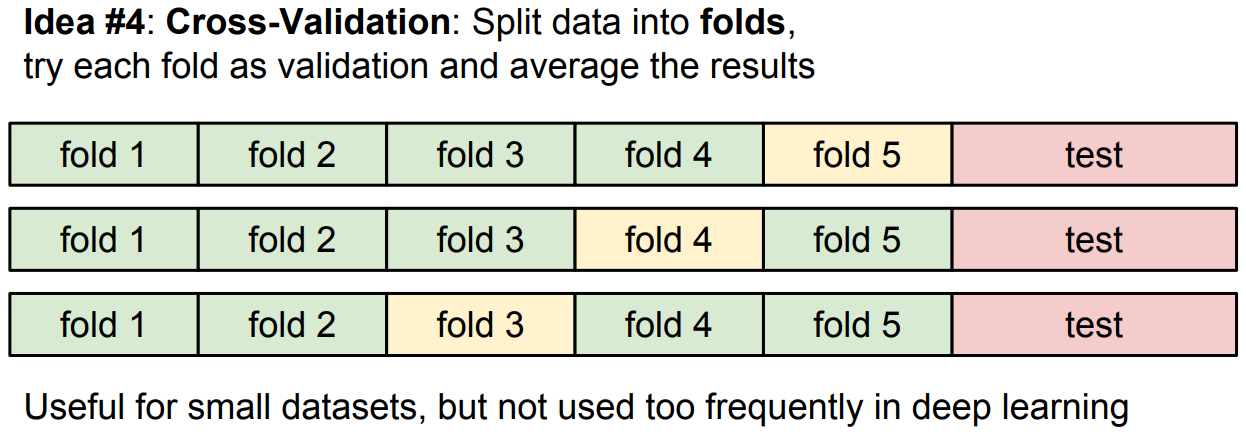
- idea #4 - cross-validation는 test셋이 적을 때 활용
K-Nearest Neighbor는 이미지에 사용하지 않음
- test시간이 느림
- 픽셀에 대한 거리가 주는 정보가 정확하지 않음
- 차원저주
- 차원은 지수 단위로 증가하여 공간을 밀도 높게 커버하기가 매우 힘듦
Linear Classification
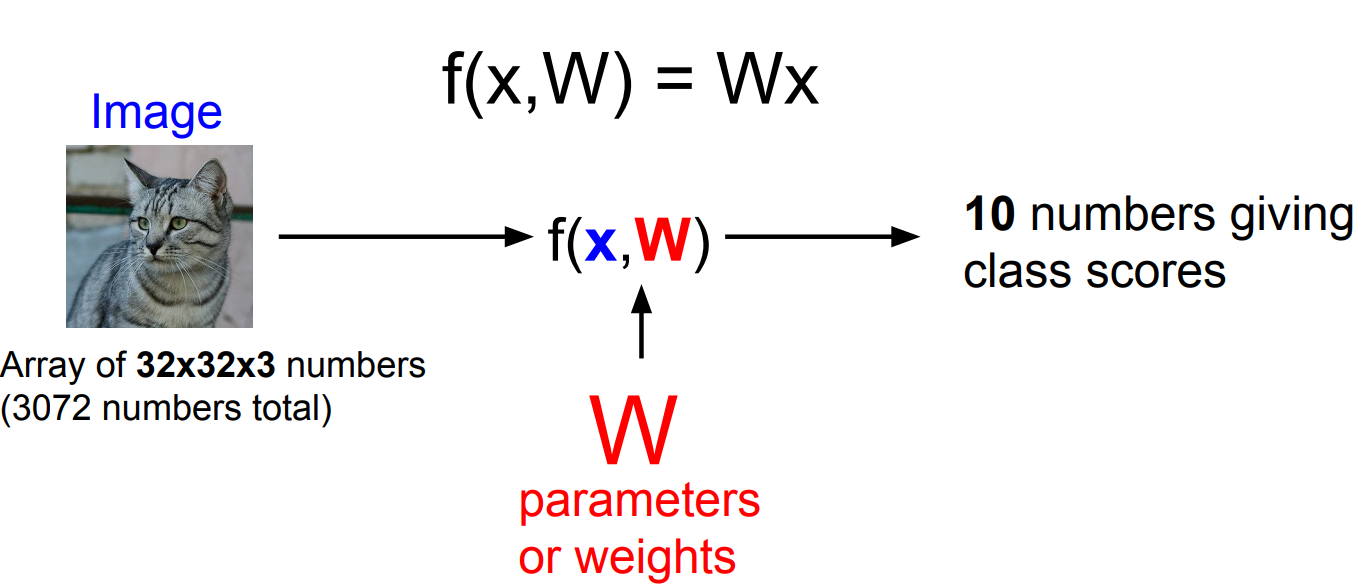
x= 입력 데이터, W= 파라미터 or 가중치
x와 W를 통해 10개 out = 각각의 카테고리에 해당하는지를 나타내는 점수
train을 통해 얻은 W를 갖고있다가 test이미지가 들어오면
train데이터는 필요없고, W만 이용하여 결과를 도출함
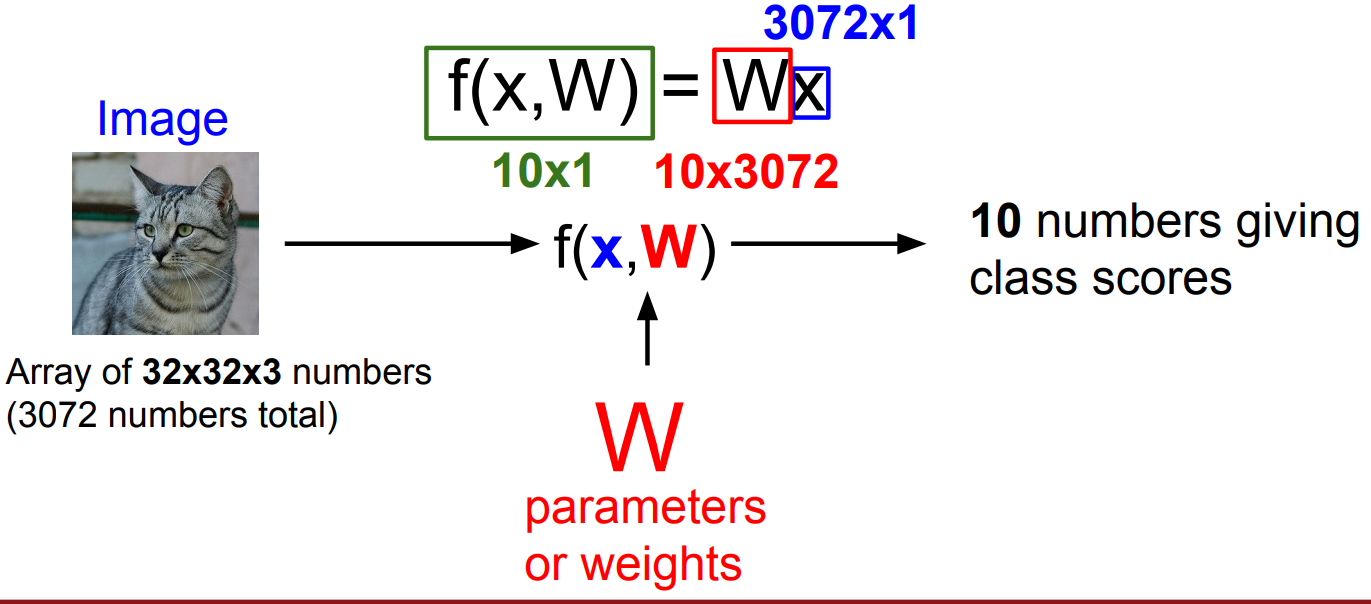
x = 32x32x3(이미지 크기) = 3072 x 1 벡터
W = 32x32x3x10(카테고리 점수)
x와W를 곱하면 10x1개 output
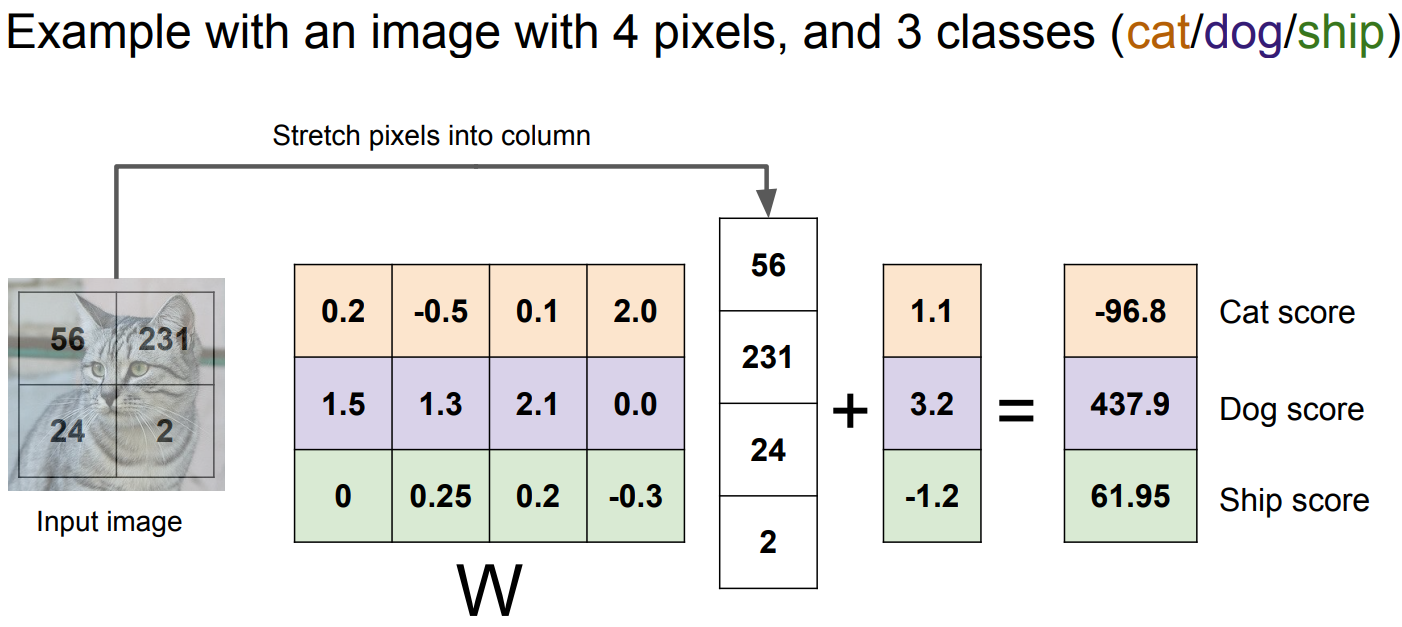
- ex)
Linear Classification은 다른 관점에서 이미지를 고차원 공간에서의 한 점으로 만드는 것
Linear Classification의 문제점
- 하나의 클래스에 대해 하나의 템플릿만 배우기 때문에 변화에 매우 취약함
- Linear Classification은 결정 바운더리를 형성하지만,
모든 데이터에 완벽한 결정 바운더리를 그릴 수 없음

ComputerVision 누구냐 넌