tonbistudio/turboquant-pytorch · Python
"From-scratch PyTorch implementation of Google's TurboQuant (ICLR 2026) for LLM KV cache compression"
왜 이걸 보게 됐나
지난달 초 Google Research 블로그에 TurboQuant 발표가 올라왔다. 요지는 이렇다. LLM 추론에서 제일 큰 메모리 병목은 긴 컨텍스트의 KV 캐시인데, 여기에 극단적 양자화(3-bit)를 먹이면 약 6배까지 메모리를 줄일 수 있고 품질도 거의 손실 없다. ICLR 2026 accept, Google + KAIST + NYU 조인트. 제목에 "Near-optimal Distortion Rate"가 붙어 있어 이론 쪽 주장도 강했다.
최근 AI 인프라 쪽에서 KV 캐시 메모리 절감이 꽤 핫한 주제다. 특히 TurboQuant의 "3-bit까지 가면서 품질은 거의 유지"라는 라인은 눈에 띄었다. 모델 가중치 자체를 건드리지 않고 inference 메모리를 수 배 줄일 수 있다면 단일 GPU에서 돌릴 수 있는 컨텍스트 길이가 그만큼 달라진다는 뜻이라, 내 작업 환경(3090 Ti 24GB 한 장)에도 직접 영향이 있는 얘기였다. 한 번 해봐야겠다고 생각했다.
TurboQuant 레포는 하나가 아니다 — 왜 tonbistudio를 골랐나
"TurboQuant"라고 검색하면 별 표시가 많은 레포가 여러 개 떠서 처음엔 어떤 걸 돌려야 할지 혼란스럽다. GitHub에서 찾아본 star 순위를 정리하면:
| 순위 | 레포 | Stars | 성격 |
|---|---|---|---|
| 1 | TheTom/turboquant_plus | 6,408 | llama.cpp 확장, GGUF, Metal/CUDA/HIP 네이티브 커널 |
| 2 | 0xSero/turboquant | 1,136 | Triton 커널 + vLLM 통합 |
| 3 | tonbistudio/turboquant-pytorch | 951 | 순수 PyTorch 참조 구현 |
| 4~ | OnlyTerp / back2matching / RecursiveIntell(Rust) / scos-lab 등 | 4~56 | 각자 다른 포크 |
상위 3개가 다 같은 "TurboQuant"이지만 포지션이 완전히 다르다.
- TheTom/turboquant_plus (1위, 6.4k stars) — llama.cpp에
--cache-type-k turbo3같은 cache type을 추가한 확장판. C/Metal/CUDA native kernel을 쓰고 GGUF 모델(Q8_0 / Q4_K_M)을 먹는다. Boundary V (첫·끝 2개 레이어 q8_0 보호)와 sparse V dequantization (softmax weight<1e-6 지점 dequant 스킵, +22.8% decode) 같은 실전 최적화가 붙어 있다. Qwen2.5 1.5~7B, Llama 3.1-70B, Mistral, phi-4, Command-R+, Qwen3.5 MoE 35B까지 검증. 배포 지향. - 0xSero/turboquant (2위, 1.1k stars) — Triton 커널로 compressed-domain attention을 구현하고 vLLM에 통합한 포크. 풀 벤치마크(
proof.py)가 4× RTX 3090을 요구해서 단일 GPU 환경과 안 맞는다. - tonbistudio/turboquant-pytorch (3위, 951 stars) — 순수 PyTorch 참조 구현. 작고 읽기 쉽고 HF safetensors + bitsandbytes 4-bit 로딩을 쓴다. RTX 3060 12GB에서도 검증. 연구·알고리즘 검증 지향.
내 환경은 단일 RTX 3090 Ti 24GB다. 조건에 맞추면:
- TheTom은 가장 hot한 선택지이고 RTX 3090급에서 돈다고 커뮤니티에서 검증됐지만, llama.cpp custom 빌드 + GGUF 변환 + 별도 실행 API가 필요해서 범위가 큰 다른 실험이 된다.
- 0xSero는 4× GPU 요건이라 제외.
- tonbistudio는 단일 GPU + 파이썬 환경에서 가장 단순·확실하게 돌릴 수 있는 구현이라 이걸 골랐다.
이 선택의 성격을 미리 밝혀두면: 이 글은 "TurboQuant PyTorch 참조 구현(tonbistudio) 재현 기록"이지 TurboQuant 전체 기술이나 실전 deploy까지의 평가는 아니다. 배포 지향 구현(TheTom, 0xSero)에서는 이 글의 숫자가 다르게 나올 가능성이 높고, 그건 별도 실험 주제다. 다음 GitHub 탐방 글에서 TheTom으로 같은 실험을 재현해볼 계획.
이 실험이 레포 원본과 어떻게 달라졌는지
tonbistudio의 표준 실행은 한 줄이다.
python -m turboquant.generation_test # 고정: Qwen2.5-3B-Instruct, 내장 6 config × 3 ctx여기서 두 가지를 바꿨다.
- 모델 확장: Qwen2.5-3B 하드코딩을 CLI 인자(
--model-path,--model-label,--prompt-format)로 바꾸고, 내 장비에 이미 있던 Qwen2.5-7B / Qwen2.5-14B / EXAONE-3.5-7.8B 로 확장했다.MODEL_NAME = "Qwen/Qwen2.5-3B-Instruct"한 줄을 바꾸기만 해선 프롬프트 포맷·trust_remote_code등이 엉켜서, 얇은 argparse 래퍼를 덧붙이는 게 깔끔했다. - 계측 추가: 원본은 pass/fail 바이너리만 기록한다. 거기에 per-test
elapsed_sec/peak_mb(torch.cuda.max_memory_allocated())를 붙여 JSON으로 떨어뜨리게 했다. "몇 배 빨라졌다", "몇 배 메모리 줄였다" 류의 주장을 숫자로 관찰하려면 이게 있어야 했다.
즉 이 글은 레포의 공식 테스트 재현이라기보다 레포를 baseline으로 "다른 모델 크기에서도 같은 패턴이 나오는지"를 보는 확장 실험에 가깝다. 원 README가 Qwen2.5-3B에 대해서만 보고한 pass/fail 표가 있으니, 이 글에서 나온 결과와 겹치는 부분은 교차 검증 정도로 읽으면 좋다.
참고로 tonbistudio의 V3는 원 논문의 QJL 단계를 제거한 수정판이다. README에 "We implemented the paper's algorithm, found that its key innovation (QJL) actually hurts in practice, and built an improved version (V3)" 라고 명시되어 있다. 즉 이 레포는 이미 논문에서 한 발짝 옮겨와 있고, 이 글 역시 그 수정판 기준의 재현이지 논문의 알고리즘 그대로의 재현이 아니다.
실험 설계
- 레포: tonbistudio/turboquant-pytorch (버전: 2026-04-21 시점 master)
- 알고리즘: 레포 저자들은 원 논문 V2(MSE+QJL)를 구현해 본 뒤 QJL의 분산이 softmax 이후 증폭되어 attention에 해롭다는 결론을 내리고 V3(MSE-only, asymmetric K/V, residual window)로 재설계한 상태였다. 즉 이 실험은 "논문 그대로"가 아니라 "논문 + 커뮤니티 수정판"의 재현이다.
- 모델: 내 노트북
LLM_Model_File/에 이미 있던 모델 4종을 시도 대상으로 잡았다.- Qwen2.5-7B-Instruct, Qwen2.5-14B-Instruct — 실제로 실험까지 완료
- EXAONE-3.5-7.8B-Instruct — 환경 이슈로 중도 실패 (아래)
- gemma-4-E2B — 멀티모달 모델이라 범위 밖
- 태스크: 레포에 내장된 needle-in-haystack. 반복 filler 문단 중간에
The secret project code name is AURORA-7749.를 꽂고, 생성 결과에AURORA-7749가 나오면 FOUND. - 조건: 컨텍스트 2K/4K/8K × config 6종 (FP16 baseline + V3 K4/V4·K4/V2·K3/V3 각각 rw=0, + K4/V4·K4/V2 rw=128). 모델은 bitsandbytes 4-bit NF4로 로딩.
- 측정: pass/fail + wall-clock 시간 +
torch.cuda.max_memory_allocated()피크 VRAM. - 환경: RTX 3090 Ti 24GB, CUDA 13.0, PyTorch 2.11.0, transformers 5.5.4, WSL2.
- 산출물: 원
generation_test.py에 CLI 파라미터와 시간/메모리 계측을 덧붙인generation_test_instrumented.py(약 250줄). 시간·피크 메모리·pass/fail을 JSON으로 떨어뜨림.
결과 — 품질

| Config | Qwen2.5-7B (2K/4K/8K) | Qwen2.5-14B (2K/4K/8K) |
|---|---|---|
| FP16 baseline | FOUND / FOUND / FOUND | FOUND / FOUND / FOUND |
| V3 K4/V4 rw=0 | MISS / MISS / MISS | FOUND / FOUND / FOUND |
| V3 K4/V2 rw=0 | MISS / MISS / MISS | FOUND / FOUND / FOUND |
| V3 K3/V3 rw=0 | MISS / MISS / MISS | FOUND / FOUND / FOUND |
| V3 K4/V4 rw=128 | MISS / MISS / MISS | FOUND / FOUND / FOUND |
| V3 K4/V2 rw=128 | MISS / MISS / MISS | FOUND / FOUND / FOUND |
Qwen2.5-7B 기준 18 테스트 중 FP16 3개만 통과, V3 압축 15개 전부 깨졌다. MISS 사례는 전형적으로 "1006)450505 0000 the.00..." 식으로 생성 자체가 망가진 출력이었다. 같은 스크립트·같은 설정을 Qwen2.5-14B에 돌리면 18개 전부 FOUND. 바이트 수준에선 가장 공격적인 K3/V3 rw=0 조합조차 14B에선 멀쩡했다.
레포 README는 Qwen2.5-3B에서 K4/V4 rw=128이 EXACT라고 보고했고, rw=0은 깨진다고 명시해 두었다. 내가 본 결과는 그것보다 한 단계 더 갈라진다. 같은 alg가 7B에선 rw=128에서도 깨지고 14B에선 rw=0에서도 안전하다. 모델 크기(또는 layer·head 구성)가 압축 오차 흡수 능력에 결정적으로 작용한다는 뜻으로 읽었다.
가장 직관적인 가설은 capacity redundancy다. 파라미터 수·레이어 수가 2배인 14B는 각 레이어가 가진 중복 표현이 더 넉넉해서 KV 양자화로 인한 오차를 흡수할 여유가 있는 쪽으로 해석할 수 있다. 작은 모델일수록 각 토큰·각 헤드의 정보 밀도가 상대적으로 높아, 약간의 quantization noise가 downstream attention 패턴을 쉽게 무너뜨리는 것 같다.
다만 이 설명만으로는 바이트 레벨에서 가장 공격적인 K3/V3 rw=0조차 14B에선 멀쩡한 이유까지 깔끔히 정리되진 않는다. capacity 의존성이 선형보다 더 가파르게 작용하는 걸 수도 있고, layer 수 자체(28 → 48)가 더 결정적인 변수일 수도 있다. 내 실험 두 모델만으론 단정이 어렵고, 3B·32B까지 포함된 스윕이 있어야 제대로 답이 나올 문제다. 그래서 이 섹션은 "한 번 해봤더니 두 모델 사이에 이렇게 갈렸다"는 단일 관찰 정도로 읽어주면 좋겠다.
결과 — 피크 VRAM
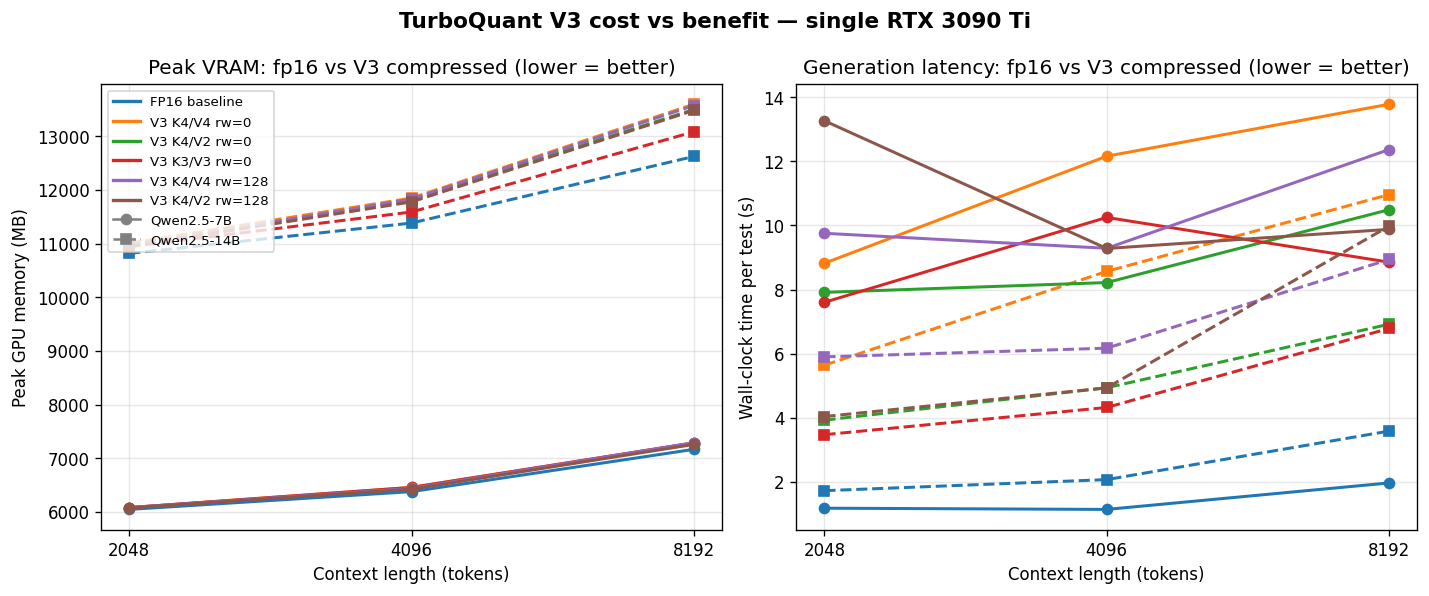
| FP16 baseline | V3 min | V3 max | |
|---|---|---|---|
| Qwen2.5-7B 8K | 7,166 MB | 7,258 MB | 7,289 MB |
| Qwen2.5-14B 8K | 12,624 MB | 13,084 MB | 13,597 MB |
이 표가 이번 실험에서 가장 들여다본 결과였다. V3 압축 config의 피크 VRAM이 FP16과 같거나 살짝 높게 나왔다. 14B의 8K에선 최대 약 +970MB (+7.7%)까지 올라갔다.
처음엔 측정 실수인가 했는데 코드를 보면 구조적인 실행 경로 차이다. V3Cache.update()가 매 스텝·매 레이어에서 다음을 한다.
- 저장해 둔 compressed chunk 전체를 꺼내
decompress_kv()호출 → fp16 풀 텐서로 materialize - 최근 residual window fp16 토큰을 덧붙임
torch.cat으로 합친 fp16 텐서를 attention 레이어에 반환
즉 이 구현은 "bit-packed 저장 + 매 스텝 decompress-then-attend" 구조다. 저장 공간은 분명 줄지만(이론적으로 K4/V2에서 5.12×) — 위의 compression_ratios.py에서 확인한 숫자 — attention 연산 시점엔 fp16 풀 텐서가 재구성되고 그 위에 압축기 중간 버퍼도 얹히니까 "저장소 절감"과 "inference 피크 VRAM 절감"이 같은 수치로 맞물리지 않았다.
원 논문이나 Google 포스트의 6× 주장은 compressed domain에서 attention이 직접 도는 경로를 상정한 쪽에 가깝다 (fused kernel이 압축된 K와 쿼리를 그대로 곱하는 식). 이 PyTorch 참조 구현은 알고리즘 자체의 검증과 양자화 오차 측정에 초점을 맞추고 그 경로는 잡지 않았을 뿐이다. 커뮤니티 포크 중 하나인 0xSero/turboquant는 Triton 커널로 그 쪽을 노리고 있어서, 그 구현 위에서 돌리면 피크 VRAM 그림이 달라질 가능성이 높다. 이 글은 그 영역까지 가진 않았다.
결과 — 속도
| FP16 2K | V3 min 2K | V3 max 2K | slowdown | |
|---|---|---|---|---|
| Qwen2.5-7B | 1.19s | 7.61s | 13.26s | 6.4× ~ 11.1× |
| Qwen2.5-14B | 1.73s | 3.48s | 5.90s | 2.0× ~ 3.4× |
32 토큰 생성 기준. 양쪽 다 V3이 느리고, 7B가 비율로 더 느리다. 레이어당 압축/해제 오버헤드가 어텐션 자체 연산과 같은 스케일로 들어가다 보니, 레이어가 적고 어텐션이 상대적으로 가벼운 7B 쪽에서 상대적 slowdown이 더 크게 나타났다.
이 숫자는 파이썬 전용 참조 구현의 비용이라는 맥락에서 봐야 한다. 레포 자체가 "algorithm validation"이 주 목적이고 배포용 최적화는 스코프 밖이라 fused kernel이 없다. Triton/CUDA 커널이 붙은 포크에선 이 숫자가 많이 줄어들 것이다. 그래서 이 표는 "TurboQuant이 느리다"가 아니라 "이 참조 구현 기준으로 inference 중 오버헤드가 어느 정도 규모인지"를 보여주는 자료로 읽으면 좋다.
곁가지에서 나온 관찰
원래 네 모델을 다 돌려보고 싶었지만 두 개는 실험 전 단계에서 멈췄다. 그 과정에서 "이 V3Cache가 어떤 조건에선 아예 슬롯인 안 된다"는 그림이 자연스럽게 그려져서, 같이 적는다.
(1) 멀티모달 모델엔 이 V3Cache가 바로 안 꽂힌다 — gemma-4-E2B
로컬에 gemma-4-E2B가 있어서 같이 돌릴 생각이었는데 config.json을 열어보면 model_type=gemma4에 architectures=["Gemma4ForConditionalGeneration"]. 즉 ...ForCausalLM이 아니라 텍스트 디코더 + 오디오 인코더 + 비전 인코더의 conditional generation 모델이다. 텍스트만 돌리려 해도 내부 cache 구조가 일반 디코더 LLM과 다르다.
여기서 문제가 두 겹이다.
- 레포의
V3Cache는transformers.DynamicCache를 단순 상속한다. 멀티모달 파이프라인이 기대하는 건 종종HybridCache(sliding window 레이어와 일반 레이어를 섞어 쓰는 경우)나 모델 전용 cache 구조다. 이 둘 사이에 슬롯인을 하려면V3Cache가 cache type을 감지해서 레이어별로 다르게 동작하도록 바꿔야 한다. - gemma-4 같은 모델은 slidding window attention이 every-other-layer로 섞여 있다. sliding window 레이어는 고정 크기 최근 K개 토큰만 들고 있다가 밀어내는데, 우리가 들고 있는 compressed chunk를 끼워 넣으면 "윈도우 밖이지만 압축된 형태로 존재하는 토큰"이라는 논리 상충이 생긴다. 즉 동일한 V3 코드를 sliding window 레이어에 그대로 적용하면 attention 영역 자체가 깨지기 쉽다.
이 글 범위에서 패치할 일이 아니라 스킵했지만, "멀티모달 / hybrid cache 모델에 TurboQuant를 적용하려면 이 참조 구현 위에 레이어 타입 분기가 추가로 필요하다"는 건 꽤 현실적인 제약이다. 음성·비전이 점점 LLM에 합쳐지는 추세라 이 부분이 필요해질 일이 많을 것 같다.
(2) EXAONE은 transformers 5.x와 엇갈려서 test 앞 단계에서 멈춤
EXAONE-3.5-7.8B-Instruct도 같이 실험하려 했지만 로드는 되는데 첫 model.generate()에서 다음으로 죽는다.
# modeling_exaone.py:1124
elif input_ids.shape[1] != cache_position.shape[0]:
AttributeError: 'NoneType' object has no attribute 'shape'EXAONE이 배포한 custom modeling_exaone.py는 transformers 4.x 시대 prepare_inputs_for_generation에 맞춰 작성되어 있어서 cache_position이 항상 넘어온다고 가정한다. transformers 5.x에서 그 경로에 None이 들어오는 케이스가 열리면서 가드가 빠져버렸다. FP16 baseline generate() 단계에서 죽는 거라 V3Cache 호환성은 아예 시도조차 못 했다. TurboQuant이슈라기보다 커스텀 모델 코드와 transformers 메이저 버전 사이의 지연 이슈. 적어 둔다.
(3) 3-bit 설정은 4-bit와 같은 저장 풋프린트를 쓴다
compressors_v3.py의 bit-packing 로직은 indices_per_byte = 8 // bits. 4-bit면 8/4=2 인덱스/바이트, 3-bit면 8/3=2 (내림). 즉 3-bit 설정도 실제론 인덱스 하나가 바이트의 절반(4 bits effective)을 차지한다. 같은 아키텍처에서 K3/V2 ≡ K4/V2 ≡ 5.12× 압축, K3/V3 ≡ K4/V3 ≡ 3.88× 압축. 헤드라인에 "3-bit"라 써 있지만 현재 구현의 실제 저장은 4-bit와 구분되지 않는다는 뜻. 알고리즘이 처음부터 3비트의 정보량을 쓰도록 설계된 것과, 구현이 3비트를 바이트에 패킹하는 것은 다른 얘기다.
3-bit라는 숫자가 실제 저장량에선 4-bit와 구분되지 않는 건 현재 구현의 제약이지만, 알고리즘의 정보량 설계는 여전히 3-bit 경계를 쓰니까 양자화 오차 역시 3-bit 기준으로 쌓인다. 즉 "3-bit의 손해는 다 보면서 4-bit의 이득만 얻는" 포지션이 되기 쉬워 보여서, 의도적으로 3-bit 설정을 고를 땐 조심할 부분이다. 개인적으로도 이런 "헤드라인 숫자와 실제 저장 사이의 갭"은 양자화 쪽에선 흔한 함정이라 듣기만 했었는데 손에 쥐어본 건 이번이 처음이었다. 앞으로 양자화 기법 볼 때 indices_per_byte 같은 패킹 코드부터 먼저 읽는 습관을 들이려 한다.
GPU 세대가 바뀌면 결과가 달라질까
실험이 3090 Ti 한 장이라 "RTX 50 (Blackwell) 이나 H100에서 돌리면 다르지 않을까"라는 질문이 자연스럽게 따라온다. 세대 간 정밀도 지원 차이를 정리해 두면:
| 세대 | Tensor Core 정밀도 | 비고 |
|---|---|---|
| RTX 30 (Ampere) | fp16, bf16, tf32, int8 | fp8/fp4 없음 |
| RTX 40 (Ada) | + fp8 (E4M3 / E5M2) | 첫 소비자용 fp8 |
| RTX 50 (Blackwell) | + fp4 (NVFP4 / MXFP4), GDDR7, 32GB | 첫 소비자용 fp4 |
| H100 / H200 (Hopper) | fp8 + Transformer Engine | 데이터센터 계열 |
| B200 (Blackwell DC) | fp4 + 대용량 HBM | 데이터센터 Blackwell |
결과 3축별로 영향이 다르다.
(1) 품질 (7B 전멸·14B 전승) — GPU 무관일 가능성 높음. TurboQuant V3의 핵심은 Lloyd-Max 스칼라 양자화. 2^bits 개의 센트로이드에 각 좌표를 매핑하는 순수 수학 연산이라 hardware fp8/fp4 Tensor Core를 쓰지 않는다. 센트로이드 인덱스가 결정되는 순간 양자화 오차는 확정이고, 그걸 softmax에 통과시켰을 때 attention 패턴이 버티느냐 깨지느냐는 모델의 representation 밀도에 달린 문제다. RTX 50에서 같은 코드를 돌려도 7B는 깨지고 14B는 통과할 것으로 본다.
(2) 피크 VRAM — 참조 구현에선 GPU 무관, 커널 구현에선 유관. 이번 실험에서 드러난 "저장 공간 절감 ≠ 피크 VRAM 절감" 갭은 매 스텝마다 compressed chunk를 fp16으로 풀어 materialize하는 Python 로직에서 나온다. 이건 Ampere건 Blackwell이건 똑같이 일어나는 일이다. 갭을 닫으려면 compressed domain에서 attention을 직접 도는 fused kernel이 필요한데, 이 경로는 fp8이나 int8 Tensor Core를 써야 효율적이다. RTX 30은 fp8이 없어서 이 커널 경로를 int8 fallback으로 내려야 하고, RTX 40/50이나 H100은 fp8 Tensor Core를 그대로 활용할 수 있다. 0xSero/turboquant의 Triton 커널이 이 쪽을 겨냥하고 있으니, RTX 50 + 0xSero 조합이면 Google 포스트의 "6× 메모리 절감" 숫자가 처음으로 제대로 드러날 가능성이 있다.
(3) 속도 — 참조 구현에선 GPU 무관. 같은 이유. 현재 참조 구현의 병목은 Python 레이어별 압축/해제 오버헤드이지 Tensor Core 처리량이 아니다. RTX 50으로 옮겨도 slowdown 비율은 크게 다르지 않을 것으로 예상. 다만 kernel-fused 구현에선 fp8 Tensor Core 처리량 이득으로 큰 차이가 날 수 있다.
정리하면: "RTX 50에서 돌리면 TurboQuant이 잘 먹히는가"라는 질문은, 질문을 조금 더 쪼개면 이렇게 갈린다.
- 내가 돌린 tonbistudio 참조 구현을 RTX 50에 그대로 올려도 → 거의 차이 없음. 품질 패턴도, VRAM 갭도, 속도도 비슷할 것.
- 0xSero의 fused Triton 커널 같은 "compressed-domain attention" 구현을 RTX 50에 올리면 → Google 포스트의 헤드라인 숫자가 비로소 재현될 여지가 있음. 특히 fp8 Tensor Core 활용으로 메모리·속도 양쪽 다.
- 품질 측면의 모델 크기 민감성 은 GPU와 독립적이라 어느 세대에서도 같은 패턴.
이번 실험은 전자만 측정했다. 후자는 4× RTX 3090 또는 RTX 50급 장비·fused kernel 환경이 필요한 일이라 별도 실험 주제다. "메모리 절감이 실제로 확 드러나는 실험"은 그쪽에서 해야 한다는 숙제를 인지하고 넘긴다.
정리
이번 확장 실험에서 관찰한 것들.
- 품질이 모델 크기에 민감. Qwen2.5-7B에선 V3 5개 config × 3 ctx 모두 needle MISS. 같은 스크립트·같은 config를 Qwen2.5-14B에 걸면 모두 FOUND. 같은 패밀리 내 2배 차이에서 이렇게 갈리는 건 의외였다. 작은 모델이 압축 오차를 흡수할 capacity가 얇다는 쪽으로 해석 가능하지만, 단일 태스크 데이터라 단정은 어려움.
- "저장 공간 절감"과 "inference 피크 VRAM 절감"은 서로 다른 숫자. 이 참조 구현은 compressed chunk를 저장만 하고 attention 연산 직전에 fp16으로 푼다. 그래서
memory_bytes()로 계산한 이론 압축비(5.12× 등)는 그대로 유지되지만max_memory_allocated()피크는 FP16과 같거나 살짝 더 높게 나왔다. 원 논문의 "6× 메모리 절감"은 compressed-domain attention 커널을 전제한 수치인데, 참조 구현이 그 경로를 잡지 않은 것이 원인. - 속도는 pure Python 참조 구현 맥락에서 읽을 것. V3이 FP16 대비 2× ~ 11× 느림. Triton/CUDA 커널이 붙은 포크에선 그림이 많이 달라질 것.
- Hybrid cache / multi-modal 모델엔 추가 엔지니어링 필요. V3Cache가 DynamicCache 단순 상속이라 sliding window·cross-attention 캐시와 바로 맞물리지 않는다. gemma-4 같은 모델에 꽂으려면 cache type 감지·레이어별 분기가 들어가야 한다.
"TurboQuant이 나쁘다"보다는 "어느 구현·어느 전제 위에서 그 숫자가 성립하는가"를 들여다본 결과에 가깝다. 같은 이름의 레포가 GitHub에 여럿 있고(turboquant_plus, 0xSero/turboquant, tonbistudio/turboquant-pytorch), 각자 다른 디자인 선택·다른 최적화를 적용한다. 내가 본 건 그중 파이썬 참조 구현(tonbistudio) 하나의 그림이지, TurboQuant 계열 전체의 평가가 아니다.
이번 실험 덕에 앞으로 KV 양자화 기법을 볼 때 먼저 체크할 것들이 손에 잡혔다. 세 가지 정도. (1) attention이 compressed domain에서 직접 도는 구조인가, 아니면 decompress-then-attend인가. (2) 논문·레포의 압축비 숫자가 저장소의 숫자인가 피크 VRAM의 숫자인가. (3) 모델 크기 스케일링을 어떤 범위에서 검증했는가 — "6× 메모리 절감"이라고 쓰여 있다면 어느 크기 모델에서 관측된 숫자인지.
이 블로그의 GitHub 탐방 편을 쓰는 이유 자체가, 논문·레포 헤드라인 숫자가 내 환경·내 유즈케이스에서도 같은 숫자로 나오는지 손으로 한 번 돌려보는 데 있다. 이번처럼 "어느 전제 위에서 그 숫자가 성립하는가"를 하나씩 구분해서 읽을 수 있게 되는 것, 그 자체가 가장 큰 수확이었다.
다음 편 예고
TurboQuant trending 1위인 TheTom/turboquant_plus(6.4k stars)는 llama.cpp 확장으로 구성되어 있고 Boundary V·sparse V dequantization 같은 실전 최적화가 붙어 있다. 이 글의 후속편에서 같은 Qwen2.5-7B/14B 모델(GGUF 변환)에 대해 같은 needle 태스크를 재현해볼 계획이다. 연구용 구현(tonbistudio)에서 깨진 구간이 실전용 구현(TheTom)에서 어떻게 달라지는지 — 혹은 달라지지 않는지 — 를 보는 게 목적.
한계
- 단일 모델 패밀리(Qwen2.5) × 2 크기만 측정. Llama·Mistral 등 다른 family에선 패턴이 다를 수 있다.
- Needle-in-haystack 단 하나의 태스크. Perplexity·MMLU·long-context QA 같은 지표는 미측정. 니들은 정확한 토큰 회수에 민감한 편이라 KV 양자화에 특히 취약할 가능성이 있다.
- 니들 위치 50% 고정. 시작/끝 근처에선 residual window 효과가 달라진다.
- bitsandbytes 4-bit NF4 가중치 + V3 KV 양자화 혼용. 논문 원래 세팅(fp16 가중치)과 상호작용이 다를 수 있다.
- 속도 수치는 pure Python 참조 구현 한정. 0xSero의 Triton 커널이나 TheTom의 llama.cpp 네이티브 커널은 다른 그림일 것.
- 레포 선택이 결과를 결정한다. Trending 1위 TheTom/turboquant_plus는 이 글에서 다루지 않았고, 다음 편으로 미뤘다. 연구용 PyTorch 참조 구현(tonbistudio)의 재현 기록이지 TurboQuant 기술 일반의 평가가 아님.
- 멀티모달·hybrid cache 모델에서의 동작은 직접 돌리지 않고 구조만 보고 "추가 엔지니어링 필요"라고 적은 부분이 있음. 실제 패치·실행 없이 한 추론이라 그만큼 가설 수준.
- RTX 30 시리즈(Ampere, fp8 미지원) 위에서만 측정. RTX 40/50 (fp8/fp4 Tensor Core)에서 fused kernel 구현을 돌리면 메모리·속도 그림이 크게 달라질 수 있음. 이번 글은 그쪽까지 가진 않았고, 참조 구현 재현에 한정한 단일 세대 측정임.
레퍼런스
이 글에서 돌린 레포
- tonbistudio/turboquant-pytorch — PyTorch 참조 구현
같은 주제의 다른 trending 레포들 (star 순)
- TheTom/turboquant_plus — 6.4k stars, llama.cpp 확장, GGUF 기반, 실전 최적화 포함 (다음 편)
- 0xSero/turboquant — 1.1k stars, Triton 커널 + vLLM 통합
- OnlyTerp/turboquant — 56 stars
- RecursiveIntell/turbo-quant — 24 stars, Rust 구현
원 논문·블로그
