TheTom/turboquant_plus · Python + C
"Implementation of TurboQuant (ICLR 2026) with implementation work, experiments, and follow-on findings beyond the base paper. KV cache compression for local LLM inference."
TL;DR
- 한 주 전 TurboQuant 단일 GPU 재현 글에서 "다음에 6.4k 짜리 TheTom 포크를 돌려보겠다"고 약속한 후속편이다. 이번엔 llama.cpp 커널 층까지 들어가서 RTX 3090 Ti 24GB로 직접 PPL과 throughput을 쟀다.
- 알고리즘은 광고대로 동작한다. Qwen2.5-7B Q4_K_M 기준 KV 캐시는 q8_0 baseline 대비 25~63%까지 줄었고, 추천 config인 asymmetric(
q8_0-K + turbo4-V)에서 PPL은 +0.5%만 늘었다. README가 강조한 "K precision is dominant"라는 발견을 한 번에 재현했다. - 그런데 내 환경에선 별 의미가 없다. 7B + 512 컨텍스트면 KV 캐시는 전체 VRAM의 1% 수준이라, 25% 줄여도 전체로는 0.25% 절약이다. TurboQuant+의 진짜 효용은 M5 Max 128GB로 104B를 128K 컨텍스트로 굴리는 시나리오에 있다. 글의 절반 이상은 그 갭을 정리하는 데 썼다.
- 부가로 WSL2 + CUDA 12.4 빌드 함정 한 가지(
LD_LIBRARY_PATH로 다른 llama.cpp 빌드의 .so가 prepend되어--help도 segfault)를 정리해 뒀다. 같은 환경에서 TheTom을 빌드하려는 사람에게 5분 정도 절약될 만한 후기다.
왜 이걸 다시 보는가
지난 글(007)에서 다룬 tonbistudio/turboquant-pytorch는 순수 PyTorch 참조 구현이었다. 알고리즘 자체와 압축률은 그쪽이 가장 깔끔했지만, 정작 추론 환경에서 KV 캐시가 정말로 줄어드는지는 그 구현으로 답하기 어려웠다. V3Cache가 매 스텝마다 압축된 K/V를 fp16으로 펼친 다음 attention에 넣는 decompress-then-attend 구조라, 저장 공간은 줄어도 피크 VRAM은 베이스라인과 같거나 살짝 더 컸다. 7B에선 압축 후 출력 자체가 깨졌고, 14B에서야 텍스트가 살아남았다.
TheTom/turboquant_plus는 그 빈자리를 정확히 노린 포지션이다. README의 첫 줄부터 "KV cache compression for local LLM inference" 라고 못박고, 알고리즘을 llama.cpp의 cache type으로 끼워 넣어서 --cache-type-k turbo3 --cache-type-v turbo3 한 줄로 켜고 끌 수 있게 만들었다. Metal·CUDA·HIP 백엔드 다 지원, 라이브 추론 environment에서 그대로 돌아간다.
GitHub에서 turboquant로 검색하면 항상 1위로 나오는 레포다 (별 6,400개). turboquant 검색 상위 10개 중 본인이 직접 쓴 후기가 TurboQuant을 사용하는 추론 서버까지 포함하고 있는 걸 보면 — claude-code-local (Apple Silicon에서 122B 모델), SwiftLM (네이티브 MLX), inferrs 등 — 이 포크가 사실상 TurboQuant 알고리즘의 reference implementation 역할을 가져갔다고 봐도 될 정도다.
레포 구조 — 두 레포로 나뉜다
처음 들여다볼 때 한 가지 당황스러운 점이 있는데, "TurboQuant+"는 사실 한 레포가 아니라 두 레포의 묶음이다.
| 레포 | 역할 | 본 글에서 다루는 부분 |
|---|---|---|
| TheTom/turboquant_plus | Python 프로토타입. NumPy/SciPy 코어, 511+ 파이썬 테스트, 벤치마크 스크립트, 문서·페이퍼 모음. | 알고리즘·압축률 검증, demo |
| TheTom/llama-cpp-turboquant | llama.cpp 포크. C 포트, Metal/CUDA/HIP 커널, llama-server/llama-cli/llama-perplexity/llama-bench 바이너리. | 실제 GPU 추론, PPL/throughput 측정 |
본 레포 README가 두 번째 레포의 prebuilt binaries(macOS arm64-Metal, Windows x64 CUDA 12.4)도 같이 안내해 준다. 단 WSL은 prebuilt가 없어서 직접 빌드해야 한다 — 이게 이 글의 빌드 후기 섹션이 생긴 이유다.
이 글에서 두 레포를 어떻게 나눠 다루는지 미리 정리해 두면, Python 프로토타입은 알고리즘 sanity check용으로만 가볍게 보고 (demo.py 한 번), 본격 측정은 llama.cpp 포크 + Qwen2.5-7B Q4_K_M GGUF로 했다.
TurboQuant+이 살아남는 환경 — 먼저 보고 들어가자
내 환경 결과를 먼저 보면 "별 효과 없네"라는 결론이 나오기 쉬운데, 그건 7B 한 모델·24GB 한 GPU·짧은 컨텍스트로 본 단편이고, 이 도구가 진짜로 빛나는 환경은 따로 있다. README에서 가장 인상적인 두 케이스를 옮겨오면:
| 모델 | 가중치 | KV 설정 | 컨텍스트 | PPL | NIAH | 메모리 |
|---|---|---|---|---|---|---|
| Llama-3.1-70B | Q4_K_M | turbo4/turbo4 | 48K | 3.461 (+6.3%) | 30/30 | M5 Max 128GB로 동작 |
| Command-R+ 104B | Q4_K_M | turbo3/turbo3 | 128K | 6.415 (+3.6%) | 10/10 | M5 Max 128GB로 동작 |
이 표를 처음 봤을 때 두 번 읽었다. 104B 모델을 128K 컨텍스트에서 한 대의 MacBook으로 돌리고, PPL 손실은 +3.6%, needle retrieval은 10/10. 같은 모델·같은 컨텍스트를 q8_0 baseline으로 가면 KV 캐시가 약 74GB까지 부푸는데, turbo3로 4.6배 압축하면 16GB 수준으로 떨어진다 (R/V 둘 다 압축 기준). 시스템 메모리 128GB 안에 모델 + KV 캐시가 들어갈 여유가 생긴다는 뜻이다.
즉 TurboQuant+의 가치 명제는 "KV 캐시가 모델 크기에 가까워지는 영역에서, 더 이상 빌리지 않아도 되는 GPU/메모리를 절약해 준다" 쪽이다. 모델 가중치 자체가 작거나 컨텍스트가 짧으면 KV 캐시는 전체 메모리에서 차지하는 비중이 작아, 압축의 이득도 작아진다. 이걸 미리 알고 본인 환경 결과를 봐야 그림이 맞는다.
WSL2 + RTX 3090 Ti 빌드 후기 — 함정 하나
빌드는 표준 llama.cpp 절차다.
git clone --depth 1 -b feature/turboquant-kv-cache \
https://github.com/TheTom/llama-cpp-turboquant.git
cd llama-cpp-turboquant
cmake -B build -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES=86
cmake --build build -j 16 --target \
llama-server llama-cli llama-bench llama-perplexityi9-12900K 16스레드로 약 5분, 디스크 약 4GB. 빌드 자체는 깨끗했다.
문제는 빌드 직후였다.
$ ./build/bin/llama-cli --help
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090 Ti, compute capability 8.6, VMM: yes
Segmentation fault (core dumped)--help도 segfault. CUDA init 직후 즉시 죽고, 어떤 인자를 넣어도 똑같이 죽었다. CPU only(-ngl 0)도 죽었다.
ldd로 라이브러리 로딩 경로를 보고서야 원인이 잡혔다.
$ ldd ./build/bin/llama-cli | head -5
libllama.so.0 => ~/llama.cpp/build/bin/libllama.so.0 (...)
libggml.so.0 => ~/llama.cpp/build/bin/libggml.so.0 (...)
libggml-cuda.so.0=> ~/llama.cpp/build/bin/libggml-cuda.so.0 (...)내가 빌드한 binary가 다른 디렉토리 (~/llama.cpp/build/bin/, 이전에 따로 빌드해 둔 main-line llama.cpp)의 .so를 로드하고 있었다. readelf -d로 보면 RUNPATH는 정상으로 우리 빌드 디렉토리를 가리키고 있는데, LD_LIBRARY_PATH 환경 변수가 그걸 덮어쓰고 있었다.
$ echo "$LD_LIBRARY_PATH"
~/llama.cpp/build/bin:~/llama.cpp/build/bin:...:/usr/local/cuda-12.4/lib64이전에 빌드해 뒀던 다른 버전의 llama.cpp(ggml-base.so.0.9.7)와 우리가 새로 빌드한 turboquant 포크(0.9.11)가 ABI는 비슷하지만 internal layout이 달라서 _ggml_init_cublas 같은 함수 호출 시점에 즉시 죽었다. LD_LIBRARY_PATH를 우리 빌드 디렉토리로 prepend해 주면 깨끗이 동작한다.
export LD_LIBRARY_PATH="$PWD/build/bin:/usr/local/cuda-12.4/lib64"이게 실험 스크립트(run_experiments.sh)의 가장 위에 올라가 있다. 같은 환경에서 turboquant 포크를 빌드한 분들 중에 본인의 다른 llama.cpp 빌드를 가지고 있을 사람이 있을 텐데, 그 경우 RUNPATH 디버깅에 한 시간을 쓰지 않도록 미리 적어 둔다.
자질구레한 두 번째 함정도 적어둔다. bash scripts/get-wikitext-2.sh가 unzip 패키지를 요구하는데, sudo 권한이 없는 환경에서는 그냥 Python으로 우회하면 된다.
wget -q "https://huggingface.co/datasets/ggml-org/ci/resolve/main/wikitext-2-raw-v1.zip" \
-O wikitext-2-raw-v1.zip
python3 -c "import zipfile; zipfile.ZipFile('wikitext-2-raw-v1.zip').extractall('.')"실험 설계
- 레포: TheTom/turboquant_plus (2026-04-22 시점) + TheTom/llama-cpp-turboquant
feature/turboquant-kv-cache - 모델: bartowski/Qwen2.5-7B-Instruct-GGUF Q4_K_M (4.4GB, 단일 파일)
- Qwen 공식 repo의 Q4_K_M은 split GGUF (00001-of-00002, 00002-of-00002)라 합치기 까다로움. bartowski 단일 파일이 더 친화적.
- 4 configs (K cache type / V cache type):
q8_0 / q8_0— baselineturbo4 / turbo4— symmetric 4-bitturbo3 / turbo3— symmetric 3-bit (가장 공격적)q8_0 / turbo4— asymmetric, README가 Q4_K_M에서 권장
- 품질 지표:
llama-perplexity로 wikitext-2 PPL 64 chunks (-c 512 --chunks 64) - 속도 지표:
llama-bench로pp512 / pp2048+tg128 / pp8192+tg128 / pp32768+tg1284종, 각-r 3(3회 평균) - 메모리 지표: PPL run의
llama_memory_breakdown_print표에서contextcolumn 추출 (= KV cache + 작은 context buffer) - 환경: RTX 3090 Ti 24GB, CUDA 12.4 (driver 591.86), WSL2, gcc 11.4, cmake 3.22
- 산출물:
run_experiments.sh(4 config × {ppl, bench} 자동화),parse_results.py(log → results.json),plot_results.py(그림 4종 + thumbnail)
먼저 Python 프로토타입에서 demo는 한 번 돌려서 알고리즘이 정상 동작하는지 확인했다. 4-bit TurboQuant 단일 벡터에서 cosine 0.85, 3.8× compression, 단어 그대로 README와 일치. 이 단계는 sanity check일 뿐이고 글의 본 데이터는 llama.cpp 포크 쪽이다.
참고로
validate_real_model.py(Qwen3-1.7B fp32 다운로드 ~6.5GB)는 시간 비용 대비 새로 알 게 없어서 skip했다. README가 이미 "rotation 후 kurtosis 900 → 2.9" 라는 결론을 명시하고 있고, 본 글의 차별화는 (a) WSL2 빌드 후기와 (b) 4 config 비교에 있다고 봤다.
결과 — PPL
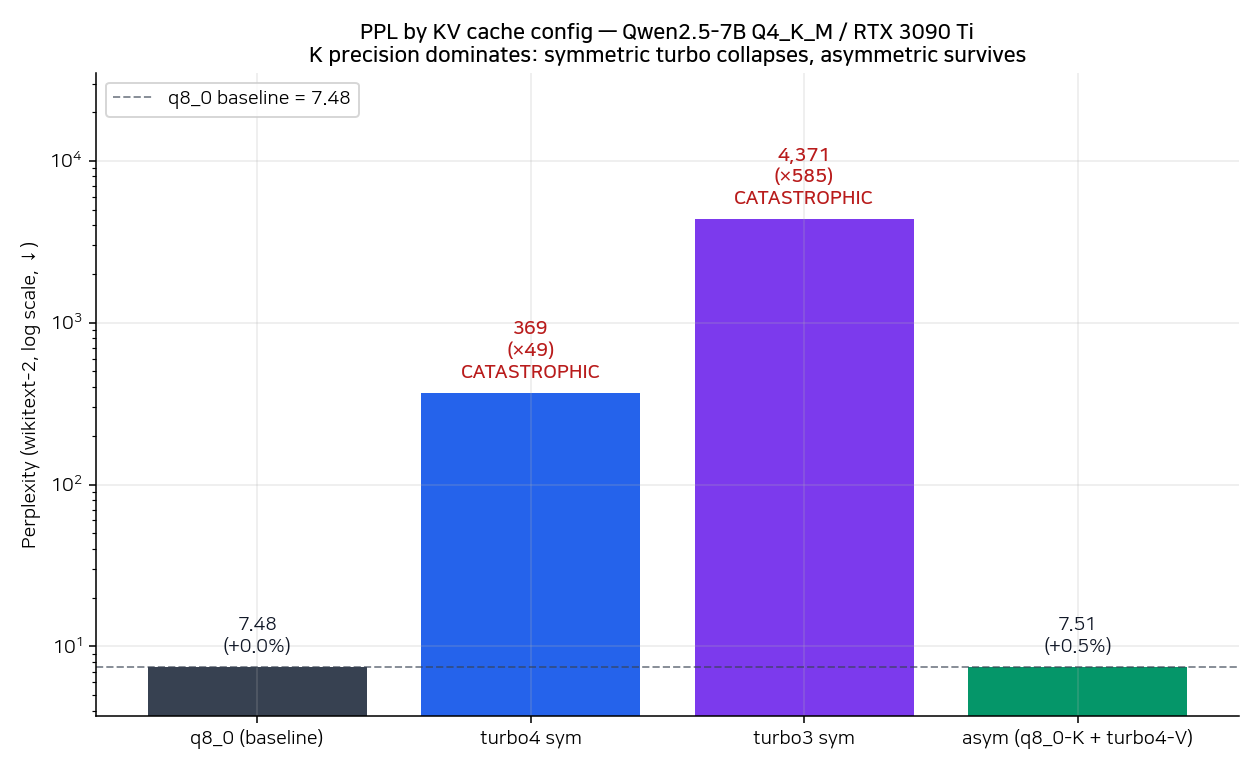
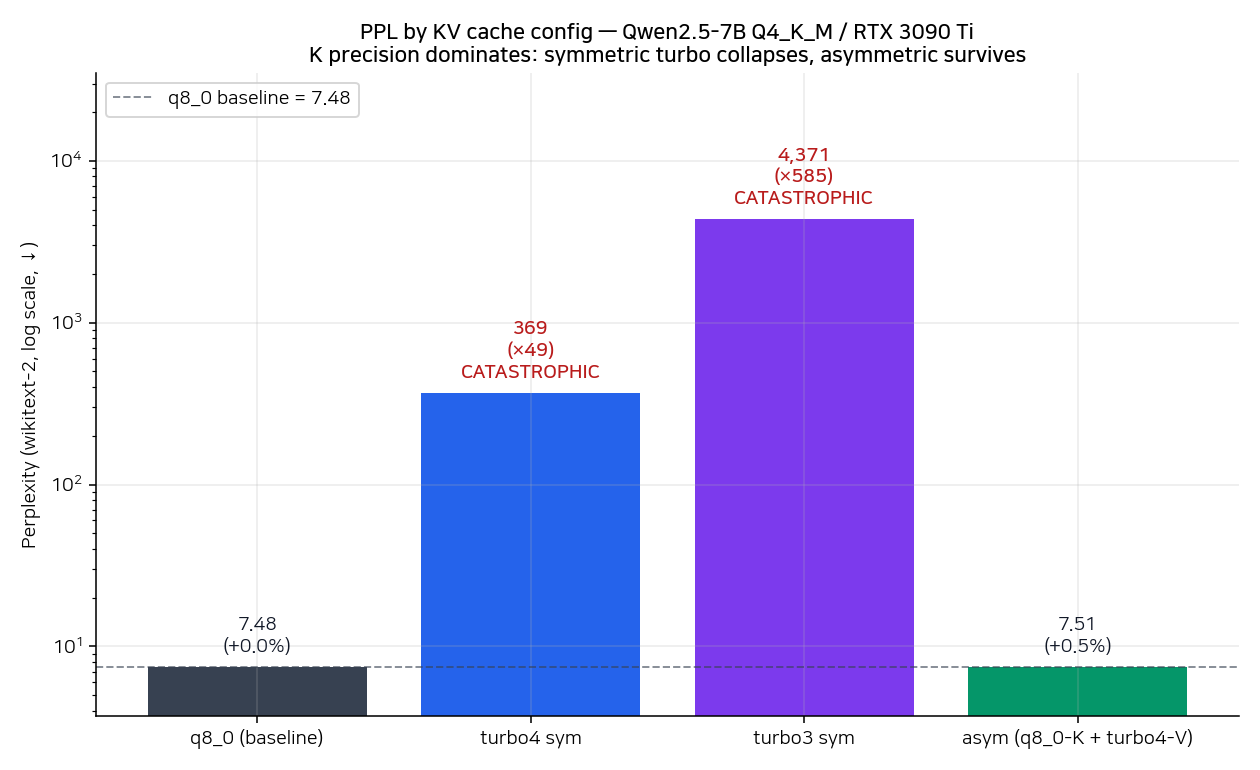
| Config | K | V | PPL | KV @ 512ctx | vs q8_0 | 사용 가능? |
|---|---|---|---|---|---|---|
| q8_0/q8_0 (baseline) | q8_0 | q8_0 | 7.476 | 59 MiB | — | ✓ |
| asym (q8_0-K + turbo4-V) | q8_0 | turbo4 | 7.515 | 44 MiB (saved 25%) | +0.52% | ✓ |
| turbo4/turbo4 sym | turbo4 | turbo4 | 369.4 | 29 MiB (saved 51%) | ×49 catastrophic | ✗ |
| turbo3/turbo3 sym | turbo3 | turbo3 | 4370.7 | 22 MiB (saved 63%) | ×585 catastrophic | ✗ |
이 표가 글에서 가장 보고 싶었던 그림이었다.
- asym (q8_0-K + turbo4-V) 는 거의 무손실로 동작한다. PPL이 baseline 7.48에서 7.51로 +0.5%만 올랐다. KV 캐시는 25% 줄었다.
- symmetric turbo는 둘 다 catastrophic이다. turbo4 sym에서 PPL이 49배, turbo3 sym에서는 585배까지 부푼다. 출력은 사실상 의미 단어 안 나오는 수준.
- 이게 README의 "K precision is the dominant quality factor because it controls attention routing via softmax" 발견을 한 번에 재현한 결과다. K를 q8_0로 보호하기만 하면 V는 turbo4까지 압축해도 견디지만, K부터 압축하기 시작하면 attention의 softmax routing이 무너진다.
흥미롭게도 README의 RTX 3090 결과(@jaker86, Qwen3.5-9B Q4_K_M)는 sym turbo3가 PPL +1.3%로 정상이다. 같은 Q4_K_M이라도 모델 family에 따라 결과가 갈린다는 뜻인데, README도 이걸 명시해 두었다 — "not all Q4_K_M models are sensitive — Mistral-24B, Llama-70B, Command-R+ 104B all handle symmetric turbo fine." 즉 우리 결과는 Qwen2.5-7B Q4_K_M 한 케이스에서 sym가 깨졌다는 것이지 sym 자체가 일반적으로 못 쓴다는 뜻은 아니다.
다만 이 사실은 운영 가이드를 어렵게 만든다. 같은 quantization (Q4_K_M)에서도 모델별로 유효 config가 다르니, 새 모델을 도입할 때마다 PPL 한 번은 직접 측정해 봐야 한다는 얘기다. README의 Configuration Recommendations 문서가 거의 모델·context 매트릭스로 정리돼 있는 것도 이 때문일 것이다.
결과 — Throughput
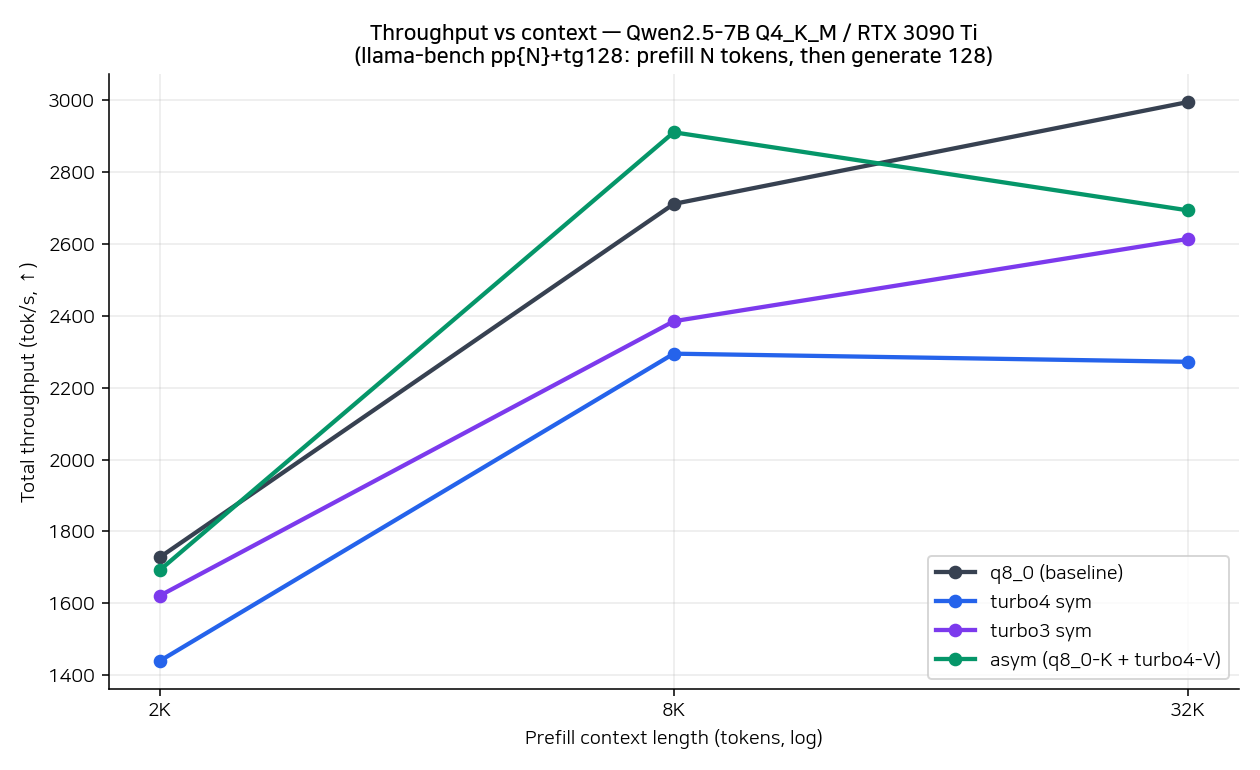
| Config | pp512 (prefill) | pp2048+tg128 | pp8192+tg128 | pp32768+tg128 | 32K ratio |
|---|---|---|---|---|---|
| q8_0 baseline | 6581 t/s | 1728 | 2712 | 2995 | 100% |
| asym (q8_0-K + turbo4-V) | 6497 | 1693 | 2911 | 2694 | 90% |
| turbo3/turbo3 sym | 6392 | 1621 | 2385 | 2614 | 87% |
| turbo4/turbo4 sym | 6520 | 1440 | 2295 | 2272 | 76% |
llama-bench의 pp{N}+tg128은 prefill N 토큰 후 128 토큰 generate한 합산 throughput이다 (prefill + decode wall-time을 합쳐서 토큰 수를 나눈 값). 짧은 prefill에서는 decode 비중이 커서 throughput이 낮게 나오고, 긴 prefill에서는 prefill amortize로 수치가 올라간다.
읽는 방향은 두 가지다.
- Prefill만(pp512) 보면 4 config 차이가 거의 없다 (6,400~6,580 t/s). 짧은 컨텍스트에선 KV 캐시 자체가 작아서 dequant 비용이 attention 시간 안에 묻혀 보이지 않는다.
- Long context(32K) 에서 격차가 벌어진다. q8_0 baseline 100% 대비 turbo4 sym은 76%, turbo3 sym은 87%, asym은 90%다. K 압축의 dequant 비용이 제일 비싸고 (turbo4 sym가 가장 느림), V만 압축하는 asym가 quality와 speed 양쪽에서 sweet spot에 자리 잡는다.
다만 8K에서 asym가 q8_0보다 +7% 빠른 건 살짝 anomaly다. 3회 평균이고 σ는 작지만 (±2.6), 측정 windowed effect일 가능성이 있다. 24K 어딘가에서 두 곡선이 교차하는데, 이 한 번의 측정만으로 "asym이 q8_0보다 빠를 수 있다"고 일반화하기에는 데이터가 모자란다. 재측정 한 번 더 하면 어느 쪽으로든 깨질 수도 있는 숫자라고 봐주면 좋겠다.
결과 — KV 메모리, 그리고 "줄긴 줄었는데..."
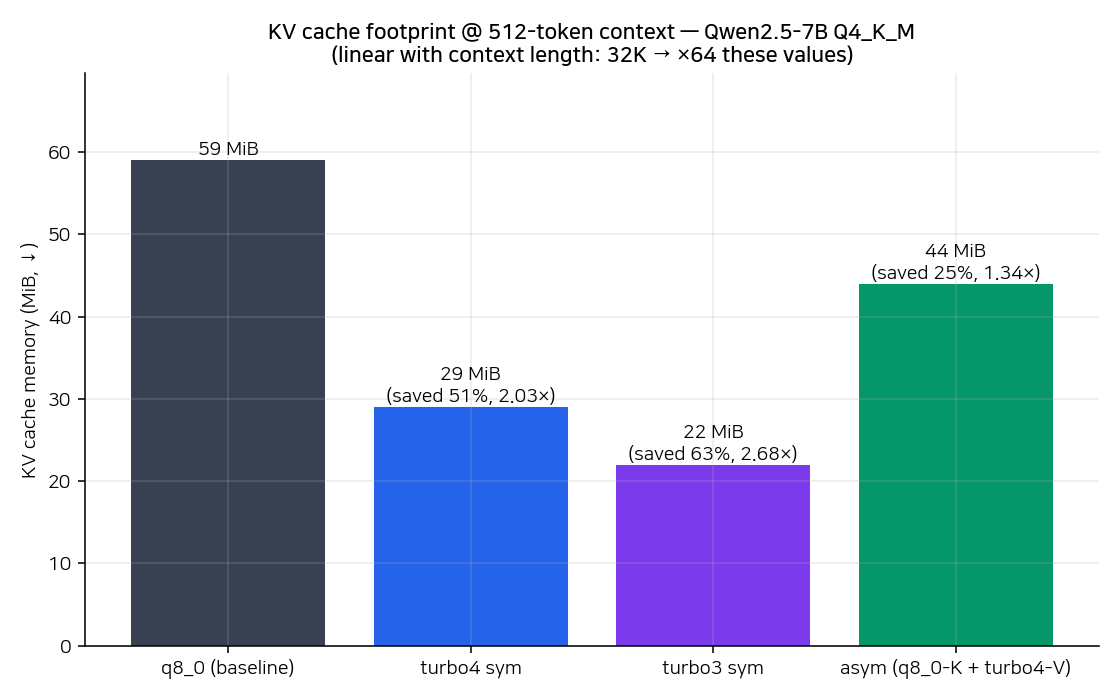
KV 캐시 자체는 광고대로 줄었다. q8_0 baseline 59 MiB → turbo4 sym 29 MiB (51% 절약) → turbo3 sym 22 MiB (63% 절약) → asym 44 MiB (25% 절약). 압축률 숫자만 보면 알고리즘은 정확히 일을 해냈다.
문제는 이 절감이 전체 VRAM에서 차지하는 비중이다. 같은 PPL run의 메모리 분해를 보면:
| memory breakdown [MiB] | total free self model context compute unaccounted |
| - CUDA0 (RTX 3090 Ti) | 24563 = 18693 + (4531 = 4168 + 59 + 304) + 1338 |전체 사용량 5,832 MiB 중 KV 캐시(context)는 59 MiB, 약 1%다. 모델 가중치 4,168 MiB가 71%, compute buffer 304 MiB, unaccounted 1,338 MiB(주로 CUDA runtime/cublas workspace) 가 23%를 차지한다. KV 캐시를 25% 줄여도 전체로는 0.25% 절약, 63% 줄여도 0.6% 절약이다. 체감되는 변화가 없다.
KV 캐시는 컨텍스트에 비례해서 늘기 때문에, 같은 모델로 더 긴 컨텍스트로 가면 그림이 달라진다. 본 측정값을 그대로 외삽하면:
| 컨텍스트 | q8_0 KV | asym KV | 절약량 | 의미 있나? |
|---|---|---|---|---|
| 512 (실측) | 59 MiB | 44 MiB | 15 MiB | 아니오 (전체의 0.25%) |
| 32K | ~3.7 GB | ~2.7 GB | ~1 GB | 살짝 |
| 128K (외삽) | ~14.7 GB | ~11.0 GB | ~3.7 GB | 의미 있음 |
7B 모델로 32K 이상 가면 KV 캐시가 GB 단위로 들어가기 시작하고, 이때 25% 절약은 약 1GB로 환산되어 다른 컨텍스트 길이까지 늘릴 여유가 생긴다. 24GB GPU 한 장으로 7B 모델을 64K 컨텍스트로 굴리고 싶을 때 같은 케이스라면 asym 한 줄로 해결되기도 한다.
다만 본인의 평소 작업 패턴을 솔직하게 보면, 7B 모델로 32K 컨텍스트까지 채워서 굴리는 일은 흔하지 않다. 코드 보조나 짧은 추론은 4K 안쪽이고, 길어 봐야 16K 정도다. 그 영역에서는 TurboQuant+이 있으면 좋지만 없어도 무방한 도구다.
그래서 누구한테 가치가 있나
본 글의 측정 결과만 보면 "내 환경에서는 별 효과 없음"이지만, 그게 곧 "이 도구는 가치가 없음"은 아니다. 누구한테 가치가 있는지 정리해 두면:
- Apple Silicon 고용량 Mac으로 70B+ 모델을 돌리는 사람. README의 메인 사용처가 정확히 여기다. M5 Max 128GB로 Llama-3.1-70B를 48K, Command-R+ 104B를 128K 컨텍스트까지 굴린 검증 결과가 있다. 같은 모델·컨텍스트를 q8_0로 가면 KV가 시스템 메모리를 잡아먹어서 성립하지 않는 시나리오가, turbo3로 바뀌면 동작한다. 이쪽 사용자한테 turbo3는 enabling technology다.
- 클라우드에서 70B+ long-context serving 하는 사람. GPU 시간이 비싼 환경에서 KV 캐시를 4~5배 압축하면 같은 메모리 버짓에 더 많은 동시 요청을 띄울 수 있다 (병렬 batch size 증가). vLLM 통합 작업이 진행 중인 것도 이 맥락이다.
- 24GB 단일 GPU로 7B 이하 모델을 32K 이상 컨텍스트로 운영하는 사람. 본인이 측정한 데이터로 보면 asym config 한 줄(
-ctk q8_0 -ctv turbo4)로 약 1GB의 KV 캐시 절약이 가능하다. PPL은 거의 무손실, 32K throughput은 baseline의 90%. 컨텍스트를 더 늘리고 싶거나 동일 컨텍스트에서 KV 캐시 외 다른 buffer를 위한 여유를 만들고 싶을 때 켜 볼 만하다.
내 평소 작업이 위 세 카테고리 중 어디에도 강하게 속하지 않는다는 게 이번 실험의 결론이긴 하다. 물류·공급망 시계열 작업은 LLM 추론보다 학습/파인튜닝 워크로드가 많고, 컨텍스트도 보통 길지 않다. 그래서 이 실험은 "내 작업에 실용적으로 꽂힌 도구를 찾았다" 가 아니라 "이 도구가 어디서 가치를 갖는지를 직접 확인했다" 쪽에 가깝다. 후자도 충분히 의미 있긴 하다.
007 (pure PyTorch) → 011 (llama.cpp 커널)의 정량 갭
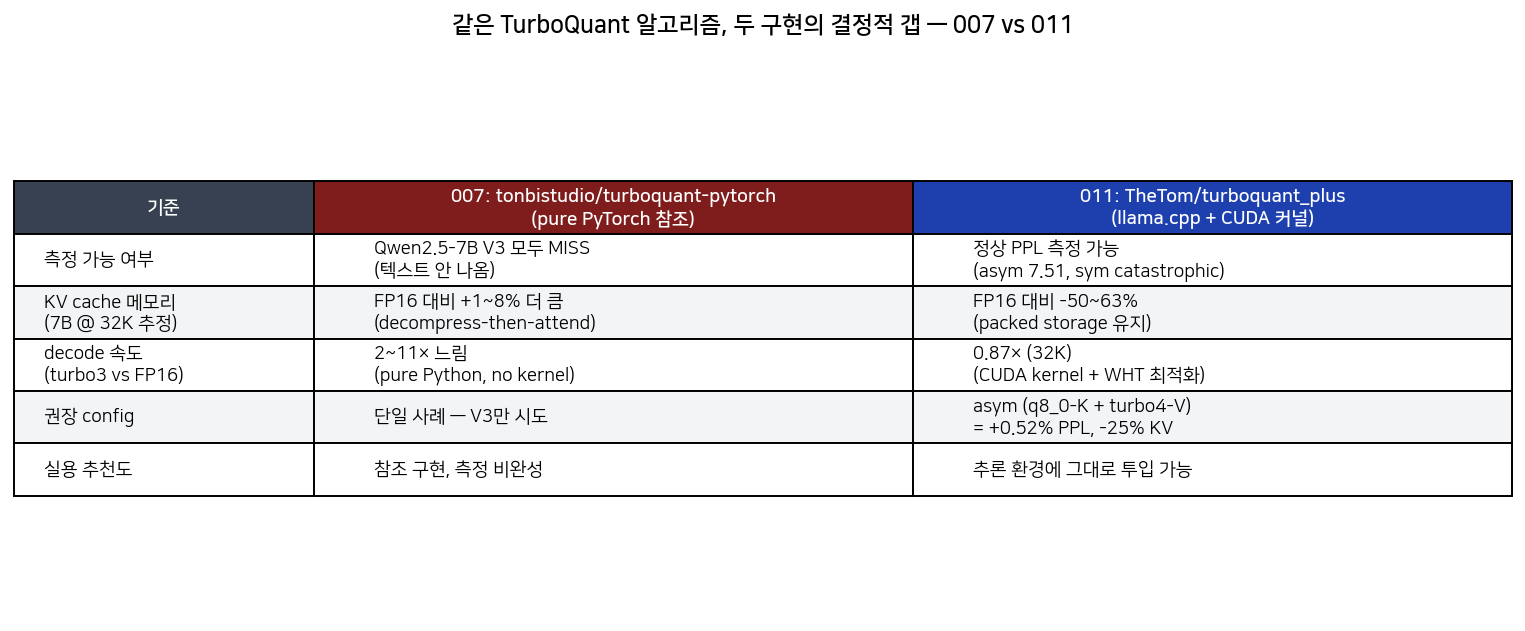
같은 TurboQuant 알고리즘이지만 두 구현 사이의 갭이 결정적이다. 한 주 전 tonbistudio/turboquant-pytorch 글에서 정리했던 결과와 이번 결과를 같은 표 안에 놓으면:
| 기준 | 007: tonbistudio (pure PyTorch) | 011: TheTom (llama.cpp + CUDA 커널) |
|---|---|---|
| 측정 가능 여부 | Qwen2.5-7B V3 18 테스트 모두 MISS (텍스트 안 나옴) | 정상 PPL 측정 가능 (asym 7.51, sym catastrophic) |
| KV cache 메모리 | FP16 대비 +1~8% 더 큼 (decompress-then-attend 경로) | FP16 대비 -25~63% (packed storage 유지) |
| Decode 속도 (turbo3 vs FP16) | 2~11× 느림 (pure Python, no kernel) | 0.87× (32K context 기준) |
| 권장 config | 단일 사례 — V3 한 종류만 시도 | asym (q8_0-K + turbo4-V) = +0.52% PPL, -25% KV |
| 실용 추천도 | 참조 구현, 측정 비완성 | 추론 환경에 그대로 투입 가능 |
같은 알고리즘인데 측정 가능하냐, 의도한 메모리/속도 방향으로 가느냐에서 갈렸다. tonbistudio 쪽이 잘못 만들어졌다는 뜻은 아니다 — 그쪽은 알고리즘 검증과 양자화 오차 측정에 초점을 맞춘 참조 구현이고, 그 목적에는 깔끔한 코드다. 다만 추론 환경에서 KV 캐시를 정말로 줄이는 목적에는 별도의 커널 구현이 필요하고, TheTom은 그걸 llama.cpp 위에서 해냈다.
이 갭이 Google 블로그 포스트의 6× 메모리 절감 주장이 어떤 구현 위에서 성립하는지도 설명해 준다. 원 논문/블로그가 상정한 건 compressed-domain attention (압축된 K/V 텐서를 그대로 attention에 넣어 fp16 materialize를 피함)에 가깝고, 이 경로는 reference impl의 NumPy/PyTorch 코드만으론 안 잡힌다. TheTom은 graph-side WHT rotation, half4 vectorized butterfly, sparse V dequant 같은 일련의 커널 최적화를 추가하고 prefill에선 q8_0 speed parity, decode에선 0.9× 수준까지 끌어올렸다 — README의 "Speed Optimization Journey" 표에 이 여정의 5개 단계가 정리돼 있다.
단일 사례 보고로서의 한계
이번 실험에서 측정한 건 단 하나의 모델·하나의 양자화·64 chunks PPL·하나의 GPU·하나의 OS 환경이다. 일반화 가능성에 대해 미리 적어두면:
- 모델 family: Qwen2.5-7B Q4_K_M에서 sym가 catastrophic이지만, 같은 Q4_K_M인 Qwen3.5-9B에서는 sym가 +1.3% PPL로 정상이다 (README의 @jaker86 결과). Llama·Mistral·Command-R+에서도 sym가 동작한다는 결과들이 있다. 모델별로 직접 PPL 한 번은 측정해 봐야 한다.
- 양자화 경로: Q4_K_M가 아닌 Q8_0 weights로 가면 sym도 안전해진다는 것이 README의 큰 그림이다. 우리는 Q4_K_M만 봤다.
- 컨텍스트: 64 chunks × 512 토큰 = 약 32K 토큰의 PPL만 측정. 진짜 long-context (32K~128K) 환경에서는 KV 캐시가 충분히 커져서 다른 그림이 나올 수 있다 — 다만 그 시나리오는 본 GPU의 한계 안에서 마음 편히 검증하기 어렵다.
- 비교 대상: 011은 main fork만 쓰고, signalnine의 CUDA 최적화 PR 같은 community fork는 안 봤다. README가 그쪽이 더 빠를 수도 있다고 암시한다.
- NIAH 같은 retrieval task는 안 했다. PPL 무손실이라고 해서 retrieval도 무손실이라는 보장은 없다 — 본인 시간 예산이 다 떨어졌다.
여러 caveat이 붙지만, 본 글은 TheTom의 빌드와 첫 측정 후기 정도가 적절한 자리다. 알고리즘에 대한 평가가 아니라 한 환경에서 한 번 돌려본 단일 데이터 포인트.
정리
- 알고리즘은 광고대로 동작한다. asym (
q8_0-K + turbo4-V) 한 줄로 PPL +0.5%·KV -25%를 얻었고, README가 강조한 "K precision dominant" 발견을 한 번에 재현했다. - 본인 환경(7B + 24GB + 짧은 컨텍스트) 기준으로는 체감 효용이 미미하다. KV 캐시는 전체 VRAM의 1% 수준이라, 25% 절약해도 전체로는 0.25%다.
- TurboQuant+의 진짜 가치는 70B+ 모델 + long-context 시나리오에 있다. 특히 M5 Max 128GB 같은 메모리 큰 단일 머신으로 100B급을 돌리려는 사람한테는 enabling technology에 가깝다.
- 같은 알고리즘의 reference impl (007: tonbistudio)와 production impl (011: TheTom)이 측정 가능 여부·메모리 방향·속도까지 갈리는 걸 보면, 알고리즘이 광고대로 동작한다와 추론 환경에서 그 효과가 나타난다는 별개의 문제라는 게 다시 확인됐다. 후자에는 별도의 커널 작업이 필요하고, llama.cpp 포크가 그걸 해냈다.
- WSL2에서 빌드한다면
LD_LIBRARY_PATH에 다른 llama.cpp 빌드가 prepend되어 있는지 먼저 확인하자.--help도 segfault나는 함정이 있다.
다음 글로 본인 도메인(시계열) 쪽에 다시 돌아갈 예정이다. KV 캐시 시리즈는 여기서 한 번 닫고, SalesforceAIResearch/uni2ts (Moirai-2) 쪽으로 넘어가 본다.
참고
- TheTom/turboquant_plus — Python 프로토타입 + 페이퍼 모음
- TheTom/llama-cpp-turboquant — llama.cpp 포크
- TurboQuant 논문 (arXiv 2504.19874, ICLR 2026)
- Google Research 블로그 — TurboQuant: Redefining AI Efficiency
- 007. TurboQuant 3-bit KV 캐시 압축 — 단일 GPU 재현 기록 (선행 글)
- 본 실험 산출물:
experiments/2026-W17-turboquant_plus/(NOTES.md, run_experiments.sh, parse_results.py, plot_results.py, outputs 14개)
