데이터에 대해 알아보자.
우리는 게임을 하면서 데이터를 저장할 필요성을 느낀다. 예를 들어 스타크래프트 유닛 공격력, 방어력, 자원 등등을 표기하기 위해서는 이를 데이터 안에 저장해 두어야 한다.
데이터는 단순형과 복잡형으로 나눌 수 있다. 먼저 단순형에 대해 알아보겠다.
다음은 변수를 정의하는 방법이다.
int attack = 60;(참고로 모든 코드의 끝에는 세미 콜론(;)를 붙여야 한다. 세미 콜론은 하나의 명령어가 끝났다는 것을 의미한다.)
여기서 int는 '자료형'이고, attack은 '변수 이름'이다. 이렇게 정의하면 attack이라는 변수 이름 안에 60을 대입한다는 뜻이다. 수학에서 =는 등호의 의미이지만, 프로그래밍에서는 대입의 의미이다. 변수 이름은 자유롭게 정할 수 있으나 한눈에 알아보기 쉽게 정하는 것이 좋다. 또한 변수 이름에는 몇 가지 규칙이 필요하다.
1)변수 이름에는 영문자, 숫자, 밑줄(_) 문자만을 사용할 수 있다.
2)숫자를 변수 이름의 첫 문자로 사용할 수 없다.
3)변수 이름에서 대문자와 소문자는 구별된다.
4)C++키워드는 변수 이름으로 사용할 수 없다.
다음은 c++변수 이름으로 맞는 것과 틀린 것의 예시이다.
int dog // 맞다.
int Dog // 맞다. dog랑 다르다.
int 1Dog // 틀리다. 숫자를 맨 앞에 쓸 수 없다.
int int // 틀리다. c++키워드를 변수 이름을 쓸 수 없다.
int _dog // 맞다.
int I_have_a_dog_and_a_cat1557 //맞다. int 외에도 여러 자료형이 있다. short, long, long long 등등...
왜 여러 데이터형이 필요할까? → 메모리를 절약하기 위해서이다. 이건 마치 밥그릇과 비슷하다. 밥을 밥 그릇 말고 김치 담을때나 쓰는 대야에다가 담아서 먹는 사람이 있을까? 정신이 이상하지 않고서는 없을 것이다. 마찬가지로 김치 담을 때 밥그릇이나 국그릇에 담는 사람이 있을까? 각자의 용도에 맞는 그릇이 있는 것이다. 자료형도 이와 마찬가지이다. 자료형의 종류에 따라서 크기가 다르고, 이에 따라 저장할 수 있는 데이터의 범위도 다르다.
다음은 여러 자료형의 크기와 범위를 보여준다.
| 자료형 | 명칭 | 크기 | 값의 표현범위 |
|---|---|---|---|
| char | 1바이트 | -128이상 +127이하 | |
| short | 2바이트 | -32,768이상 + 32,767이하 | |
| 정수형 | int | 4바이트 | -2,147,483,648이상 +2,147,483,648이하 |
| long | 4바이트 | -2,147,483,648이상 +2,147,483,648이하 | |
| long long | 8바이트 | -9,223,372,036,854,775,808이상 +9,223,372,036,854,775,808이하 |
자료형의 크기와 범위는 관계가 있다. 컴퓨터의 메모리를 구성하는 기본 단위는 비트이다. 비트는 키고 끌 수 있는 전기 스위치를 연상하면 쉽게 이해할 수 있다. 일반적으로 8비트 = 1byte이다. int는 4byte이므로 32비트이다. 여기서 32비트를 일렬로 늘어놓는다면, 맨 앞의 비트는 데이터가 음수인지 양수인지 판별하는 역할을 한다. 그러면 나머지 31비트가 남아있으므로 2^31을 하면, 양수일 땐 +2,147,483,648, 음수일 땐 -2,147,483,648이 된다. 그래서 범위가 저렇게 되는 것이다. 나머지 자료형도 마찬가지이다.
바이트의 의미는 컴파일러와 운영체제에 따라서 다를 수 있다. 이를 명확하게 확인하는 방법이 있다.
첫 번째는 sizeof를 사용하는 방법이다.
#include <iostream>
using namespace std;
int main()
{
cout << "bool의 크기 : " << sizeof(bool) << endl;
cout << "char의 크기 : " << sizeof(char) << endl;
cout << "short의 크기 : " << sizeof(short) << endl;
cout << "int의 크기 : " << sizeof(int) << endl;
cout << "long의 크기 : " << sizeof(long) << endl;
cout << "long long의 크기 : " << sizeof(long long) << endl;
int attack = 10;
cout << "변수를 이용해 크기 알아보기 : " << sizeof attack << endl;
return 0;
}('using namespace std;'를 사용함으로써 'std::cout , std::endl'이라고 표기할 필요가 없어졌다.)
자료형 그대로 알아보고 싶다면 'sizeof(자료형)'으로 적으면 되고 변수를 통해 알고 싶다면 'sizeof 변수명'으로 적으면 된다.
다음은 컴파일 결과이다.

두 번째 방법은 climits 헤더 파일을 이용하는 방법이다.
헤더 파일은 개발자가 이용하기 편하게 여러 데이터들을 미리 저장해놓은 특정 파일이라고 보면 된다. #include를 통해 포함시켜준다.
#include <iostream>
#include <climits>
using namespace std;
int main()
{
cout << "char의 범위 : " << -CHAR_MAX << "~" << CHAR_MAX << endl;
cout << "short의 범위 : " << -SHRT_MAX << "~" << SHRT_MAX << endl;
cout << "int의 범위 : " << -INT_MAX << "~" << INT_MAX << endl;
cout << "long의 범위 : " << -LONG_MAX << "~" << LONG_MAX << endl;
cout << "long long의 범위 : " << -LLONG_MAX << "~" << LLONG_MAX << endl;
return 0;
}컴파일 결과
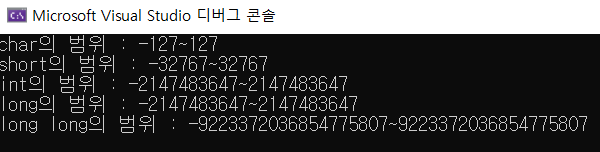
이렇게 데이터형의 크기와 범위를 알 수 있다.
데이터형은 앞에서 나온 것 이외에도 많으므로 다양하게 활용할 수 있다.
아까 변수를 정의하는 방법에 알아봤는데, 좀 더 정확하게 말하자면 선언 및 대입으로 나뉜다.
#include <iostream>
using namespace std;
int main()
{
int attack; // 선언
attack = 10; // 대입
int defence = 20; // 선언과 동시에 대입 = 초기화.
int critical = attack + 2; // 이런식으로도 가능.
cout << "attack : " << attack << endl;
cout << "defence : " << defence << endl;
cout << "critical : " << critical << endl;
return 0;
}실행 결과
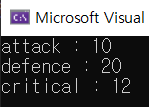
또한 c++식 초기화도 가능하다.
#include <iostream>
using namespace std;
int main()
{
int attack = 10; // c언어식 초기화.
int defence(20); // c++식 초기화.
return 0;
}앞의 자료형은 음수와 양수의 범위를 가지지만, 음수값이 필요 없을 때도 있다. ex)인구수. 자료형 앞에 unsigned를 붙이면 음수 범위가 없어지는 대신 양수의 범위가 늘어난다. 예를 들어 short의 범위는 -32768 ~ +32768이다. 하지만 unsigned short의 범위는 0 ~ +65535이다.
#include <iostream>
#include <climits>
using namespace std;
int main()
{
cout << "unsigned char의 최대값 : " << UCHAR_MAX << endl;
cout << "unsigned short의 최대값 : " << USHRT_MAX << endl;
cout << "unsigned int의 최대값 : " << UINT_MAX << endl;
cout << "unsigned long의 최대값 : " << ULONG_MAX << endl;
cout << "unsigned long long의 최대값 : " << ULLONG_MAX << endl;
return 0;
}실행 결과.
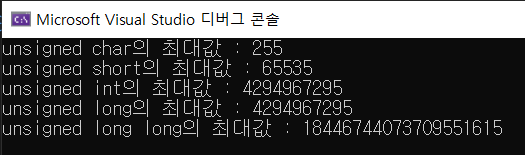
최대값이 늘어남을 알 수 있다.
만약 최대값을 넘어가면 어떻게 될까?
#include <iostream>
#include <climits>
using namespace std;
int main()
{
short test = SHRT_MAX;
cout << "SHRT_MAX : " << test << endl;
test = test + 1;
cout << "SHRT_MAX + 1 : " << test << endl;
unsigned short test2 = USHRT_MAX;
cout << "USHRT_MAX : " << test2 << endl;
test2 = test2 + 1;
cout << "USHRT_MAX + 1 : " << test2 << endl;
return 0;
}실행 결과.
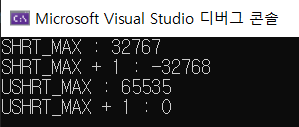
최대값을 벗어나려고 하면 다시 최소값이 되는 것을 알 수 있다. 이를 정수의 오버플로우 혹은 언더플로우라고 부른다. 다음 그림을 보면 쉽게 이해할 수 있다.
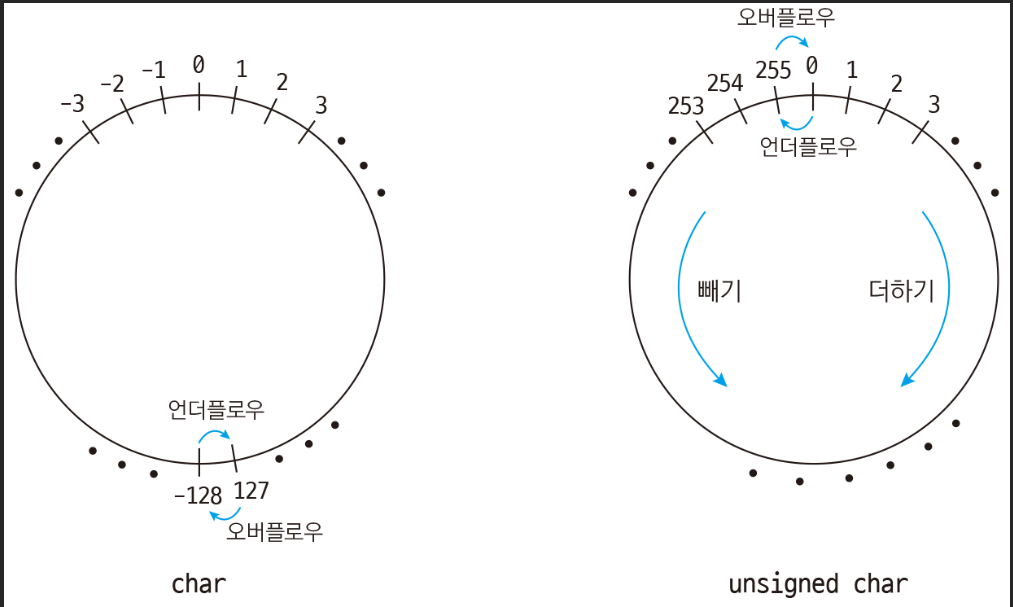
사진 출처
자료형 중 char형과 bool형은 조금 특별하다.
char형은 문자(character)를 저장할 수 있다.
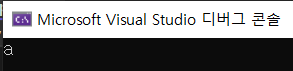
char a = 'a';
cout << a << endl;실행 결과.
bool형은 true냐 false냐를 가려내는 자료형이다.
bool skillReady = true;
bool portionReady = false;
cout << skillReady << endl;
cout << portionReady << endl;
skillReady = skillReady + 100; // bool 자료형은 무조건 0 or 1로 표현한다.
cout << skillReady << endl; // 바꿔 말하면 0만 false이고 이외의 숫자는 모두 true로 판단.실행 결과.

