개요
연구실에서 석준이 진행하는 인턴 트레이닝에 대학원생들도 참여해서 하는 중, Detection & Segmentation 위주로 논문 리뷰 + Detectron2 위주의 과제(?)도 나온다고 한다. 근데 인턴 위주라서 대학원생들은 깍두기 느낌
여기에는 내가 논문 읽거나 정리하는 내용들만 추가할 예정
이번 주에 읽을 논문은 총 3개
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, NIPS 2015, paper link
- Accurate, Large Minibatch SGD:Training ImageNet in 1 Hour, Tech Report on arXiv, paper link
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, ICML 2015, paper link
기본적인 모델의 구조 파악과 트레이닝에 필요한 논문들이다
References
[Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks]
Quick Look
Authors & Affiliation: Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, Microsoft Research
Link : https://arxiv.org/pdf/1506.01497.pdf
Comments: Published at NIPS 2015
TLDR: Detection Network(e.g. Fast R-CNN)과 backbone을 공유하는 Region Proposal Network 제시, Single image, single-path filter를 이용하는 anchor mechnism을 제시. 속도, 성능, 일반화에서 모두 더 나은 결과를 보여줌.
Relevance: 4, 현재 진행 중인 연구의 Baseline으로 사용되고 있는 Model Architecture
Research Topic
- Category (General) : Object Detection
- Category (Specific) : Deep Neural Network Architecture Design
Paper summary (What)
- GPU에서 Down-stream Detection Network와 연산을 공유할 수 있는 Region Proposal Network(RPN)을 제시해 속도 상승 (10ms per image)
- Anchor를 이용해서 하나의 이미지로도 scale-invariant한 region proposal를 수행
- RPN을 기존의 Fast R-CNN에 통합하기 위한 Training Scheme 제시
- Pascal VOC과 MS COCO dataset에서 평가
- 일찍 공개 되어 다른 down-stream task, competition, 제품에서 사용하는 SOTA DNN Architecture가 됨
Issues addressed by the paper (Why)
- 기존의 Region Proposal을 위한 method들은 Detector-free한 external module이라 Down-stream Detection Network와 메모리, 연산 공유가 어려웠다
- Scale-invariance를 위해 Multiple Image, Filter Pyramid를 사용하는 건 너무 연산이 무겁다
Detailed Information (How)
Methodology
- Region Proposal Network 제시
- Anchor 사용 제시(a나 b와 달리 ahcor를 reference로 이용해 single image, single-path filter를 사용한다)
- RPN과 Fast-RCNN을 어떻게 트레이닝 시키는 게 가장 Optimal 한지에 대한 고민이 있을 수 있는데
4-Step Alternating Training를 제시
Assumptions
- Down-stream(Object-Detection) Network의 Feature를 이용해서 Region Proposal이 가능할 것이다 > 둘 모두 Localization을 목표로 하기 때문에 충분히 가능하다고 생각, MultiBox, OverFeat, DeepMask 등을 보면 이미 선례가 있음
- 무거운 Pyramid image, feature를 사용하지 않아도 scale-invariant한 region proposal이 가능하며, 더 적은 parameter를 사용함으로써 generalization이 더 좋아질 수 있다 > COCO Train 후 Pascal VOC Test로 어느 정도 보였다고 생각
Prominent Formulas
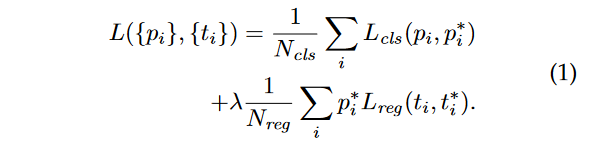 | 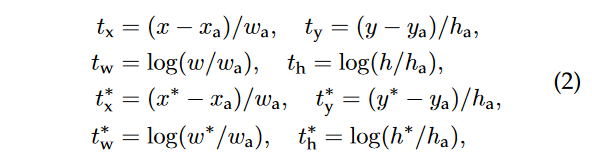 |
|---|---|
| Loss Function 수식 | Regressor에서 coordinate에 사용하는 수식 |
Prominent Figures
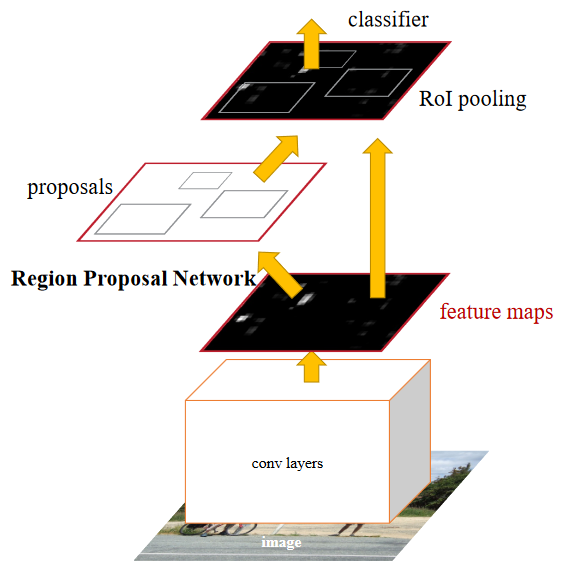 |
|---|
| 전반적인 흐름, Fast-RCNN과 RPN이 같은 conv layers를 공유한다 |
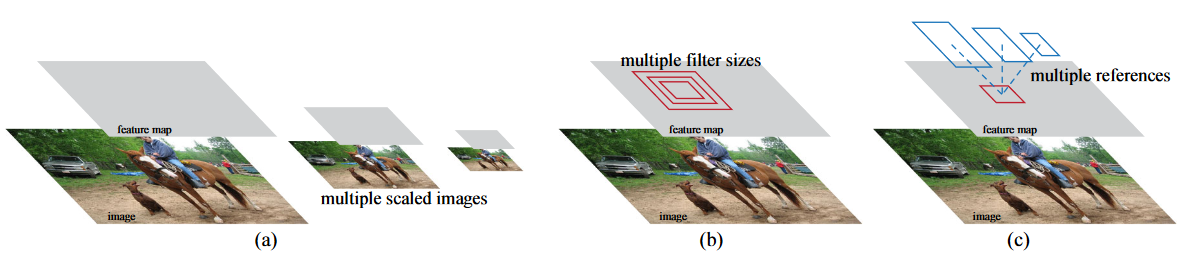 | 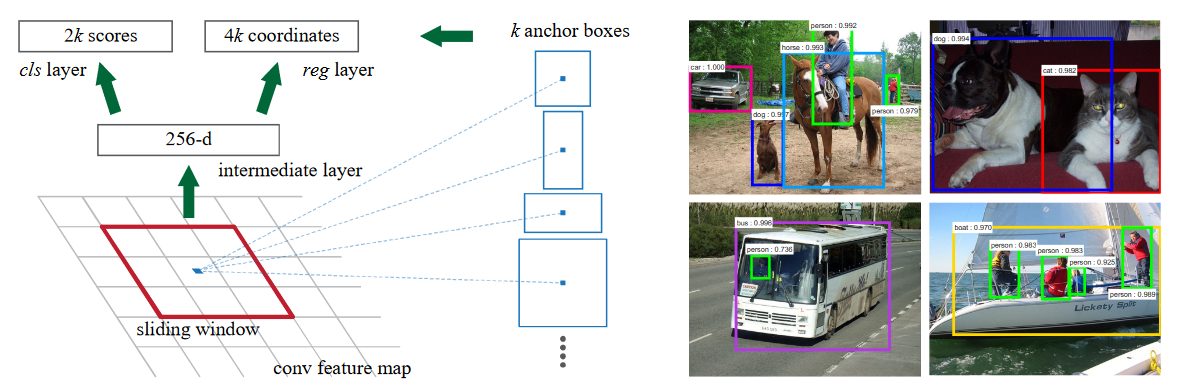 |
|---|---|
| Pyramid(Multiple) images나 filterse를 사용하지 않고 anchor라는 reference를 베이스로 single image, single-path filter로 접근 | 각 anchor(3 scales, 3 ratio로 9개)별 objectness, coordinate을 예측 |
Results
 |
|---|
| Selective Search나 Edge boxes보다 좋은 정확도 |
 |
|---|
| Selective Searc보다 빠른 속도 |
 |
|---|
| COCO에서 Train 후 Pascal VOC에서 Test 했을 때 더 좋은 일반화 성능 |
Limitations
- Anchor Desin이 Heuristic하다 > 관련 실험이 있기는 하지만 자동화가 될 수 있다면 좋지 않을까?
- Sliding Window 부분은 여전히 무거운데 이 부분에서 더 공유할 수 있는 여지가 있을 것 같다
- Proposal 수도 Heuristic하며 Non-Maximum Suppression(NMS)와 같은 알고리즘을 필요로 한다
Confusing aspects of the paper
- 서로 다른 Training Scheme이 보여주는 결과들이 직관적이지 않다, 좀더 분석이 되었다면 좋았을텐데 어떻게 해야할진 잘 모르겠다
Conclusions
The author's conclusions
- RPN은 Fast-RCNN에 거의 cost-free하게 적용될 수 있으며 성능, 속도, 일반화 측면에서 모두 더 나아진 결과를 보여줬다
My Conclusion
- 좋은 assumption, implementation 그리고 experiment가 있었다
- R-CNN, Fast R-CNN, Faster R-CNN으로 이어지는 계보는 딥러닝 시대 초반의 좋은 논문 흐름 중 하나라고 생각
Rating
Fine, Good, Great, Wow, Turing Award
Possible future work / improvements
- SSD와 같은 single-shot detection 방식이 혼합될 여지가 있어보인다
- 실제로 이 뒤에 YOLO 같은 work들이 등장했던 것으로 기억
Extra
References
[Accurate, Large Minibatch SGD:Training ImageNet in 1 Hour]
Quick Look
Authors & Affiliation: Priya Goyal, Piotr Dollar, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, Kaiming He, Facebook(현 Meta)
Link : https://arxiv.org/pdf/1706.02677.pdf
Comments: Tech Report on arXiv
TLDR: batch size를 늘려서 트레이닝할 때 잘 안 되는 문제가 있었는데 learning rate 조절을 통해 validation error와 training curve를 똑같이 가져가면서도 빠르게 트레이닝을 시킬 수 있다는 사실을 알아냈다
Relevance: 3, 기본적으로 알고 있으면 좋은 공식
Research Topic
- Category (General) : Hyper parameter tuning
- Category (Specific) : Learning Rate
Paper summary (What)
- batch size를 늘리는 만큼 learning rate를 줄이면 된다
- 초반에 작은 learning rate에서 시작해서 올리는 learning rate warm up을 하면 초기 학습이 안정적이다
- 이를 증명하기 위해 다양한 실험을 진행해서 ImageNet에서 ResNet-50을 256개의 GPU로 1시간만에 트레이닝 시키는데 성공했다
Issues addressed by the paper (Why)
- Multiple GPU를 이용해서 CNN을 병렬 트레이닝 시킬 때 Single GPU에서 트레이닝 시키는 것과 비슷한 성능을 달성하려면 생각보다 많은 것(learning rate, lr scheduling, normalization, initialization, dropout 등)을 고려해야한다
- 이렇게 트레이닝 된 CNN이 detection, segmentation 등에 사용이 가능한지도 체크를 해봐야한다
Detailed Information (How)
Methodology
- batch normalization
- multiple gpu 사용을 위해서는 gradient aggregation 전략을 사용
Assumptions
[What assumptions were made and are these assumptions valid?]
Prominent Formulas
 |
|---|
| Learning rate linear scaling |
Prominent Figures
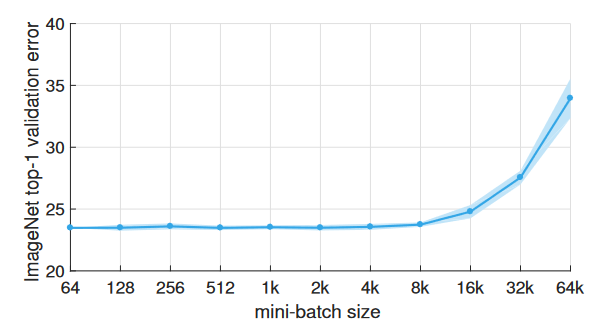 |
|---|
| batch size 8k까지는 별 문제가 없다 |
Results
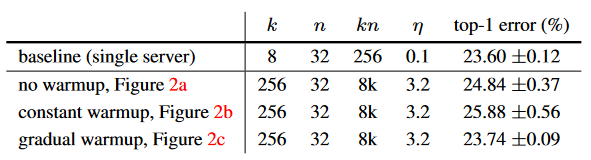 |
|---|
| learning rate linera scaling과 warm up의 validation error |
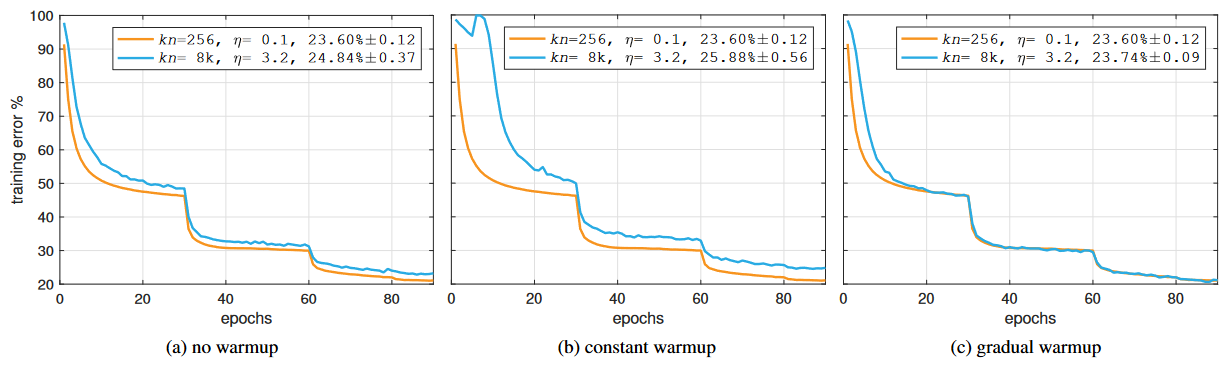 |
|---|
| learning rate linera scaling과 warm up의 training curve |
Limitations
- 그냥 뭐... tech report라서 딱히 없다
Confusing aspects of the paper
- 실험이 많고 코드가 공개되어 있어서 딱히 없다
Conclusions
The author's conclusions
- 이 실험결과들을 바탕으로 detection, segmentation에서도 쓰기 좋은 8개 Multiple GPU를 사용해서 사용하는 안정적인 Multiple GPU 코드를 게시했으니 많이들 사용해주세요
My Conclusion
- 넵
Rating
Fine, Good, Great, Wow, Turing Award
Possible future work / improvements
- 딱히 없음
Extra
References
- None
[Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift]
Quick Look
Authors & Affiliation: Sergey Ioffe, Christian Szegedy, Google Inc
Link : https://arxiv.org/pdf/1502.03167.pdf
Comments: ICML 2015
TLDR: 딥뉴럴넷에서 feature의 internal covariate shift때문에 트레이닝이 불안정해지는 현상을 각 layer에서의 batch normalization으로 해결, 더 안정적인 training이 가능하고 generalization도 좋아진다는 사실을 발견
Relevance: 4, 이걸 안 쓰는 CNN은 없다
Research Topic
- Category (General) : Model Architecture Design
- Category (Specific) : Normalization Layer
Paper summary (What)
- internal covariate shift 현상을 찾아내고 리포트
- 이를 해결할 방법으로 batch normalization algorithm 제안
- training을 안정화 시킬뿐 아니라 generalization도 좋아진다는 사실 발견
Issues addressed by the paper (Why)
- 머신러닝에서 input을 normalization 시키는 건 흔한 테크닉이다
- 그런데 딥뉴럴넷은 층층이 쌓여있어서 feature의 internal covariate shift가 발생하고 쌓여서 트레이닝을 굉장히 어렵게 만든다
Detailed Information (How)
Methodology
 |  |
|---|---|
| BN의 사용 | BN의 트레이닝 |
Assumptions
- internal covariate shift를 제거하면 학습이 훨씬 더 안정적이게 될 것 이다
Prominent Formulas
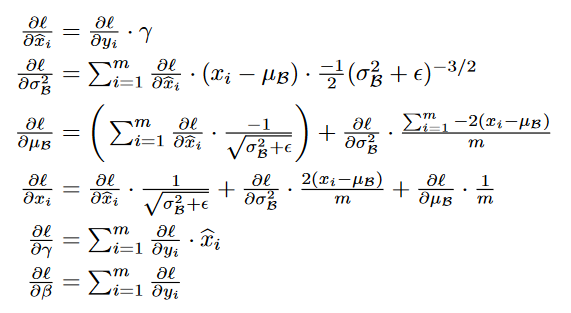 |
|---|
| 트레이닝에 사용되는 상세한 chain rule |
Prominent Figures
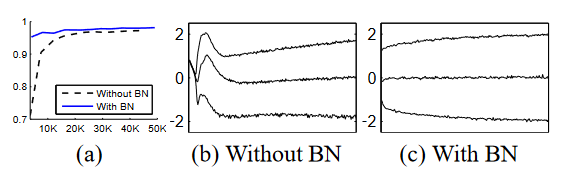 |
|---|
| 훨씬 더 안정적인 그래프 |
Results
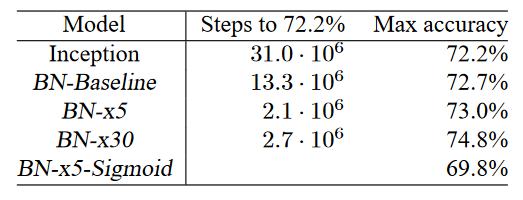 |
|---|
| 결과표 |
Limitations
- 분석해볼 hyper paramter 조합이 더 많은 거 같은데 충분히 제시되지 않음
Confusing aspects of the paper
- internal covariate shift를 해결한다고 저런 효과들이 나타나나?
- bias-variance trade-off라고 볼 수 있는건가?
- 수학적 lower boundary가 없다
Conclusions
The author's conclusions
- batch normalization을 통해 안정화된 트레이닝으로 더 높은 learning rate를 이용해서 빠르게 트레이닝을 시킬 수 있게 되었다
- 학습되는 representation도 더 generalizable하다
My Conclusion
- 맨 처음 태클했던 문제보다 훨씬 더 많은 걸 해결한 것 같다
- 이런 부분이 좀더 분석이 되어야할 필요가 있다
Rating
Fine, Good, Great, Wow, Turing Award
Possible future work / improvements
- batch normalization이 실제로 DNN에 끼치는 효과가 더 상세하게 분석될 필요가 있다
Extra
References
