오늘의 주제
오늘은 밑바닥부터 시작하는 딥러닝의 chapter 3, 신경망 부분에 대해서 다뤄볼 것이다.
퍼셉트론에서 신경망으로
이전 포스트에서 다뤘던 퍼셉트론은 퍼셉트론만으로 복잡한 함수, 컴퓨터가 수행하는 복잡한 처리도 표현할 수 있다는 장점을 가지고 있었다. 하지만 가중치를 설정하는 작업은 여전히 사람이 수동으로 한다는 단점이 있다. 신경망은 가중치에 들어가는 매개변수의 적절한 값을 데이터로부터 자동으로 학습하는 능력을 가지고 있어 퍼셉트론의 단점을 극복할 수 있다.
신경망의 구조
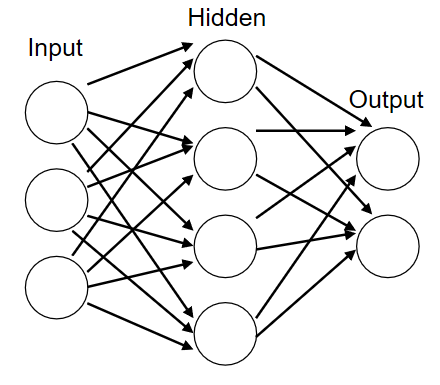
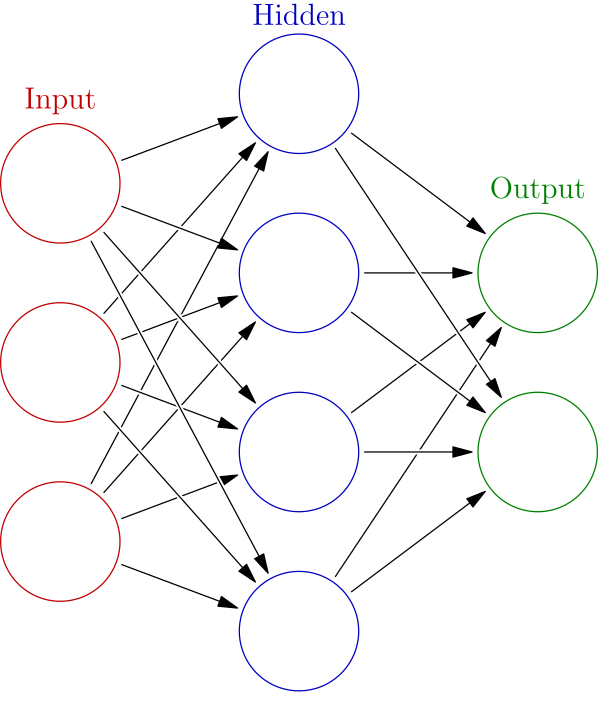 출처 : 위키백과
출처 : 위키백과
여기 그림에서 가장 왼쪽 세로줄에 위치한 원들을 입력층, 가장 오른쪽 세로줄에 위치한 원들을 출력층, 중간 줄을 은닉층이라고 한다. 은닉층의 뉴런은 입력층이나 출력층의 뉴런과 다르게 사람 눈에는 보이지 않는다. 가장 왼쪽부터 0층, 1층 2층 이렇게 표현한다.(이 책에서는 다음과 같이 약속을 하였다.)
퍼셉트론 다시 떠올리기
우리가 전시간에서 퍼셉트론의 식을 다음과 같이 소개했었다.
y = 0 if b+w1x1+w2x2 <=0
y = 1 if b+w1x1+w2x2 > 0
위 식을 간결하게 표현하면 다음과 같이 표현할 수 있다.
y=h(b+w1x1+w2x2)
h(x) = 0 x<=0
h(x) = 1 x>0
여기서 x는 x = b+w1x1+w2x2를 의미한다.
입력 신호의 총합을 x라 하고, 이를 h(x)라는 함수를 통해 변환 되어 y라는 출력값이 나오는 식이 된다.
활성화 함수
위에서 언급한 h(x)를 입력 신호의 총합을 출력 신호로 변환하는 함수, 활성화 함수라고 한다. 입력 신호의 총합이 활성화를 일으키는지를 정하는 역할을 한다.
활성화 함수에는 여러 종류가 있는데 여기서 계단 함수, 시그모이드 함수, ReLU 함수에 대해서 다뤄볼 것이다.
계단 함수
임계값을 경계로 출력이 바뀌는 함수를 말한다. 그래프가 계단 모양이라 계단 함수라 불린다.
파이썬을 이용해서 해당 함수를 구현해 보자.
def step_function(x):
if x>0:
return 1
else:
return 0계단 함수의 그래프는 다음과 같다.
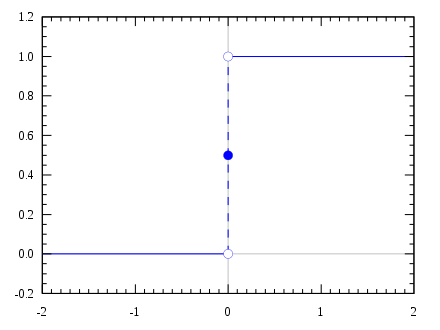
출처 : 위키백과
시그모이드 함수
시그모이드 함수의 식은 다음과 같다.
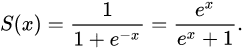
그래프는 다음과 같다.
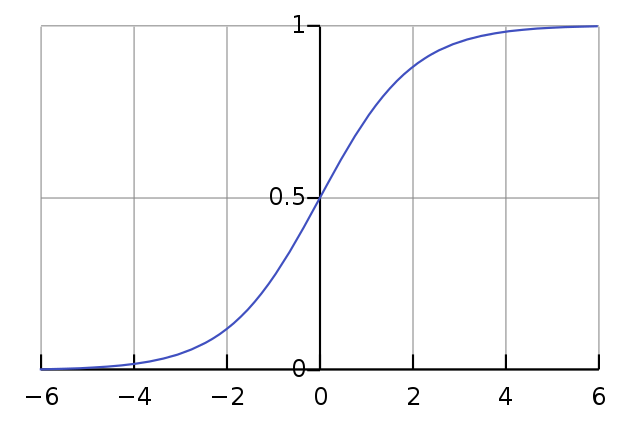
출처 : 위키백과
두 함수의 차이점
시그모이드 함수는 부드러운 곡선으로 입력에 따라 출력이 연속적으로 변화한다. 하지만 계단 함수는 0을 경계로 출력이 바뀐다. 또한 시그모이드 함수는 연속된 실수를 결과로 반환하지만, 계단 함수는 0, 1 중 하나의 값만 반환한다.
두 함수의 공통점, 비선형 함수
두 함수의 공통점은 비선형 함수라는 것이다. 1개의 직선으로는 그릴 수 없는 함수를 뜻하는데, 신경망에서는 활성화 함수로 비선형 함수를 사용해야한다.
그 이유는 선형 함수를 사용하면 신경망의 층을 깊게 하는 의미가 없기 때문이다. 선형 함수를 사용하면 층을 아무리 깊게 해도 은닉층이 없는 네트워크로도 똑같은 기능을 할 수 있다.
h(x) = cx라고 가정했을 때, 3층을 가진 네트워크를 식으로 나타내 보면
y(x) = h(h(h(x)))가 된다. y(x) = c^3x가 되고, 사실상 앞의 계수의 값만 바뀌기 때문에 y(x) = ax와 같은 식이라고 할 수 있다. 그러므로 은닉층이 없는 네트워크로 표현할 수 있다.
ReLU 함수
마지막으로 소개할 함수는 ReLU 함수이다. 예전엔 시그모이드 함수를 신경망 분야에서 사용했으나, 최근에는 이 ReLU 함수를 많이 이용한다. ReLU 함수는 입력이 0을 넘으면 입력을 그대로 출력하고, 0 이하이면 0을 출력하는 함수이다.
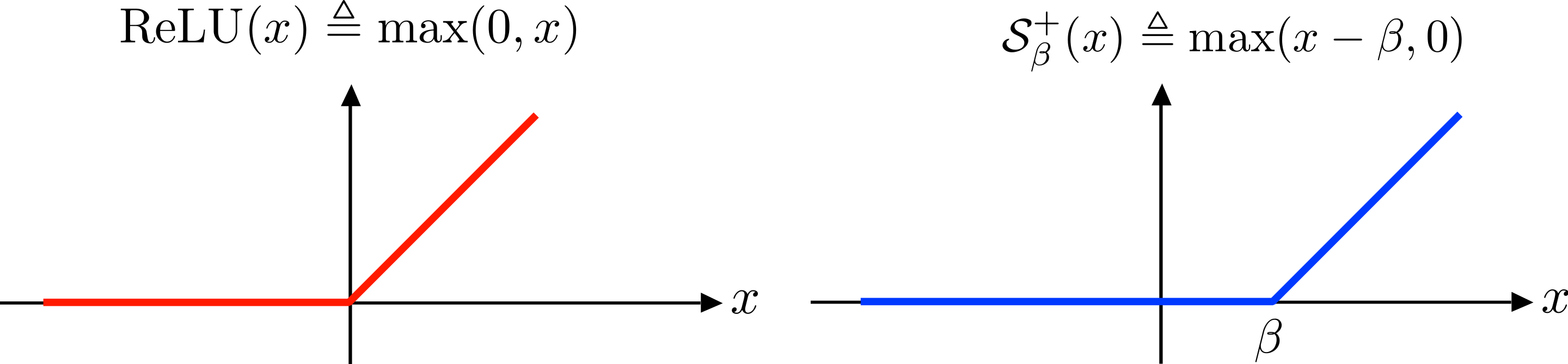
출처 : 위키백과
수식은 다음과 같다.
h(x) = x if x > 0
h(x) = 0 if x <= 0
3층 신경망 구현하기
퍼셉트론과 매우 비슷하지만, 차이점은 각 층에서 입력을 받은 후에 활성화 함수로 은닉층에서 입력을 처리하여 다음 층으로 넘긴다. 3층 신경망에서는 입력층에서 1층 은닉층으로 가중신호와 편향의 총합을 보내고 이 은닉층에서는 활성화 함수 시그모이드로 정보를 처리하고 2층 은닉층으로 다시 정보를 보낸다. 마지막으로 2층 은닉층에서는 3층 출력층으로 시그모이드 함수로 정보를 처리 후 보내고, 3층 출력층은 항등함수를 이용해 그대로 그 입력을 출력한다.
이를 python 코드로 나타내면 다음과 같다.
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return yinit_network에서 가중치 정보를 가져오고, predict 함수가 위에서 설명한 구현 과정을 구현해 둔것이다.
출력층 설계하기
신경망은 분류와 회귀 모두에 이용할 수 있다.
분류 : 데이터가 어느 클래스에 속하는가?
회귀 : 입력 데이터에서 연속적인 수치를 예측하는 것
어떤 문제인가에 따라 출력층에서 사용하는 활성화 함수가 달라진다. 회귀에서는 항등 함수를, 분류에서는 소프트맥스를 사용한다.
항등함수와 소프트맥스 함수
항등 함수는 위에서도 언급했지만 입력을 그대로 출력하는 함수이다.
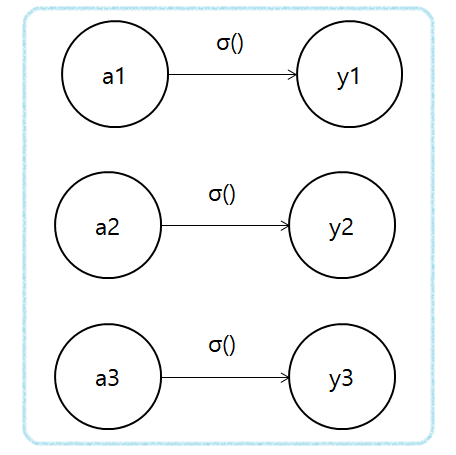
그림으로는 다음과 같이 표현한다.
소프트맥스 함수의 식은 다음과 같다.
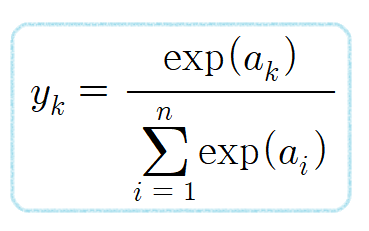
소프트맥수 함수의 분자는 입력신호의 지수함수, 분모는 모든 입력 신호의 지수 함수의 합으로 구성된다.
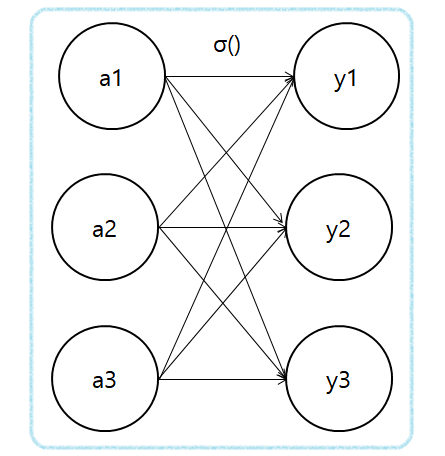
위 그림은 소프트맥스 함수를 나타낸 것이다. 소프트맥스의 출력은 모든 입력 신호로부터 화살표를 받는다. 출력층의 각 뉴런이 모든 입력 신호에서 영향을 받기 때문이다.
소프트맥스 함수의 문제점과 해결책
소프트맥스 함수를 컴퓨터로 계산할 때, 오버플로우 문제가 발생한다. 지수함수를 사용하는 소프트맥스 함수에 특성상 지수함수에서 큰 값이 발생하고, 이 큰 값 끼리 나눗셈을 하게 되면 결과 수치가 불안정해진다.
이 문제를 해결하기 위해 소프트맥스 함수를 개선하였다.

임의의 정수를 더해도 결과 값이 바뀌지 않기 때문에, C를 추가해 오버플로우를 막는것이다. 보통은 입력 신호 중 최댓값을 C에 대입하여 사용한다.
소프트맥스 함수를 계산할 때, 입력 신호 중 최댓값을 빼서 계산한다면 오버플로우 문제를 해결 할 수 있다.
소프트맥스 함수의 특징
소프트맥스 함수의 출력은 0에서 1.0 사이의 실수이며 소프트맥스 함수 출력의 총합은 1이다.
이 성질을 이용해서 소프트맥스 함수의 출력을 확률로 해석할 수 있다.
소프트맥스 함수를 적용해도 각 원소의 대소 관계는 변하지 않는다. 그러므로 분류에서는 출력층에서 소프트맥스 함수를 생략하여 사용한다.
출력층의 뉴런 수 정하기
풀려는 문제에 맞게 적절히 정해야 하지만, 보통 분류에선 분류하고 싶은 클래스 수로 설정하는 것이 일반적이다.
배치 처리
입력데이터를 하나로 묶어서 처리하는 것을 배치 처리라고 한다. 이 배치처리는 컴퓨터 계산에서 큰 이점을 가지고 있다. 대부분의 수치 계산 라이브러리가 큰 배열을 효율적으로 처리할 수 있도록 최적화 되어있으며, 커다란 신경망에서는 데이터 전송이 병목으로 작용하는 경우가 있어 배치 처리를 통해 버스에 주는 부하를 줄일 수 있어 효율적이다. 또한 느린 I/O를 통해 데이터를 읽는 횟수가 줄어, 빠른 CPU나 GPU로 순수 계산을 수행하는 비율이 높아진다.
컴퓨터에서는 큰 배열을 한꺼번에 계산 하는 것이 분할된 작은 배열을 여러번 계산하는것보다 빠르다.
마무리
이번 시간에는 신경망의 구조와 활성화 함수, 출력층 구현에 대해서 알아보았다. 다음 시간에는 chapter 4 신경망 학습에 대해서 다뤄보도록 하겠다.
