데이터베이스 설계
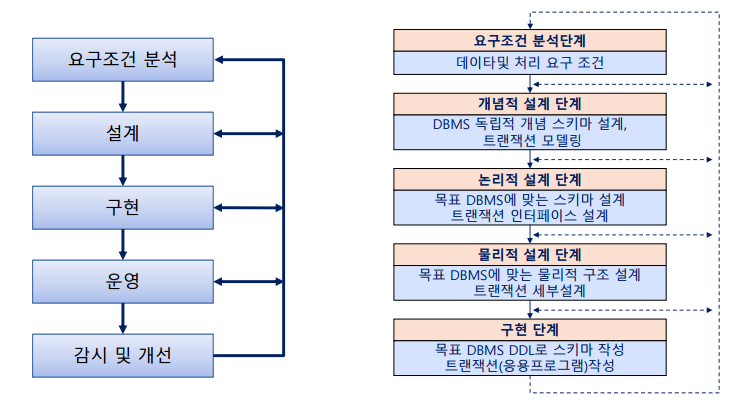
설계
- 개념적 설계
- ER 모델, 트랜잭션 모델링
- 논리적 설계 목표
- DBMS에 맞는 스키마 설계
- 트렌젝션 인터페이스 설계
- (table 만들어짐) – 테이블에 빠르게 접근하기 위해 제품마다 각자 다양한 방법을 씀
- 물리적 설계
- 물리적 구조를 설계함, 트랜잭션 내부설계
구현 DBMS DDL 스키마로 작성 (SQL)
운영
감시 및 개선- 중간에 문제가 생기거나 데이터가 늘어나서 성능변화가 생기면 수행함
데이터베이스 설계시 고려사항
-
무결성
- 제약조건 (학년은 1~4까지만)
- foreign key가 있다면 참조무결성을 지켜야해서 foreign 키가 가르키는 data가 있어야함
-
일관성
- 데이터간, 응답 간의 일치성이 중요함
- 100원 빼면 반대쪽에 100원 더해주기
-
회복
- 장애 복구
- 운용중에 어떠한 트랜잭션이 비정상종료되면 이를 복구해야함
- 일관성을 유지하기 위해서 중간까지만 수행중이던 트랜잭션이 오류나면 처음으로 되돌림
-
보안
- 불법접근의 방지
- 로그인을 해서 권한이 열린것만 사용하게 해줌
- 테이블에서 select, insert, delete, update 4가지 작업에 대한 권한을 각 테이블별로 설정할 수 있음
-
효율성
- 응답시간, 저장공간, 처리도
처리도 – 초당 트랜잭션이 몇 개 실행되는가 1000TPS = 초당 1000개 클수록 효율적
- 응답시간, 저장공간, 처리도
-
데이터베이스 성장
- 응용과 데이터의 계속적 확대
요구조건 분석
정보의 내용과 처리 요구조건의 수집
- 정보수집은 설문지 인터뷰 회의를 통해 문서화
범 기관적 경영목표와 제약조건의 식별
공식적인 요구조건 명세의 작성
- 작업 데이터 관계, 데이터 요소 사이의 제약조건, 값의 유일성, 함수 종속성 등도 명세에 포함
요구조건 명세의 검토
개념적 설계

1) 뷰 통합방법 – 하향식 방법
- 각 부분별 뷰를 식별하고 모델링함
개체와 관계를 찾아내서 er모델을 씀
2) 애트리뷰트 합성 방법 – 상향식 방법
- 작업 데이터에서 시작 -> 개체, 키 식별 -> 관계성 식별
위의 작업들은 추상화 일반화 일반화를 통해 이루어진다
개체간의 계승관계가 있을 수 있고, 이를 ER로 표현한다
트랜잭션 모델링
처리중심 설계이고, 동적인 설계이다.
응용을 위한 트랙잭션을 식별하고 명세, I/O의 기능적 행태를 명세한다.
논리적 설계
ER 모델 개념적 스키마로부터 목표 DBMS가 처리할 수 있는 논리적 스키마를 생성
RDMBS
- 논리적 데이터 모델로 변환
- ER모델을 목표 DBMS의 DDL로 변환 (SQL)
- 트랜잭션 인터페이스 설계
- 입출력과 기능적 형태 정의
- 스키마의 평가 및 정제
- 정량적 정보 : 데이터의 양, 처리빈도수, 처리작업량
- 성능평가기준 : 논리적 레코드 접근, 데이터 전송량, DB크기
ER모델을 독립된 릴레이션 관계를 표현
관계 데이터 모델로의 변환 예시
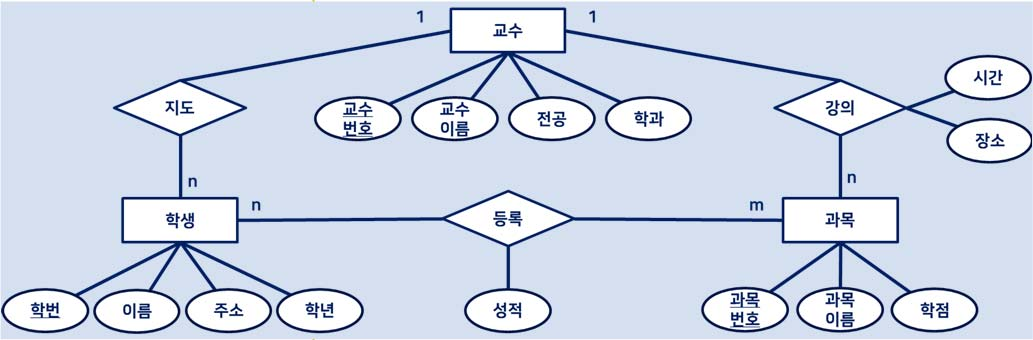
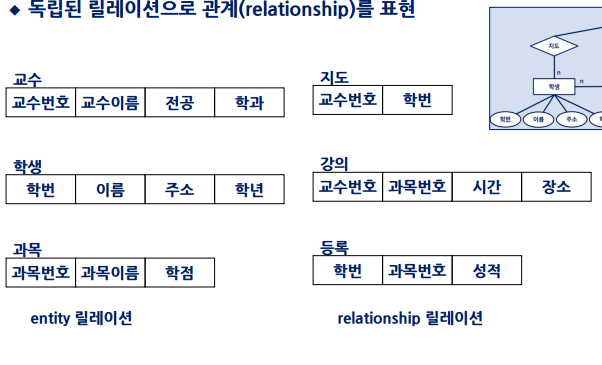
보이는것처럼 er 모델에서 서로 관계가 있는것들을 묶어서 표현하였다.
하지만 하지만 지도, 혹은 강의는 1대 N 관계임
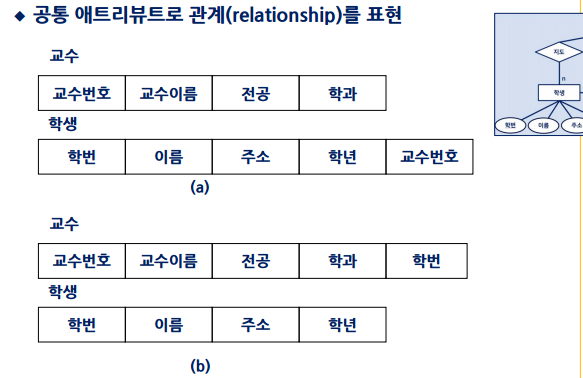
따라서 다음과 같이 학생에 교수번호를 넣거나, 교수에 학번을 넣어서 관계를 표현 할 수 있음.
만약 교수와 학생관 지도 릴레이션을 나타내려면 교수에 학번을 추가한다. 이때는 교수는 학생 1명과 관계를 맺는다 n대 1
- 만약 1대1관계면 둘중에 아무거나 써도 된다.
물리적 설계
저장레코드의 양식 설계
데이터를 클러스터링 하는게 좋다
클러스터링이란 데이터가 한곳에 뭉쳐있는것을 말한다.
접근경로 설계
옵션 : 여러 유형의 인덱싱 기법, 디스크상의 레코드 집중화, 포인터, 해싱 등
고려사항 : 응답시간, 저장공간의 효율화, 트랜잭션 처리도
물리적인 위치가 바뀌더라도 여전히 가르킬수는 있음
초단 트랜잭션을 높일 수 있는 방향으로 access path 결정
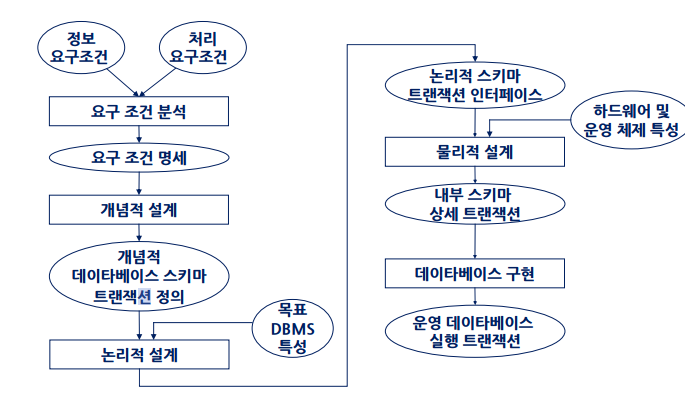
설계과정의 요약
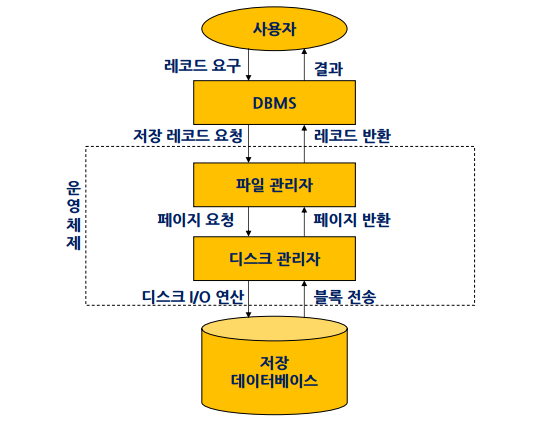
데이터베이스 접근, 저장
데이터베이스 접근 과정
데이터베이스의 저장
직접 접근 저장 (특정위치에 직접 저장)
- DISK SSD (테이프는 감아야해서 차래대로 읽어야한다)
- 비휘발성 온라인 장치
임의 접근 시간 = seek tiem + rotational delay + block transer time
약 10~30 : 메민 메모리 접근시간에 비해 매우 느림
대량전송률 – 연속적인 블록을 전송하는 시간
디스크 접근 횟수의 최소화가 필요하고 이를 고려해서 저장해야함
섹터단위로 읽는 것이 아니라 섹터를 묶어서 블록/페이지/클러스터 단위로 만드 후 접근함
학생, 교수, 과목 같은 테이블들을 파일로 디스크에 저장, 파일단위로 읽어냄
파일관리자가 릴레이션별로 파일을 저장함 (어떤 파일이 어떤 페이지에 있는지 알고있음)
파일과 페이지 세트
파일
- 페이지 저장
- 페이지 세트로 구성
달력과같은 페이지가 생기고, 그 안에 데이터가 저장된다.
하나의 레코드는 하나의 페이지에 저장된다 가정한다
0번에는 메타데이터, 사용되지 않는 공간은 자유공간 page set 이다.
삭제하고나면 자유공간이 된다
그 후 추가는 자유공간 아무데나 넣어도 된다. 페이지헤드에 포인터가 있는 경우 현제페이지 번호 || 다음페이지번호를 넣는다.
레코드 구성 및 레코드 연산
한 페이지의 크기는 1 2 4 8 16 등이 일반적이다
- sqlite 에서는 기본이 1kb이다
- winsdows / linux 의 file system cluster 크기 4kb이다.
한페이지안에는 여러 개의 데이터가 들어간다
레코드 하나의 크기가 수kb가 될 수도 있다. (이미지, 비디오)
이때 LOB를 지원한다
- CLOB
- BLOB
시작 바이트에 각 레코드의 크기를 더해서 다음 레코드의 위치를 계산할 수 있음.
실제 계산에서는 다음과 같이 수행된다.
1개의 페이지를 dbms에서 읽으려고 할 때 빠른 읽기를 위해서 buffer를 만들어둠.
DISK에 저장되어 있는 것을 복사해서 메모리에 넣고 buffer에서 반환함 (파일관리자안에 buffer관리자가 존재함)
Slotted page
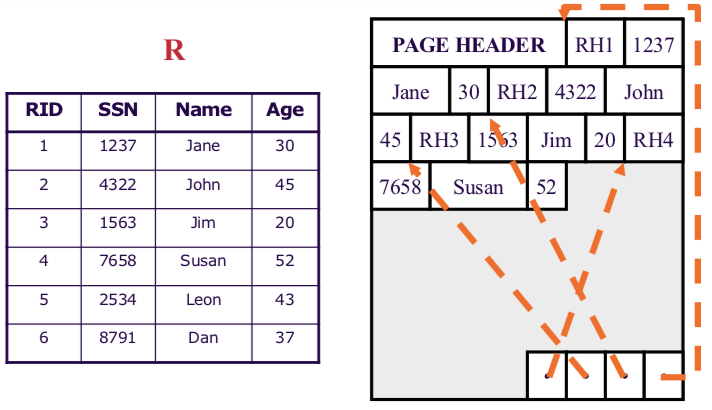
다음과 같은 페이지를 슬롯페이지라고 한다. 모든 페이지는 다음과 같은 형태이며 RID를 통해 접근한다
RID는 두 개의 숫자로 이루어져있는데, 앞에 숫자는 페이지번호, 뒤의 숫자는 슬롯번호이다. 각 슬롯은 특정 레코드를 지칭하고 있다.
다음과 같은 형태가 사용되는것은 레코드의 길이가 서로 다 다르기 때문에 더 빠르게 접근하기 위해서이다.
