📌 검증(Validation) Set
- 훈련 Set 60% + 검증 Set 20% || 테스트 Set 20%
- 두 번 split
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42
)
sub_input, val_input, sub_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42
)
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(sub_input, sub_target)
print(dt.score(sub_input, sub_target))
print(dt.score(val_input, val_target))0.9971133028626413
0.864423076923077
📍 교차 검증 (only ML)
- 데이터를 n개의 폴드로 나누고 순서대로 검증 set로 사용
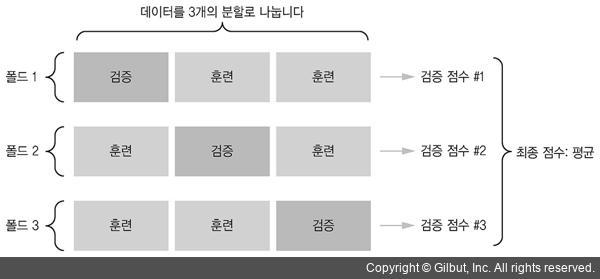
- cross_validate() : 기본 5개의 폴드로 분할 -> 5개의 모델
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
import numpy as np
print(np.mean(scores['test_score'])){'fit_time': array([0.00821614, 0.00822687, 0.00734401, 0.00731444, 0.00711036]),
'score_time': array([0.00078368, 0.0007267 , 0.00067711, 0.00068378, 0.00078654]),
'test_score': array([0.86923077, 0.84615385, 0.87680462, 0.84889317, 0.83541867])}
0.855300214703487 // 검증 score 평균 (이름만 test)
📍 그리드 서치
-
GridSearchCV()
-
min_impurity_decrease : 부모와 자식 노드간 불순도 차이(감소율)의 최솟값을 지정하여 이보다 작으면 분할 X
(= 정보이득. 클 수록 좋은 분할) -
5폴드 교차검증 x 5번 = 25개 모델
-
n_jobs = -1 : cpu의 모든 코어를 사용해 병렬로 작업
-
최적의 값을 best_estimator_ 속성에 넣어 결정 트리로
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
dt = gs.best_estimator_
print(dt.score(train_input, train_target))
print(gs.best_params_)
print(gs.cv_results_['mean_test_score'])0.9615162593804117
{'min_impurity_decrease': 0.0001} // 최적
[0.86819297 0.86453617 0.86492226 0.86780891 0.86761605]
-> 교차검증 점수
📍 랜덤 서치
- 균등 분포 샘플링 클래스 : uniform(실수), randint(정수)
- 넒은 범위, 랜덤 샘플링 -> 모델 훈련 효율적
from scipy.stats import uniform, randint
rgen = randint(0, 10)
rgen.rvs(10)array([1, 0, 4, 8, 6, 2, 2, 3, 6, 9]) // 랜덤 수 뽑아줌
- RandomizedSearchCV
n_iter : 샘플링 횟수
params = {'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25),
}
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params,
n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)
print(gs.best_params_)
print(np.max(gs.cv_results_['mean_test_score']))
dt = gs.best_estimator_
print(dt.score(test_input, test_target)){'max_depth': 39, 'min_impurity_decrease': 0.00034102546602601173,
'min_samples_leaf': 7, 'min_samples_split': 13}
0.8695428296438884
// mean_test_score의 최댓값 = best_params_ 로 찾은 검증값
0.86 // 최적값으로 Test
